
Methodology and Models for Individuals’ Creditworthiness Management Using Digital Footprint Data and Machine Learning Methods


Abstract
:1. Introduction
- Diagnose the lending market in the RF;
- Analyze the existing methods for assessing individual creditworthiness as well as to describe their strengths and weaknesses;
- Develop a new conceptual approach for assessing individual creditworthiness using data about their digital footprint;
- Propose new models for borrower clustering, classification and predicting the riskiness of a new borrower;
- Design a methodology for assessing individual creditworthiness.
2. Literature Review
2.1. Approaches and Methods for Credit Risk Management
- The probability of default (PD) reflects the probability of a borrower defaulting on the annual horizon and is estimated on the basis of the internal rating of a borrower;
- The exposure at default (EAD) determines the outstanding loan in the case of borrower default;
- The loss given default (LGD) estimates the share of the loan under the credit risk that could be lost in case of a borrower defaulting.
2.2. Credit Portfolio Quality: Methods and Management Techniques
- The scenario approach (or stress testing) [17,18,19,20] is aimed at modeling various scenarios of changes in the state and structure of the credit portfolio. The sensitivity of performance indicators to risk factors is analyzed. As a result of applying the method, the most significant factors determining credit risk are identified;
- The method of internal ratings [21,22,23,24,25], developed in accordance with the standards of the Basel Committee, is designed using a borrower’s credit risk and financial instrument credit risk. The result is the assignment of a specific borrower’s rating, the determination of the borrower’s risk. It allows for building an adequate system of relations with a specific borrower (in accordance with their rating), establishing lending conditions.
- Approach and technique improvement for assessing the borrower’s creditworthiness;
- Monitoring payment discipline and organization of interaction with unreliable borrowers;
- Updating the credit agreement terms;
- Increasing the efficiency of the financial organization’s security service;
- Credit portfolio diversification.
2.3. Advanced Data Analytics and Machine Learning Techniques for Assessing Credit Risk
- Extraction of information [55,56,57,58]. The problem of information retrieval, whose purpose is to automatically obtain structured data when processing unstructured or semi-structured information, is one of the main objectives in the processing of financial data. This applies to working with web content such as articles, publications on social networks, and various documents.
- Credit scoring [58,59,60,61,62]. Increasingly, companies operating in the field of lending are using machine learning to predict the creditworthiness of customers, as well as to build models for credit risks. Diffrent machine learning algorithms used to determine the borrower’s credit rating are used, such as multilayer perceptron, logistic regression, and the support vector machine, as well as the classifier enhancement algorithm (boosting) and vector quantization during training among others.
- Decision making [63,64,65,66,67,68,69]. Financial computing and decision making can be performed through machine learning algorithms that enable computers to process data and make lending decisions more efficiently and faster. Machine learning models are widely used by companies to find a new approach to traditional problems using machine learning and big data analysis. The company analyzes thousands of potential credit variables from financial information to the use of technology to better assess factors such as potential fraud, the risk of default, and the likelihood of long-term customer relationships. As a result, the company can make more “correct” decisions about loans, which leads to an increase in the availability of loans for borrowers and a higher percentage of their repayment.
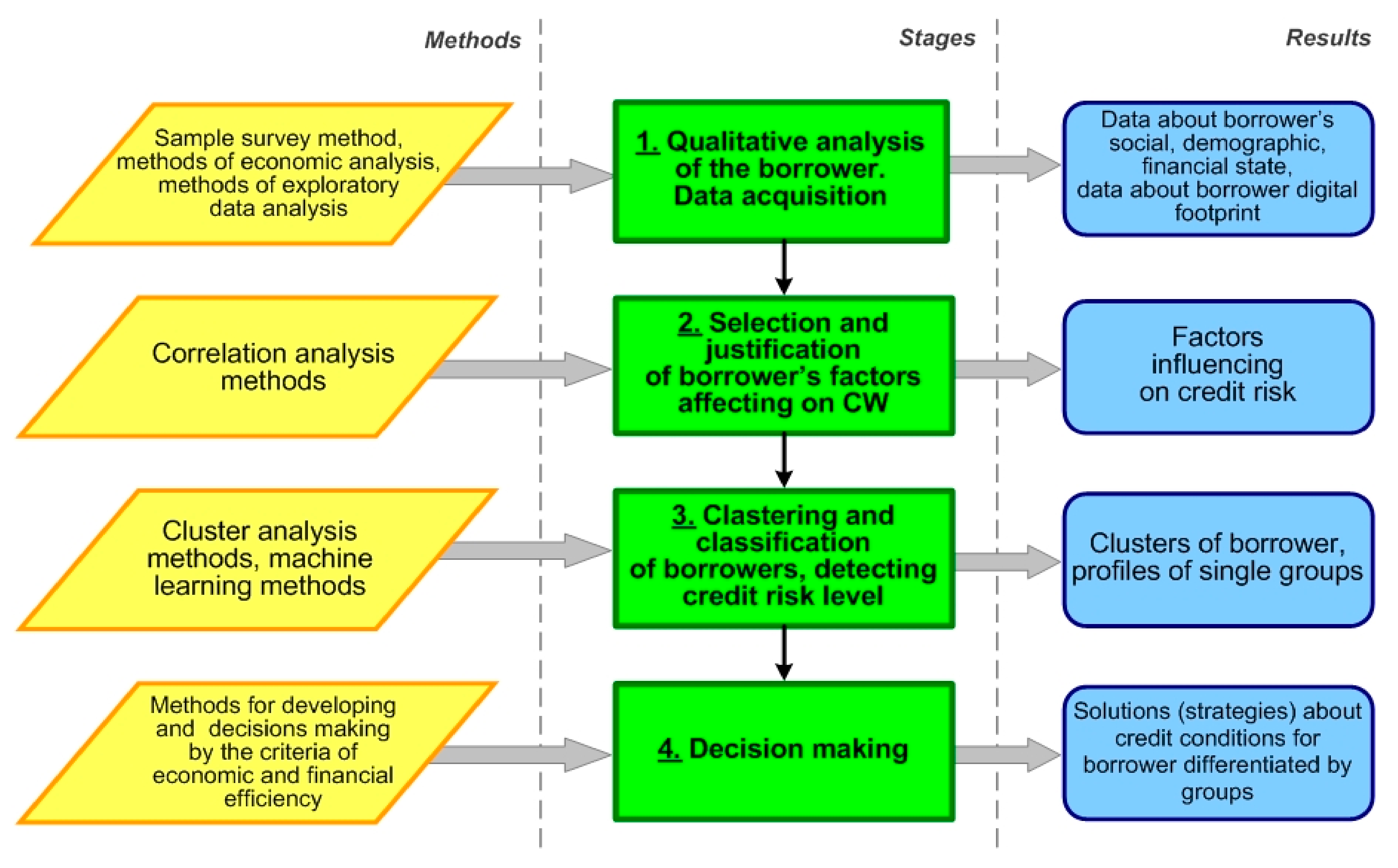
3. Methodology
Qualitative Analysis of Borrowers and Initial Data Description
- Anthropometric and social information: gender, age, educational level, profession, marital status, and children;
- Financial information: regular income, income value, overdue debt, the borrower’s riskiness, and the desired loan value;
- Digital footprint data obtained from social networks and search engines. Analysis of social media will make it possible to evaluate the borrower’s digital avatar.
4. Empirical Results and Analysis
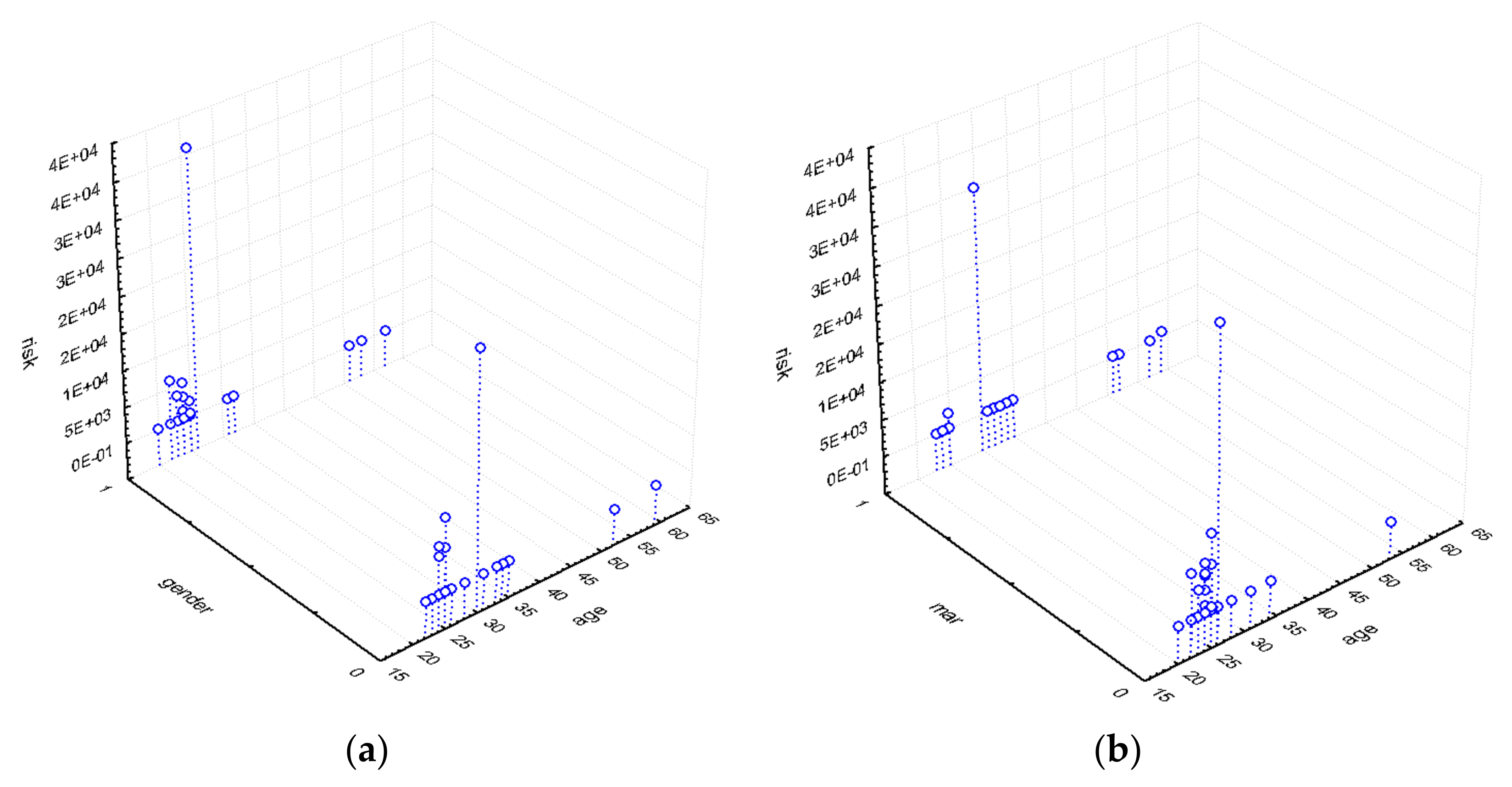
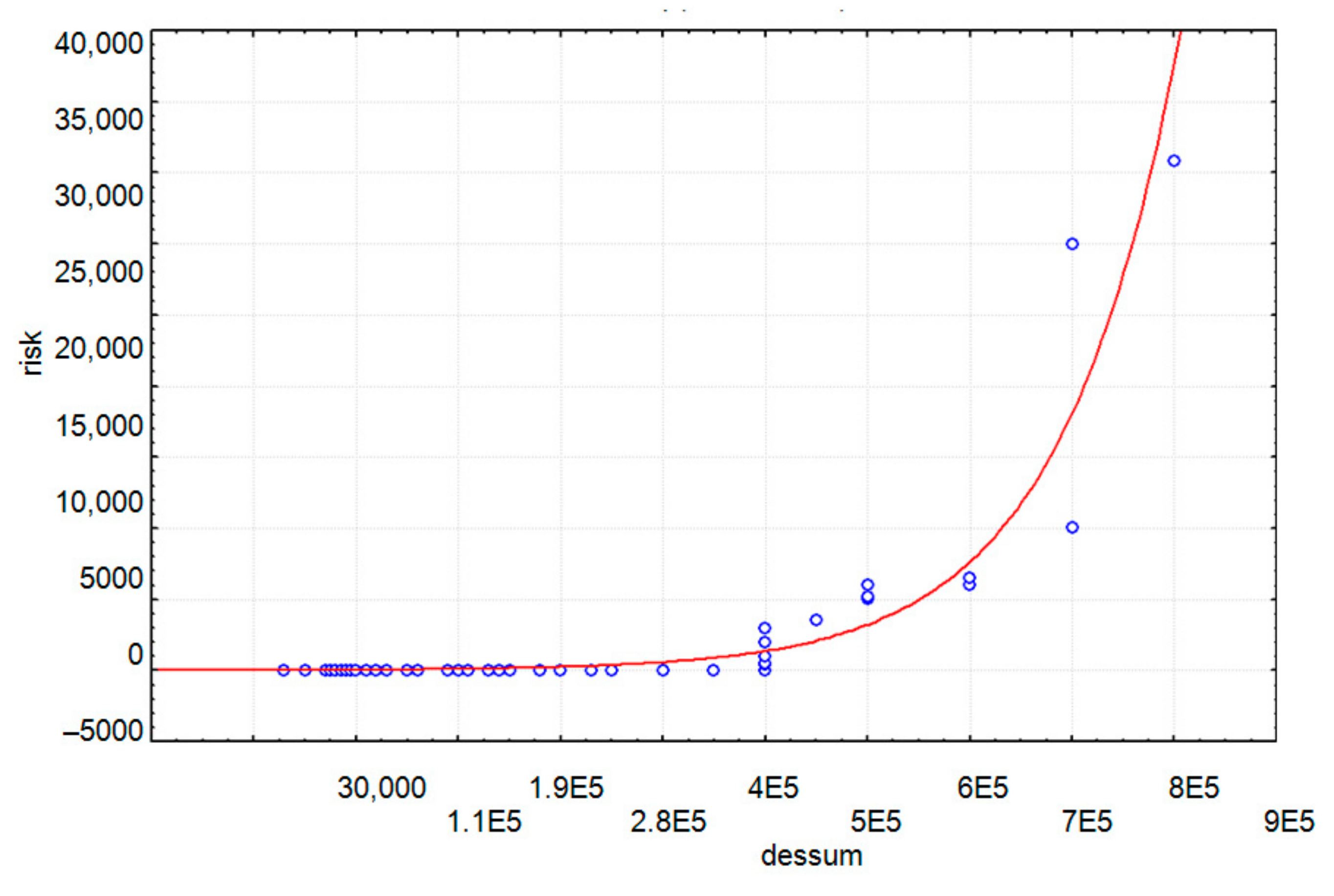
4.1. Selection Factors Affecting the Borrower’s Creditworthiness: Exploratory Data Analysis
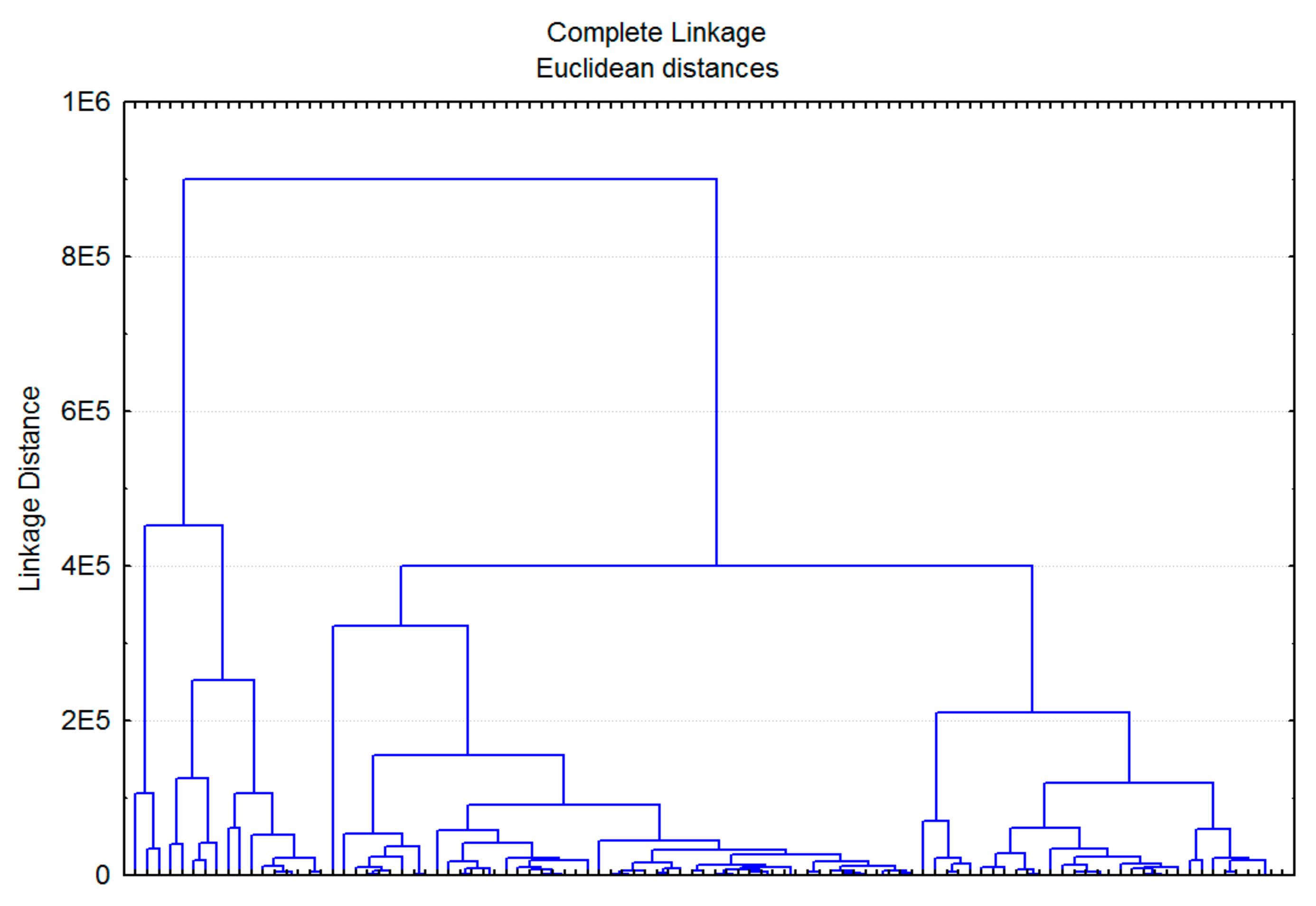
4.2. Model for Borrower Clustering
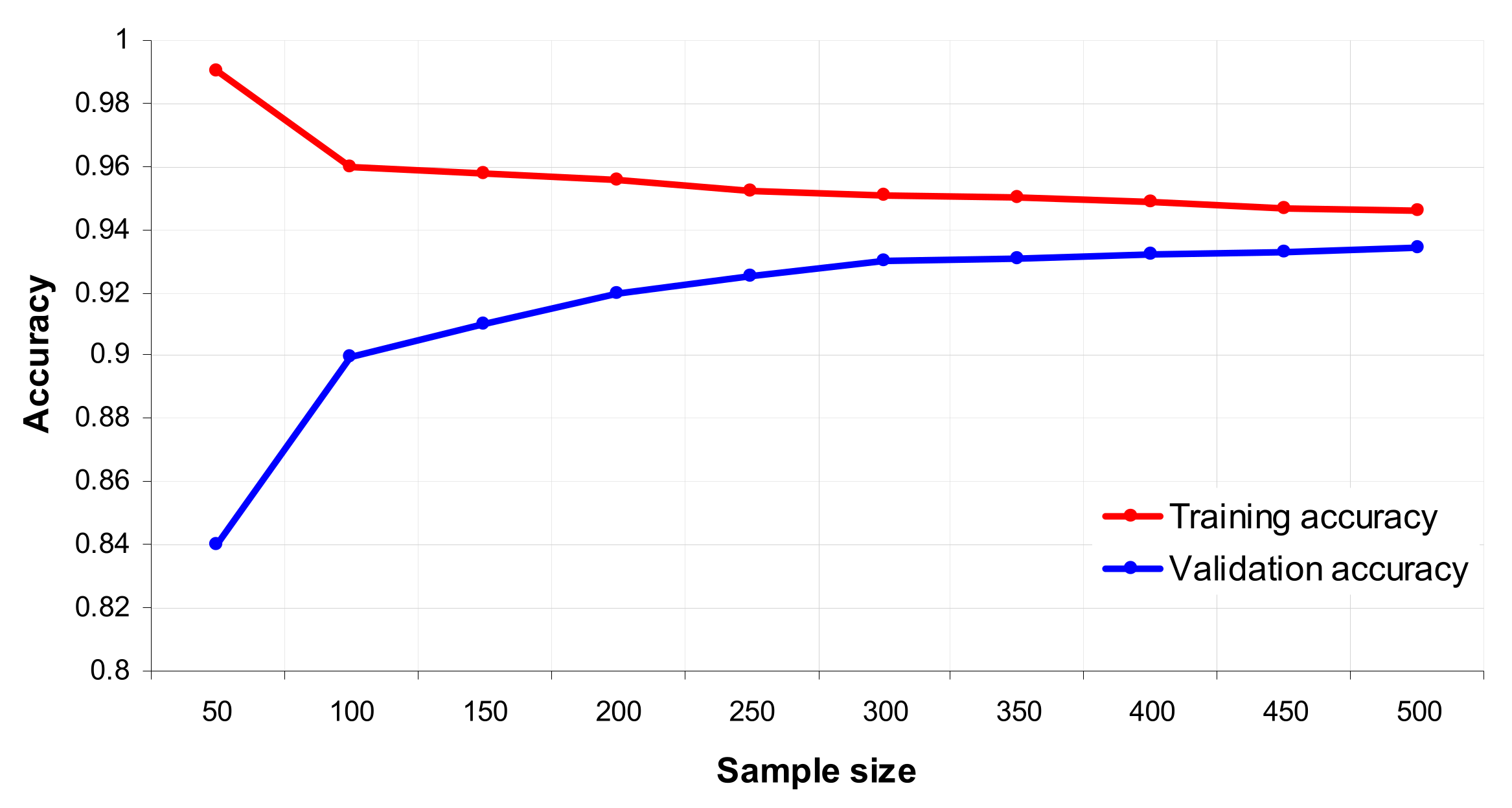
4.3. Model for Borrower Classification
Statement of the Classification Problem
| Algorithm 1 Search for basic algorithms and their weights |
| Input: training sample ; number of iterations K; learning step . Output: basic algorithms and their weights .
;
;
|
5. Discussion of Results
5.1. Comparative Analysis of Different Borrower Classification Models
5.2. Comparative Analysis of the Proposed Methodology and Models with the Traditional Credit Scoring Model
6. Conclusions
- The new factors for a comprehensive assessment of the borrower’s risk profile were compiled as well as economically and financially substantiated. The data about borrowers, collected on the basis of their digital footprints, reflected more complete and adequate borrower digital profiles and should be included in the methodology that, in turn, helps a financial organization to design individual credit trajectories for each borrower and to improve the issued loans’ quality.
- A new methodological approach for borrower CW assessment was proposed, which was designed to reduce credit risks and increase a bank’s financial stability.
- Models for clustering and classification were suggested which, by being a part of the methodology, gave more reliable results about borrower risk profiles and were the basis for making decisions about loan conditions for new borrowers. Application of these models increased the efficiency of financial decisions.
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Principles for the Management of Credit Risk. Basel Committee on Banking Supervision. 2000. Available online: https://www.bis.org/publ/bcbs75.pdf (accessed on 20 February 2021).
- Basel Committee on Banking Supervision. International Convergence of Capital Measurement and Capital Standards. A Revised Framework; Consultative Document; Bank for International Settlements: Basel, Switzerland, 2004; Available online: https://www.bis.org/publ/bcbs128.pdf (accessed on 20 February 2021).
- Basel Committee on Banking Supervision. International Regulatory Framework for Banks; Consultative Document; Bank for International Settlements: Basel, Switzerland, 2010; Available online: https://www.bis.org/bcbs/basel3.htm (accessed on 20 February 2021).
- Pestova, A.; Mamonov, M. Macroeconomic and Bank-Specific Determinants of Credit Risk: Evidence from Russia; EERC Working Paper Series 13/10E; Economics Education and Research Consortium: Kyiv, Ukraine, 2013. [Google Scholar]
- Chernikova, L.I.; Faizova, G.R.; Egorova, E.N.; Kozhevnikova, N.V. Functioning and Development of Retail Banking in Russia. Mediterr. J. Soc. Sci. 2015, 6, 274–284. [Google Scholar] [CrossRef] [Green Version]
- Kjosevski, J.; Petkovski, M. Non-performing loans in Baltic States: Determinants and macroeconomic effects. Balt. J. Econ. 2017, 1, 25–44. [Google Scholar] [CrossRef] [Green Version]
- Fainstein, G.; Novikov, I. The comparative analysis of credit risk determinants in the banking sector of the Baltic States. Rev. Econ. Financ. 2011, 1, 20–45. [Google Scholar]
- Shai, S.-S.; Shai, B.-D. Understanding Machine Learning: From Theory to Algorithms; Cambridge University Press: Cambridge, UK, 2014; p. 294. [Google Scholar]
- Leo, M.; Sharma, S.; Maddulety, K. Machine Learning in Banking Risk Management: A Literature Review. Risk 2018, 7, 29. [Google Scholar] [CrossRef] [Green Version]
- Saqib, A.; Dowling, M.M. AI and Machine Learning for Risk Management. Available online: https://library.oapen.org/bitstream/handle/20.500.12657/23126/1007030.pdf?sequence=1#page=54 (accessed on 20 February 2021).
- Instruction of the Bank of Russia. On Mandatory Ratios and Surcharges to Capital Adequacy Ratios for Banks with a Universal License; Bank of Russia: Moscow, Russia, 2019; Available online: https://rudata.info/files/rudata/add-in/documents/199-i.pdf (accessed on 20 February 2021).
- Provision on the Procedure for the Formation by Credit Organizations of Reserves for Possible Losses on Loans, Loan Debt and Equivalent Debt. Available online: https://base.garant.ru/71721612/ (accessed on 20 February 2021).
- Lunyakova, N.A.; Lavrushin, O.I.; Lunyakov, O.V. Clustering the regions of the Russian Federation by the level of deposit risk. Econ. Reg. 2018, 3, 1046–1060. [Google Scholar]
- Lavrushin, O.I. The Development of the Banking Sector and Its Infrastructure in the Russian Economy; KNORUS: Moscow, Russia, 2017; p. 176. [Google Scholar]
- Tobin, P.; Brown, A. Estimation of Liquidity Risk in Banking. ANZIAM J. 2004, 45, 519–533. [Google Scholar] [CrossRef] [Green Version]
- Allan, J.; Boot, P.; Verrall, R.; Walsh, D. The Management of Risks in Banking. Br. Actuar. J. 1998, 4, 707–802. [Google Scholar] [CrossRef]
- Kuznetsov, I.V.; Zhevaga, A.A. Stress testing of credit risk in a commercial bank on the basis of macroeconomic indicators. Financ. Risk Manag. 2018, 1, 2–11. [Google Scholar]
- Shamrina, S.Y.; Lomakina, A.N. Scenario analysis of stress testing in assessing the main types of risks of a credit institution. Financ. Credit 2018, 24, 1736–1750. [Google Scholar] [CrossRef]
- Kurennoy, D.S. Algorithm for solving the problem of reverse stress testing the bank’s loan portfolio based on system-dynamic models of borrowers. Int. J. Open Inf. Technol. 2018, 10, 9–21. [Google Scholar]
- Principles for Sound Stress Testing Practices and Supervision. Basel Committee on Banking Supervision. 2009. Available online: https://www.bis.org/publ/bcbs155.pdf (accessed on 25 February 2021).
- Kazansky, A.V. Functioning of the Internal Rating System of a Commercial Bank. Probl. Mod. Econ. 2016, 4, 127–131. [Google Scholar]
- Dedova, M.S. Comparing the bootstrap methods of time series for the purpose of backtesting banking risk assessment models. Econ. J. HSE 2018, 22, 84–109. [Google Scholar] [CrossRef]
- Rashevskikh, M.A. Methods of credit portfolio management in Russia. Econ. Sociol. 2017, 1, 32–34. [Google Scholar]
- Ruiz, I. XVA: Desks—A New Era for Risk Management; Palgrave Macmillan UK: London, UK, 2015; p. 433. [Google Scholar]
- Basel Committee on Banking Supervision. Sound Practices for Backtesting Counterparty Credit Risk Models. 2010. Available online: https://www.bis.org/publ/bcbs185.pdf (accessed on 25 February 2021).
- Bronshtein, E.M.; Shaposhnikova, A.G. Portfolio optimization based on complex index risk measures. Audit Financ. Anal. 2010, 5, 220–224. [Google Scholar]
- Orlova, E.V. The AI Model for Identification the Impact of Irrational Factors on the Investor’s Risk Propensity. In Proceedings of the 30th International Business Information Management Association Conference (IBIMA), Vision 2020: Sustainable Economic Development, Innovation Management, and Global Growth, Madrid, Spain, 8–9 November 2017; pp. 713–721. [Google Scholar]
- Saaty, T. Decision Making with Dependencies and Feedback, Analytic Networks; LKT Publishing House: Moscow, Russia, 2008; p. 360. [Google Scholar]
- Rockafellar, R.T.; Uryasev, S. Conditional Value-at-Risk for General Loss Distribution. J. Bank. Financ. 2002, 26, 1443–1471. [Google Scholar] [CrossRef]
- Rockafellar, R.T.; Uryasev, S. Optimization of Conditional Value-At-Risk. J. Risk 2003, 2, 21–41. [Google Scholar] [CrossRef] [Green Version]
- Rachev, S.T.; Menn, C.; Fabozzi, F.J. Fat-Tailed and Skewed Asset Return Distributions. Implications for Risk Management, Portfolio Selection and Option Pricing; John Wiley & Sons: Hoboken, NJ, USA, 2005; p. 369. [Google Scholar]
- Orlova, E.V. Economic Efficiency of the Mechanism for Credit Risk Management. In Proceedings of the Workshop on Computer Modelling in Decision Making (CMDM 2017), Saratov, Russia, 14–15 November 2019; pp. 139–150. [Google Scholar]
- Niu, B.; Ren, J.; Li, X. Credit Scoring Using Machine Learning by Combing Social Network Information: Evidence from Peer-to-Peer Lending. Information 2019, 10, 397. [Google Scholar] [CrossRef] [Green Version]
- Orlando, G.; Pelosi, R. Non-Performing Loans for Italian Companies: When Time Matters. An Empirical Research on Estimating Probability to Default and Loss Given Default. Int. J. Financ. Stud. 2020, 8, 68. [Google Scholar] [CrossRef]
- Bankova, V.K. Scoring Models to Assess the Creditworthiness of Borrowers in Russia. Izv. Acad. Man. 2011, 4, 14–16. [Google Scholar]
- Glinkina, E.V. Credit Scoring as a Tool for Effective Credit Assessment. Financ. Credit. 2011, 16, 43–47. [Google Scholar]
- Lebedev, E.A. Synthesis of Scoring Models Method of Systemic-Cognitive Analysis. Polythematic Netw. Electron. Sci. J. Kuban State Agrar. Univ. 2007, 29, 17–30. [Google Scholar]
- Makarenko, T.M. The Combination of Scenario Forecasting Procedures with the Dynamic Ranking of Experts when Assessing the Credit Risk of the Borrower—Physical Persons in the Bank. Bull. Leningr. State Univ. A. S. Pushkin. 2012, 3, 56–63. [Google Scholar]
- Crone, S.F.; Finlay, S. Instance Sampling in Credit Scoring: An Empirical Study of Sample Size and Balancing. Int. J. Forecast. 2012, 28, 224–238. [Google Scholar] [CrossRef]
- Crook, J.N.; Edelman, D.B.; Thomas, L.C. Recent Developments in Consumer credit Risk Assessment. Eur. J. Oper. Res. 2007, 3, 1447–1465. [Google Scholar] [CrossRef]
- Mircea, G.; Pirtea, M.; Neamţu, M.; Băzăvan, S. Discriminant Analysis in a Credit Scoring Model. Recent Adv. Appl. Biomed. Inform. Comput. Eng. Syst. Appl. 2011, 2, 56–69. [Google Scholar]
- Ong, C.; Huang, J.; Tzeng, G. Building Credit Scoring Models Using Genetic Programming. Expert Syst. Appl. 2005, 9, 41–47. [Google Scholar] [CrossRef]
- Aebi, V.; Sabato, G.; Schmid, M. Risk management, corporate governance, and bank performance in the financial crisis. J. Bank. Financ. 2012, 12, 3213–3226. [Google Scholar] [CrossRef]
- Berger, A.N.; Sedunov, J. Bank liquidity creation and real economic output. J. Bank. Financ. 2017, 81, 3213–3226. [Google Scholar] [CrossRef]
- Caporale, G.M.; Cerratot, M.; Zhang, X. Analyzing the Determinants of Insolvency Risk for General Insurance Firms in the UK. J. Bank. Financ. 2017, 84, 107–122. Available online: http://www.sciencedirect.com/science/article/pii/%20S0378426617301711 (accessed on 1 November 2020). [CrossRef]
- Basulin, M.A. Analysis Software «Sas Credit Scoring» for the Commercial Bank. Innov. Inf. Technol. 2013, 2, 32–37. [Google Scholar]
- Orlova, E.V. Mechanism for Credit Risk Management. In Proceedings of the 30th International Business Information Management Association Conference (IBIMA), Vision 2020: Sustainable Economic Development, Innovation Management, and Global Growth, Madrid, Spain, 8–9 November 2017; pp. 827–837. [Google Scholar]
- Mehra, R.; Prescott, E.C. The Equity Premium: A Puzzle. J. Monet. Econ. 1985, 5, 145–161. [Google Scholar] [CrossRef]
- Benartzi, S.; Thaler, R. Myopic Loss Aversion and the Equity Premium Puzzle. Q. J. Econ. 1995, 110, 75–92. [Google Scholar] [CrossRef] [Green Version]
- Ang, A.; Bekaert, G.; Liu, J. Why Stocks May Disappoint. J. Financ. Econ. 2000, 76, 471–508. [Google Scholar] [CrossRef] [Green Version]
- Fielding, D.; Stracca, L. Myopic Loss Aversion, Disappointment Aversion, and Equity Premium Puzzle; Working Paper Series; European Central Bank: Frankfurt, Germany, 2003. [Google Scholar]
- Khandani, A.E.; Kim, A.J.; Lo, A.W. Consumer credit risk models via machine learning algorithms. J. Bank. Financ. 2010, 34, 2767–2787. [Google Scholar] [CrossRef] [Green Version]
- McKinsey—Analytics in Banking. 2017. Available online: https://www.mckinsey.com/industries/financial-services/%20our-insights/analytics-in-banking-time-to-realize-the-value (accessed on 19 March 2021).
- McKinsey’s Global Banking Annual Review. 2020. Available online: https://www.mckinsey.com/industries/financial-services/our-insights/global-banking-annual-review (accessed on 19 March 2021).
- Bhatore, S.; Mohan, L.; Reddy, Y.R. Machine learning techniques for credit risk evaluation: A systematic literature review. J. Bank Financ. Technol. 2020, 4, 111–138. [Google Scholar] [CrossRef]
- Machine Learning for Asset Management: New Developments and Financial Applications. ISTE Ltd. 2020. Available online: https://onlinelibrary.wiley.com/doi/book/10.1002/9781119751182 (accessed on 20 March 2021).
- Bagherpour, A. Predicting Mortgage Loan Default with Machine Learning Methods. 2017. Available online: https://www.semanticscholar.org/paper/Predicting-Mortgage-Loan-Default-with-Machine-Bagherpour/a4e53d7255dd397da78242c4ad41213a404cb51e (accessed on 19 March 2021).
- Maheswari, P.; Narayana, C.V. Predictions of Loan Defaulter—A Data Science Perspective. In Proceedings of the 5th International Conference on Computing, Communication and Security (ICCCS), Patna, India, 14–16 October 2020; pp. 1–4. [Google Scholar] [CrossRef]
- Sivasree, M.S. Loan Credibility Prediction System Based on Decision Tree Algorithm. Int. J. Eng. Res. Technol. 2015. [Google Scholar] [CrossRef]
- Krichene, A. Using a naive Bayesian classifier methodology for loan risk assessment. J. Econ. Financ. Adm. Sci. 2017, 22, 3–24. [Google Scholar] [CrossRef]
- Namvar, A.; Siami, M.; Rabhi, F.; Naderpour, M. Credit risk prediction in an imbalanced social lending environment. Int. J. Comput. Intell. Syst. 2018, 11, 925–935. [Google Scholar] [CrossRef] [Green Version]
- Sudhamathy, G. Credit Risk Analysis and Prediction Modelling of Bank Loans Using R. Int. J. Eng. Technol. 2016, 8, 1954–1966. [Google Scholar] [CrossRef] [Green Version]
- Semiu, A.; Gilal, A. A Boosted Decision Tree Model for Predicting Loan Default in P2P Lending Communities. Int. J. Eng. Adv. Technol. 2019, 9. [Google Scholar] [CrossRef]
- Uzair, A.; Ilyas, T.; Asim, S.; Nowshath, B. An Empirical Study on Loan Default Prediction Models. J. Comput. Theor. Nanosci. 2019, 16, 3483–3488. [Google Scholar] [CrossRef]
- Orlova, E.V. Model for Operational Optimal Control of Financial Recourses Distribution in a Company. Comput. Res. Modeling 2019, 2, 343–358. [Google Scholar] [CrossRef] [Green Version]
- Orlova, E.V. Technology for Control an Efficiency in Production and Economic System. In Proceedings of the 30th International Business Information Management Association Conference (IBIMA). Vision 2020: Sustainable Economic Development, Innovation Management, and Global Growth, Madrid, Spain, 8–9 November 2017; pp. 811–818. [Google Scholar]
- Orlova, E.V. Synergetic Approach for the Coordinated Control in Production and Economic System. In Proceedings of the 30th International Business Information Management Association Conference (IBIMA). Vision 2020: Sustainable Economic development, Innovation Management, and Global Growth, Madrid, Spain, 8–9 November 2017; pp. 704–712. [Google Scholar]
- Orlova, E.V. Control over Chaotic Price Dynamics in a Price Competition model. Autom. Remote Control 2017, 78, 16–28. [Google Scholar] [CrossRef]
- Orlova, E.V. Decision-Making Techniques for Credit Resource Management Using Machine Learning and Optimization. Information 2020, 11, 144. [Google Scholar] [CrossRef] [Green Version]
- Friedman, J. Stochastic Gradient Boosting. Comput. Stat. Data Anal. 1999, 38, 367–378. [Google Scholar] [CrossRef]
- Friedman, J. Greedy Function Approximation: A Gradient Boosting Machine. Ann. Stat. 2001, 29, 1189–1232. [Google Scholar] [CrossRef]
- Mason, L.; Baxter, J.; Barlett, R.; Frean, M. Boosting Algorithm as Gradient Descent. Advances in Neural Information Processing Systems Computational Statistics and Data Analysis; MIT Press: Cambridge, MA, USA, 2000; Volume 12, pp. 512–518. [Google Scholar]
- Hastie, T.; Tibshriani, R.; Friedman, J. The Elements of Statistical Learning; Springer: Berlin, Germany, 2014; p. 739. [Google Scholar]
- Provost, F.; Fawcett, T.; Kohavi, R. The case against accuracy estimation for comparing induction algorithms. In Proceedings of the 15th International Conference on Machine Learning, Morgan Kaufmann, San Francisco, CA, USA, 24–27 July 1998; pp. 445–453. [Google Scholar]
- Davis, J.; Goadrich, M. The Relationship Between Precision-Recall and ROC Curves. In Proceedings of the 23rd International Conference on Machine Learning, ACM, Pittsburgh, PA, USA, 25–29 June 2006. [Google Scholar] [CrossRef] [Green Version]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Indicator Group | Indicator | Variable | Range of Value or Binary |
|---|---|---|---|
| anthropometric and social indicators | gender | gender | female (1), male (0) |
| age | age | 18…65 | |
| education level | edu | secondary, specialized (0), higher (1) | |
| profession | proof | any profession (1), no profession (0) housewife, student (0) | |
| family status | mar | single (0), married (1) | |
| children | child | 0, 1, 2, 3, … | |
| finantial indicators | regular income | avinc | yes (1), no (0) |
| income value | aminc | 0...1000000 | |
| loan value | dessum | 0...1000000 | |
| overdue debt value (risk) | risk | 0...1000000 | |
| bad habits | bad_hab | yes (1), No (0) | |
| interests | ints | e.g., career, family, philosophy (1), anti-collector, gambling (0) | |
| bad environment | bad_env | 1 or more (0), 0 (1) | |
| music style | mus | classical, pop, jazz (1), prison nature, prohibited in the RF (0) | |
| film genre | mov | e.g., comedy, family, drama (1), prohibited in the RF (0) | |
| confirmed income | inc | compliant (1), differs (0) | |
| ideal family man | ideal_fam | yes (1), no (0) | |
| digital footprint data | borrower profile assessment | profile | compliant (1), differs (0) |
| frequency of entries to the site on the subject of fraud | fraud | 1 or more (0), less than 1 (1) | |
| frequency of entries to the site on the topic of diseases | illness | 1 or more (0), less than 1 (1) | |
| frequency of entries to the site related to gambling | gambling | 1 or more (0), less than 1 (1) | |
| frequency of entries to the site on the topic of drug distribution and use | drugs | 1 or more (0), less than 1 (1) | |
| frequency of entries to the site on the subject of banned organizations in the RF | forbidden | 1 or more (0), less than 1 (1) | |
| frequency of entries to the site on the topic of business development and self-development | career | 1 or more (0), less than 1 (1) |
| Indicator | Calculated Value | Indicator | Calculated Value |
|---|---|---|---|
| Mean (monetary units) | 1149 | Standard deviation (monetary units) | 4864 |
| Maximum (monetary units) | 35,800 | Variance (%) | 423 |
| Variable | Gender | Age | Edu | Empl | Mar | Child | Avinc | Aminc | Dessum | Risk | Bad_hab | Ints | Bad_env | Mus | Mov | Inc | Ideal_fam | Profile | Fraud | Illness | Gambling | Career |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| gender | 1 | −0.264 | 0.172 | −0.109 | −0.007 | 0.049 | 0.014 | −0.351 | −0.342 | −0.061 | 0.247 | 0.234 | 0.094 | −0.051 | −0.077 | −0.017 | 0.085 | −0.117 | 0.266 | −0.157 | 0.277 | −0.167 |
| age | −0.264 | 1 | 0.159 | 0.145 | 0.373 | 0.245 | 0.034 | 0.363 | 0.324 | 0.086 | 0.143 | 0.13 | 0.145 | 0.164 | 0.128 | 0.06 | 0.193 | 0.095 | −0.001 | −0.021 | 0.131 | 0.183 |
| edu | 0.172 | 0.159 | 1 | 0.092 | 0.171 | 0.038 | 0.093 | 0.149 | 0.09 | −0.132 | 0.283 | 0.239 | 0.203 | 0.252 | 0.184 | −0.076 | 0.252 | 0.055 | 0.131 | −0.118 | 0.223 | 0.282 |
| empl | −0.109 | 0.145 | 0.092 | 1 | −0.055 | −0.029 | 0.623 | 0.239 | 0.139 | 0.057 | 0.124 | 0.119 | 0.074 | 0.335 | −0.014 | 0.229 | −0.045 | −0.048 | −0.029 | −0.076 | 0.241 | 0.1 |
| mar | −0.007 | 0.373 | 0.171 | −0.055 | 1 | 0.473 | 0.059 | 0.221 | 0.331 | −0.095 | 0.097 | 0.321 | 0.176 | 0.14 | 0.069 | 0.046 | 0.485 | 0.157 | 0.14 | 0.002 | 0.188 | 0.157 |
| child | 0.049 | 0.245 | 0.038 | −0.029 | 0.473 | 1 | 0.083 | 0.137 | 0.159 | −0.188 | 0.036 | 0.247 | 0.246 | 0.15 | 0.074 | −0.118 | 0.23 | 0.096 | 0.15 | −0.098 | 0.202 | −0.043 |
| avinc | 0.014 | 0.034 | 0.093 | 0.623 | 0.059 | 0.083 | 1 | 0.154 | 0.121 | −0.182 | 0.014 | 0.131 | −0.036 | 0.187 | −0.023 | 0.164 | 0.072 | 0.076 | −0.047 | −0.122 | 0.297 | −0.034 |
| aminc | −0.351 | 0.363 | 0.149 | 0.239 | 0.221 | 0.137 | 0.154 | 1 | 0.446 | 0.077 | −0.058 | 0.024 | 0.011 | 0.195 | 0.023 | 0.137 | 0.128 | 0.248 | −0.057 | 0.15 | 0.022 | 0.252 |
| dessum | −0.342 | 0.324 | 0.09 | 0.139 | 0.331 | 0.159 | 0.121 | 0.446 | 1 | −0.091 | −0.112 | 0.13 | −0.041 | 0.241 | −0.024 | −0.048 | 0.187 | 0.024 | −0.129 | −0.037 | −0.143 | 0.216 |
| risk | −0.061 | 0.086 | −0.132 | 0.057 | −0.095 | −0.188 | −0.182 | 0.077 | −0.091 | 1 | −0.061 | −0.282 | −0.016 | −0.226 | 0.04 | 0.186 | −0.057 | 0.039 | 0.082 | 0.071 | −0.012 | 0.078 |
| bad_hab | 0.247 | 0.143 | 0.283 | 0.124 | 0.097 | 0.036 | 0.014 | −0.058 | −0.112 | −0.061 | 1 | 0.302 | 0.346 | 0.177 | 0.087 | −0.133 | 0.252 | −0.047 | 0.177 | −0.124 | 0.159 | 0.164 |
| ints | 0.234 | 0.13 | 0.239 | 0.119 | 0.321 | 0.247 | 0.131 | 0.024 | 0.13 | −0.282 | 0.302 | 1 | 0.36 | 0.303 | −0.047 | −0.060 | 0.289 | −0.069 | 0.303 | −0.060 | 0.28 | 0.218 |
| bad_env | 0.094 | 0.145 | 0.203 | 0.074 | 0.176 | 0.246 | −0.036 | 0.011 | −0.041 | −0.016 | 0.346 | 0.36 | 1 | 0.336 | 0.165 | −0.128 | 0.116 | 0.023 | 0.221 | 0.003 | 0.275 | 0.091 |
| mus | −0.051 | 0.164 | 0.252 | 0.335 | 0.14 | 0.15 | 0.187 | 0.195 | 0.241 | −0.226 | 0.177 | 0.303 | 0.336 | 1 | −0.021 | −0.014 | 0.15 | 0.102 | 0.219 | −0.108 | 0.344 | 0.143 |
| mov | −0.077 | 0.128 | 0.184 | −0.014 | 0.069 | 0.074 | −0.023 | 0.023 | −0.024 | 0.04 | 0.087 | −0.047 | 0.165 | −0.021 | 1 | −0.063 | 0.074 | −0.034 | −0.021 | −0.053 | −0.028 | 0.071 |
| inc | −0.017 | 0.06 | −0.076 | 0.229 | 0.046 | −0.118 | 0.164 | 0.137 | −0.048 | 0.186 | −0.133 | −0.060 | −0.128 | −0.014 | −0.063 | 1 | 0.084 | −0.059 | −0.127 | 0.153 | 0.003 | 0.153 |
| ideal_fam | 0.085 | 0.193 | 0.252 | −0.045 | 0.485 | 0.23 | 0.072 | 0.128 | 0.187 | −0.057 | 0.252 | 0.289 | 0.116 | 0.15 | 0.074 | 0.084 | 1 | 0.175 | 0.15 | −0.015 | 0.201 | 0.243 |
| profile | −0.117 | 0.095 | 0.055 | −0.048 | 0.157 | 0.096 | 0.076 | 0.248 | 0.024 | 0.039 | −0.047 | −0.069 | 0.023 | 0.102 | −0.034 | −0.059 | 0.175 | 1 | 0.102 | −0.097 | 0.039 | −0.121 |
| fraud | 0.266 | −0.001 | 0.131 | −0.029 | 0.14 | 0.15 | −0.047 | −0.057 | −0.129 | 0.082 | 0.177 | 0.303 | 0.221 | 0.219 | −0.021 | −0.127 | 0.15 | 0.102 | 1 | 0.015 | 0.344 | 0.035 |
| illness | −0.157 | −0.021 | −0.118 | −0.076 | 0.002 | −0.098 | −0.122 | 0.15 | −0.037 | 0.071 | −0.124 | −0.060 | 0.003 | −0.108 | −0.053 | 0.153 | −0.015 | −0.097 | 0.015 | 1 | 0.138 | 0.013 |
| gambling | 0.277 | 0.131 | 0.223 | 0.241 | 0.188 | 0.202 | 0.297 | 0.022 | −0.143 | −0.012 | 0.159 | 0.28 | 0.275 | 0.344 | −0.028 | 0.003 | 0.201 | 0.039 | 0.344 | 0.138 | 1 | −0.058 |
| career | −0.167 | 0.183 | 0.282 | 0.1 | 0.157 | −0.043 | −0.034 | 0.252 | 0.216 | 0.078 | 0.164 | 0.218 | 0.091 | 0.143 | 0.071 | 0.153 | 0.243 | −0.121 | 0.035 | 0.013 | −0.058 | 1 |
| Variable | Gender | Age | Edu | Empl | Mar | Child | Avinc | Aminc | Dessum | Bad_hab | Ints | Bad_env | Mus | Mov | Inc | Ideal_fam | Profile | Fraud | Illness | Gambling | Drugs | Forbidden | Career | Risk |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| gender | 1 | −0.163 | 0.172 | −0.109 | −0.007 | −0094 | 0.014 | −0.315 | −0.359 | 0.247 | 0.234 | 0.094 | −0.051 | −0.077 | −0.017 | 0.085 | −0.117 | 0.266 | −0.157 | 0.232 | −0.109 | 0.038 | −0.167 | −0.060 |
| age | −0.163 | 1 | −0.096 | 0.09 | 0.393 | 693 | 0.093 | 0.129 | 0.269 | 0.076 | 0.135 | −0.101 | 0.1 | 0.049 | −0.057 | 0.153 | 0.065 | 0.064 | −0.058 | 0.134 | 0.04 | 0.08 | 0.062 | −0.002 |
| edu | 0.172 | −0.096 | 1 | 0.092 | 0.171 | 45 | 0.093 | −0.055 | 0.13 | 0.283 | 0.239 | 0.203 | 0.252 | 0.184 | −0.076 | 0.252 | 0.055 | 0.131 | −0.118 | 0.277 | −0.078 | 0.092 | 0.282 | −0.165 |
| empl | −0.109 | 0.09 | 0.092 | 1 | −0.055 | −0066 | 0.623 | 0.125 | 0.111 | 0.124 | 0.119 | 0.074 | 0.335 | −0.014 | 0.229 | −0.045 | −0.048 | −0.029 | −0.076 | 0.221 | −0.020 | −0.020 | 0.1 | 0.03 |
| mar | −0.007 | 0.393 | 0.171 | −0.055 | 1 | 644 | 0.059 | 0.1 | 0.305 | 0.097 | 0.321 | 0.176 | 0.14 | 0.069 | 0.046 | 0.485 | 0.157 | 0.14 | 0.002 | 0.202 | 0.098 | 0.098 | 0.157 | −0.012 |
| child | −0.094 | 0.693 | 0.045 | −0.066 | 0.644 | 1000 | 0.026 | 0.146 | 0.31 | 0.07 | 0.233 | 0.044 | 0.102 | 0.05 | −0.031 | 0.398 | 0.102 | 0.102 | −0.105 | 0.147 | 0.071 | 0.071 | 0.058 | 0.014 |
| avinc | 0.014 | 0.093 | 0.093 | 0.623 | 0.059 | 0.026 | 1 | 0.106 | 0.136 | 0.014 | 0.131 | −0.036 | 0.187 | −0.023 | 0.164 | 0.072 | 0.076 | −0.047 | −0.122 | 0.271 | −0.033 | −0.033 | −0.034 | −0.094 |
| aminc | −0.315 | 0.129 | −0.055 | 0.125 | 0.1 | 0.146 | 0.106 | 1 | 0.22 | −0.104 | −0.152 | 0.082 | 0.106 | 0.024 | 0.114 | −0.001 | 0.112 | −0.013 | 0.143 | 0.064 | 0.039 | 0.045 | 0.116 | −0.058 |
| dessum | −0.359 | 0.269 | 0.13 | 0.111 | 0.305 | 0.31 | 0.136 | 0.22 | 1 | −0.145 | 0.087 | −0.059 | 0.166 | 0.018 | −0.005 | 0.1 | −0.026 | −0.109 | −0.037 | −0.137 | 0.092 | 0.055 | 0.302 | 0.01 |
| bad_hab | 0.247 | 0.076 | 0.283 | 0.124 | 0.097 | 0.07 | 0.014 | −0.104 | −0.145 | 1 | 0.302 | 0.346 | 0.177 | 0.087 | −0.133 | 0.252 | −0.047 | 0.177 | −0.124 | 0.182 | −0.164 | −0.020 | 0.164 | −0.037 |
| ints | 0.234 | 0.135 | 0.239 | 0.119 | 0.321 | 0.233 | 0.131 | −0.152 | 0.087 | 0.302 | 1 | 0.36 | 0.303 | −0.047 | −0.060 | 0.289 | −0.069 | 0.303 | −0.060 | 0.342 | 0.119 | −0.067 | 0.218 | −0.244 |
| bad_env | 0.094 | −0.101 | 0.203 | 0.074 | 0.176 | 0.044 | −0.036 | 0.082 | −0.059 | 0.346 | 0.36 | 1 | 0.336 | 0.165 | −0.128 | 0.116 | 0.023 | 0.221 | 0.003 | 0.319 | −0.087 | 0.074 | 0.091 | −0.083 |
| mus | −0.051 | 0.1 | 0.252 | 0.335 | 0.14 | 0.102 | 0.187 | 0.106 | 0.166 | 0.177 | 0.303 | 0.336 | 1 | −0.021 | −0.014 | 0.15 | 0.102 | 0.219 | −0.108 | 0.316 | −0.029 | −0.029 | 0.143 | −0.373 |
| mov | −0.077 | 0.049 | 0.184 | −0.014 | 0.069 | 0.05 | −0.023 | 0.024 | 0.018 | 0.087 | −0.047 | 0.165 | −0.021 | 1 | −0.063 | 0.074 | −0.034 | −0.021 | −0.053 | −0.030 | −0.014 | −0.014 | 0.071 | 0.021 |
| inc | −0.017 | −0.057 | −0.076 | 0.229 | 0.046 | −0.031 | 0.164 | 0.114 | −0.005 | −0.133 | −0.060 | −0.128 | −0.014 | −0.063 | 1 | 0.084 | −0.059 | −0.127 | 0.153 | −0.020 | 0.07 | 0.07 | 0.153 | 0.108 |
| ideal_fam | 0.085 | 0.153 | 0.252 | −0.045 | 0.485 | 0.398 | 0.072 | −0.001 | 0.1 | 0.252 | 0.289 | 0.116 | 0.15 | 0.074 | 0.084 | 1 | 0.175 | 0.15 | −0.015 | 0.216 | 0.105 | 0.105 | 0.243 | −0.025 |
| profile | −0.117 | 0.065 | 0.055 | −0.048 | 0.157 | 0.102 | 0.076 | 0.112 | −0.026 | −0.047 | −0.069 | 0.023 | 0.102 | −0.034 | −0.059 | 0.175 | 1 | 0.102 | −0.097 | 0.025 | −0.048 | −0.048 | −0.121 | 0.036 |
| fraud | 0.266 | 0.064 | 0.131 | −0.029 | 0.14 | 0.102 | −0.047 | −0.013 | −0.109 | 0.177 | 0.303 | 0.221 | 0.219 | −0.021 | −0.127 | 0.15 | 0.102 | 1 | 0.015 | 0.316 | −0.029 | −0.029 | 0.035 | 0.043 |
| illness | −0.157 | −0.058 | −0.118 | −0.076 | 0.002 | −0.105 | −0.122 | 0.143 | −0.037 | −0.124 | −0.060 | 0.003 | −0.108 | −0.053 | 0.153 | −0.015 | −0.097 | 0.015 | 1 | 0.11 | 0.097 | −0.076 | 0.013 | −0.038 |
| gambling | 0.232 | 0.134 | 0.277 | 0.221 | 0.202 | 0.147 | 0.271 | 0.064 | −0.137 | 0.182 | 0.342 | 0.319 | 0.316 | −0.030 | −0.020 | 0.216 | 0.025 | 0.316 | 0.11 | 1 | −0.042 | −0.042 | −0.028 | −0.260 |
| drugs | −0.109 | 0.04 | −0.078 | −0.020 | 0.098 | 0.071 | −0.033 | 0.039 | 0.092 | −0.164 | 0.119 | −0.087 | −0.029 | −0.014 | 0.07 | 0.105 | −0.048 | −0.029 | 0.097 | −0.042 | 1 | −0.020 | −0.052 | 0.03 |
| forbidden | 0.038 | 0.08 | 0.092 | −0.020 | 0.098 | 0.071 | −0.033 | 0.045 | 0.055 | −0.020 | −0.067 | 0.074 | −0.029 | −0.014 | 0.07 | 0.105 | −0.048 | −0.029 | −0.076 | −0.042 | −0.020 | 1 | −0.052 | 0.03 |
| career | −0.167 | 0.062 | 0.282 | 0.1 | 0.157 | 0.058 | −0.034 | 0.116 | 0.302 | 0.164 | 0.218 | 0.091 | 0.143 | 0.071 | 0.153 | 0.243 | −0.121 | 0.035 | 0.013 | −0.028 | −0.052 | −0.052 | 1 | 0.006 |
| risk | −0.060 | −0.002 | −0.165 | 0.03 | −0.012 | 0.014 | −0.094 | −0.058 | 0.01 | −0.037 | −0.244 | −0.083 | −0.373 | 0.021 | 0.108 | −0.025 | 0.036 | 0.043 | −0.038 | −0.260 | 0.03 | 0.03 | 0.006 | 1 |
| Variable | Average Value in Cluster | |||
|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |
| age | 29.2 | 24.2 | 23.7 | 27.6 |
| child | 0.62 | 0.03 | 0 | 0.22 |
| aminc | 31,531.2 | 25,137.93 | 38,941.2 | 38,500.0 |
| gender | 1 | 1 | 0 | 0 |
| edu | 1 | 1 | 0 | 1 |
| empl | 1 | 1 | 1 | 1 |
| mar | 1 | 0 | 0 | 0 |
| avinc | 1 | 1 | 1 | 1 |
| bad hab | 1 | 1 | 0 | 0 |
| ints | 1 | 1 | 0 | 1 |
| bad env | 1 | 1 | 1 | 0 |
| mus | 1 | 1 | 1 | 1 |
| mov | 1 | 1 | 1 | 1 |
| inc | 1 | 1 | 1 | 1 |
| ideal fam | 1 | 0 | 0 | 0 |
| profile | 1 | 1 | 1 | 1 |
| fraud | 1 | 1 | 1 | 1 |
| illness | 1 | 1 | 1 | 1 |
| gambling | 1 | 1 | 1 | 1 |
| drugs | 1 | 1 | 1 | 1 |
| forbidden | 1 | 1 | 1 | 1 |
| career | 0 | 1 | 0 | 1 |
| cluster size | 32 | 29 | 17 | 22 |
| Variable | Statistical Metric | Number of Borrowers in Cluster | |||
|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | ||
| age | Minimum | 23 | 22 | 20 | 22 |
| Maximum | 57 | 32 | 26 | 59 | |
| Mean | 29.2 | 24.2 | 23.7 | 27.7 | |
| Standard deviation | 9.87 | 1.68 | 1.44 | 8.1 | |
| child | Minimum | 0 | 0 | 0 | 0 |
| Maximum | 2 | 1 | 0 | 2 | |
| Mean | 1 | 0.1 | 0 | 0.3 | |
| Standard deviation | 0.4 | 0.02 | 0 | 0.05 | |
| aminc | Minimum | 10,000 | 2000 | 100,000 | 18,000 |
| Maximum | 100,000 | 60,000 | 300,000 | 109,000 | |
| Mean | 31,531 | 25,137 | 138,941 | 38,500 | |
| Standard deviation | 17,542 | 10,252 | 67,755 | 21,054 | |
| requested loan amount | Minimum | 70,000 | 50,000 | 100,000 | 30,000 |
| Maximum | 700,000 | 900,000 | 550,000 | 800,000 | |
| Mean | 248,125 | 178,448 | 165,300 | 340,681 | |
| Standard deviation | 167,166 | 181,339 | 53,569 | 232,083 | |
| overdue debt amount | Minimum | 0 | 0 | 0 | 0 |
| Maximum | 30,000 | 5000 | 35,800 | 3500 | |
| Mean | 917 | 172 | 3735 | 159 | |
| Standard deviation | 5300 | 928 | 8837 | 745 | |
| Cluster Number | Credit Risk Level | Borrower Reliability |
|---|---|---|
| 1 | no risk | very high |
| 2 | low risk | high |
| 3 | high risk | low |
| 4 | medium risk | medium |
| Observed | Predicted | Percent Correct | |
|---|---|---|---|
| Reliable (0) | Risky (1) | ||
| Reliable (0) | 31 (TN) | 55 (FP) | 36 |
| Risky (1) | 6 (FN) | 8 (TP) | 57 |
| Observed | Predicted | Percent Correct | |
|---|---|---|---|
| Reliable (0) | Risky (1) | ||
| Reliable (0) | 12 (TN) | 74 (FP) | 14 |
| Risky (1) | 2 (FN) | 12 (TP) | 86 |
| Borrower ID | Checking for Compliance with Loan Conditions | Interim Assessment on a 4-Point Scale | |||
|---|---|---|---|---|---|
| RF Citizenship | Working Age | Permanent Work | Registration in the Region where the Borrower Applies for a Loan | ||
| 001 | + | + | + | + | 4 |
| 002 | + | + | + | + | 4 |
| 003 | + | + | + | + | 4 |
| Borrower ID | Financial Position | Sociodemographic Data | Credit History | Final Assessment Score | |||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Regular Income | Monthly Income | Gender | Age | Education | Profession | Marital Status | Children | Out-Standing Loans | Delays in Payments | ||
| 001 | + | 29,000 | f | 28 | high | specialist | married | - | absent | 10 | |
| 002 | + | 23,000 | f | 21 | special | seller | single | - | absent | 8 | |
| 003 | + | 32,000 | m | 26 | high | teller | single | - | absent | 9 | |
| Borrower ID | Requested Loan (RUB) | Requested Loan Term (years) | Interest Rate (%) | CW Class |
|---|---|---|---|---|
| 001 | 300,000 | 5 | 12 | high (no risk) |
| 002 | 500,000 | 7 | 11 | high (no risk) |
| 003 | 200,000 | 5 | 12 | high (no risk) |
| Variable/Indicator | Borrower ID | ||
|---|---|---|---|
| 001 | 002 | 003 | |
| age | 28 | 21 | 26 |
| child | 0 | 0 | 0 |
| aminc | 29,000 | 23,000 | 32,000 |
| dessum | 300,000 | 500,000 | 200,000 |
| gender | 1 | 1 | 0 |
| edu | 1 | 0 | 1 |
| empl | 1 | 1 | 1 |
| mar | 1 | 0 | 0 |
| avinc | 1 | 1 | 1 |
| bad hab | 0 | 0 | 0 |
| ints | 0 | 0 | 0 |
| bad env | 1 | 1 | 1 |
| mus | 1 | 1 | 0 |
| mov | 0 | 1 | 1 |
| inc | 0 | 0 | 0 |
| ideal fam | 0 | 0 | 0 |
| profile | 1 | 0 | 0 |
| fraud | 1 | 0 | 0 |
| illness | 0 | 0 | 1 |
| gambling | 0 | 0 | 0 |
| drugs | 0 | 0 | 0 |
| forbidden | 0 | 0 | 1 |
| career | 0 | 0 | 0 |
| Cluster of the borrower | 4 | 2 | 3 |
| Credit risk level | medium | low | high |
| Reliability | medium | high | low |
| Indicator | Borrower ID | ||
|---|---|---|---|
| 001 | 002 | 003 | |
| Level of CW (and risk) by the old methodology | high (no risk) | high (no risk) | high (no risk) |
| Level of CW (and reliability) by the new methodology | medium | medium | medium |
| Potential risk associated with an incorrect assessment of the borrower’s CW (for the entire crediting period) (RUB) | 90,000 | 25,000 | 160,000 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Orlova, E.V. Methodology and Models for Individuals’ Creditworthiness Management Using Digital Footprint Data and Machine Learning Methods. Mathematics 2021, 9, 1820. https://doi.org/10.3390/math9151820
Orlova EV. Methodology and Models for Individuals’ Creditworthiness Management Using Digital Footprint Data and Machine Learning Methods. Mathematics. 2021; 9(15):1820. https://doi.org/10.3390/math9151820
Chicago/Turabian StyleOrlova, Ekaterina V. 2021. "Methodology and Models for Individuals’ Creditworthiness Management Using Digital Footprint Data and Machine Learning Methods" Mathematics 9, no. 15: 1820. https://doi.org/10.3390/math9151820
APA StyleOrlova, E. V. (2021). Methodology and Models for Individuals’ Creditworthiness Management Using Digital Footprint Data and Machine Learning Methods. Mathematics, 9(15), 1820. https://doi.org/10.3390/math9151820