1. Background
The Weibull distribution is a popular continuous probability distribution that is commonly utilized to model the lifetimes or failure times of objects or systems. It was initially introduced by Waloddi Weibull in 1951 [
1] and has since found applications in various fields. For instance, in reliability engineering, Keshevan et al. [
2] employed the Weibull distribution to model the Hertzian fracture of Pyrex glass. In another study, Queeshi and Sheikh [
3] used the Weibull distribution to analyze adhesive wear in metals. Similarly, Durham and Padgett [
4] applied the distribution to carbon fibers and small composite specimens. Almeida [
5] investigated the failure of coating using the Weibull distribution, while Fok et al. [
6] focused on its use for brittle material. Additionally, Newell et al. [
7] employed the distribution to study compressive failure in high-performance polymers and Li et al. [
8] analyzed concrete components using the Weibull distribution.
The distribution mentioned above has been widely applied as a flexible modeling tool in various fields, addressing a diverse range of issues. It has been successfully utilized in disciplines such as quality control, weather forecasting, industrial engineering, electric systems engineering, communications systems engineering, hydrology, and more. For instance, Bebbington and Lai [
9] utilized it for volcanic eruptions, while Durrans [
10] and Heo et al. [
11] applied it to regional flood frequency analysis. Fleming [
12] used it to describe the dynamics of foliage biomass on Scots pine. In the field of Economics, Roed and Zhang [
13] employed it to analyze unemployment duration data. In the context of wireless communications, the Weibull distribution is very flexible. Ikki and Ahmed [
14] analyzed the performance of multi-hop relaying systems over Weibull fading channels in terms of bit error rate and outage probability. A similar analysis of the bit error rate and outage probability over multi-hop Weibull fading channels was also conducted by Wang et al. [
15].
The Weibull distribution is defined by two parameters: the shape parameter (
) and the scale parameter (
). The shape parameter determines the shape of the distribution curve, while the scale parameter determines the characteristic magnitude or scale of the failure times. Depending on the value of the shape parameter
, the Weibull distribution can exhibit different shapes. When
, the distribution is positively skewed, indicating a decreasing failure rate over time. This shape is commonly known as the bathtub curve and is often observed in reliability analysis. In this curve, failures are more likely to occur either early on, due to manufacturing defects or initial wear, or in the later stages, due to aging or wear-out effects. When
, the distribution simplifies to the exponential distribution, which is the only continuous distribution with a constant hazard function on the positive axis. For
, the distribution is negatively skewed, indicating an increasing failure rate over time (Rinne [
16]).
The versatility and importance of this distribution can be seen in its close relationship with several well-known distributions in statistics. It includes other distributions as special cases, such as the exponential distribution (when the shape parameter
is equal to 1) and the Rayleigh distribution (when
is equal to 2). Furthermore, if
T follows a Weibull distribution, then
follows an extreme-value distribution. By applying a simple log transformation, the Weibull distribution can also be converted into the Gumbel distribution. Additionally, it acts as a limit distribution for the Burr distribution, establishing a significant connection between these distributions (Lai and Xie [
17]). These relationships further emphasize the importance and wide-ranging applicability of the Weibull distribution in statistical modeling and analysis.
The Weibull distribution is widely used in modeling lifetimes because it can effectively represent different failure patterns observed in real-life situations. Failure data can be classified into two types: complete data and incomplete (censored) data. Complete data refer to cases where the actual observed values are known for every observation in the dataset. On the other hand, censored data occur when the actual observed values are unknown for some or all of the observations. It is worth noting that there are various types of censoring; more information can be found in the work by Lawless [
18]. Several studies have examined the application of the Weibull distribution in analyzing censored data. For example, Ghitany et al. (2005) [
19] and Klakattawi (2022) [
20] extended the Weibull model and applied it to bladder cancer data, Joarder (2011) [
21] and Jia et al. (2016) [
22] studied leukemia data, and Lee et al. (2007) [
23] focused on the head-and-neck-cancer trial. The Weibull distribution has an intriguing application in models involving a fraction of cure. This distribution is particularly well-suited for estimating the time it takes for cancer cells to produce detectable cancer. As a result, it has gained significant popularity in this field. Several studies, including those by Chen et al. [
24], Yin and Ibrahim [
25], Rodrigues et al. [
26], Gallardo et al. [
27], and Azimi et al. [
28], have extensively explored this topic.
There are numerous extensions, generalizations, and modifications to the Weibull distribution. These developments have emerged to address the requirements of empirical datasets that exhibit characteristics beyond what can be effectively captured by a standard two-parameter Weibull model (Lai and Xie [
17]). These extended models can be broadly classified into three groups: univariate, multivariate, and stochastic process models. Univariate models focus on enhancing the flexibility of the Weibull distribution for single variable analysis. Multivariate models extend the Weibull framework to handle multiple variables and their dependencies. Stochastic process models delve into time-dependent and dynamic variations of the Weibull distribution. Noteworthy references, such as Murthy et al. [
29,
30], provide insights into these diverse extensions and shed light on the advancements made in modeling techniques beyond the traditional Weibull framework. Silva et al. [
31] derived the power-series extended Weibull class of distributions. Santos-Neto et al. [
32] and Nascimento et al. [
33] introduced a family of distributions encompassing well over forty variants. For more details about the generalizations and modifications of the Weibull distribution, see Murthy [
30], Nadarajah and Kotz [
34], Pham and Lai [
35], and Almalki and Nadarajah [
36], as well as the references therein. The analysis of the truncated Weibull distribution has been explored in many papers. For example, Wingo [
37] proposed the left-truncated Weibull distribution. The right-truncated Weibull distribution has been analyzed by Zhang and Xie [
38]. The doubly-truncated Weibull distribution has been studied in work by McEwen and Parresol [
39].
In summary, the Weibull distribution is a versatile probability distribution that finds widespread application in modeling the failure times of objects or systems. The distribution’s characteristics and behaviors are determined by two key parameters: the shape parameter and the scale parameter. The shape parameter governs the shape of the distribution, allowing it to range from exponential to highly skewed distributions. On the other hand, the scale parameter influences the location and spread of the distribution. By manipulating these parameters, the Weibull distribution can effectively capture various failure patterns observed in real-world scenarios. Its flexibility and wide range of applications make it a valuable tool in reliability analysis and survival modeling.
The main objectives of this manuscript are as follows:
- 1.
We perform a review of the different parameterizations of the Weibull distribution documented in the literature, including the interpretation of the regression coefficients, when incorporating regression structures into these parameterizations.
- 2.
We introduce a novel parameterization of the Weibull model based on the mode of this distribution.
- 3.
We theoretically explore the equivalence of the five parameterizations of the Weibull distribution in the context of regression models, since there is no discussion connecting all the mentioned parameterizations.
The manuscript is organized as follows. In
Section 2, five parameterizations of the Weibull distribution are introduced. Three of these parameterizations are mean-based, one is quantile-based, and the last one is mode-based. Each parameterization is characterized by examining the respective hazard and survival functions.
Section 3 delves into the interpretation of regression coefficients when regression structures are incorporated into the parameters of the five Weibull model parameterizations. In
Section 5, we analytically demonstrate that the five parameterizations of the Weibull model discussed in the previous section define the same log-likelihood function.
Section 6 presents Monte Carlo (MC) simulation studies for parameter estimation and residuals. In
Section 6, the analyzed models are applied to real data. Specifically, two illustrations are provided to exemplify their applicability and use in material fatigue life and survival data. should be noted that all models have been implemented using the R-project code (
https://www.r-project.org/, accessed on 5 December 2023). Finally,
Section 7 summarizes the main conclusions of the manuscript and discusses possible avenues for future work.
2. Weibull Parameterizations
As discussed in
Section 1, the Weibull distribution is one of the most used models in reliability analysis because it is a parsimonious model with a simple expression for the density, survival, and hazard functions, and with some interesting properties. For instance, it can assume a decreasing, increasing, or constant hazard rate, depending only on the shape parameter
(<1, >1, or =1, respectively). However, the Weibull distribution has many parameterizations in the literature, depending on the study.
The accelerated failure time (AFT) model, which is employed as the base parameterization, is used for the Weibull model; it has hazard and survival functions given by
and
respectively, with
and
parameters of scale and shape, respectively. This parameterization is referred to as WEI
. An alternative parameterization of the Weibull model is associated with the proportional hazards model, in which the hazard and survival functions are given by
and
respectively. This parameterization is referred to as WEI2
, where
and
act as the scale and shape parameters, respectively. A third alternative parameterization of the Weibull model is related to its mean. Fernandes et al. [
40] propose a reparameterization that expresses the Weibull distribution in terms of the process mean, enabling straightforward monitoring of the Weibull mean. In this parameterization, the hazard and survival functions are given by
where
and
respectively. This parameterization is referred to as WEI3
. In this case,
.
Recently, a fourth parameterization for the Weibull distribution was introduced by Sánchez et al. [
41]. In this parameterization, the hazard and survival functions are given by
where
and
respectively. This parameterization is referred to as WEI4
. In this case,
represents the
q-quantile of the distribution.
Alternatively, a fifth parameterization of the Weibull is proposed, based on its mode. The main motivation for re-parameterizing the model in terms of this measure is associated with the robustness of the mode (above the mean, for example) and the fact that it is a measure that has been used more frequently in the literature in recent years. For instance, see Yao and Li [
42], Chen [
43], and Bourguignon et al. [
44]. In this parameterization, the hazard and survival functions are given by
and
This parameterization is referred to as WEI5
. In this case,
represents the mode of the distribution.
Table 1 presents the mean, mode,
q-quantile, and variance for the five parameterizations of the Weibull distribution explored in this study.
For a set of
p covariates observed for each individual and the intercept term, say
, and for the four parameterizations, it is typical to include a regression structure in
, as follows
where
, and
is a twice differentiable function, such as
. The most common choice is
, which also facilitates the interpretation of the regression coefficients. In each model, such interpretation depends on its specific parameterization (WEI, WEI2, WEI3, WEI4, and WEI5). However, it will be demonstrated that when a regression structure is incorporated solely into
, as in Equation (
1), without affecting the shape parameter
, then all five models share the same probability density function (PDF) and, consequently, the same log-likelihood function. Furthermore, it will also be demonstrated that introducing a dual regression structure for both
and
in the WEI, WEI2, WEI3, and WEI4 models results in different PDFs among the models.
3. Interpretation of the Coefficients
In this section, we explore the varying interpretations of regression coefficients in the Weibull model across different parameterizations. Let us consider two individuals with associated covariates, and , which is that and are identical, except for an increase of one unit in the j-th covariate. The scenario where the j-th covariate is quantitative will be focused on. However, in all cases, a similar interpretation can be applied to , assuming two categories (labeled as 0 and 1). Note that .
3.1. WEI Model
For the AFT parameterization, we obtain
where
. In this context,
is known as the accelerator factor. More precisely, as mentioned by Kleinbaum and Klein [
45], “the accelerator factor is a ratio of survival times corresponding to any fixed value of
”. In this case, to facilitate the interpretation of the coefficients, it is set
. Consequently, the interpretations of covariates are as follows: If
, then the median survival time doubles when the
j-th covariate is increased by one unit, compared to the median survival time when the
j-th covariate remains unchanged.
Remark 1. For WEI2, WEI3, and WEI4 parameterizations, the traditional link function is .
3.2. WEI2 Model
In this case, the quotient between the hazard function related to
and
is
This does not depend on
t (hence, the name ‘proportional hazard models’). Therefore,
should be interpreted as the increase (or decrease) in the hazard function when the
j-th covariate increases by one unit.
3.3. WEI3 Model
In this case, the expected value of the distribution is
. Therefore, the quotient between the mean related to
and
is
Therefore,
should be interpreted as the percentage increase (or decrease) in the mean when the
j-th covariate is increased by one unit.
3.4. WEI4 Model
In this case, the
-th quantile of the distribution is
. Therefore, the quotient between the
-th quantile related to
and
is given by
Then,
represents the percentage increase (or decrease) in the
-th quantile when the
j-th covariate is increased by one unit.
3.5. WEI5 Model
For this model, the mode of the distribution is Mo
. Therefore, the model related to
and
is
In this case,
represents the percentage increase (or decrease) in the mode when the
j-th covariate is increased by one unit.
3.6. The Bi-Univocity among the Four Parameterizations When Modeling Only
To date, there is no discussion in the literature about the connection between the different parameterizations of the Weibull distribution when incorporating regression structures into these parameterizations. The following theorem establishes the biunivocal relationship between the WEI, WEI2, WEI3, WEI4, and WEI5 models when modeling only .
Theorem 1. Let be independent random variables, such as , where , and a constant shape parameter ν. Consider alternative parameterizations for the Weibull model, such as or , with and a non-modeled τ. If intercept terms are considered in , then the elements of can be obtained uniquely from .
Proof. Equating the hazard functions for the WEI2, WEI3, WEI4, and WEI5 models with those associated with the WEI model, we obtain and , where , for the WEI2 model, , for the WEI3 model, , for the WEI4 model and , for the WEI5 model. Considering the partitions , and , i.e., and are related to the non-intercept terms of and , respectively. With this, the equation assumes the following forms for each case:
In this case, we conclude that and .
Here, it can be concluded that and .
WEI4 model:
where we conclude that
and
.
In this case, we conclude that and .
Note that in all cases, can be obtained uniquely from . □
Remark 2. Theorem 1 implies that when only λ is modeled in the WEI, WEI2, WEI3, WEI4, and WEI5 models, all the distributions produce the same PDF. Consequently, model selection criteria, such as the Akaike Information criterion (AIC) and Bayesian information criterion (BIC), yield identical values.
Remark 3. When an additional set of covariates, denoted as (not necessarily identical to ), is considered to model the shape parameter as , where , the five parameterizations of the Weibull model define different PDFs. This distinction arises because the relationship incorporates only the covariates on the left side of the equation, while both sets of covariates are involved on the right side.
7. Conclusions and Future Work
In this paper, a general parameterization for Weibull regression models was introduced, based on central tendency measures and shape parameters. A comprehensive review of Weibull regression models was provided, specifically focusing on different parameterizations of the Weibull distribution that utilize central tendency measures. The interpretation of regression coefficients when incorporating regression structures into these parameterizations was also explored. Furthermore, closed-form expressions for the expected Fisher information matrix have been derived for this general parameterization of Weibull regression models. Two types of residuals were explored, and maximum likelihood inference was implemented for estimating model parameters. The performance of this inference method was assessed through Monte Carlo simulations.
A significant result, as established in Theorem 1, is that when modeling only in the WEI, WEI2, WEI3, WEI4, and WEI5 models, the same probability density function is yielded by all these parameterizations. Therefore, in these cases, it does not matter which model is used, as the conclusions for any measure of interest must be the same for any of the five models.
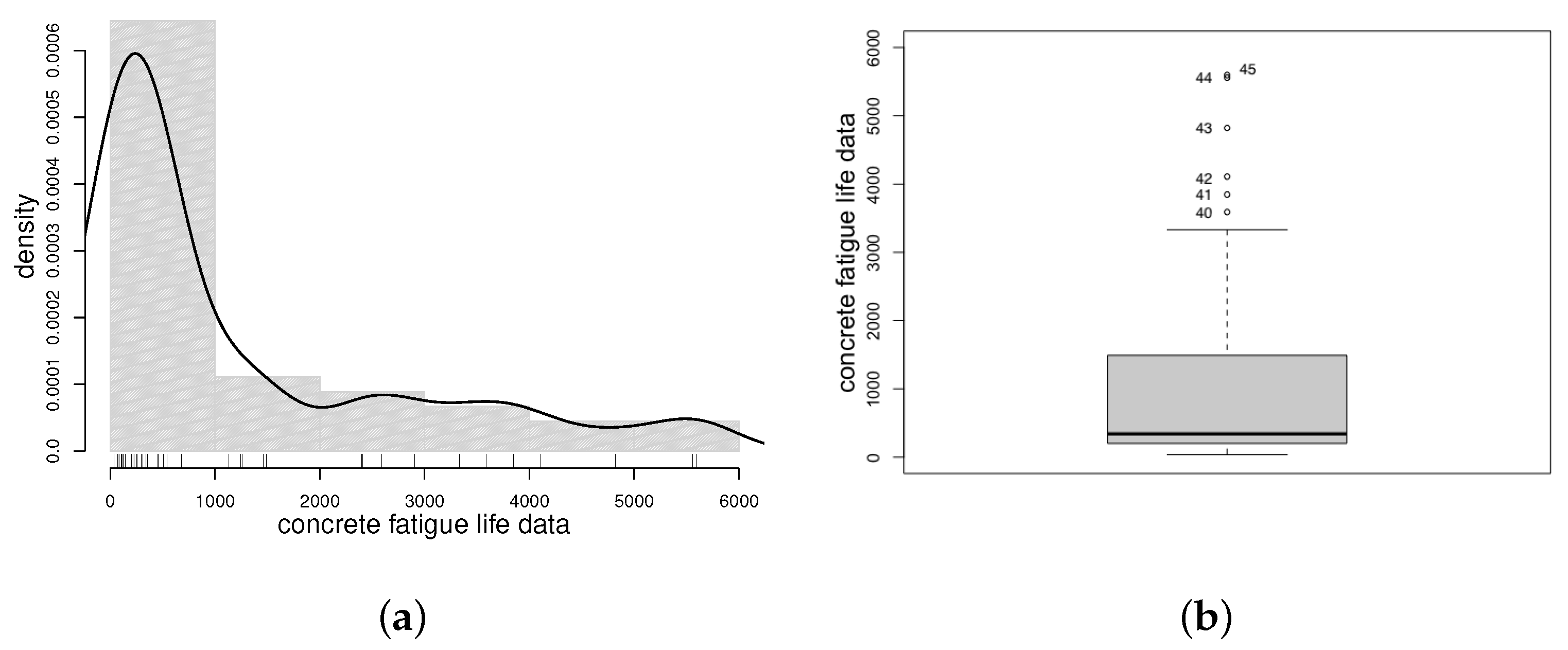
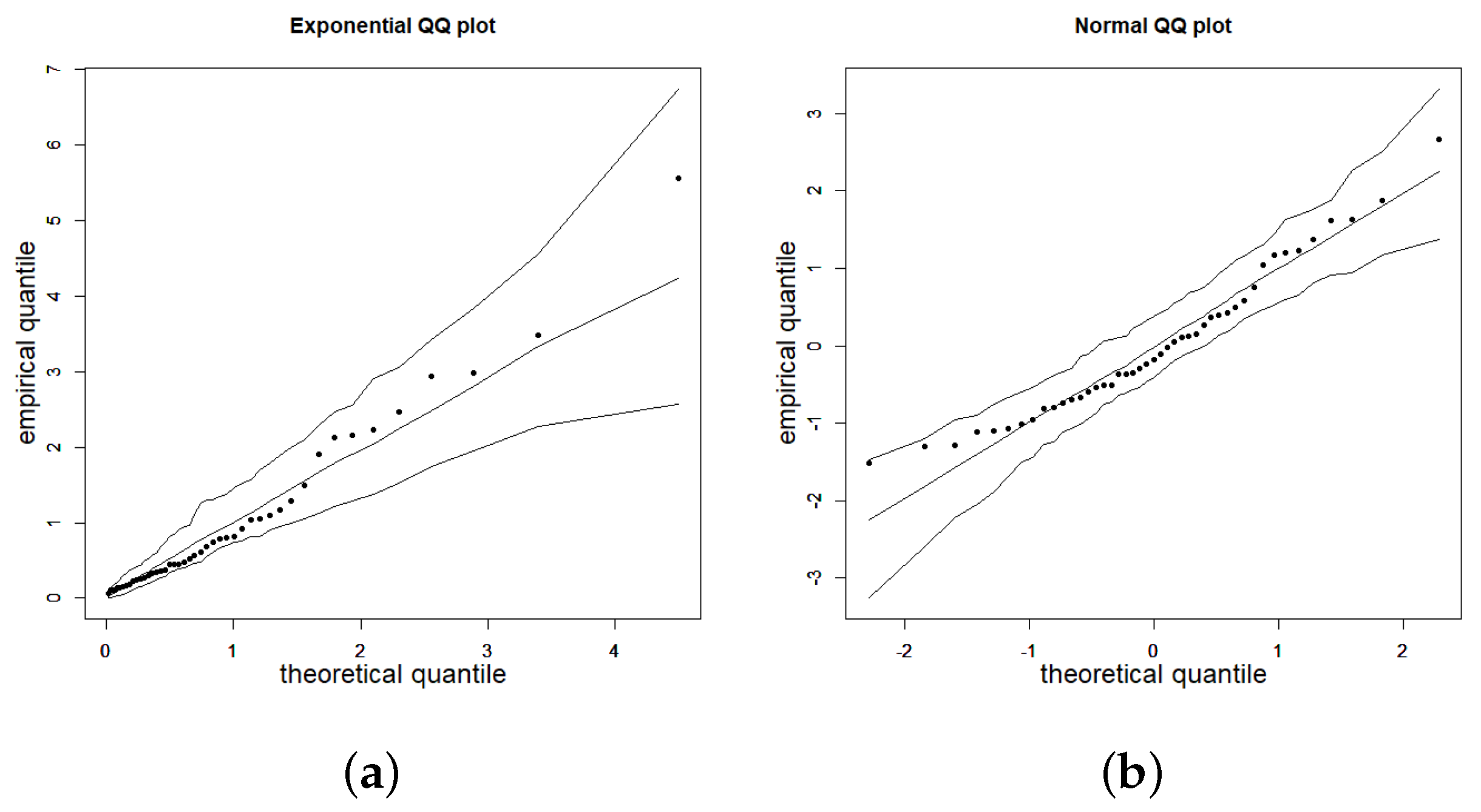
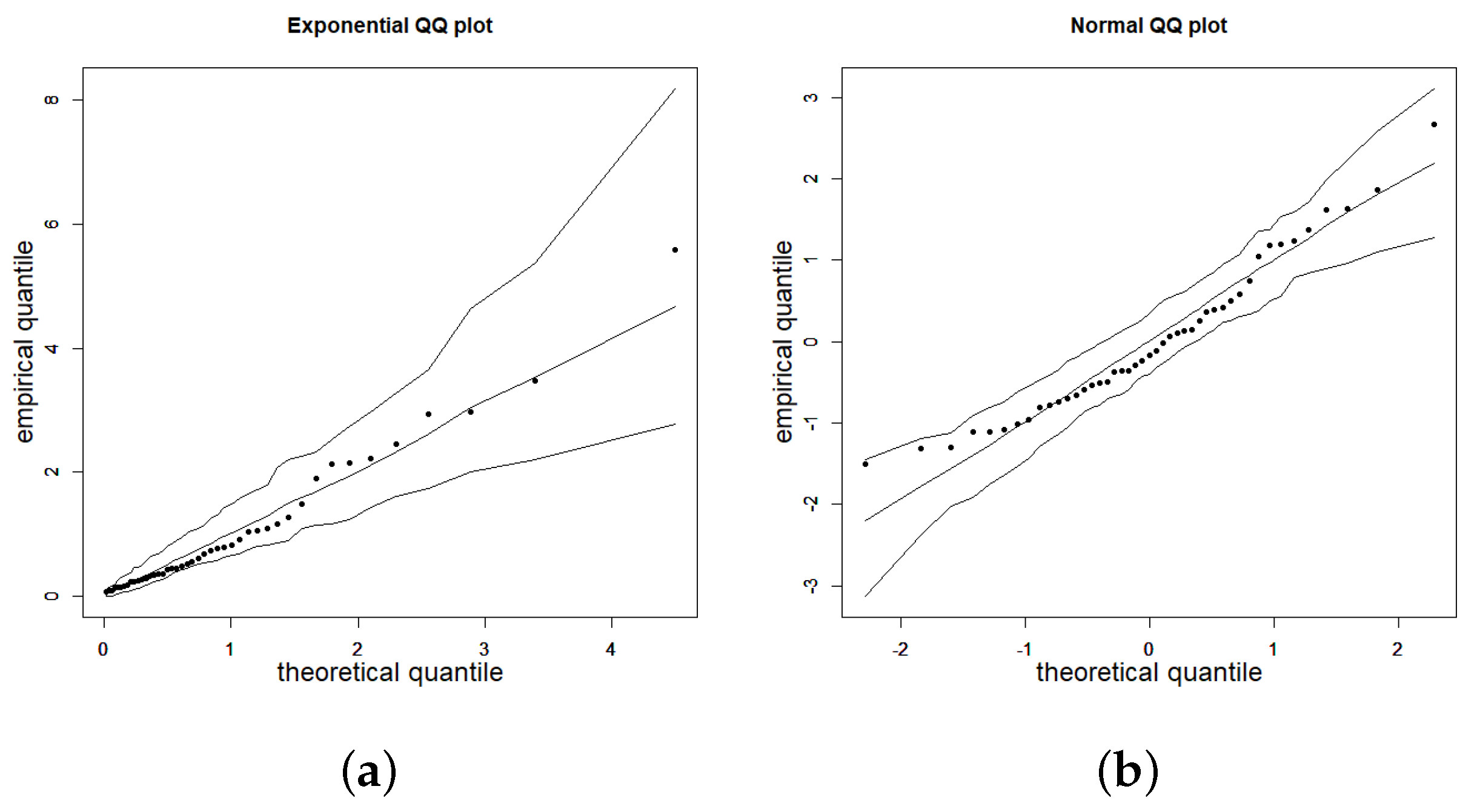
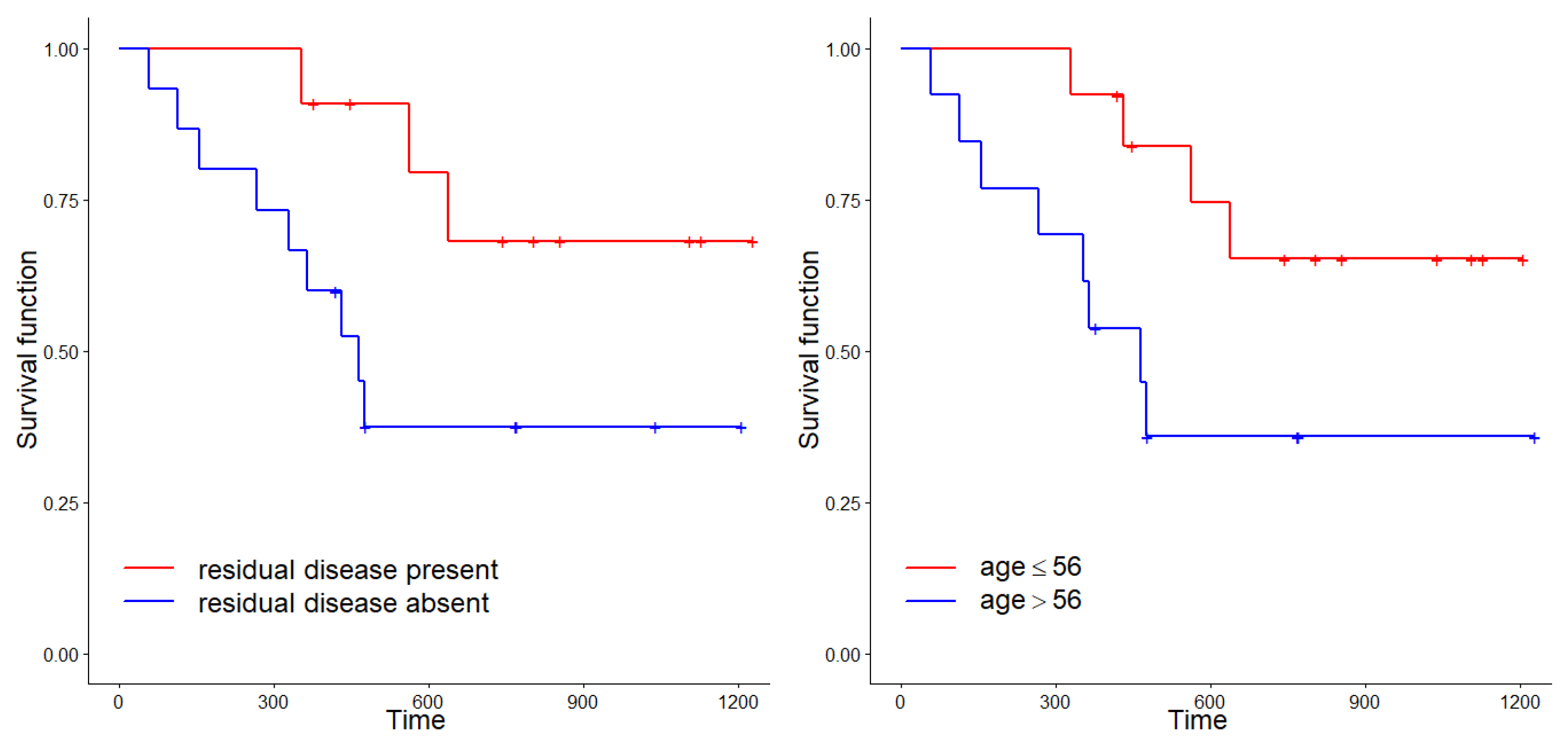
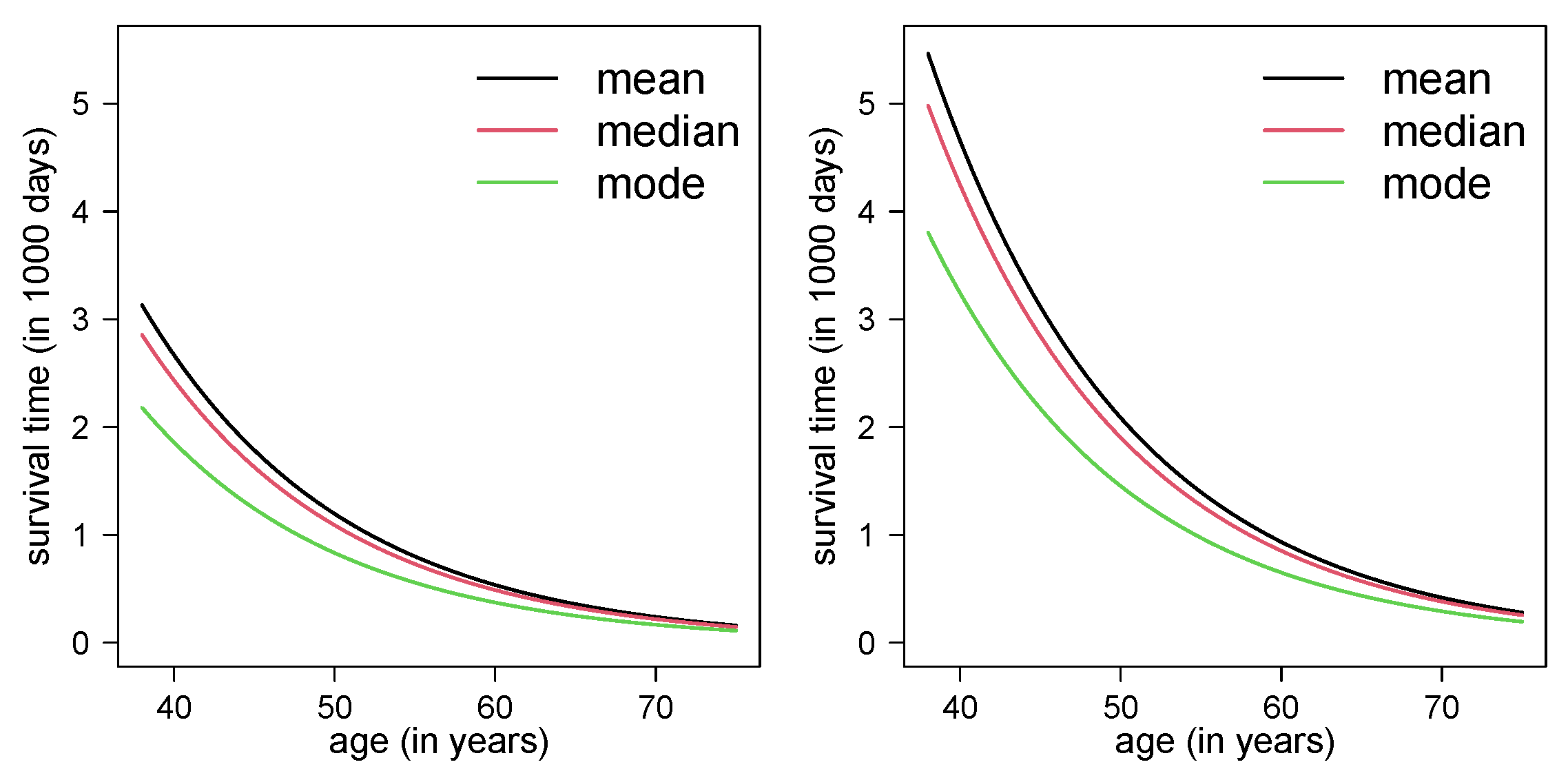
To illustrate the practical relevance of the approach, two real-world applications using authentic datasets were presented. These applications underscored the adequacy of the introduced Weibull models when data present an asymmetric distribution. Depending on which parameter is of interest in the study, one model will be more convenient to use than the other.
As part of future research, the plan is to develop an R package that facilitates inference in WEI4 and WEI5 regression models.


 ,
, 










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}