3.1.1. Bike Sharing Demand
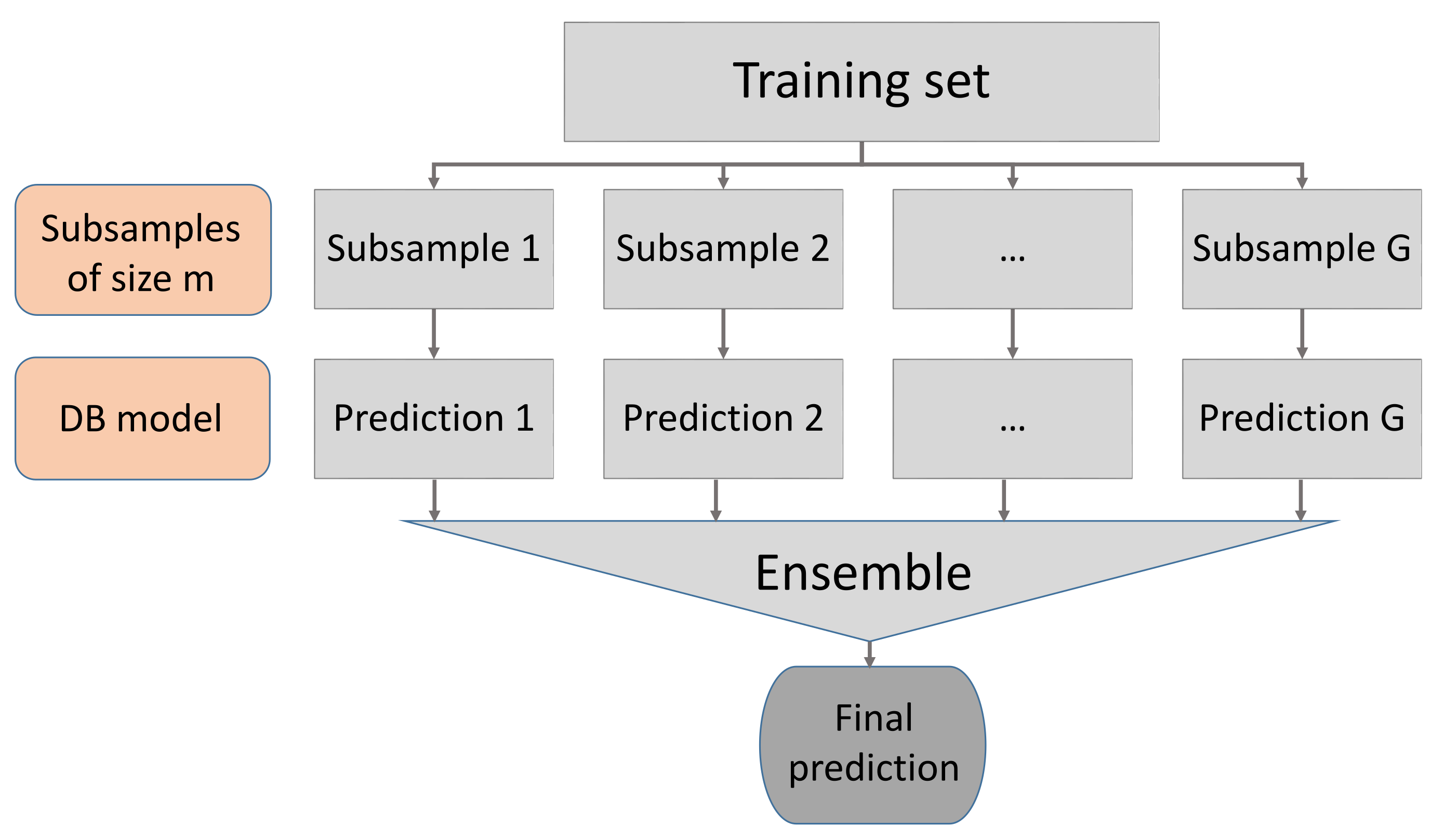
Let us fix the values of the technical parameters in the subsampling, aggregation, and overall analysis. In each of the Monte Carlo runs, the sample was randomly divided into a test sample (of 290 individuals) and a training one (of size ). We have tried three different numbers G of subsamples: 3, 5 and 10 and three different values for the subsample size, , 300, 600 and 900. For this specific dataset, of relatively low size, we have been able to compute the predicted responses in the test sample using DB-LM on all the training sample. Thus, we are able to compute the mean squared error attained using all the training information simultaneously in the classical linear regression (only with the quantitative predictors) and the DB-LM. These results are compared with the MSE obtained with the ensemble procedures.
In
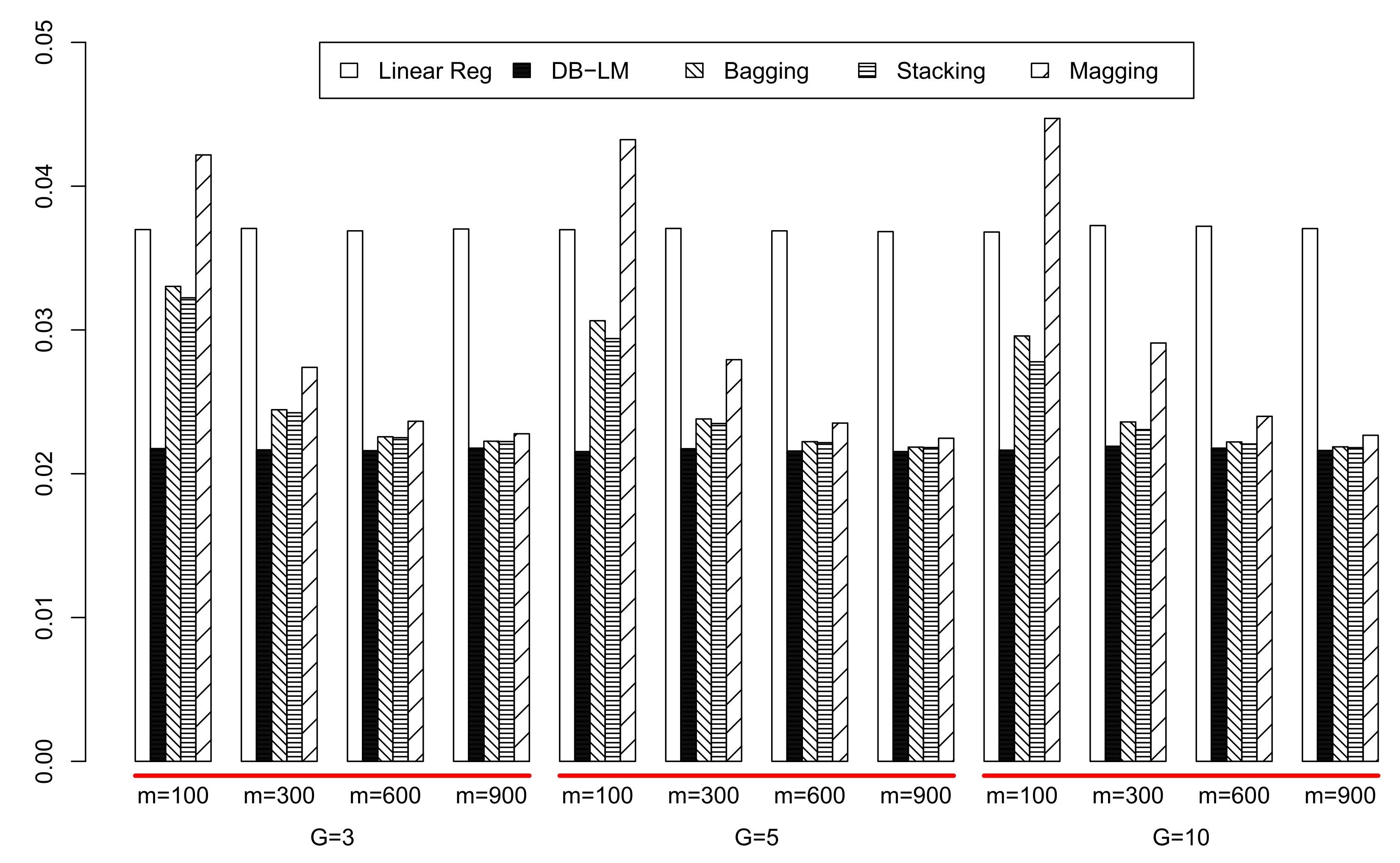
Table 3, we display the average and standard deviation of mean squared prediction errors (MSE), computed from 500 iterations, for the subsampling and aggregation methods. With linear regression, DB-LM and random forests (R-package
ranger with 100 trees,
mtry = 7,
depth = 20) the MSE is, respectively, 0.03700, 0.02168, and 0.01746. In
Figure 3, we show the mean squared errors for all the regression methods. For this data set, it is clear that the number
G of subsamples does not have a great influence on the MSE: this is good news since increasing
G increases also noticeably computation time and memory requirements. In
Table 4, we see the subsample size
m and the overall number
of observations used as input in the ensemble predictions. From
Table 3 and
Table 4 and
Figure 3, we can see that, for
and
, even if
is considerably below 100%, the three aggregation procedures are very near the MSE of DB-LM using the whole sample. Bagging and stacking actually show very good performance for all values of
G and
(which is only 11% of the training sample size). Conversely, for any
G, magging needs at least a subsample size
for its MSE to get closer to that of bagging and stacking. A possible explanation to the worse performance of magging with respect to bagging and stacking is that any inhomogeneity in the data is well described by the qualitative predictors. Furthermore, the information of these is already incorporated into the bagging and stacking DB regression procedures via the distance matrix. Of course, it is important to choose a convenient dissimilarity between qualitative variables.
In order to statistically test the differences on the performance of the ensemble methods under evaluation, we conducted two-sided paired-sample Wilcoxon tests (with Bonferroni correction). The performance of each method is evaluated with the MSE distribution computed from 500 runs within each scenario.
Table 5 contains the
p-values of these tests, from which we conclude that all methods are significantly different in all cases. For all choices of
G and
m, the best aggregation procedure is stacking, but it is always very closely followed by bagging. Again, this is also good news: even if the DB-LM has a high computational complexity, the simplest aggregation procedure, bagging, is a very good alternative to reduce the effective sample size in the DB procedure (and the dimension of the distance matrix involved) and, consequently, its computational cost, without a significant increase in the MSE of response prediction.
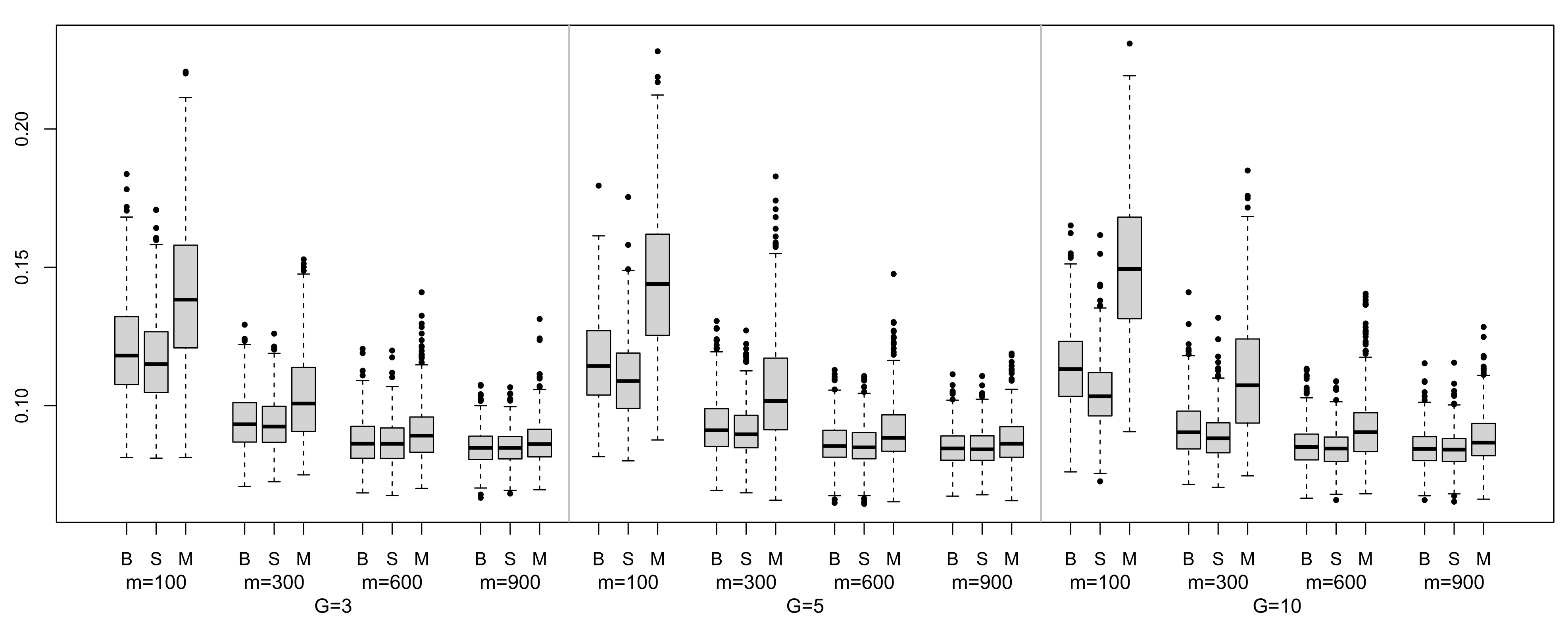
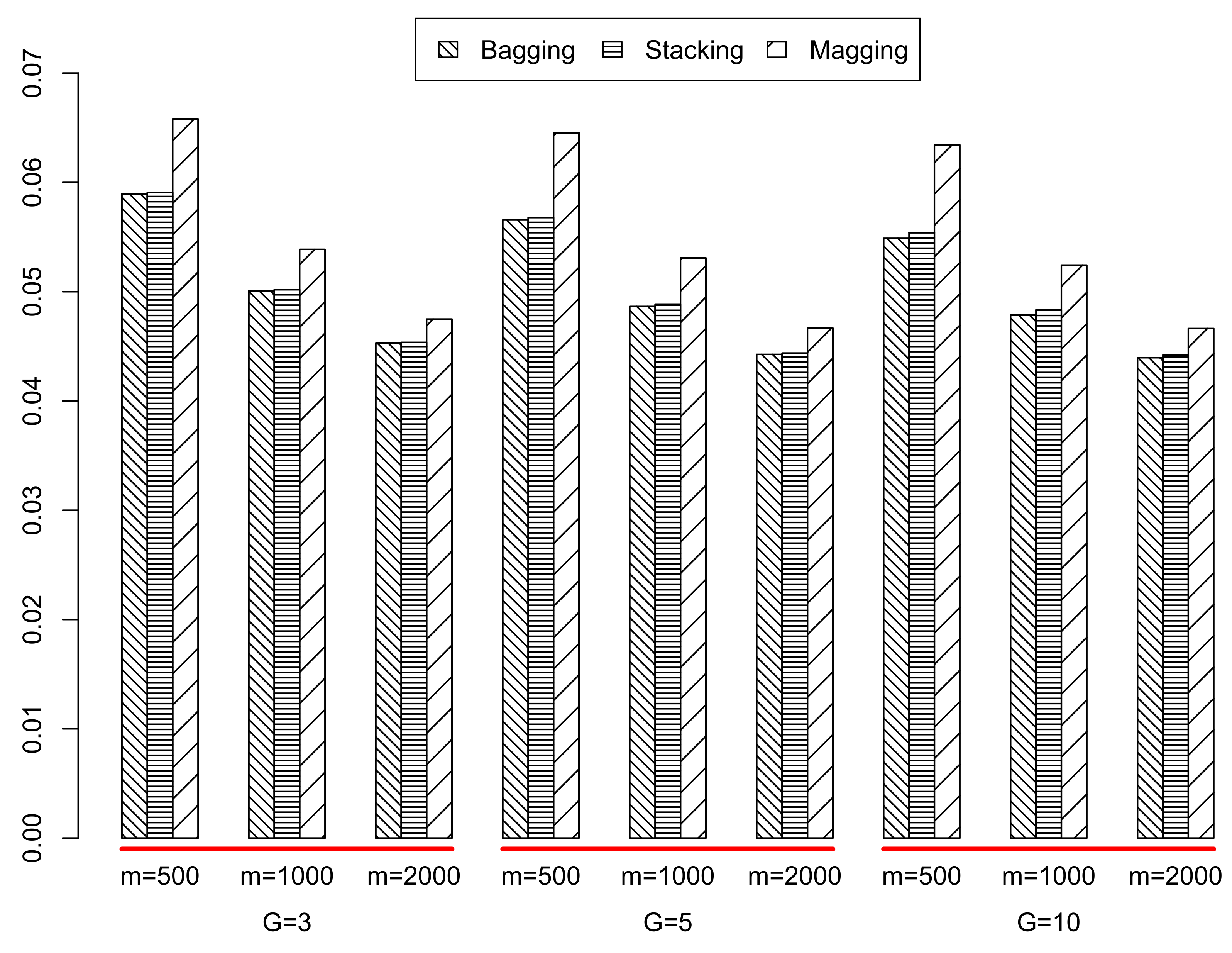
Additionally, we studied the median absolute prediction errors (MAE) of the ensemble methods under study for this data set.
Figure 4 contains the box plots of the MAE distributions computed from 500 runs in each scenario. Most of the distributions are rightly skewed, with the exception of magging for
; In general, magging takes greater median values than bagging or stacking and these differences are even greater for
. Summing up, it seems that the best performance is attained by stacking, although as
m increases, the differences between stacking and bagging tend to decrease.
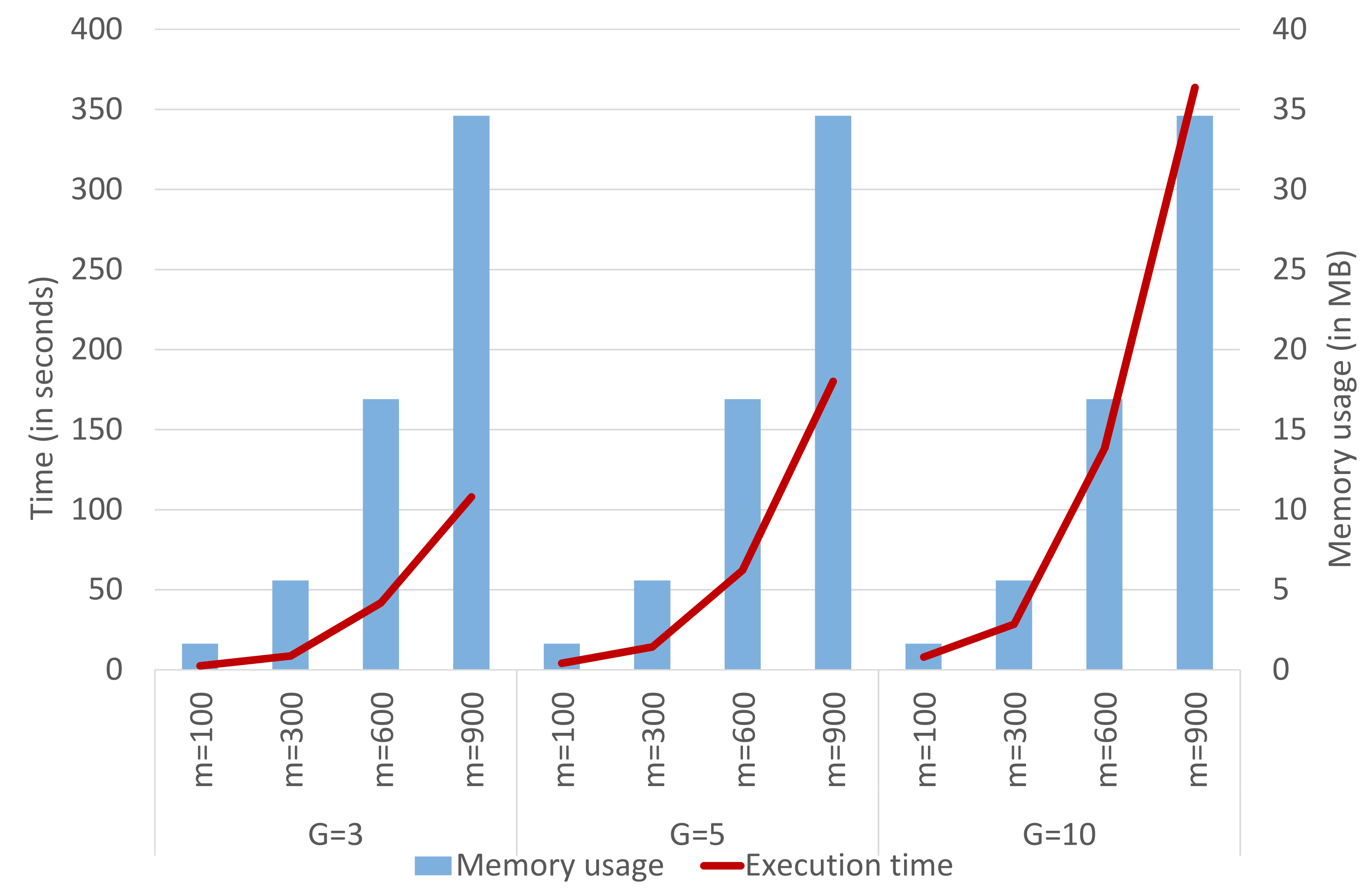
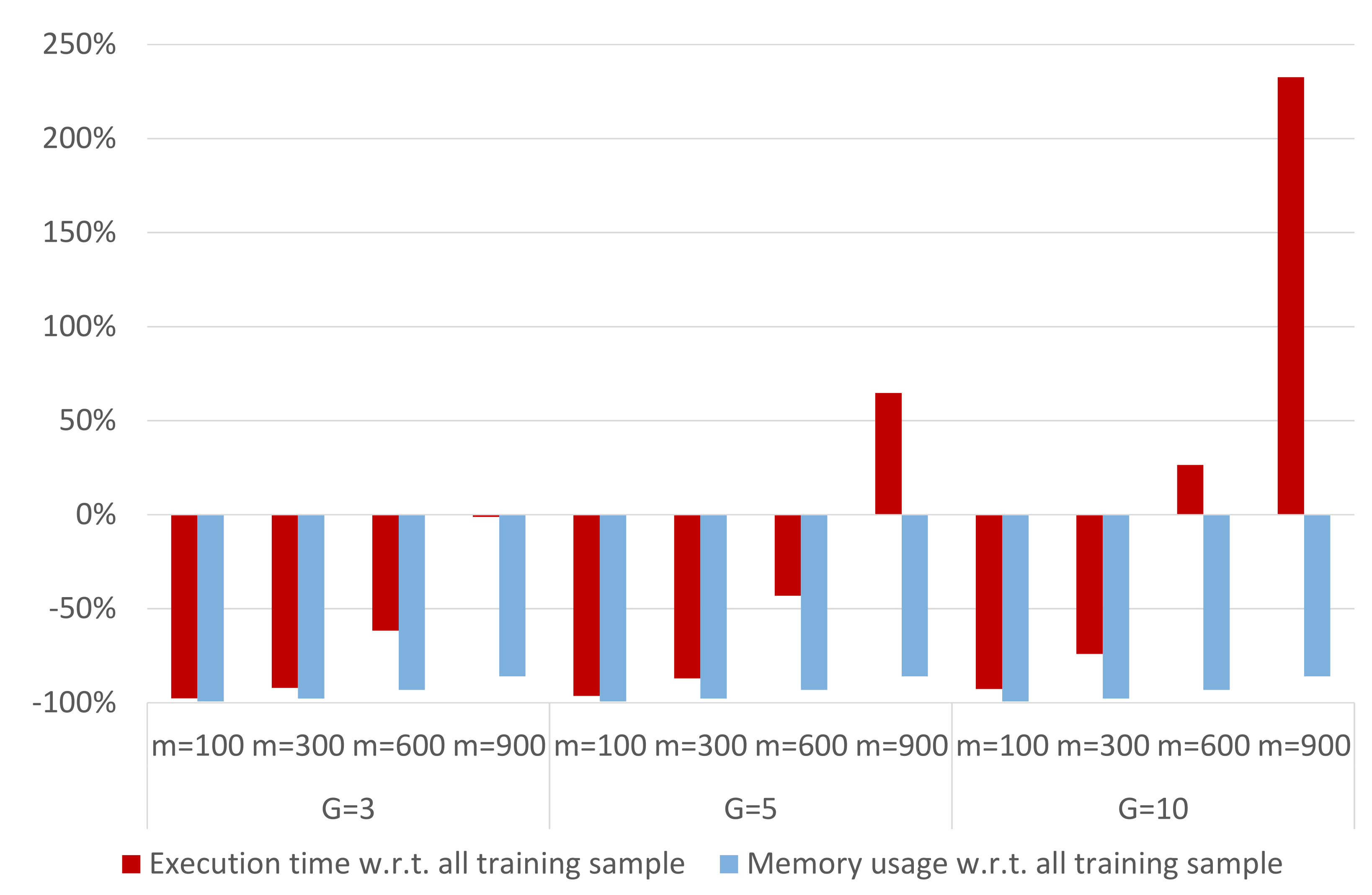
Finally, we analyze the complexity reduction, in terms of execution time and memory usage, when applying an ensemble technique to the DB-LM prediction model. Thus, we focus on the following R-functions, which are the actual bottlenecks of the computation process:
daisy,
disttoD2, and
dblm. For the Capital Bikeshare data, DB-LM takes 109.35 s and occupies 247.3 MB when predicting 290 new cases based on a training sample of 2903 observations. On the other hand, the LM model takes 0.03 s to make these predictions and uses 1 MB of memory. DB-LM execution times and memory usage can considerably be reduced when applying any of the ensemble methods studied (in fact, they take 0 s in the optimization and averaging procedures for the predictions, which is why the execution time refers only to the three R-functions mentioned above). This can be seen in
Figure 5, where we analyze the complexity of the ensemble DB-LM prediction model. We observe that the memory usage increases with
m, although it remains constant with
G. The execution time increases with
m and
G. These findings reinforce our conclusion that, for
and
, the ensemble DB-LM prediction model provides a solution to the scalability problem, since the complexity of the DB-LM prediction model is considerably reduced and MSE is very close to that of the DB-LM (see
Figure 3 and
Figure 6).
3.1.2. King County House Sales
In each run of the Monte Carlo experiment, the whole sample was randomly divided into a test sample of 2159 individuals and a training sample of size
n = 19,435. The number
G of subsamples used was again 3, 5, and 10, and the values for the subsample size were
, 1000, and 2000. Given the large value of
n, in this case it was not possible to perform DB regression on the whole training sample. Consequently, we report the average and standard deviation of the mean squared error attained with the ensemble procedures applied to DB-LM. In
Table 6 and
Table 7 and
Figure 7, we display these results. For standard linear regression (using all the training information but only the quantitative predictors), the MSE was 0.10093, and with random forests (with 100 trees,
mtry = 10,
depth = 20) it was 0.04704.
In
Table 8, we provide the
p-values of the two-sided paired-sample Wilcoxon tests (with Bonferroni correction) conducted to compare the performance of the three ensemble methods for the King County sales data. As before, we evaluated the performance of each method with the MSE distribution computed from 500 runs within each scenario. The results confirm that all methods are significantly different in all cases. The results support even more the conclusions of
Section 3.1.1. In this case, the best performing method is always bagging, although the results of stacking are almost identical. However, since the optimization inherent to stacking increases complexity as the sample size increases, again we strongly recommend the use of bagging in this framework of DB regression. Magging does not perform as well as bagging or stacking, even for the largest values of
G and
m. Larger values of
m for stacking or magging were impossible to handle in the several, different computing resources we used (see Acknowledgements), even when dividing the Monte Carlo experiment in batches of 50 runs.
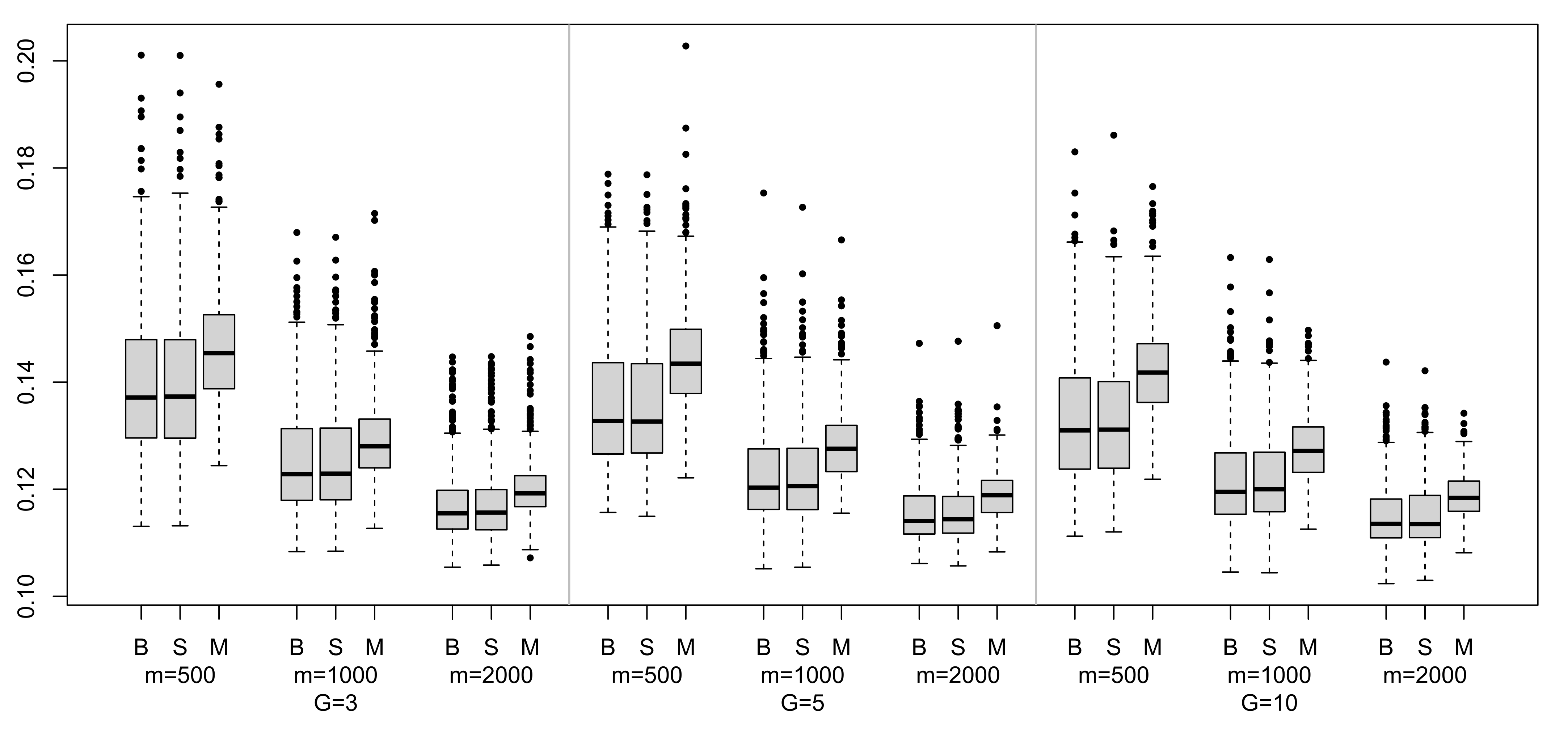
As before, we studied the MAE of the ensemble methods under study for this second data set.
Figure 8 contains the box-plots of the MAE distributions computed from 500 runs in each scenario. We observe that all of them are rightly skewed distributions and that magging always takes greater median values than bagging or stacking, which seem to have a very similar distribution.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}