Link Prediction (LP) is a branch of Complex Networks science that aims at explaining the evolutionary dynamics of a network, looking at possible supplementary connections which can be established between entities (nodes) in the network. A common approach to LP is to introduce a definition of similarity between entities and to calculate similarity values accordingly, between all pairs of still non-connected nodes. In the ranking induced by the similarity rates, pairs ranked prime represent relationships with a higher formation likelihood. The image of a network at time
t used to compute similarities is called
training network, the information deriving from the ranking is tested on the
test network, representing the status of the same network at a future time-step
. The concept of similarity is central to the problem; in literature, various definitions are available, including semantic [
1] and topological [
2] similarity. The former evaluates similarity according to features of the nodes; intuitively, two nodes are as similar as their feature values are. The latter looks at the position of nodes in the network, either limiting the analysis to a k-depth bounded local neighborhood [
3], or considering the whole network at once; e.g., [
4,
5] the broadly used Jaccard [
6] and Adamic-Adar [
7] indices. Important characteristics to consider for different approaches are the requirements, e.g., the number of training items for the learning phase; the possibility of reading and analyzing the process steps as well as the result, thus the readability of results; the result type, boolean, rank or absolute value with particular details. The choice of the approach will consider such requirements and adapt the technique and setting to the goal. In this work, we study the class of topological similarities, focusing on measures based on the shared local neighborhood (i.e., common neighbors), given that semantic similarity measures can also be mapped to topological ones [
8], thus can be included in the same point of view. Similarities of depth 2, e.g., Resource Allocation and Adamic-Adar, have been demonstrated in the literature to be more effective in terms of prediction ability than other more straightforward measures [
8]. However, this does not apply to all domains, and simple measures, e.g., Common Neighbours or Jaccard, often can outperform more elaborate ones. It looks like no all-purpose neighborhood-based similarity ratio, able to effectively capture the peculiar characteristics of each different domain, is available in the literature for a general application on every domain. Two research questions emerge:
To the best of our knowledge, the only attempt to answer the first research question is a plain linear combination of well-known indices [
9], where the weights regulating the contribution of each index are evolved using the covariance matrix adaptation evolution strategy [
10] for numerical optimization. This linear combination can be identified as a preliminary definition of a meta-correlation, but its adaptability power to different domains is limited. Our approach contributes to finding original meta-correlations evolving basic ones using Differential Evolution (DE) [
11], where an added value is provided evolving the whole meta-correlation instead of using a plain linear combination of measures. Among the existing approaches to the problem of link prediction, we have chosen to build a meta-correlation based on the best indices in the literature and to adapt them to any domain using the Differential Evolution algorithm. DE is suitable for our goal for its readability and differentiation since our aim is finding a generalized meta-correlation metric to be applied to any domain without prerequisites of knowledge, density and connection of the graph. For example, methods based on full knowledge of the graph are very difficult to apply in large graphs, so the analysis of the nodes neighborhood is certainly more convenient [
3]. Among these link prediction techniques, each of which can be better than others for different contexts, simple measurements often have decent results, but in the literature, many techniques are present for enhancing performances, with different variations. The Quasi-common proximity approach [
3,
12] varies the basic measurements in the graph to evaluate them at point 2 of the graph and is applicable to any topological similarity measure. Path-based heuristic approaches, such as the Heuristic Semantic Walk [
13], calculate the similarity of potential nodes, applicable in link prediction, by choosing on the basis of semantic heuristics the direction for the graph navigation, adding partial randomization to avoid loops. Recently, some works combine topological and semantic similarity [
1,
8,
14] to predict links in specific domains, e.g., co-authorship networks, providing techniques that could be applied also in other domains. Adapting the approach to many different similarity measures, very satisfying results are obtained, predicting links on the basis of sub-graphs [
12,
14] around nodes connected by each potential link, especially when semantic features are present but also using semantic measures mapped to the graph topology [
1]. While topological and semantic approaches can exploit the characteristics of the network by recommending the network structure, on the other hand, approaches based on deep learning can be very performing, but require a very high number of training elements and provide results without any possibility for the researcher to analyze the process, which can be considered a black box. Some of these approaches, e.g., SEAL [
5], use random sampling on potential links, not providing a complete list of rankings, to ease the computation. Unfortunately, all these techniques are not directly comparable, not only because of the different goals and approaches but because each of them uses proper evaluation metrics, which are different for each approach and not overlapping. The used similarity metrics vary based on the graph structure or features, and anyway, domain-specific characteristics do not allow a direct comparison where tests are made on different data sets. The choice of the right approach will vary in different contexts and goals, but it will be primarily based on the requirements of each approach. In real-world applications, e.g., where a company needs a correlation metric to exploit link prediction on any domain without the need for professional resources to set up different learning algorithms for each possible domain, it is useful to build meta-correlations with generalization capabilities.
The paper structure is the following: in
Section 2 a formal definition of meta-correlation indices is given, the related state of the art is presented for the basic correlation metrics, and our proposed novel meta-correlations are presented in detail;
Section 3 provides in-depth information for the experiment reproducibility and setting, including network preprocessing and partition, a description of the data sets where the experiments are exploited, and the setting of the Differential Evolution pipeline.
Section 4 presents the experimental results and discussion;
Section 5 concludes the paper.







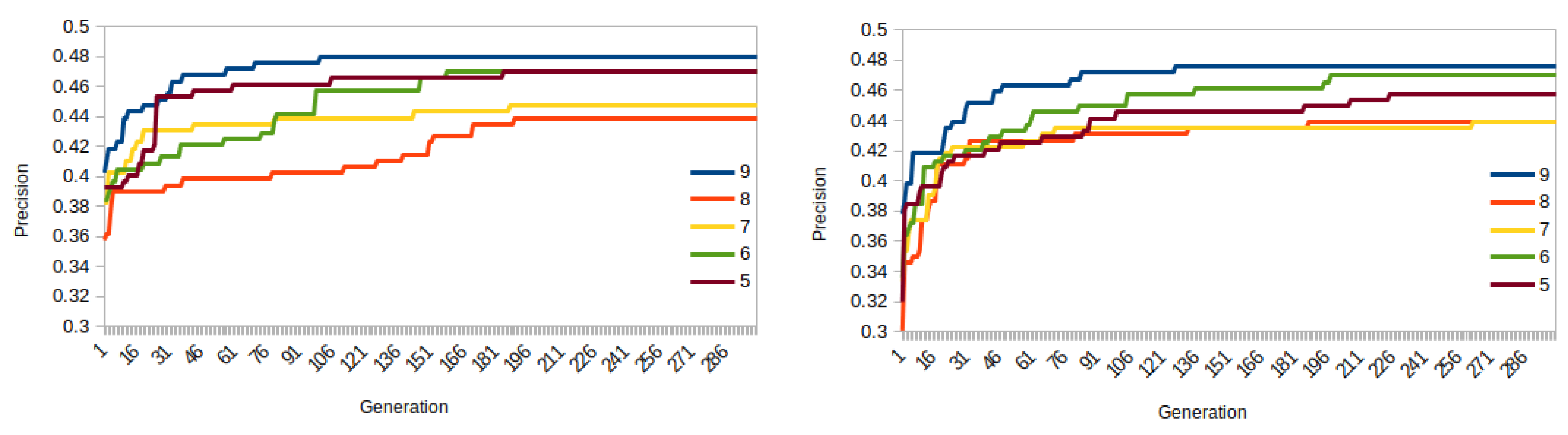{kind=link}
{kind=link}