
Alternative Dirichlet Priors for Estimating Entropy via a Power Sum Functional



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
2. Essential Components
3. Alternative Dirichlet Priors
3.1. Dirichlet Generator Prior
- (1)
- is a Borel-measurable function;
- (2)
- admits a Taylor series expansion;
- (3)
- .
| Algorithm 1 Acceptance/Rejection method |
3.2. Noncentral Dirichlet Prior
4. Entropy Estimates
4.1. Dirichlet Generator Prior
4.2. Noncentral Dirichlet Prior
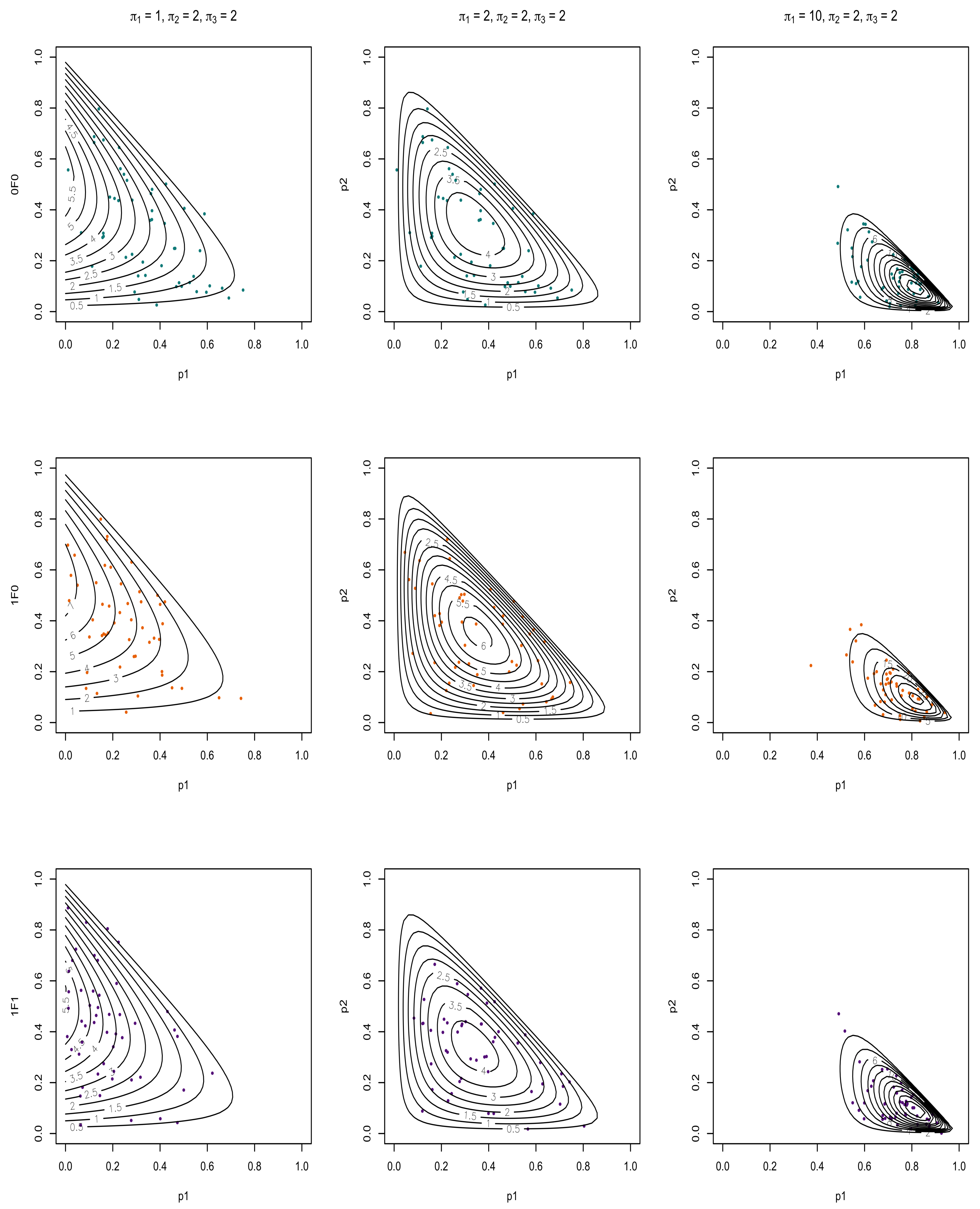
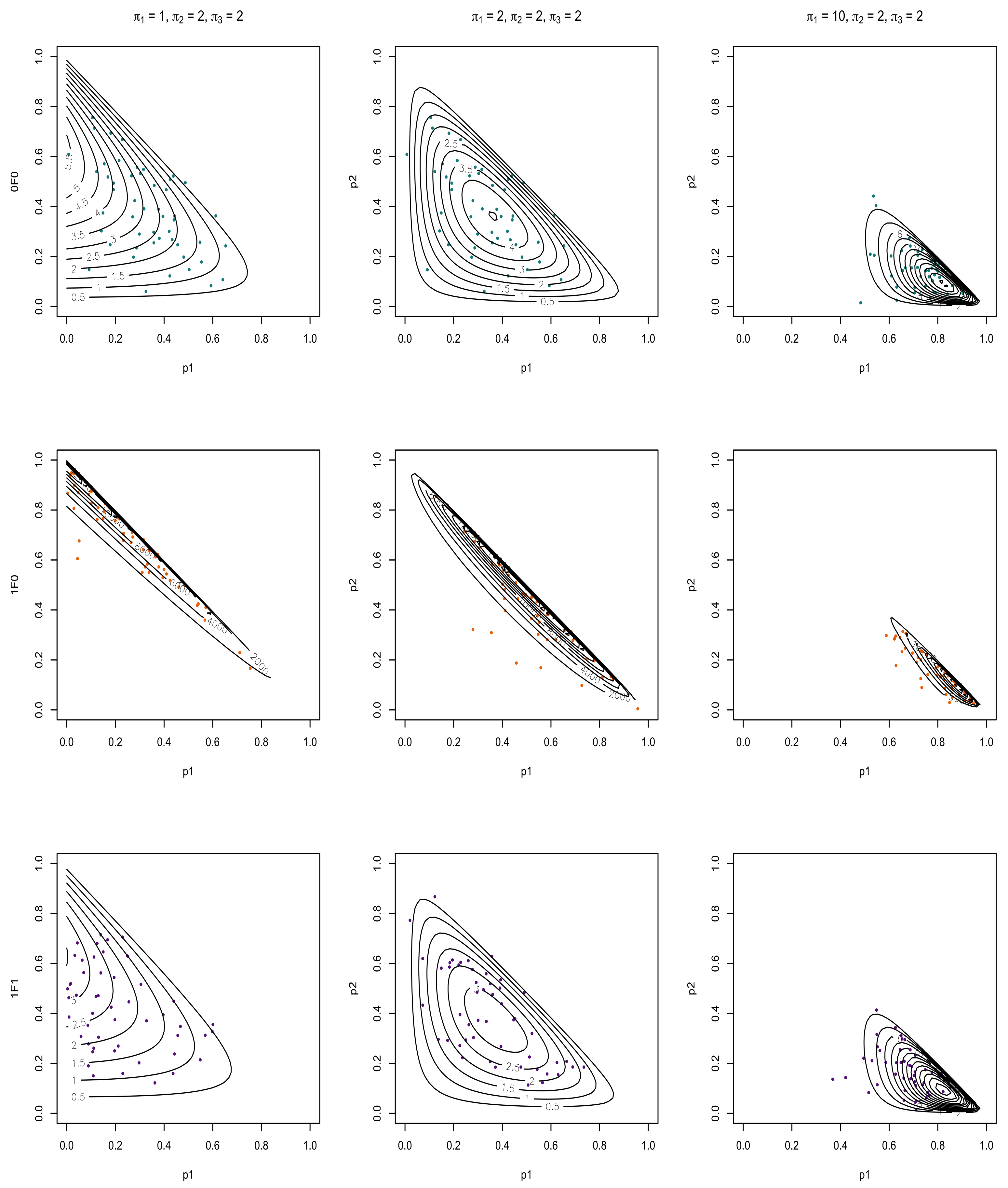
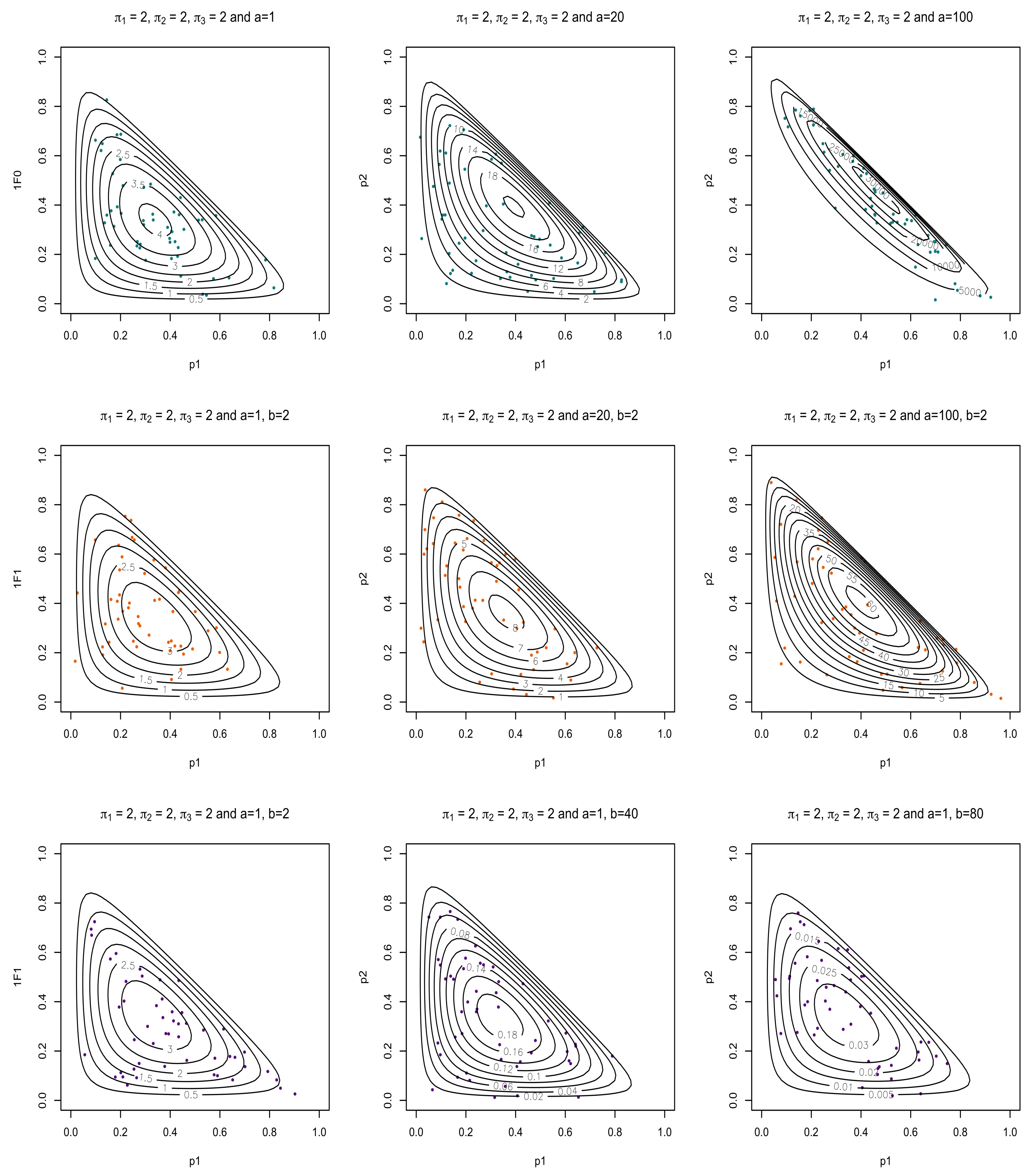
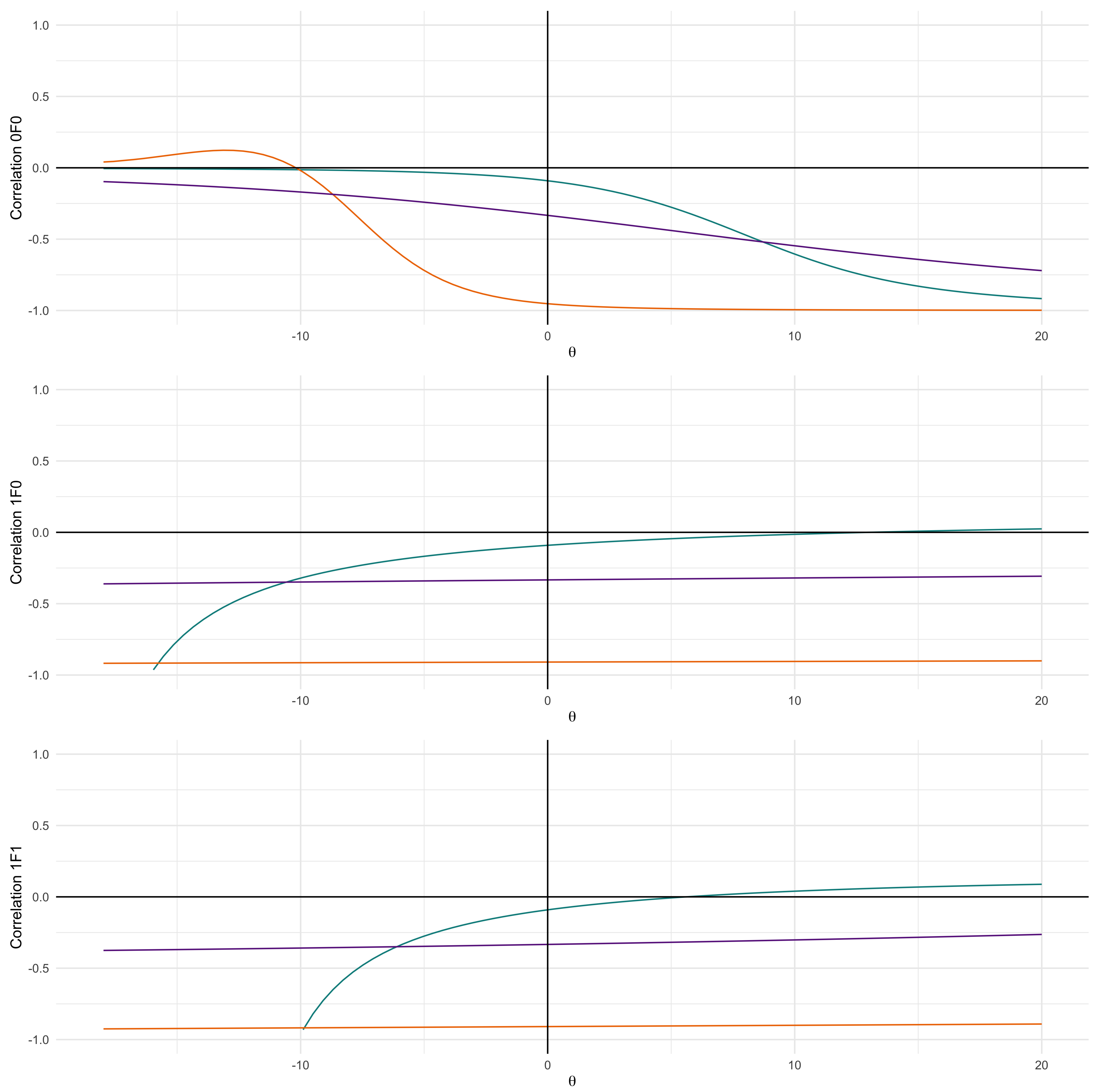
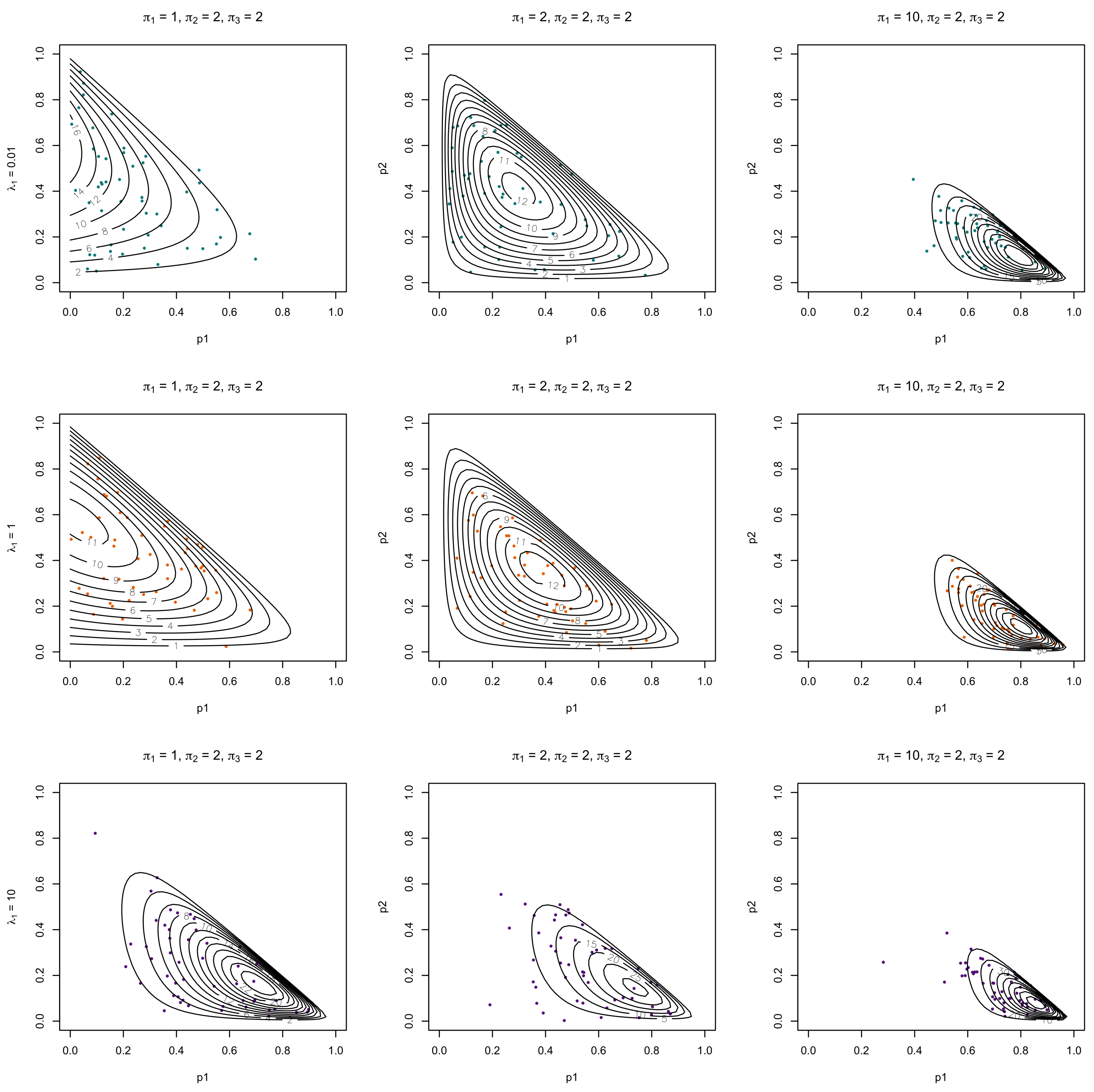
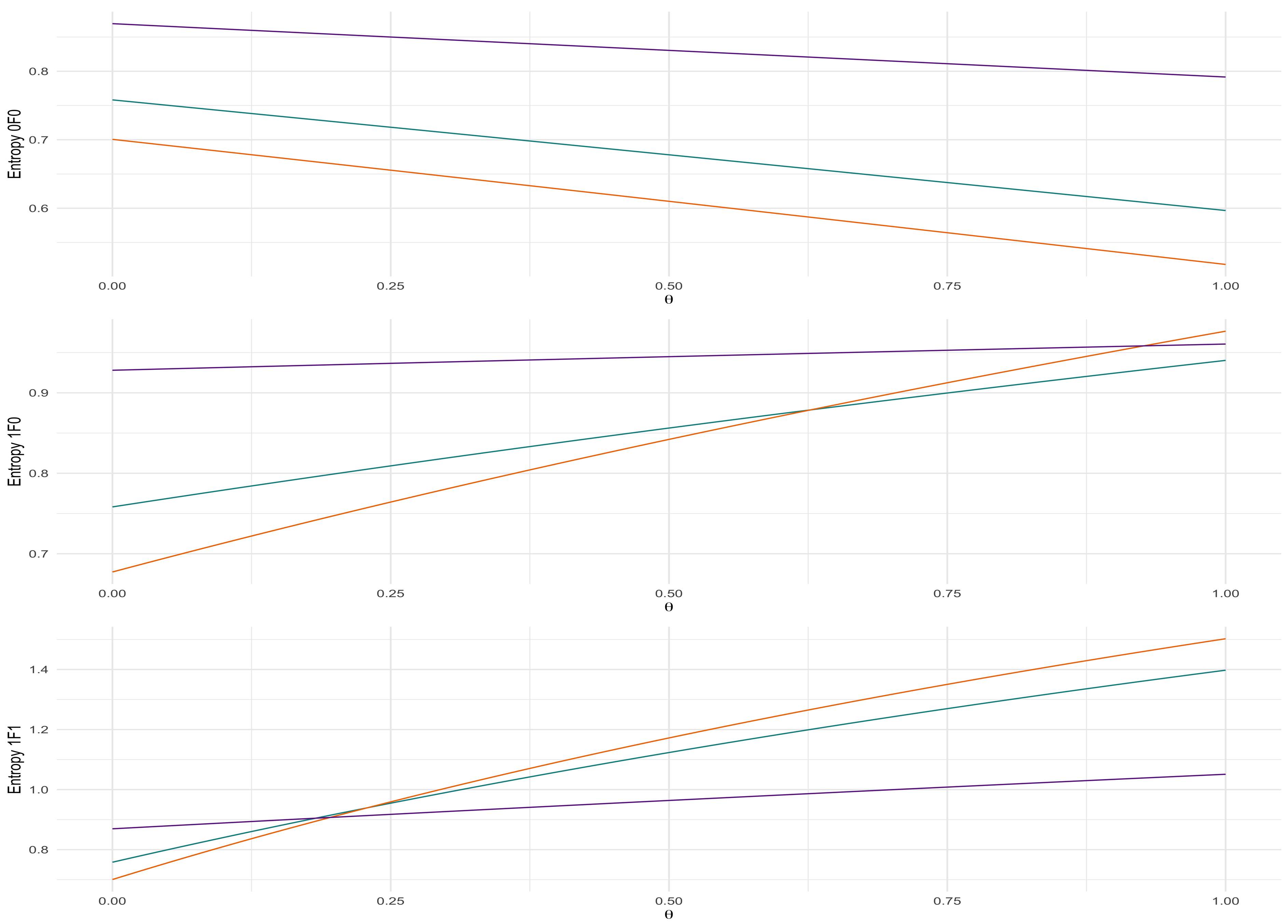
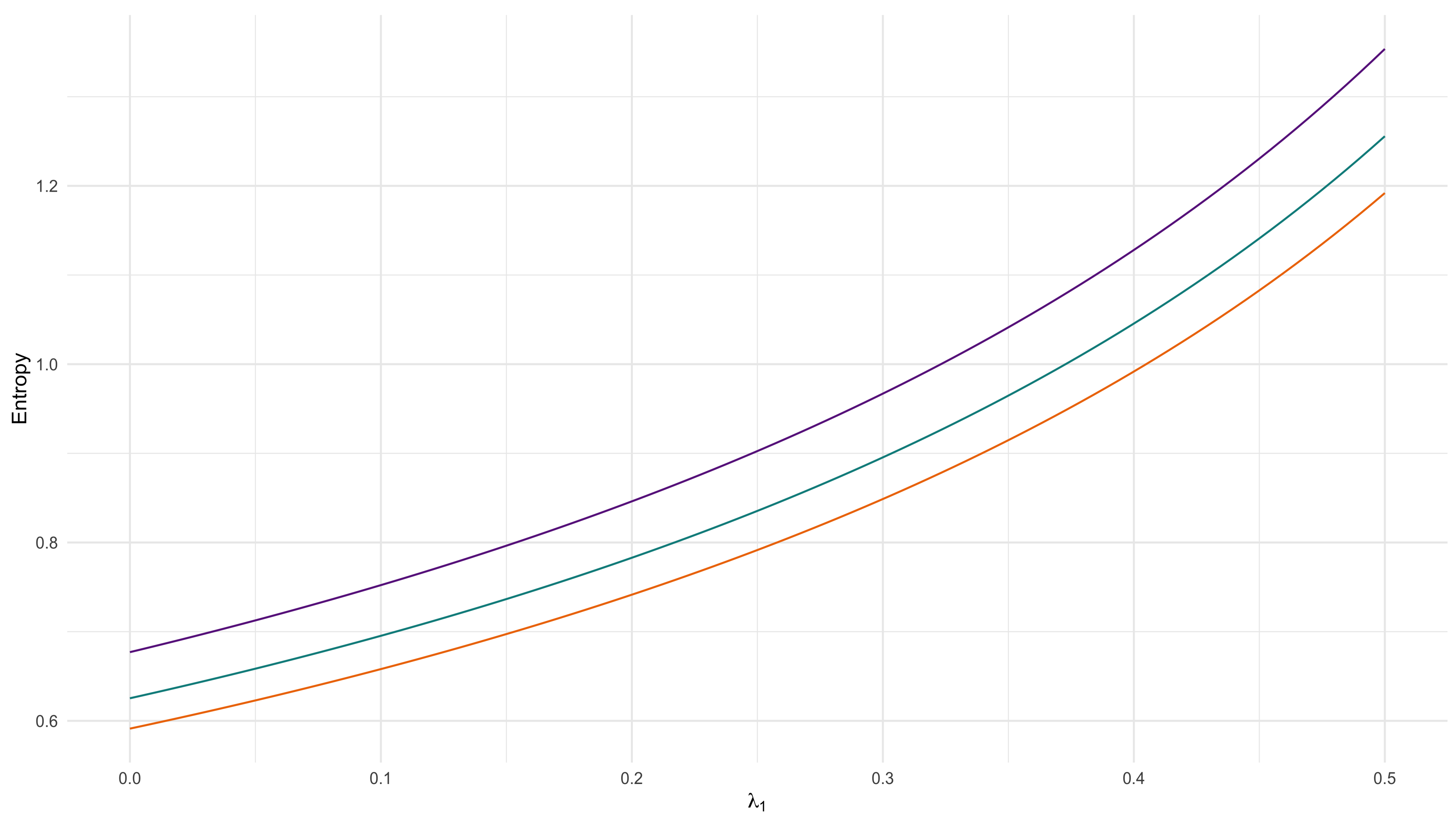
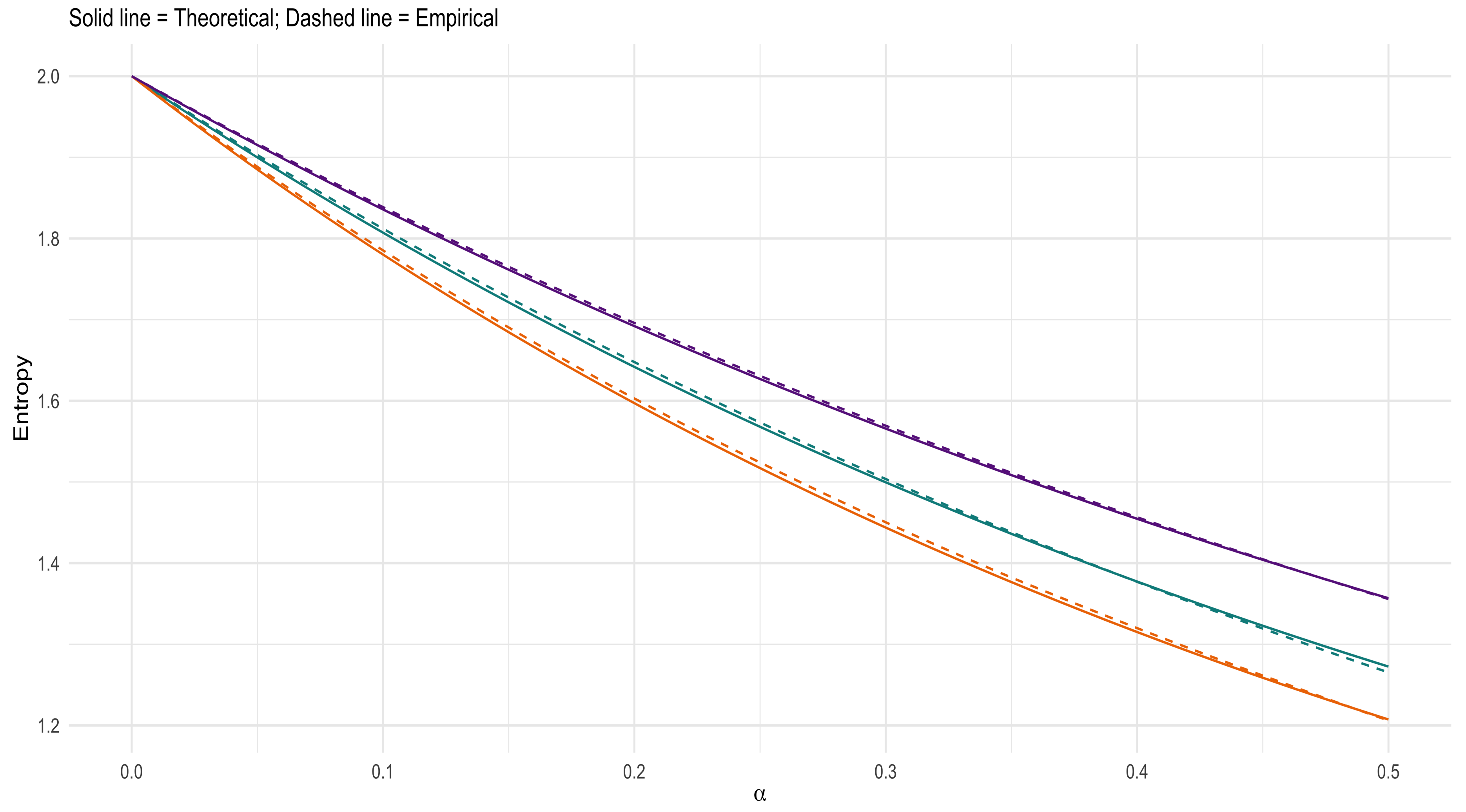
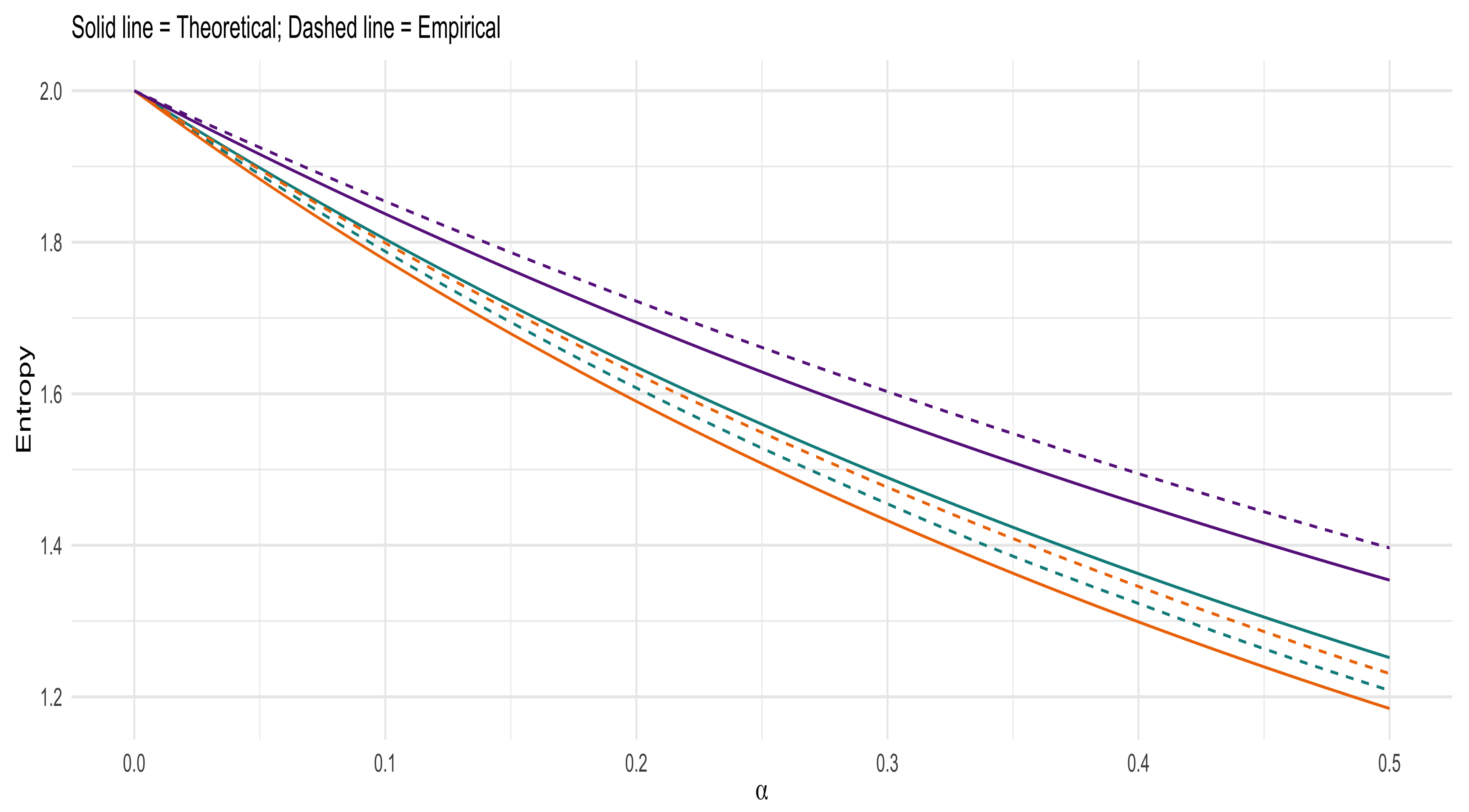
4.3. Numerical Experiments of Entropy
| Algorithm 2 Numerical Experiments of Entropy |
|
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| MLE | Maximum likelihood estimation |
| pmf | Probability mass function |
| Probability density function |
Appendix A. Proof of Complete Product Moments of Dirichlet Generator (11)
Appendix B. Proof of Complete Product Moments of Noncentral Dirichlet (15)
References
- Archer, E.; Park, I.M.; Pillow, J. Bayesian entropy estimation for countable discrete distributions. J. Mach. Learn. Res. 2014, 15, 2833–2868. [Google Scholar]
- Ilić, V.; Korbel, J.; Gupta, S.; Scarfone, A.M. An overview of generalized entropic forms. arXiv 2021, arXiv:2102.10071. [Google Scholar]
- Rashad, M.; Iqbal, Z.; Hanif, M. Characterizations and entropy measures of the Libby-Novick generalized beta distribution. Adv. Appl. Stat. 2020, 63, 235–259. [Google Scholar] [CrossRef]
- Jiao, J.; Venkat, K.; Han, Y.; Weissman, T. Maximum likelihood estimation of functionals of discrete distributions. IEEE Trans. Inf. Theory 2017, 63, 6774–6798. [Google Scholar] [CrossRef] [Green Version]
- Contreras Rodríguez, L.; Madarro-Capó, E.J.; Legón-Pérez, C.M.; Rojas, O.; Sosa-Gómez, G. Selecting an Effective Entropy Estimator for Short Sequences of Bits and Bytes with Maximum Entropy. Entropy 2021, 23, 561. [Google Scholar] [CrossRef] [PubMed]
- Wolpert, D.H.; Wolf, D. Estimating functions of probability distributions from a finite set of samples. Phys. Rev. E Stat. Phys. Plasmas Fluids Relat. Interdiscip. Top. 1995, 52, 6841–6854. [Google Scholar] [CrossRef] [PubMed]
- Han, Y.; Jiao, J.; Weissman, T. Does Dirichlet prior smoothing solve the Shannon entropy estimation problem? In Proceedings of the IEEE International Symposium on Information Theory, Hong Kong, China, 14–19 June 2015; pp. 1367–1371. [Google Scholar]
- Little, D.J.; Toomey, J.P.; Kane, D.M. Efficient Bayesian estimation of permutation entropy with Dirichlet priors. arXiv 2021, arXiv:2104.08991. [Google Scholar]
- Zamzami, N.; Bouguila, N. Hybrid generative discriminative approaches based on Multinomial Scaled Dirichlet mixture models. Appl. Intell. 2019, 49, 3783–3800. [Google Scholar] [CrossRef]
- Holste, D.; Grosse, I.; Herzel, H. Bayes’ estimators of generalized entropies. J. Phys. A Math. Gen. 1998, 31, 2551. [Google Scholar] [CrossRef] [Green Version]
- Bodvin, L.J.S.; Bekker, A.; Roux, J.J. Shannon entropy as a measure of certainty in a Bayesian calibration framework with bivariate beta priors: Theory and methods. S. Afr. Stat. J. 2011, 45, 171–204. [Google Scholar]
- Sánchez, L.E.; Nagar, D.; Gupta, A. Properties of noncentral Dirichlet distributions. Comput. Math. Appl. 2006, 52, 1671–1682. [Google Scholar] [CrossRef] [Green Version]
- Kang, M.S.; Kim, K.T. Automatic SAR Image Registration via Tsallis entropy and Iterative Search Process. IEEE Sens. J. 2020, 20, 7711–7720. [Google Scholar] [CrossRef]
- Mathai, A.M.; Haubold, H.J. On generalized entropy measures and pathways. Phys. A Stat. Mech. Appl. 2007, 385, 493–500. [Google Scholar] [CrossRef] [Green Version]
- Gradshteyn, I.S.; Ryzhik, I.M. Table of Integrals, Series, and Products; Academic Press: Cambridge, MA, USA, 2014. [Google Scholar]
- Ferreira, J.T.; Bekker, A.; Arashi, M. Bivariate noncentral distributions: An approach via the compounding method. S. Afr. Stat. J. 2016, 50, 103–122. [Google Scholar]
- Bekker, A.; Ferreira, J.T. Bivariate gamma type distributions for modeling wireless performance metrics. Stat. Optim. Inf. Comput. 2018, 6, 335–353. [Google Scholar] [CrossRef]
- Ongaro, A.; Orsi, C. Some results on non-central beta distributions. Statistica 2015, 75, 85–100. [Google Scholar]









Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Botha, T.; Ferreira, J.; Bekker, A. Alternative Dirichlet Priors for Estimating Entropy via a Power Sum Functional. Mathematics 2021, 9, 1493. https://doi.org/10.3390/math9131493
Botha T, Ferreira J, Bekker A. Alternative Dirichlet Priors for Estimating Entropy via a Power Sum Functional. Mathematics. 2021; 9(13):1493. https://doi.org/10.3390/math9131493
Chicago/Turabian StyleBotha, Tanita, Johannes Ferreira, and Andriette Bekker. 2021. "Alternative Dirichlet Priors for Estimating Entropy via a Power Sum Functional" Mathematics 9, no. 13: 1493. https://doi.org/10.3390/math9131493
APA StyleBotha, T., Ferreira, J., & Bekker, A. (2021). Alternative Dirichlet Priors for Estimating Entropy via a Power Sum Functional. Mathematics, 9(13), 1493. https://doi.org/10.3390/math9131493