1. Introduction
It is known that computer processing is a mathematical (functional) transformation of a set of input data (
D) into output results (
R), summarized by a global function
f: D→
R. In this sense, computer data processing is a form of concrete realization of a complex mathematical function in an environment of hardware and software tools and means in different versions—traditional, parallel [
1], real-time [
2], learning scheduling [
3], etc. Regardless of the computer environment realization, the organization of computer processes covers two hierarchical levels related to its program management at a high (macro) level and its machine implementation at low (micro) level. The micro-level presents the organization of elementary operations for machine calculations generated by firmware (concrete sequence of microinstructions from the activated microprogram). An approach for organization of low-level model investigation is discussed in [
4], proposing a unified framework for the joint conduct of the classification process and the modelling. The goal is to ensure the effectiveness of model investigation on a micro level (firmware). The firmware analysis permits the determination of correct functionality of processing at the micro level, with the generalized approach being presented in [
5], which is directed to identification of firmware modules, its extraction, disassembling, modification, and reprogramming. This approach is particularly relevant in the development of embedded devices for the purpose of the Internet of things (IoT). In this respect, a software technological framework for the continuous execution of binary firmware together with independent testing is proposed in [
6], which is not affected by the peripherals (without ignoring them) and processes the input–output data for the firmware on the basis of automatically generated models. An evaluation of this framework is made and good assessment for the effectiveness is obtained. Another actual example of the importance of the investigation of the processing in micro-level (firmware) is the proposed in the method of [
7] for security analysis of a memory, which stores micro algorithms for 3G modem control. Testing the method for different versions of the modem has shown good results.
The macro level (as opposite of micro level) in general is a sequence of separate (generally independent) procedures for data stream processing, which are realized by activation of separate algorithms integrated in the frame of symbolic general algorithm, conditionally marked as A
G. In both cases, the organization of the processes at each of the two levels is subject to probabilistic parameters and conditions in the computer environment [
8]. Formally, from the point of view of formalization, any investigation of processes at the macro level and communications between them is subject to a defined procedure. In this aspect, a generalized scheme of a procedure for analysis and optimization of complex-structured objects during the modelling and algorithms is proposed in [
9]. Numerical methods and algorithms for finding the optimal solution are used. Analysis of the features of the management process is carried out to increase the efficiency of using these components of the analyzed system.
The research of information processing in the processes of program module design at a high (macro) level has different applications due to the modern architectures, including distributed computer systems. One of the directions is the formalization of the relationship between the two levels—micro and macro—with the article in [
10] proposing an abstract basis for field calculations, which contain several syntactic constructions, and the relationship with the micro level (actions of individual devices and their interaction when performing collective processing) is analyzed. The goal is to facilitate the design of a user interface (API—Application Program Interface) in complex software systems.
Another direction for the application of the analysis of high-level programming processes is the automatic correction of programs, which must ensure reliable implementation of the applied actions through the use of modern tools. In this sense, the study in [
11] discusses the problem of locating faults in program codes at the macro level and interactions between programs, including their impact on automatic correction systems. The goal is to analyze the activated procedures, the possibilities for error correction, and the reliable investigation of system performance parameters through analysis at the macro level. The practical use of formal techniques for analysis is discussed in [
12], where a pragmatic application of formal method technologies is a purpose of the research. This formal analysis was focused on the controller components of the software implementation for error management and the logic was analyzed by using a technique of model investigation. This helped to analyze the possible situation of a risk and for verification of risk control measures relating to the software components.
The relationships between different software entities can be used for evaluation of the quality of a program, which determines the importance of the tools for computation of their metrics. In this respect, a classification (made by a systematic literature review in software engineering) of the different kinds of coupling relations, together with the metrics to measure them, is presented in [
13]. The result of this research is a proposal of suitable tools for software engineering for extracting program metrics united in four groups—structural, dynamic, semantic, and logical. As an addition, this research retrieves tools that extract the metrics belonging to each coupling group. The problem of object monitoring, including software components, is an important one in the processes of relationship evaluation. The communication time between software objects is a critical parameter and is subject to minimization. A set of procedures for effective communication between territorially connected systems is proposed in [
14] and an analysis of the effectiveness is made.
One of the applied approaches for investigation of computer processes is mathematical modelling by using formalized descriptions of the investigated object through abstract language (mathematical formal system) or through mathematical relations describing functional behavior. This approach is applicable in different areas—for example, an application in the field of complex electronic systems for various purpose is discussed in [
15]. The article proposes a hierarchical method of mathematical and computer modelling of interval-stochastic thermal processes that take into account various physical phenomena in in the considered systems. Different mathematical means can be used for their creation (algebraic, differential, and integral calculus; theoretical systems; etc.). The research presented in [
15] is realized by systems of stochastic, unsteady, and nonlinear partial differential equations, and their computer simulation is made by using supercomputer. Another approach is applied in [
16], when “
a new rumour spreading model in social networks” is proposed that was realized by using discrete mathematical modelling. An optimal control strategy to fight against the spread of the rumor is recommended in the article. Five different perspectives on mathematical modelling are reviewed in [
17] because, according to the authors, “
there is not a single agreed-on-definition of what mathematical modelling is or how it should be done”. The classification discussed in the article is directed to “
realistic modelling, educational modelling, models and modelling perspective, socio-critical modelling, and epistemological modelling”. Finally, a statistical approach for mathematical modelling or solving the problem with minimization of the search time for the necessary information is proposed in [
18].
Computer modelling is mathematical modelling in which computer tools are used to create the model and to conduct experiments with it. Mine principles of computer modelling are discussed in [
19] and a formal technological scheme for investigation by modelling is proposed. The basic phases of this process are determined: (a) preliminary functional decomposition of the modelled object and a conceptual model formulation, (b) mathematical formalization of structure and relations based on the conceptual model, (c) defining of the functional algorithm, (d) design of the mathematical model, (e) realization of a program model in suitable software system, and (f) organization of experiments with results analysis and conclusions. In addition, a hierarchical procedure for evaluation based on obtained results from modelling with three levels (empirical, analytical, and evaluation) is proposed.
Different language tools (universal and specialized) can be used to create a program model, with thousands of languages having been developed for various applications. In this regard, article [
20] proposes an overview of the set of modelling languages, specifically in Industry 4.0. On the basis of this extensive review, the researchers updated the systematic mapping study of modelling languages and modelling techniques. A total of 408 relevant publications were identified on the basis of the study of 3344 candidate publications. One of the article’s goals was to determine the modelling languages in system engineering and knowledge representation. The program language, which can be used for mathematical formal description and model preparation in the area of computing, is APL2 (Array Program Language), which allows for the creation of additional user workspaces with models formed as a separate function or as sequentially called functions. Each defined function (enclosed by symbol ∇) can be executed independently or when calling from another function. Each function has its own definition (header part), which contains its name and its possible arguments (variables), through which data can be exchanged with other functions. There are rules for defining (explicitly or implicitly) local and global variables. Three basic components are connected with the loading—definition of virtual vector (array) for storing items, definition of a relative storage address where the array could be stored, and definition of the virtual distance between subsequent elements [
21].
The investigation of processes in data processing is essential for improving the overall organization, both at the macro level and at the low (micro) level. This would allow pre-ensuring the effectiveness of the software and firmware, which is important to minimize the time parameters of execution and communications. The task of ensuring efficient processing is relevant in today’s digital age due to the increased amount of processed data and communications between programs, including cloud computing, Internet of things, and big data analytics. In this respect, the article presents an approach for automation of the process interactions on a macro level on the basis of mathematical description and software realization. A technological scheme of the formal procedure for investigation is proposed. Three phases form the core of this procedure on the basis of which the investigation was conducted—mathematical formalization, mathematical description, and program realization. As a result of their implementation, we performed the following: (1) defining an initial conceptual model by using graph theory, (2) producing a deterministic mathematical formalization for analytical description of the proposed graph scheme and its transformation into an ordered structure, and (3) program realization of the developed mathematical models in the software system TryAPL2 by using the program language APL2. The aim was to propose a formal mathematical approach and tool for evaluation of characteristics of macro-level computer processing. The proposed models are part of a generalized environment for program investigation of the computer processing organization at macro and micro levels.
2. Materials and Methods
The main essence of a model study is to replace the original object Ω
O with another object-model Ω
M through which the properties or behavior in certain situations of the original are studied by experimenting with the model [
22].
The object-original ΩO can be an arbitrary system or process that may not actually exist. Nevertheless, its system properties can be described by finite sets, such as SO—system parameters characterizing the internal state of the real system, its structure, and functioning; YO—quantitative characteristics of system parameters, describing mainly resultant behavioral features that are important in the interaction with other systems; and XO—external actions influencing the behavior of system parameters. In this way, a formal representation of the object-original as a class of finite discrete sets ΩO = {SO, YO, XO} can be made. The peculiarity is that the main sets in the formed class may be too large, which will require the selection of adequate subsets. In this reason, when studying a system, a subset {yo} ∊ YO is usually chosen to be analyzed under the influence of external factors {xo} ∊ XO, and each individual characteristic yoi (i = 1 ÷ K, where K is the total number of elements in the subset of individual characteristics) depends on some subset {so} ∊ SO of system parameters (usually the influence of the other parameters is neglected). This subset of selected system parameters determines the spice of the system, and the characteristics are the data describing its organization and behavior according to the goal of the research. In this sense, each object of study should be considered as a complex of two related parts—static (independent of time) and dynamic (system parameters and characteristics that depend on time).
The object-model ΩM must reproduce with sufficient accuracy the real object under study, being in accordance with the selected goal of the concrete research. The model should comply with the selected conditions for the analysis of the behavior of the original system or process. This determines the need to coordinate the subsets of the class ΩO with appropriate components used for realization of ΩM. In the concrete case, this coordination requires correct transformation of the selected subset in mathematically presented subsets for the model realization. As a result, the following components can be defined: {sm} ∊ SM—parameters of the object-model, {ym} ∊ YM—characteristics of the object-model, and {xm} ∊ XM—external factors of influence for the object-model. The replacement ΩO→ΩM is admissible if the determined model characteristics {ym} ∊ YM sufficiently reflect the respective quantitative characteristics {yo} ∊ YO, defined in the modelling process. In this sense, the modelling is a replacement of a real functional dependence {yo} = ΦO[{so}, {xo}, To], describing the behavior of the original object in time, with a corresponding equivalent dependence {ym} = ΦM[{sm}, {xm}, Tm], where usually the model time Tm is related to the real time To by scaling. The main requirement in modelling is to find such an analytical dependence that describes with sufficient accuracy the behavior of the original in terms of the objectives of the study.
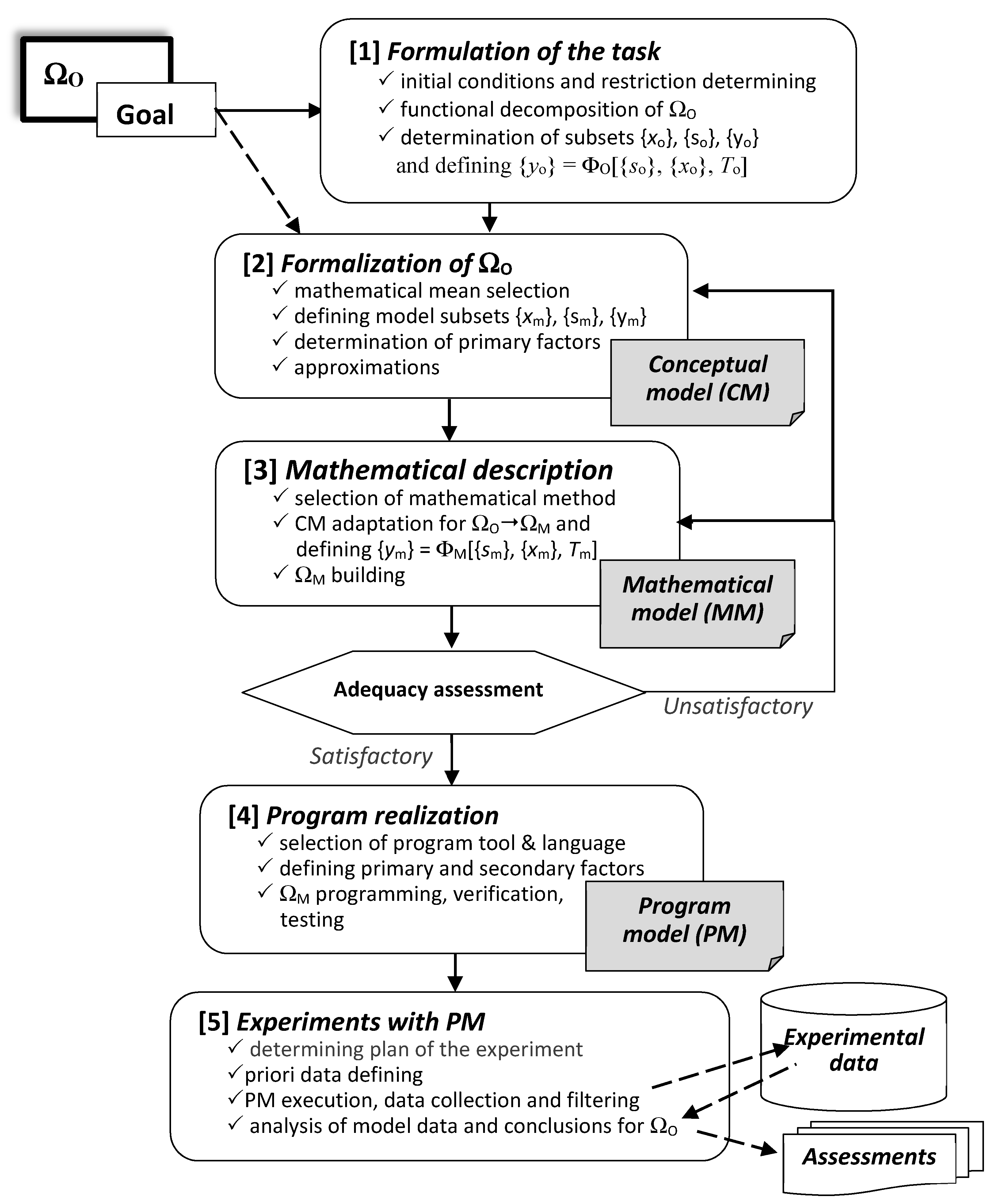
A summary of the information above is made by the formalized scheme of model investigation presented in
Figure 1.
The model investigation is related to three basic phases, realizing the successive components of a computer model (conceptual model (CM), mathematical model (MM), program model (PM)) on the basis of mathematical formalization, mathematical description, and program realization of the designed mathematical model in a program source using a suitable software environment. The phase of mathematical formalization is an initial stage, allowing us to make an adequate transition from the formulated task to achieve the goal in the investigation of the object-original (ΩO) to the actual development of a mathematical model (ΩM). The phase of mathematical description is the basic stage in the investigation because it must build a sufficiently adequate model of the real object (process or system). This requires an appropriate mathematical environment to be selected (formal, deterministic, probabilistic, empirical, etc.). The third phase of program realization transforms the mathematical description into a suitable software environment and creates the final result of the modelling, which will be subjected to experiments. A large number of program languages (universal and specialized) can be used to develop the program model, but the choice must take into account the type of mathematical description (ΩM) and the nature of the model investigation—deterministic, probabilistic, simulation, statistical, or heterogeneous. A good opportunity is provided by the APL2 language and the TryAPL2 operating environment, which is relevant to the deterministic model investigation of computer process organization presented in the following sections.
APL is a high-level program language that is suitable for analytical descriptions and for working with vectors and matrices. There is a possibility for parallel execution of several operations, which surpasses in these respects many of the modern universal algorithmic languages. Characteristic features are the specific alphabet, the maintenance of various data structures, the ability to work in dialog and program mode, a wide range of mathematical operations, and the possibility for laconic expression of complex transformations through composite operators. The order of operations in the expressions is from right to left. It is suitable for expressing the subordination between the different parts of the algorithm, allowing parallel execution of several operations. In a sequence of included functions, a variable, determined by a value in an external function, remains with the same value in the internal functions if it is not re-defined in them. The last specified value is actual. The functions use labels interpreted as local, and it is possible to apply recursive calculation.
The language version of APL2, implemented in the TryAPL2 operating environment, allows the creation of additional user workspaces from models formed as a separate function or as sequentially called functions. The function (enclosed by the symbol ∇) can be performed independently or when it is called by another function. Each function has its own definition (header part), which contains its name and its possible arguments (variables), through which data can be exchanged with other functions. There are rules for defining (explicitly or implicitly) local and global variables. A function is executed by calling its name, which can be done on its own in an expression or in the body of another function. Execution requires that the arguments (if any) be real variables or constants. In the environment, system variables and functions with reserved name names (starting with the symbol □) are maintained and used. The organization of work is performed through system commands that serve to manage the work session, store and edit copies of workspaces, and transfer data from one working space to another (file exchange management).
An illustration of the applicability of APL2 in deterministic model investigation is made in
Figure 2, which is a program description of a formalized functionality of an idealized computing environment supporting traditional processing in a processor (intensity
f1 and number of tasks
N1) and
k calls to external memory (intensity
f2 and number of tasks
N2). It is accepted that
N =
N1 +
N2 =
const; the task falls in the processor to (
k + 1); and the bandwidth
p coincides with the intensity for falling
f0 into a passive state, which allows for the presentation of the following simple analytical dependences:
To solve the mathematical model, it is necessary to determine the intensity f1(N1), which is based on the following: (a) there is zero intensity for the CPU (Central Processor Unit) load when it does not process a task (N1 = 0), for example, due to an infinitely long time for servicing the tasks in state S2; (b) the service is performed only in one processor and if number of tasks is N1 ≥ 1, the analytical dependence f1(N1 ≥ 1) = const will be saturated and limited to maximum bandwidth (k + 1)/t; (c) to solve the situation 0 < N1 < 1, it is necessary to know f2(N2), which is usually a nonlinear dependence.
The following analytical description can be provided as a result:
The program model is defined as a separate function WORKLOAD for calculating
f1(
N1) and
p, requiring the presentation of of the controllable model parameters (T—fixed processing time for processor, K—number of external memory access). To construct a functional dependence, successive experiments are performed according to a randomized factor plan, for example at values N = 5; T = 10; K = 2, 3, 4, 5. The results of execution of the function at a fixed value for K = 4 and different values (0; 0.2; 0.4; 0.6; 0.8; 1; 2; 4) of the argument N1 are graphically presented in
Figure 2c.
3. Mathematical Formalization and Model Construction
In the general case, computer processing can be determined as a set of sequentially executed procedures over data streams. The procedures are implemented on the base of a corresponding algorithm Aj, which can be considered as components of a global functional algorithm AG. Theoretically, the complete algorithm AG can be described logically if the individual algorithms Aj and the conditions for their activation at a specific input information flow are known. This undermines its formal description by a directed graph representing a graph scheme of algorithm (GSA), in which the matrix of connections {cij} describes the existence of an information connection Ai→Aj between two individual algorithms. In an investigation of the computer processes organization, it is possible to apply both approaches—stochastic (if the relationships are defined as probabilities) or deterministic (the matrix of relationships is Boolean).
3.1. Mathematical Formalization
A preliminary formalization of the investigated object Ω
O is made on the basis of the requirement of the phase [
2] of the general technological procedure presented in
Figure 1. In the current case, the object Ω
O of model investigation is a global algorithm
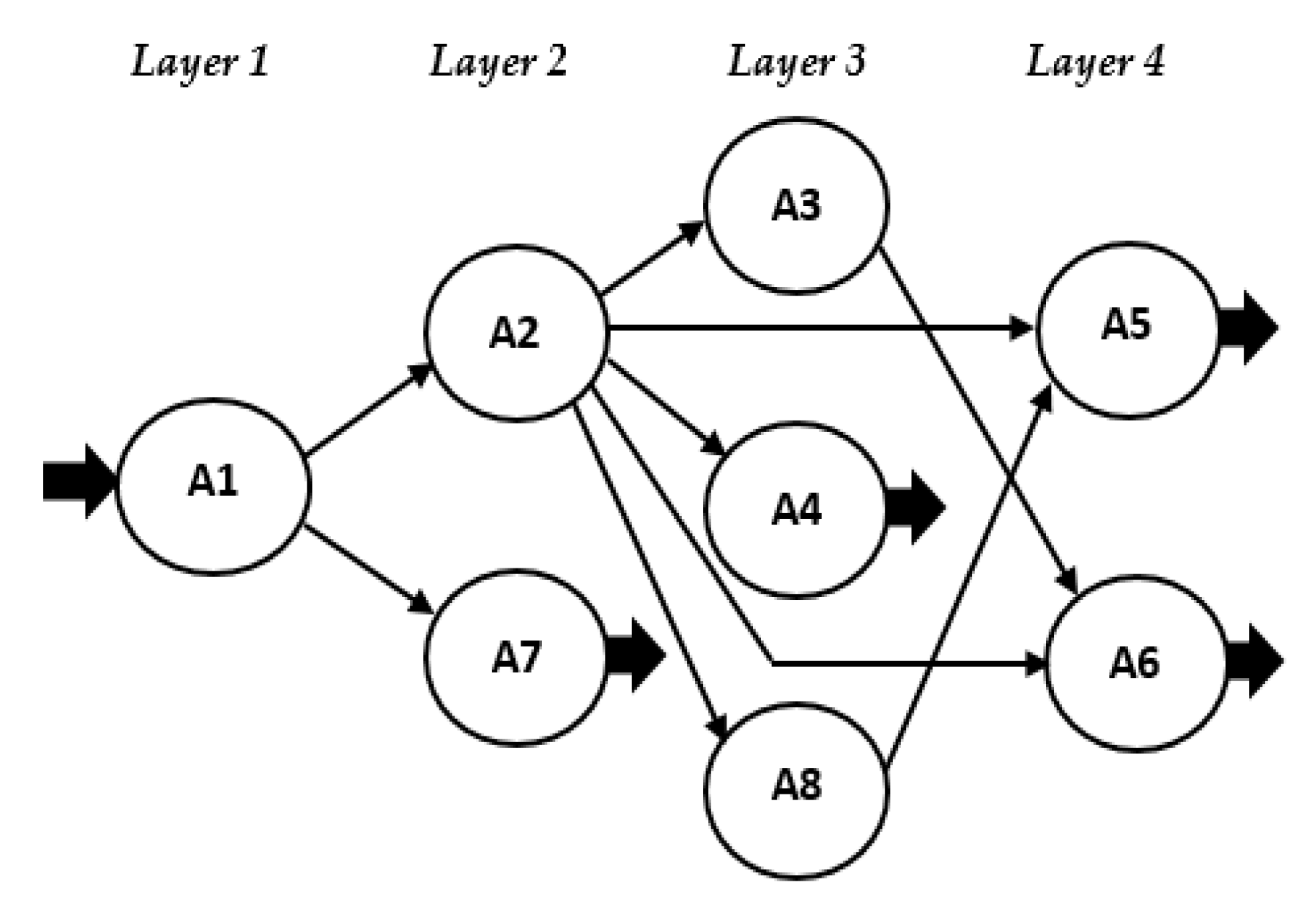
AG of exemplary computer processing presented as a GSA (
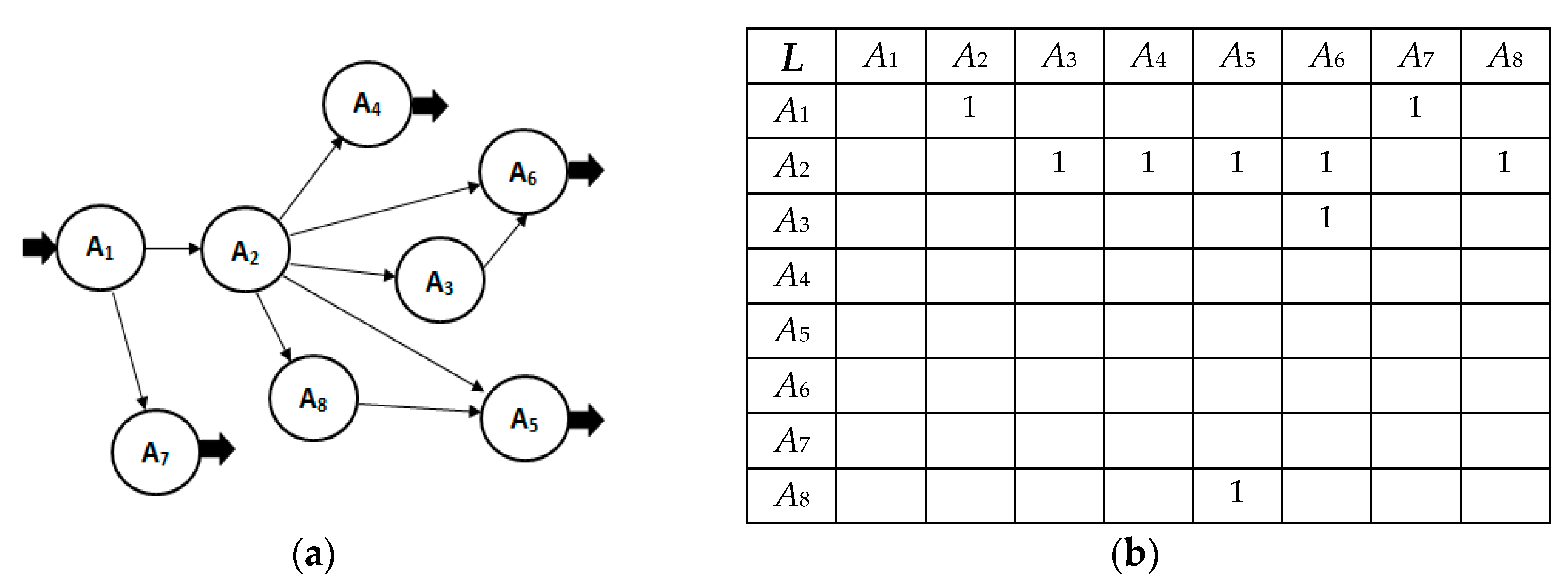
Figure 3a). It is a generalized structure of communicating program modules, each of which can be activated by another, depending on the development of the generalized process. In practice, the interactions between different modules and the possible activations of a concrete sequence of them is a probabilistic process, but the task determined for the research allows a deterministic approach to be applied. In this case, the goal is to determine the number and lengths of all possible paths representing the possible realizations of information processing.
In the deterministic approach, a Boolean matrix of connections
L = {
lij} is applied, where
lij = 1 (if there is a connection) and
lij = 0 (in the absence of a connection), as seen in
Figure 3b.
The formalization will allow for the construction of a conceptual model (CM) for the model investigation organization, which will formulate the basis for the next mathematical descriptions and the creation of a mathematical model (MM—phase [
3] in the
Figure 1) on the basis of a graph structure
G(
A,
L).
The object of the investigation is a set of independent algorithms (processes), presented as a final discrete set
A = {
A1,…,An}, which are executed in different sequences with possible input/output interactions. This allows for the determination of a tree of relations between sequential processes in GSA on the basis of the consequence matrix
L—
lij:
Ai→
Aj (
i,j ∊ {1,2,…,
n}), as shown in
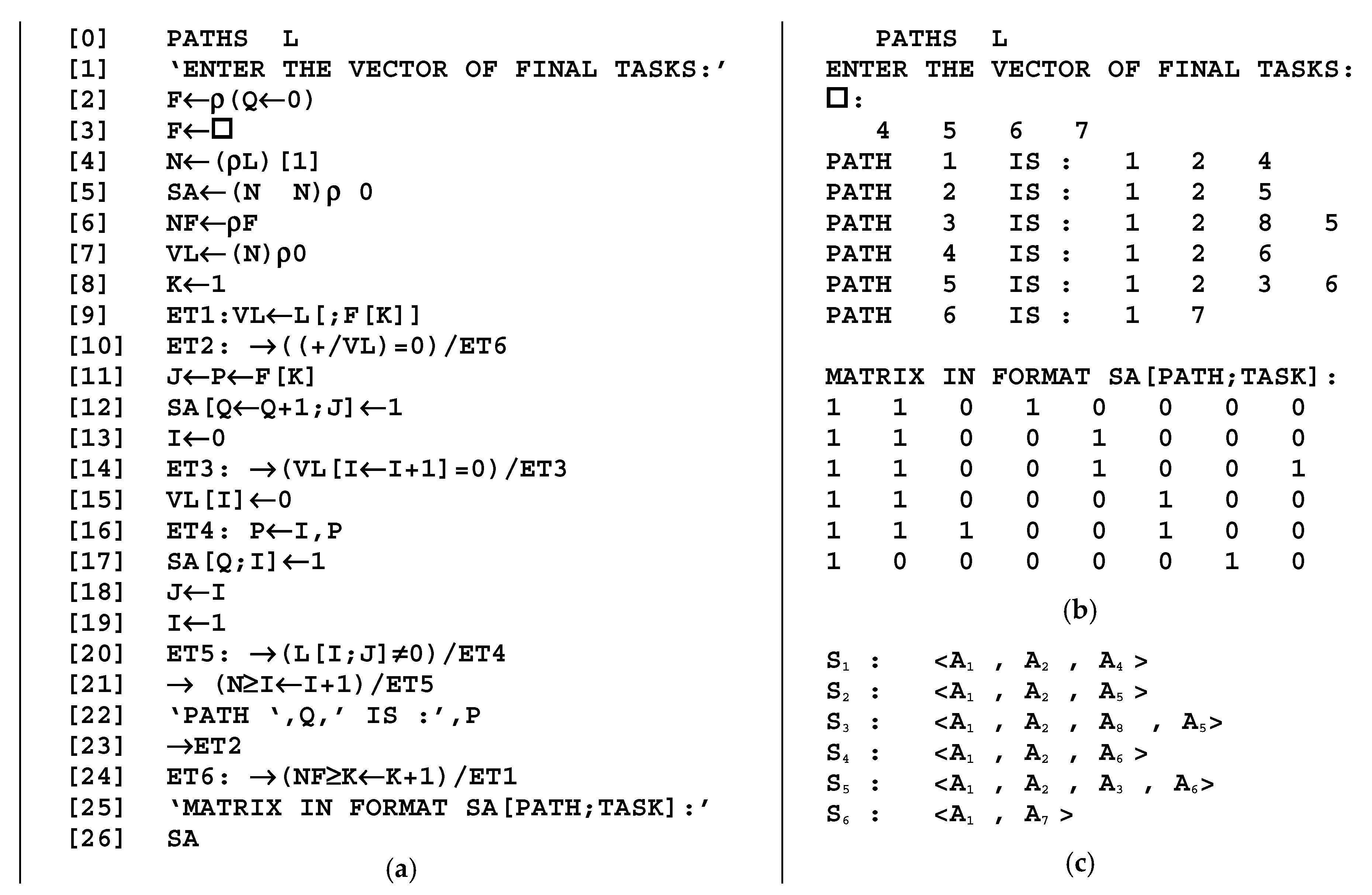
Figure 3b. Usually, the investigation is connected with determining the reachability of a given final task (algorithm) from one or several initial tasks. For this purpose, a system of algebraic equations is compiled, describing the presence of edges
aij between individual algorithms
Ai and
Aj:
Solving this system of equations allows for the construction of all directed paths, as well as for the determination of the equivalent paths that lead to the same event in computer processing. The dependence presented above allows to define a graph model (GSA) of the complete processing algorithm
G(α
A), which will be transformed in an ordered GSA (OGSA) with nodes numbered on the basis of the following condition:
The ordering forms layers of information-independent nodes so that (a) the nodes of the first layer have no predecessors and the nodes of the last layer have no successors, and (b) the nodes included in a common layer have no connecting arcs. The rules for the OGSA formation are as follows:
All initial nodes (without predecessors) are numbered first and included in layer (1).
A node is numbered and included in the current layer if all its predecessors are already numbered (included in previous determined layers).
Nodes to be numbered are successors of already numbered nodes.
3.2. Deterministic Mathematical Description
The phase 3 of the procedure shown in
Figure 1 recommends making a transition from the formal model to a mathematical description. On the basis of the chosen approach for deterministic mathematical description, we can make the construction of the model Ω
M on the basis of the following steps.
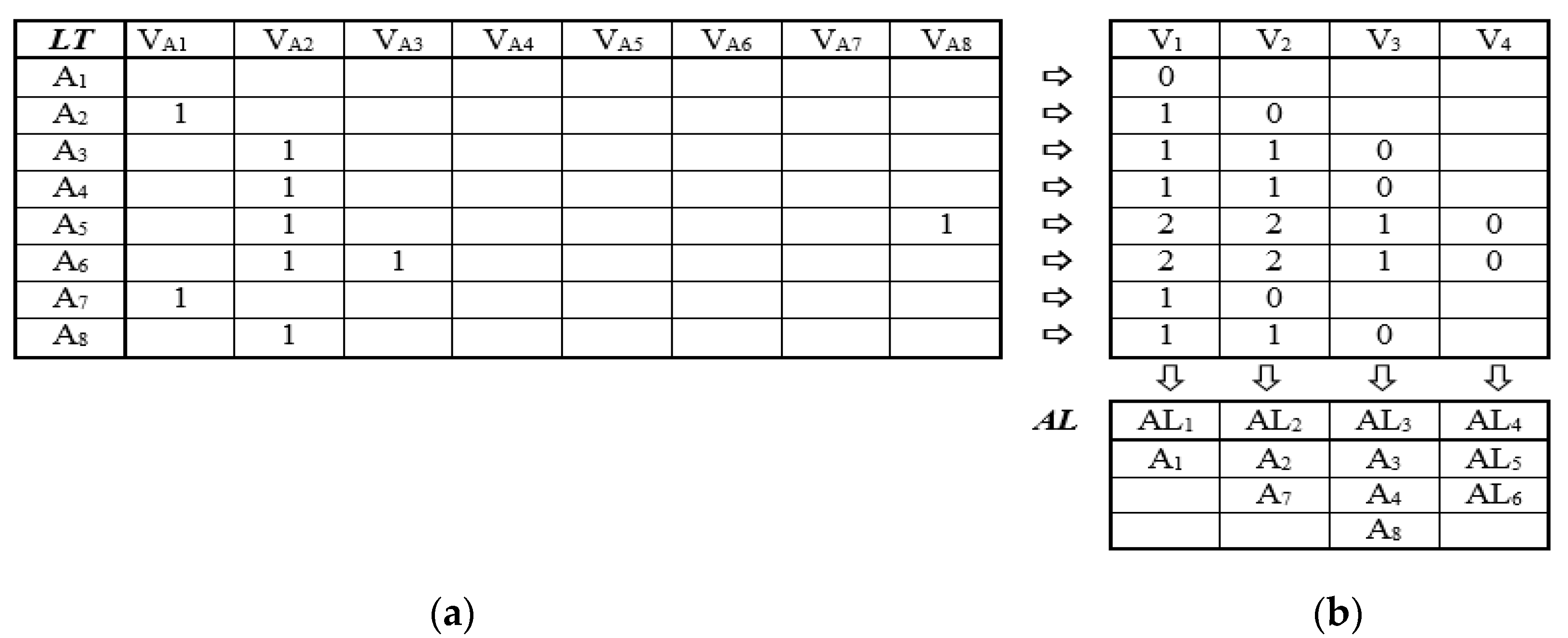
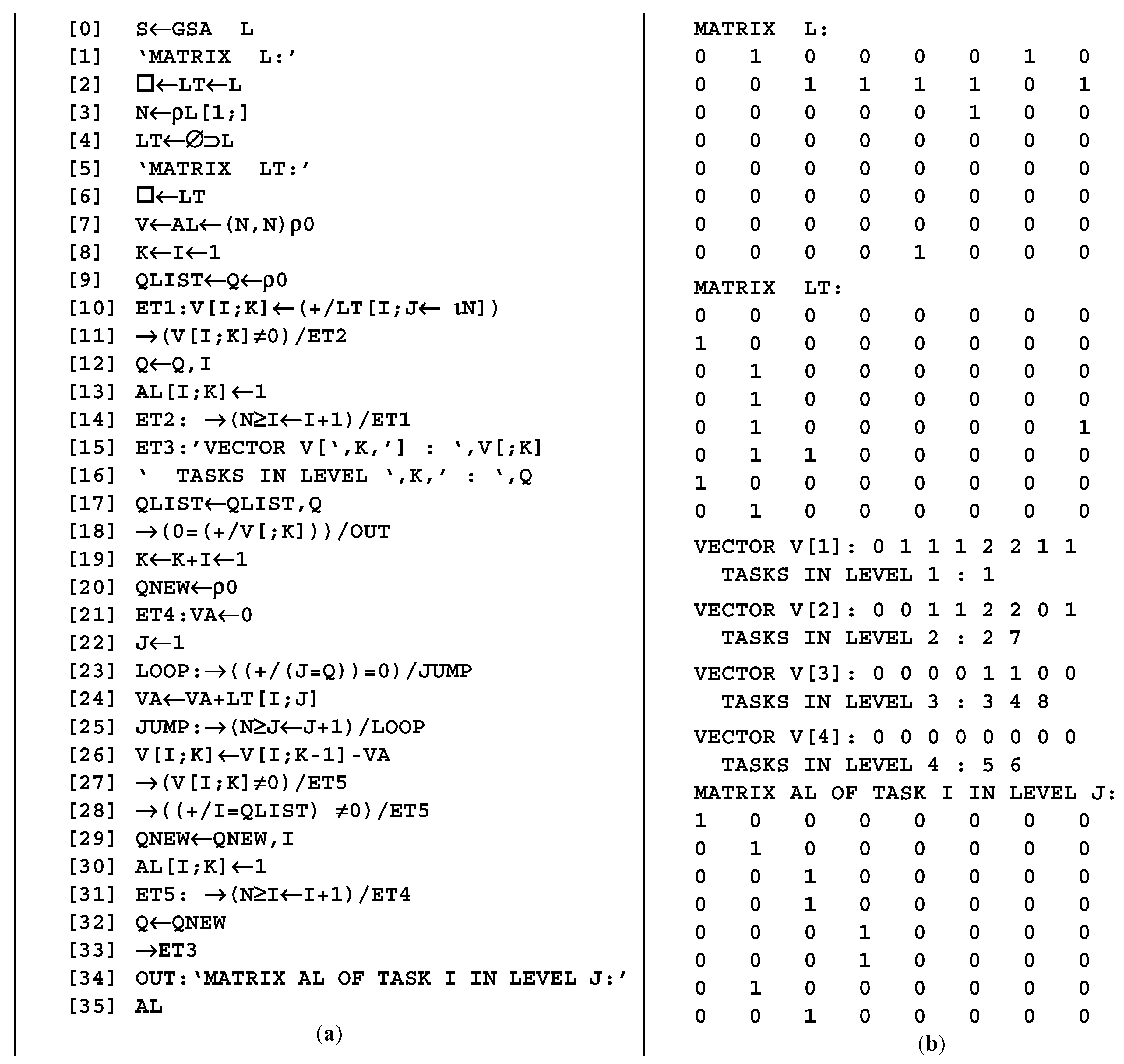
Step 1. Formation of a transposed matrix
LT by transforming the initial
L, where the columns are vectors
VAj, describing the successors of each node, fulfilling the condition
LT[
i,j] ≠ 0 (
j = 1 ÷
n), shown in
Figure 4a. This can be realized by constructions LT←L & N←ρL [1;] and LT←⌀⊃L.
Step 2. Calculation of the elements of a new vector
V1 = ∑ VAj (
j = 1 ÷
n;
n = 8) from
LT:
If
V1[
j] = 0 ⇒
Aj ∊
Layer(1
), node
Aj must be included in the layer (1), which is marked in the matrix of layers
AL. In this case, it is only
V1[
1] = 0, which determines that the algorithm
A1 must be included in
Layer(1) (see column
AL1 in
Figure 4b).
Step 3. Calculation of elements of the next vector
V2 on the basis of vector
V1 and row
j of
LT:
Elements
V2[
j] = 0 determine algorithms included in the
Layer(2)—in our case, algorithms
A2 and
A7, column
AL2 in
Figure 4b.
Steps 4, 5, etc. Similar calculation of the next vectors
Vq (q = 3, 4, ...) to determine algorithms included in the
Layer(
q):
For each layer “q”, an added element is marked by AL[j,q] = 1. The steps are performed to obtain a vector with only zero elements ∀Vq[j] = 0 (j= 1 ÷ n).
The result of applying all steps of the procedure is the distribution of the analyzed processes into separate ranks and defining the complete set of final processes (algorithms).
3.3. Possibility for Application of Formalization in Process Dispatching
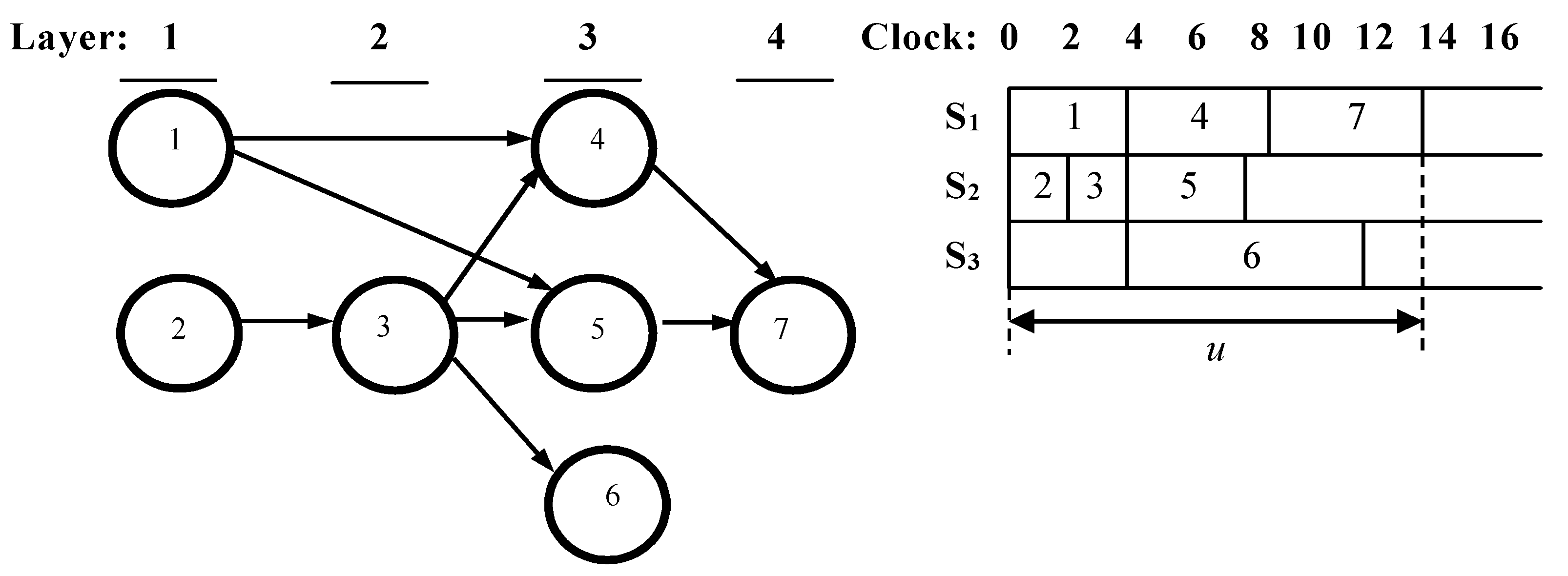
An example of the proposed approach can be made by extension of the mathematical formalization in the direction of dispatching independent processes in a closed system S for which the processes of the set A do not require additional resources beyond it. It is accepted that the time vector T = {t1, …, tn} for realization of processes Ai (i = 1 ÷ n) is known. If the system of resources has a heterogeneous nature, it is possible for a given process Ai to occupy several devices in succession, staying in each for different times {ti1, ti2, …, tik}. Then, ti = ∑tik and the vector T can be modified in a matrix T* = {tij} with n = |A| rows and m = |S| columns. This will allow for the formalization of the process of creating a dispatching plan for the analyzed processes in the system, which can be presented as a ordered discrete structure p = <S, A, G, T, F>, where S is a set of system resources with |S| = m, A is a final discrete partially ordered set of processes in the environment S with |A| = n, G(A,L) is a directed graph for describing GSA of the processes from set A, T = {t1, …, tn} presents the vector of execution times for all processes in the environment, and F determines a formal criteria (strategy) for process dispatching.
This formalization allows for the presentation of the dispatching as a function D(t) = {d1(t), …, dm(t)} defined in the interval (0, τ) and accepting integer values from the set of indices (1, 2, …, n) of A. Thus, the elements di(t) = j (1 ≤ i ≤ m; 1 ≤ j ≤ n) of the function D will represent the occupation of a resource Si in the moment t during the execution of process Aj.
When defining a static parallel plan, it is usually assumed that the GSA does not take into account the logical connections, but only the information dependence on data transmission. This is mainly related to the requirement to minimize the total execution time of the set A in a fixed structure S. In this case, the nodes of GSA determine times for realization of the processes. An example for application of this approach for formalization is presented in the next section.
5. Conclusions
This article discusses problems related to the mathematical formalization of objects, processes, and structures in the computer field for the purposes of research, analysis, and evaluation of parameters of information services. The proposed approach allows automation of the evaluation of certain characteristics of computer processing, presented as a sequence of relatively independent processes. To solve the set goals, we proposed a formalized technological procedure for mathematical model investigation, which had a sufficiently wide field of application, both in studying the implementation of complex software environments and in dispatching various independent processes (homogeneous and heterogeneous). In particular, the basis of the carried out investigation included two main parts—developing an approach for transforming a graph-formalized scheme of structure of algorithms (processes) and automation of the determination of possible sequences of executed processes (all paths in the ordered graph scheme). This allowed for the analysis of selected characteristics of execution and of the dispatching of a set of processes in computer structure—for example, time parameters such as minimum and maximum execution time, and consecutive calls of procedures (algorithms). The choice of the program language was made due to its possibility for parallel calculations and direct work with two-dimensional structures as variables. Program modules for the TryAPL2 operating environment were developed, allowing for the organization of experiments for investigation of developed formal mathematical models. Program experiments were performed, and some experimental results were presented and discussed. The applicability of the designed program tools was extended by additional examples for investigation of dispatching in a computer environment for execution of a sequence of processes. Characteristics for evaluation of the efficiency of the dispatching were defined and used for calculation and comparison of assessments to select the best plan in each of the evaluated dispatch strategies.
The research presented in this article is mainly related to homogeneous processes developing in a homogeneous environment. This can be continued in further research by analyzing processes in micro and macro levels, including in heterogeneous computer spaces, parallel structures, and distributed computer environments. For example, when studying process dispatching in a heterogeneous structure, it will be necessary to determine the time parameters t(Ai) for execution, which in the formalization can be presented by scalar weights of the graph nodes. In this respect, the further research will be directed to an extension of the model investigation to application of a probabilistic approach, which is typical for computer processes. This will be well supported by the capabilities of the software environment TryAPL2 for presentation and executions of stochastic processes.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
