Total Least-Squares Collocation: An Optimal Estimation Technique for the EIV-Model with Prior Information

{kind=link}
Abstract
:1. Introduction
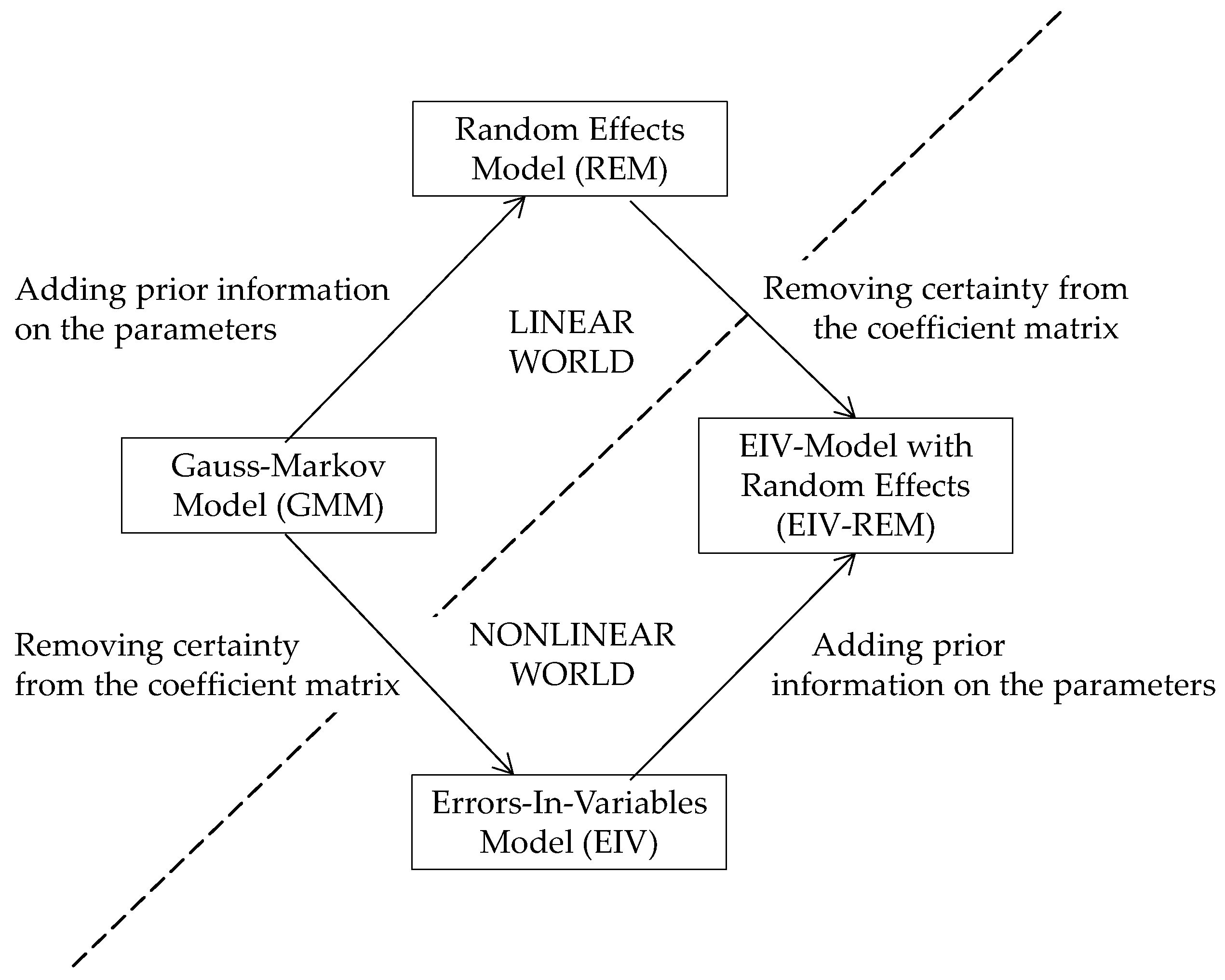
- the GMM after weakening the coefficient matrix through the replacement of fixed entries by observed data, resulting in the (nonlinear) Errors-In-Variables (EIV) Model. When nonlinear normal equations are formed and subsequently solved by iteration, the resulting estimation technique has been termed “Total Least-Squares (TLS) estimation” [5,6,7]. The alternative approach, based on iteratively linearizing the EIV-Model, will lead to identical estimates of the parameters [8].
2. A Compact Review of the “Linear World”
2.1. The (linearized) Gauss-Markov Model (GMM)
- the matrix of coefficients (given),
- the vector of (incremental) parameters (unknown),
- the vector of random errors (unknown) with expectation while the dispersion matrix is split into the (unknown) factor
- as variance component (unit-free) and
- as (homogeneized) symmetric and positive-definite “cofactor matrix” whose inverse is better known as “weight matrix” ; here for the sake of simplicity.
2.2. The Random Effects Model (REM)
3. An Extension into the “Nonlinear World”
3.1. The Errors-In-Variables (EIV) Model
3.2. A New Model: The EIV-Model with Random Effects (EIV-REM)
4. Conclusions and Outlook
- EIV-REM becomes the REM if ,
- EIV-REM becomes the EIV-Model if ,
- EIV-REM becomes the GMM if both and .
Funding
Conflicts of Interest
References
- Rao, C.R. Estimation of parameters in a linear model. Ann. Statist. 1976, 4, 1023–1037. [Google Scholar] [CrossRef]
- Koch, K.-R. Parameter Estimation and Hypothesis Testing in Linear Models; Springer: Berlin/Heidelberg, Germany, 1999; p. 334. [Google Scholar]
- Moritz, H. A generalized least-squares model. Studia Geophys. Geodaet. 1970, 14, 353–362. [Google Scholar] [CrossRef]
- Schaffrin, B. Model Choice and Adjustment Techniques in the Presence of Prior Information; Technical Report No. 351; The Ohio State University Department of Geodetic Science and Survey: Columbus, OH, USA, 1983; p. 37. [Google Scholar]
- Golub, G.H.; van Loan, C.F. An analysis of the Total Least-Squares problem. SIAM J. Numer. Anal. 1980, 17, 883–893. [Google Scholar] [CrossRef]
- Van Huffel, S.; Vandewalle, J. The Total Least-Squares Problem: Computational Aspects and Analysis; SIAM: Philadelphia, PA, USA, 1991; p. 300. [Google Scholar]
- Schaffrin, B.; Wieser, A. On weighted Total Least-Squares adjustment for linear regression. J. Geod. 2008, 82, 415–421. [Google Scholar] [CrossRef]
- Schaffrin, B. Adjusting the Errors-In-Variables model: Linearized Least-Squares vs. nonlinear Total Least-Squares procedures. In VIII Hotine-Marussi Symposium on Mathematical Geodesy; Sneeuw, N., Novák, P., Crespi, M., Sansó, F., Eds.; Springer International Publishing: Cham, Switzerland, 2015; pp. 301–307. [Google Scholar]
- Schaffrin, B. Total Least-Squares Collocation: The Total Least-Squares approach to EIV-Models with prior information. In Proceedings of the 18th International Workshop on Matrices and Statistics, Smolenice Castle, Slovakia, 23–27 June 2009. [Google Scholar]
- Snow, K.; Schaffrin, B. Weighted Total Least-Squares Collocation with geodetic applications. In Proceedings of the SIAM Conference on Applied Linear Algebra, Valencia, Spain, 18–22 June 2012. [Google Scholar]
- Schaffrin, B.; Snow, K. Progress towards a rigorous error propagation for Total Least-Squares estimates. J. Appl. Geod. 2020. accepted for publication. [Google Scholar] [CrossRef]
- Grafarend, E.; Schaffrin, B. Adjustment Computations in Linear Models; Bibliographisches Institut: Mannheim, Germany; Wiesbaden, Germany, 1993; p. 483. (In German) [Google Scholar]
- Harville, D.A. Using ordinary least-squares software to compute combined intra-interblock estimates of treatment contrasts. Am. Stat. 1986, 40, 153–157. [Google Scholar]
- Amiri-Simkooei, A.R.; Zangeneh-Nejad, F.; Asgari, J. On the covariance matrix of weighted Total Least-Squares estimates. J. Surv. Eng. 2016, 142. [Google Scholar] [CrossRef] [Green Version]
- Schaffrin, B.; Snow, K. Towards a more rigorous error propagation within the Errors-In-Variables Model for applications in geodetic networks. In Proceedings of the 4th Joint International Symposium on Deformation Monitoring (JISDM 2019), Athens, Greece, 15–17 May 2019. electronic proceedings only. [Google Scholar]
- Schaffrin, B.; Snow, K.; Neitzel, F. On the Errors-In-Variables Model with singular dispersion matrices. J. Geod. Sci. 2014, 4, 28–36. [Google Scholar] [CrossRef]

© 2020 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Schaffrin, B. Total Least-Squares Collocation: An Optimal Estimation Technique for the EIV-Model with Prior Information. Mathematics 2020, 8, 971. https://doi.org/10.3390/math8060971
Schaffrin B. Total Least-Squares Collocation: An Optimal Estimation Technique for the EIV-Model with Prior Information. Mathematics. 2020; 8(6):971. https://doi.org/10.3390/math8060971
Chicago/Turabian StyleSchaffrin, Burkhard. 2020. "Total Least-Squares Collocation: An Optimal Estimation Technique for the EIV-Model with Prior Information" Mathematics 8, no. 6: 971. https://doi.org/10.3390/math8060971
APA StyleSchaffrin, B. (2020). Total Least-Squares Collocation: An Optimal Estimation Technique for the EIV-Model with Prior Information. Mathematics, 8(6), 971. https://doi.org/10.3390/math8060971