1. Introduction
There are many situations in which empirical data show slight or marked asymmetry. This is frequently the case, for example, with actuarial and financial data which, in addition to this feature, have heavy tails reflecting the existence of extreme values. The se features mean that the data can not be adequately modeled by the Gauss (or normal) distribution. Furthermore, bimodal distributions appear naturally in many different scenarios. For example, in certain disease patterns, as well as in certain cancer incidence curves. Behind the bimodality (and multimodality as well) of some cancer incidence curves, and their study, clinicians can improve their understanding of cancer, the development process as well as the potential characteristics that identify cancer and that separate a particular type of cancer of all other types. This occurs, for example, in cases where there are two peaks of occurrence per age. The se cancers include Kaposi’s sarcoma and Hodgkin’s lymphoma. The latter type of cancer has two peaks of occurrence: in young people adults and middle-aged adults. On the other hand, the normal skew distribution appears naturally in stochastic frontier analysis when a normal distribution is assumed to represent the noise or idiosyncratic component and a half-normal distribution to represent the inefficiency term, in the event that the researcher imposes inefficient behavior on all firms in the sample of interest. See, for instance [
1]. Recently, [
2] introduces (using a finite mixture model) the zero inefficiency stochastic frontier model which can accommodate the presence of both efficient and inefficient firms in the sample by appearing various bimodal scenarios. The refore, it seems plausible to try to obtain families of distributions that incorporate bias to the normal distribution but that at the same time are more versatile in the sense of being able to adapt to the bimodal scenario that appears in different situations.
Although there are various mechanisms to obtain skewed distributions from an initial that is not skewed, (Two well-known procedures that allow to generalize an initial probability distribution, symmetric or not, are those provided in the works of [
3,
4], among others). Our attention here will focus on the mechanism for this purpose introduced by [
5], which enjoys an undoubted popularity and has been the subject of research in numerous works. Let
g and
G be, respectively, the probability density function (pdf) and the cumulative distribution function (cdf) of a symmetric distribution. A random variate
Z is said to have a skew distribution if its pdf is given by
This family of distributions has been widely studied as an extension of the normal distribution by means of a shape parameter,
, which accounts for the skewness. In this case
g and
G are replaced in Equation (
1) by the pdf and cdf of the standard normal distribution and the resulting distribution is called the skew normal distribution. It should be pointed out that the function
g does not have to be precisely the derivative of the cdf
G to ensure that the pdf given in Equation (
1) is a genuine pdf, although this case has not been studied in depth in the statistical literature. Following the notation provided in Reference [
6] we denote the family of distributions given by
, where
and
are the pdf and cdf of the standard normal distribution, respectively, by
. Furthermore, when a random variable follows a skew normal distribution with location parameter
and scale parameter
we will write SN
.
In this article, a new generalization of the family of skew distributions given in Equation (
1) is proposed, which also includes the skew family of distributions of Azzalini as a particular case; that is, the expression (
1). The methodology used is based on the combination of Azzalini’s proposal and a result provided by [
7] which led us to add a new parameter to the family (
1). Later, from this new family a second family, very similar to the first, is introduced. This new family of distributions can exhibit bimodality and its standardized fourth central moment (kurtosis) can be lower than the kurtosis of the Azzalini skew normal distribution (and can be positive or negative).
In recent decades, starting from Azzalini’s proposal, several generalizations and extensions of the skew-normal distribution have been introduced (see for example [
8]). For multivariate extensions, see References [
9,
10,
11], among others. The methods applied in the present paper can be considered as extensions and alternatives to the well-known skew-normal distribution (see [
5,
12]), whose properties (see [
12,
13]), and corresponding estimation [
14] have been widely discussed. Other ways of obtaining skewed normal distributions have also been introduced, such as the one proposed by Reference [
15], the Balakrishnan skew-normal density in Reference [
16], the proposed model of Reference [
17] and the generalized normal distribution in References [
18,
19,
20], among others. For an exhaustive and comprehensive study of the skew-normal distribution, see the recent book by Reference [
21].
The class of probability models proposed in the present paper can also be considered as alternatives or as approximations to the usual collective risk models in actuarial settings (see [
22,
23] among others). Data sets in these settings are typically skewed and the generalized models of the present paper expected to provide better fits than the standard models. In collective risk settings the right tail of the distribution is of considerable interest since the likelihood of large claims is of concern. In addition, the total claim distribution is of interest. Normal approximations are frequently resorted to when dealing with these variables. The use of more flexible generalized normal models can be expected to yield improvement.
The organization of this paper is as follows. The main result from which we constructed the two proposed families is shown in
Section 2. Due to the importance that the normal distribution plays in numerous problems of applied statistics we dedicate a complete section,
Section 3, to the study of this distribution. For this purpose, the pdf, which appears in closed form, is shown for the two families. We also give expressions for the mean, variance and the third and fourth standardized cumulant, to compare with their equivalents corresponding to the classical (Azzalini) skew normal distribution. In
Section 4, the parameter estimation problem is studied. In order to obtain numerical solutions to the maximum likelihood (ML) estimation problem, suitable software has to be used. Multivariate extensions are described briefly in
Section 5. Some examples and applications are described in
Section 6. Finally, some conclusions are drawn and promising fields for further research are proposed in the last Section.
3. The Normal Distribution Case
Of greater interest, because it is expressed in a simpler formulation, is the pdf obtained from Equation (
6) when
g and
G are replaced by the pdf and cdf of the standard normal distribution, respectively. This is given by
In the folowing discussion, when a random variate
X has its pdf given by Equation (
10) it will be denoted by
.
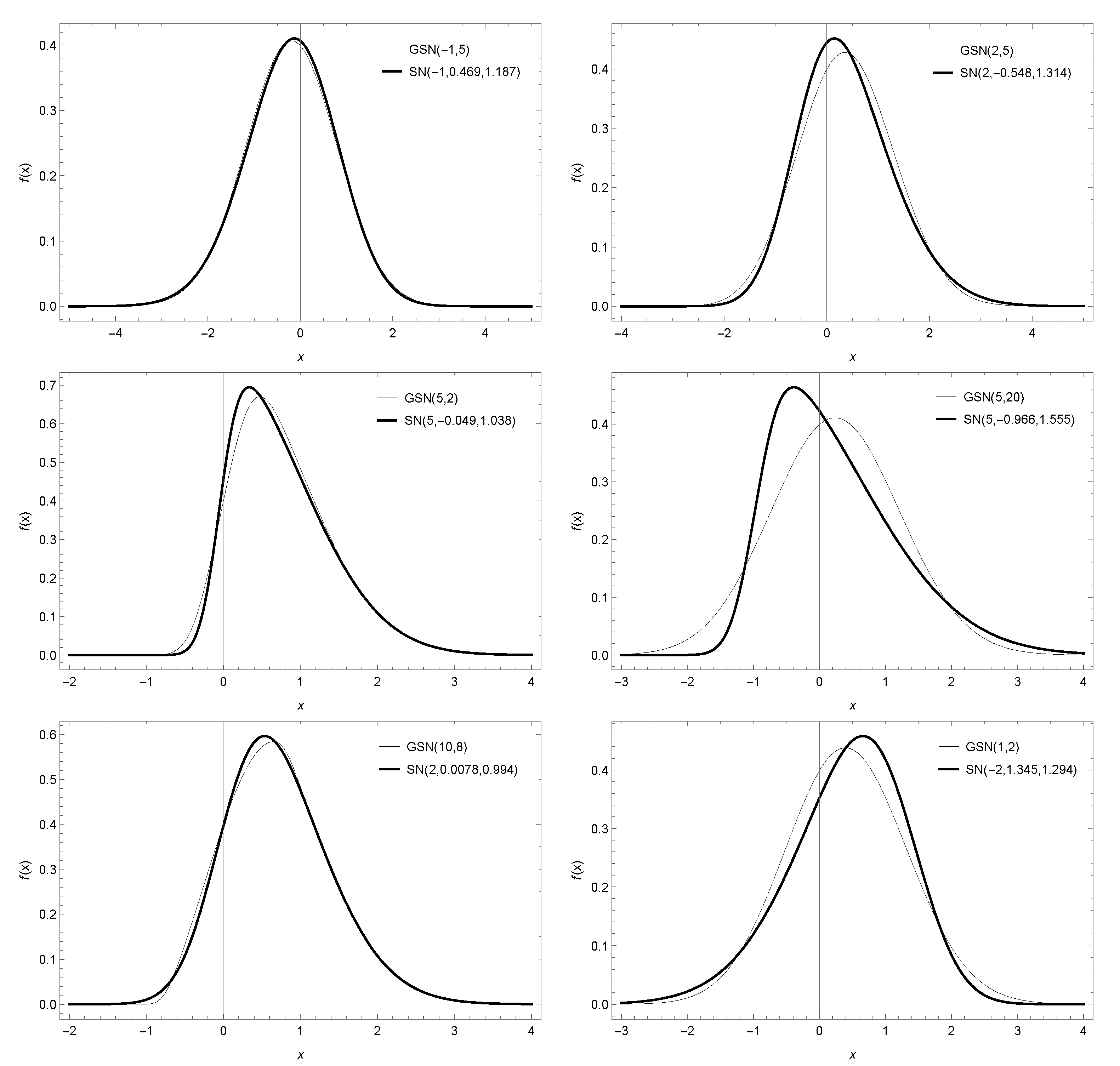
Figure 2 show some graphs of this pdf and the corresponding skew normal pdf with the same mean and variance. (In this case, the skew parameter
of the SN distribution has been set so that, once equal to the mean and variance of the new distribution, the values of
and
were obtained numerically so that both distributions should have the same mean and the same variance. It can be seen that the new model is very versatile and that the value of the parameters provide a distribution which can exhibit unimodality and bimodality. Again, as with
Figure 1, the distribution can take approximately the same shape as the normal skew distribution with fewer parameter).
We next provide the moment generating function of the family given in Equation (
10).
Proposition 3. The moment generating function of a random variable X having its pdf given by Equation (10) is of the formwhere Proof. It is straightforward following the same argument as the one used in Reference [
5] in order to get the moment generating function of the skew-normal distribution. □
Moments can then be readily obtained by differentiation of Equation (
11). In particular, the mean and variance are given by
where
.
Table 1 shows the mean and variance of the proposed distribution and the corresponding ones for the skew normal distribution for some special cases of parameters. Similar to case of the skew normal distribution, it can be verified that
. Another important property that
shares with the skew normal distribution is that if
then
for all values of
and
. In complete moments can also be studied following the work of Reference [
31]. The third (skewness) and fourth (kurtosis) standardised cumulants are given by,
where
and
and
are given by Equations (
12) and (13), respectively. Comparisons of these values with the standard skew normal distribution are shown in
Table 2. As can be seen, the standardized fourth central moment (kurtosis) can be lower for the GSN distribution than it is for Azzalini’s skew normal distribution.
Let denote the cdf of .
Proposition 4. If , then its cdf is given bywhere is the Owen’s function see [32] given by Proof. The proof is direct by applying result B.21 in Reference [
21]. □
Proposition 5. If , then it follows that:
.
.
.
Proof. The proof is also direct this time by applying the result B.23 in [
21]. □
To end this Section we provide a result related to probability transformations which generalises a result appearing in Reference [
5] and provided also in Reference [
31].
Proposition 6. Let W and Z be independent random variables with distribution and , respectively. The n, the random variable , where , follows a , where and .
Proof. It can be proved following the same argument as that used in Lemma 1 in Reference [
31]. □
4. Estimation
The family of distributions
can be generalized by means of a linear transformation in order to introduce a location and a scale parameter adding more flexibility to the model (
10). We thus will consider the location-scale generalization of the skew-normal distribution defined as the distribution of
, where
given in Equation (
10), where
and
. Its pdf is given by
When
this pdf reduces to the
and when
to the
. For a sample
we can estimate the four parameters,
, of the model given in Equation (
14) by a direct search for the maximum of the log-likelihood surface given by
From Equation (
15) we get the normal equations which are given by:
where
and
Since it is not possible to obtain closed expressions for the maximum likelihood estimators, algorithms based on numerical methods, such as Newton-Raphson or Broyden-Fletcher-Goldfarb-Sanno (BGGS), among others, will have to be used. It is recommended to use different seed points as initial values to ensure that the solution obtained constitutes a global maximum of the logarithm-likelihood function.
The standard errors of the estimators can be obtained by inverting the Hessian matrix. Both Mathematica and WinRats have at least two methods for this purpose. The first is to use Cholesky factors (this package is available on the web upon request). The second, faster method, involves by finite differentiation. Furthermore, WinRats package also offers the possibility to get the maximum of the log-likelihood directly giving us the elements of the Fisher information matrix. In fact, for the examples considered later these two packages were used to get the maximum likelihood estimators in a fast way.
6. Numerical Illustrations
In this section, three examples for the GSN model given in Equation (
14) are carried out and the results are compared with the flexible epsilon skew-normal (FESN) model introduced by Reference [
33] in the first example, with the mixture of two normals (MN) model in the second example and flexible skew-normal (FSN) model introduced by Reference [
34] in the third example. The three densities respectively are given by:
where and denote the density and distribution functions of the standard normal distribution, , , , and .
We use these three models, since they have been used in the applied statistics literature to explain bimodal empirical data. We chose the MN model since it is a classic model that is used to model bimodal data sets, we chose the FESN model since it is one of the first bimodal extensions of the family of epsilon-skew-simétric distributions and We chose the FSN model since it is one of the first bimodal extensions of the family of skew-simétric distributions.
6.1. Example 1
The data in this example is a set of fiber levels for 315 patients and is available online at
http://Lib.stat.cmu.edu/datasets/Plasma_Retinol and contains values for 14 variables for each patient. For our analysis we will use only the variable called Fiber (Grams of fiber consumed per day). Low levels of this variable may be associated with higher risk of certain types of cancer. Descriptive statistics for the data set are displayed in
Table 3. In the table
and
denote sample skewness and kurtosis coefficients. Note that the data exhibits a high level of kurtosis.
The estimated values of the parameters for the two models are shown in
Table 4 together with the standard errors (SE) in parentheses. The table also includes the maximum of the log-likelihood function (
), the Akaike information criterion (AIC) and the consistent Akaike information criterion (CAIC), proposed in References [
35,
36] respectively. Amodel with a lower AIC or CAIC is preferred to a model with a higher value.
Graphs of histogram of the data and fitted densities are given in
Figure 4. As it can be seen, the GSN distribution is the better of the two models with regard to reflecting the nature of the empirical data. All computations here were done using Mathematica v.11.0 and WinRATS v.7.0. These codes are available from the authors upon request.
6.2. Example 2
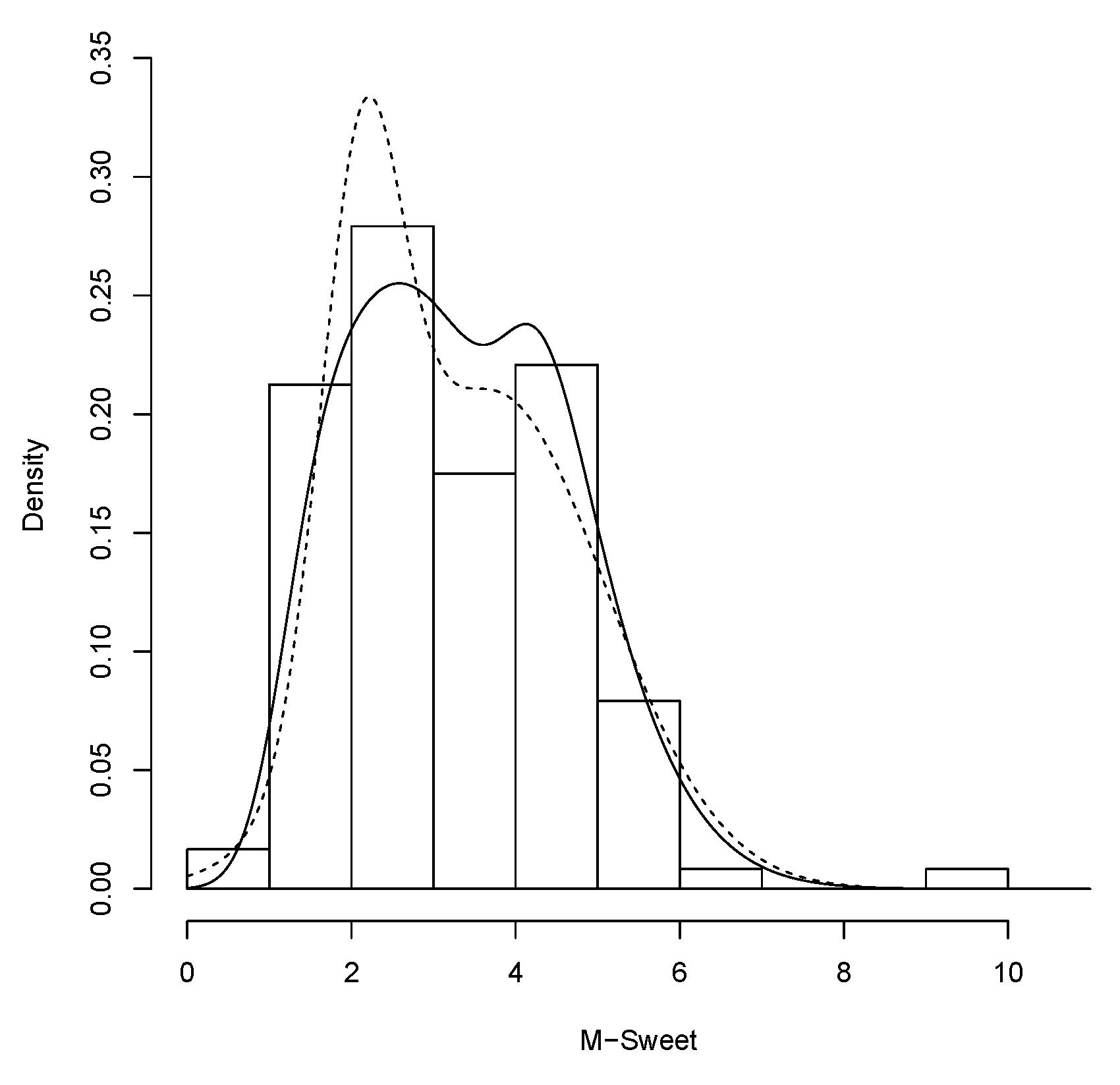
Table 5 shows summary statistics for the M-Sweet dataset.
In
Table 6, presents parameter estimates (SE) for both, the MN and GSN models. It can be seen that the log-likelihood for the GSN model is higher than the for the MN model. The AIC and CAIC criterion are used again to compare the estimated models, it can be seen that the GSN model presents the best fit (smallest AIC and CAIC values).
Finally, the histogram of the data and the fitted densities are shown in
Figure 5.
6.3. Example 3
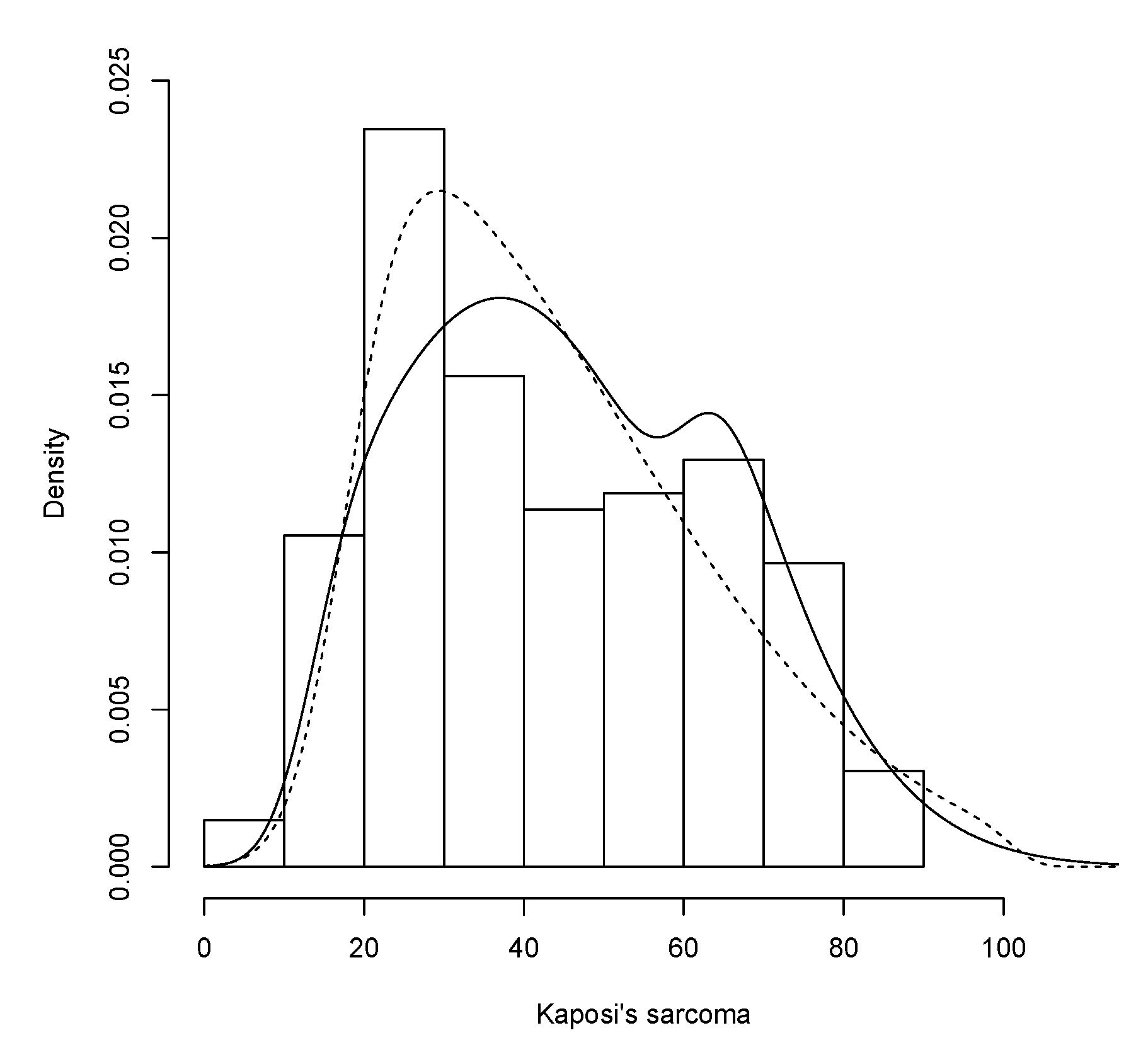
Finally, data corresponding to the age and frequency of cancer cataloged as Kaposi’s sarcoma have been taken. This is a type of cancer that can form masses in the skin, lymph nodes, or other organs without distinguishing the sub-types. The data has been collected from the website of the Office for National Statistics (ONS, section Health statistics) and it can be seen in
Table A1 in the
Appendix A. It can be observed that there is a higher incidence in individuals with an age around 25 years as well as for those with an age around 60 years. The se records were taken during the years 1995–2016 and correspond to different regions of the United Kingdom.
Table 7 shows summary statistics for the Kaposi’s sarcoma dataset.
The two fitted models are represented in
Figure 6 and the correspondent estimated values can be seen in
Table 8. The GSN model presents better fit for the data, since the AIC and CAIC values are smaller.






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}





