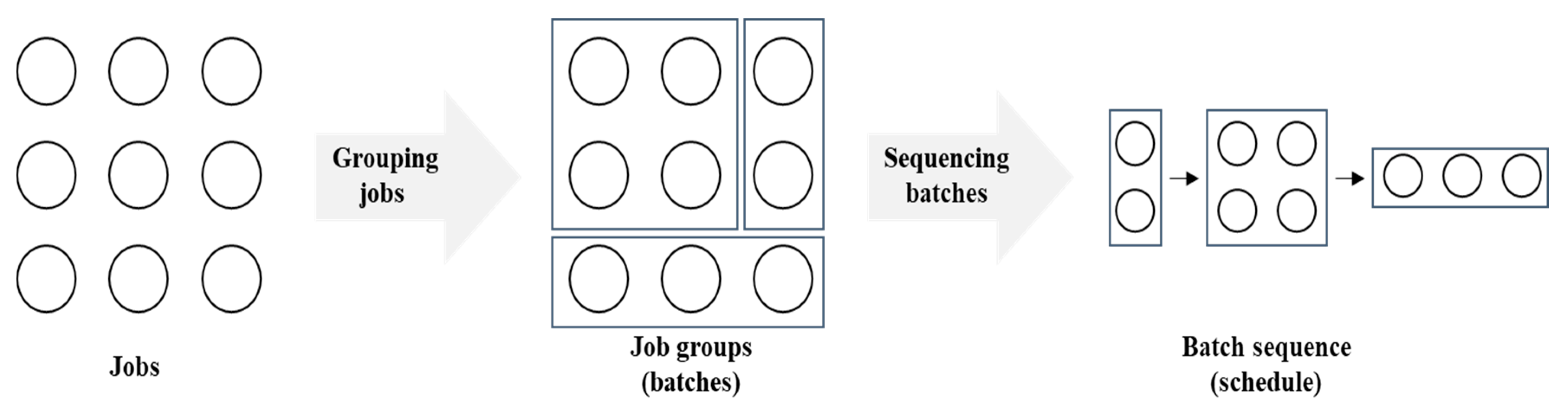
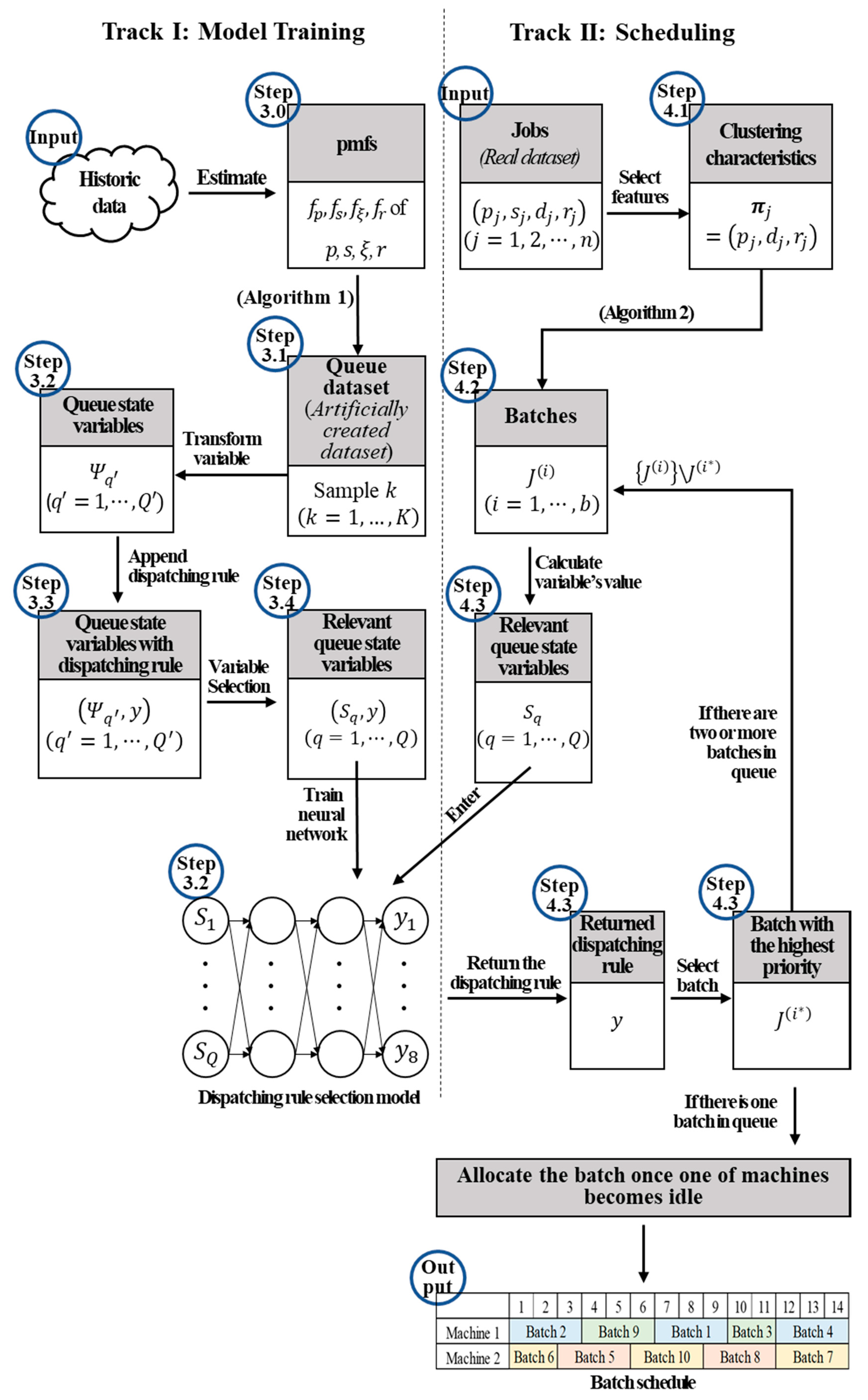
3.1. Generating the Training Dataset
In this subsection, we introduce the step-by-step method used to create a dataset from historic data of job characteristics. The probability distributions of each job characteristic are calculated, and samples are then created to form a virtual batch dataset. This dataset is then transformed to a more adequate format for training.
Step 3.0: Prepare the probability distributions of job characteristics.
First, the pmfs (probability mass functions)
,
,
, and
of processing time (
), size (s), slack time (
, and release time (r), respectively, are estimated from the historic data based on the relative frequencies as follows:
where
and
denote the number of jobs that satisfy
.
Step 3.1: Create batches in the queue dataset.
With the pmfs, total samples are generated where sample exhibits batches and each batch consists of one or more jobs characterized by job characteristics . Specifically, is arbitrarily picked in the interval , where . Next, the system’s clock time of sample should exceed any release times of jobs in the queue (). It also must be smaller than the maximum remaining processing time, and this is as follows. There are currently batches that remain in the queue, and thus it is inferred that batches are processed and the mean processing time of existing batches in the queue corresponds to . Therefore, is arbitrarily picked and satisfies .
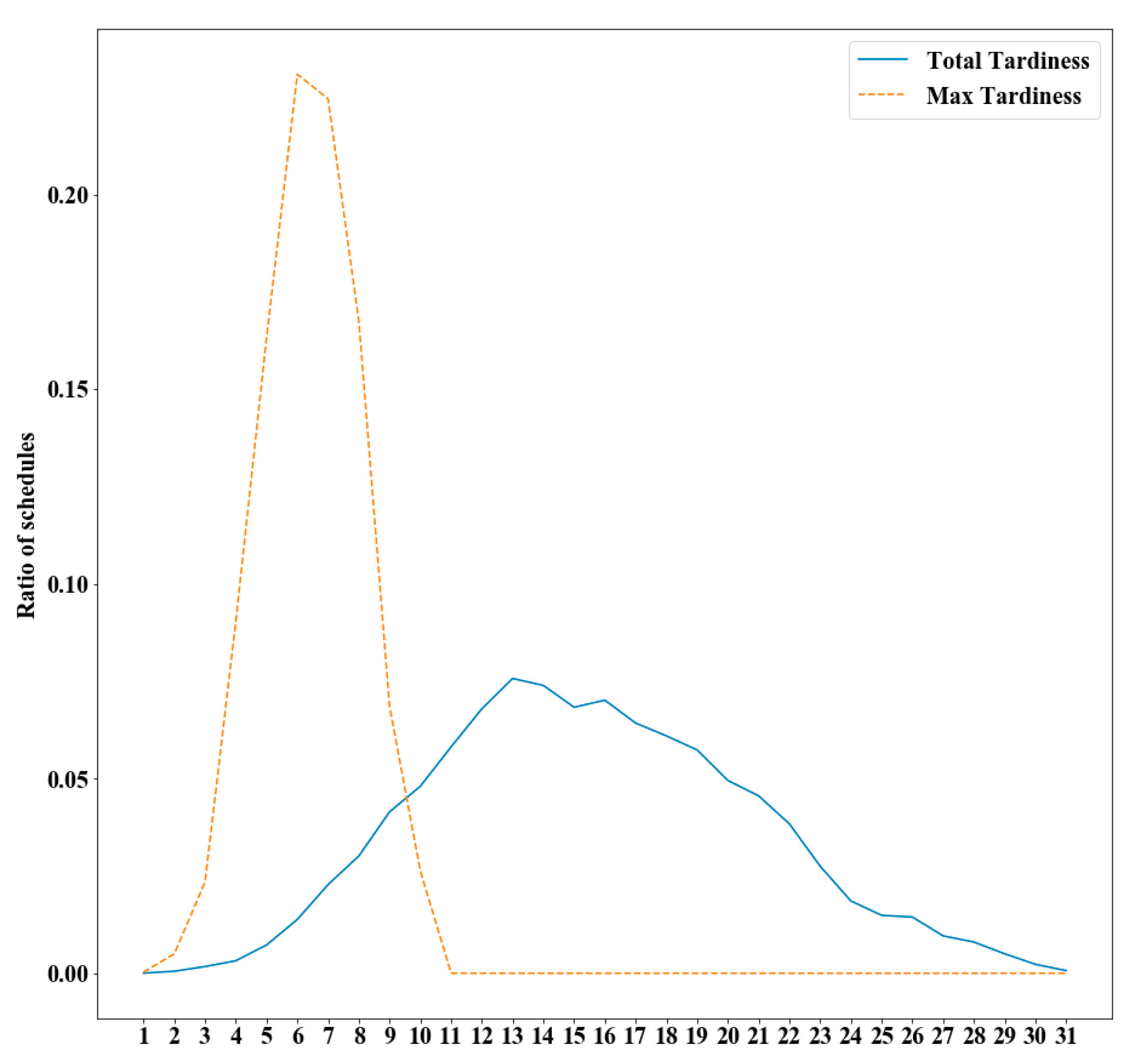
Figure 3 shows a typical example of a set of
samples generated from estimated pmfs. The set of artificial samples is termed as the queue dataset because the batches in each sample wait in the queue to be processed.
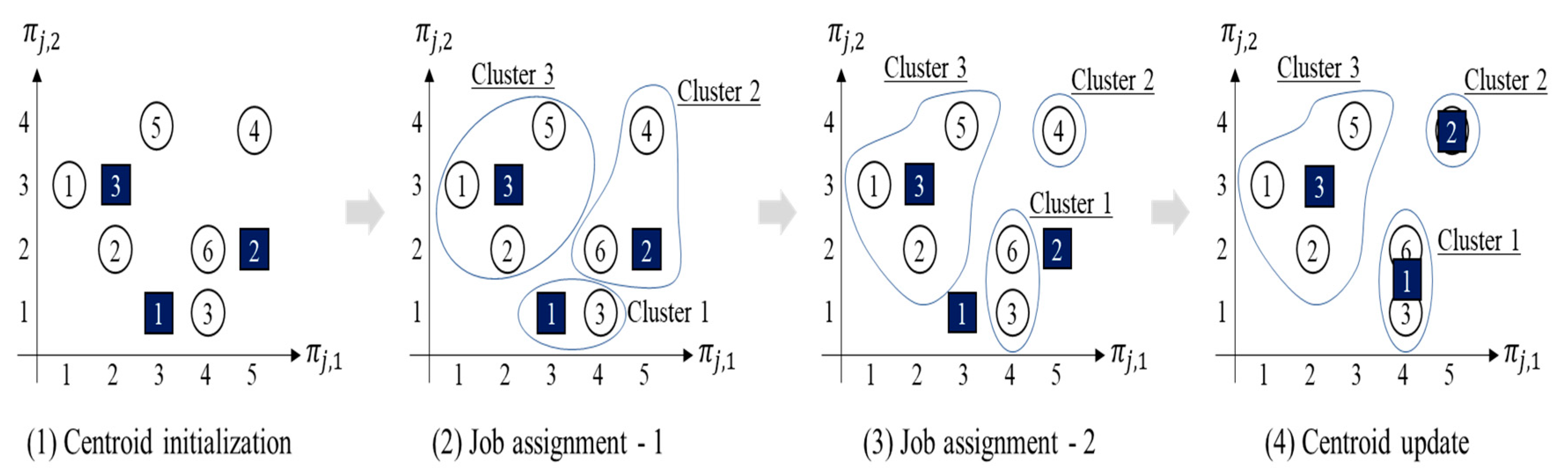
Note: It is necessary to exercise caution when more than one job is created in a batch. When a job is sampled, then the next job should be “similar” in terms of its job characteristics
to that previously sampled because batches contain “similar” jobs. This is performed by using the following conditional pmfs as follows:
where
denotes one of the variables
,
denotes the previously generated job’s characteristic,
denotes the number of clusters containing jobs satisfying
and
, and
denotes the number of clusters that contain at least one job wherein
corresponds to
.
Algorithm 1 shows the generation process of the queue dataset explained above.
| Algorithm 1. Queue dataset generation algorithm |
| Input | , , , , , , , , |
| Procedure | For ( to ) Do { |
| Select from at random |
| Initialize batch as an empty set for |
| For ( to ) Do { |
| job_size_sum = 0 |
| /* First job generation */ |
| , , , |
| |
| Append job 1 = (, , , ) to batch |
| Increase job_size_sum by |
| |
| /* job generation */ |
| While (True) Do { # while capacity constraint is satisfied |
| , , , |
| |
| If (job_size_sum + ) Do { |
| break} |
| Increase job_size_sum by |
| Append job = (, , , ) to batch |
| Increase by 1} |
| Append batch to sample in queue dataset} |
| is randomly selected from [, ]} |
| Output | Queue dataset |
Step 3.2: Transform the variables.
Each sample of the queue dataset contains the values of system time (
) and job characteristics (
). It is necessary to transform them into the values representing the status of batches in the queue, as this facilitates improved training for the machine learning model. We introduce queue state variables,
, with which the current status of the queue is well defined and contributes to determining the optimal dispatching rule [
3]. Queue state variables are defined by in extant studies [
3,
4,
8] as listed in
Table 1.
Variables to represent the batch state (e.g., number of batches and processing times of the batch) while to describe the job state (e.g., slack time of jobs). Moreover, the queue dataset consists of 21 queue state variables along with system time.
Step 3.3: Assign the optimal dispatching rule to each training sample.
This step determines the optimal dispatching rule
for sample
of the batches in the queue dataset. The dispatching rules in
Table 2 are considered.
We apply each rule to the batches in each queue dataset sample and then determine the optimal rule to minimize total tardiness. This is appended to each queue dataset sample and is used as a class label of the dispatching rule selection model.
Step 3.4: Select relevant queue state variables.
This step involves examining the queue state variables and removing those that are not relevant to the dispatching rule,
. The relevance of a queue state variable is calculated, and variables with high relevance are selected as inputs in the training. We adopt ANOVA’s (analysis of variance) F-statistics for class-relevance, as suggested by [
9]:
where the group denotes a set of samples with the same optimal dispatching rule.
Table 3 shows the structure of the queue dataset that is used as the training dataset for the dispatching rule, where
denotes a set of (selected) relevant queue state variables.
3.2. Model Training
We develop a machine learning model that uses the values of the queue state variables to determine the dispatching rule, from which the processing order of actual job batches is derived. We select the artificial neural network because it is widely used and has yielded reliable results in previous research [
10]. It should be noted that any type of classification model can be used in place of the neural network model.
Recall that, according to the steps of
Section 3.1, values of the queue state variables
are calculated from the generated dataset, and the optimal dispatching rule
is derived, which gives the minimum tardiness. We use the ANOVA to select the relevant queue state variables
, and then (
) composes one sample of the training dataset that will be an input to the neural network. Therefore, the neural network is trained against the dispatching rule for each given values of the queue state variables.
The neural network in our model exhibits an input layer, an output layer, and two hidden layers. Each node in the input layer corresponds to each queue state variable, and each node in the output layer matches the candidate dispatching rule. The number of nodes in the hidden layers are parameters that should be tuned. We test 45 models with nodes in each hidden layer , where and denote the number of nodes in the first and second hidden layers, respectively, and we select the parameters exhibiting the optimal performance with five-fold cross validation.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}