1. Introduction
Coronavirus disease 2019 (COVID-19), which was first reported in Hubei, China at the end of 2019, has spread globally during 2020. The World Health Organization (WHO) renamed this disease as COVID-19 in 11 February 2020 and made the assessment that COVID-19 can be characterized as the third pandemic caused by coronavirus, after SARS-CoV (2002) and MERS-CoV (2012) [
1]. According to a report from Johns Hopkins University, by 18 July 2021, there were 183.82 million confirmed cases and 3.97 million deaths from COVID-19 worldwide. More than 190 countries have confirmed cases of COVID-19, and the cumulative number of confirmed cases in eight countries exceeds 500,000, these being the United States (USA), India, Brazil, France, Russia and Turkey, and four countries (USA, India, Brazil and Mexico) have more than 200,000 deaths. There is no doubt that COVID-19 has brought a serve threat to the health and livelihoods of people all over the world. In the face of the wanton spread of the epidemic, it is important to effectively discover the internal dynamic laws of the epidemic and build an effective epidemic model to analyze and predict the spread of the disease. Implementation of such a model can minimize the impact of the epidemic on the community economy and help countries around the world take reasonable epidemic prevention and control measures.
The prediction of an epidemic refers to the application of dynamical, statistical, and other models to estimate the trend of the number of future cases, this being the compass of epidemic prevention and control. According to the prediction principle, the existing COVID-19 epidemic models can be divided into the dynamical models based on mechanistic analysis and the statistical models based on actual data. Among the dynamical models, the SIR model, the SEIR model, and their extensions can reflect the intrinsic dynamical characteristics of the spread of infectious diseases and can better reproduce the development process of diseases, reveal the epidemic law, and predict the change trend, so they are favored by researchers. Yang et al. [
2] used the improved SEIR model to predict and analyze the epidemic under the prevention and control policies, and the experimental results showed that strong prevention and control policies could effectively inhibit the spread of the epidemic. Wu et al. [
3] predicted the global spread of COVID-19 using an improved SEIR model. Lopez et al. [
4] used the modified SEIR model to predict the COVID-19 outbreak in Spain and Italy. Ashutosh et al. [
5] estimated pure asymptomatic infection cases based on a SEIR model. The results showed that infection may last for a long time without a vaccine. Tang et al. [
6] proposed that the risk of secondary outbreaks can be effectively reduced by intermittent population mobility and effective isolation of infected people in the floating population based on a novel stochastic discrete transmission model. In the meantime, the data-driven statistical models were also widely used in the prediction and analysis of COVID-19 epidemics, including function fitting models [
7,
8,
9], machine learning [
10,
11], deep learning [
12,
13], and time series models [
14,
15].
It is well-known that the basic infection number
plays an important role in such dynamical models. However, it is difficult to accurately estimate this parameter due to the fact that it can vary depending on a number of factors [
16]. To overcome this difficulty, Huang et al. [
17] proposed a data-driven, simple calculation of the dynamic propagation rate to replace
based on the law of natural growth. Subsequently, Hu et al. [
18] used a power function to fit the dynamic transmission rate to predict and analyze epidemic in China. Hu et al. [
19] developed a dynamic growth rate model (DGRM) to predict and analyze epidemic at abroad. Both of studies used a single prediction model that could not be adjusted adapted according to the actual situation. Inspired by existing work [
17,
18,
19], Xie et al. [
20] proposed an nonlinear combinational dynamic transmission rate model based on support vector regression (SVR) to analyze the epidemic situation of major cities in China. Their work improved the problem of insufficient prediction accuracy of single model, but the sub-model selection method was manual selection, which lacked interpretability, and the selection method needed to be strengthened. In addition, in the face of complex epidemic data abroad, the results of using a single kernel function for research are often unsatisfactory.
In the present work, we propose an improved nonlinear combinational dynamic transmission rate model (INCDTRM), that can automatically select the optimal sub-model based on forecasting effective measure (FEM) and SVR. We employ the model to predict the existing cases and inflection points of COVID-19 for USA, Canada, Germany, Italy, France, Spain, South Korea, Iran and the global epidemic, and we present a comparative case analysis. The results show that such a combinational model is able to predict new cases with very high efficiency, in some countries above 95%. This study may help in understanding the development trend of COVID-19 and the effectiveness of mitigation measures.
The remainder of this article is organized as follows.
Section 2 introduces the dynamic transmission rate, and explains the use of SVR and FEM.
Section 3 discusses our simulations and empirical studies, including dataset description, choice of sliding window period, weight and parameters setting in SVR, comparative analysis of different models, inflection point prediction, sensitivity analysis and the global epidemic forecast. Some conclusions are drawn in
Section 4.
2. Methodology
2.1. Dynamic Transmission Rate
Let
be the existing number of cases at time
t, where
,
, and
are cumulative confirmed cases, cumulative cures and cumulative deaths, respectively. Then, we have
where
is the growth rate of the number of existing infections at time
t. It follows from Equation (
1) that
Considering that only taking the number of existing cases in two adjacent days to calculate the dynamic growth rate is not robust and is vulnerable to data fluctuations, a sliding window period
k is introduced into Equation (
1) to obtain the following new dynamic growth rate, i.e.,
which is similar to the average growth rate. It follows that
. Equaiton (
3) is the geometric average of the ratio of the number of existing infections during a sliding window period, and the calculated results will be more robust. The corresponding dynamic growth rate sequence becomes smoother with the increasing of the sliding window period.
To facilitate the calculation, the discrete value of dynamic transmission rate is given by
where
is non-negativity. It should be noted that when the
is close to 0, which means the epidemic has basically ended, that is, the cumulative confirmed cases are not changing again. In addition, we define this special case, i.e.,
, as the inflection point of the epidemic [
18]. We record the farthest day of the dataset as 1 and the nearest as
T, so it follows that
.
According to the discrete value of the dynamic transmission rate
, selecting an effective function
to fit
is the key to accurately predicting a COVID-19 outbreak. Some well-known fitting functions
in
Table 1 are considered in this paper.
It should be noted that the parameters
and
of
can respectively reflect the severity of the initial epidemic and the degree of human interference in the development of the epidemic, including the effectiveness of preventive measures and the abundance of medical resources. For the three-parameter logarithmic function
, the parameters
and
have similar role to the corresponding parameters in fitting function
, and
can reflect the number of people infected in the initial epidemic. However, for the fitting functions
and
, the parameters of
can be positive or negative, and the parameters of
fluctuate strongly. In fact, the parameters of
and
have strong interpretability, and their prediction abilities are poor, while the parameters of
and
have poor interpretability, and their prediction abilities are strong (shown in
Section 3.4).
Therefore, we use the functions
to fit the discrete value of dynamic transmission rate
and build a nonlinear weighted least squares model as follows:
where
is the weighting function. By solving the above model, we can obtain the values of the unknown parameters in
, so that the concrete form of
can be obtained.
In order to make full use of the data during the optimal sliding window period, the number of existing cases is predicted by
where
and
represent the predicted value of dynamic transmission rate at time
and the estimated numbers of existing cases at time
t, respectively. When
is unknown, we can use
instead of it.
2.2. Support Vector Regression
The support vector machine (SVM) is one of the most important predictive models; it has been widely used in various fields and has achieved great success. In addition, it has the advantages of fast learning, global optimization and strong generalization ability. In particular, SVR is an important application of SVM. The main idea is to introduce an
-insensitive loss function in SVM to adapt to the regression problem and use a kernel function to map the sample set to the high-dimensional feature space to achieve nonlinear regression. Due to its powerful fitting and generalization abilities, SVR has been widely used in various fields, such as in industry [
21,
22] and atmospheric field [
23,
24].
Let
be the learning sample set, where
and
represent the input values and the corresponding desired output, respectively, and
N is the number of samples. The general form of the regression function of SVR can be formulated by:
where
and
b stand for the weight vector and the offset, respectively. The original problem of SVR can be transformed into the following optimization problem:
where slack variables
,
make the SVR tolerate the noises or errors and
C is a pre-set penalty factor. Though constructing a Lagrangian function and using the KKT conditions, the entire problem can be formulated as the following optimization problem:
where
and
are Lagrange multipliers.
Let
be the optimal solution of the optimization problem (
9). Then the decision function can be expressed as follows:
where
and
is a scalar in
called bias term. More discussions of SVR and SVM can be found in the work by Vapnik et al. [
25,
26] and references within.
It is well-known that the performance of an SVR model is mainly dependent on the so-called kernel functions; these include the linear kernel function, the polynomial kernel function, the Gaussian kernel function, and so on. Peng et al. [
27] reported that overfitting for the Gaussian kernel function and the linear kernel function had the worst in-sample but the best out-of-sample performance when predicting the epidemic pattern. Therefore, we combine these two kernel functions linearly, and the expression of the combined kernel function is given by
where
is the weight coefficient,
represents the kernel parameter, and
and
represent the
i-th and
j-th samples, respectively.
SVR has many advantages in measuring tolerance error, solving nonlinear and high dimensional pattern recognition, and then use these to improve the forecasting. Also, it is advantageous to forecast COVID-19 cumulative cases, especially when the sample sizes are small [
28]. In this paper, SVR is used to combine multiple single models nonlinearly, i.e., multiple fitting functions, to construct a nonlinear combination dynamic transmission rate model.
2.3. Forecasting Effective Measure
FEM was proposed by Chen in 2001 [
29] as an indicator to measure the effectiveness of a model; this can be used to select the optimal sub-models to build a combination forecasting model. In addition, FEM represents the average and comprehensive accuracy of the model, which can be described by the mean of accuracy and the standard deviation reflecting the degree of dispersion.
Let
be a learning sample, and
where
is the actual value at time
t and
is the relative error of the
i-th model at time
t. Then the expression for FEM of the
i-th model
is provided below, i.e.,
where
and
represent the mathematical expectation and the standard deviation of the
i-th model
, respectively, which are defined by
and
where the
is same in Equation (
5).
The fundamental purpose of the combined forecasting is to add additional single models to the existing model to improve the forecasting effect. If the new model cannot improve the accuracy of the combined model (a so-called “redundant” model), then we eliminate it. The algorithm for selecting the optimal sub-model employed in this paper is given in Algorithm 1 below.
| Algorithm 1 Selecting the optimal combined model based on FEM and SVR |
Input: Sub-models ,() Output: The optimal combined model - 1:
begin - 2:
Evaluate using Equation ( 13), . - 3:
Sort : . - 4:
Let , . - 5:
fordo - 6:
Get the corresponding estimated dynamic transmission rate by and . - 7:
Call SVR, take the estimated and the real dynamic transmission rate as the training input and the desired output of SVR to construct a combination model , and evaluate using Equation ( 13). - 8:
if then - 9:
Let , and . - 10:
end if - 11:
end for - 12:
Calculate the number of sub-models in . - 13:
if = 1 then - 14:
Let . - 15:
end if - 16:
return
|
2.4. Process Steps
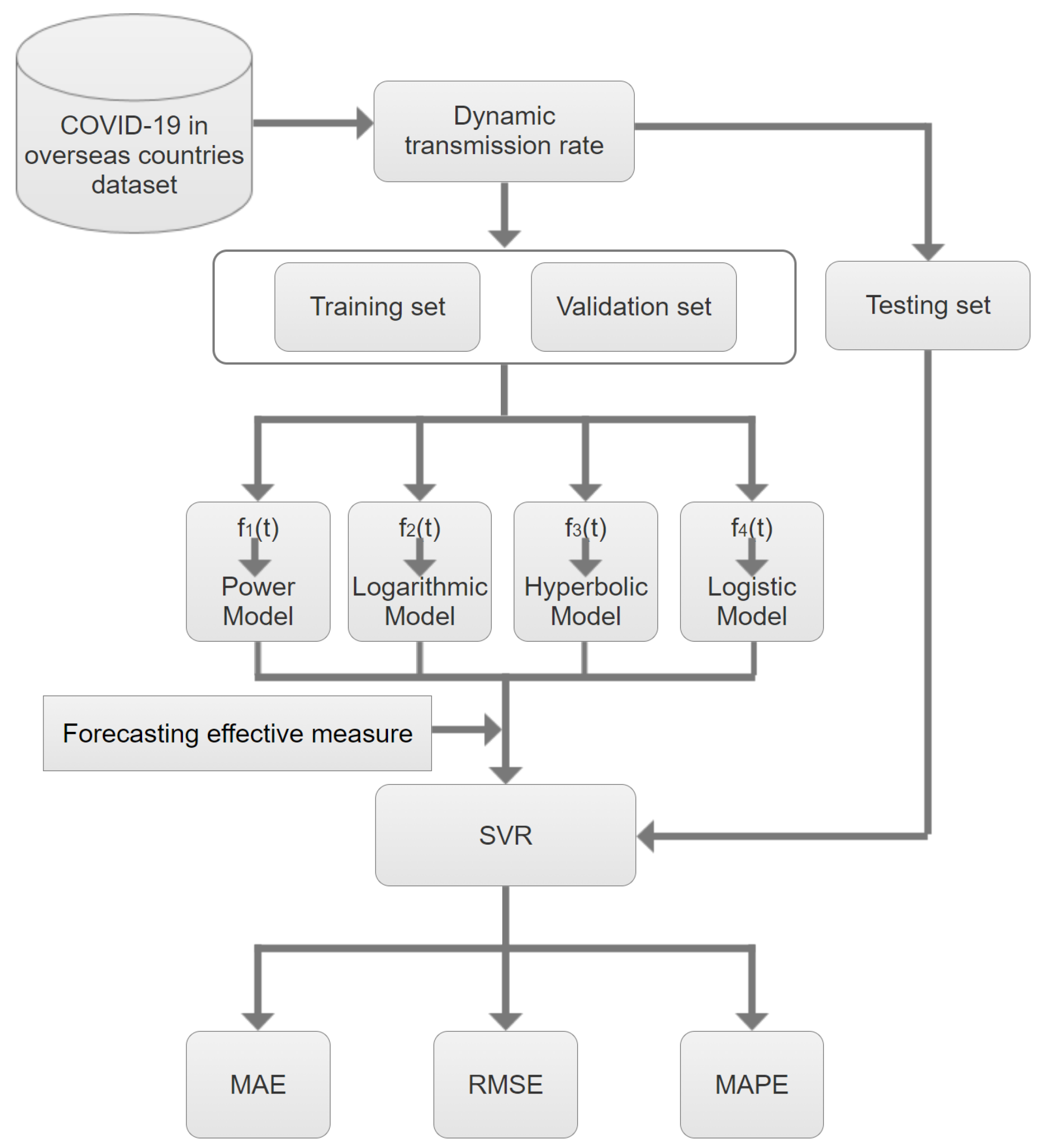
The forecasting framework of INCDTRM is carried out in seven main stages, that are shown in
Figure 1 and explained below.
Input Cumulative confirmed cases , Cumulative deaths , Cumulative cures , .
Output Estimates of the existing cases , .
Step 1. Calculating the existing cases , .
Step 2. Choosing the best sliding window period k.
Step 3. Calculating
using Equations (
3) and (
4), and divided the result into two parts. 3/4 sub-sets are used as the training set where time
and the remaining sub-sets are devoted as the validation set,
.
Step 4. Fitting the training set based on four fitting functions (), and getting the estimated dynamic transmission rate ,
Step 5. Introducing () into SVR, and using SVR to estimate the dynamic transmission rate () corresponding to the validation set. Then selecting the optimal combined model based on FEM and SVR by Algorithm 1.
Step 6. Predicting the dynamic transmission rate from the optimal combined model
, and calculating the estimated number of existing cases using Equation (
6) after the
T-th periods, respectively.
Step 7. The performance of the model is determined by the mean absolute error (MAE), root mean square error (RMSE), and mean absolute percentage error (MAPE), which are given by
and
respectively, where
and
are the estimated numbers of existing cases and actual numbers of existing cases, respectively.
It should be noted that in Step 6, training set and validation set are used to train the SVR and select the corresponding model parameters, respectively. Therefore, in the calculation of FEM, we consider the fitting ability and prediction ability of the model, which effectively avoids the overfitting of the model.
3. Results and Discussion
All our numerical experiments are carried out on a PC with AMD Ryzen 7 4800u CPU at 1.80 GHz and 16 GB of physical memory. The PC runs Python Version: 3.7.2 on Window 10 Enterprise 64-bit operating system, and the nonlinear fitting model and the SVR regression model are imported from the SVM class of sklearn python library and leastsq class of scipy python library.
3.1. Dataset Description
The COVID-19 data repository (
https://github.com/CSSEGISandData/COVID-19, accessed on 17 September 2021) used in the study was obtained from the Johns Hopkins University Center for Systems Science and Engineering (JHU CSSE) [
30]. In this paper, we consider the following countries: USA, Canada, Germany, Italy, France, Spain, South Korea and Iran. The cumulative confirmed cases and deaths in each country, as well as the period from the first and last reports, are listed in
Table 2.
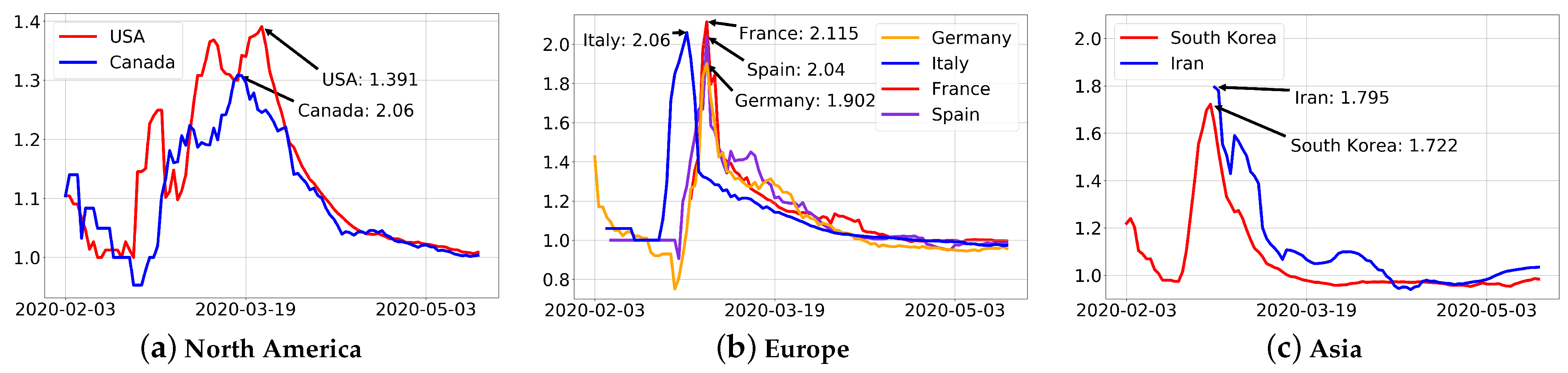
17 May 2020 is the end date of the first wave of the epidemic in most countries. When sliding window period is set to 7, the resulting dynamic transmission rates of the eight countries are shown in
Figure 2.
Figure 2 shows that most countries experienced three stages, including a slow growth in the early stage, a rapid increase in the middle stage and a slow decline in the later stage. The experimental objects of this paper are mainly the third stage of overseas countries, i.e., the data after the dynamic transmission rate reaches the peak, and the subsets before 28 April 2020 are used to train the model to predict cases from 28 April 2020 to 17 May 2020. The data is normalized before training SVR and the normalized formula is given by
3.2. Choice of Sliding Window Period
The best sliding window period can effectively improve the prediction ability of the model. The basic idea of selecting the best sliding window period employed in this paper is to calculate the average mean absolute error (AVG_MAE) of four single models under different sliding window periods, and then determine the best sliding window period
k according to the minimum AVG_MAE. The algorithm used for selecting the sliding window period in this paper is given in Algorithm 2 below.
| Algorithm 2 Selecting the best sliding window period |
Input: Existing cases , Output: The best sliding window period k - 1:
begin - 2:
Divide the data into two parts, a training set where and a testing set where . - 3:
fordo - 4:
Evaluate the dynamic transmission rate using Equations ( 3) and ( 4) with the training set. - 5:
Built four prediction models using Equation ( 5). - 6:
Predict the dynamic transmission rate using four single models , and evaluate the estimated values of existing cases using ( 6), . - 7:
Evaluate the MAE of the four models using Equation ( 16), and calculate AVG_MAE. - 8:
end for - 9:
return min(AVG_MAE) → best k
|
Using Algorithm 2, we obtain the best sliding window periods for eight countries (
Table 3). The results show that the best sliding window periods for North American and European countries are larger than those for Asia. The result is attributed to the sliding window period being capable of effectively suppressing data fluctuations due to the large numbers of existing cases in North American and European countries.
3.3. Weight and Parameters Setting in SVR
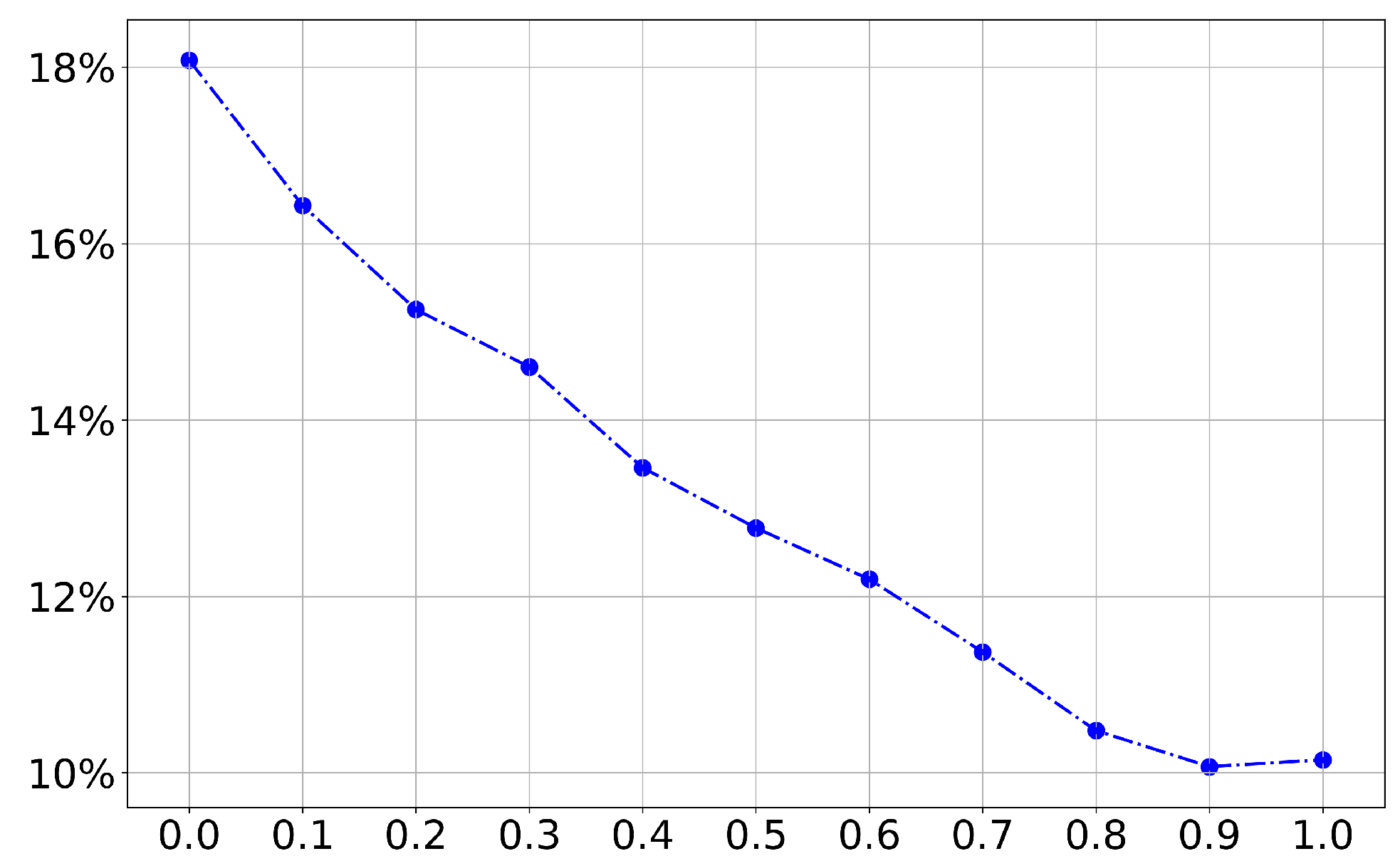
Reasonable parameters for SVR can effectively improve the model’s fitting and predictive ability. In this paper, we use the grid search to select the weight
of the combined kernel function, and
Figure 3 shows the average MAPE of the epidemic prediction in eight countries under different weights
.
It can be seen from
Figure 3 that with the increase of weight, the average MAPE shows a decreasing trend, and when the weight is 0.9, the predicted average MAPE takes the minimum value, so the weight of the combined kernel function is set to 0.9 in this paper.
In addition, the particle swarm optimization (PSO) algorithm is used to search the optimal parameters for SVR. The initial values of the parameters in the PSO algorithm are set as shown in
Table 4 and the results are displayed in
Table 5.
3.4. Comparative Analysis of Different Models
To verify the validity of each model, we present the experimental results in detail in this subsection; at the same time, we also compare the performance results of our proposed method with the six different regression models, including four single methods, DGRM [
19], and nonlinear combinational dynamic transmission rate model (NCDTRM). In
Table 6, we present the predictive performance on the testing set of seven models (from 28 April 2020 to 17 May 2020).
Table 6 shows that INCDTRM achieves the best results in multiple countries, followed by NCDTRM, and both combinational models obtain better prediction performance than single models. The MAPEs of INCDTRM are calculated as 1.20%, 3.11%, 7.81%, 3.97%, 8.66%, and 4.42% for USA, Canada, Germany, Italy, Spain and South Korea, respectively. These results illustrate the accuracy of INCDTRM in estimating the number of existing COVID-19 daily cases. Among them, the MAE and RMSE of INCDTRM are the smallest for Germany, but the MAPE is larger than that of the model
. This is because when INCDTRM is used to predict the epidemic in Germany, the date with the largest number of existing cases is relatively accurate, but the date of the smallest number of existing cases has a larger prediction error.
Although the prediction accuracy of INCDTRM is not as good as that of SVR when predicting the epidemic pattern in USA and Iran, the overall accuracy of INCDTRM is better than that of the other six models, and the AVG_MAPE of INCDTRM is 10.07%, indicating the reliability and feasibility of the FEM in selecting the optimal sub-model.
It should be noted that when forecasting the epidemic pattern in France and Iran, all models perform very poorly. This situation occurs because the number of confirmed cases in these two countries has unpredictably increased and second wave of the epidemic has appeared. Moreover, the fitting functions used in this paper are all monotonically decreasing functions. If the predicted country has a second wave of the epidemic, i.e., the dynamic transmission rate increases instead of decreasing, then all models in this paper will fail. This is the defect of this type of model.
3.5. Inflection Point Prediction
In this subsection, we estimate the inflection points of the epidemics in these countries. The definition of the inflection point is that the number of existing cases does not increase until it starts to decline, i.e., the dynamic transmission rate is equal to 1 [
18]. The epidemic has the following properties around the inflection point: Before the inflection point, the epidemic is at an increasing stage; at the inflection point, the epidemic has the greatest pressure on the prevention and the medical system; after the inflection point, the epidemic situation has eased, and the pressure on prevention and control has gradually reduced. The emergence of an inflection point indicates that the number of existing infections has reached the maximum and has since been declining, which means that the epidemic is turning from bad to good. Using this model to estimate the inflection point of the epidemic can provide a reference value for understanding the epidemic spreading trend and can guide the timely release of relevant policies. The results are displayed in
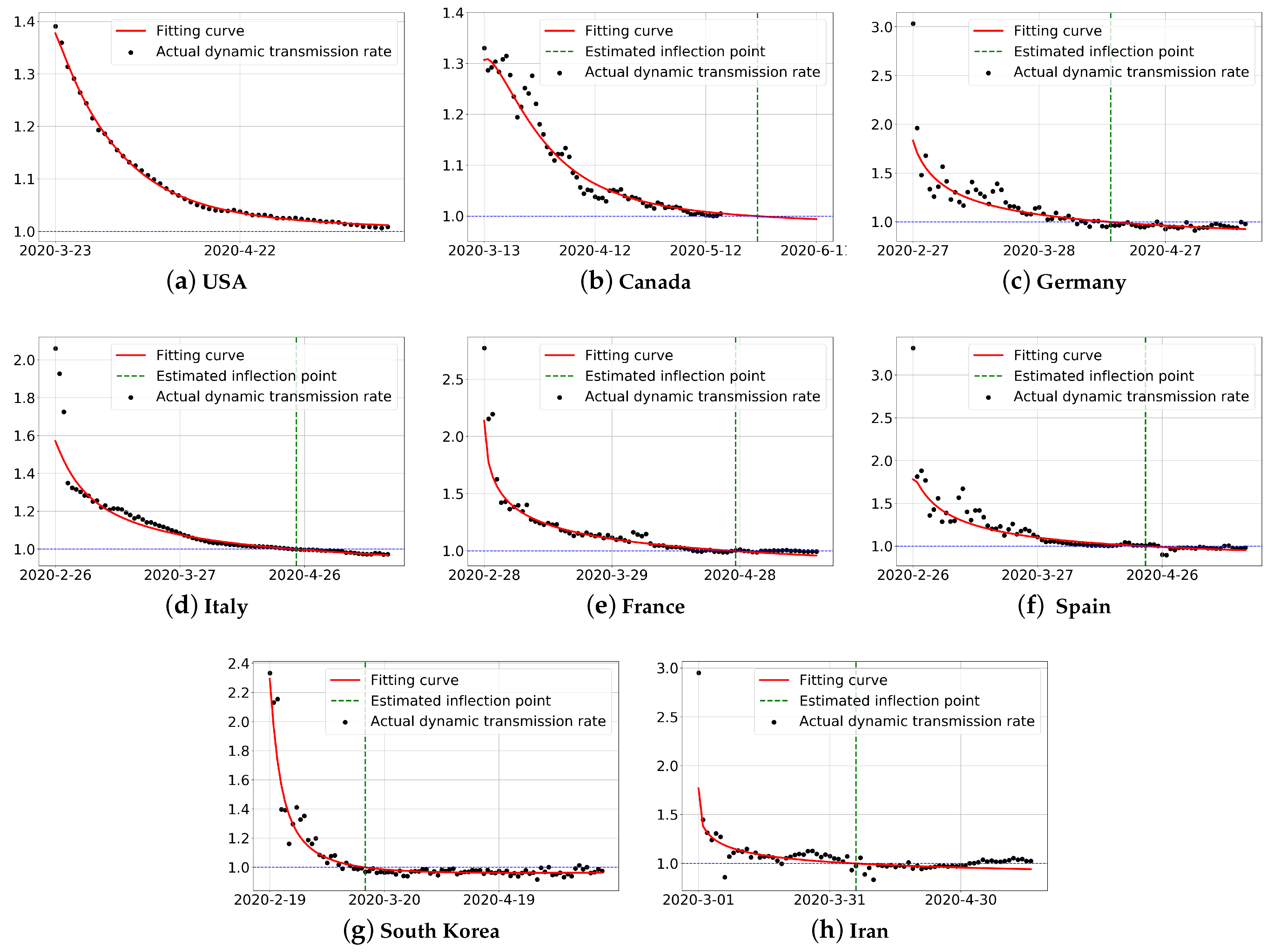
Table 7 and
Figure 4.
Figure 4 shows that there is a delay between the estimated inflection point and the actual inflection point. This due to the fact that the model introduces the sliding window period
k, which delays the transmission and updating of information, and the delay increases with the size of the sliding window period. However, most of the inflection point estimation errors are within one week.
Figure 4a,b show that the epidemic spread in North American countries is relatively late. The fitting curve of USA is relatively flat, but the change in the dynamic transmission rate from 22 April 2020 to 27 April 2020 is very small, and the decline in the curve is not obvious in the subsequent prediction, which is approximately a straight line, and resulting in a backward estimate of the inflection point. The outbreak in Canada fluctuate considerably, but overall shows a downward trend, and the inflection point is estimated in 26 May 2020.
Figure 4c–f show that European countries do not pay enough attention to the epidemic in the early stages, and the epidemic spread more rapidly, meaning that the dynamic transmission rate is larger. Then, with the subsequent strengthening of the prevention and control measures, the epidemic trend improves. Finally, the inflection points of Germany, Italy, France and Spain are estimated in 14 April 2020, 24 April 2020, 27 April 2020 and 22 April 2020, respectively. It should be noted that the dynamic transmission rate of France hovered in Annex 1 from 15 April to 27 April, which led to the delay of the estimated inflection point.
Figure 4g,h show that in the epidemic curves for South Korea and Iran, the declines are larger in the early days, meaning that the slopes of the curves are comparatively large. This is mainly due to the two countries implementing strong prevention and control measures in the early stages, and the epidemic situation is quickly brought under control. The inflection points for South Korea and Iran are estimated to be 14 March 2020 and 5 April 2020, respectively, earlier than those for European and North American countries. However, the outbreak in Iran rebounds again in May, and this is the main reason for the relatively large error in the forecast.
3.6. Sensitivity Analysis
Due to the deviation of epidemic statistics and the lag of data updating in various countries, whether the prediction model can effectively resist noise, that is, the impact of small changes in the original data on the output of the model, is also an important evaluation index in this paper.
The data is processed as follows: the daily number of existing cases is randomly added or reduced by 0–1% of its own value. Then the output of the model is compared with the output of the original model, and the formula of relative change rate is as follows:
where
and
represent the output of the noise model and the output of the original model, respectively. Each country has done 10 experiments, and the experimental results are shown in the form of average ± standard deviation.
As shown in
Table 8, in terms of dynamic transmission rate, the average rate of change in all countries is less than 0.3%. Except Germany and France, all average variabilities of the existing number of cases in other countries are not greater than 3%. For Germany, the fluctuation of the early dynamic transmission rate is obvious, and the later dynamic transmission rate fluctuates periodically (as shown in
Figure 4), which are the reasons for the larger average rate of change. It is noteworthy that the standard deviation of the change rate in the existing number of cases in Italy is greater than that in Germany, but the average ± standard deviation is better than that in Germany. The average change rate of the dynamic transmission rate in all experiments was smaller than that of the existing infected population. This is because that the base number of the existing cases was large, and the small change of the dynamic transmission rate would cause large changes in the existing infected population. On the whole, our model has good anti-noise ability and stability when dealing with data fluctuations.
3.7. Global Epidemic Forecast
Accurate prediction of the global epidemic is the key to effectively grasping the overall trend of the COVID-19 pandemic. Based on the high performance of INCDTRM, we analyze and forecast the global epidemic. Since the global epidemic database is large and the data period is long, the late dynamic transmission rate is almost linear, and we do not have the ability to predict it. Therefore, the data are preprocessed as follows. First, we select the data from 1 April to 30 June 2021. Then, the existing case sequence is calculated, and the sequence is subtracted from the number of the existing cases on 31 March 2021. Finally, we take the sequence as experimental dataset.
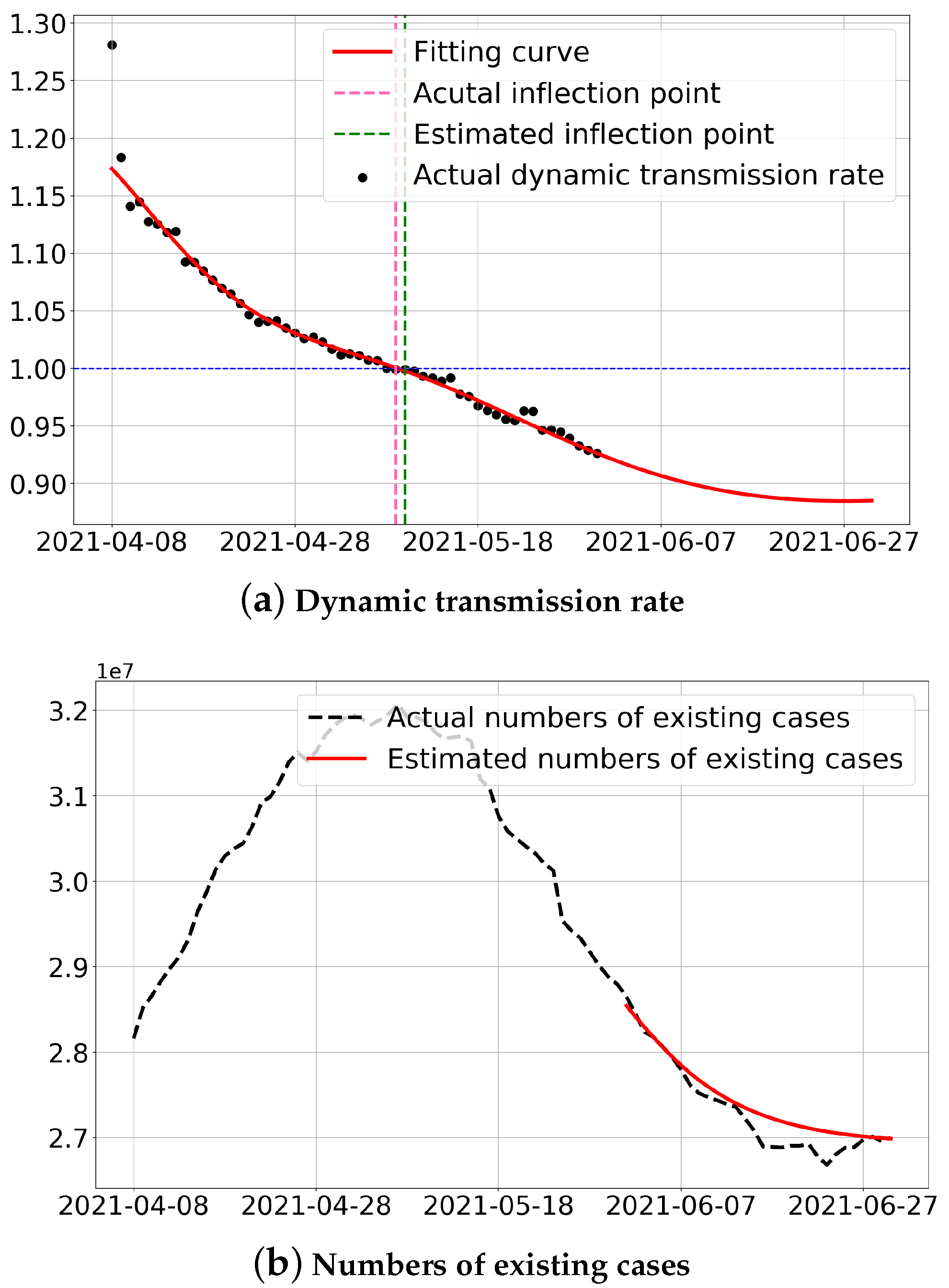
Figure 5 shows the development trend of the global epidemic in the future using INCDTRM.
As shown in
Figure 5a, the spread of the global epidemics is falling, but with the increase of time, the declining trend of the global dynamic transmission rate begins to slow down. The inflection point is predicted as 10 May 2021, in which the actual inflection point was 9 May 2021, indicating that the model in this paper has high reliability. In addition, the number of existing infections is predicted in the global epidemic from 1 June to 30 June 2021, a total of 30 days. In
Figure 5b, the number of existing infections in the global epidemic is decreasing, and the estimated number of existing cases is consistent with the actual trend of the number of existing cases. The estimated errors of MAE, RMSE and MAPE are 141,374.15, 182,765.24 and 0.522%, respectively.
However, the number of existing infections in the global epidemic fluctuated in June 2021. Therefore, we should continue to appeal to wear masks and stop large-scale gatherings to avoid the rebound of the epidemic trend. At the same time, the development of a vaccine for COVID-19 is also an effective way to effectively suppress the spread of infectious diseases [
31]. In addition, we can update the prediction model in real time according to the daily new data, and thus we can grasp the spread trend of global epidemics in a timely manner.
4. Conclusions
In this paper, we have presented an INCDTRM based on FEM and SVR for analyzing and predicting the COVID-19 pandemic in eight countries. The experimental results show that INCDTRM has smaller prediction error and stronger generalization ability than the single prediction models, DGRM and NCDTRM that have been used previously; forecast errors for epidemics in USA, Canada, Italy and South Korea were within 5%. This shows the rationality of using dynamic transmission rate to replace the basic infection number , and our model can thus be utilized for predicting the COVID-19 epidemic.
Furthermore, we also used INCDTRM to model the global COVID-19 pandemic. The experimental results predict that the inflection point of the global epidemic is May 10, 2021. and the estimated errors of MAE, RMSE and MAPE are 141,374.15, 182,765.24 and 0.522%, respectively. As Ferguson et al. [
32] pointed out that we are now at a critical moment of the epidemic, and any slackening in prevention and control will lead to a rebound in the spread of the epidemic.
It should be noted that this paper has the following defects: (1) Due to the monotonicity of the fitting functions, INCDTRM is not suitable for predicting a rebound in an epidemic; (2) The weights of the combined kernel function and the initial parameters of PSO need to be set according to experience; (3)The spread of COVID-19 epidemic is affected by social factors [
33], population [
34], climate, environment [
35] and other factors, which is very complex, but this paper only considers a single epidemic data, without considering other factors that may affect the spread of the epidemic.
According to the above limitations, the future work of this paper is as follows: (1) Finding a suitable COVID-19 multi-stage infectious disease development model; (2) Using more effective multi kernels learning models and adaptive optimization algorithms; (3) We will further collect relevant data and conduct research with data assimilation or SEIR and its extended model.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}