Comparing Groups of Decision-Making Units in Efficiency Based on Semiparametric Regression

Abstract
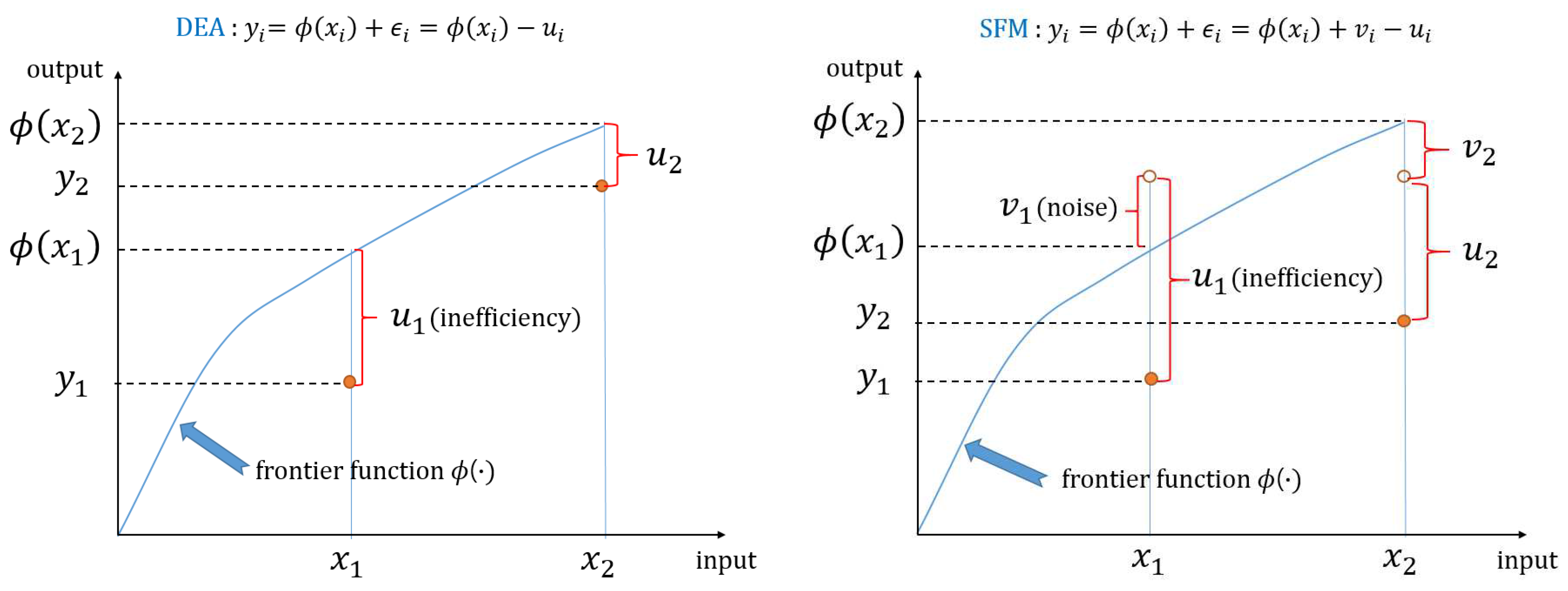
:1. Introduction
2. Group Efficiency Comparison under SFM
2.1. The Previous Work
2.2. The Proposed Test
3. Numerical Studies
3.1. Single Input Case
3.2. Multiple Input Case
4. Application to PISA 2015 Data
5. Discussion and Conclusions
Author Contributions
Funding
Conflicts of Interest
Appendix A
- The kernel function K is symmetric, and Lipschitz continuous in .
- is twice partially continuously differentiable.
- The density functions of are continuous, and bounded away from zero and infinity on their supports , which are bounded.
- and have finite second moments.
- For , are asymptotic to for such that and as n goes to infinity.
Appendix B
- The kernel function K is symmetric, and Lipschitz continuous in .
- are twice continuously differentiable.
- The density functions of are continuous, and bounded away from zero and infinity on their supports, which are bounded.
- and have finite second moments.
- For , and as n goes to infinity.
References
- Golany, B.; Storberg, J. A data envelopment analysis of the operational efficiencies of bank branches. Interfaces 1999, 29, 14–26. [Google Scholar] [CrossRef]
- Lee, H.; Park, Y.; Choi, H. Comparative evaluation of performance of national R&D programs with heterogeneous objectives: A DEA approach. Eur. J. Oper. Res. 2009, 196, 847–855. [Google Scholar]
- Cummins, J.D.; Weiss, M.A.; Zi, H. Organizational form and efficiency: The coexistence of stock and mutual property-liability insurers. Manag. Sci. 1999, 45, 1254–1269. [Google Scholar] [CrossRef]
- Simar, L.; Zelenyuk, V. On testing equality of distributions of technical efficiency scores. Econom. Rev. 2006, 25, 497–522. [Google Scholar] [CrossRef] [Green Version]
- Li, Q. Nonparametric testing of closeness between two unknown distribution functions. Econom. Rev. 1996, 15, 261–274. [Google Scholar] [CrossRef]
- O’Donnell, C.J.; Rao, D.S.P.; Battese, G.E. Metafrontier frameworks for the study of firm-level efficiencies and technology ratios. Empir. Econ. 2008, 34, 231–255. [Google Scholar] [CrossRef]
- Aigner, D.; Chu, S. On estimating the industry production function. Am. Econ. Rev. 1968, 58, 826–839. [Google Scholar]
- Meeusen, W.; van den Broeck, J. Efficiency estimation from Cobb-Douglas production functions with composed error. Int. Econ. Rev. 1977, 18, 435–444. [Google Scholar] [CrossRef]
- Banker, R.D.; Zheng, Z.; Natarajan, R. DEA-based hypothesis tests for comparing two groups of decision making units. Eur. J. Oper. Res. 2010, 206, 231–238. [Google Scholar] [CrossRef]
- Simar, L.; Wilson, P.W. Two-stage DEA: Caveat emptor. J. Product. Anal. 2011, 36, 205–218. [Google Scholar] [CrossRef]
- Banker, R.D.; Natarajan, R. Evaluating contextual variables sffecting productivity using data envelopment analysis. Oper. Res. 2008, 56, 48–58. [Google Scholar] [CrossRef]
- Liang, H. Estimation in partially linear models and numerical comparisons. Comput. Stat. Data Anal. 2006, 50, 675–687. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Ma, Y.; Chiou, J.M.; Wang, N. Efficient semiparametric estimator for heteroscedastic partially linear models. Biometrika 2006, 93, 75–84. [Google Scholar] [CrossRef] [Green Version]
- Huang, J. A note on estimating a partly linear model under monotonicity constraints. J. Stat. Plan. Inference 2002, 107, 343–351. [Google Scholar] [CrossRef]
- Ruppert, D.; Sheather, S.J.; Wand, M.P. An effective bandwidth selector for local least squares regression. J. Am. Stat. Assoc. 1995, 90, 1257–1270. [Google Scholar] [CrossRef]
- Ferrara, G.; Vidoli, F. Semiparametric stochastic frontier models: A generalized additive model approach. Eur. J. Oper. Res. 2017, 258, 761–777. [Google Scholar] [CrossRef]
- Hastie, T.J.; Tibshirani, R.J. Generalized Additive Models; Chapman and Hall/CRC: New York, NY, USA, 1990. [Google Scholar]
- Samuelsson, M.; Samuelsson, J. Gender differences in boys’ and girls’ perception of teaching and learning mathematics. Open Rev. Educ. Res. 2016, 3, 18–34. [Google Scholar] [CrossRef]
- Noh, H.; Van Keiligom, I. On relaxing the distributional assumption of stochastic frontier models. J. Korean Stat. Soc. 2020, in press. [Google Scholar]
- Van de Geer, S. Empirical Processes in M-Estimation; Cambridge University Press: Cambridge, UK, 2000. [Google Scholar]
- Fan, J.; Hardle, W.; Mammen, E. Direct estimation of low-dimensional components in additive models. Ann. Stat. 1998, 26, 943–971. [Google Scholar] [CrossRef]
- Fan, Y.; Li, Q. A kernel-based method for estimating additive partially linear models. Stat. Sin. 2003, 13, 739–762. [Google Scholar]
- Li, Q. Efficient estimation of additive partially linear models. Int. Econ. Rev. 2000, 41, 1073–1092. [Google Scholar] [CrossRef]
- Wei, C.H.; Liu, C. Statistical inference on semi-parametric partial linear additive models. J. Nonparametric Stat. 2012, 24, 809–823. [Google Scholar] [CrossRef]
- Fan, J.; Jiang, J. Nonparametric inferences for additive models. J. Am. Stat. Assoc. 2005, 100, 890–907. [Google Scholar] [CrossRef]


{kind=link}
| Type I Error | Power | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| (Rejection Rate When = 0) | (Rejection Rate When = 0.3305) | ||||||||||||
| Variances | PT | OLS | T | MW | KS | F | PT | OLS | T | MW | KS | F | |
| Equal | 100 | 0.052 | 0.050 | 0.050 | 0.050 | 0.037 | 0.013 | 0.377 | 0.336 | 0.320 | 0.283 | 0.200 | 0.152 |
| () | 200 | 0.062 | 0.058 | 0.056 | 0.062 | 0.047 | 0.006 | 0.595 | 0.555 | 0.547 | 0.483 | 0.397 | 0.300 |
| 400 | 0.063 | 0.064 | 0.062 | 0.061 | 0.052 | 0.003 | 0.848 | 0.822 | 0.818 | 0.761 | 0.665 | 0.533 | |
| Unequal | 100 | 0.047 | 0.065 | 0.060 | 0.050 | 0.062 | 0.037 | 0.337 | 0.337 | 0.328 | 0.276 | 0.277 | 0.279 |
| () | 200 | 0.053 | 0.064 | 0.063 | 0.052 | 0.099 | 0.029 | 0.505 | 0.468 | 0.463 | 0.388 | 0.521 | 0.401 |
| 400 | 0.044 | 0.051 | 0.050 | 0.048 | 0.179 | 0.026 | 0.738 | 0.722 | 0.712 | 0.645 | 0.836 | 0.650 | |
| Type I Error | Power | ||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| (Rejection Rate When = 0) | (Rejection Rate When = 0.3305) | ||||||||||||||
| Variances | PT(a) | PT(n) | OLS | T | MW | KS | F | PT(a) | PT(n) | OLS | T | MW | KS | F | |
| Equal | 100 | 0.066 | 0.053 | 0.044 | 0.043 | 0.054 | 0.040 | 0.141 | 0.220 | 0.294 | 0.234 | 0.235 | 0.170 | 0.133 | 0.492 |
| () | 200 | 0.059 | 0.077 | 0.049 | 0.050 | 0.044 | 0.035 | 0.113 | 0.328 | 0.488 | 0.473 | 0.471 | 0.356 | 0.268 | 0.644 |
| 400 | 0.048 | 0.056 | 0.039 | 0.039 | 0.037 | 0.031 | 0.064 | 0.509 | 0.765 | 0.705 | 0.706 | 0.580 | 0.517 | 0.815 | |
| Unequal | 100 | 0.061 | 0.063 | 0.101 | 0.099 | 0.054 | 0.046 | 0.316 | 0.199 | 0.258 | 0.346 | 0.340 | 0.173 | 0.143 | 0.649 |
| () | 200 | 0.058 | 0.074 | 0.139 | 0.137 | 0.062 | 0.053 | 0.381 | 0.302 | 0.433 | 0.583 | 0.580 | 0.347 | 0.331 | 0.849 |
| 400 | 0.048 | 0.060 | 0.128 | 0.130 | 0.046 | 0.093 | 0.385 | 0.468 | 0.682 | 0.793 | 0.792 | 0.530 | 0.650 | 0.947 | |
| Type I Error | Power | ||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| (Rejection Rate When = 0) | (Rejection Rate When = 0.3305) | ||||||||||||||
| Variances | PT(a) | PT(n) | OLS | T | MW | KS | F | PT(a) | PT(n) | OLS | T | MW | KS | F | |
| Equal | 100 | 0.054 | 0.072 | 0.046 | 0.045 | 0.041 | 0.034 | 0.065 | 0.364 | 0.328 | 0.213 | 0.208 | 0.170 | 0.132 | 0.279 |
| () | 200 | 0.066 | 0.060 | 0.063 | 0.061 | 0.056 | 0.045 | 0.045 | 0.578 | 0.551 | 0.387 | 0.384 | 0.318 | 0.258 | 0.403 |
| 400 | 0.054 | 0.055 | 0.034 | 0.034 | 0.033 | 0.033 | 0.018 | 0.820 | 0.801 | 0.572 | 0.571 | 0.503 | 0.419 | 0.517 | |
| Unequal | 100 | 0.057 | 0.070 | 0.066 | 0.062 | 0.044 | 0.048 | 0.144 | 0.301 | 0.295 | 0.236 | 0.228 | 0.153 | 0.121 | 0.381 |
| () | 200 | 0.068 | 0.060 | 0.089 | 0.089 | 0.054 | 0.060 | 0.137 | 0.501 | 0.481 | 0.415 | 0.414 | 0.281 | 0.290 | 0.566 |
| 400 | 0.057 | 0.054 | 0.058 | 0.058 | 0.032 | 0.056 | 0.096 | 0.719 | 0.695 | 0.588 | 0.586 | 0.446 | 0.535 | 0.720 | |
| min | median | mean | max | ||||
|---|---|---|---|---|---|---|---|
| male | 27.89 | 39.52 | 41.72 | 43.10 | 47.81 | 56.70 | |
| 338.5 | 470.6 | 499.7 | 483.9 | 513.8 | 565.6 | ||
| female | 25.23 | 38.99 | 41.49 | 41.98 | 45.26 | 56.67 | |
| 339.0 | 456.9 | 487.9 | 474.8 | 501.9 | 565.0 |
| test | PT | OLS | T | MW | KS | F |
|---|---|---|---|---|---|---|
| p-value | 0.049 | 0.150 | 0.150 | 0.044 | 0.057 | 0.322 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Noh, H.; Yang, S.J. Comparing Groups of Decision-Making Units in Efficiency Based on Semiparametric Regression. Mathematics 2020, 8, 233. https://doi.org/10.3390/math8020233
Noh H, Yang SJ. Comparing Groups of Decision-Making Units in Efficiency Based on Semiparametric Regression. Mathematics. 2020; 8(2):233. https://doi.org/10.3390/math8020233
Chicago/Turabian StyleNoh, Hohsuk, and Seong J. Yang. 2020. "Comparing Groups of Decision-Making Units in Efficiency Based on Semiparametric Regression" Mathematics 8, no. 2: 233. https://doi.org/10.3390/math8020233
APA StyleNoh, H., & Yang, S. J. (2020). Comparing Groups of Decision-Making Units in Efficiency Based on Semiparametric Regression. Mathematics, 8(2), 233. https://doi.org/10.3390/math8020233