1. Introduction
Peer-to-Peer (P2P) lending belongs to FinTech services that directly match the lenders with borrowers through online platforms without the intermediation of financial institutions such as banks [
1]. P2P lending has grown rapidly, attracting many users and generating huge transaction data. For example, the total loan issuance of the Lending Club reached about
$31 billion in the second half of 2017.
When a borrower applies to the platform, many lenders select a borrower and lend money. It is the financial loss of the lender that the borrowers do not pay or only partially pay to them in the repayment period. The lenders may suffer due to the default of the borrowers [
2]. To reduce the financial risk of the lenders, it is important to predict defaults and assess the creditworthiness of the borrowers [
3].
Since P2P social lending data is processed online, large and various data is generated, and the P2P lending platform provides much information on borrowers’ characteristics to solve problems, such as information asymmetry and transparency [
4,
5]. The availability and prevalence of transaction data on P2P lending have attracted many researchers’ attention. Recent studies mainly address the issues such as assessing credit risk, portfolio optimization and predicting default.
They extract features from information on borrowers and loan products of transaction data and solve the problems using machine learning methods with extracted features [
6]. Most studies design feature extractors based on statistical methods [
7], and extract hand-crafted feature representations [
8].
However, these studies are potentially faced with problems such as scale limitation and variety. The conventional machine learning is difficult to train and test large data [
9] and tree-based classification methods with high performance require many features [
10]. Also, statistical methods and hand-crafted methods are limited in extracting features by capturing the relationship between complex variables inherent in various data.
In the case of the Lending Club in the United States, it provides a total of one million data, consisting of 42,535 in 2007–2011, 188,181 in 2012–2013, 235,629 in 2014, 421,095 in 2015 and 434,407 in 2016 (March 2017,
https://www.lendingclub.com). The amount of data in the P2P lending is increasing, and the data structure is very large and complex.
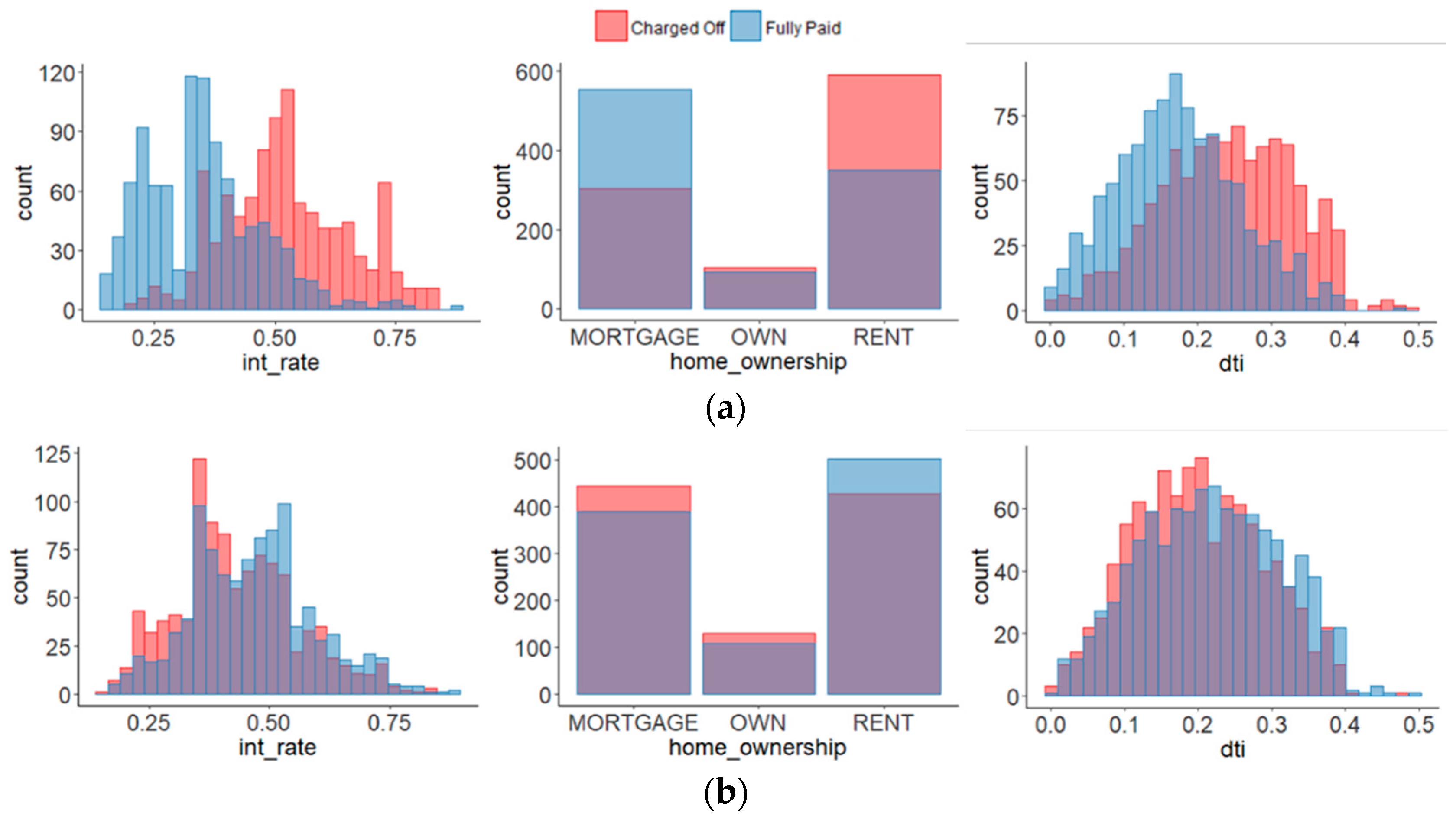
Table 1 shows the statistics of the data from the Lending Club and
Table 2 shows the description of some attributes.
Figure 1 shows some of the correlation plots for the loan status of the samples after normalizing the raw data. As can be seen in the figure, the “charged off” and the “fully paid” have very similar plot correlations. These loan status classes can be easily confused with each other. It is difficult to extract discriminative features for the loan status.
Deep learning, which has become a huge tide in the field of big data and artificial intelligence, has made a significant breakthrough in machine learning and pattern recognition research. It provides a predictive model for large and complex data [
11], which automatically extracts non-linear features by stacking layers deeply. Especially, deep convolutional neural network (CNN), one of the deep learning models, extracts hierarchically local features through weighted filters [
12]. Several researchers have studied mainly to recognize patterns using images [
13], video [
14], speech [
15], text [
16], and other datasets [
17]. It is also applied to other problems such as recognizing the emotions of people [
18,
19] and predicting power consumption [
20].
In this paper, we exploit a deep CNN approach for repayment prediction in social lending. The CNN is well-known as powerful tool for image classification, but has not been explored for general data mining tasks. We aim to extend the edge of the applications of CNN to large-scale data classification. The social lending data contains a specific pattern for the borrowers and the loan product. The convolutional layer captures the various features of borrowers from the transaction data, and the pooling layer merges similar features into one. By stacking several convolutional layers and the pooling layers, the basic features are extracted in the lower layer, and the complex ones are derived in the higher layer. The deep CNN model can classify the loan status of borrowers by extracting discriminative features among them and learning patterns in lending data.
We confirm the potential of CNN in the problem of social lending by designing one-dimensional CNN, and analyzing the features extracted and the performance in Lending Club data, evaluating whether the feature representation is generalized for other lenders. We show how various convolutional architectures affect overall performance, and how the systems that do not require hand-crafted features outperform other machine learning algorithms. We provide empirical rules and principles for designing deep CNN architectures for repayment prediction in social lending.
This paper is organized as follows. In
Section 2, we discuss the related work on social lending.
Section 3 explains the proposed deep CNN architecture.
Section 4 presents the experimental results, and
Section 5 concludes this paper.
2. Related Works
Milne et al. stress that P2P lending platforms are increasing in many countries around the world, and that the probability of increased defaults and potential problems are important [
21]. As shown in
Table 3, there are many studies on the default of borrowers and the credit risk in P2P social lending.
Most researchers have mainly used a few data and attributes by extracting features using a statistical method or hand-crafted ones. They presented a default prediction model and a credit risk assessment model using a machine learning method. Lin et al. proposed a credit risk assessment model using Yooli data from a P2P lending platform in China [
7]. They extracted the features affecting defaults by analyzing the demographic characteristics of borrowers using a nonparametric test. As a result, ten variables, including gender, age, marital status and loan amount were extracted, and a credit risk assessment model established using logistic regression. Malekipirbazari and Aksakalli assessed credit risk in social lending using random forest [
8]. Data pre-processing and manipulation tasks were used to extract 15 features and evaluate the performance according to the number of features. As the number of features grew, it performed better. They achieved higher performance compared to other methods.
All of these studies have been hand-designed to derive unique features, which makes it difficult to compare them with other experimental grounds [
29]. As the amount of data and the number of attributes increase, it is difficult to extract discriminative features of the borrower. However, because big data brings about new opportunities for discovering new values [
30], it is important to use all the information of the borrower to predict the repayment of the borrower accurately.
On the other hand, there have been studies using a lot of data. Kim and Cho used semi-supervised learning to improve the performance leveraging the unlabeled data of Lending Club data [
23]. They predicted the default of borrowers using a decision tree with unlabeled data. Vinod Kumar et al. analyzed the credit risk by labeling new classes to all data as “Good” or “Bad”, such as “current,” “default,” “late”, including the data of the borrower who was “fully paid” and “charged off” [
10]. However, these studies also require the process of extracting features. In this paper, we show that deep CNN can overcome the problem of default prediction by using all the data and attributes.
5. Conclusions
We have presented an architecture of deep CNN for repayment prediction in P2P social lending. It is confirmed that the deep CNN model is very effective in repayment prediction compared to the feature engineering and machine learning algorithms. The presented model can help choice of the lenders. The visualization analysis reveals that the feature space is clustered well depending on the success of repayment, and verifies that the extracted features of the deep CNN are effective to the prediction.
In addition, we have analyzed the features extracted by the deep CNN model with the misclassification cases based on the confusion matrix, which shows the problem of skewed distribution of classes.
To solve this problem, we need data from borrowers that have not been repaid. In reality, however, it is difficult to collect data, because there are fewer borrowers who did not repay than the borrower who has been repaid. This problem can be worked out by giving more weight to the data on the less observable side (non-repaid borrowers), or more losses when the data is misclassified. In addition, an architecture of deep CNN can be deeply established by extracting dense information and sparse information at the same time using a various size of filters, and it can extract features of the borrower who did not repay. This problem remains for a future work that we must address. We also need more effort to find the various parameters of deep CNN automatically such as the number of layers and the order of layers in addition to the basic parameters such as the number of filters and the size of the kernel in order to determine the optimal architecture. For fairer comparison, we also need to adopt more sophisticated classifiers such as gradient boosting trees.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}





