A Model for Predicting Statement Mutation Scores


Abstract
:1. Introduction
2. Basic Terms
| Program 1: An original program. | |
| #include <stdio.h> | |
| typedef int bool ; | |
| void fun(int m, int n) { | |
| int dist, fac ; | |
| if(m>n) | |
| dist=m-n ; | |
| else | |
| dist=n-m; | |
| fac=1; | |
| while (dist>1) { // Loop for factorial | |
| fac=fac * dist ; | |
| dist = dist -1 ; | |
| } | |
| printf (“fac=%d ∖n”, fac); | |
| if ( m<n ) // classify the factorial | |
| printf (“class 1 ∖n” ) ; | |
| else if (fac<5) | |
| printf (“class 2 ∖n” ) ; | |
| else | |
| printf (“class 1 ∖n” ) ; | |
| } | |
| Program 2: The mutant of Program 1. | |
| #include <stdio.h> | |
| typedef int bool ; | |
| void fun(int m, int n) { | |
| int dist, fac ; | |
| if(m>n) | |
| dist=m%n ; | |
| else | |
| dist=n-m; | |
| fac=1; | |
| while (dist>1) { // Loop for factorial | |
| fac=fac * dist ; | |
| dist = dist -1 ; | |
| } | |
| printf (“fac=%d ∖n”, fac); | |
| if ( m<n ) // classify the factorial | |
| printf (“class 1 ∖n” ) ; | |
| else if (fac<5) | |
| printf (“class 2 ∖n” ) ; | |
| else | |
| printf (“class 1 ∖n” ) ; | |
| } | |
3. Formal Definitions of Statement Features
3.1. Value Impact Factor
3.1.1. Value Impact Factor of Statement
3.1.2. The Value Impact Relationship between Statement Instance and Its Direct Impact Successors
3.1.3. Value Impact Set of Branch Instance
3.1.4. Value Impact Set of the Special Statement Instance
3.2. Path Impact Factor
3.2.1. Path Impact Factor of Statement
3.2.2. The Path Impact Relationship of the Statement Instance and Its Direct Impact Successor
3.2.3. Path Impact Set of Branch Instance
3.2.4. Path Impact Set of the Special Statement Instance
3.3. Generalized Value Impact Factor
3.3.1. Generalized Value Impact Factor of Statement
3.3.2. Generalized Value Impact Set of the Special Statement Instance
3.3.3. The Generalized Value Impact Relationship between a Statement and Its Direct Impact Successors
3.4. Generalized Path Impact Factor
3.4.1. Generalized Path Impact Factor of Statement
3.4.2. Generalized Path Impact Set of the Special Statement Instance
3.4.3. The Generalized Path Impact Relationship between a Statement Instance and Its Direct Impact Successors
3.5. Latent Impact Factor
3.5.1. Latent Impact Factor of the Program Statement
3.5.2. The Latent Impact Relationship between a Statement Instance and its Direct Impact Successors
3.5.3. Latent Impact Set of the Special Statement Instance
3.6. Information Hidden Factor
4. Calculation of Statement Features
4.1. Calculation Process
- Step 1
- Set test case serial number .
- Step 2
- Construct the execution impact graph of the test case .
- Step 3
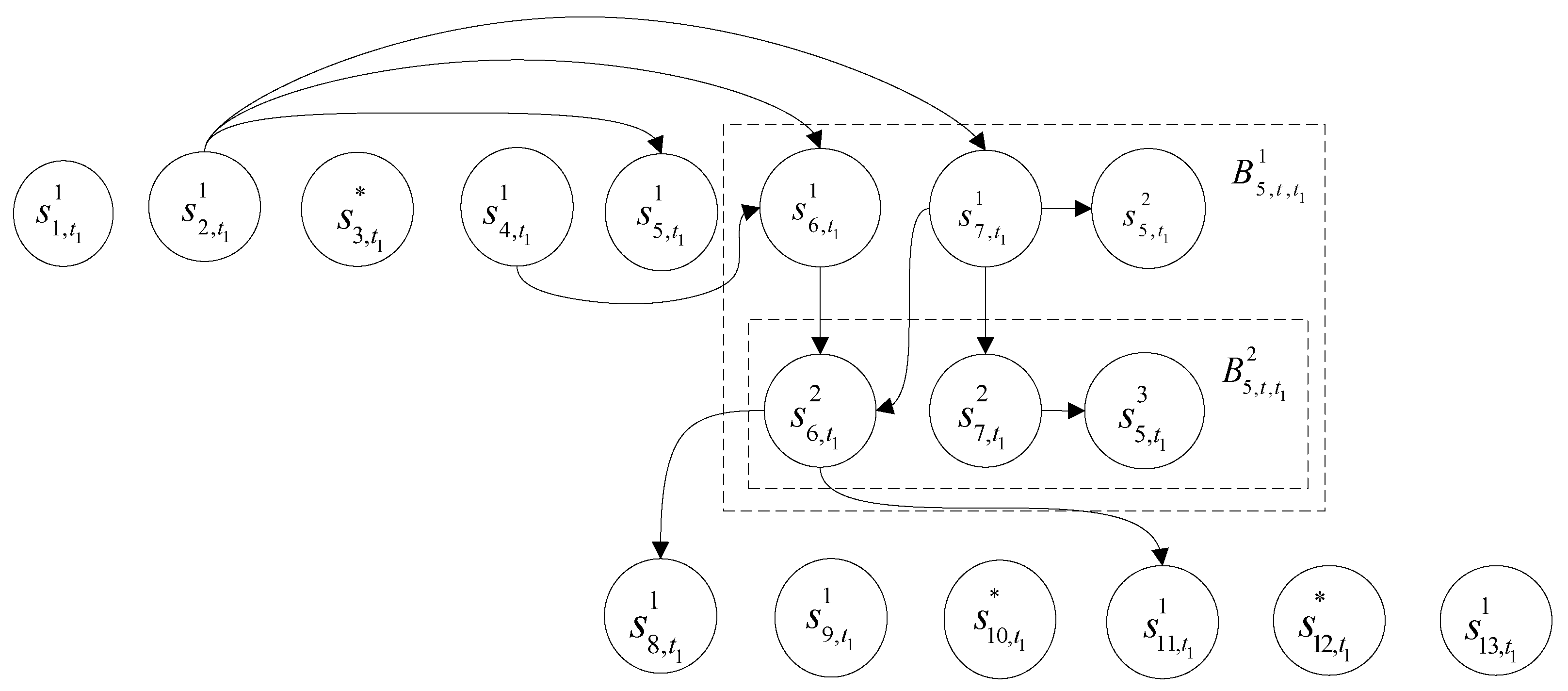
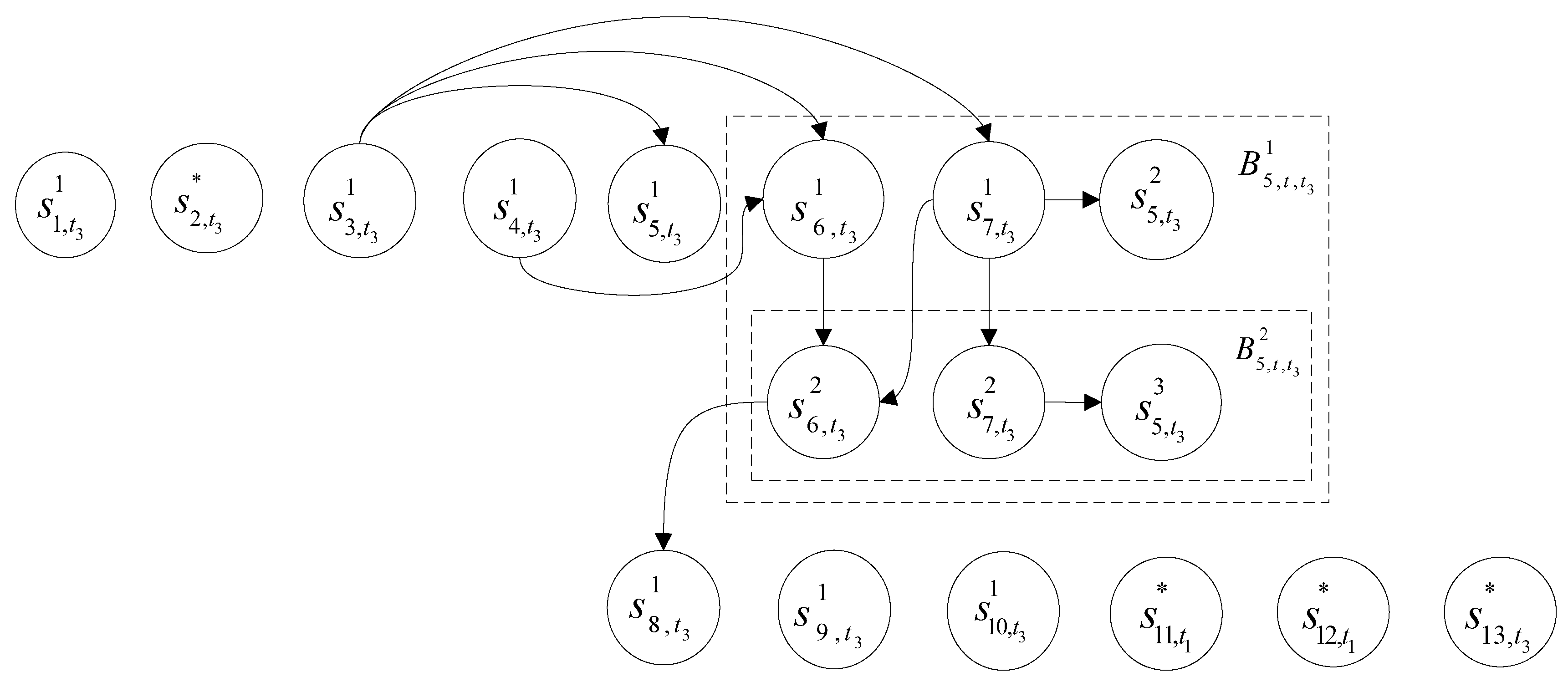
- First, from the original execution path of the test case , find all statement instances that have not been analyzed. From these unanalyzed statement instances, find the last executed statement instance. We might as well denote this statement instance as .(1) If has one or more impact successors, then we construct the impact sets of its first five features according to the formulas (2), (5), (8), (10) and (12).(2) If does not have any impact successors, then we construct the impact sets of its first five features according to the methods mentioned in Section 3.1.4, Section 3.2.4, Section 3.3.2, Section 3.4.2 and Section 3.5.3.
- Step 4
- If there are some statement instances which appear in the original execution path of test case but have not yet been analyzed, go to step 3, else go to step 5.
- Step 5
- If test case is not the last test case in test suite, then k = k + 1, and go to step 2, else go to step 6.
- Step 6
- First, construct each program statement’s value impact set, path impact set, generalized value impact set, generalized path impact set and latent impact set by formulas (1), (4), (7), (9) and (11). Next, for each program statement, calculate its value impact factor, path impact factor, generalized value impact factor, generalized path impact factor factor and the latent impact factor.
- Step 7
- For each statement in program under testing, compute the total number of times it is executed by the test cases in the test suite.
- Step 8
- For each statement in the program under testing, compute its information hidden factor by formula (13).
4.2. Computational Complexity Analysis
5. Machine Learning Algorithms Comparison and Modelling
5.1. Experimental Subjects
5.2. The Construction Method of Data Set
5.3. Performance Metrics
5.3.1. Area under Curve
5.3.2. Logarithmic Loss
5.3.3. Brier Score
5.3.4. Metric Comparison
5.4. Model Comparing and Tuning
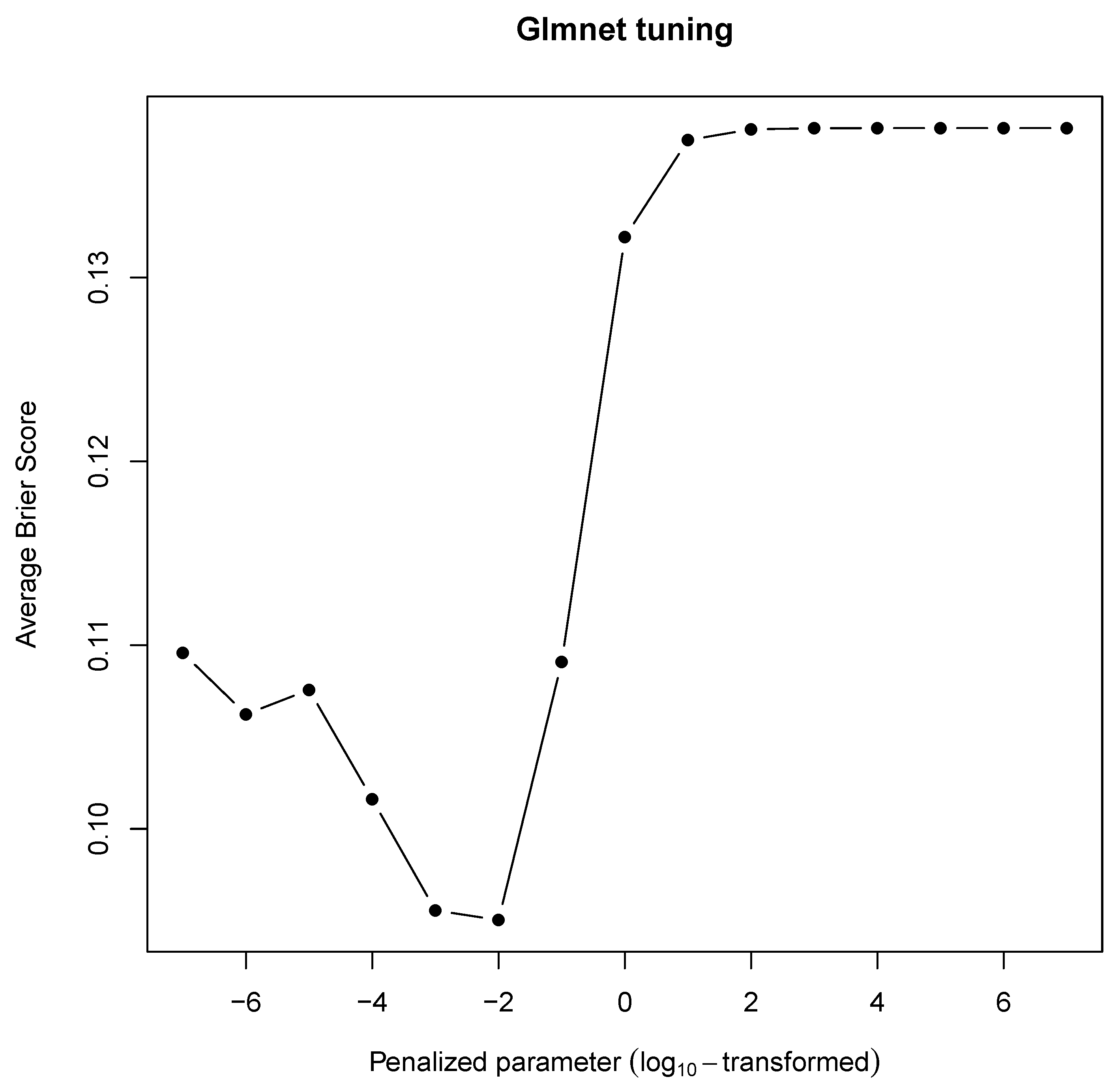
5.4.1. Logistic Regression
- (1)
- Introduction to Logistic Regression
- (2)
- Logistic regression tuning
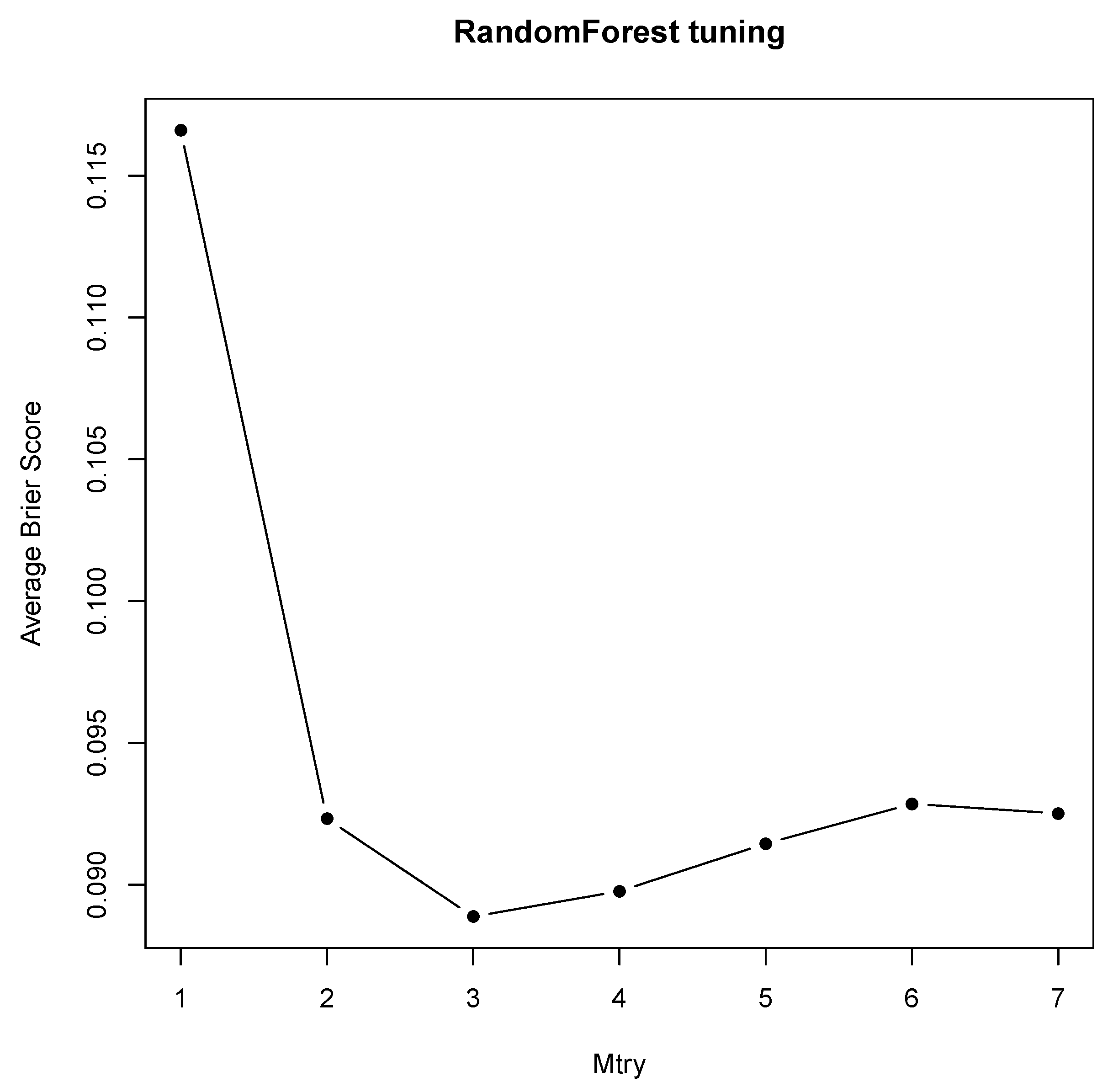
5.4.2. Random Forests
- (1)
- Introduction to Random Forest
- (2)
- Random forest tuning
5.4.3. Artificial Neural Networks
- (1)
- Introduction to neural network
- (2)
- Neural network tuning
5.4.4. Support Vector Machines
- (1)
- Introduction to support vector machine
- (2)
- Support vector machine tuning
5.4.5. Symbolic Regression
- (1)
- Introduction to symbolic regression
- (2)
- Symbolic regression tunning
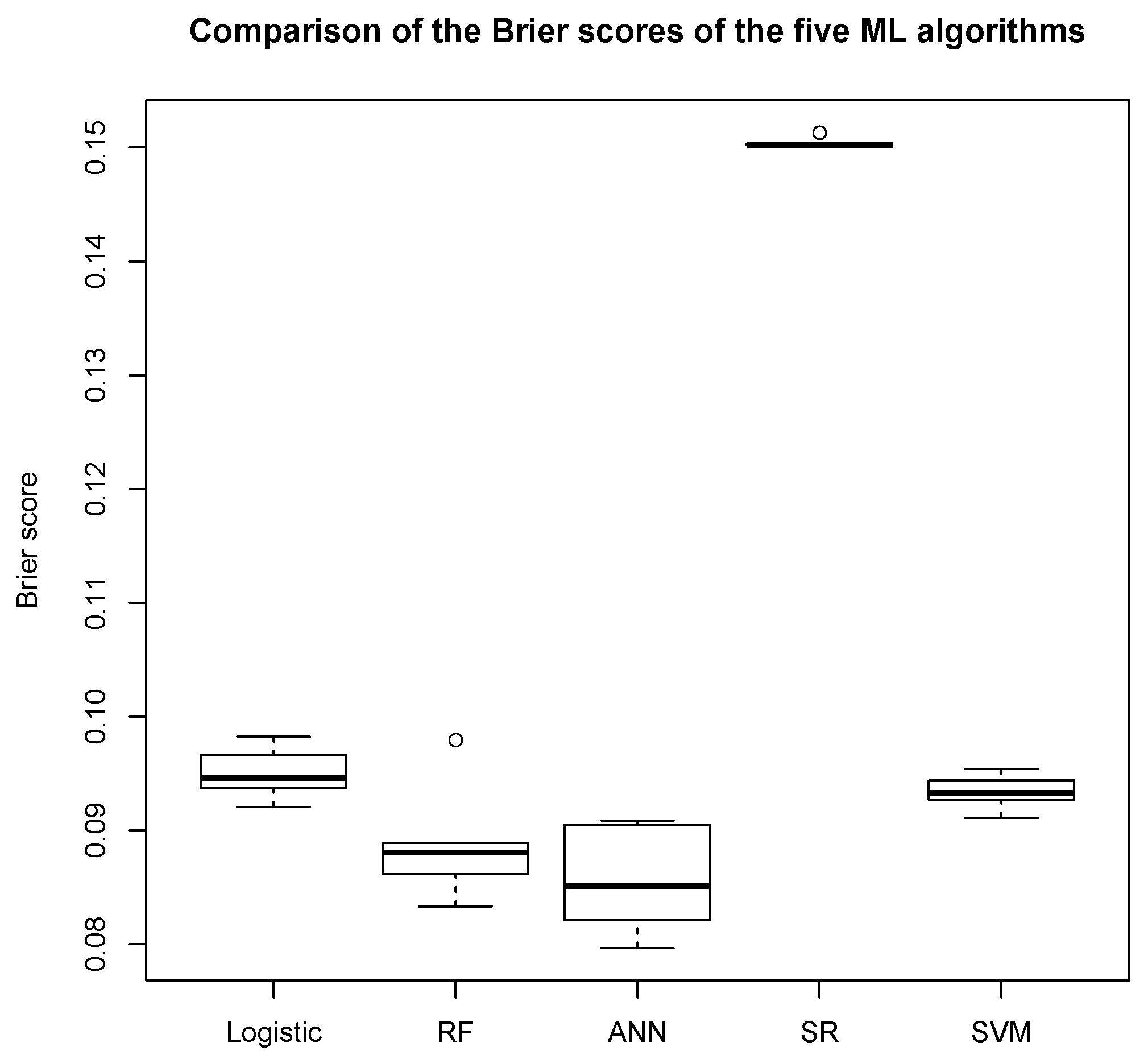
5.4.6. Comparing Models
5.4.7. Testing Predictions in Practice
5.5. Further Confirmation of the Optimization Model
6. Structure of the Automated Prediction Tool
7. Conclusions
Author Contributions
Funding
Conflicts of Interest
Abbreviations
| value impact set of the statement | |
| value impact factor of the statement | |
| value impact set of the statement instance | |
| value impact set of the branch instance | |
| path impact set of the statement | |
| path impact factor of the statement | |
| path impact set of the statement instance | |
| path impact set of the branch instance | |
| generalized value impact set of the statement | |
| generalized value impact factor of the statement | |
| generalized value impact set of the statement instance | |
| generalized path impact set of the statement | |
| generalized path impact factor of the statement | |
| path impact set of the generalized statement instance | |
| latent impact set of statement | |
| latent impact factor of statement | |
| latent impact set of statement instance | |
| information hidden factor of statement |
References
- Andrews, J.H.; Briand, L.C.; Labiche, Y. Is mutation an appropriate tool for testing experiments? In Proceedings of the 27th International Conference on Software Engineering, St. Louis, MO, USA, 15–21 May 2005; pp. 402–411. [Google Scholar]
- DeMillo, R.A.; Lipton, R.J.; Sayward, F.G. Hints on test data selection: Help for the practicing programmer. Computer 1978, 11, 34–41. [Google Scholar] [CrossRef]
- Mirshokraie, S.; Mesbah, A.; Pattabiraman, K. Efficient JavaScript mutation testing. In Proceedings of the 2013 IEEE Sixth International Conference on Software Testing, Verification and Validation, Luxembourg, 18–22 March 2013; pp. 74–83. [Google Scholar]
- Jia, Y.; Harman, M. An analysis and survey of the development of mutation testing. IEEE Trans. Softw. Eng. 2011, 37, 649–678. [Google Scholar] [CrossRef]
- Frankl, P.G.; Weiss, S.N.; Hu, C. All-uses vs mutation testing: An experimental comparison of effectiveness. J. Syst. Softw. 1997, 38, 235–253. [Google Scholar] [CrossRef]
- Maldonado, J.C.; Delamaro, M.E.; Fabbri, S.C.; da Silva Simão, A.; Sugeta, T.; Vincenzi, A.M.R.; Masiero, P.C. Proteum: A family of tools to support specification and program testing based on mutation. In Mutation Testing for the New Century; Springer: Berlin/Heidelberg, Germany, 2001; pp. 113–116. [Google Scholar]
- Acree, A.T., Jr. On Mutation; Technical Report; Georgia Inst of Tech Atlanta School of Information and Computer Science: Atlanta, GA, USA, 1980. [Google Scholar]
- Zhang, L.; Hou, S.S.; Hu, J.J.; Xie, T.; Mei, H. Is operator-based mutant selection superior to random mutant selection? In Proceedings of the 32nd ACM/IEEE International Conference on Software Engineering, Cape Town, South Africa, 1–8 May 2010; Volume 1, pp. 435–444. [Google Scholar]
- Hussain, S. Mutation Clustering. Master’s Thesis, Kings College London, London, UK, 2008. [Google Scholar]
- Gligoric, M.; Zhang, L.; Pereira, C.; Pokam, G. Selective mutation testing for concurrent code. In Proceedings of the 2013 International Symposium on Software Testing and Analysis, Lugano, Switzerland, 15–20 July 2013; pp. 224–234. [Google Scholar]
- Offutt, A.J.; Rothermel, G.; Zapf, C. An experimental evaluation of selective mutation. In Proceedings of the 1993 15th International Conference on Software Engineering, Baltimore, MD, USA, 17–21 May 1993; pp. 100–107. [Google Scholar]
- Zhang, J.; Zhang, L.; Harman, M.; Hao, D.; Jia, Y.; Zhang, L. Predictive mutation testing. IEEE Trans. Softw. Eng. 2018. [Google Scholar] [CrossRef]
- Jalbert, K.; Bradbury, J.S. Predicting mutation score using source code and test suite metrics. In Proceedings of the First, International Workshop on Realizing AI Synergies in Software Engineering, Zurich, Switzerland, 5 June 2012; pp. 42–46. [Google Scholar]
- Goradia, T. Dynamic impact analysis: A cost-effective technique to enforce error-propagation. In Proceedings of the 1993 ACM SIGSOFT International Symposium on Software Testing and Analysis, Cambridge, MA, USA, 28–30 June 1993; Volume 18, pp. 171–181. [Google Scholar]
- C programming Language Standard—C99. Available online: https://en.wikipedia.org/wiki/C99 (accessed on 19 August 2019).
- The Program schedule.c. Available online: https://www.thecrazyprogrammer.com/2014/11/c-cpp-program-forpriority-scheduling-algorithm.html (accessed on 19 August 2019).
- The Program tcas.c. Available online: https://sir.csc.ncsu.edu/php/showfiles.php (accessed on 19 August 2019).
- Kuhn, M.; Johnson, K. Applied Predictive Modeling; Springer: Berlin/Heidelberg, Germany, 2013; Volume 26. [Google Scholar]
- Brier, G.W. Verification of forecasts expressed in terms of probability. Mon. Weather Rev. 1950, 78, 1–3. [Google Scholar] [CrossRef]
- Hosmer, D.W., Jr.; Lemeshow, S.; Sturdivant, R.X. Applied Logistic Regression; John Wiley & Sons: Hoboken, NJ, USA, 2013; Volume 398. [Google Scholar]
- Harrell, F.E. Regression Modeling Strategies; Springer: Berlin/Heidelberg, Germany, 2001. [Google Scholar]
- Hastie, T.; Tibshirani, R.; Wainwright, M. Statistical Learning with Sparsity: The Lasso and Generalizations; Chapman and Hall/CRC: Boca Raton, FL, USA, 2015. [Google Scholar]
- Friedman, J.; Hastie, T.; Tibshirani, R. Regularization paths for generalized linear models via coordinate descent. J. Stat. Softw. 2010, 33, 1. [Google Scholar] [CrossRef] [PubMed]
- Tibshirani, R. Regression Shrinkage and Selection Via the Lasso. J. R. Stat. Soc. Ser. B 1994, 58, 267–288. [Google Scholar] [CrossRef]
- Glmnet. Available online: https://CRAN.R-project.org/package=glmnet (accessed on 19 August 2019).
- Breiman, L. Some Infinity Theory for Predictor Ensembles; Technical Report 579; Statistics Dept. UCB: Berkeley, CA, USA, 2000. [Google Scholar]
- Breiman, L. Consistency for a Simple Model of Random Forests; Technical Report (670); University of California at Berkeley: Berkeley, CA, USA, 2004. [Google Scholar]
- Quinlan, J.R. Simplifying decision trees. Int. J. Hum.-Comput. Stud. 1999, 51, 497–510. [Google Scholar] [CrossRef] [Green Version]
- The randomForest. Available online: https://cran.r-project.org/web/packages/randomForest/index.html (accessed on 19 August 2019).
- Li, C. Probability Estimation in Random Forests. Master’s Thesis, Department of Mathematics and Statistics, Utah State University, Logan, UT, USA, 2013. [Google Scholar]
- Demuth, H.B.; Beale, M.H.; De Jess, O.; Hagan, M.T. Neural Network Design, 2nd ed.; Martin Hagan: Stillwater, OK, USA, 2014. [Google Scholar]
- R Package nnet. Available online: https://CRAN.R-project.org/package=nnet (accessed on 19 August 2019).
- Platt, J.C. Probabilistic Outputs for Support Vector Machines and Comparisons to Regularized Likelihood Methods. In Advances in Large Margin Classifiers; MIT Press: Cambridge, MA, USA, 1999; pp. 61–74. [Google Scholar]
- Lin, H.T.; Lin, C.J.; Weng, R.C. A note on Platt’s probabilistic outputs for support vector machines. Mach. Learn. 2007, 68, 267–276. [Google Scholar] [CrossRef]
- Hsu, C.W.; Lin, C.J. A comparison of methods for multiclass support vector machines. IEEE Trans. Neural Netw. 2002, 13, 415–425. [Google Scholar] [PubMed]
- Software Package Kernlab. Available online: https://CRAN.R-project.org/package=kernlab (accessed on 19 August 2019).
- Caputo, B.; Sim, K.; Furesjo, F.; Smola, A. Appearance-based object recognition using SVMs: Which kernel should I use? In Proceedings of the NIPS Workshop on Statistical Methods for Computational Experiments in Visual Processing and Computer Vision, Whistler, BC, Canada, 12–14 December 2002; Volume 2002. [Google Scholar]
- Karatzoglou, A.; Smola, A.; Hornik, K.; Zeileis, A. kernlab—An S4 package for kernel methods in R. J. Stat. Softw. 2004, 11, 1–20. [Google Scholar] [CrossRef]
- The Symbolic Regression Tool Rgp. Available online: http://www.rdocumentation.org/packages/rg (accessed on 19 August 2019).
- Sahoo, S.K.; Criswell, J.; Geigle, C.; Adve, V. Using likely invariants for automated software fault localization. In Proceedings of the 18th International Conference on Architectural Support for Programming Languages and Operating Systems, ASPLOS 2013, Houston, TX, USA, 16—20 March 2013; ACM SIGARCH Computer Architecture News. Volume 41, pp. 139–152. [Google Scholar]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Key Technology | Time Cost | Target |
|---|---|---|---|
| random mutation | simple random sampling | low | estimating program mutation score |
| mutant clustering | stratified sampling | low | estimating program mutation score |
| selective mutation | non-probability sampling | high | estimating program mutation score |
| predictive mutation | supervised learning | low | estimating program mutation score classifying mutants |
| Test Case | Program Output | Execution History | Branch Instances in Loop |
|---|---|---|---|
| m = 4, n = 1 | fac = 6, class 1 () | = {, , , , , }, = {, , } | |
| m = 2, n = 2 | fac = 1, class 2 () | , , , , , , , | |
| m = 1, n = 4 | fac = 6, class 1 () | = {, , , , , }, = {, , } |
| Statement Instance | Direct Impact Successors | Value Impact Set | Path Impact Set | Generalized Value Impact Set | Generalized Path Impact Set | Latent Impact Set |
|---|---|---|---|---|---|---|
| ⌀ | ⌀ | ⌀ | ⌀ | ⌀ | ||
| ⌀ | ⌀ | ⌀ | ||||
| ⌀ | ⌀ | ⌀ | ||||
| ⌀ | ⌀ | ⌀ | ⌀ | ⌀ | ||
| ⌀ | ⌀ | ⌀ | ⌀ | |||
| ⌀ | ⌀ | ⌀ | ||||
| , | ⌀ | |||||
| ⌀ | ⌀ | ⌀ | ||||
| , , | , , | , | ||||
| ⌀ | ||||||
| ⌀ | ⌀ | ⌀ | ||||
| ⌀ | ||||||
| , , | , , , | , | , | |||
| ⌀ | ⌀ | , , , | ||||
| ⌀, | ⌀ | ⌀ | ⌀ | ⌀ | ||
| ⌀, | ⌀ | ⌀ | ||||
| ⌀ | ⌀ | ⌀ | ||||
| ⌀ | ⌀ | ⌀ | ⌀ | ⌀ | ||
| ⌀ | ⌀ | ⌀ | ⌀ | |||
| , | ⌀ | |||||
| ⌀ | ⌀ | ⌀ | ||||
| ⌀ | ⌀ | ⌀ | ||||
| ⌀ | ⌀ | ⌀ | ⌀ | ⌀ | ||
| ⌀ | ⌀ | ⌀ | ||||
| ⌀ | ⌀ | ⌀ | ⌀ | ⌀ | ||
| ⌀ | ⌀ | ⌀ | ⌀ | |||
| ⌀ | ⌀ | ⌀ | ||||
| ⌀ | ⌀ | ⌀ | ⌀ | |||
| ⌀ | ⌀ | ⌀ | ⌀ | |||
| , , | ⌀ | |||||
| ⌀ | ⌀ | ⌀ | ⌀ | |||
| ⌀ | ⌀ | ⌀ | ⌀ | |||
| ⌀ | ⌀ | ⌀ | ⌀ | |||
| , , | , , | ⌀ | ||||
| ⌀ | ⌀ | , , |
| Statement instance | Value Impact Set | Path Impact Set | Generalized Value Impact Set | Generalized Path Impact Set | Latent Impact Set |
|---|---|---|---|---|---|
| ⌀ | , , | , | , , , ,, , , | , , | |
| , , , | , | , | |||
| , , , | ⌀ | , | |||
| , , | , | , | ⌀ | , | |
| ⌀ | , , , , , , | , | , , | ||
| , | , | ⌀ | |||
| , | , , , , | , | , , | ||
| , , | ⌀ | ⌀ | ⌀ | ⌀ | |
| ⌀ | , , | , , | ⌀ | , , | |
| ⌀ | ⌀ | ⌀ | ⌀ | ||
| ⌀ | , | , | ⌀ | , | |
| ⌀ | ⌀ | ⌀ | ⌀ | ||
| ⌀ | ⌀ | ⌀ | ⌀ |
| Statement | Value Impact Factor | Path Impact Factor | Generalized Value Impact Factor | Generalized Path Impact Factor | Latent Impact Factor |
|---|---|---|---|---|---|
| 0 | 3 | 2 | 8 | 3 | |
| 1 | 4 | 2 | 1 | 2 | |
| 1 | 4 | 1 | 0 | 2 | |
| 3 | 2 | 2 | 0 | 2 | |
| 0 | 7 | 2 | 1 | 3 | |
| 2 | 1 | 1 | 0 | 1 | |
| 2 | 5 | 3 | 1 | 3 | |
| 3 | 0 | 0 | 0 | 0 | |
| 0 | 3 | 3 | 0 | 3 | |
| 1 | 0 | 0 | 0 | 2 | |
| 0 | 2 | 2 | 0 | 2 | |
| 1 | 0 | 0 | 0 | 0 | |
| 1 | 0 | 0 | 0 | 0 |
| 3 | 1 | 2 | 3 | 7 | 4 | 4 | 3 | 3 | 1 | 2 | 1 | 1 |
| Ratio (fac = 6 class 1) | Ratio (fac = 1 class 2) | Information Hidden Factor | |
|---|---|---|---|
| 2/3 | 1/3 | − | |
| 1/1 | |||
| 1/2 | 1/2 | − | |
| 2/3 | 1/3 | − | |
| 2/3 | 1/3 | − | |
| 2/2 | |||
| 2/2 | |||
| 2/3 | 1/3 | − | |
| 2/3 | 1/3 | − | |
| 1/1 | |||
| 1/2 | 1/2 | − | |
| 1/1 | |||
| 1/1 |
| Mean | 0.1095 | 0.1062 | 0.1075 | 0.1016 | 0.0955 |
| 1 | |||||
| Mean | 0.0950 | 0.1090 | 0.1321 | 0.1374 | 0.1380 |
| Mean | 0.1381 | 0.1381 | 0.1381 | 0.1381 | 0.1381 |
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | |
|---|---|---|---|---|---|---|---|
| Mean | 0.1166 | 0.0923 | 0.0888 | 0.0897 | 0.0914 | 0.0928 | 0.0925 |
| 1 | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 0.1180 | 0.0984 | 0.0928 | 0.0968 | 0.1111 | 0.1397 | 0.1956 | 0.2419 | 0.2491 | 0.2499 | |
| 2 | 0.0915 | 0.0869 | 0.0883 | 0.0876 | 0.1104 | 0.1379 | 0.1889 | 0.2404 | 0.2489 | 0.2498 | |
| 3 | 0.0953 | 0.0890 | 0.0865 | 0.0867 | 0.1099 | 0.1371 | 0.1835 | 0.2390 | 0.2488 | 0.2498 | |
| 4 | 0.0897 | 0.0889 | 0.0863 | 0.0881 | 0.1094 | 0.1367 | 0.1791 | 0.2375 | 0.2486 | 0.2498 | |
| 5 | 0.0874 | 0.0890 | 0.0865 | 0.0880 | 0.1093 | 0.1366 | 0.1753 | 0.2361 | 0.2484 | 0.2498 | |
| 6 | 0.0881 | 0.0869 | 0.0865 | 0.0881 | 0.1093 | 0.1365 | 0.172 | 0.2348 | 0.2483 | 0.2498 | |
| 7 | 0.0896 | 0.0887 | 0.0862 | 0.0878 | 0.1093 | 0.1364 | 0.1694 | 0.2334 | 0.2481 | 0.2498 | |
| 8 | 0.0884 | 0.0878 | 0.0856 | 0.0882 | 0.1093 | 0.1364 | 0.1670 | 0.2321 | 0.2479 | 0.2497 | |
| 9 | 0.0884 | 0.0871 | 0.0869 | 0.0881 | 0.1093 | 0.1364 | 0.1649 | 0.2308 | 0.2478 | 0.2497 | |
| 10 | 0.0870 | 0.0880 | 0.0867 | 0.0878 | 0.1093 | 0.1365 | 0.1631 | 0.2295 | 0.2476 | 0.2497 | |
| Name | Expression | Parameter |
|---|---|---|
| linear kernel | ||
| polynomial kernel | , , d | |
| radial kernel |
| C | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Mean | 0.0984 | 0.0967 | 0.0933 | 0.0978 | 0.0978 | 0.0985 | 0.1004 | 0.1008 | 0.0997 | 0.1003 | 0.1002 |
| Generation | 3 | 6 | 9 | 12 | 15 | 18 |
|---|---|---|---|---|---|---|
| Mean | 0.1640 | 0.1546 | 0.1548 | 0.1504 | 0.1527 | 0.1515 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tan, L.; Gong, Y.; Wang, Y. A Model for Predicting Statement Mutation Scores. Mathematics 2019, 7, 778. https://doi.org/10.3390/math7090778
Tan L, Gong Y, Wang Y. A Model for Predicting Statement Mutation Scores. Mathematics. 2019; 7(9):778. https://doi.org/10.3390/math7090778
Chicago/Turabian StyleTan, Lili, Yunzhan Gong, and Yawen Wang. 2019. "A Model for Predicting Statement Mutation Scores" Mathematics 7, no. 9: 778. https://doi.org/10.3390/math7090778
APA StyleTan, L., Gong, Y., & Wang, Y. (2019). A Model for Predicting Statement Mutation Scores. Mathematics, 7(9), 778. https://doi.org/10.3390/math7090778