Undergraduate Students’ Solutions of Modeling Problems in Algorithmic Graph Theory



Abstract
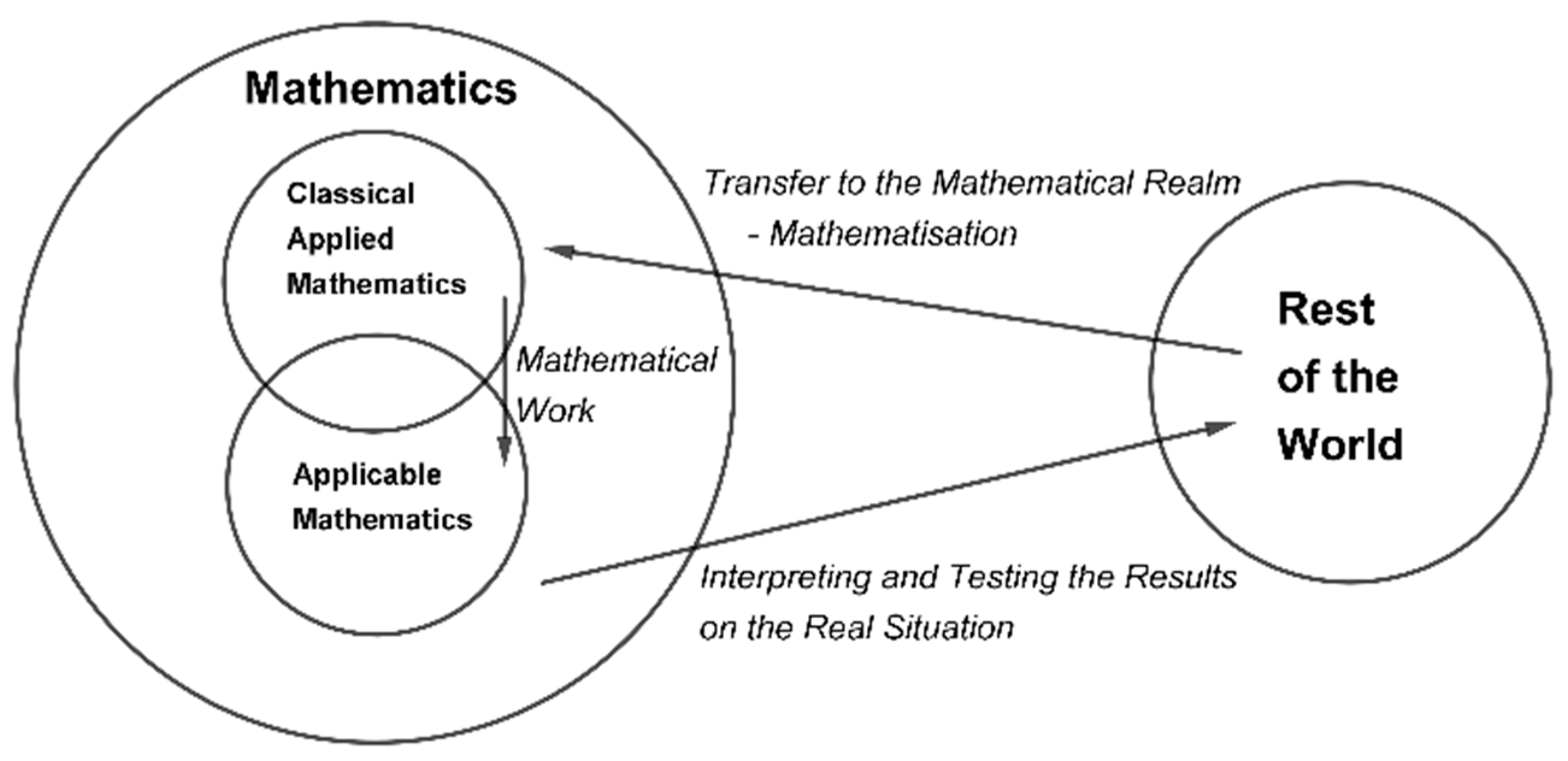
:1. Introduction
2. Materials and Methods
2.1. Description of the Settings
2.2. Data
2.3. Statistical Analysis
3. Results
3.1. Problem 1: Minimum Spanning Tree Problem
3.2. Problem 2: Shortest Path Problem
3.3. Problem 3: Chinese Postman Problem
3.4. Analysis
3.5. IRT Analysis
3.6. Hierarchical Cluster Analysis
4. Discussion
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Appendix A



References
- Blomhøj, M. Different perspectives in research on the teaching and learning mathematical modeling. In Mathematical Applications and Modeling in the Teaching and Learning of Mathematics; Proceedings from Topis Study Group 21 at the 11th ICME, Monterrey, Mexiko, 6–13 July, 2008; Blomhøj, M., Carreira, S., Eds.; Roskilde University: Roskilde, Denmark, 2009; pp. 6–13. [Google Scholar]
- Lesh, R.; Carmona, G.; Post, T. Models and Modeling. In Proceedings of the Annual Meeting of the North American Chapter of the International Group for PME, Athens, Greece, 26–29 October 2002; pp. 89–98. [Google Scholar]
- Fischer, R.; Malle, G. Mensch und Mathematik; Bibliographisches Institut: Mannheim, Germany, 1985; ISBN 3-411-03117-4. [Google Scholar]
- Binns, B.; Burkhardt, H.; Gillespie, J.; Swan, M.B. Mathematical modeling in the School Classroom: Developing Effective Support for Representative Teachers. In Applications and Modeling in Learning and Teaching mathematics; Proceedings of the 3rd ICTMA, Kassel University, Germany, 8–11 September, 1987; Blum, W., Niss, M., Huntley, I., Eds.; Halsted Press: Chichester, UK, 1989; pp. 136–143. [Google Scholar]
- Voskoglou, M.G. Mathematical Modeling as a Teaching Method of Mathematics. J. Res. Innov. Teach. 2015, 8, 35–50. [Google Scholar]
- Kaiser, G. Mathematical Modeling in School—Examples and Experiences. In Mathematikunterricht im Spannungsfeld von Evolution und Evaluation. Festschrift für Werner Blum; Henn, H.-W., Ed.; Franzbecker: Hildesheim, Germany, 2005; pp. 99–108. [Google Scholar]
- Blomhøj, M.; Jensen, T.H. Developing mathematical modeling competence: Conceptual clarification and educational planning. Teach. Math. Appl. 2003, 22, 123–139. [Google Scholar] [CrossRef]
- Blomhøj, M.; Kjeldsen, T.H. Teaching mathematical modeling through project work. ZDM 2006, 38, 163–177. [Google Scholar] [CrossRef]
- Blomhøj, M.; Kjeldsen, T.H. Learning the Integral Concept through Mathematical Modeling. In Proceedings of the 5th CERME, Larnaca, Cyprus, 22–26 February 2007; Pitta-Pantazi, D., Philippou, G., Eds.; pp. 2070–2079. [Google Scholar]
- Blum, W.; Borromeo Ferri, R. Mathematical Modeling: Can it Be Taught and Learnt? J. Math. Model. Appl. 2009, 1, 45–58. [Google Scholar]
- Plothová, L. Development of Abilities to Model and to Algebrize Relations and Dependencies as Part of Standard Competences in Education of Mathematics on Grammar-School. Ph.D. Thesis, Constantine the Philosopher University, Nitra, Slovakia, 2017. [Google Scholar]
- Boaler, J. Mathematical Mindsets, 1st ed.; Jossey-bass, A Wiley Brand: San Francisco, CA, USA, 2016; ISBN 978-0-470-89452-1. [Google Scholar]
- Samkova, L. The current state of IBME in the Czech Republic. In Implementing Inquiry in Mathematics Education; Baptist, P., Raab, D., Eds.; University of Bayreuth: Bayreuth, Germany, 2012; pp. 82–93. [Google Scholar]
- Bruder, R.; Prescott, A. Research evidence on the benefits of IBL. ZDM 2013, 45, 811–822. [Google Scholar] [CrossRef]
- Balogh, Z.; Turčáni, M.; Magdin, M. Design and Creation of a Universal Model of Educational Process with the Support of Petri Nets. Lect. Notes Electr. Eng. 2014, 269, 1049–1060. [Google Scholar] [CrossRef]
- Li, X.; Li, G.; Zhang, S. Routing Space Internet Based on Dijkstra’s Algorithm. In Proceedings of the 2009 First Asian Himalayas International Conference on Internet, Kathmandu, Nepal, 3–5 November 2009; pp. 1–4. [Google Scholar]
- Biza, I.; Giraldo, V.; Hochmuth, R.; Khakbaz, A.; Rasmussen, C. Research on Teaching and Learning Mathematics at the Tertiary Level: State-of-the-Art and Looking Ahead; ICME-13 Topical, Surveys; Kaiser, G., Ed.; Springer Open: Berlin, Germany, 2016; pp. 1–32. [Google Scholar] [CrossRef]
- Marion, W.A. Discrete mathematics for computer science majors—Where are we? How do we proceed? In Proceedings of the SIGCSE ‘89 Twentieth SIGCSE Technical Symposium on Computer Science Education, Louisville, KY, USA, 23–24 February 1989; Volume 21, pp. 273–277. [Google Scholar]
- Li, C.-C.; Mehrotra, K.; Jong, C. Discrete mathematics as a transitional course. Ideas 2012, 3, 40. [Google Scholar]
- Ivanov, O.A.; Ivanova, V.V.; Saltan, A.A. Discrete mathematics course supported by CAS MATHEMATICA. Int. J. Math. Educ. Sci. Technol. 2017, 48, 953–963. [Google Scholar] [CrossRef]
- Ho, W.K.; Toh, P.C.; Teo, K.M.; Zhao, D.; Hang, K.H. Beyond School Mathematics. In Mathematics Education in Singapore; Toh, T.L., Kaur, B., Tay, E.G., Eds.; Springer: Singapore, 2019; pp. 67–100. ISBN 978-981-13-3573-0. [Google Scholar]
- Almstrum, V.L.; Henderson, P.B.; Harvey, V.; Heeren, C.; Marion, W.; Riedesel, C.; Soh, L.-K.; Tew, A.E. Concept inventories in computer science for the topic discrete mathematics. ACM SIGCSE Bull. 2006, 38, 132–145. [Google Scholar] [CrossRef]
- Turčáni, M.; Kuna, P. Analysis of subject discrete mathematics parts and proposal of e-course model following Petri nets for informatics education. ERIES J. 2013, 6, 1–13. [Google Scholar] [CrossRef]
- Marion, W. Discrete mathematics a mathematics course or a computer science course? Probl. Resour. Issues Math. Undergr. Stud. 1991, 1, 314–324. [Google Scholar] [CrossRef]
- Gries, D.; Schneider, F.B. A new approach to teaching discrete mathematics. Probl. Resour. Issues Math. Undergr. Stud. 1995, 5, 113–138. [Google Scholar] [CrossRef]
- Paterson, J.; Sneddon, J. Conversations about curriculum change: Mathematical thinking and team-based learning in a discrete mathematics course. Int. J. Math. Educ. Sci. Technol. 2011, 42, 879–889. [Google Scholar] [CrossRef]
- Kuna, P.; Turčáni, M. Design of new methods of teaching the subject Discrete Math. In Proceedings of the 11th ICETA, Stara Lesna, Slovakia, 24–25 October 2013; pp. 247–251. [Google Scholar]
- Falcón, R.; Ríos, R. The use of GeoGebra in Discrete Mathematics. GeoGebra Int. J. Rom. 2015, 4, 39–50. [Google Scholar]
- Baudon, O.; Laborde, J.M. Cabri-graph, a sketchpad for graph theory. Math. Comp. Simul. 1996, 42, 765–774. [Google Scholar] [CrossRef]
- Fest, A.; Kortenkamp, U. Teaching graph algorithms with Visage. Teach. Math. Comp. Sci. 2009, 7, 35–50. [Google Scholar] [CrossRef]
- Quinn, A. Using Apps to Visualize Graph Theory. Math. Teach. 2015, 108, 626–631. [Google Scholar] [CrossRef]
- Vidermanová, K.; Melušová, J.; Vasková, V. Employing learning management system Moodle in discrete mathematics course in undergraduate education from students’ point of view. In Proceedings of the APLIMAT, Bratislava, Slovakia, 6–9 February 2007; pp. 413–417, ISBN 978-80-969562-8-9. [Google Scholar]
- Karagiannis, P.; Markelis, I.; Paparrizos, K.; Samaras, N.; Sifaleras, A. E-learning technologies: Employing matlab web server to facilitate the education of mathematical programming. Int. J. Math. Educ. Sci. Technol. 2006, 37, 765–782. [Google Scholar] [CrossRef]
- Hanzel, P.; Voštinár, P. Elektronický kurz “Vybrané kapitoly z diskrétnej matematiky” [Electronic Course in Discrete Mathematics]. Stud. Sci. Fac. Peadagogicae 2016, 11, 88–96. [Google Scholar]
- Milková, E. Constructing knowledge in graph theory and combinatorial optimization. WSEAS Trans. Math. 2009, 8, 424–434. [Google Scholar]
- Dagdilelis, V.; Satratzemi, M. DIDAGRAPH: Software for teaching graph theory algorithms. ACM SIGCSE Bull. 1998, 30, 64–68. [Google Scholar] [CrossRef]
- Niman, J. Graph theory in the elementary school. Educ. Stud. Math. 1975, 6, 351–373. [Google Scholar] [CrossRef]
- Yanagimoto, T.; Nakamoto, A.; Mazura, N. A study on teaching graph theory—For primary & junior high school students. In Proceedings of the TSG 13 in ICME-10, Copenhagen, Denmark, 4–11 July 2004; Niss, M., Ed.; Roskilde University: Roskilde, Denmark, 2008; pp. 346–350, ISBN 978-87-7349-733-3. [Google Scholar]
- Geschke, A.; Kortenkamp, U.; Lutz-Westphal, B.; Materlik, D. Visage—Visualization of algorithms in discrete mathematics. ZDM 2005, 37, 395–401. [Google Scholar] [CrossRef]
- Lodder, J. Networks and spanning trees: The juxtaposition of Prüfer and Borůvka. Probl. Resour. Issues Math. Undergr. Stud. 2014, 24, 737–752. [Google Scholar] [CrossRef]
- Cigas, J.; Hsin, W.-J. Teaching proofs and algorithms in discrete mathematics with online visual logic puzzles. J. Educ. Resour. Comput. 2005, 5, 1–12. [Google Scholar] [CrossRef]
- Vidermanová, K.; Melušová, J. Teaching graph theory with Cinderella and Visage: An undergraduate case. In New Trends in Mathematics Education: DGS in Education; Vallo, D., Šedivý, O., Vidermanová, K., Eds.; Univerzita Konštantína Filozofa v Nitre: Nitra, Slovakia, 2011; pp. 79–85. ISBN 978-80-8094-853-5. [Google Scholar]
- Hazzan, O.; Hadar, I. Reducing Abstraction when Learning Graph Theory. J. Comp. Math. Sci. Teach. 2005, 24, 255–272. [Google Scholar]
- Star, J.R. Foregrounding Procedural Knowledge. J. Res. Math. Educ. 2007, 38, 132–135. [Google Scholar] [CrossRef]
- Rittle-Johnson, B.; Schneider, M.; Star, J. Not a One-Way Street: Bidirectional Relations between Procedural and Conceptual Knowledge of Mathematics. Educ. Psychol. Rev. 2015, 27, 587–597. [Google Scholar] [CrossRef]
- Brodie, K. Learning about learner errors in professional learning communities. Educ. Stud. Math. 2014, 85, 221–239. [Google Scholar] [CrossRef]
- Ketterlin-Geller, L.R.; Yovanoff, P. Diagnostic assessments in mathematics to support instructional decision making. Pract. Assess. Res. Eval. 2009, 14, 1–11. [Google Scholar]
- Borasi, R. Exploring mathematics through the analysis of errors. Learn. Math. 1987, 7, 2–8. [Google Scholar]
- Hejný, M. Teória Vyučovania Matematiky 2 [Theory of Mathematics Education 2]; SPN: Bratislava, Slovakia, 1989; ISBN 80-08-01344-3. [Google Scholar]
- Milková, E. The minimum spanning tree problem: Jarník’s solution in historical and present context. Electron. Notes Discret. Math. 2007, 28, 309–316. [Google Scholar] [CrossRef]
- Milková, E. Combinatorial Optimization: Mutual Relations among Graph Algorithms. WSEAS Trans. Math. 2008, 7, 293–302. [Google Scholar]
- Nešetřil, J.; Milková, E.; Nešetřilová, H. Otakar Borůvka on minimum spanning tree problem: Translation of both the 1926 papers, comments, history. Discret. Math. 2001, 233, 3–36. [Google Scholar] [CrossRef]
- Edmonds, J.; Johnson, E.L. Matching, Euler tours and the Chinese postman. Math. Program. 1973, 5, 88–124. [Google Scholar] [CrossRef]
- Kráľ, P.; Kanderová, M.; Kaščáková, A.; Nedelová, G.; Valenčáková, V. Viacrozmerné Štatistické Metódy so Zameraním na Riešenie Problémov Ekonomickej Praxe [Multivariate Statistical Methods with Focus on Solving Problems of Economic Practice]; Univerzita Mateja Bela v Banskej Bystrici: Banská Bystrica, Slovakia, 2009; ISBN 978-80-8083-840-9. [Google Scholar]
- Novotná, J.; Chvál, M. Impact of order of data in word problems on division of a whole into unequal parts. ERIES J. 2018, 11, 85–92. [Google Scholar] [CrossRef]
- Meijer, R.R.; Baneke, J.J. Analyzing psychopathology items: A case for nonparametric item response theory modeling. Psychol. Methods 2004, 9, 354–368. [Google Scholar] [CrossRef] [PubMed]
- Mokken, R.J. A Theory and Procedure of Scale Analysis; De Gruyter Mouton: Berlin, Germany, 1971; ISBN 978-3-11-081320-3. [Google Scholar]
- Ramsay, J.O. A functional approach to modeling test data. In Handbook of Modern Item Response Theory; van der Linden, W.J., Hambleton, R.K., Eds.; Springer: New York, NY, USA, 1997; pp. 381–394. ISBN 978-1-4757-2691-6. [Google Scholar]
- Simonoff, J.S. Smoothing Methods in Statistics; Springer: New York, NY, USA, 1996; ISBN 978-1-4612-4026-6. [Google Scholar]
- Bloom, B.S.; Engelhart, M.D.; Furst, E.J.; Hill, W.H.; Krathwohl, D.R. Taxonomy of Educational Objectives. Handbook I: Cognitive Domain; McKay: New York, NY, USA, 1956; pp. 20–24. [Google Scholar]
- Kirschner, P.A.; Sweller, J.; Clark, R.E. Why minimal guidance during instruction does not work: An analysis of the failure of constructivist, discovery, problem-based, experiential, and inquiry-based teaching. Educ. Psychol. 2006, 41, 75–86. [Google Scholar] [CrossRef]
- Thimbleby, H. The directed Chinese postman problem. Softw. Pract. Exp. 2003, 33, 1081–1096. [Google Scholar] [CrossRef]
- Rosen, K.H. Discrete Mathematics and Its Applications, 7th ed.; McGraw Hill Companies: New York, NY, USA, 2007; ISBN 978-0-07-338309-5. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Number of Correctly Solved Problems | Frequency | Relative Frequency |
|---|---|---|
| 3 correct solutions | 50 | 39.4% |
| 2 correct solutions | 62 | 48.8% |
| 1 correct solution | 12 | 9.4% |
| 0 correct solutions | 3 | 2.4% |
| Total | 127 | 100.0% |
| Problem | Number of Students Who Attempted to Solve the Problem | Number of Correct Solutions |
|---|---|---|
| Minimum spanning tree problem | 122 | 110 a |
| Shortest path problem | 112 | 100 a |
| Chinese postman problem | 117 | 76 b |
| Category | Description of Mistake | Frequency |
|---|---|---|
| A | Wrong approach. Student tried to list all the spanning trees and compare their values (3 spanning trees listed) | 1 |
| B | Wrong order of the selection of edges (as a result of not sorting the list of weights of the edges) | 5 |
| Creating a circle (continuing the computation after the computations should have been stopped according to the algorithm) | 2 | |
| C | Assigning a wrong edge to the weight in the list | 1 |
| D | Numerical mistake when estimating the value of the spanning tree | 3 |
| Total | 12 |
| Category | Description of Mistake | Frequency |
|---|---|---|
| A | Wrong approach to determine the weights of vertices | 5 |
| B | Skipping the determination of the path | 3 |
| D | Numerical mistake in determination of the weights of vertices | 1 |
| Numerical mistake when using the different methods for the determination of the path | 2 | |
| Graphical mistake when using the tracing table for the determination of the path (confusion of vertices labels C and G) | 1 | |
| Total | 12 |
| Category | Description of Mistake | Frequency |
|---|---|---|
| A | Wrong approach | 5 |
| B | Wrong estimation of distance between vertices in three and more cases | 7 |
| Wrong pairing of odd-degree vertices | 3 | |
| Skipping the determination of Eulerian circle | 4 | |
| C | Wrong estimation of distance between vertices in one case | 2 |
| Wrong estimation of distance between vertices in two cases | 3 | |
| D | Numerical mistake in the sum of the distances | 12 |
| Graphical mistake in determination of Eulerian circle | 5 | |
| Total | 41 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Medová, J.; Páleníková, K.; Rybanský, Ľ.; Naštická, Z. Undergraduate Students’ Solutions of Modeling Problems in Algorithmic Graph Theory. Mathematics 2019, 7, 572. https://doi.org/10.3390/math7070572
Medová J, Páleníková K, Rybanský Ľ, Naštická Z. Undergraduate Students’ Solutions of Modeling Problems in Algorithmic Graph Theory. Mathematics. 2019; 7(7):572. https://doi.org/10.3390/math7070572
Chicago/Turabian StyleMedová, Janka, Kitti Páleníková, Ľubomír Rybanský, and Zuzana Naštická. 2019. "Undergraduate Students’ Solutions of Modeling Problems in Algorithmic Graph Theory" Mathematics 7, no. 7: 572. https://doi.org/10.3390/math7070572
APA StyleMedová, J., Páleníková, K., Rybanský, Ľ., & Naštická, Z. (2019). Undergraduate Students’ Solutions of Modeling Problems in Algorithmic Graph Theory. Mathematics, 7(7), 572. https://doi.org/10.3390/math7070572