In this section, we introduce the simulated data used for model development and propose two methods for detecting defects in TEM images of GaAs. We specifically consider defect detection using high-resolution transmission electron microscopy (HRTEM) images, hereafter referred to as TEM images. The first method involves using PCA and reconstruction error, measured by mean squared error (MSE), to detect defects. The second method involves using PCA in combination with a weakly supervised CNN classification model to detect defects. Both models are trained using simulated TEM images of GaAs samples that are free of defects and then used to determine the location of a point defect in a simulated image of a GaAs sample. For each of the models, we consider the case when imaging noise is present and when there is no imaging noise.
2.1. Data Processing
The first step in developing a model for predicting the location of point defects is to generate simulated TEM images. We note that atomic resolution TEM imaging is performed in two different modes, wherein the electron beam is in parallel illumination (conventional high-resolution transmission electron microscopy) or as a focused probe (scanning transmission electron microscopy). The present work is based on parallel beam mode, since images simulated for this mode exhibits widely varying patterns for different imaging conditions, providing a large dataset for training and testing purposes. However, the results are also applicable to focused probe mode images. TEM images for GaAs were simulated using the TempasTM software. The TempasTM software has been developed in collaboration with the Material and Manufacturing Directorate, Air Force Research Lab (AFRL) and AFRL has validated the simulation results against experimental images of GaAs. The output of the simulation for a crystal projected along the [110] zone axis for TEM accelerating voltage of 300 kV and up to specimen thickness of 15 nm. The imaging parameters for the objective lens were set such that the spherical aberration coefficient was −15 μm and defocus ranging from −20 nm to +20 nm.
Ideally, experimental data would be used for this study, but due to the difficulty in acquiring experimental data, we use simulated TEM images to train and test our defect detection models. The use of simulated data is a start towards developing a method that can be trained directly on experimental data. A key consideration, then, is an understanding of the extent to which we can control defects in experimental images. As discussed earlier, it is possible to produce experimental GaAs samples that are defect-free so we assume it is feasible to acquire experimental TEM images that are known to be defect-free. In contrast, when defects, such as dopants, are added to experimental GaAs samples during the production process, the true locations of the dopant atoms in the GaAs sample are unknown. Thus, it is infeasible to generate a set of TEM images for which we know the true location of the point defects. The lack of knowledge about the true location of the defects in an experimental image is crucial. In light of this lack of defect truth data, the goal is to develop a defect detection method that is trained solely on defect-free TEM images.
Our dataset consists of simulated TEM images of GaAs using 8 different thickness conditions and 21 different defocus conditions. The thickness is varied from 1 nm to 15 nm in 2 nm steps. The defocus condition ranges from −20 nm to 20 nm in 2 nm steps. Thus, there are a total of 168 unique imaging conditions. These 168 imaging conditions are split into a set of 112 train conditions (66%) and 56 test conditions (33%). The splitting of the train and test conditions is done in a nonrandom manner. A third of the defocus conditions, {−18 nm, −12 nm, −6 nm, 0 nm, +6 nm, +12 nm, +18 nm}, are assigned to the test set and the remaining are assigned to the training set. The imaging conditions have a significant impact on the resulting TEM image so splitting on the imaging conditions ensures that model performance generalizes beyond conditions only in the set of training conditions. For the remainder of the paper, we refer to these sets as the train and test conditions.
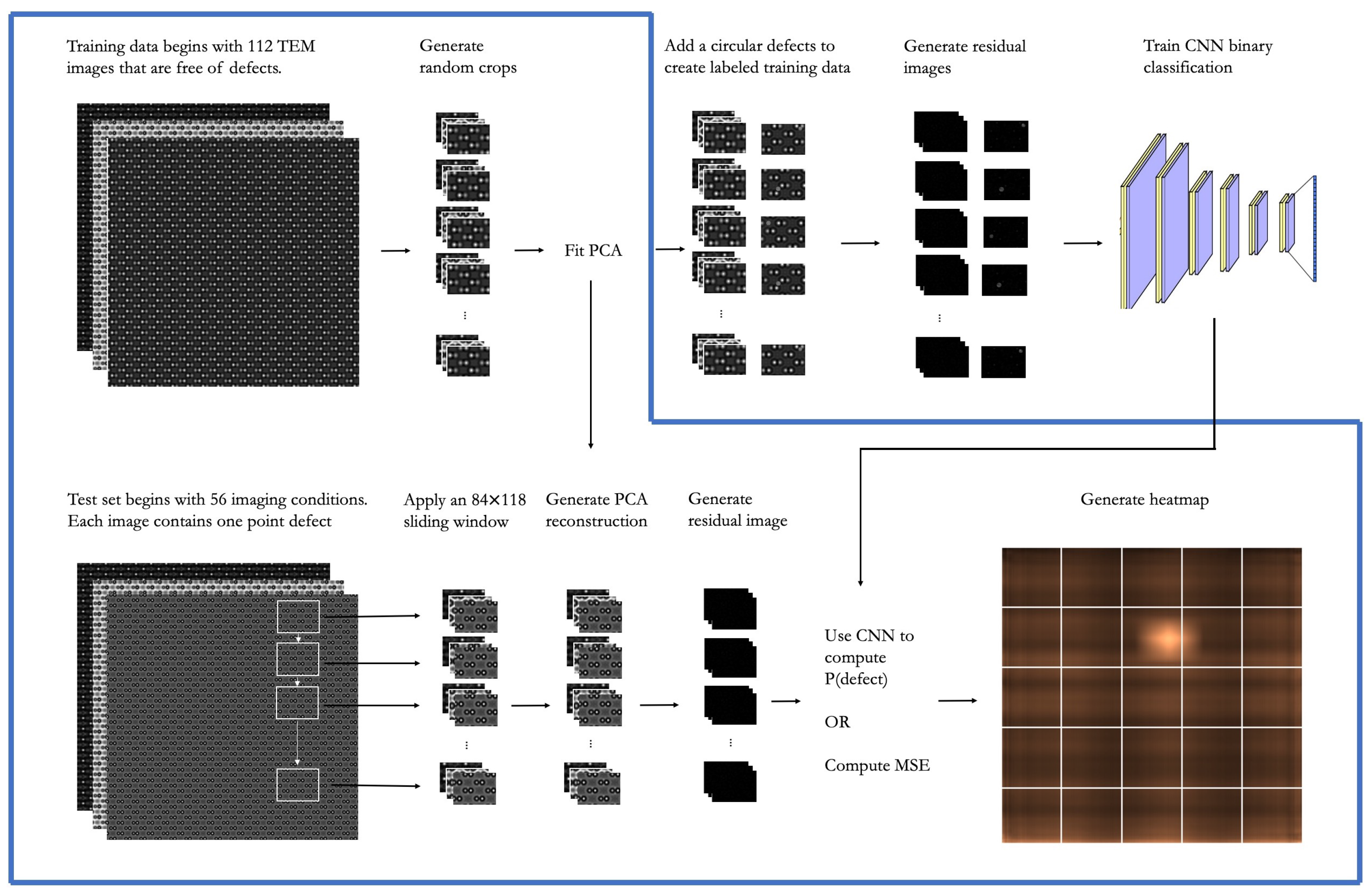
We use the train and test conditions to further generate the training and tests data for our models. For each of the 112 train conditions, we simulate a single TEM image of dimension 1007 × 1024. The image is represented as a matrix of dimension 1007 × 1024 where each entry represents a grayscale pixel value. Since the TEM image consists of a repeating lattice structure, we choose to analyze the TEM images in smaller segments of dimension 84 × 118. Each of these image segments is large enough to include two sets of GaAs pairs in both the vertical and horizontal direction. At the same time, these image segments are small enough such that accurately identifying the presence of a defect in a particular image segment is nearly equivalent to determining the location of the defect. Thus, after generating the larger simulated TEM images, we generate 50 random crops from each training set image where each crop is an image segment of dimension 84 × 118. Please note that the crops are random so the location of the GaAs atoms differs within each image segment. These 5600 image segments constitute the training data for the PCA and form the basis for the training data for the CNN. During the training of the CNN, we apply data augmentation and randomized circular defects to the 5600 image segments to generate labeled training data. This process is described in more detail when we present the PCA-CNN model.
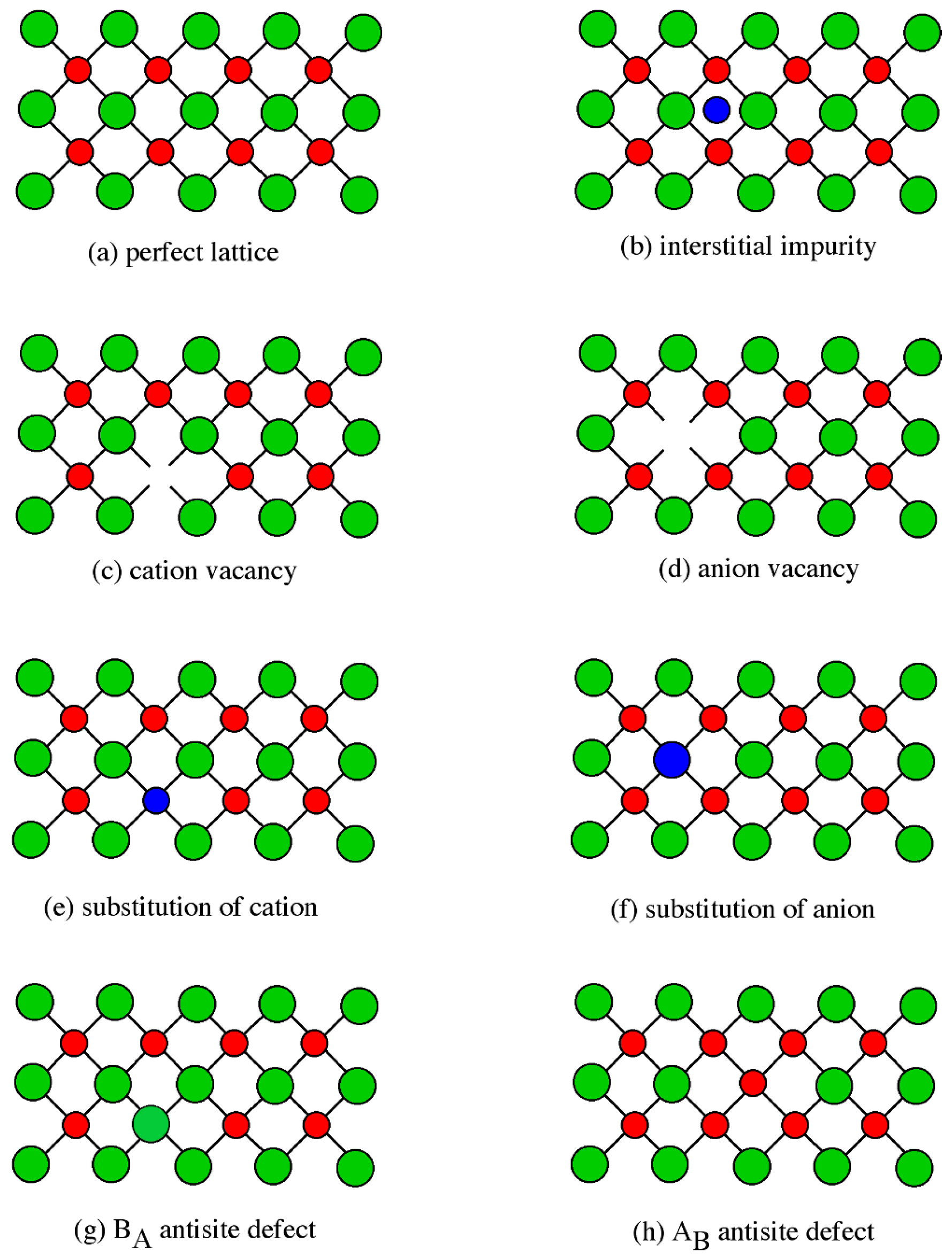
Next we use the test conditions to generate the test data. For each of the 56 test conditions, we generate 30 TEM images that are each 1007 × 1024. Specifically, each simulated image contains a single point defect that can be one of three defect types. For each of these three defect types, 10 replicates are generated where the defect location is randomized for each replicate. This results in a total of 1680 test images that are each 1007 × 1024. The three types of defects are (1) an antisite complex where the Gallium and Arsenic atoms are reversed, (2) substitutional defect where a dopant has an approximately 5% larger radius, (3) an arbitrary circular defect.
Figure 2a shows an example of each of the three defect types. We choose to consider these three types of defects because it includes a very subtle defect in the substitutional defect, a more obvious defect in the antisite defect, and a general defect in the circular defect. The circular defect is located randomly in an image segment while the other two located appropriately. The circular defect is meant to capture any general point defect such as an interstitial defect or a vacancy. The circular defect is unique in that it is easily added to any TEM image, either simulated or experimental. This flexibility plays an important role in the CNN model that introduced in a later section. For each combination of imaging condition and defect type, we generate 10 simulated TEM images with a randomly located defect. This results in 1680 test images where the defect location is known. Unlike the smaller image segments used in the training set, the images in the test set are 1007 × 1024. The test set images are used to evaluate whether or not the defect detection methods can accurately predict the location of the defect in the test image. Specifically, a 84 × 118 sliding window is used to determine the likelihood that each image segment in the 1007 × 1024 image contains a defect. Using a stride length of 4, each 1007 × 1024 image results in over 50,000 image segments that must be individually analyzed. The process for generating the training and test data is summarized in
Figure 3.
The simulated TEM images do not include imaging noise. However, experimental TEM images can have varying degrees of noise that make it difficult to identify defects in a TEM image. Therefore, it is desirable for our proposed defect detection methods to be robust to imaging noise. To account for the presence of imaging noise in experimental images, Gaussian noise is used in both the training and test sets. Specifically, Gaussian noise with
is added to each pixel value for images in the training set. For the test set, varying levels of Gaussian noise, where
σ2 = 0.00, 0.05, 0.10, are added to the TEM images and model performance is evaluated for each noise level.
Figure 2b shows the effect of the Gaussian noise on a TEM image.
2.2. PCA Model
We present a method of detecting defects using PCA reconstructions. We fit a PCA transformation on the 5600 defect-free 84 × 118 image segments in the training set. Then we apply an 84 × 118 sliding window across each 1007 × 1024 test set image and, for each window, we generate a PCA reconstruction of the image segment in the window. Since the PCA transformation (and inverse transformation) is only fitted on defect-free TEM images, the assumption is that PCA will struggle to reconstruct an image with a defect. Thus, we expect that the reconstruction error of image segments with a defect to be greater than the reconstruction error of images without defects. We can predict the location of a defect by identifying the image segment with the highest MSE. With this framework in mind, we present the method in more detail below.
In general, PCA is a method for transforming a data matrix,
, with dimensions
to a lower-dimensional representation,
, with dimensions
where
. Specifically, PCA involves a linear transformation,
, where the transformation matrix is defined as
with the constraint that
is orthogonal,
. Notice that
is an
matrix that can be interpreted as a reconstruction of the original data using the lower-dimensional representation. Thus,
is a transformation matrix that minimizes reconstruction error for a given data matrix
and dimension
k [
33].
In our PCA-based model, the training data consists of 50 randomly cropped image segments from each of the 112 larger TEM images in the training set. These 5600 training image segments can be represented by the data matrix where the rows represent individual image segments and the columns represent mean-centered values at each pixel location. The orthogonal linear transformation projects the original data, , to a lower k-dimensional representation, . In PCA, the weight matrix is constructed such that the reconstruction MSE, , is minimized. Notice that , a matrix of dimension 5600 × 9912 represents the reconstructed images. The projection to the lower-dimensional space and the reconstruction back to the original dimensional space are both determined by . Once is fit using the training data, it can be used to generate the reconstruction of any 84 × 118 image segment.
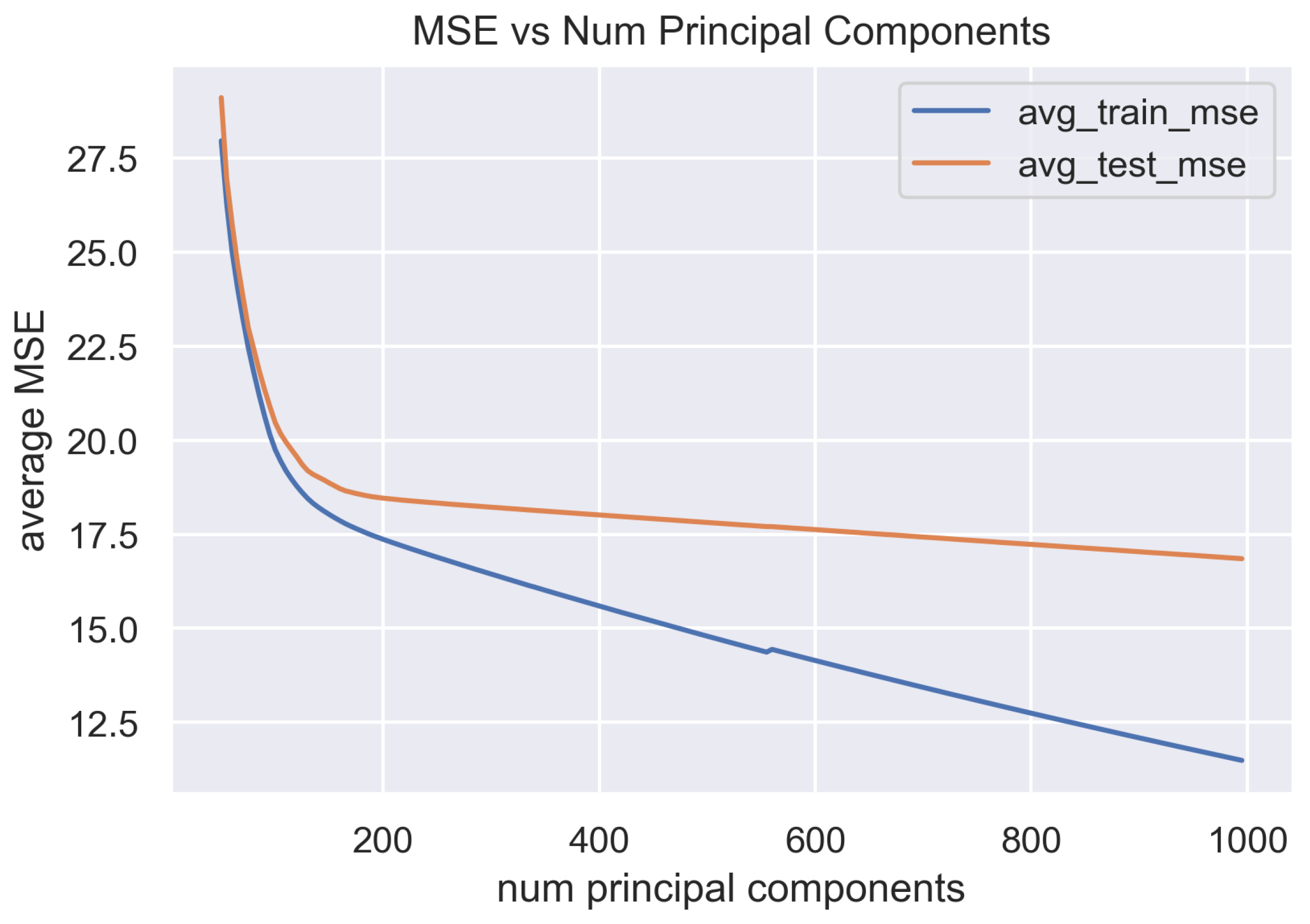
We set the value of
k using reconstruction mean-squared error (MSE) of a test set. Specifically, we fit the PCA using the 5600 image segments in the training set and then apply the fitted PCA to image segment from the test conditions to compute the average reconstruction MSE. For each of the 56 test conditions, 50 random crops are taken where each crop is known to be free of defects.
Figure 4 shows the effect of increasing the number of components on MSE. To prevent overfitting to the noise in the training set, we set
.
Figure 4 shows several examples of image segments under various imaging conditions as well as the associated reconstruction with
.
Figure 5 also shows examples of circular defects and the effect of the PCA reconstruction on the defect. The circular defects in the raw image are not visible in the PCA reconstruction which indicates that PCA reconstruction struggles to accurately reconstruct anomalous point defects.
The difference between an image segment and its reconstruction is referred to as the residual image. The residual image, intuitively, shows what is remaining when the general lattice structure is “subtracted” from the original image. Thus, the residual images consists of noise and any anomalies in the lattice structure. The reconstruction MSE can be regarded as a scalar that summarizes the residual image. For each of the 5600 images in the training set, we can compute the reconstruction MSE with and without a circular defect to understand the distribution of reconstruction MSE.
Figure 6a shows how the presence of a defect changes the reconstruction MSE for each training example. In addition,
Figure 6b shows how the addition of imaging noise affects the reconstruction MSE distribution with and without a defect. The concept of a residual image plays an important role in the CNN model that is presented in the next section.
After fitting the PCA transformation, we apply the resulting
to the test set images via a sliding window. Recall that each test set image is of dimension 1007 × 1024 and contains a single point defect with known location. We use a 84 × 118 sliding window across the 1007 × 1024 image and, for each window, we complete the following three steps: (1) generate the PCA reconstruction, (2) generate the residual between the original image segment and the reconstruction, (3) compute the pixel-wise mean squared error (MSE). We then generate a heatmap that shows the average reconstruction MSE for each pixel in the full-size TEM image. The predicted location of the defect corresponds to the area of the heatmap that has the largest reconstruction MSE.
Figure 7 shows an example of a test image and the corresponding MSE heatmap. The defect in the test image is a substitutional defect where a single Gallium atom is replaced with a dopant atom that has a 5% larger radius. The defect is difficult to identify visually, but the heatmap accurately locates the defect. This method is applied to all imaging conditions in the test set and we evaluate the accuracy in predicting the location of each type of defect.
Figure 3 summarizes the process for predicting defect location using PCA.
2.3. PCA-CNN Model
In this section, we supplement the PCA-based detection method with a CNN classifier to improve the accuracy of the defect location predictions. This combined method significantly improves the prediction accuracy of the PCA model, especially in the case when there is imaging noise.
The PCA-based defect detection method has the benefit of being straightforward. However, in the presence of imaging noise, using PCA reconstruction error can lead to issues.
Figure 5 shows the PCA residual images of segments with and without defects. In these particular examples, the reconstruction MSE for the defect images is actually lower than the reconstruction of the MSE for the defect-free images. Notably, if we visually inspect the residual images, the residual images clearly show the presence of a point defect. To address this shortcoming, we introduce a CNN classification model fitted on the PCA residual images. Intuitively, reconstruction MSE is equivalent to adding up the squared values in the residual image and it ignores any local patterns in the residual image. A CNN, on the other hand, can be trained to look for the presence of local patterns in the residual image that may be evidence of a defect. To the best of our knowledge, the use of the residual image for defect detection is a novel approach.
A CNN is a type of neural network that is commonly used for analyzing image data ([
4]). The key concept in a CNN involves the use of small filters or kernels to extract local information from an image. A filter, often of dimension 3 × 3, is a matrix consisting of weights. The filter is applied to an image by sliding the filter across the image and taking the sum of the element-wise product between the filter weights and the image pixel values. The sums of these element-wise products are then stored in a new matrix, commonly referred to as a feature map, which can once again be analyzed using another set of filters. The training process of a CNN involves optimizing the filter weights to minimize a given loss function. In our application, our goal is to train a CNN to identify the presence of a defect within a residual image.
The training data for the CNN model begins with the same set of defect-free training images used to fit the PCA. Recall that 50 random crops from each of the 112 training images were used to fit the PCA. These same 5600 images are used to build a set of labeled training data for the CNN classifier. Since the training data only includes image segments that are defect-free, a set of labeled training data with defects is generated by adding random, circular defects to each of the 5600 training images. These circular defects could be representative of an interstitial defect or a vacancy, but they are not necessarily meant to represent a realistic defect that would be observed in an experimental image. Instead, the hope is that the CNN will learn to classify any residual image with an abnormal local pattern as one containing a defect. Since the circular defects are arbitrary and are added post-hoc to the simulated image, this method can easily be applied to experimental TEM images as well. After generating the labeled training, a CNN classification model is trained such that for an input PCA residual image, the model outputs a scalar
where
is the probability that the image segment contains a defect. A summary of the CNN model development process is visualized in
Figure 3.
Our primary CNN architecture is adapted from the classic LeNet-5 architecture [
34] and has 58,000 trainable parameters.
Figure 8 shows the details of each layer of the CNN. It contains four convolutional layers with max-pooling following by two dense layers. We use a binary cross-entropy loss function and is optimized using nAdam. The model is trained for 200 epochs. Importantly, the training data are generated randomly for each batch so the location of the circular defects and noise patterns in the training set are randomized during training. The CNN is trained using Python 3.7 and Keras 2.3 with a TensorFlow 2.4.1 backend. The model achieves >99% training accuracy and test accuracy in less than 100 epochs. At the completion of 200 epochs, the test accuracy is 99.8% (
Figure 9. Since the test set images are generated using a separate set of imaging conditions (focal length and thickness), the strong performance on the test set suggests that the trained CNN generalizes well to imaging conditions that were not included in the training set.
In addition to the LeNet based architecture, a VGG-16 architecture [
35] was also implemented for comparison. The VGG-16 model was pretrained on ImageNet and the top dense layers were retrained using the TEM images. This resulted in 14.7 million fixed parameters and 3.2 million trainable parameters. After training for 100 epochs, the VGG-16 model achieved an accuracy of 98.2%. Given the much smaller size of the LeNet-based model and the better test set performance, the LeNet-based model was chosen as the preferred model.
After training the CNN, an 84 × 118 sliding window is applied to each of the 168 test images that are 1007 × 1024 with one hidden point defect. Using a stride of four pixels, this process results in 50,000 image segments that must be classified as having a defect or not. For each 84 × 118 window, we apply the following three steps: (1) generate a PCA reconstruction, (2) generate a residual image between the original image segment and the PCA reconstruction, and (3) pass the residual image into the trained CNN to generate P(defect). For each pixel in the 1007 × 1024 test image, we compute the average P(defect) for all sliding windows that contain the pixel. This results in a smoothed heatmap for the entire test image. The location of the defect is then predicted to be the area of the heatmap that has the highest average P(defect). The heatmap shown earlier in
Figure 3 is an example of a heatmap generated using the CNN classification model with a sliding window.
In many applications of CNNs for anomaly detection, the output of the CNN classifier, P(defect), is compared to a fixed threshold value to determine if a particular input contains an anomaly or not [
19]. Please note that a threshold is not necessary here since the predicted defect location is simply the pixel value with the largest average P(defect). If we generalize to the case where there are
n defects in a GaAs sample, then the locations corresponding to the
n largest average P(defect) would be the predicted locations of the defects.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}