Decomposition of Dynamical Signals into Jumps, Oscillatory Patterns, and Possible Outliers

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
1.1. Motivations
1.2. Previous Works
1.2.1. Piecewise Constant Trend Estimation
1.2.2. Seasonality Estimation
1.2.3. Joint Estimation
1.3. Our Contribution
2. Background on Penalised Filtering, Robust PCA, and Componentwise Optimisation
2.1. The Nonsmooth Approach to Sparsity Promoting Penalised Estimation: Lessons from the LASSO
2.2. Piecewise Constant Signals
2.3. Prony’s Method
2.4. Finding a Low Rank Hankel Approximation
3. Main Results
3.1. Putting It All Together
3.2. A Component-Wise Optimisation Method
| Algorithm 1: ADMM-based jump-seasonality-outlier decomposition |
 |
| Algorithm 2: Componentwise jump-seasonality-outlier decomposition |
 |
3.3. Convergence of the Algorithm
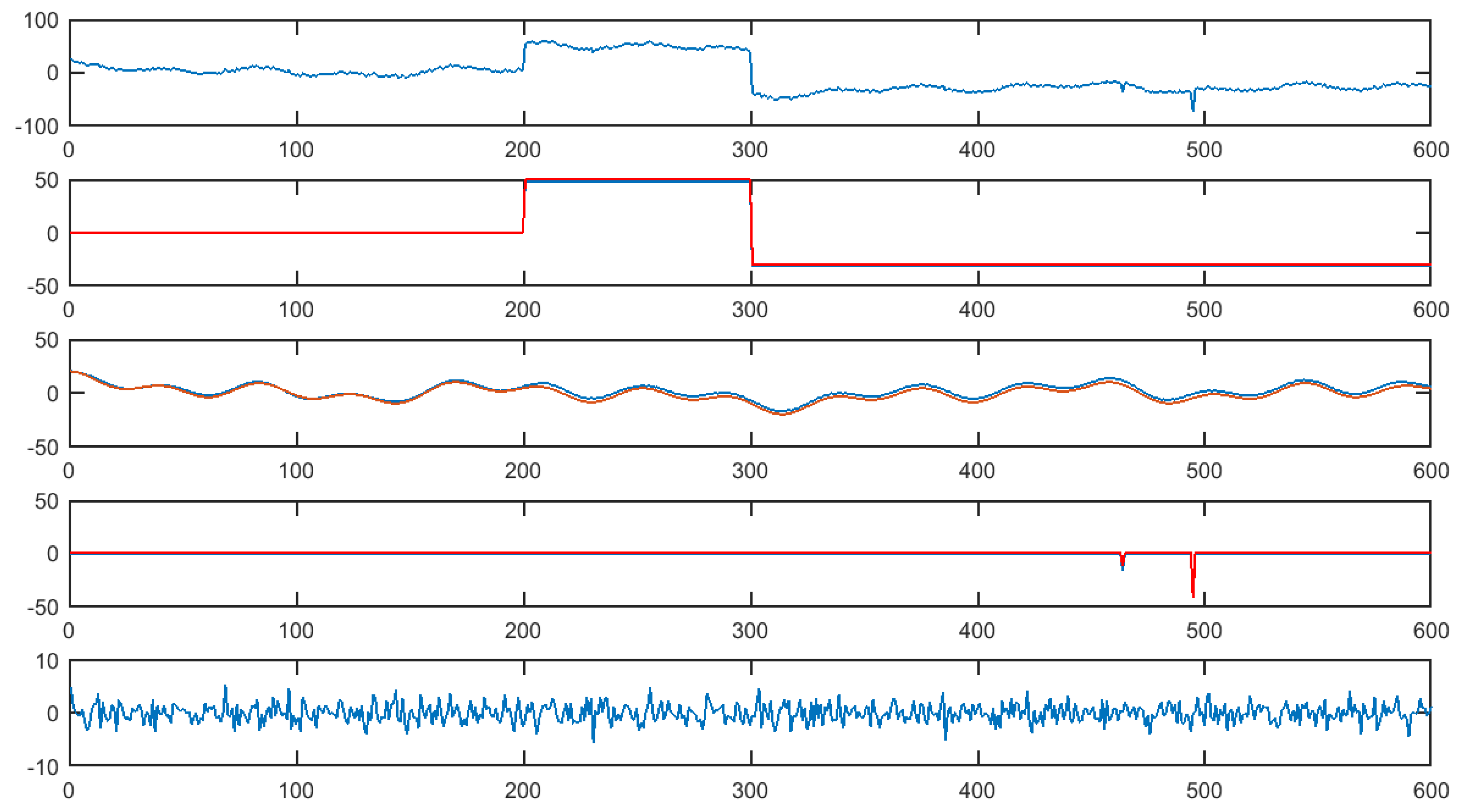
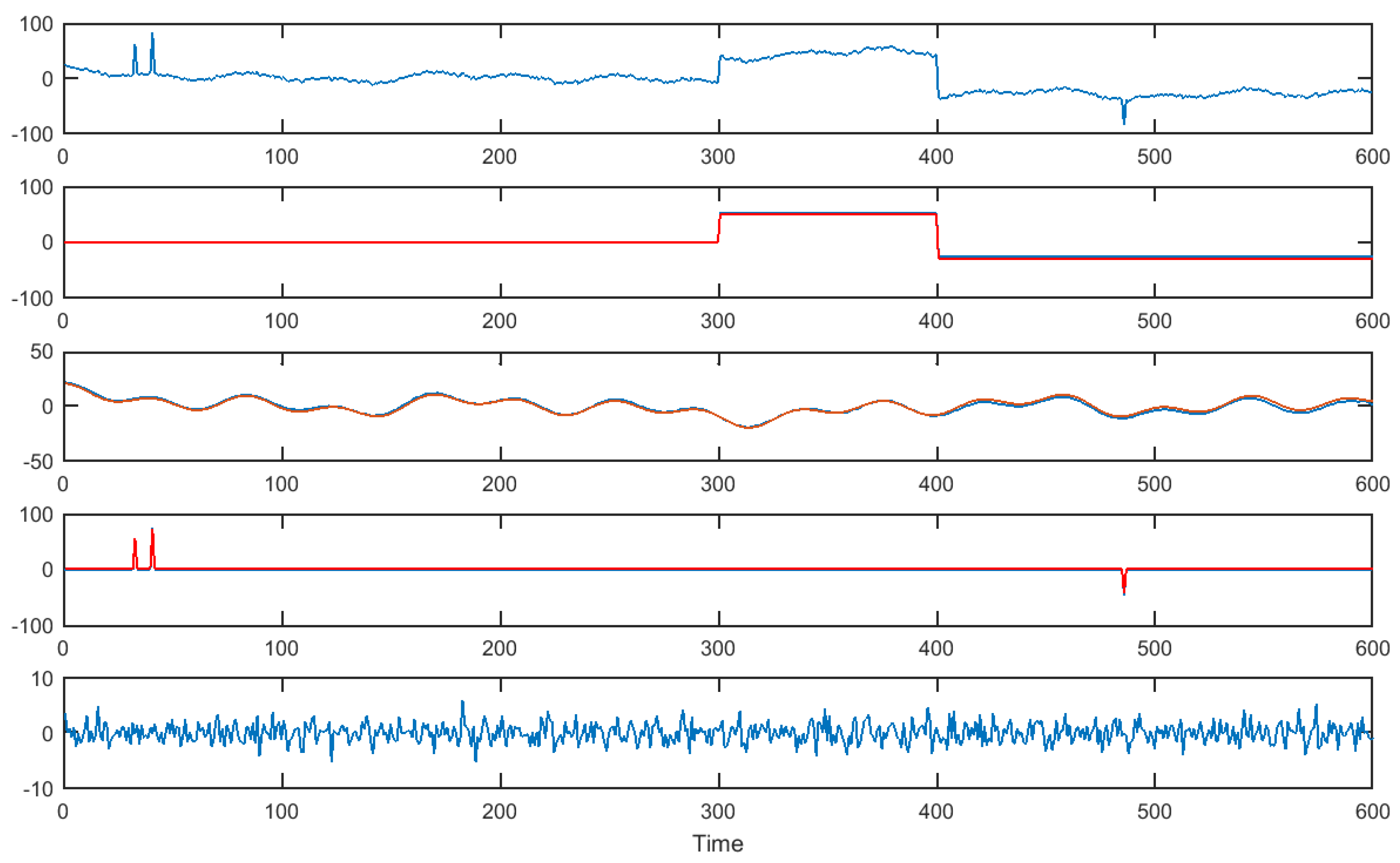
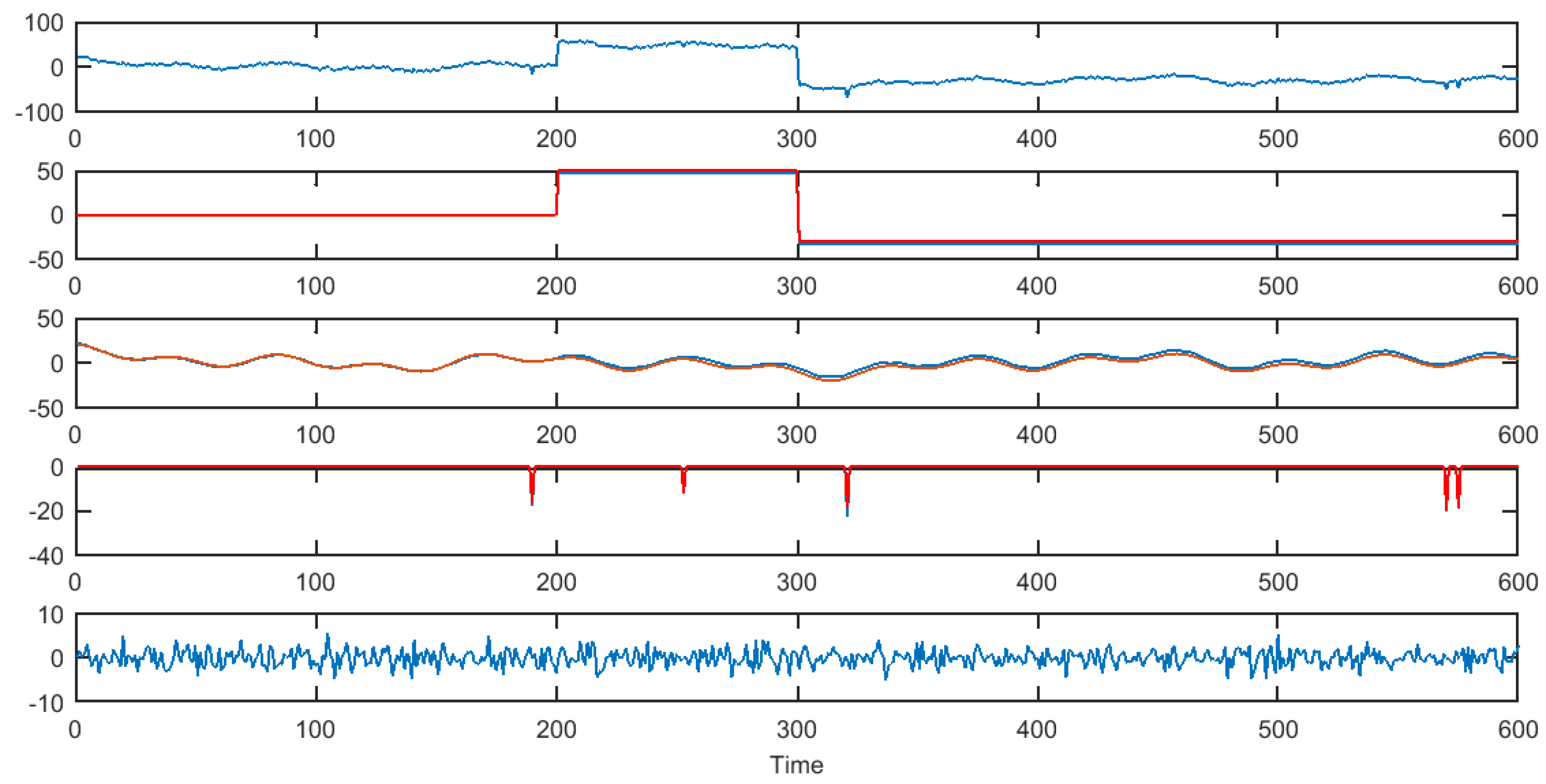
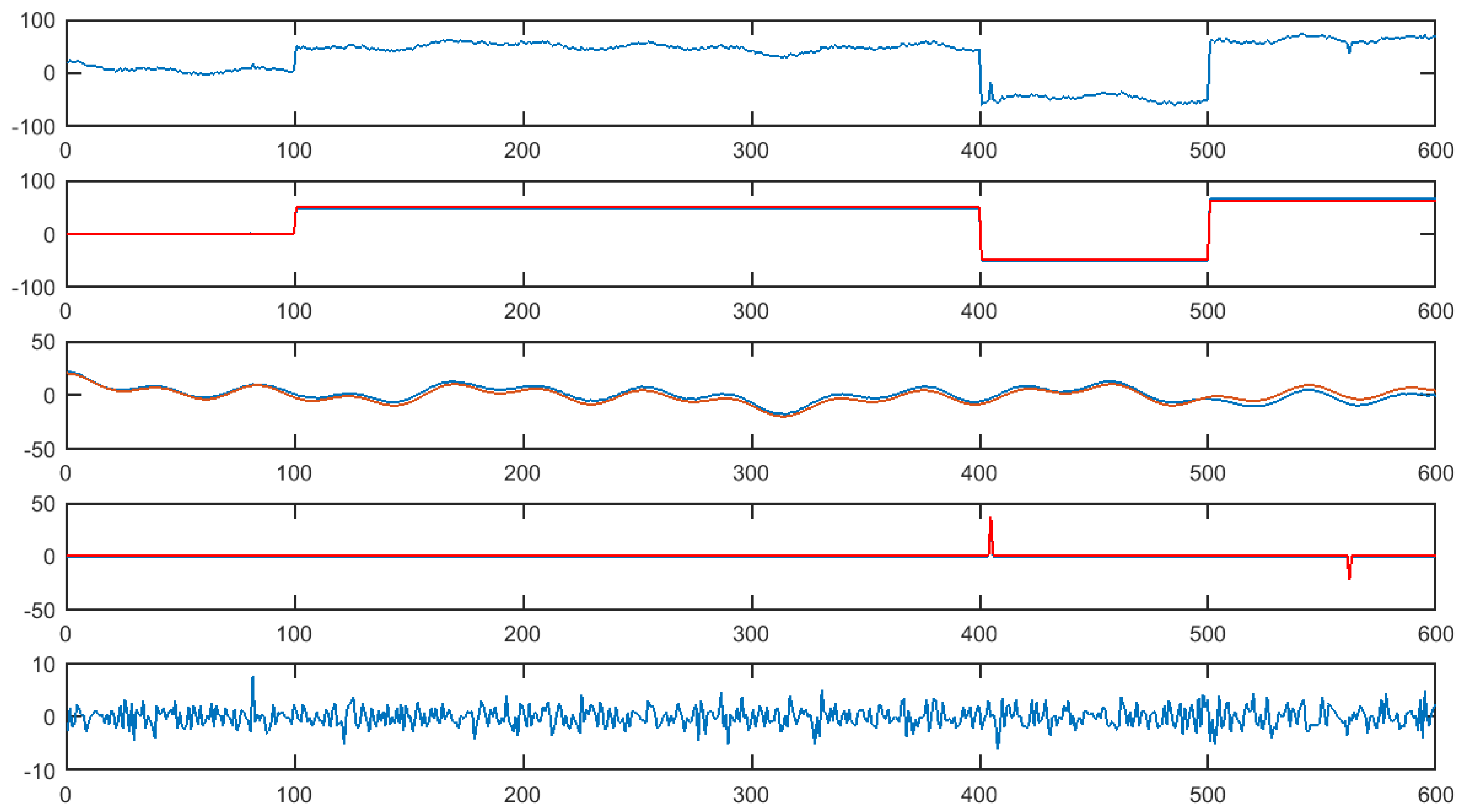
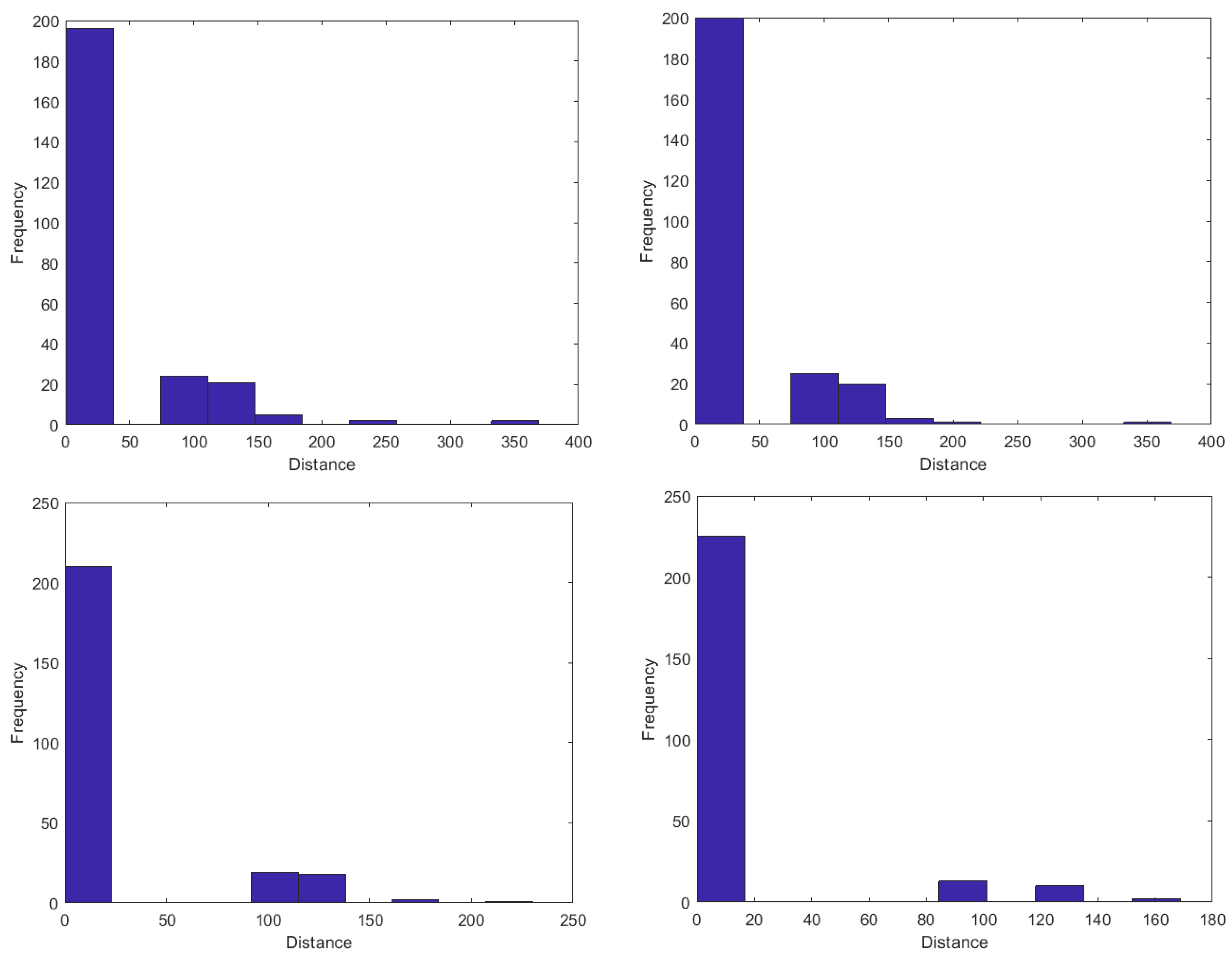
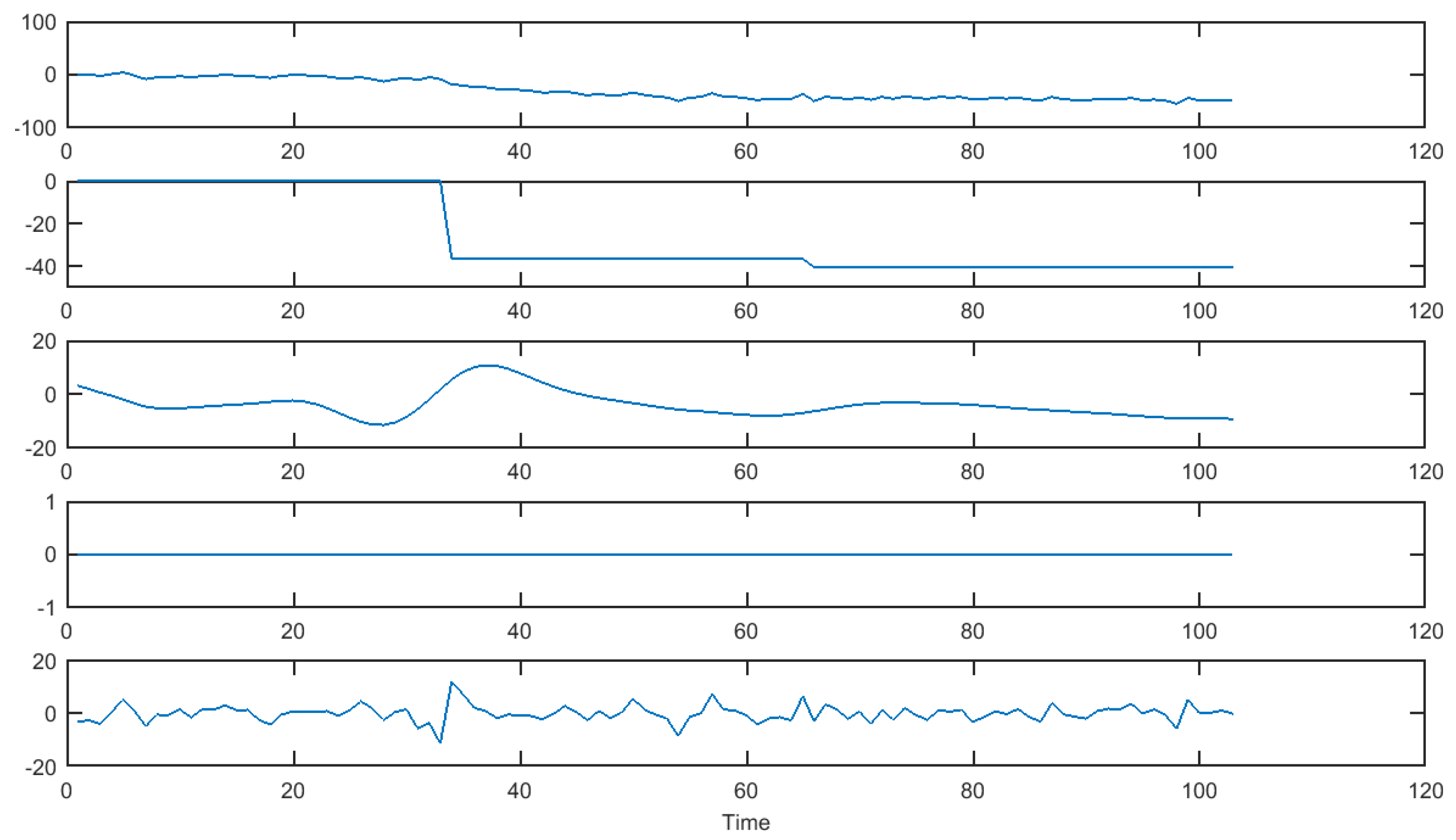
3.4. Numerical Experiments
3.4.1. Simulated Data
3.4.2. Real Data
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Box, G.E.; Jenkins, G.M.; Reinsel, G.C.; Ljung, G.M. Time Series Analysis: Forecasting and Control; John Wiley & Sons: Hoboken, NJ, USA, 2015. [Google Scholar]
- Chatfield, C. The Analysis of Time Series: An Introduction; CRC Press: Boca Raton, FL, USA, 2013. [Google Scholar]
- Shumway, R.H.; Stoffer, D.S. Time Series Analysis and It’s Applications; Springer: Berlin, Germany, 2000. [Google Scholar]
- Bianchi, M.; Boyle, M.; Hollingsworth, D. A comparison of methods for trend estimation. Appl. Econ. Lett. 1999, 6, 103–109. [Google Scholar] [CrossRef]
- Young, P.C. Time-variable parameter and trend estimation in non-stationary economic time series. J. Forecast. 1994, 13, 179–210. [Google Scholar] [CrossRef]
- Greenland, S.; Longnecker, M.P. Methods for trend estimation from summarized dose-response data, with applications to meta-analysis. Am. J. Epidemiol. 1992, 135, 1301–1309. [Google Scholar] [CrossRef] [PubMed]
- Visser, H.; Molenaar, J. Trend estimation and regression analysis in climatological time series: An application of structural time series models and the Kalman filter. J. Clim. 1995, 8, 969–979. [Google Scholar] [CrossRef]
- Isermann, R.; Balle, P. Trends in the application of model-based fault detection and diagnosis of technical processes. Control Eng. Pract. 1997, 5, 709–719. [Google Scholar] [CrossRef]
- Hogarth, R.M.; Makridakis, S. Forecasting and planning: An evaluation. Manag. Sci. 1981, 27, 115–138. [Google Scholar] [CrossRef]
- Faraway, J.; Chatfield, C. Time series forecasting with neural networks: A comparative study using the airline data. Appl. Stat. 1998, 47, 231–250. [Google Scholar] [CrossRef]
- Kim, S.J.; Koh, K.; Boyd, S.; Gorinevsky, D. ℓ1 Trend Filtering. SIAM Rev. 2009, 51, 339–360. [Google Scholar] [CrossRef]
- Candès, E.J.; Li, X.; Ma, Y.; Wright, J. Robust principal component analysis? J. ACM (JACM) 2011, 58, 11. [Google Scholar] [CrossRef]
- Mattingley, J.; Boyd, S. Real-time convex optimization in signal processing. Signal Process. Mag. IEEE 2010, 27, 50–61. [Google Scholar] [CrossRef]
- Alexandrov, T.; Bianconcini, S.; Dagum, E.B.; Maass, P.; McElroy, T.S. A review of some modern approaches to the problem of trend extraction. Econ. Rev. 2012, 31, 593–624. [Google Scholar] [CrossRef]
- Brockwell, P.J.; Davis, R.A. Time Series: Theory and Methods; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2013. [Google Scholar]
- Cleveland, R.B.; Cleveland, W.S.; McRae, J.E.; Terpenning, I. STL: A seasonal-trend decomposition procedure based on loess. J. Off. Stat. 1990, 6, 3–73. [Google Scholar]
- Harvey, A.; Trimbur, T. Trend estimation and the Hodrick-Prescott filter. J. Jpn. Stat. Soc. 2008, 38, 41–49. [Google Scholar] [CrossRef]
- Percival, D.B.; Walden, A.T. Wavelet Methods for Time Series Analysis; Cambridge University Press: Cambridge, UK, 2006; Volume 4. [Google Scholar]
- Tibshirani, R.J. Adaptive piecewise polynomial estimation via trend filtering. Ann. Stat. 2014, 42, 285–323. [Google Scholar] [CrossRef]
- Neto, D.; Sardy, S.; Tseng, P. l1-Penalized Likelihood Smoothing and Segmentation of Volatility Processes Allowing for Abrupt Changes. J. Comput. Graph. Stat. 2012, 21, 217–233. [Google Scholar] [CrossRef]
- Levy-leduc, C.; Harchaoui, Z. Catching change-points with LASSO. Adv. Neural Inf. Process. Syst. 2008, 20, 161–168. [Google Scholar]
- Harchaoui, Z.; Lévy-Leduc, C. Multiple change-point estimation with a total variation penalty. J. Am. Stat. Assoc. 2010, 105, 1480–1493. [Google Scholar] [CrossRef]
- Chatfield, C.; Prothero, D. Box-Jenkins seasonal forecasting: Problems in a case-study. J. R. Stat. Soc. Ser. A (Gen.) 1973, 136, 295–336. [Google Scholar] [CrossRef]
- Franses, P.H. Recent advances in modelling seasonality. J. Econ. Surv. 1996, 10, 299–345. [Google Scholar] [CrossRef]
- Osborn, D.R.; Smith, J.P. The performance of periodic autoregressive models in forecasting seasonal UK consumption. J. Bus. Econ. Stat. 1989, 7, 117–127. [Google Scholar]
- McCall, K.; Jeraj, R. Dual-component model of respiratory motion based on the periodic autoregressive moving average (periodic ARMA) method. Phys. Med. Biol. 2007, 52, 3455. [Google Scholar] [CrossRef] [PubMed]
- Tesfaye, Y.G.; Meerschaert, M.M.; Anderson, P.L. Identification of periodic autoregressive moving average models and their application to the modeling of river flows. Water Resour. Res. 2006, 42. [Google Scholar] [CrossRef] [Green Version]
- Weiss, L.; McDonough, R. Prony’s method, Z-transforms, and Padé approximation. Siam Rev. 1963, 5, 145–149. [Google Scholar] [CrossRef]
- Scharf, L.L. Statistical Signal Processing; Addison-Wesley: Reading, MA, USA, 1991; Volume 98. [Google Scholar]
- Tufts, D.W.; Fiore, P.D. Simple, effective estimation of frequency based on Prony’s method. In Proceedings of the 1996 IEEE International Conference on Acoustics, Speech, and Signal Processing Conference, Atlanta, GA, USA, 9 May 1996; Volume 5, pp. 2801–2804. [Google Scholar]
- Van Blaricum, M.; Mittra, R. Problems and solutions associated with Prony’s method for processing transient data. IEEE Trans. Electromagn. Compat. 1978, 1, 174–182. [Google Scholar] [CrossRef]
- Hurst, M.P.; Mittra, R. Scattering center analysis via Prony’s method. IEEE Trans. Antennas Propag. 1987, 35, 986–988. [Google Scholar] [CrossRef]
- Wear, K.A. Decomposition of two-component ultrasound pulses in cancellous bone using modified least squares Prony method–Phantom experiment and simulation. Ultrasound Med. Biol. 2010, 36, 276–287. [Google Scholar] [CrossRef] [PubMed]
- Cadzow, J.A. Signal enhancement—A composite property mapping algorithm. IEEE Trans. Acoust. Speech Signal Process. 1988, 36, 49–62. [Google Scholar] [CrossRef]
- Rukhin, A.L. Analysis of time series structure SSA and Related techniques. Technometrics 2002, 44, 290–290. [Google Scholar] [CrossRef]
- Candès, E.J. Mathematics of sparsity (and a few other things). In Proceedings of the International Congress of Mathematicians, Seoul, Korea, 13–21 August 2014; Volume 123. [Google Scholar]
- Al Sarray, B.; Chrétien, S.; Clarkson, P.; Cottez, G. Enhancing Prony’s method by nuclear norm penalization and extension to missing data. Signal Image Video Process. 2017, 11, 1089–1096. [Google Scholar] [CrossRef]
- Tibshirani, R. Regression shrinkage and selection via the lasso. J. R. Stat. Soc. Ser. B (Methodol.) 1996, 58, 267–288. [Google Scholar]
- Candès, E.J.; Plan, Y. Near-ideal model selection by ℓ1 minimization. Ann. Stat. 2009, 37, 2145–2177. [Google Scholar] [CrossRef]
- Giraud, C. Introduction to High-Dimensional Statistics; CRC Press: Boca Raton, FL, USA, 2014; Volume 138. [Google Scholar]
- Bühlmann, P.; Van De Geer, S. Statistics for High-Dimensional Data: Methods, Theory and Applications; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2011. [Google Scholar]
- Chrétien, S.; Darses, S. Sparse recovery with unknown variance: A LASSO-type approach. IEEE Trans. Inf. Theory 2014, 60, 3970–3988. [Google Scholar] [CrossRef]
- Belloni, A.; Chernozhukov, V.; Wang, L. Pivotal estimation via square-root lasso in nonparametric regression. Ann. Stat. 2014, 42, 757–788. [Google Scholar] [CrossRef]
- Gandy, S.; Recht, B.; Yamada, I. Tensor completion and low-n-rank tensor recovery via convex optimization. Inverse Probl. 2011, 27, 025010. [Google Scholar] [CrossRef]
- Mu, C.; Huang, B.; Wright, J.; Goldfarb, D. Square deal: Lower bounds and improved relaxations for tensor recovery. In Proceedings of the International Conference on Machine Learning, Beijing, China, 21–26 June 2014; pp. 73–81. [Google Scholar]
- Chrétien, S.; Wei, T. Sensing tensors with Gaussian filters. IEEE Trans. Inf. Theory 2017, 63, 843–852. [Google Scholar] [CrossRef]
- Deledalle, C.A.; Vaiter, S.; Fadili, J.; Peyré, G. Stein Unbiased GrAdient estimator of the Risk (SUGAR) for multiple parameter selection. SIAM J. Imag. Sci. 2014, 7, 2448–2487. [Google Scholar] [CrossRef]
- Chretien, S.; Gibberd, A.; Roy, S. Hedging parameter selection for basis pursuit. arXiv, 2018; arXiv:1805.01870. [Google Scholar]
- Fazel, M.; Pong, T.K.; Sun, D.; Tseng, P. Hankel matrix rank minimization with applications to system identification and realization. SIAM J. Matrix Anal. Appl. 2013, 34, 946–977. [Google Scholar] [CrossRef]
- Parikh, N.; Boyd, S. Proximal algorithms. Found. Trends® Optim. 2014, 1, 127–239. [Google Scholar] [CrossRef]
- Nishihara, R.; Lessard, L.; Recht, B.; Packard, A.; Jordan, M. A General Analysis of the Convergence of ADMM. In Proceedings of the International Conference on Machine Learning, Lille, France, 6–11 July 2015; pp. 343–352. [Google Scholar]







© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Barton, E.; Al-Sarray, B.; Chrétien, S.; Jagan, K. Decomposition of Dynamical Signals into Jumps, Oscillatory Patterns, and Possible Outliers. Mathematics 2018, 6, 124. https://doi.org/10.3390/math6070124
Barton E, Al-Sarray B, Chrétien S, Jagan K. Decomposition of Dynamical Signals into Jumps, Oscillatory Patterns, and Possible Outliers. Mathematics. 2018; 6(7):124. https://doi.org/10.3390/math6070124
Chicago/Turabian StyleBarton, Elena, Basad Al-Sarray, Stéphane Chrétien, and Kavya Jagan. 2018. "Decomposition of Dynamical Signals into Jumps, Oscillatory Patterns, and Possible Outliers" Mathematics 6, no. 7: 124. https://doi.org/10.3390/math6070124
APA StyleBarton, E., Al-Sarray, B., Chrétien, S., & Jagan, K. (2018). Decomposition of Dynamical Signals into Jumps, Oscillatory Patterns, and Possible Outliers. Mathematics, 6(7), 124. https://doi.org/10.3390/math6070124