
Enhancing Surveillance Vision with Multi-Layer Deep Learning Representation


Abstract
:1. Introduction
- ₋
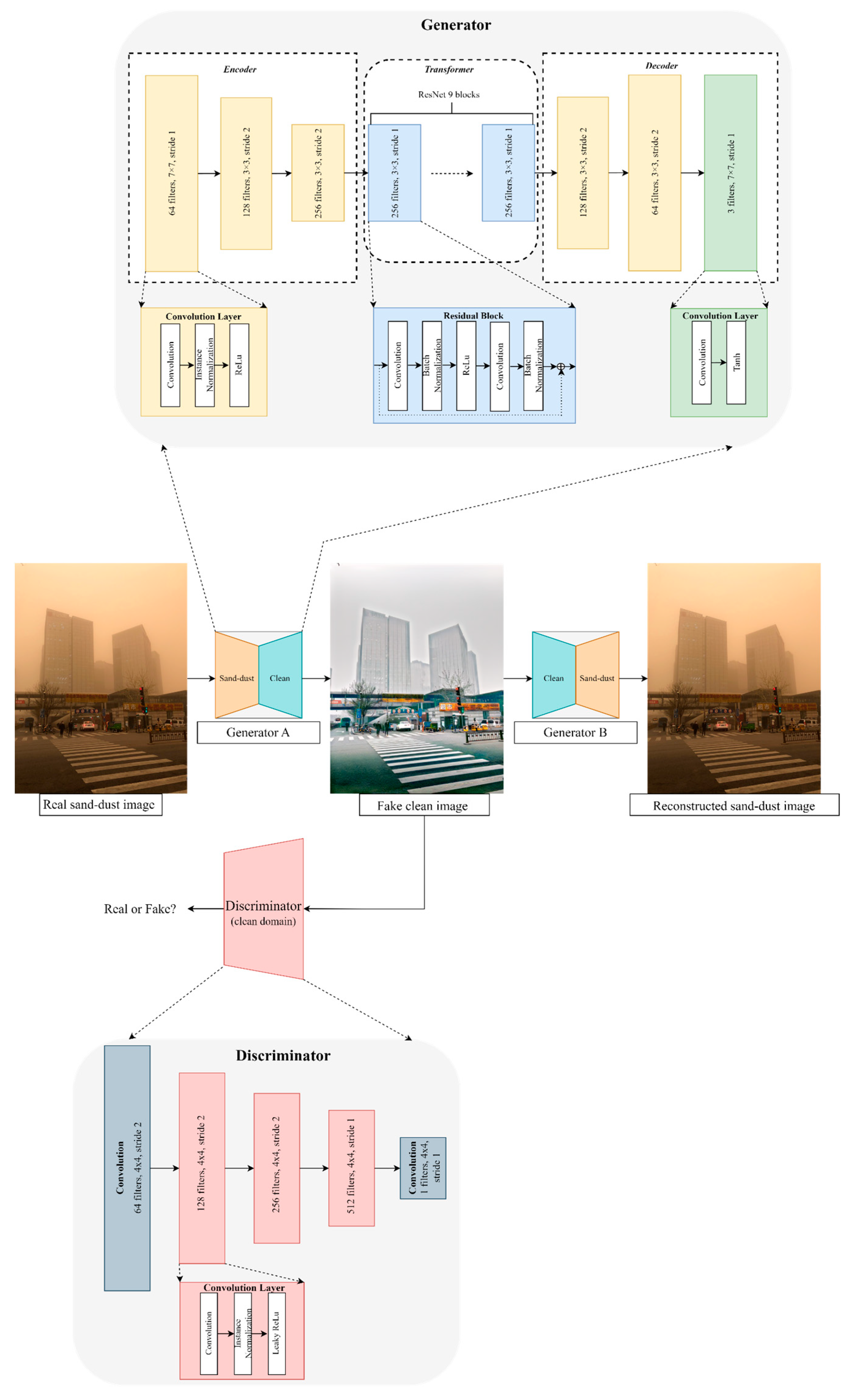
- The proposed method addressed the inadequacy of unpaired dataset learning in CycleGAN by training on paired datasets of sand–dust and clean images.
- ₋
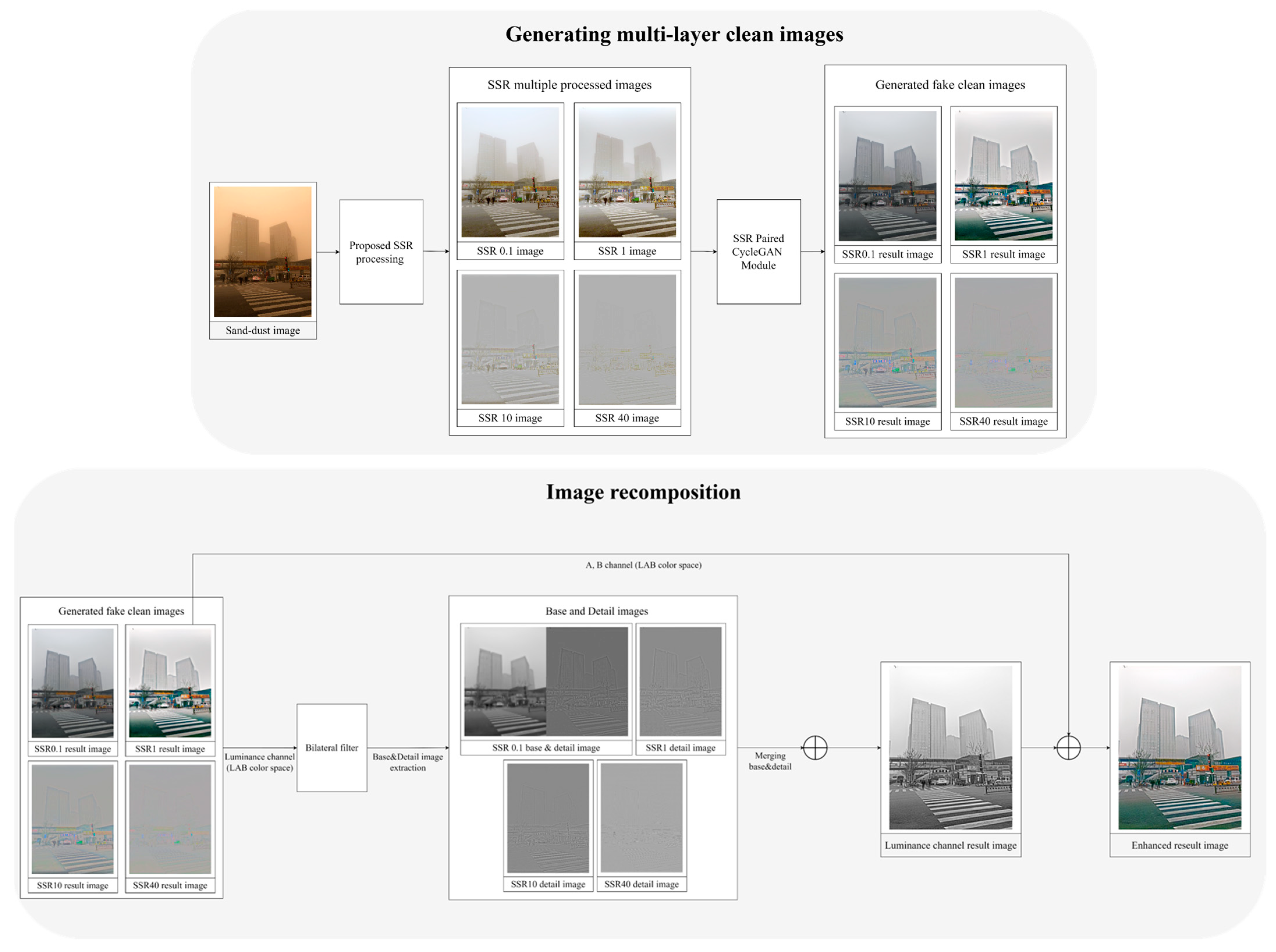
- To enhance the representation of object details during image transformation, the SSR algorithm was adopted. Four-scale hierarchical SSR processing was applied to construct each pair dataset.
- ₋
- The results from each module were separated into base and detail components. The smaller sigma-scale module captured overall image information, while the remaining three modules with larger sigma scales acquired image detail information. The base and detail components were then combined. Color information from the sigma 1 scale was utilized to generate the final clean image transformation.
2. Materials and Methods
2.1. Single-Scale Retinex Processing for Preparing Train Dataset
2.2. Paired Dataset Training Using CycleGAN
2.3. Proposed Method
3. Simulation Results
3.1. Dataset and Computer Specification
3.2. Simulation Results Comparison
4. Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Kwon, H.J.; Lee, S.H. Raindrop-Removal Image Translation Using Target-Mask Network with Attention Module. Mathematics 2023, 11, 3318. [Google Scholar] [CrossRef]
- Liu, J.; Liu, R.W.; Sun, J.; Zeng, T. Rank-One Prior: Toward Real-Time Scene Recovery. arXiv 2021, arXiv:2103.17126. [Google Scholar]
- Liu, J.; Liu, R.W.; Sun, J.; Zeng, T. Rank-One Prior: Real-Time Scene Recovery. IEEE Trans. Pattern Anal. Mach. Intell. 2023, 45, 8845–8860. [Google Scholar] [CrossRef] [PubMed]
- Shi, Z.; Feng, Y.; Zhao, M.; Zhang, E.; He, L. Normalised Gamma Transformation-Based Contrast-Limited Adaptive Histogram Equalisation with Colour Correction for Sand-Dust Image Enhancement. IET Image Process. 2020, 14, 747–756. [Google Scholar] [CrossRef]
- Jeon, J.J.; Park, T.H.; Eom, I.K. Sand-Dust Image Enhancement Using Chromatic Variance Consistency and Gamma Correction-Based Dehazing. Sensors 2022, 22, 9048. [Google Scholar] [CrossRef] [PubMed]
- Cai, B.; Xu, X.; Jia, K.; Qing, C.; Tao, D. DehazeNet: An End-to-End System for Single Image Haze Removal. IEEE Trans. Image Process. 2016, 25, 5187–5198. [Google Scholar] [CrossRef]
- Liu, X.; Ma, Y.; Shi, Z.; Chen, J. GridDehazeNet: Attention-Based Multi-Scale Network for Image Dehazing. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; Institute of Electrical and Electronics Engineers Inc.: New York, NY, USA, 2019; pp. 7313–7322. [Google Scholar]
- Dong, H.; Pan, J.; Xiang, L.; Hu, Z.; Zhang, X.; Wang, F.; Yang, M.H. Multi-Scale Boosted Dehazing Network with Dense Feature Fusion. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; IEEE Computer Society: New York, NY, USA, 2020; pp. 2154–2164. [Google Scholar]
- Zhu, Q.; Mai, J.; Shao, L. A Fast Single Image Haze Removal Algorithm Using Color Attenuation Prior. IEEE Trans. Image Process. 2015, 24, 3522–3533. [Google Scholar] [CrossRef] [PubMed]
- He, K.; Sun, J.; Tang, X. Single Image Haze Removal Using Dark Channel Prior. IEEE Trans. Pattern Anal. Mach. Intell. 2011, 33, 2341–2353. [Google Scholar] [CrossRef] [PubMed]
- Qin, X.; Wang, Z.; Bai, Y.; Xie, X.; Jia, H. FFA-Net: Feature Fusion Attention Network for Single Image Dehazing. Proc. AAAI Conf. Artif. Intell. 2020, 34, 11908–11915. [Google Scholar] [CrossRef]
- Petro, A.B.; Sbert, C.; Morel, J.-M. Multiscale Retinex. Image Process. OnLine 2014, 4, 71–88. [Google Scholar] [CrossRef]
- Isola, P.; Zhu, J.-Y.; Zhou, T.; Efros, A.A. Image-to-Image Translation with Conditional Adversarial Networks. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Zhu, J.-Y.; Park, T.; Isola, P.; Efros, A.A. Unpaired Image-to-Image Translation Using Cycle-Consistent Adversarial Networks. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017. [Google Scholar]
- Mao, X.; Li, Q.; Xie, H.; Lau, R.Y.K.; Wang, Z.; Smolley, S.P. Least Squares Generative Adversarial Networks. arXiv 2016, arXiv:1611.04076. [Google Scholar]
- Si, Y.; Yang, F.; Liu, Z. Sand Dust Image Visibility Enhancement Algorithm via Fusion Strategy. Sci. Rep. 2022, 12, 13226. [Google Scholar] [CrossRef] [PubMed]
- Ancuti, C.O.; Ancuti, C.; Timofte, R.; De Vleeschouwer, C. O-HAZE: A Dehazing Benchmark with Real Hazy and Haze-Free Outdoor Images. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Salt Lake City, UT, USA, 18–22 June 2018. [Google Scholar]
- Li, B.; Ren, W.; Fu, D.; Tao, D.; Feng, D.; Zeng, W.; Wang, Z. Benchmarking Single Image Dehazing and Beyond. arXiv 2017, arXiv:1712.04143. [Google Scholar] [CrossRef]
- Mittal, A.; Moorthy, A.K.; Bovik, A.C. Blind/Referenceless Image Spatial Quality Evaluator. In Proceedings of the 2011 Conference Record of the Forty Fifth Asilomar Conference on Signals, Systems and Computers (ASILOMAR), Pacific Grove, CA, USA, 6–9 November 2011; IEEE: New York, NY, USA, 2011; pp. 723–727. [Google Scholar]
- Venkatanath, N.; Praneeth, D.; Maruthi Chandrasekhar, B.; Channappayya, S.S.; Medasani, S.S. Blind Image Quality Evaluation Using Perception Based Features. In Proceedings of the 2015 Twenty First National Conference on Communications (NCC), Mumbai, India, 27 February–1 March 2015; IEEE: New York, NY, USA, 2015; pp. 1–6. [Google Scholar]
- Yan, J.; Li, J.; Fu, X. No-Reference Quality Assessment of Contrast-Distorted Images Using Contrast Enhancement. arXiv 2019, arXiv:1904.08879. [Google Scholar]
- Abdoli, M.; Nasiri, F.; Brault, P.; Ghanbari, M. Quality Assessment Tool for Performance Measurement of Image Contrast Enhancement Methods. IET Image Process. 2019, 13, 833–842. [Google Scholar] [CrossRef]
- Hassen, R.; Wang, Z.; Salama, M. No-Reference Image Sharpness Assessment Based on Local Phase Coherence Measurement. In Proceedings of the 2010 IEEE International Conference on Acoustics, Speech and Signal Processing, Dallas, TX, USA, 14–19 March 2010; IEEE: New York, NY, USA, 2010; pp. 2434–2437. [Google Scholar]
- Hassen, R.; Wang, Z.; Salama, M.M.A. Image Sharpness Assessment Based on Local Phase Coherence. IEEE Trans. Image Process. 2013, 22, 2798–2810. [Google Scholar] [CrossRef]
- Vu, C.T.; Phan, T.D.; Chandler, D.M. S-3: A Spectral and Spatial Measure of Local Perceived Sharpness in Natural Images. IEEE Trans. Image Process. 2012, 21, 934–945. [Google Scholar] [CrossRef] [PubMed]






















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| BRISQUE ↓ | PIQE ↓ | CEIQ ↑ | MCMA ↑ | LPC-SI ↑ | S3 ↑ | |
|---|---|---|---|---|---|---|
| TargetMask | 22.283 | 28.708 | 3.245 | 0.628 | 0.948 | 0.172 |
| DehazeNet | 31.109 | 39.040 | 3.208 | 0.577 | 0.935 | 0.107 |
| ROP | 26.911 | 41.271 | 3.436 | 0.672 | 0.959 | 0.237 |
| CLIE | 22.268 | 43.481 | 3.221 | 0.601 | 0.942 | 0.184 |
| Chromatic-gamma | 29.266 | 40.831 | 3.575 | 0.647 | 0.959 | 0.154 |
| MSR | 35.102 | 36.523 | 2.06 | 0.319 | 0.897 | 0.056 |
| CycleGAN | 22.195 | 28.205 | 3.427 | 0.65 | 0.948 | 0.162 |
| Proposed method | 21.52 | 31.783 | 3.468 | 0.724 | 0.968 | 0.217 |
| BRISQUE ↓ | PIQE ↓ | CEIQ ↑ | MCMA ↑ | LPC-SI ↑ | S3 ↑ | |
|---|---|---|---|---|---|---|
| Grid-dehazeNet | 19.109 | 26.959 | 3.3801 | 0.728 | 0.949 | 0.187 |
| MSBDN-DFF | 19.248 | 30.845 | 3.3804 | 0.696 | 0.942 | 0.147 |
| DehazeNet | 21.11 | 34.477 | 3.3732 | 0.663 | 0.939 | 0.141 |
| Color Attenuation Prior | 19.73 | 35.582 | 3.3056 | 0.654 | 0.944 | 0.138 |
| Dark channel prior | 16.654 | 31.774 | 3.2168 | 0.653 | 0.942 | 0.163 |
| FFA-Net | 19.73 | 35.582 | 3.306 | 0.654 | 0.944 | 0.138 |
| Proposed method | 22.77 | 33.081 | 3.4587 | 0.717 | 0.967 | 0.243 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Son, D.-M.; Lee, S.-H. Enhancing Surveillance Vision with Multi-Layer Deep Learning Representation. Mathematics 2024, 12, 1313. https://doi.org/10.3390/math12091313
Son D-M, Lee S-H. Enhancing Surveillance Vision with Multi-Layer Deep Learning Representation. Mathematics. 2024; 12(9):1313. https://doi.org/10.3390/math12091313
Chicago/Turabian StyleSon, Dong-Min, and Sung-Hak Lee. 2024. "Enhancing Surveillance Vision with Multi-Layer Deep Learning Representation" Mathematics 12, no. 9: 1313. https://doi.org/10.3390/math12091313
APA StyleSon, D. -M., & Lee, S. -H. (2024). Enhancing Surveillance Vision with Multi-Layer Deep Learning Representation. Mathematics, 12(9), 1313. https://doi.org/10.3390/math12091313