Innovative Platform for Designing Hybrid Collaborative & Context-Aware Data Mining Scenarios



Abstract
:1. Introduction
1.1. Collaborative Data Mining (CDM)
1.2. Context Aware Data Mining (CADM)
1.3. Combining CADM and CDM in a Flexible Architecture
2. Data and Methods
2.1. Proposal: Scenarios Platform-Collaborative & Context-Aware Data Mining (SP-CCADM)
2.1.1. Preliminary Analysis Steps
- Identify main data (MD) that is the subject of analysis, with attributes , , … . We denote the attribute that is the subject for the prediction with .
- Identify whether there is a possible suitable context that could be used in the analyzed scenario. The suite of k attributes corresponding to the context will be noted with , , … .
- Identify possible collaborative sources (, , … ), each with a variable number of attributes that could be used.
- Choose the machine learning algorithms that seem suitable for the problem at hand.
- Decide upon the measures that you would want to measure when deciding on the best possible combinations.
- Define the test scenarios that you would want to analyze. Table 1 defines an example of scenarios that could be analysed. Question mark for attribute name means that the attribute is not considered.
2.1.2. SP-CCADM Description on Data Mining Algorithm
- Load main data.
- Load context data.
- Load correlated sources data.
- for each defined test scenario:
- −
- Preprocess context data attributes specified in the test scenario; add it to the main data source.
- −
- Preprocess collaborative sources specified in the test scenarios and add specified attributes to the main data source.
- −
- Mark the item specified in the test scenario as wanted prediction.
- −
- Apply machine learning algorithm.
- −
- Register chosen measure results for the chosen scenario.
- In the end, analyze the best scenario suitable for the chosen machine learning algorithm and combination of CADM and CDM.
2.2. Data Sources
2.3. Methods
2.3.1. Environment and Techniques
2.3.2. Machine Learning Algorithms
- k-Nearest Neighbour (k-NN)—as Cunningham and Delany [39] mentioned, it is one of the most straightforward machine learning techniques;
- Deep Learning (DL)—not yet used in the industry as a valuable option, even though deep learning had very successful applications in the last years [40];
- Gradient Boosted Trees (GBT)—Yu et al. [41] used GBT to predict the short-term wind speed;
- Decision Trees (DT)—according to Geurts [42], this algorithm is “fast, immune to outliers, resistant to irrelevant variables, insensitive to variable rescaling”.
- −
- k-NN is a straight forward and most used mathematical model;
- −
- Deep Learning means complex neural networks with advanced mathematics behind them;
- −
- Gradient boosted trees represent a mathematical approach to decision trees;
- −
- Decision trees are algorithm-based discrete models.
2.3.3. Measurements Performed
- Absolute Error (AE)—the average absolute deviation of the prediction from the actual value. This value is used for Mean Absolute Error which is very common measure of forecast error in time series analysis [43].
- Relative Error (RE)—the average of the absolute deviation of the prediction from the actual value divided by actual value [44].
- Root Mean Squared Error (RMSE)—the standard deviation of the residuals (prediction errors). It is calculated by finding the square root of the mean/average of the square of all errors [45]:where n is the number of outputs, is the i-th actual output and is the i-th desired output.
- Spearman —computes the rank correlation between the actual and predicted values [46].
2.4. Implementation
- Standalone—predict the soil humidity for a location, knowing previous evolution of the soil humidity for that location (main data).
- CADM—predict the soil humidity for a location, knowing: previous evolution of the soil humidity for that location (main data); air temperature evolution for the location (context data).
- CADM + CDM 1 source—predict the soil humidity for a location, knowing: previous evolution of the soil humidity for that location (main data); air temperature evolution for the location (context data); soil humidity information for one of the closest locations (correlated source 1 data).
- CADM + CDM 2 sources—predict the soil humidity for a location, knowing: previous evolution of the soil humidity for that location (main data); air temperature evolution for the location (context data); soil humidity information for two of the closest locations (correlated source 1 data and correlated source 2 data).
- CADM + CDM 3 sources—predict the soil humidity for a location, knowing: previous evolution of the soil humidity for that location (main data); air temperature evolution for the location (context data); soil humidity information for three of the closest locations (correlated source 1 data, correlated source 2 data and correlated source 3 data).
- CDM 3 sources—predict the soil humidity for a location, knowing: previous evolution of the soil humidity for that location (main data); soil humidity information for three of the closest locations (correlated source 1 data, correlated source 2 data and correlated source 3 data).
3. Results
3.1. Overall Statistical Results
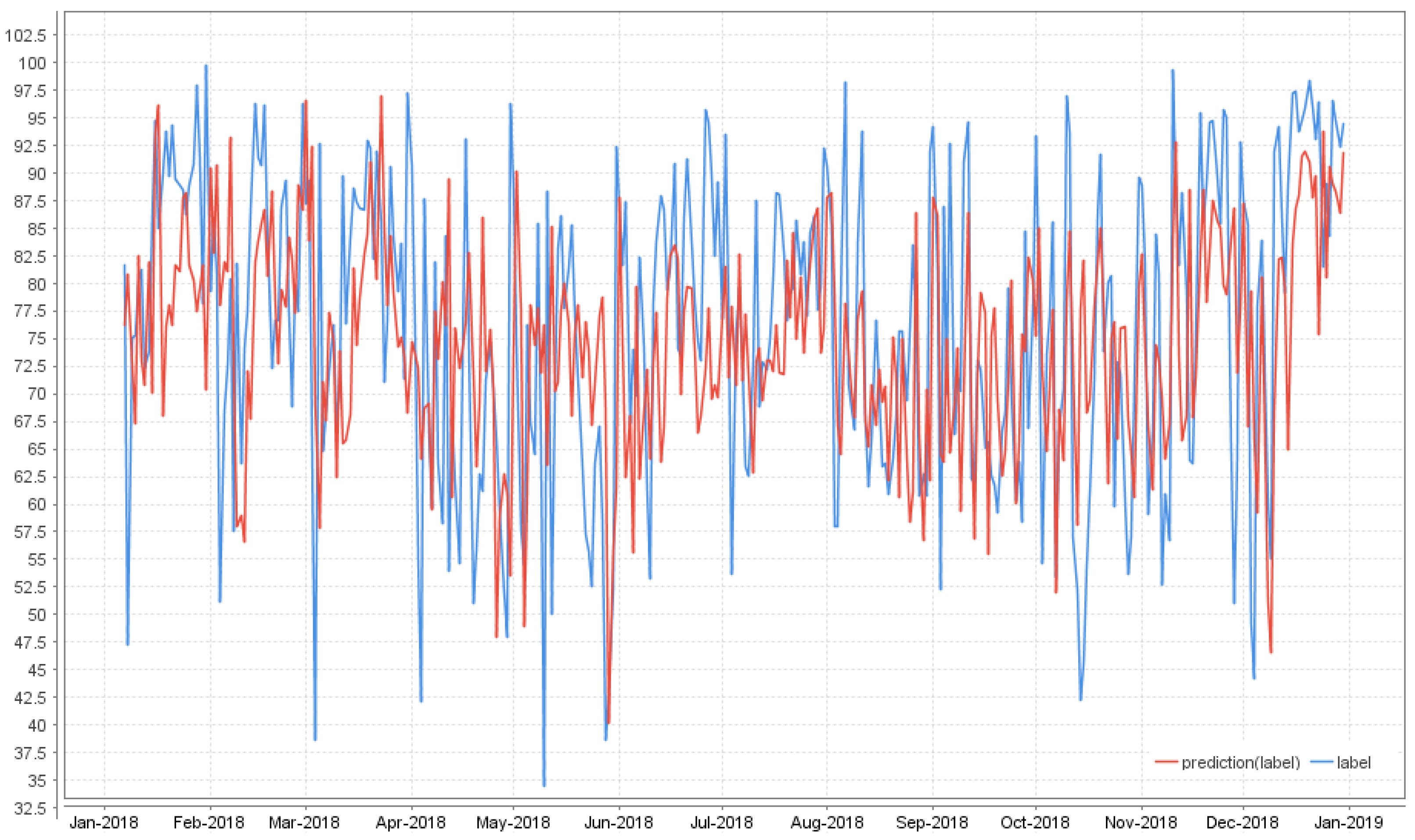
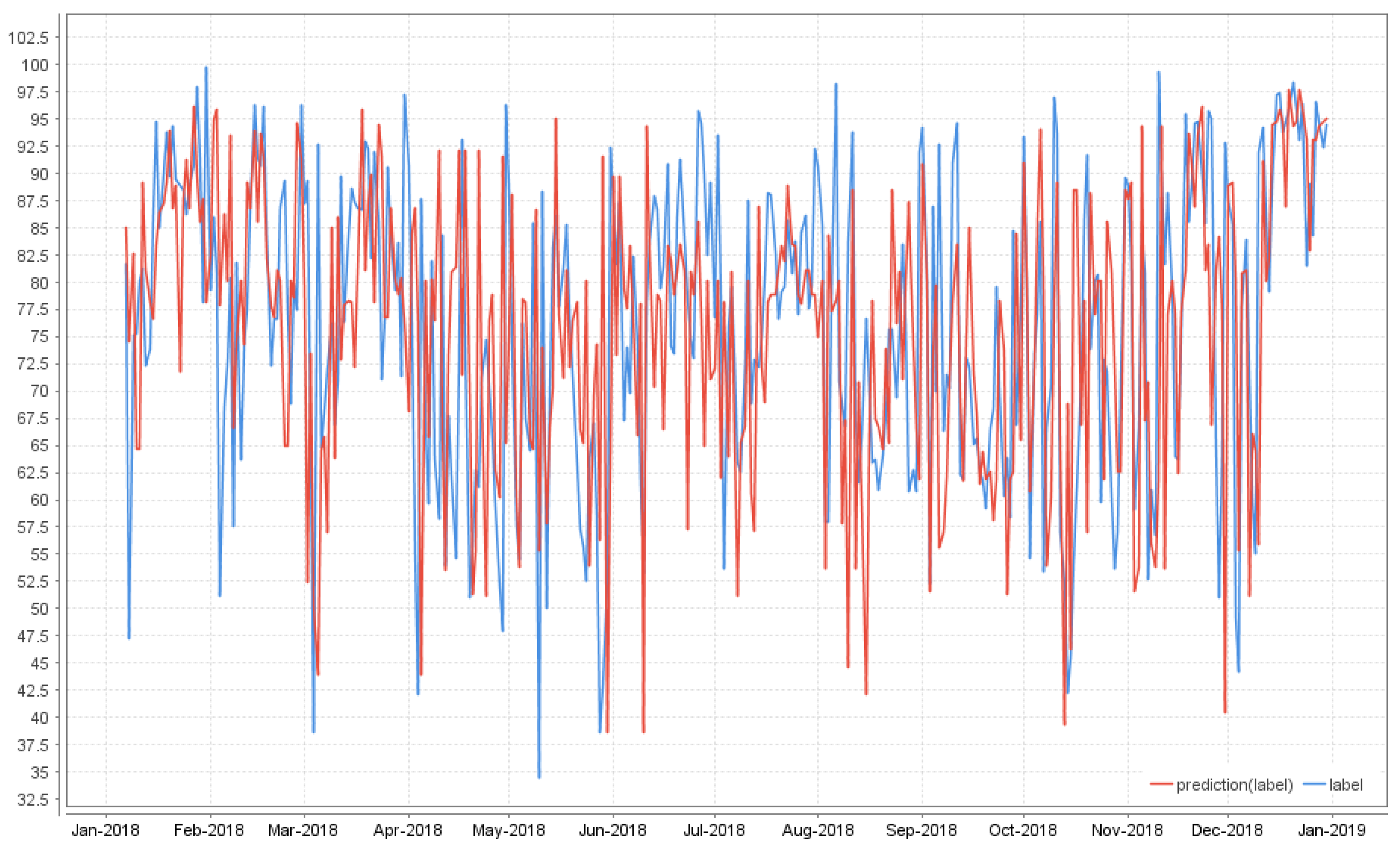
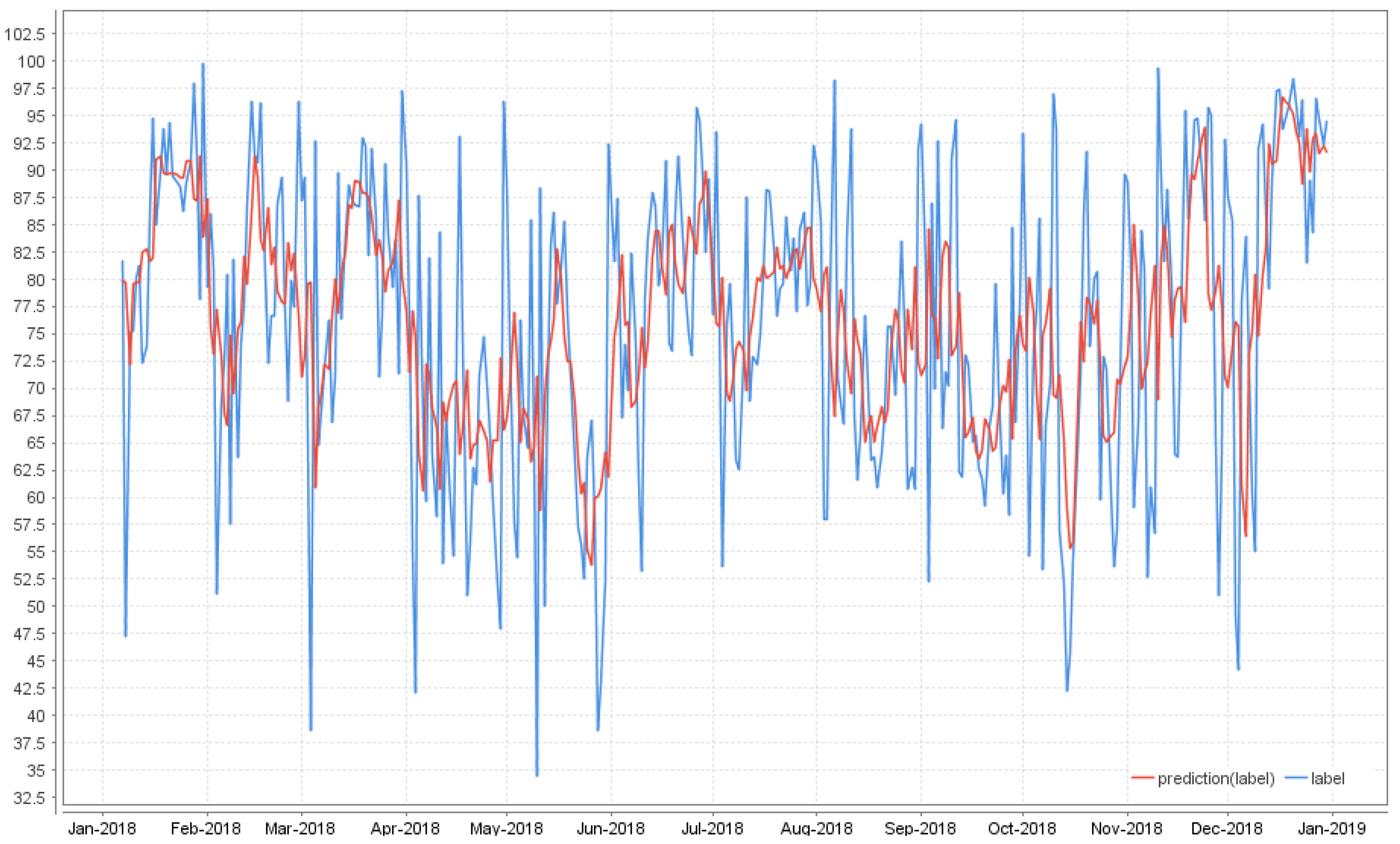
- k-NN, overall, has the smallest relative error, and it is a solid candidate when choosing a data mining technique, no matter the chosen scenario. The Spearman coefficient also provides the best results for both Canadian and Transylvanian data source when using k-NN.
- GBT offers a similar performance for all scenarios in terms of RE.
- Overall, for DT, both the RE report and the raking statistics show that the best results are obtained in the CADM + CDM 3 sources scenario and in the Collaborative with 3 sources scenario, emphasizing once again that the combination of the quality context data and collaborative sources available, would improve the results.
- for DL, the best result is obtained also in the CDM + 3 sources scenario from the RE perspective, but from the Spearman perspective, it proves that the data sources might influence the results.
3.2. Specific Scenario Results
4. Conclusions
- the possibility to embed the context of the main data source;
- the possibility to embed correlated data and apply machine learning techniques on all of them;
- allowing to test multiple variations of scenarios in a single run, without human intervention;
- rapid introduction of a new testing scenario, if needed;
- flexibility in easily adding a new machine learning algorithm to be tested;
- adding a new attribute to the context or to the correlated source is only a configuration task, not influencing the overall process.
Author Contributions
Funding
Conflicts of Interest
Abbreviations
| CADM | Context-aware data mining |
| CDM | Collaborative data mining |
| DL | Deep Learning |
| DT | Decision Tree |
| GBT | Gradient Boosted Tree |
| IoT | Internet of Things |
| k-NN | k-Nearest Neighbour |
| RE | Relative Error |
| RMSE | Root Mean Squared error |
| SVM | Support Vector Machine |
References
- Han, J.; Pei, J.; Kamber, M. Data Mining: Concepts and Techniques; Elsevier: Amsterdam, The Netherlands, 2011. [Google Scholar]
- Crisan, G.C.; Pintea, C.; Chira, C. Risk assessment for incoherent data. Environ. Eng. Manag. J. 2012, 11, 2169–2174. [Google Scholar] [CrossRef]
- Stahl, F.; Gaber, M.M.; Bramer, M.; Philip, S.Y. Pocket data mining: Towards collaborative data mining in mobile computing environments. IEEE Tools Artif. Intell. 2010, 2, 323–330. [Google Scholar]
- Correia, F.; Camacho, R.; Lopes, J.C. An architecture for collaborative data mining. In Proceedings of the KDIR 2010—International Conference on Knowledge Discovery and Information Retrieval, Valencia, Spain, 25–28 October 2010; SciTePress: Setubal, Portugal, 2010; pp. 467–470. [Google Scholar]
- Fenza, G.; Fischetti, E.; Furno, D.; Loia, V. A hybrid context aware system for tourist guidance based on collaborative filtering. In Proceedings of the IEEE International Conference on Fuzzy Systems (FUZZ-IEEE 2011), Taipei, Taiwan, 27–30 June 2011; pp. 131–138. [Google Scholar]
- Matei, O.; Anton, C.; Bozga, A.; Pop, P. Multi-layered architecture for soil moisture prediction in agriculture 4.0. In Proceedings of the Computers and Industrial Engineering, CIE, Lisboa, Portugal, 11–13 October 2017; Volume 2, pp. 39–48. [Google Scholar]
- Matei, O.; Anton, C.; Scholze, S.; Cenedese, C. Multi-layered data mining architecture in the context of Internet of Things. In Proceedings of the IEEE International Conference on Industrial Informatics, INDIN 2017, Emden, Germany, 24–26 July 2017; pp. 1193–1198. [Google Scholar]
- Weiser, M.; Gold, R.; Brown, J.S. The origins of ubiquitous computing research at PARC in the late 1980s. IBM Syst. J. 1999, 38, 693–696. [Google Scholar] [CrossRef]
- Bouquet, P.; Giunchiglia, F.; Van Harmelen, F.; Serafini, L.; Stuckenschmidt, H. C-owl: Contextualizing ontologies. In Proceedings of the 2nd International Semantic Web Conference, Sanibel Island, FL, USA, 20–23 October 2003; Springer: Berlin, Germany, 2003; pp. 164–179. [Google Scholar]
- Voida, S.; Mynatt, E.D.; MacIntyre, B.; Corso, G.M. Integrating virtual and physical context to support knowledge workers. IEEE Pervas. Comput. 2002, 1, 73–79. [Google Scholar] [CrossRef] [Green Version]
- Avram, A.; Matei, O.; Pintea, C.-M.; Pop, P.C.; Anton, C.A. Context-Aware Data Mining vs Classical Data Mining: Case Study on Predicting Soil Moisture. In Proceedings of the SOCO 2019, Advanced Computing and Systems for Security, Seville, Spain, 13–15 May 2019; Springer: Berlin, Germany, 2019; Volume 950, pp. 199–208. [Google Scholar]
- Anton, C.A.; Avram, A.; Petrovan, A.; Matei, O. Performance Analysis of Collaborative Data Mining vs Context Aware Data Mining in a Practical Scenario for Predicting Air Humidity. In Proceedings of the CoMeSySo 2019, Computational Methods in Systems and Software, Zlin, Czech Republic, 10–12 September 2019; Springer: Berlin, Germany, 2019; Volume 1047, pp. 31–40. [Google Scholar]
- Mladenic, D.; Lavrač, N.; Bohanec, M.; Moyle, S. Data Mining and Decision Support: Integration and Collaboration; Springer Science & Business Media: Berlin, Germany, 2003. [Google Scholar]
- Blockeel, H.; Moyle, S. Collaborative data mining needs centralised model evaluation. In Proceedings of the ICML-2002 Workshop on Data Mining Lessons Learned, Sydney, Australia, 8–12 July 2002; pp. 21–28. [Google Scholar]
- Anton, C.A.; Matei, O.; Avram, A. Collaborative data mining in agriculture for prediction of soil moisture and temperature. In Proceedings of the CSOC 2019, Advances in Intelligent Systems and Computing, Zlin, Czech Republic, 24–27 April 2019; Springer: Berlin, Germany, 2019; Volume 984, pp. 141–151. [Google Scholar]
- Matei, O.; Di Orio, G.; Jassbi, J.; Barata, J.; Cenedese, C. Collaborative data mining for intelligent home appliances. In Proceedings of the Working Conference on Virtual Enterprises, Porto, Portugal, 3–5 Ocotber 2016; Springer: Berlin, Germany, 2016; pp. 313–323. [Google Scholar]
- Dey, A.K. Understanding and using context. Pers. Ubiquit. Comput. 2001, 5, 4–7. [Google Scholar] [CrossRef]
- Lee, S.; Chang, J.; Lee, S.G. Survey and trend analysis of context-aware systems. Information 2011, 14, 527–548. [Google Scholar]
- Yang, S.J. Context aware ubiquitous learning environments for peer-to-peer collaborative learning. J. Educ. Tech. Soc. 2006, 9, 188–201. [Google Scholar]
- Stokic, D.; Scholze, S.; Kotte, O. Generic self-learning context sensitive solution for adaptive manufacturing and decision making systems. In Proceedings of the ICONS14 International Conference on Systems, Nice, France, 23–27 February 2014; pp. 23–27. [Google Scholar]
- Scholze, S.; Barata, J.; Stokic, D. Holistic context-sensitivity for run-time optimization of flexible manufacturing systems. Sensors 2017, 17, 455. [Google Scholar] [CrossRef] [Green Version]
- Perera, C.; Zaslavsky, A.; Christen, P.; Georgakopoulos, D. Context aware computing for the internet of things: A survey. IEEE Commun. Surv. Tut. 2013, 16, 414–454. [Google Scholar] [CrossRef] [Green Version]
- Scholze, S.; Kotte, O.; Stokic, D.; Grama, C. Context-sensitive decision support for improved sustainability of product lifecycle. In Proceedings of the Intelligent Decision Technologies, KES-IDT, Sesimbra, Portugal, 26–28 June 2013; Volume 255, pp. 140–149. [Google Scholar]
- Vajirkar, P.; Singh, S.; Lee, Y. Context-aware data mining framework for wireless medical application. In Proceedings of the International Conference on Database and Expert Systems Applications DEXA, Prague, Czech Republic, 1–5 September 2003; Springer: Berlin, Germany, 2003; Volume 2736, pp. 381–391. [Google Scholar]
- Marakas, G.M. Modern Data Warehousing, Mining, and Visualization: Core Concepts; Prentice Hall: Upper Saddle River, NJ, USA, 2003. [Google Scholar]
- Ziafat, H.; Shakeri, M. Using data mining techniques in customer segmentation. J. Eng. Res. App. 2014, 4, 70–79. [Google Scholar]
- Vashenyuk, E.; Balabin, Y.; Germanenko, A.; Gvozdevsky, B. Study of radiation related with atmospheric precipitations. Proc. ICRC Beijing 2011, 11, 360–363. [Google Scholar]
- Sitnov, S.; Mokhov, I.; Gorchakov, G. The link between smoke blanketing of European Russia in summer 2016, Siberian wildfires and anomalies of large-scale atmospheric circulation. In Doklady Earth Sciences; Springer: Berlin, Germany, 2017; Volume 472, pp. 190–195. [Google Scholar]
- Weather Prognosis. Available online: https://rp5.ru/ (accessed on 1 April 2020).
- Current and Historical Alberta Weather Station Data Viewer. Available online: http://agriculture.alberta.ca/acis/weather-data-viewer.jsp (accessed on 1 April 2020).
- Land, S.; Fischer, S. Rapid Miner 5. RapidMiner in Academic Use; Rapid-I GmbH: Dortmund, Germany, 2012. [Google Scholar]
- Hofmann, M.; Klinkenberg, R. RapidMiner: Data Mining Use Cases and Business Analytics Applications; CRC Press: Boca Raton, FL, USA, 2016. [Google Scholar]
- Kumar, R.; Balara, A. Time series forecasting of nifty stock market using Weka. Int. J. Res. Publ. Sem. 2014, 5, 1–6. [Google Scholar]
- Li, Y.; Yang, P.; Wang, H. Short-term wind speed forecasting based on improved ant colony algorithm for LSSVM. Cluster Comput. 2019, 22, 11575–11581. [Google Scholar] [CrossRef]
- Pintea, C.M.; Crisan, G.C.; Chira, C. Hybrid ant models with a transition policy for solving a complex problem. Logic J. IGPL 2011, 20, 560–569. [Google Scholar] [CrossRef]
- Nayak, J.; Vakula, K.; Dinesh, P.; Naik, B.; Mishra, M. Ant Colony Optimization in Data Mining: Critical Perspective from 2015 to 2020. In Innovation in Electrical Power Engineering, Communication, and Computing Technology; Springer: Belrin, Germany, 2020; pp. 361–374. [Google Scholar]
- Azzag, H.; Guinot, C.; Venturini, G. Data and text mining with hierarchical clustering ants. Stud. Comput. Intell. 2006, 34, 153–189. [Google Scholar]
- Koskela, T.; Varsta, M.; Heikkonen, J.; Kaski, K. Time series prediction using recurrent SOM with local linear models. Int. J. Knowl. Based Intell. Eng. Syst. 1998, 2, 60–68. [Google Scholar]
- Cunningham, P.; Delany, S.J. k-Nearest neighbour classifiers. Mult. Classif. Syst. 2007, 34, 1–17. [Google Scholar]
- Fawaz, H.I.; Forestier, G.; Weber, J.; Idoumghar, L.; Muller, P.A. Deep learning for time series classification: A review. Data Min. Knowl. Disc. 2019, 33, 917–963. [Google Scholar] [CrossRef] [Green Version]
- Yu, C.; Li, Y.; Xiang, H.; Zhang, M. Data mining-assisted short-term wind speed forecasting by wavelet packet decomposition and Elman neural network. J. Wind Eng. Ind. Aerod. 2018, 175, 136–143. [Google Scholar] [CrossRef]
- Geurts, P. Contributions to Decision Tree Induction: Bias/variance Tradeoff and Time Series Classification. Ph.D. Thesis, University of Liège, Liège, Belgium, 2002. [Google Scholar]
- Hyndman, R.J.; Athanasopoulos, G. Forecasting: Principles and Practice; OTexts: Melbourne, Australia, 2014. [Google Scholar]
- Abramowitz, M.; Stegun, I.A. Handbook of Mathematical Functions: With Formulas, Graphs, and Mathematical Tables; Dover Publications: Mineola, NY, USA, 1965. [Google Scholar]
- Hyndman, R.J.; Koehler, A.B. Another look at measures of forecast accuracy. Int. J. Forecast. 2006, 22, 679–688. [Google Scholar] [CrossRef] [Green Version]
- Dodge, Y. Spearman Rank Correlation Coefficient. The Concise Encyclopedia of Statistics; Springer: New York, NY, USA, 2008; pp. 502–505. [Google Scholar]
- Schmid, F.; Schmidt, R. Multivariate extensions of Spearman’s rho and related statistics. Stat. Probab. Lett. 2007, 77, 407–416. [Google Scholar] [CrossRef]
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Main Data | Context Attributes | Collaborative Sources | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| … | ||||||||||||||
| … | … | … | … | … | … | |||||||||
| val | val | val | val | val | val | val | val | val | ||||||
| val | val | val | val | val | val | val | ? | ? | ||||||
| val | val | val | val | val | ? | ? | ? | ? | ||||||
| val | val | val | ? | ? | val | val | val | val | ||||||
| val | val | val | ? | ? | ? | ? | val | val | ||||||
| val | val | val | ? | ? | ? | ? | ? | ? | ||||||
| Data Sources | Time Interval | Locations | Public Data |
|---|---|---|---|
| 6 locations in Transylvania, Romania | 01.01.2016 to 31.12.2018 | Sarmasu, Reghin, Targu Mures, Ludus, Blaj, Dumbraveni | website [29] |
| 4 locations in Alberta Province, Canada | 01.05.2018 to 01.04.2020 | Breton, St. Albert, Tomahawk, Leedale | website [30] |
| Campeni | Sarmasu | TMures | Reghin | Ludus | Blaj | Dumbraveni | |
|---|---|---|---|---|---|---|---|
| Campeni | 1 | 0.751 | 0.743 | 0.651 | 0.729 | 0.785 | 0.741 |
| Sarmasu | 0.751 | 1 | 0.902 | 0.880 | 0.931 | 0.867 | 0.858 |
| TMures | 0.743 | 0.902 | 1 | 0.861 | 0.869 | 0.886 | 0.920 |
| Reghin | 0.651 | 0.880 | 0.861 | 1 | 0.886 | 0.983 | 0.845 |
| Ludus | 0.729 | 0.993 | 0.867 | 0.996 | 1 | 0.784 | 0.845 |
| Blaj | 0.785 | 0.867 | 0.886 | 0.983 | 0.784 | 1 | 0.896 |
| Dumbraveni | 0.741 | 0.858 | 0.920 | 0.845 | 0.845 | 0.896 | 1 |
| Activation: Tanh | Activation: Rectifier | Activation: ExpRectifier | |||
|---|---|---|---|---|---|
| Epochs | RE | Epochs | RE | Epochs | RE |
| 2 | 0.163572675 | 2 | 0.135942805 | 2 | 0.145482752 |
| 4 | 0.158022918 | 4 | 0.146780326 | 4 | 0.175774121 |
| 6 | 0.157398315 | 6 | 0.182660829 | 6 | 0.172397822 |
| 8 | 0.174560711 | 8 | 0.192005928 | 8 | 0.184494165 |
| 10 | 0.159373990 | 10 | 0.121232879 | 10 | 0.136397852 |
| 15 | 0.175305445 | 15 | 0.186658629 | 15 | 0.173097985 |
| k-NN | GBT | DT | DL | ||||
|---|---|---|---|---|---|---|---|
| k: | 5 | Number of Trees: | 50 | Maximal depth: | 4 | Activation: | Rectifier |
| Measure: | Euclidean | Maximal depth: | 7 | Minimal gain: | 0.01 | Epochs: | 5 |
| distance | Learning rate: | 0.01 | Minimal leaf size: | 2 | |||
| Number of bins: | 20 | ||||||
| Predicted | Context | Correlated Source 1 | Correlated Source 2 | Correlated Source 3 | Scenario |
|---|---|---|---|---|---|
| H_Sarmasu | T_Sarmasu | H_Reghin | H_TMures | H_Ludus | CADM+CDM 3 sources |
| H_Sarmasu | T_Sarmasu | H_Reghin | H_TMures | ? | CAD+CDM 2 sources |
| H_Sarmasu | T_Sarmasu | H_Reghin | ? | ? | CADM+CDM 1 source |
| H_Sarmasu | T_Sarmasu | ? | ? | ? | CADM |
| H_Sarmasu | ? | H_Reghin | H_TMures | H_Ludus | CDM 3 sources |
| H_Sarmasu | ? | ? | ? | ? | Standalone |
| H_TMures | T_TMures | H_Reghin | H_Sarmasu | H_Ludus | CADM+CDM 3 sources |
| H_TMures | T_TMures | H_Reghin | H_Sarmasu | ? | CADM+CDM 2 sources |
| H_TMures | T_TMures | H_Reghin | ? | ? | CADM+CDM 1 source |
| H_TMures | T_TMures | ? | ? | ? | CADM |
| H_TMures | ? | H_Reghin | H_Sarmasu | H_Ludus | CDM 3 sources |
| H_TMures | ? | ? | ? | ? | Standalone |
| Data Source | Scenario | DL | DT | GBT | kNN |
|---|---|---|---|---|---|
| Transylvania | CADM | 0.80982 | 0.74204 | 0.87051 | 0.81566 |
| Transylvania | CADM + CDM 1 source | 0.84593 | 0.73765 | 0.88172 | 0.82123 |
| Transylvania | CADM + CDM 2 sources | 0.85932 | 0.75500 | 0.89184 | 0.81689 |
| Transylvania | CADM + CDM 3 sources | 0.86358 | 0.76217 | 0.87103 | 0.83141 |
| Transylvania | Standalone | 0.82657 | 0.72264 | 0.87448 | 0.81372 |
| Transylvania | CDM + 3 sources | 0.83730 | 0.76077 | 0.87631 | 0.81345 |
| Canada | CADM | 0.61548 | 0.83449 | 0.87627 | 0.87236 |
| Canada | CADM + CDM 1 source | 0.73143 | 0.83447 | 0.87627 | 0.87513 |
| Canada | CADM + CDM 2 sources | 0.66200 | 0.83450 | 0.87412 | 0.87429 |
| Canada | CADM + CDM 3 sources | 0.70211 | 0.89523 | 0.86505 | 0.90480 |
| Canada | Standalone | 0.72011 | 0.80276 | 0.87412 | 0.86220 |
| Canada | CDM + 3 sources | 0.66265 | 0.83450 | 0.89818 | 0.88124 |
| Alg | Value | Standard Deviation | Standard Deviation(%) |
|---|---|---|---|
| k-NN | 0.138381577 | 0.026396991 | 19.08 |
| DL | 0.148357962 | 0.02705544 | 18.24 |
| GBT | 0.147488567 | 0.019781613 | 13.41 |
| DT | 0.150515614 | 0.033728874 | 22.41 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Avram, A.; Matei, O.; Pintea, C.; Anton, C. Innovative Platform for Designing Hybrid Collaborative & Context-Aware Data Mining Scenarios. Mathematics 2020, 8, 684. https://doi.org/10.3390/math8050684
Avram A, Matei O, Pintea C, Anton C. Innovative Platform for Designing Hybrid Collaborative & Context-Aware Data Mining Scenarios. Mathematics. 2020; 8(5):684. https://doi.org/10.3390/math8050684
Chicago/Turabian StyleAvram, Anca, Oliviu Matei, Camelia Pintea, and Carmen Anton. 2020. "Innovative Platform for Designing Hybrid Collaborative & Context-Aware Data Mining Scenarios" Mathematics 8, no. 5: 684. https://doi.org/10.3390/math8050684
APA StyleAvram, A., Matei, O., Pintea, C., & Anton, C. (2020). Innovative Platform for Designing Hybrid Collaborative & Context-Aware Data Mining Scenarios. Mathematics, 8(5), 684. https://doi.org/10.3390/math8050684