1. Introduction
Stand attributes prediction has been a popular and challenging research topic in both forestry science and economics due to its importance to forest managers, governments, as well as economic stakeholders in recent years. Sustainable forest management process requires growth and yield models that enable prediction of the development of forest stands under different natural environment, economic and sociocultural pillars. Diameter at the breast height, total tree height, crown base height and crown width size dimensions (in the sequel—tree size variables), and the number of trees per hectare are substantial components of stand growth and yield models whose evolution provide details on stand development [
1]. These tree size variables are the most important predictor variables for the estimation of stem volume, biomass and carbon storage in natural forests. Rational management needs the dynamical individual tree growth and yield models because they provide the evolution for forward and backward directions, and produce detailed information about changes of stand structure [
2]. Tree size variables can be modeled as a complex system, each with its own regulatory mechanism and all continuously interacting between them. The mathematical and numerical methods used to describe the dynamic of biological system are largely concerned with the derivation, and use of ordinary stochastic and partial differential equations [
3,
4]. Individual-tree and stand-level growth models traditionally are represented by a system of ordinary differential equations [
5]. The basic idea is to describe a system of ordinary differential equations, which specifies changes of a suitable number of tree or stand size variables via age (time) and to summarize the relevant information about the size variables’ dependence. One of the advantages of ordinary differential equation approach lies in parameter interpretation, which simplifies the results’ interpretation by using asymptotic and inflection points. Unfortunately, an ordinary differential equations approach has some limitations, including the absence of the factor of tree size variables dependence and the variance-covariance matrix of tree size variables [
6,
7,
8]. In addition, eco-regional growth and yield models must be updated by including the random factor of a stand quality [
9]. Statistical analysis of developed relationships between tree size components at a given stand or location is usually performed based on statistical indexes and tests for an observed dataset. However, no single equation for tree size variables has gained global acceptance. The traditional method is to try a variety of models and choose the best fitted equation based on a particular mathematical norm, such as the least square error or a likelihood norm. The disadvantages of this method of choosing are that it is laborious because too many equations need to be tried and empirical choices of candidate equations make the results subjective. In order to overcome these disadvantages, the multivariate stochastic differential equations have recently gained a lot of attention. Stochastic differential equations are often used in the modeling of population dynamic [
10,
11,
12], tumor growth [
13], chemical reaction networks [
14], environmental pollution [
15,
16], forest growth and yield [
17]. The deterministic differential equation carries its solution, which is completely determined in the value sense by knowledge of boundary and initial conditions. It means that the identical initial and boundary conditions generate identical solutions. Conversely, a stochastic differential equation (SDE) is a differential equation with a solution which is a stochastic process. Because tree diameter at breast height, total tree height, crown base height and crown width are empirically correlated, the multivariate SDE models should be considered [
6,
8,
18].
The greatest advantage of multivariate SDE approach is that it provides sufficient flexibility to fit a large variety of nested models for a separate tree size and stand size variable, which facilitates the selection and comparison of newly developed models by using information measures technique [
19,
20,
21]. In order to construct the multi-information measures, it is necessary to obtain the probability density function of tree size variable, which in this study are obtained from a 4-variate Bertalanffy SDE describing the development of the tree size variables against the age. SDEs models are much more flexible than deterministic models, but come at a computational cost. The problem of representing the mechanisms governing the evolution of univariate tree size distribution have been directed using univariate SDEs in fluid mechanics [
22,
23]. Central research finding in tree size distributions by Kohyama et al. [
24] is the fact that they are positively skewed. Theoretical studies of tree size growth confirmed that the size frequency distribution of trees is inverse J-shaped, with many small trees and few larger trees due asymmetric competition [
25]. The Vasicek type 4-variate fixed effects SDE presented by Rupšys and Petrauskas [
6] defines changes in stem diameter and height distribution with age of a stand, which takes into account the 4-variate normal distribution at a given stand age, t. This study focuses on the alternative nonsymetric Bertalanfy type 4-variate diffusion process which links between tree diameter, height, crown base height and crown width dynamics, and their 4-variate lognormal probability density function development. Traditionally stochastic tree growth processes are observed in multiple populations (stands), so to quantify of both between and within stand variation the framework of the random effect parameters have been studied [
6,
11,
26,
27,
28]. In this basis, the introduction of only one additional random effect parameter allows capturing arbitrary wide stand dependencies without increasing model order, hence retaining model simplicity and ease of parameters estimation. The fixed and mixed parameters estimation for discretely observed SDE is a complex problem and during the past decades it has attracted the attention a lot of researchers. Taking the applicability and generality into account, maximum-likelihood estimation is in the lead among others [
29,
30]. Generally, when both system noise and random effects are considered, the exact form of the maximum likelihood function is unavailable, and then an approximated maximum likelihood procedure is used [
31].
This study focuses on a mixed-effects parameters 4-variate Bertalanffy type diffusion process satisfying an Itô [
32] SDE conditional on an initial value taken at a fixed initial time (age) point. In an even-aged stand tree size components’ distribution shows some asymmetry. The goal of this paper is to present a unified perspective of the tree growth in a forest stand network as a nonsymetric Markov process in a multidimensional vector space. Another goal is to study in a general way the main methods of cross comparisons of all new developed growth models by using the Shannon type differential entropy. In the Results and Discussion, we consider possible application to the study of information sharing amongst tree size variables using a dataset of the diameter at breast height, tree height, crown base height and crown width measurements in Scots pine (Pinus Sylvestris L.) stands in Lithuania. All results are implemented in symbolic algebra system MAPLE.
2. Materials and Methods
This paper focuses on a 4-variate Bertalanffy type SDE to study the tree size variables (diameter at breast height, D(t), tree height, H(t), crown base height, CH, and crown width, CW) distribution problem in forest stands. This results in an exact 4-variate asymmetrical conditional (transition) probability density function, whose parameters can be estimated by maximum likelihood procedure based on discrete time observations. The random effects are included to describe between-stand variability. Proceeding as we have in the bivariate Bertalanffy type SDE model [
8] that describes the development of the tree size variables evolving in M different stands, the mixed effect parameters 4-variate Bertalanffy type SDE model in a general manner are defined by:
here: M is the total number of stands used for model fitting,
t is the time (stand age),
,
,
,
,
,
, the drift vector
Ai (
x) is defined as:
the diffusion matrix
is defined as:
,
,
i = 1, 2, …, M, are independent 4-variate Brownian motions,
,
,
i = 1, 2, …, M, are independent and normally distributed random variables with zero mean and constant variances (
),
are fixed effect parameters to be estimated which fulfill conditions:
,
,
, and
,
, are mutually independent for all 1 ≤
i ≤ M,
. The Bertalanffy type 4-variate SDE can be converted into a well-studied 4-variate Ornstein-Uhlenbeck (1930) [
33] process by the transformation
and solved explicitly. The solution is a conditional random vector
that has a 4-variate lognormal distribution
,
i = 1, 2, … M, with the mean vector
:
the variance-covariance matrix
:
and the probability density function:
Here
3. Results
3.1. Marginal Distribution
Allowing that the random vector
,
i = 1, 2, …, M has a 4-variate lognormal distribution,
, defined by Equations (4)–(6) and referred to properties of multivariate lognormal distribution [
34,
35], the marginal univariate distribution of
,
is also lognormal
with mean and variance given by the following forms:
The marginal mean, median, mode, p-quantile (0 <
p < 1) and variance trajectories
,
,
,
and
,
are defined by [
34]:
where:
is the inverse of standard normal distribution function.
The marginal bivariate distribution of
,
,
i = 1, 2, …, M is also lognormal
with mean vector
and covariance matrix
given by the following forms:
The covariance and correlation functions are given by:
The marginal trivariate distribution of
,
,
i = 1, 2, …, M is also lognormal
with mean vector,
, and covariance matrix,
, given by the following forms:
3.2. Conditional Distributions
The conditional univariate distribution of
,
,
i = 1, 2, …, M at a given
,
is a univariate lognormal
, respectively, with mean and variance given by the following forms [
34,
35]:
The conditional mean, median, mode, p-quantile (0 < p < 1) and variance functions, , , , and , , i = 1, 2, …, M, are defined by Equations (9)–(12) after plugging the mean and variance given by Equations (20) and (21).
The conditional univariate distribution of
,
,
i = 1, 2, …, M at a given
,
is a univariate lognormal
, here:
The conditional mean, median, mode, p-quantile (0 < p < 1) and variance functions, , , , and , , i = 1, 2, …, M, , are defined by Equations (9)–(12) after plugging the mean and variance given by Equations (23) and (24).
The conditional univariate distribution of
,
,
i = 1, 2, …, M at a given
,
is a univariate lognormal
, here:
The conditional mean, median, mode, p-quantile (0 < p < 1) and variance functions, , , , and , , i = 1, 2, …, M, , are defined by Equations (9)–(12) after plugging the mean and variance given by Equations (27) and (28).
The conditional bivariate distribution of
,
,
i = 1, 2, …, M at a given
,
is a bivariate lognormal
, here:
The conditional bivariate distribution of
,
,
i = 1, 2, …, M at a given
,
is a bivariate lognormal
, here:
The conditional trivariate distribution of
,
,
i = 1, 2, …, M at a given
,
is a trivariate lognormal
, here:
3.3. Maximum Likelihood Procedure
Most natural processes evolve in continuous time, but they are observed in discrete time. To examine practical applications of the Bertalanffy type 4-variate stochastic process defined by Equation (1) suppose that we observe the process at discrete time points
composing an estimation dataset
(
ni is the number of observed trees of the
ith stand,
i = 1, 2, …, M). The associated maximum log-likelihood function for the fixed effect scenario model takes the following form:
and for the mixed effect scenario model takes the following form:
here
. As the 4-variate integral in Equation (40) does not have a closed-form solution and the analytic expression is known, the maximum log-likelihood function for the 4-variate mixed effect scenario model by using the Laplace expansion is approximately given in the following form [
36]:
here:
. The random effects
are estimated by maximization:
The maximization of is a two-step optimization problem. The internal optimization step estimates the vector for every stand i = 1, 2, …, M with Equation (42). The external optimization step maximizes after plugging the into Equation (41). These two steps are iterated until convergence.
3.4. Random Effects Calibration
A key feature of mixed effects models is that, by introducing random effects in addition to fixed effects, they allow us to correctly account both within- and between forest stand variations. In the forestry literature, calibration means that random effects are calibrated using a supplementary sample of observations taken from the previous observations
at discrete previous times (ages)
. The random effects can be calibrated by:
In the previous study [
17], calibration relies on the mean trend Equation (9) to predict the random effects in relation to fixed effects parameters
estimated by approximated maximum likelihood procedure (see Equations (41) and (42)). Both alternative techniques deal adequately with random effects calibration, whose are essential for analyzing large observed datasets.
3.5. Estimating Results
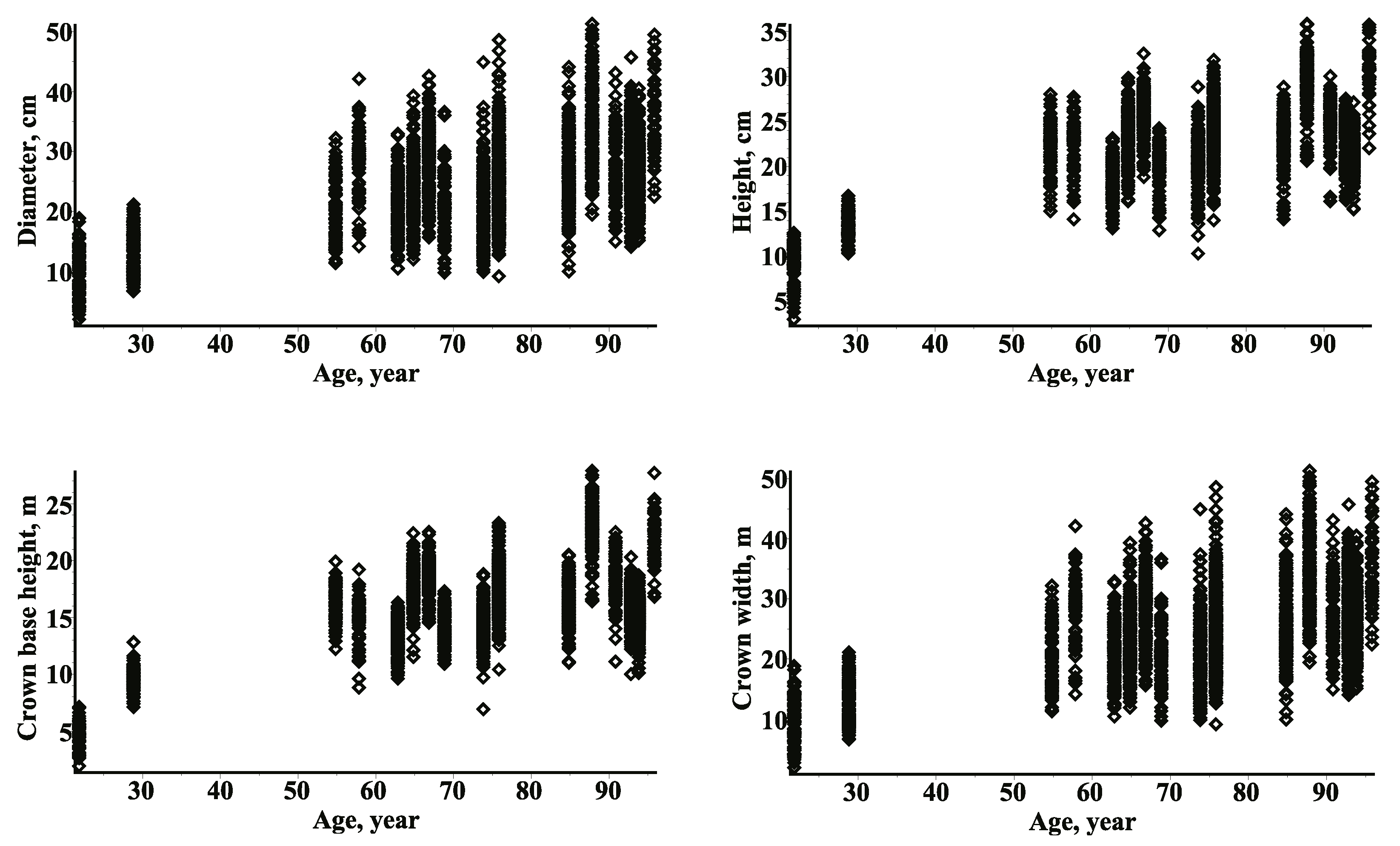
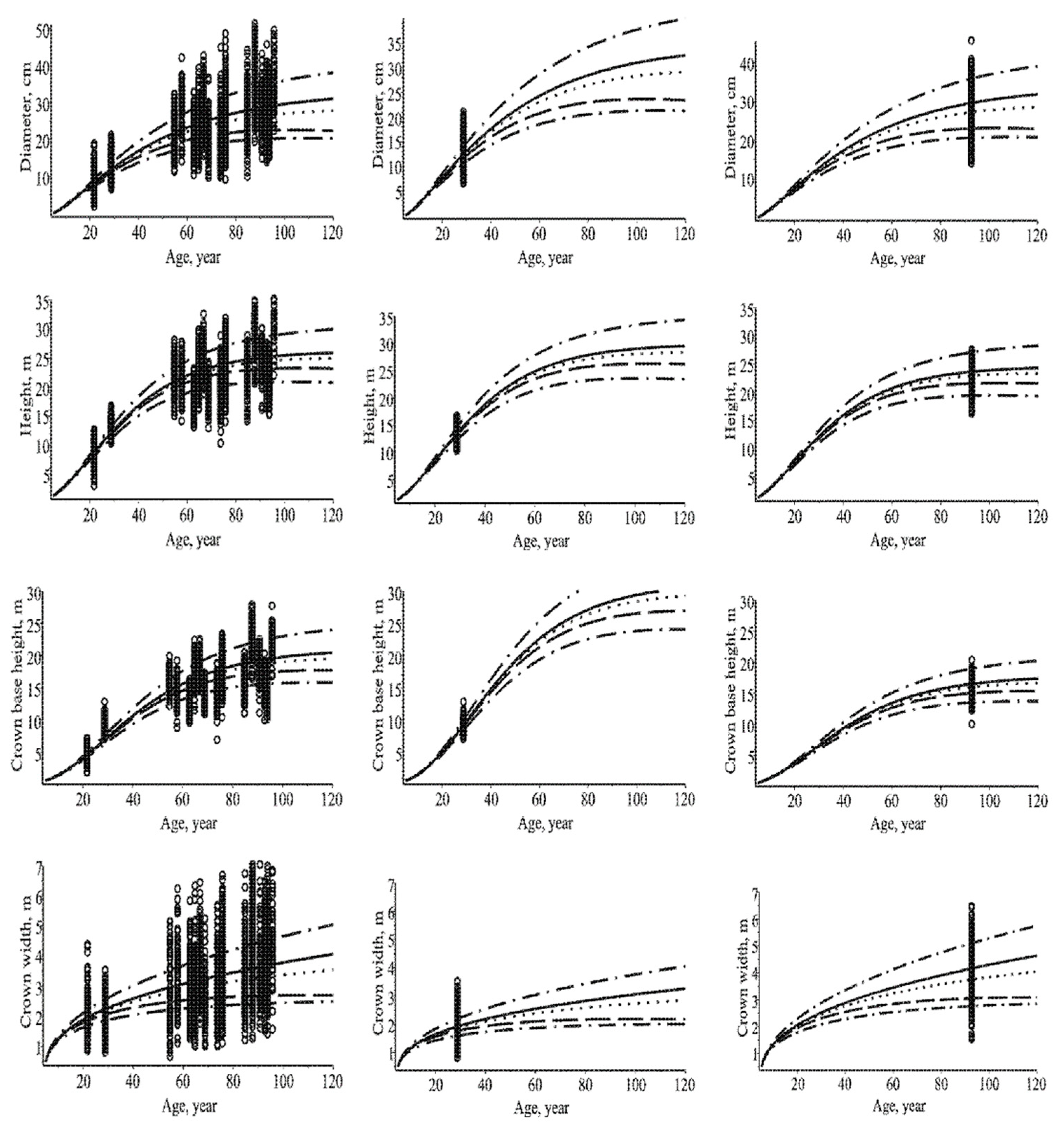
The data used were obtained from 17 permanent experimental Scots pine (Pinus sylvestris L.) stands [
6]. The measurements of the diameter at breast height (D), total height (H), crown base height (CH), and crown width (CW) are presented in
Figure 1.
The results of the parameter estimates using the NLPSolve procedure in the symbolic algebra system MAPLE [
37] are summarized in
Table 1.
3.6. Information Measures
Multivariate data analysis presents a wide range of mathematical and practical problems, particularly in forestry. Datasets sampled from forest stands measurements reflect complex biological systems confronted with diverse multiple interactions and dependencies between tree size variables. Therefore, full-scale analysis of dependencies between size components requires the use of the multivariable information measures. The inference of tree structure evolution, defined by Equation (1), is related to the estimation of the information flow between tree size variables. Entropy is a useful concept to measure the uncertainty in the multivariate stochastic systems and it can be applied to measure multivariate dependences between tree size variables. An information theoretic approach assumes that the development of tree size components will exhibit some dependencies among them, and therefore such statistical dependencies among tree size components can be used to construct the new theoretical growth and yield models. Central to this area is to determine the best relationship of target variable with one another of tree size variables by using an entropy-based technique or more generally to decide whether a subset of multiple tree size components is interdependent. This study will focus on the amount of information transmitted by a set of tree size variables. The simplest information theory measure between two variables is the interaction (mutual) information, which defines the information contained in one variable about another, defined by McGill (1954) [
38], can also be interpreted in terms of the Shannon entropy:
The definition of the differential Shannon entropy of a stochastic process directly follows that of a continuous random variable. Differential entropy cannot represent the uncertainty of continuous random processes and does not have the point of information. However, mutual information retains its interpretability in the continuous case.
Since the random vector (
X1,
X2,
X3,
X4) is lognormally distributed and for fixed effect scenario the random effects,
,
, are assumed to be equal its mean value
,
,
, moreover, taking into account stochastic representations of log-skew elliptical random vectors [
39], the expressions for univariate and multivariate Shannon entropies (measured in nats) take the following forms [
40]:
As we can see from Equation (45), the mutual information, I, is calculated directly by summing the individual entropies and subtracting the joint entropy. Mutual information, I, between two random variables,
Xs and
Xu, compares the uncertainty of measuring variables jointly with the uncertainty of measuring the two variables independently, identifies nonlinear dependence between two variables [
41,
42,
43], and is non-negative and symmetrical. A generalization of bivariate mutual information to more than two variables have been analyzed in few different scenarios [
20,
21,
41,
42,
43]. A direct multivariate extension of bivariate mutual information expressed by Equation (45) to
n variables
X1,
X2, and
Xn is named as the multi-information [
44,
45], also known as total correlation, and is defined by:
The multi-information is always non-negative and a near-zero value indicates that the variables are essentially statistically independent. Two special cases of mutual information take the normalized forms, respectively [
46,
47,
48]:
Next normalized variant of the mutual information is provided by the correlation coefficient in the following form [
49]:
A simple generalization of the normalized mutual information, defined by Equations (51)–(53), for three variables with the target variable
Xs (
s = 1, …, 4) takes the following forms:
Generalized forms of mutual information to more than two variables are called interaction information [
21,
47]. The relationship between multi-information and interaction information for the trivariate and 4-variate cases are defined in the following forms [
21]:
Providing that the target variable
Xs (
) is added to the set of
variables, the differential interaction information [
21,
47] is defined as:
In consequence of Equations (45), (46) and (59), the deltas for two variables
,
,
(the target variable
Xs) are defined as:
for three variables
,
,
(the target variable
Xs) are defined as:
for four variables
,
(the target variable
Xs) are defined as:
4. Discussion
Traditionally, the used statistical metrics for goodness-of-fit linear and nonlinear regression models mostly reflect only fitting criteria (not goodness of fit), which was used in an optimization process to get the best-fit parameters. For example, the coefficient of determination cannot determine whether the parameter estimates and predictions are biased. Similarly, a low value of the coefficient of determination can produce a good model. Consequently, the best metrics possessed model is not necessarily the one that fits best the data. Evaluation of the model fit within information measures relies on the detection of variable dependence, estimation of the significance of such dependence and inference of the functional form of the dependence [
21,
47]. Moreover, information measures operate on probability distributions rather than directly on data. In this study, the functional forms of inter-variable relationships are deducible using marginal densities (Equations (7), (8), (14), (15), (18) and (19)) of the 4-variate probability density function which is a solution of a diffusion process defined by Equation (1). In this study, the problem of inter-variable dependencies and correlations of new developed functional forms of tree size variable dynamic is analyzed by using entropy-based measures like interaction information, normalized interaction information, multi-information and differential interaction information (see Equations (45)–(62)). The Shannon entropies of the evolution of tree diameter, height, crown base height and crown width in univariate, bivariate, trivariate and four-variate cases are graphically charted in
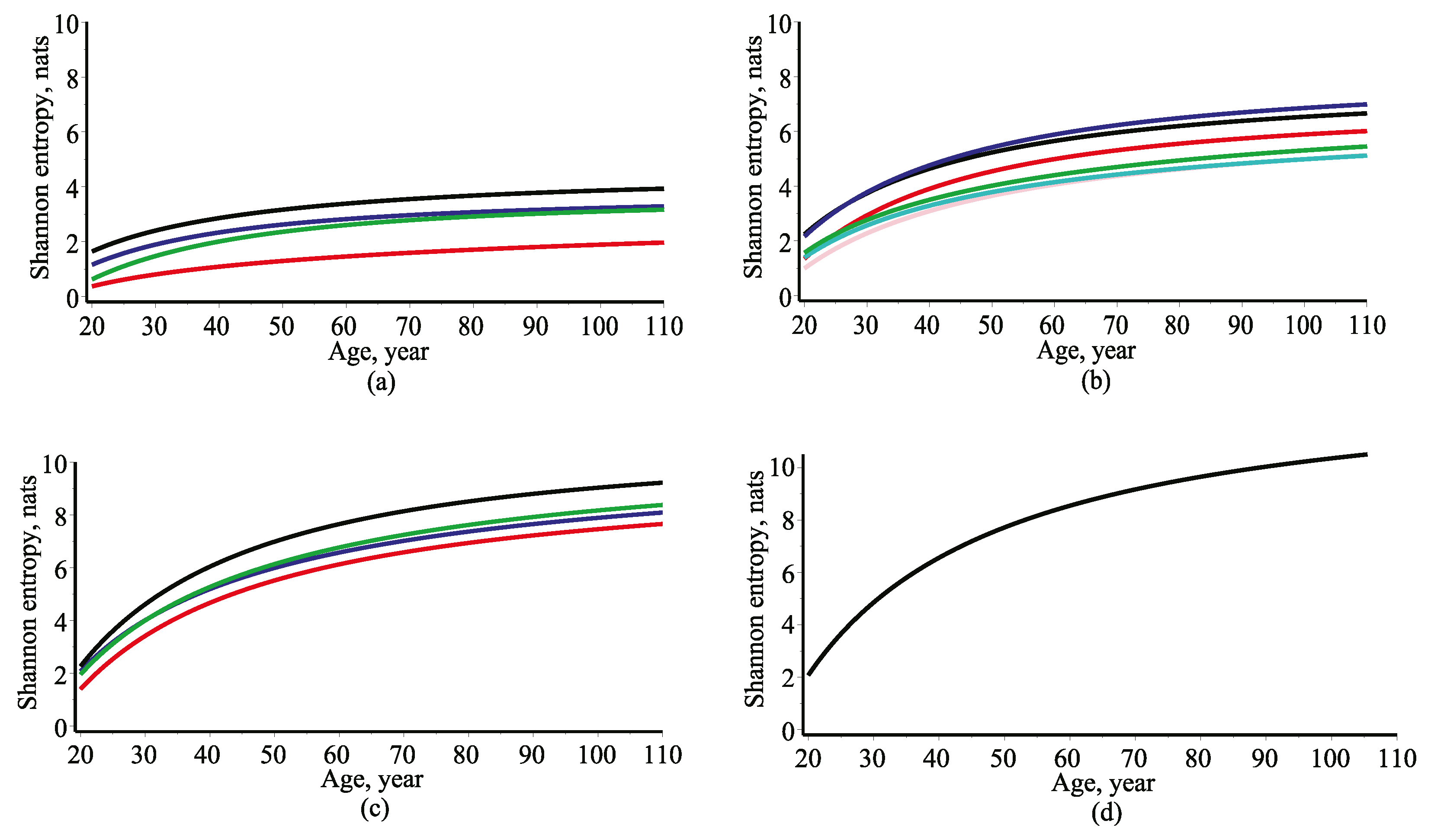
Figure 2.
It is evident that, to some extent, entropy can be viewed as the amount of information that can be gathered through observed dataset. It is understandable that the lower is the Shannon entropy of the tree size variable the less information about the evolution of a tree we are missing and providing more information about the tree development.
Figure 2 shows that for all scenarios (univariate, bivariate, trivariate and four-variate) the Shannon entropy increases against the time (age). Hence, an information available about the tree development is actually losing with acceding a tree age. Moreover, the differences of the Shannon entropy (uncertainty measures) between different scenarios of tree size variables can be interpreted as an information gain or loss. It is important to note, if a tree size variable have a small single uncertainty measure, then contribution to the multivariate entropy turns out to be negligible. The univariate probability density function of the diameter, defined by Equations (7) and (8), produced the supreme entropy relationship whereas the univariate probability density function of the crown width produced the least entropy relationship. The bivariate probability density function of the diameter and height, defined by Equations (14) and (15), produced the supreme entropy relationship whereas the bivariate probability density function of the crown base height and crown width produced the least entropy relationship. Lastly, the trivariate probability density function of the diameter, height and crown base height, defined by Equations (18) and (19), produced the supreme entropy relationship whereas the trivariate probability density function of the height, crown base height and crown width produced the minimal entropy relationship.
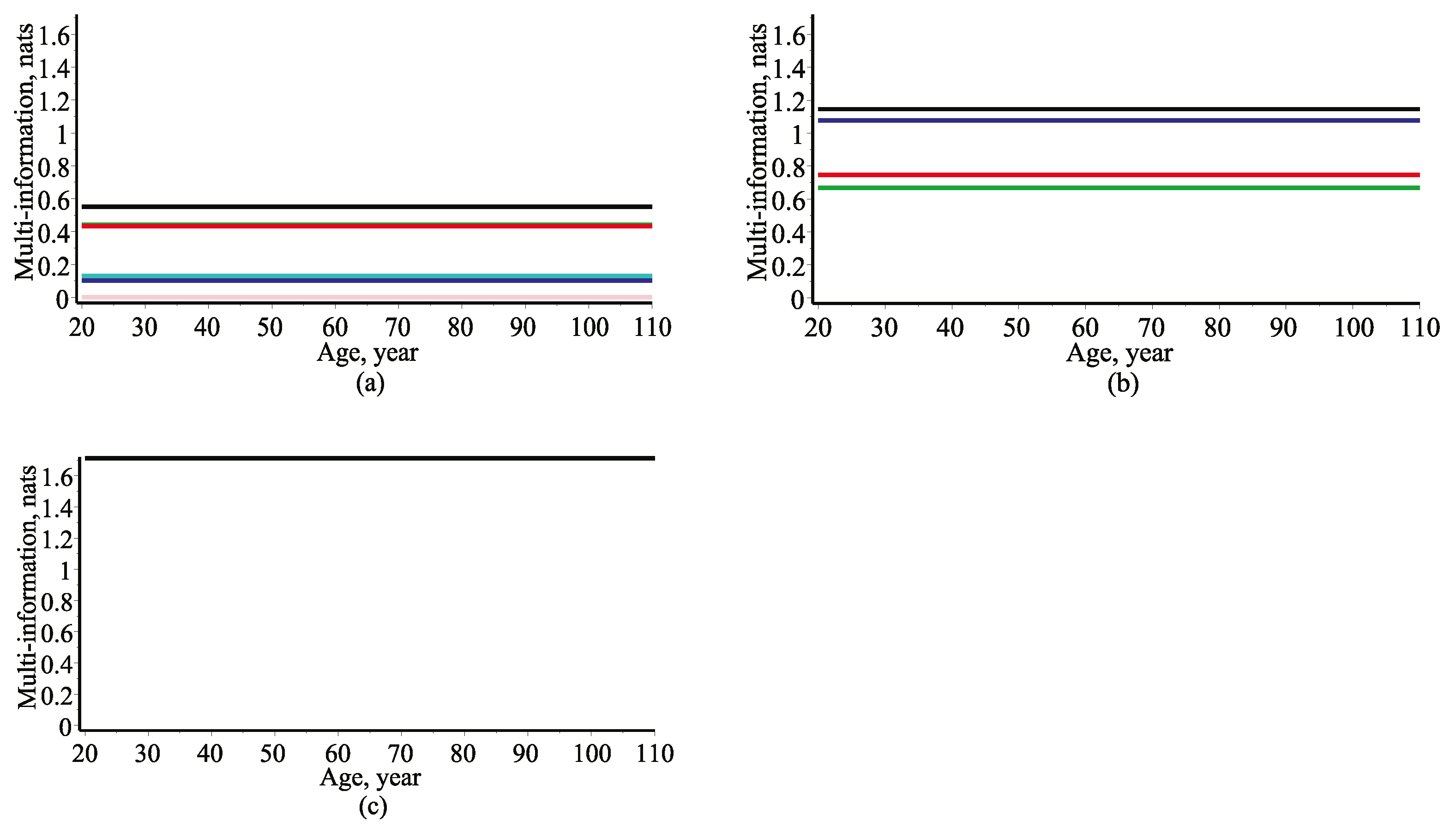
A complex way of quantifying statistical dependencies between tree size variables comes from the definition of multi-information, which is defined as the difference between the sum of single entropies for each tree size variables and the joint entropy of all tree size variables. The multi-information defined by Equation (55) quantifies the total amount of information carried by correlations between the variables. As a measure of overall multivariable dependence or redundancy, this quantity goes to zero if all variables are independent. The information measure defined by Equations (45) and (50) is named as the total multi-information of two and n random variables, respectively.
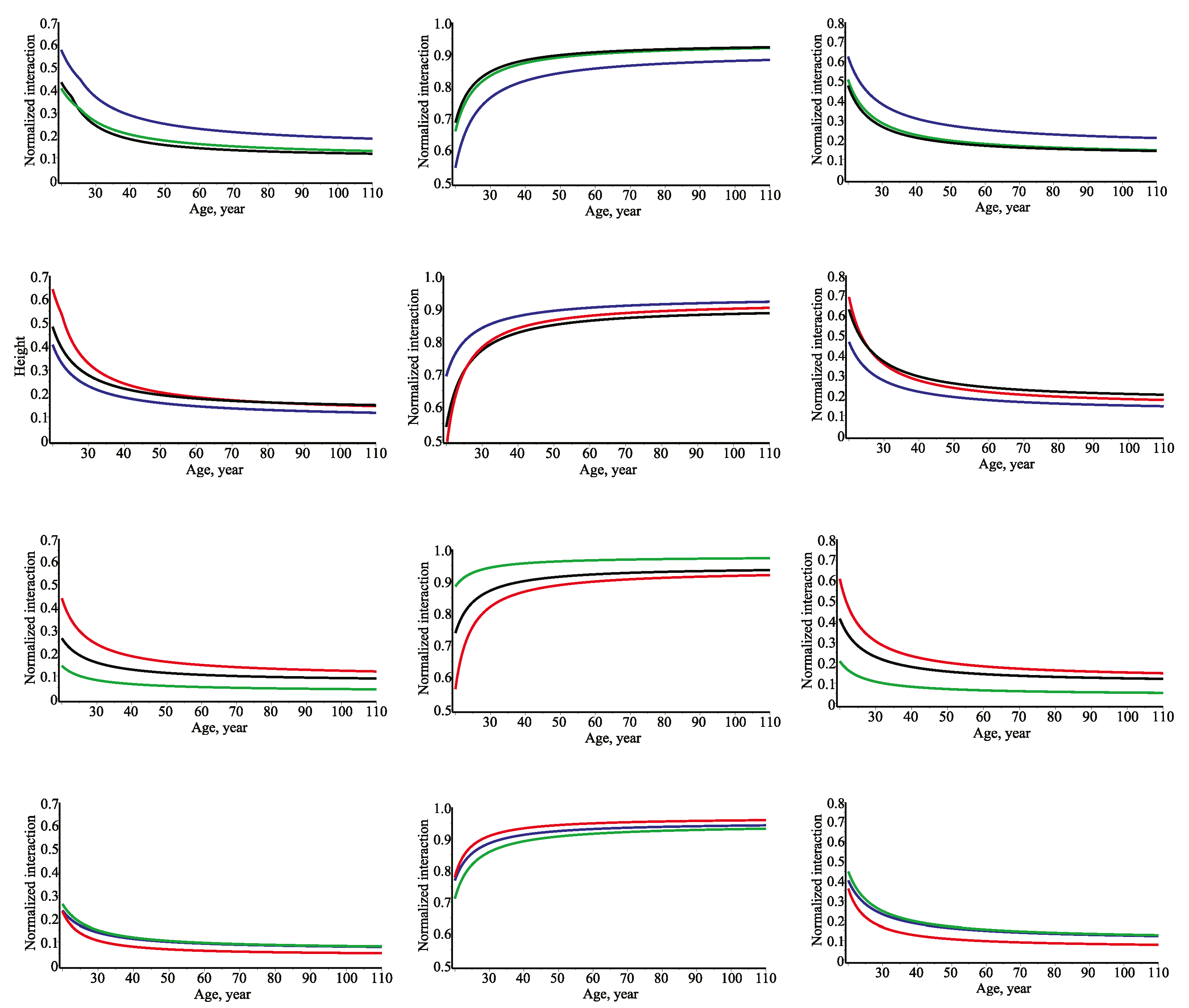
Figure 3 shows that multi-information is positive, remains stable against the age and gathers bigger values by increasing the number of tree size variables. It is obvious that the multi-information is equal to the mutual information when n = 2. If we range all relationships by using multi-information measure, then, for example, examine
Figure 3 we could choose the most important predictor variables for quantifying other response variable. It follows that for a single response tree size variable—diameter (black, blue and green curves) the superior relationship could be defined using a height (black—diameter and height) as a predictor variable; for the height (black, red and cyan curves) the superior relationship could be defined using a diameter (black—diameter and height); for the crown base height (blue, cyan and pink curves) the superior relationship could be defined using height (cyan—height and crown base height); and for the crown width (green, pink and cyan curves) the superior relationship could be defined using a diameter (green—diameter and crown diameter). However, such ranging procedure is not successful, as the low joint entropy value of n variables will also produce low the value of multi-information even if the all the variables are perfectly related.
Figure 3 shows that the amount of multi-information is apparently constant via age.
The concept of causality is commonly understandable as the capacity of one variable to influence another. As was noted by Wiener [
50] for two simultaneously measured variables, ‘if we can predict the first variable better by using the past information from the second one than by using the information without it, then we call the second variable causal to the first one’. In Wiener’s formulation, the causality is a statistical concept that is based on prediction. Consequently, the best-ranked relationship is not necessarily the one that fits best the data, but that carries superior causality information. Recognizing the statement about causality as an information [
51] about the effect of nonlinear relationship we can examine and compare new developed nonlinear relationships by using intersection information measures defined by Equations (45) and (51)–(62). Modeling of the evolution of tree size variables requires better understanding which predictor exerts primary control on response tree size variable. Mutual information quantifies the amount of information that one tree size variable reveals about another and thus the strength of their codependency. Interconnecting causality with mutual information we can measure how much knowing one of these tree size variables reduces uncertainty about the other. If two tree size variables are independent, then knowing single tree size variable does not give any information about another tree size variable and vice versa, so their mutual information is zero. Unfortunately, the value of mutual information depends on the absolute magnitude of joint entropy between the two chosen tree size variables and is not appropriate to use directly for relative comparisons. Therefore, for the ranging of all developed models is advisable to use normalized interaction measures, defined by Equations (51)–(56). The higher normalized information measure values of the bivariate and trivariate mutual information (Equations (51), (53), (54) and (56)) show stronger relationship. The normalized mutual information interpreted in typical distance metric form (see Equations (52) and (55)) is closer to zero in case of a stronger similarity.
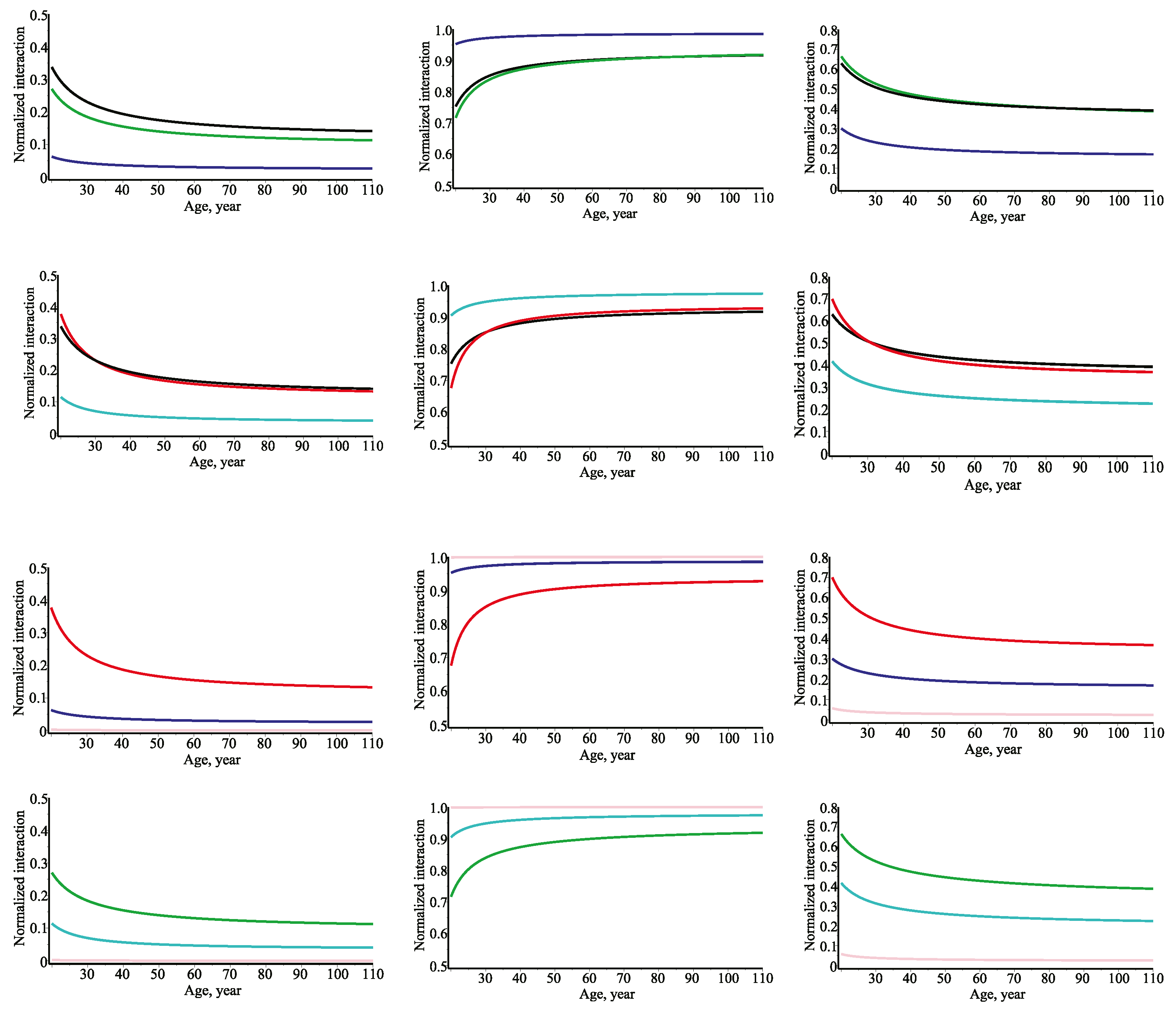
Figure 4 presents the evolution of the bivariate normalized mutual information defined by Equations (51)–(56). Eventually, the results presented in
Figure 4, provide strong evidence that information measures are powerful tools to quantify and explain the relevance of different nonlinear relationships for tree size variables modeling. It follows, that for the quantifying tree diameter relationship against a single predictor variable it must be the crown width or the height, as the corresponding bivariate normalized mutual information curves are sufficiently close or intersects. Following this overall result for the quantifying tree height relationship against a single predictor variable it must be the crown base height or the diameter, as the corresponding bivariate normalized mutual information curves are sufficiently close or intersects. For the quantifying tree crown base height relationship against a single predictor variable it must be the height and, eventually, for the quantifying tree crown base height relationship best a single predictor variable must be the diameter.
The evolution of the trivariate normalized mutual information defined by Equations (54)–(56) is presented in
Figure 5. In parallel with bivariate normalized mutual information scenario we can compare nonlinear relationships using trivariate normalized mutual information (see Equations (54)–(56)). Consequently, for the quantifying of tree diameter relationship against two predictor variables it must be the crown base height and crown width. For the quantifying of tree height relationship against two predictor variables it must be the diameter and crown base height. Moreover, for the quantifying of tree crown base height relationship against two predictor variables it must be the height and crown width. Eventually, for the quantifying of tree crown width relationship the best two predictor variables must be the diameter and crown base height.
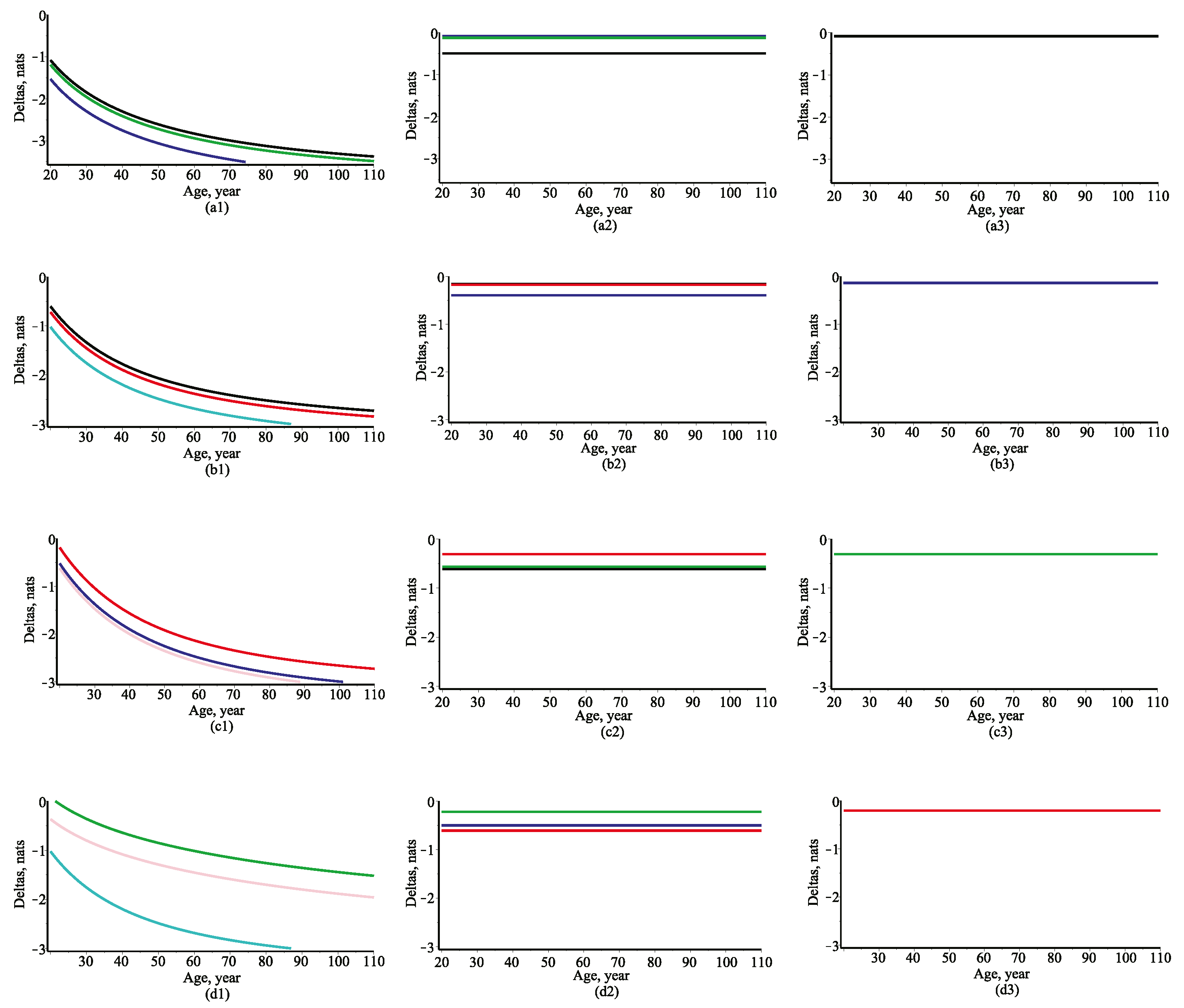
Given the initial state of the tree size variables, the solution of the SDE (1) determines the dynamic of the univariate, marginal and conditional probability density functions of state variables. These density functions of tree size variables are updated at each age. The dynamic of the univariate marginal and conditional density functions of tree size variables provides the updated prediction by using the mean and the conditional mean trend. For the test on predictive capacity of new derived nonlinear relationships previously were discussed the concepts of the normalized mutual information. To make SDE models comparison more precise, the difference of the intersection information (deltas) defined by Equations (58)–(62) prevails over previous discussed decisions.
Figure 6 presents the evolution of the difference of the intersection information (deltas). For tree growth modeling the general problem is to guarantee the maximum degree of dependence to be considered and to determine the number of the best predictor variables involved. The three non-linear scenarios (one, two and three predictors) for the mean trend of a response variable were developed in the present study. The further discussion deals with the adequacy of the deltas defined by Equations (59)–(62) in describing the dependence and causality of the tree size variables. The non-linear models showed that more of predictor variables is included the higher deltas value is achieved. Therefore, the nonlinear models with three predictors (see
Figure 6 the third column) provided the best reveal of dependence of all response variables (diameter, height, crown base height and crown width) due to the higher values of deltas than other models (one or two predictors). The shape of the deltas curves in the first column of
Figure 6 showed that height reveals the most part of dependence between diameter and other tree size variables (but remains very close result when used crown width as a predictor variable). The diameter reveals the most part of dependence between height and other tree size variables; the height reveals the most part of dependence between crown base height and other tree size variables; eventually, the diameter reveals the most part of dependence between crown width and other tree size variables.
In the second column of
Figure 6 the deltas curve showed that the height and crown width reveal the most part of dependence between diameter and other two tree size variables. The diameter and crown base height reveal the most part of dependence between height and other two tree size variables; the height and crown width reveal the most part of dependence between crown base height and other two tree size variables; eventually, the diameter and crown base height reveal the most part of dependence between crown width and other two tree size variables.
The ranking and selection of the mean tree size curves
,
,
and
can be alternately performed using basic statistical measures, for example, mean bias (MB), mean absolute bias (MAB), root mean square error (RMSE), adjusted coefficient of determination R
2, and Akaike’s information criterion (AIC) [
6,
17]. Statistical measures and the ranking for both fixed- and mixed effects scenarios presented in
Table 2. Therefore, from a statistical point of view (see
Table 2), for the fixed effects scenario all relationships attained lower values of statistical indexes than the mixed effects scenario models.
New developed nested statistical models, defined as a set of probability distributions on the sample space (dataset), support growth and yield modeling by facilitating individualized outcomes conditional on predictor variables. The goodness-of-fit of a model to dataset evaluated through the use of numerical statistical measures and presented in
Table 2 provides summary measures of the overall accuracy of the predictions. The goodness-of-fit of new developed models to data assessed by using numerical statistical measures MB, MAB, RMSE, R
2 and AIC presented in
Table 2, and information measures defined by Equations (45)–(62) and visualized in
Figure 1,
Figure 2,
Figure 3,
Figure 4 and
Figure 5 showed very similar results. This study presents that the interaction information measure approach is particularly powerful, but has less general applicability because of the complicated calculations required, which are not always presently solvable.
Forests statisticians who use mathematics but are not completely at ease with abstract mathematical notations and formulas presented in Equations (1)–(62) can often better understand the new derived mathematical models if these models are visually embodiment. Using the univariate marginal distributions (Equations (7) and (8)),
Figure 7 shows the mean, mode, median and both quartiles trends via the mean stand age (in the mixed-effect scenario for randomly selected two stands). The implementation of abstract mathematical Equations (9)–(12) visually reveals nonsymmetry that was not apparent from the observed discrete datasets. Just such a hidden nonsymmetry, disclosed by visualization, confirmed the fact that tree size variables are positively skewed.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}