The first algorithm, labeled
Cmsa++, is a revised and extended version of the
construct, merge, solve and adapt (CMSA) technique presented in prior work [
11]. The second algorithm is a new proposal, called
Barrakuda, which makes use of the algorithmic framework of a
biased random key genetic algorithm (BRKGA) [
31]. In
Figure 2, we present a high-level overview of both techniques, especially for pointing out the two separated
levels of operation. In the
original problem instance level of operation,
Cmsa++ and
Barrakuda deal with the full-size problem instance and generate a set of solutions needed for the construction of sub-instances. In this context,
Cmsa++ performs the generation of independent solutions through a
constructive probabilistic heuristic. Meanwhile,
Barrakuda makes use of BRKGA as a generator of solutions. In contrast to
Cmsa++,
Barrakuda makes use of learning for the generation of solutions. This is because it uses the natural learning mechanism of BRKGA, based on the selection of good solutions for acting as parents in order to produce offspring for the next iteration. This aspect will be explained in detail in
Section 3.2.1. In the
reduced problem instance level of operation, both algorithms make use of an ILP solver to deal with the incumbent sub-instance. If this sub-instance is small enough, the solver obtains good results providing over time high-quality solutions to the original problem instance.
The main difference between both proposals is the strategy for the creation and maintenance of the reduced sub-instances. Cmsa++ produces sub-instances by using solution components found in the solutions produced by the constructive probabilistic heuristic, keeping the sub-instance size small enough through a sub-instance maintenance process. This process uses information about the utility of solution components, which is used to eliminate seemingly useless solution components from the sub-instances. On the other hand, Barrakuda does not make use of such a maintenance mechanism. In contrast, it creates sub-instances from scratch at each iteration. For this purpose, Barrakuda uses the solution components from a set of solutions selected from a subset of the chromosomes of the incumbent BRKGA population. After the application of the ILP solver to the sub-instance, Barrakuda implements a solution encoding process in order to be able to add the high-quality solution produced by the ILP solver to the incumbent population of the BRKGA.
Finally, the main reason for choosing BRKGA—instead of another evolutionary algorithm from the literature—as the main algorithm framework of Barrakuda is the following one. A BRKGA is usually very easy to apply, as it only requires to find a clever way of translating the individuals of BRKGA (which are kept as random keys) into feasible solutions to the tackled problem. All other components, such as mutation and crossover, are the same for any BRKGA. In this way, it is possible to focus all efforts on the hybridization aspect.
3.1. Cmsa++: An Extension of Cmsa
As mentioned above,
Cmsa++ is a revised and extended version of the CMSA algorithm from [
11]. The extensions concern the following aspects:
Incorporation of a set of new features concerning successful variations used in other CMSA implementations.
Exploration of different constructive probabilistic heuristics for the probabilistic generation of solutions at each iteration.
Testing of two different sub-instance maintenance mechanisms, going beyond the original CMSA.
Making the algorithm more robust concerning the parameter values. Note that, in [
11], we had to conduct a very fine-grained tuning process in order to achieve a good algorithm performance for all problem instances.
Nevertheless, keep in mind that the original CMSA from [
11] can be obtained by setting the parameter values of
Cmsa++ in a specific way. In other words, the parameter tuning process may choose this option, if it results better than the newly introduced variations.
A high-level description of
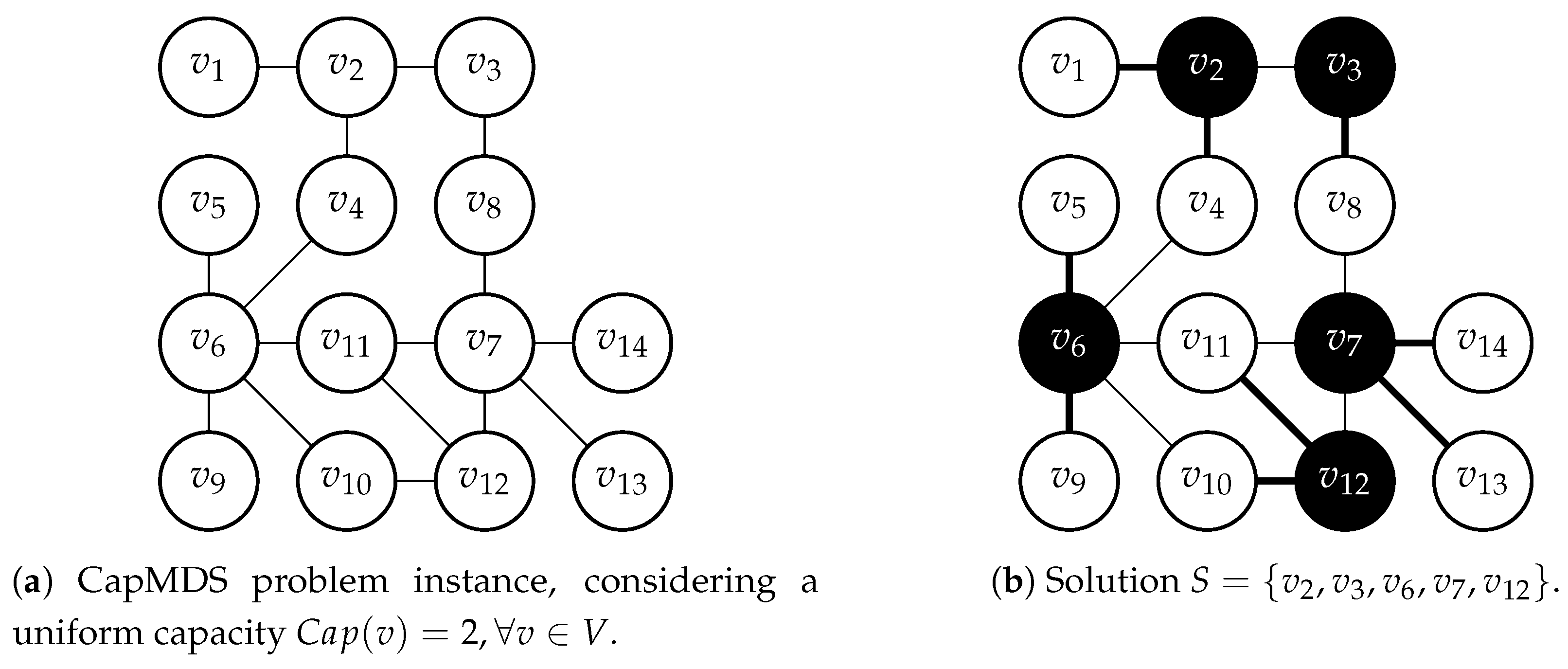
Cmsa++ for the CapMDS problem is provided in Algorithm 1. The algorithm maintains, at all times, an initially empty subset
of the set of vertices
V of the input graph. This set is henceforth called the
sub-instance. Vertices are added to sub-instance
by means of a probabilistic solution construction process, which is implemented in function
ProbabilisticSolutionGeneration (
,
,
) (see line 10 of Algorithm 1). In particular, all dominator vertices found in the solutions generated by this function are added to
—if not already in
—and their so-called “age value”
is initialized to zero (see lines 12 and 13 of Algorithm 1). Moreover, solving the sub-instance
refers to the application of the ILP solver CPLEX in order to find—if possible within the imposed time limit of
seconds—the optimal solution to sub-instance
; that is, the optimal CapMDS solution in
G that is limited to only contain dominators from
. This is achieved by adding the following set of constraints to the ILP model from the previous section:
The process of solving the sub-instance
is done in function
ApplyExactSolver(
); see line 16 of Algorithm 1.
| Algorithm 1Cmsa++ for the CapMDS problem |
| 1: input: a problem instance |
| 2: input: values for , , (original CMSA parameters) |
| 3: input: values for , , , (additional parameters) |
| 4: |
| 5: |
| 6: for all |
| 7: while CPU time limit not reached do |
| 8: |
| 9: for do |
| 10: |
| 11: for all and do |
| 12: |
| 13: |
| 14: end for |
| 15: end for |
| 16: ApplyExactSolver() |
| 17: if then |
| 18: Adapt(, , , ) |
| 19: end while |
| 20: output: |
The algorithm takes as input the tackled problem instance , and values for eight required parameters. The first four of them—see line 2 of Algorithm 1—are inherited from the original CMSA proposal, while the remaining four parameters—see line 3 of Algorithm 1—are in the context of the extensions that lead to Cmsa++. The eight parameters can be described as follows:
: establishes the number of iterations that a vertex is allowed to form part of sub-instance without forming part of the solution to returned by the ILP solver ().
: defines the number of solutions generated in the construction phase of the algorithm at each iteration; that is, the number of calls to function ProbabilisticSolutionGeneration().
: establishes the time limit (in seconds) used for running the ILP solver at each iteration.
, , : these three parameters determine the greediness of the solution construction process in function ProbabilisticSolutionGeneration(), which we described in more detail in the following subsection.
: indicates the variant of the solution construction process.
: chooses between two different behaviors implemented for the sub-instance maintenance mechanism implemented in function Adapt().
As mentioned above, Cmsa++ is—like any CMSA algorithm—equipped with a sub-instance maintenance mechanism for discarding seemingly useless solution components from the sub-instance at each iteration. The original implementation of this mechanism works as follows. First, the age values of all vertices in are incremented. Second, the age values of all vertices in are re-initialized to zero. Third, the vertices with age values greater than are erased from . In particular, this original implementation is used in case . In the other case—that is, when —a probability for being removed from is assigned to each vertex with . Note that these probabilities linearly increase until reaching probability 1 for all vertices with an age value greater than . Both mechanisms are implemented in function Adapt(, , , ) (see line 18 of Algorithm 1). Their aim is to maintain small enough in order to be able to solve the sub-instance (if possible) optimally. If this is not possible in the allotted computation time, the output of function ApplyExactSolver() is simply the best solution found by CPLEX within the given time.
One of the new features of
Cmsa++ (in comparison to the original version from [
11]) is a dynamic mechanism for adjusting the determinism rate (
) used during the solution construction at each iteration. The mechanism is the same as that described in [
32]. In the original CMSA, this determinism rate was a fixed value between 0 and 1, determined by algorithm tuning. In contrast,
Cmsa++ chooses a value for
at each iteration in function
DeterminismAdjustment from the interval
where
. This is done under the hypothesis that
Cmsa++ can escape from local optima, increasing the randomness of the algorithm. Whenever an iteration improves
, the value of
is set back to its upper bound
. Otherwise, the value of
is decreased by a factor determined by subtracting the lower bound vale from the upper bound value
and dividing the result by 3.0. Finally, whenever the value of
falls below the lower bound, it is set back to the upper bound value. Adequate values for
and
must be determined by algorithm tuning. Note that the behavior of the original CMSA algorithm is obtained by setting
.
Finally, note that Cmsa++ iterates while a predefined CPU time limit is not reached. Moreover, it provides the best solution found during the search, , as output.
Probabilistic Solution Generation
The function used for generating solutions in a probabilistic way (in line 10 of Algorithm 1) is presented in Algorithm 2. Note that there are three ways of generating solutions that are pseudo-coded in this algorithm. They are indicated in terms of three options:
,
, and
. Line 18 of Algorithm 2, for example, is only executed for options
and
. Note that option
implements the solution construction mechanism of the original CMSA algorithm for the CapMDS problem from [
11]. In the following section, first, the general solution construction procedure is described. Subsequently, we outline the differences between the three options mentioned above.
| Algorithm 2 Function ProbabilisticSolutionGeneration(, , ) |
| 1: input: a problem instance |
| 2: input: parameter values for , , |
| 3: |
| 4: |
| 5: |
| 6: ComputeHeuristicValues(W) |
| 7: while do |
| 8: Choose a random number |
| 9: if then |
| 10: Choose such as for all |
| 11: else |
| 12: Let contain the vertices from W with the highest heuristic values |
| 13: Choose uniformly at random from L |
| 14: end if |
| 15: |
| 16: |
| 17: if or then |
| 18: |
| 19: else |
| 20: |
| 21: end if |
| 22: if or then |
| 23: ComputeHeuristicValues(W) |
| 24: end if |
| 25: end while |
| 26: output: S |
The procedure takes as input the problem instance
, as well as values for the parameters
,
and
. The two first parameters are used for controlling the degree of determinism of the solution construction process. Meanwhile,
indicates one of the three options. The process starts with an empty partial solution
. At each step, exactly one vertex from a set
is added to
S, until the set of uncovered vertices (
) is empty. Note that both
W and
are initially set to
V. Next we explain how to choose a vertex
from
W at each step of the procedure. First of all, vertices from
W are evaluated in function
ComputeHeuristicValues(
W) by a dynamic greedy function
, which depends on the current partial solution
S. More specifically:
Hereby, refers to the capacity of v and , where is the set of currently uncovered neighbors of v. The -value of a vertex is henceforth called its heuristic value. The choice of a vertex is then done as follows. First, a value is chosen uniformly at random. In case , is chosen as the vertex that has the highest heuristic value among all vertices in W. Otherwise, a candidate list L containing the vertices from W with the highest heuristic values is generated, and is chosen from L uniformly at random. Thus, the greediness of the solution construction procedure depends on the values of the determinism rate () and the candidate list size (). Note that, when is greater than , we have to choose which vertices from the vertex is going to cover. In our current implementation, the set of vertices is simply chosen from uniformly at random and stored in . Finally, W and are updated at the end of each step.
When
, the solution construction procedure is the same as that used in the original CMSA algorithm for the CapMDS problem. In particular,
W is updated after each choice of a vertex
in line 18 by removing the newly covered vertices. This concerns the chosen vertex
and the vertices from
that were chosen to be covered by
. Moreover, the greedy function values are always updated according to the current partial solution
S (see line 23 of Algorithm 2). In contrast, when
the update of
W (see line 20) is done by only removing the chosen vertex
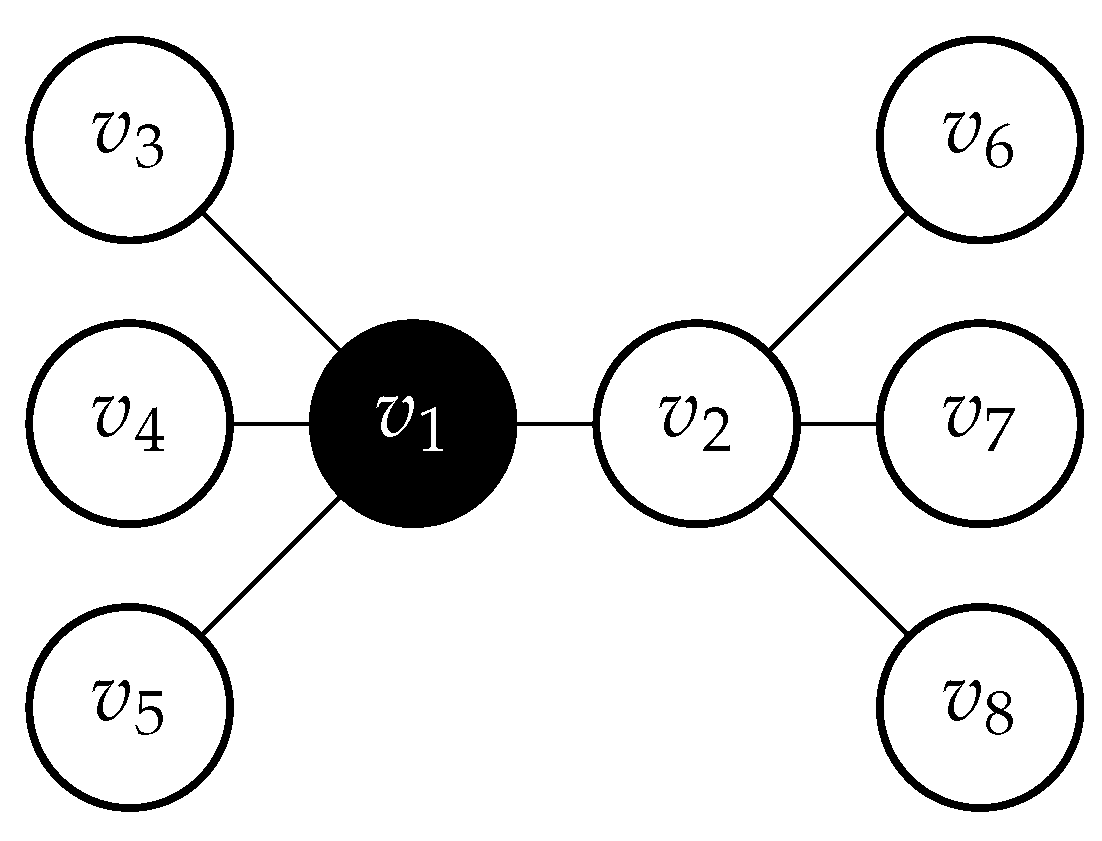
from the options. The rationale behind this is as follows. Consider the example in
Figure 3. In case
, nodes
and
are removed from
W for the next construction step. This removes node
from the set of selectable vertices, although choosing
in the next step would lead to the construction of the optimal solution in this example.
Finally, with the solution construction is the same as with , just that the greedy function values are not recalculated in line 23. The rationale behind this way of constructing solutions is to gain speed. On the negative side, this proposal possibly overestimates the heuristic values of the vertices and generally favors the hubs (vertices with a high degree) in the input graph.
3.2. Barrakuda: A Hybrid of Brkga with an ILp Solver
As mentioned before, the main algorithm proposed in this work is a hybrid between the well-known
biased random key genetic algorithm (BRKGA) [
31] and an ILP solver. Roughly, the solution components of (some of the solutions in the) population of the BRKGA are joined at the end of each iteration and the resulting sub-instance is passed to the ILP solver. Afterwards, the solution returned by the ILP solver is fed back into the population of BRKGA. As in CMSA, the main motivation for this proposal is to take profit from the ILP solver even in the context of problem instances that are too large in order to apply the ILP solver directly. The advantage of
Barrakuda over CMSA is the learning component of BRKGA, which is not present in CMSA.
3.2.1. Main Algorithmic Framework
The main algorithm framework of Barrakuda, which is pseudo-coded in Algorithm 3, is that of the BRKGA. In fact, the lines that turn the BRKGA into Barrakuda are lines 12–15, which are marked by a different background colors. In the following section, we first outline all the BRKGA components of our algorithm before describing the additional Barrakuda components.
BRKGA is a steady-state genetic algorithm which consists of a problem-independent part and of a problem-dependent part. It takes as input the tackled problem instance
, and the values of four parameters (
,
,
and
) that are found in any BRKGA. The algorithm starts with the initialization of a population
P composed of
random individuals (line 4 of Algorithm 3). Each individual
is a vector of length established by
, where
V is the set of vertices of
G. In order to generate a random individual, for each position
of
(
) a random value from
is generated. In this context, note that values
and
are associated to vertex
of the input graph
G. Then, the elements of the population are evaluated (see line 5 of Algorithm 3). This operation, which translates each individual
into a solution
(set of vertices) to the CapMDS problem, corresponds to the problem-dependent part described in the next subsection. Note that, after evaluation, each individual
has assigned the objective function value
of corresponding CapMDS solution. Henceforth,
will refer to
and vice versa.
| Algorithm 3Barrakuda for the CapMDS problem |
| 1: input: a problem instance |
| 2: input: values for , , and (BRKGA parameters) |
| 3: input: values for , , (additional Barrakuda parameters) |
| 4: |
| 5: |
| 6: while computation time limit not reached do |
| 7: |
| 8: |
| 9: |
| 10: ▹ NOTE: is already evaluated |
| 11: |
| 12: |
| 13: |
| 14: |
| 15: |
| 16: end while |
| 17: output: Best solution in P |
Then, at each iteration of the algorithm, a set of genetic operators are executed in order to produce the population of the next iteration (see lines 7–11 in Algorithm 3). First, the best individuals are copied from P to in function . Then, a set of mutant individuals are generated and stored in . These mutants are produced in the same way as individuals from the initial population. Next, a set of individuals are produced by crossover in function and stored in . Each such individual is generated as follows: First, an elite parent is chosen uniformly at random from . Then, a second parent is chosen uniformly at random from . Finally, an offspring individual is produced on the basis of and and stored in . In the context of the crossover operator, value is set to with probability , and to otherwise. After generating all new offspring in and , these new individuals are evaluated in line 10. A standard BRKGA operation would now end after assembling the population of the next iteration (line 11).
3.2.2. Evaluation of an Individual
The problem-dependent part of the BRKGA concerns the evaluation of an individual, which consists of translating the individual into a valid CapMDS solution and calculating its objective function value. For this purpose, the solution generation procedure from Algorithm 2 is applied with option . The only difference is in the choice of vertex at each step (lines 8–14 of Algorithm 2), and the choice of the set of neighbors to be covered by . Both aspects are outlined in the following section. Moreover, the resulting pseudo-code is shown in Algorithm 4.
Instead of choosing a vertex
at each iteration of the solution construction process in a semi-probabilistic way as shown in lines 8–14 of Algorithm 2, the choice is done deterministically based on combining the greedy function value
with its first corresponding value in individual
. (Remember that function
is defined in Equation (
7).) More specifically,
| Algorithm 4 Evaluation of an individual in Barrakuda |
| 1: input: an individual |
| 2: |
| 3: |
| 4: |
| 5: ComputeHeuristicValues(W) |
| 6: while do |
| 7: |
| 8: |
| 9: |
| 10: |
| 11: |
| 12: while and s.t. do |
| 13: |
| 14: |
| 15: |
| 16: end while |
| 17: |
| 18: |
| 19: ComputeHeuristicValues(W) |
| 20: end while |
| 21: output: S |
This is also shown in line 7 of Algorithm 4. In this way, the BRKGA algorithm will produce—over time—individuals with high values for vertices that should form part of a solution, and vice versa. The greedy function is only important for providing an initial bias towards an area in the search space that presumably contains good solutions. Finally, note that the first values of an individual (corresponding, in the given order, to vertices ) are used for deciding which vertices are chosen for the solution.
As mentioned above, the second aspect that differs when comparing the evaluation of an individual with the construction of a solution in Algorithm 2 is the choice of the set of neighbors
to be covered by
at each step. Remember that, in Algorithm 2,
, vertices are randomly chosen from
and stored in
. In contrast, for the evaluation of a solution, vertices are sequentially picked from
and added to
until either
vertices are picked or no further uncovered neighbor
of
exists with
. Assuming that we denote the set of remaining (still unpicked) uncovered vertices of
by
N, at each step the following vertex is picked from
N:
This is also shown in line 13 of Algorithm 4. Note that, as a greedy function for choosing from the uncovered neighbors of , we make use of the number of uncovered neighbors of these vertices, preferring those with a large number of uncovered neighbors. Note also that, for selecting the vertices that are dominated by a chosen node , the second half of an individual is used, that is, values . In other words, with the second half of an individual, the BRKGA learns by which node a non-chosen node should be covered.
3.2.3. From Brkga to Barrakuda
Finally, it remains to describe lines 12–15 of Algorithm 3 that are an addition to the standard BRKGA algorithm and that convert the algorithm into Barrakuda. This part makes use of three Barrakuda-specific parameters:
Parameter is used for establishing the time limit given to the ILP solver in function ApplyExactSolver.
Parameter is used for determining the way in which individuals/solutions are chosen from the current BRKGA population for building a sub-instance . This is done in function ChooseSolutions.
Parameter refers to the number of individuals that must be chosen from P for the construction of the sub-instance.
The Barrakuda-specific part of the algorithm starts by choosing exactly individuals from the current population P and storing their corresponding solutions (which are known, because these individuals are already evaluated) in a set . Parameter indicates the way in which these solutions are chosen. In case , the best individuals from P are chosen. Otherwise (when ), the best individual from P in addition to randomly chosen solutions are added to . Subsequently, the vertices of all solutions from are merged into set , and CPLEX is applied in function ApplyExactSolver in the same way as in the case of Cmsa++. Finally, the solution returned by the solver is fed back to BRKGA in function IntegrateSolverSolution. More specifically, is transformed into an individual , which is then added to P. Finally, the worst individual is deleted from P in order to keep the population size constant. The integration process is quite straightforward, because it only considers information about the vertices (dominators) used in the solvers’ solution and not the domination relationships (edges). More specifically, Barrakuda creates a new individual where . Moreover, for each dominating vertex in the solution of the solver , whereas for each remaining vertex , the value of , is set to zero.









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}