1. Introduction
Format-preserving encryption is a cryptography algorithm that maintains the format or type of plaintext after the encryption, (i.e., format and length of ciphertext). With these nice properties, the data format conversion (e.g., padding) is not required before the encryption. In traditional block ciphers (e.g., AES [
1]), the length of block size should be the multiple of block size (e.g., 128-bit wise). When the block size is not divisible by 128-bit, the padding should be added to the plaintext to ensure the multiple of 128-bit wise data format.
When only four out of sixteen numbers (i.e., bytes) of credit card are encrypted with the AES block cipher, the ciphertext should be extended to 128-bit wise and this is four times longer than the size of original plaintext to be encrypted. On the other hand, the format-preserving encryption can preserve the 4-digit number format, which is the storage efficient approach than the traditional block cipher method. By using the format-preserving encryption, the existing file system is still available without altering the structure of system.
The typical format-preserving encryption includes the NIST standard format-preserving encryption of FF1, FF3-1, Visa Format Preserving Encryption (VFPE), and the Korean standard Format-preserving Encryption Algorithm (FEA) [
2,
3,
4,
5]. The FEA algorithm, presented by National Security Research (NSR) institute, uses Feistel structures similar to NIST standards, such as FF1 and FF3-1. However, FF1 and FF3-1 algorithms use block ciphers as
F functions, while the FEA uses its own dedicated functions. This feature allows the high-speed encryption than other algorithms designed for the format preserving encryption. The FEA can be an appropriate choice when the sensitive personal information is generally short length.
Internet of Things (IoT) is a network of low-power devices designed to interact and communicate with each other by adding sensors and communication functions to various IoT objects. At this point, IoT devices are easily exposed to viruses or malicious attacks. For this reason, the security should be considered along with the development of IoT services. The format-preserving encryption for IoT devices enables the encryption of data values that maintain the format and length of the data [
6,
7,
8].
When utilizing block ciphers on IoT devices, it is necessary to consider a side-channel attack. The side-channel attack exploits the information when the device is working, (e.g., electromagnetic wave or heat) [
9]. There are several proposals for countermeasures [
10,
11,
12,
13,
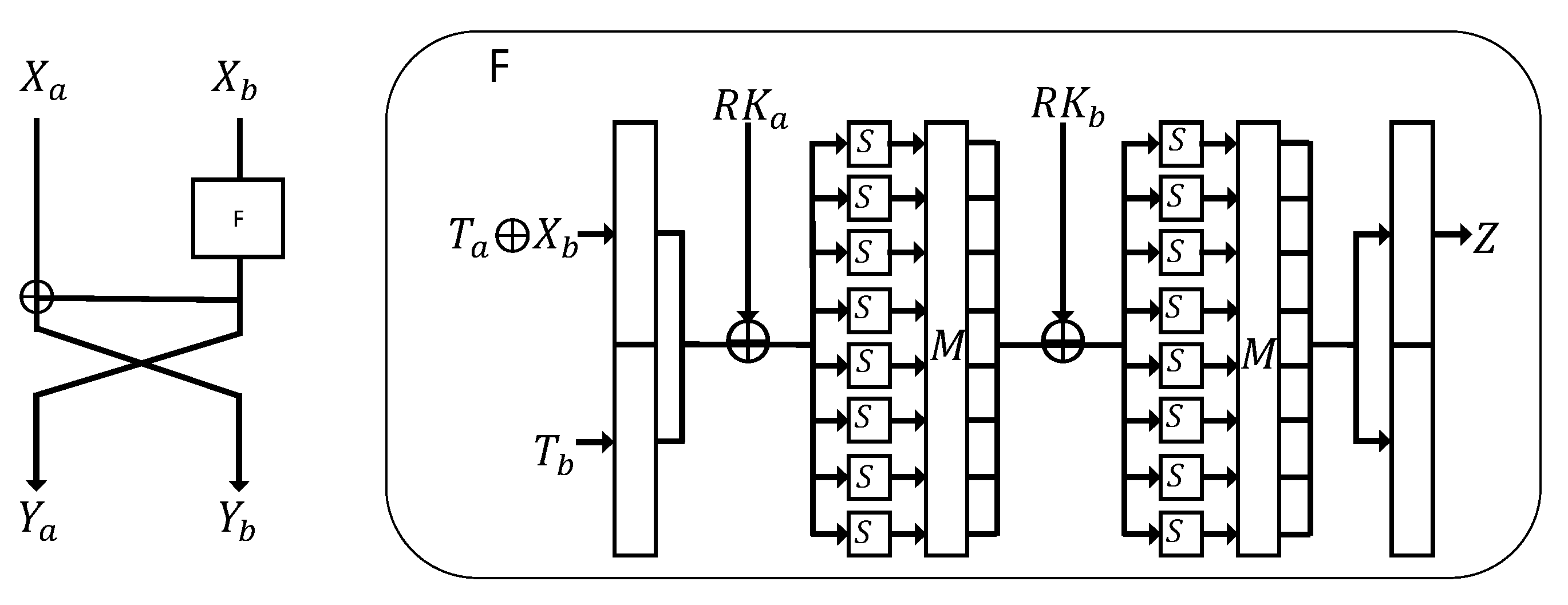
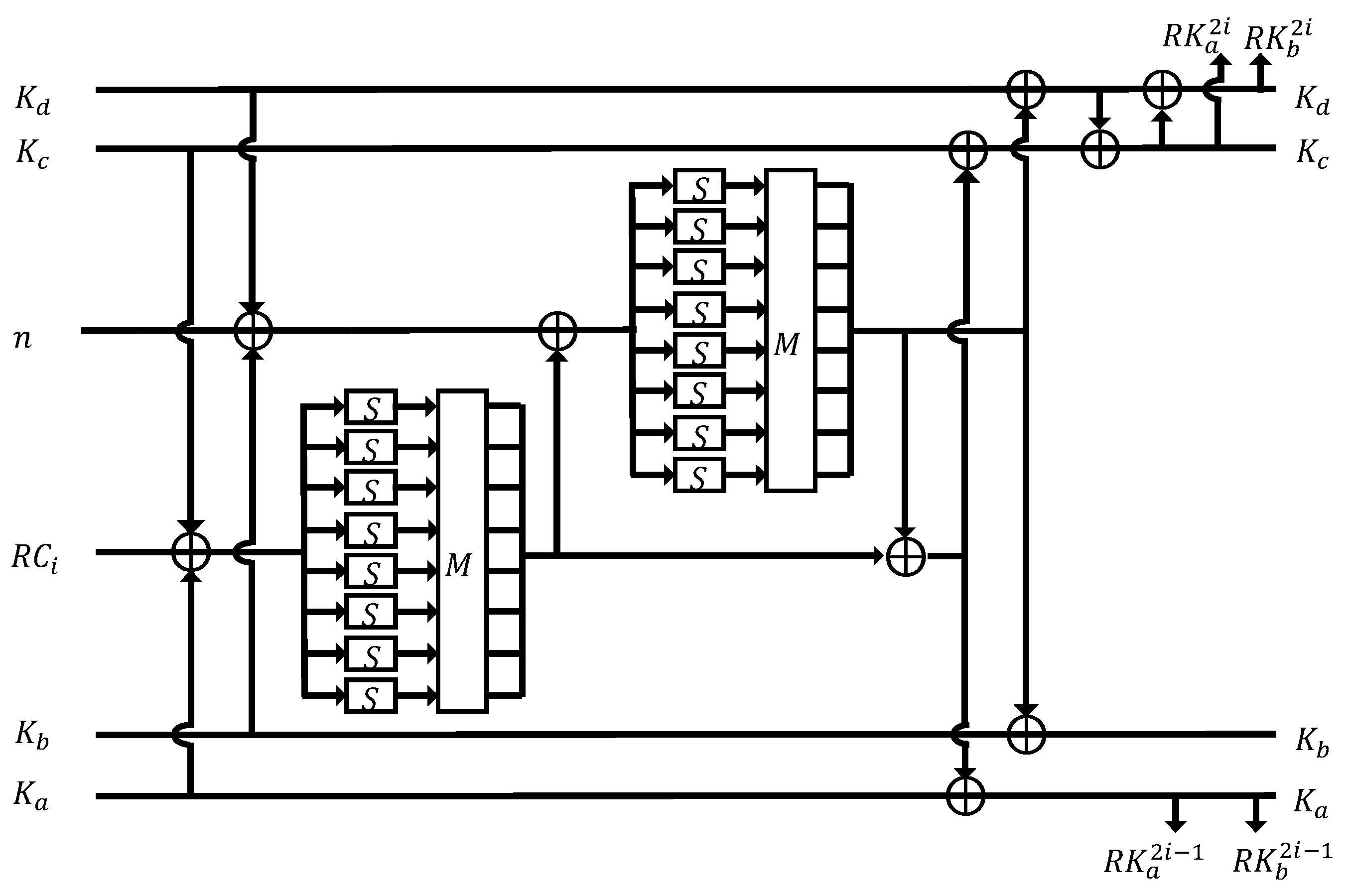
14]. All of these countermeasures reduce the direct relationship between the key and power consumption, allowing less information to be retrieved from the power trace. The masking is a popular mitigation technique used against power analysis attacks. Common masking methods consist of S-box masking and higher order masking. In this countermeasure, intermediate values are hidden with random values. The
F function of FEA consists of two layers including a substitution layer and a diffusion layer. The substitution layer uses an 8-bit wise S-Box, which is known to be vulnerable to side-channel attacks, such as DPA. Therefore, it is necessary to apply side-channel resistance techniques to IoT devices. In this paper, we propose a FEA implementation technique considering the IoT environment using masking techniques.
Contribution
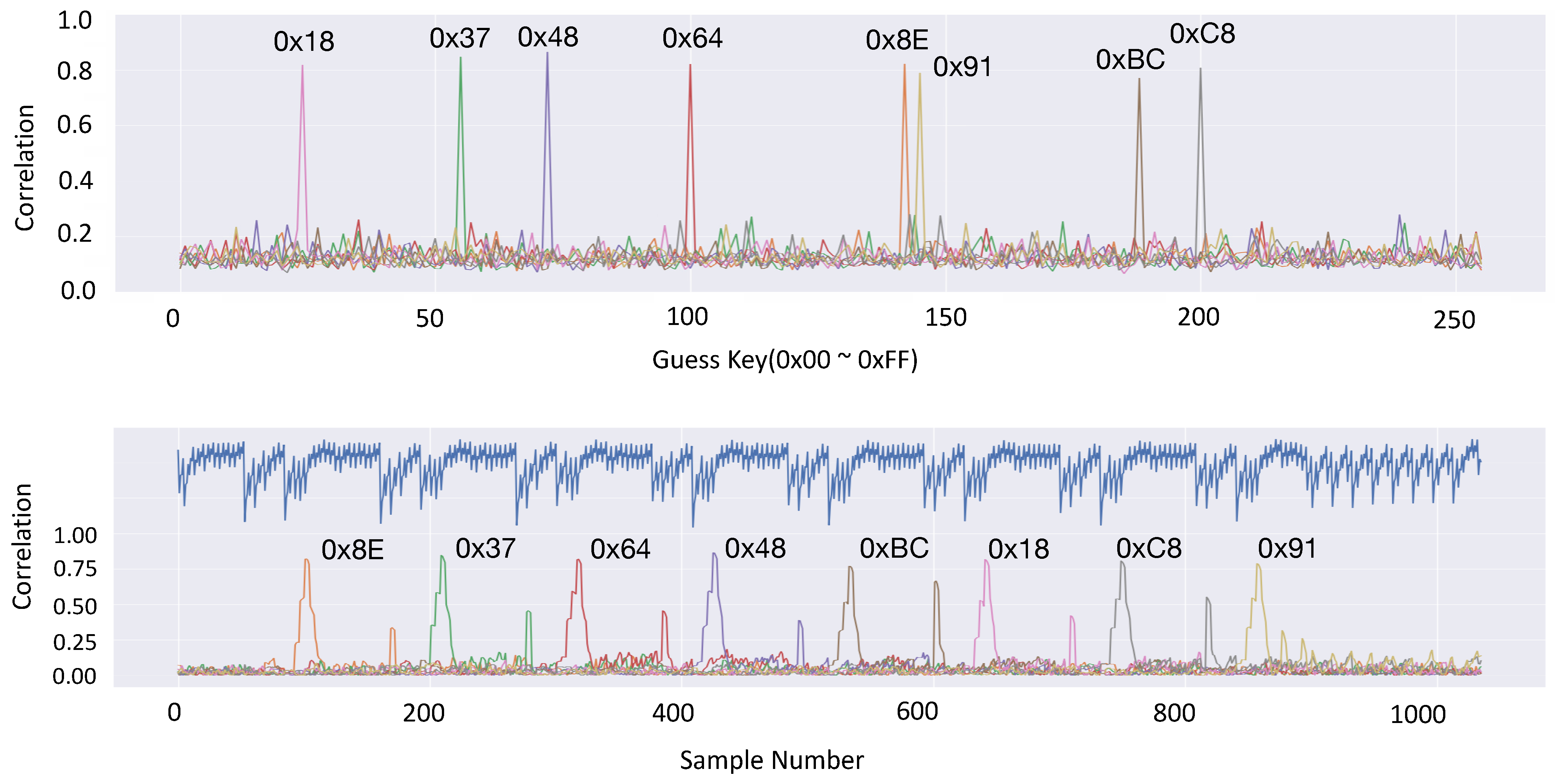
Correlation power analysis on the FEA: We implemented the FEA on low-end AVR microcontrollers. Without secure countermeasures on the FEA implementation, the design is vulnerable to side channel attacks. We evaluated the security strength through the Correlation Power Analysis (CPA) and successfully extracted the secret information.
Optimization techniques for Galois field multiplication on both low-end and high-end IoT devices: In low-end IoT environments, the log/anti-log table based Galois field multiplication is utilized. This approach replaces the complicated multiplication into the simple addition operation. For high-end IoT environments, both S-Box operation and Galois field multiplication are combined and executed at once. This approach eliminates unnecessary multiplication operations by considering bits of the removed block at the last stage of the F function.
Novel masking technique for the FEA: Masking techniques should be carefully designed for different cryptographic structures. The additional computation for masking techniques degrades the execution timing. In order to ensure the high performance, we propose the optimized first-order masking technique for the FEA implementation.
4. Proposed Masking Method
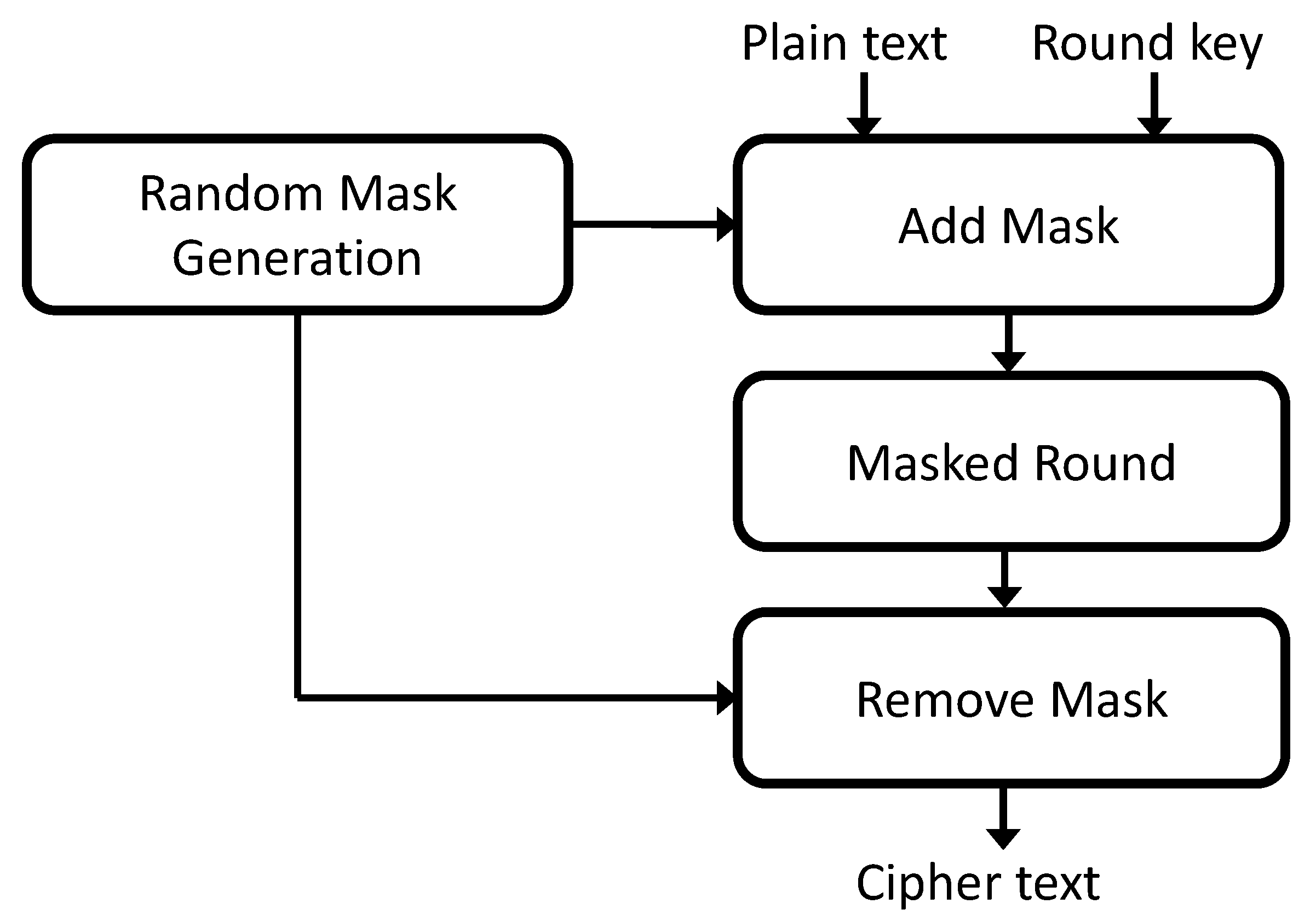
Masking techniques must be applied differently depending on the cryptographic structure, and the additional computation of masking technique affects the computational speed. Considering this point, we propose an appropriate and fast first-order masking technique in this paper. In the masking technique, a random mask value is generated as shown in
Figure 5. Afterward, it added to the plaintext and round key. After the encryption, the masking technique is applied, the mask value is removed, and the cipher text is output.
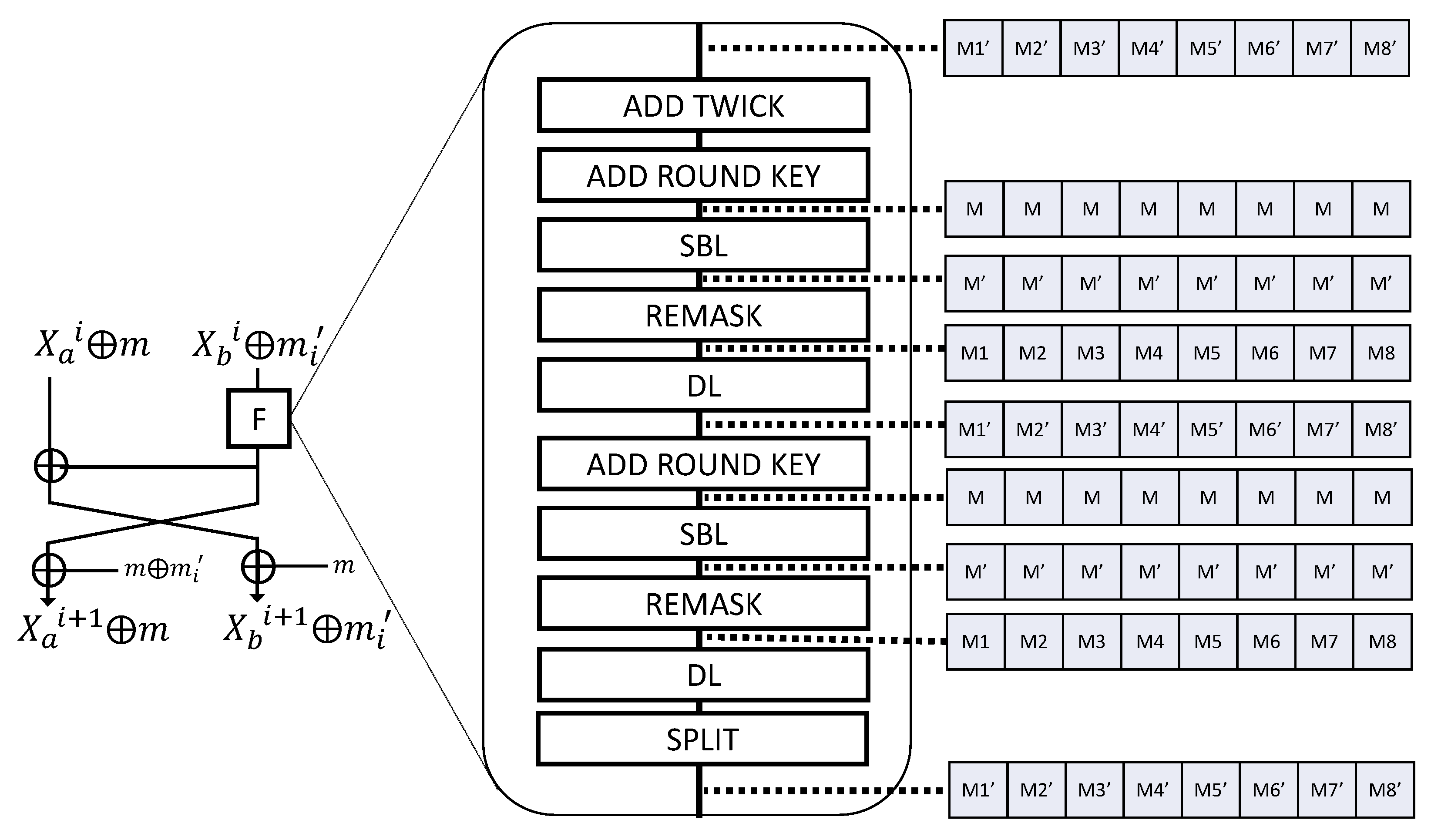
Figure 6 shows an encryption process with the proposed masking technique. In the round function, We designed to increase the efficiency of the implementation by masking the split plaintext
and
. Masks of
M and
are maintained. Mask correction values are calculated in advance to maintain the mask value. First, 8-bit masks
M,
and 8 masks
(
,
,
,
,
,
,
,
) are created. In addition, several mask values are calculated to apply the mask. The mask value is not removed during the DL operation. One performs an ML operation on
to generate
(
,
,
,
,
,
,
,
). The other is XOR operation the mask
M and the mask
values to produce the resulting value
(
,
,
,
,
,
,
,
).
The mask is used to maintain the mask value after the ML operation, and the mask is used to change the mask state to in the REMASK operation. Next, all round keys and perform XOR operations, and Mask M performs XOR operations for each 8-bit block. The masked round key changes the mask state to M when it is operated with the input value. We then generate an MS-Box table with masking values applied to the S-Box table. It is created as MS-Box = S-Box and creates a new masking table, whenever the mask value changes.
The change of the mask state when performing the encryption is as follows. First, we perform an XOR operation of the input plaintext , and each mask M, ’. This mask value is maintained during the round and is removed after the last round. The mask state of the block inputted from the F function is first calculated, resulting in the mask M state. Next, in the SBL step, the mask state becomes as an inquiry is performed in the MS-Box table. Thereafter, in the REMASK step, the XOR operation is performed on to change the mask value from to . In addition, in the DL operation, the mask value becomes the same as the initial , and the mask state becomes the same as the first time. From the next step, the same operation is performed and the mask state is repeated. In the last step of the F function, the last splitting process, the mask value of the truncated bit is removed. Only, the bit is masked back to . Thereafter, in order to keep the plaintext X in the mask M state and in the state, the value of is XORed in the block , and M is XORed in .
The application of masking to the implementation of the SBL-multiplication table is shown in
Figure 7. When the SBL operation and the multiplication operation are implemented as a table, a difference occurs in the masking scheme because the SBL and the multiplication process are combined. The masking application for SBL-multiplication table implementation is as follows. First, mask values used in the mask generation process are 8-bit mask
M,
64-bit mask
, and 8-bit
by XORing each byte of
. Finally,
is created by XORing the masks
M and
. Furthermore, the SBL multiplication table is masked like an MS-box using masks
and
. When the matrix multiplication is performed in the DL operation, these mask values are XORed with each other to become
. Next, the round key
generated by the key schedule is XORed with the masks
M and
. Then, the round key
generates a masked round key by XORing the masks
M and
. The change in mask state when performing encryption is shown in
Figure 6. First, the input plaintext
and
are XORed with
M. This mask value is retained as the round progresses and is removed after the last round. The mask state of the block input from the
F function becomes the mask
M state as the masked round key
is calculated first. Next, in the SBL-DL process, the multiplied value is XORed and the mask state becomes
. Then, as the masked round key
is XORed, the mask state becomes
M again, and the same process is carried out. In the final split process, which is the last step of the
F function, the mask value of the truncated bit is removed. Only the corresponding bit is masked again
. Thereafter, in order to keep the plaintext
and
in the mask
M state, the value of
is XORed in the block
, and
is XORed in
.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}