1. Introduction
Education is one of the most important factors in the development of a country. A better and more extensive education helps to improve levels of social wellness and economic growth. At the same time, education decreases social inequalities and promotes social mobility. Finally, it also promotes science, technology, and innovation. In summary, it helps to build a better society. According to a report from UNESCO in 2015 [
1], the global number of students in high education has grown from 28.5 million in 1970 to 196 million in 2012, and to 250 million in 2021 [
2]. However, not all these students necessarily finish their studies, and many of them abandon the university without achieving a degree.
Student dropout, defined as the abandonment of a high education program before obtaining the degree without reincorporation [
3], is a problem that affects every higher education institution. It is estimated that half of the students do not graduate [
2]. In the United States, the overall dropout rate for undergraduate college students is 40% [
4]. In the European Union, the following countries have the lowest dropout rates: United Kingdom, Norway, and France [
5] (16%, 17%, and 24% respectively), while Italy has the highest dropout rate (33%), followed by the Netherlands (31%) [
5]. In Latin America, 50% of the population between the ages of 25 and 29 who started a university degree did not complete their studies [
6].
There are different types of dropouts, and each of them can be analyzed in different ways. Even though a student can drop out of college at any time during his career, most dropouts happen during the first year. In the United States, until 2018, approximately 30% of college freshmen drop out before their sophomore year [
4]. In the United Kingdom, 6.3% of young full-time students dropped out during the first year in 2016–2017 [
7]. In Latin America, Colombia had a 36% of student dropout in the first year in 2013 [
6], while Chile had a 21% in 2019 [
8]. For example, Universidad Adolfo Ibáñez and Universidad de Talca, the universities under analysis in this work, have a 12% and 15% of first-year student dropout.
Student dropout is a major issue within the Chilean higher education system. Chilean universities are mostly funded by student fees, and high dropout rates hinder their short-term economic viability. Moreover, the accreditation process in use within the country to evaluate the quality of universities favor high retention rates (in other words, low dropout rates) and penalize low retention rates with lower accreditation rankings. Consequently, Chilean universities try to reduce dropout due to short-term economic requirements, but also focus on the metric to ensure a better accreditation rank which leads to better ranking within the system, opening the door to mid- and long-term benefits, better recruitment possibilities and better indirect funding from the government. The concerns regarding dropout levels also play a major role politically as the government recently introduced new laws that give university education access to all the population through state scholarships. In fact, this research stems from a nationwide publicly funded research project to evaluate the major sources of dropout within the higher educational system during the first year; the two above-mentioned universities were used as the test bed to identify common dropout issues within the full Chilean university system.
The Universidad Adolfo Ibáñez (UAI for short) and the Universidad de Talca (U Talca for short) constitute examples ofthe diversity within the higher education system in Chile. The UAI is one of the leading private universities in the country. The university grew from a business school with the same name, and it has two campuses, one located in Santiago de Chile, the capital of the country, and another in Viña del Mar, in the greater Valparaíso area which is the third most populated area of the country. Most students come from private high schools within the Santiago and Valparaíso region, but also the university also attracts students from different areas of the country due to the perception that the university provides a business-oriented education that covers the needs of the businesses within the country. The university only offers a limited number of academic undergraduate degrees, including engineering, business administration, journalism, psychology, design and law, as well as some Master’s and Ph.D. degrees. The U Talca is a public university located in the Maule region, in the south of the country, and is considered one of the best regional universities within the country. The university has five campuses and offers a wide variety of degrees in multiple topics at undergraduate, graduate and Ph.D. levels. The majority of students come from the Maule region and receive free education through the previously mentioned state scholarships that cover four years of undergraduate education for the population from the six deciles with lower rents. While the differences between these universities are evident, both universities are ranked among the ten best universities in Chile according to the QS university ranking [
9].
This work reports the results from machine learning models to identify the major factors involving dropout within these universities for their engineering undergraduate degrees. In order to compare possible dropout predictors between these universities, we propose multiple machine learning models and compare the dissimilarities among the models learned for each university as well as for a joint dataset covering both universities. A posterior analysis of these models will allow us to determine if the same dropout behavior pattern can be observed in both universities, and to evaluate the quality of different models within the same predictive task.
The paper is structured as follows.
Section 2 provides a literature review on the area, including the application of machine learning approaches to dropout prediction.
Section 3 describes the methodology followed in this work.
Section 4 provides an exploratory analysis of the collected data, and
Section 5 provides the main results of the study.
Section 6 gives some conclusions. We provide an appendix,
Appendix B with further details on the comparisons among models.
3. Methodology
In this paper, we compare the learned patterns from machine learning models for two different universities (UAI and U Talca) and analyze the dissimilarities among prediction models. In order to perform the comparison, we create multiple models that try to predict dropout in engineering undergraduate degrees using datasets from these two Chilean Universities. A posterior analysis of the constructed models is used to determine if the same dropout behavior patterns are observed in both universities or if there are major differences between them.
In order to reach these objectives, the research was structured as follows:
In a first stage, an exploratory data analysis is performed. The objective is to understand the data and their variables. The analysis also includes data pre-processing and data cleaning.
In this phase, we gathered initial information from the data through the description of each variable; we study the distribution of each variable, its possible values, and we identify missing data from the datasets. During this process, we clean the data by discarding variables gathered during the first year, since we cannot use them for first-year dropout prediction. Other unnecessary variables are also deleted, as well as problematic observations, such as old records or observations with numerous missing values. We also grouped potential values from some variables (i.e., changing the address of a student by its region of origin) in order to improve the quality of this variable and to reduce the complexity of the dataset. We also analyze missing data, searching for a pattern in their variable distribution to be used as a replacement. Finally, we also perform outlier detection. In our case, outliers did not require special treatment, as most of them were indirectly eliminated when deleting older data.
In the second stage, we implemented all the machine learning models. This step includes a parameter-tuning phase for the hyper-parameters of each model, and a variable selection process, per model, based on a forward selection procedure.
We implemented eight different models: a K-Nearest Neighbor (KNN) [
62], a Support Vector Machine (SVM) [
63], a decision tree [
28], a random forest [
64], a gradient-boosting decision tree [
53], a naive Bayes [
36], a logistic regression [
65], and a neural network [
66]. All models were implemented using python and the libraries scikit-learn [
67] and Keras [
68].
For each of the eight models, we performed a hyper-parameter tuning procedure to select the variables included in each model according to their performance. For the tuning process, we performed a grid search over the most common parameters for each of these models. For KNN, we searched K from 1 to 100. With the SVM, we evaluated all combinations for and three kernels: polynomial, radial basis function, and sigmoid.
For tree-related models (decision tree, random forest, and gradient boosting) we used one-hot encoding for nominal variables and tried multiple parameter combinations. In the case of the decision tree, we analyzed a variable number of minimum samples to constitute a leaf, changing its value from 10 to 200. The results provided by decision tress constructed according to this method outperformed the results provided by trees selected according to their maximum depth. For random forest and gradient-boosting methods, we tried all combinations among the minimum number of samples at a leaf, , number of trees, , and the number of sampled features per tree, .
For the Naive Bayes method, we considered numerical and nominal variable separately and tried the following Laplace smoothing coefficients,
. For logistic regression, we use the method from Broyden–Fletcher–Goldfarb–Shanno [
69,
70,
71,
72] and a “L2” regularization penalty [
73].
Finally, for neural networks, we tried multiple architectures, varying the number of hidden layers from 1 to 5 and the number of neurons from 5 to 20. The networks were trained using a binary cross-entropy loss function, and “adam” as the optimizer [
74].
The selection of variables in each model was performed using a forward selection approach [
75]. Forward selection starts with an empty model, and, at each iteration, it selects among all variables the one that provides the best performance. This process is iterated until all variables belong to the model or the results do not improve.
In the third stage, we evaluate all the models using a k-fold cross-validation procedure [
76]. This procedure will allow us to extract information from the data.
In this stage, we estimate the mean and standard deviation error through 10-fold cross-validation on different measures (accuracy and score for both classes). Ten-fold cross-validation helps us to estimate the error distribution by splitting the datasets into 10 folds. Then, 9 folds are selected for training and tested in the other fold. This process is repeated until all folds are used for testing, and the error estimation is given by the average over error folds. In addition, considering that we will model student dropout, there is likely to be an important difference in the proportion of data between students that dropout and students that do not dropout, leading to an unbalanced data problem. Unbalanced issues will be minimized through undersampling. Specifically, the majority class is reduced through random sampling, so that the proportion between the majority and the minority class is the same. To combine both methods (10-fold cross-validation with an undersampling technique), we apply the undersampling technique over each training set produced after a K-fold split and then evaluate in the original test fold. With that, we avoid possible errors of double-counting duplicated points in the test sets when evaluating them.
We measure the performance of each model using the accuracy, the score for both classes, and the precision and the recall for the positive class, all of them explained considering the values of the confusion matrix; true positives (TP); true negatives (TN); false positives (FP); and false negatives (FN).
Accuracy, Equation (
1), is one of the basic measures used in machine learning and indicates the percentage of correctly classified points over the total number of data points. An accuracy index varies between 0 and 1, where a high accuracy implies that the model can predict most of the data points correctly. However, this measure behaves improperly when a class is biased because high accuracy is achievable labeling all data points as the majority class.
To solve this problem, we will use other measures that avoid the
TN reducing the impact of biased datasets. The recall (Equation (
2)) is the number of
TP over the total points which belong to the positive class (
). The recall varies between 0 and 1, where a high recall implies that most of the points which belong to the positive class are correctly classified. However, we can have a high value of
FP without decreasing the recall.
The precision (Equation (
3)) is the number of TP over the total points classified as positive class (
). The precision varies between 0 and 1, where a high precision implies that most of the points classified as positive class are correctly classified. With precision, it is possible to have a high value of FN without decreasing its value.
To solve the problems from recall and precision, we also use the
score, Equation ((
4)). The
score is the harmonic average of the precision and recall, and tries to balance both objectives, improving the score on unbalanced data. The
score varies between 0 and 1, and a high
score implies that the model can classify the positive class and generates a low number of false negatives and false positives. Even though true positives are associated with the class with fewer labels, we report the
score using both classes as true positive, avoiding misinterpretation of the errors.
In the final fourth stage, we perform an interpretation process, where the patterns or learned parameters from each model are analyzed to generate new information applicable to future incoming processes.
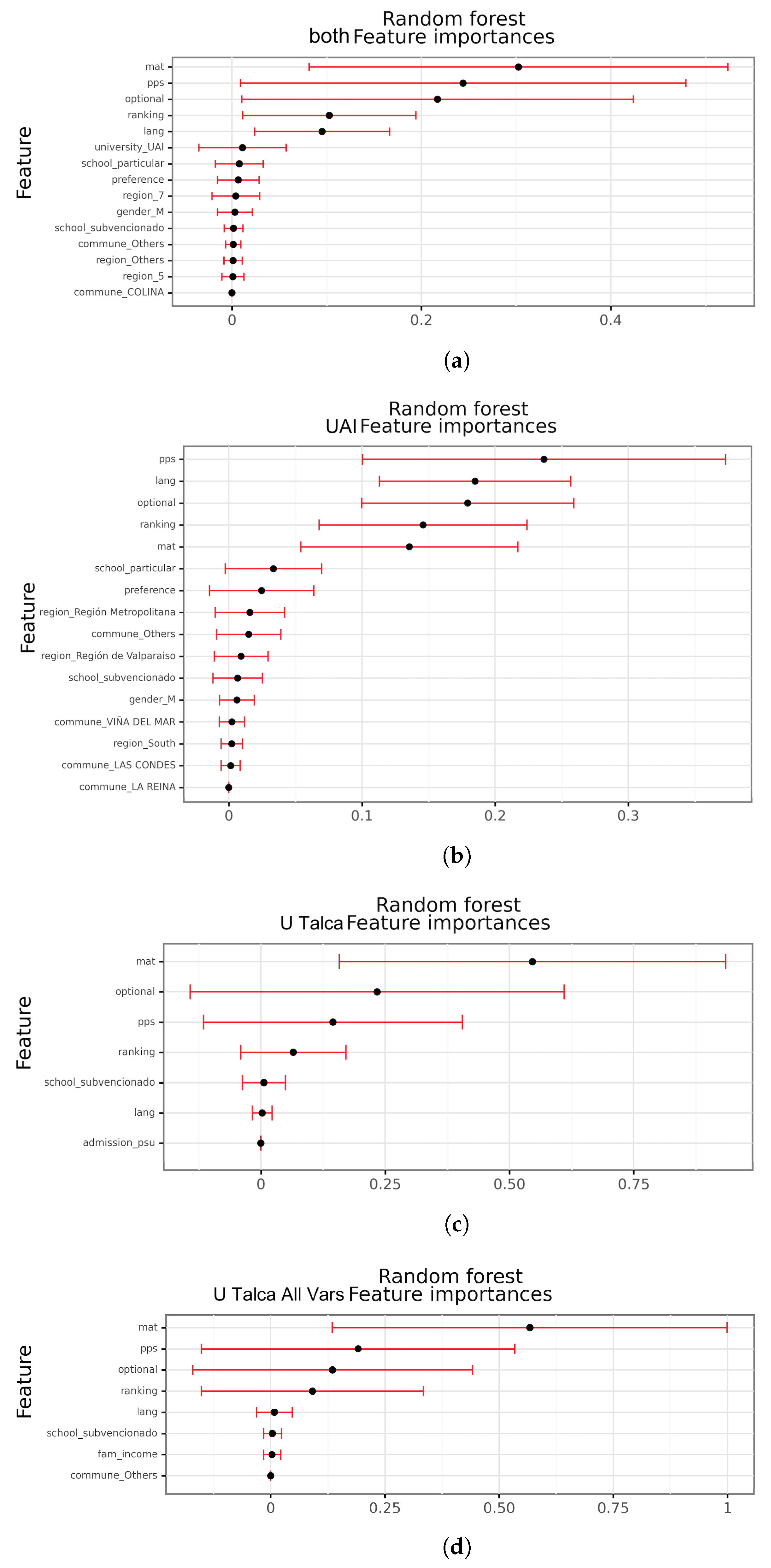
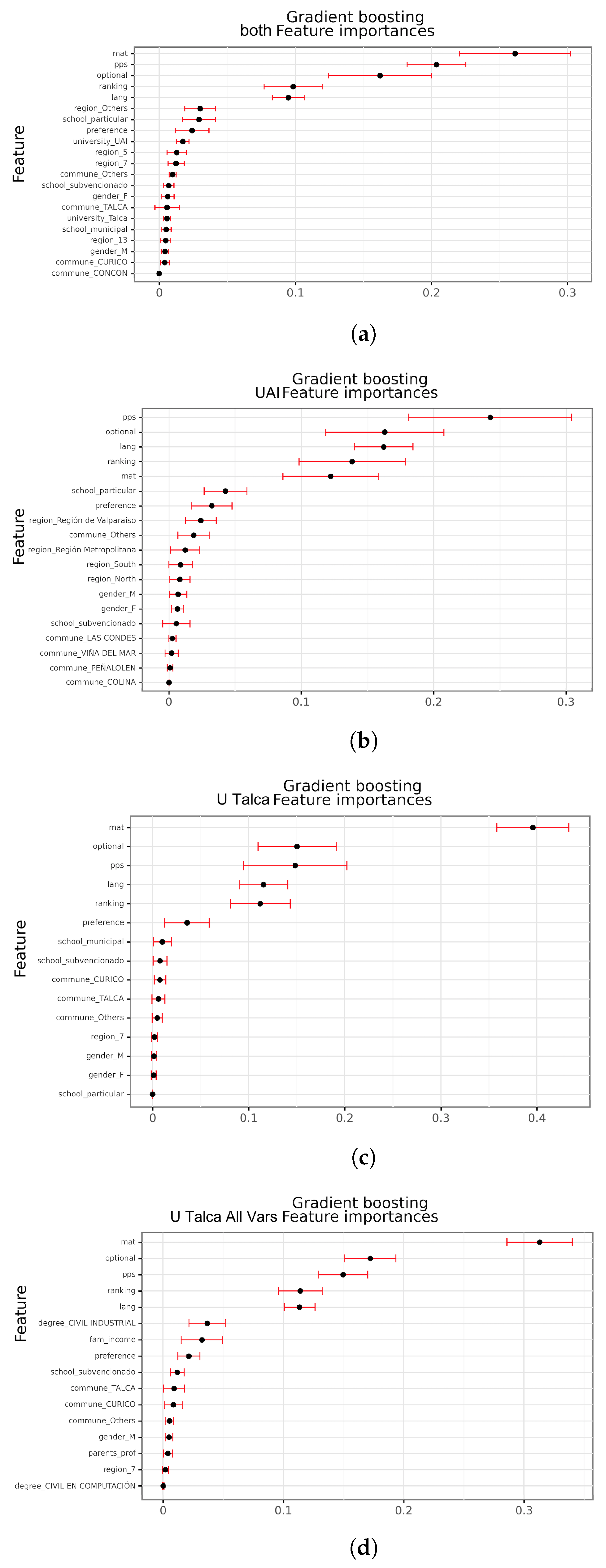
In this stage, we only consider some of the constructed models. Specifically, decision trees, random forests, gradient-boosting decision trees, logistic regressions, and naive Bayes models are interpretable models, meaning that we can identify which variables or pattern behaviors are important. This is especially relevant for dropout students, where early actions can be taken to avoid dropout. Identifying common features among students that dropout may allow decision makers to generate policies to apply within the university to mitigate the issue. For models based on tree (decision tree, random forest, and gradient boosting), we analyzed the significance of the features within the trees. With the logistic regression model, we analyzed the model parameters, values, to identify the most relevant attributes; higher absolutes values are associated with the most relevant variables related to dropout.
4. Exploratory Data Analysis
The data used in this study were provided by two Chilean universities, Universidad Adolfo Ibáñez (UAI) and Universidad de Talca (U Talca). For each dataset, we describe and analyze both variables and perform data cleaning operations. Finally, we also merge both datasets into a single dataset that considers both universities. The merged dataset will be used to evaluate the validity of a joint approach.
4.1. Universidad Adolfo Ibáñez
The data provided by the UAI contain 31,714 observations, each with 40 variables. Each observation corresponds to a student from the University. This work only considers engineering students, reducing the original dataset to 8416 observations. The dataset contains several null values and variables that did not contribute to the prediction task, hence, these variables were deleted from the dataset.
Among the deleted variables, we highlight two groups. A group of five variables whose removal was based on data quality or students that enrolled themselves into the university but never registered a course. The second group of variables were eliminated because their information was gathered after the student completes their first year in the university. Therefore the data does not apply to first-year dropout prediction. Finally, for nominal variables with many values, their values were changed to increase their significance. These preprocessing steps reduced the datasets to 3750 observations and 14 variables.
We can categorize the variables of the final dataset in the following personal variables: gender, place of residence (variable commune) and region of origin (variable region); high school data, such as the type of school (variable school, i.e., private, subsidized, or public), average high school grades (variable nem), student ranking according to their school (variable ranking); university application (variable admission, whether the application submitted via a normal or special process), year (year where the student entered the university), the preference ranking (variable preference, whether the degree they enrolled onto was listed as their first, second or lower in their list of preferences within the national system to assign students to universities); and the university admission test scores, which include scores for mathematics (variable mat), language (variable lang), science or history (variable optional), and average among all tests (variable pps). Note that this last set of scores come from standardized tests performed by all students that enroll within a Chilean university for a year. Finally, we include a class label (DROPOUT).
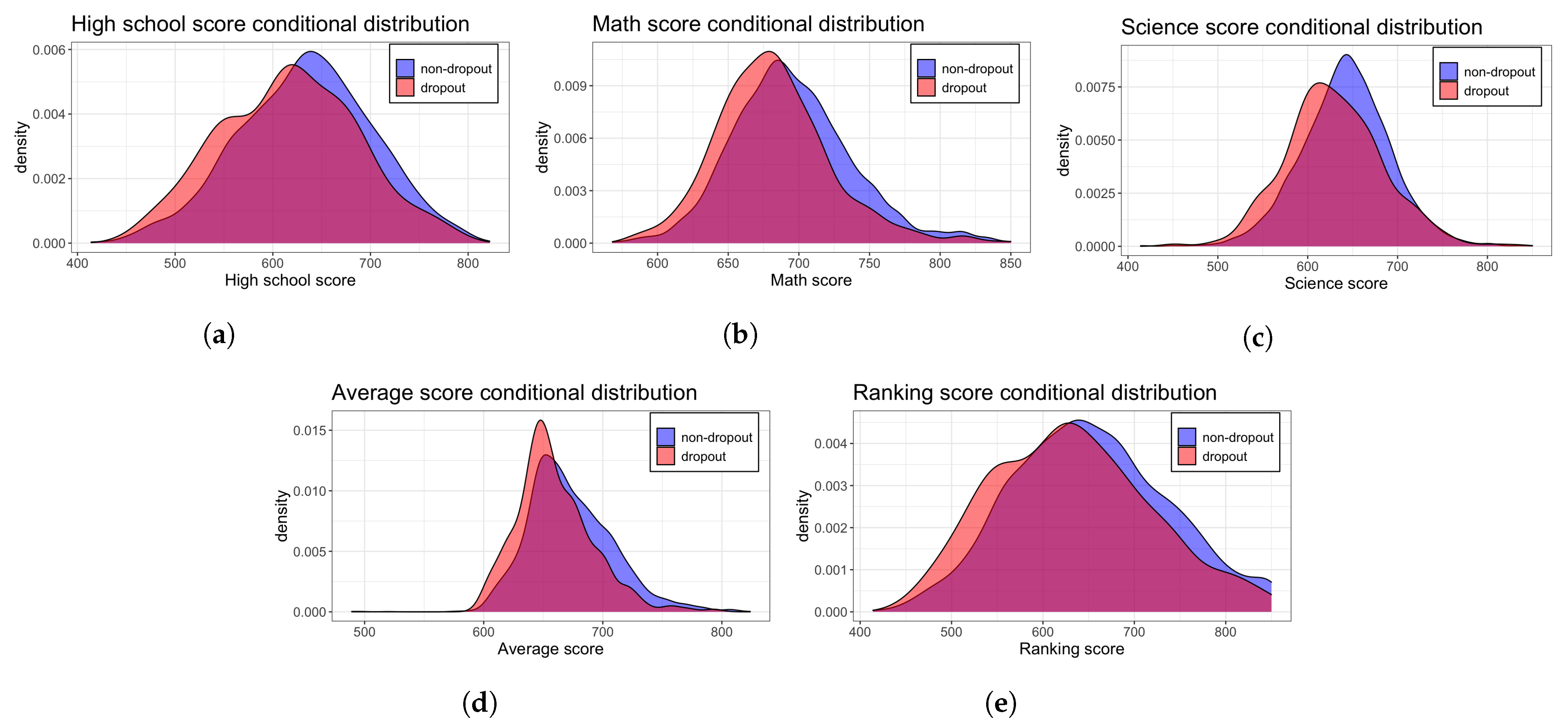
After an initial analysis of the variables conditioned according to the DROPOUT variable (
Figure 1), we observed that lower values in variables nem, mat, optional, pps and ranking seem to increase dropout probabilities. This was to be expected, since all these variables are related to the performance of the student. Moreover, students coming from public schools or schools with state support (i.e., subsidized) have lower dropout probabilities. This effect could be explained because the UAI is a private university, and students with lower resources entered the university through scholarships granted to them based on their academic performance, hence they have a previous track of being successful students. For details about categorical variables, please refer to the
Table A1 column UAI at
Appendix A.
4.2. Universidad de Talca
The data provided by the U Talca includes four datasets, with a total of 73,067 observations and 99 variables. Even though there is a large quantity of data, the datasets contained several null values and variables that did not contribute to the prediction of first year dropout, which were eliminated.
In what follows, we described the data cleaning procedure, justifying the elimination of some data and the deletion of unnecessary variables and observations.
First, we analyzed the datasets for useless data for first-year dropout prediction. We discarded two of the datasets completely. One dataset contains first-year university grades and the second dataset to students in special situations. As these datasets provide information regarding the student during their university period, they cannot be used to predict dropout of newly enrolled student. A third dataset is used to generate the label variable (DROPOUT) as it includes the date of enrolment and the current status of the student. The fourth dataset includes most of the variables related to the student itself, its previous educational record and personal information. The resulting combined dataset contains 5652 observations and 40 variables, and still needs some preprocessing to reduce unnecessary variables and observations.
This preprocessing step started by discarding five variables because of data quality (most of the observations correspond to NULL values). A second set of variables was eliminated because their information is gathered after the first year is completed; therefore, this is not useful for first-year dropout prediction. Finally, for nominal variables with a large number of possible values, we grouped in order to create meaningful classes. These processes reduce the datasets to 2201 observations and 17 variables. From the 17 variables, both universities share 14 of them, while the remaining three corresponding to the engineering degree that the student enroll to, and the information about the education of the father and their family income. The first of these variables, specific engineering degree, is not recorded within the UAI as the university offers a common first year and students only select a specific engineering degree after their second year, while students from U Talca enter specific engineering degrees as freshmen. We contacted Universidad Adolfo Ibáñez regarding the availability of the two other variables, but they have only been recorded in the last two years, making them unavailable for most of the observations.
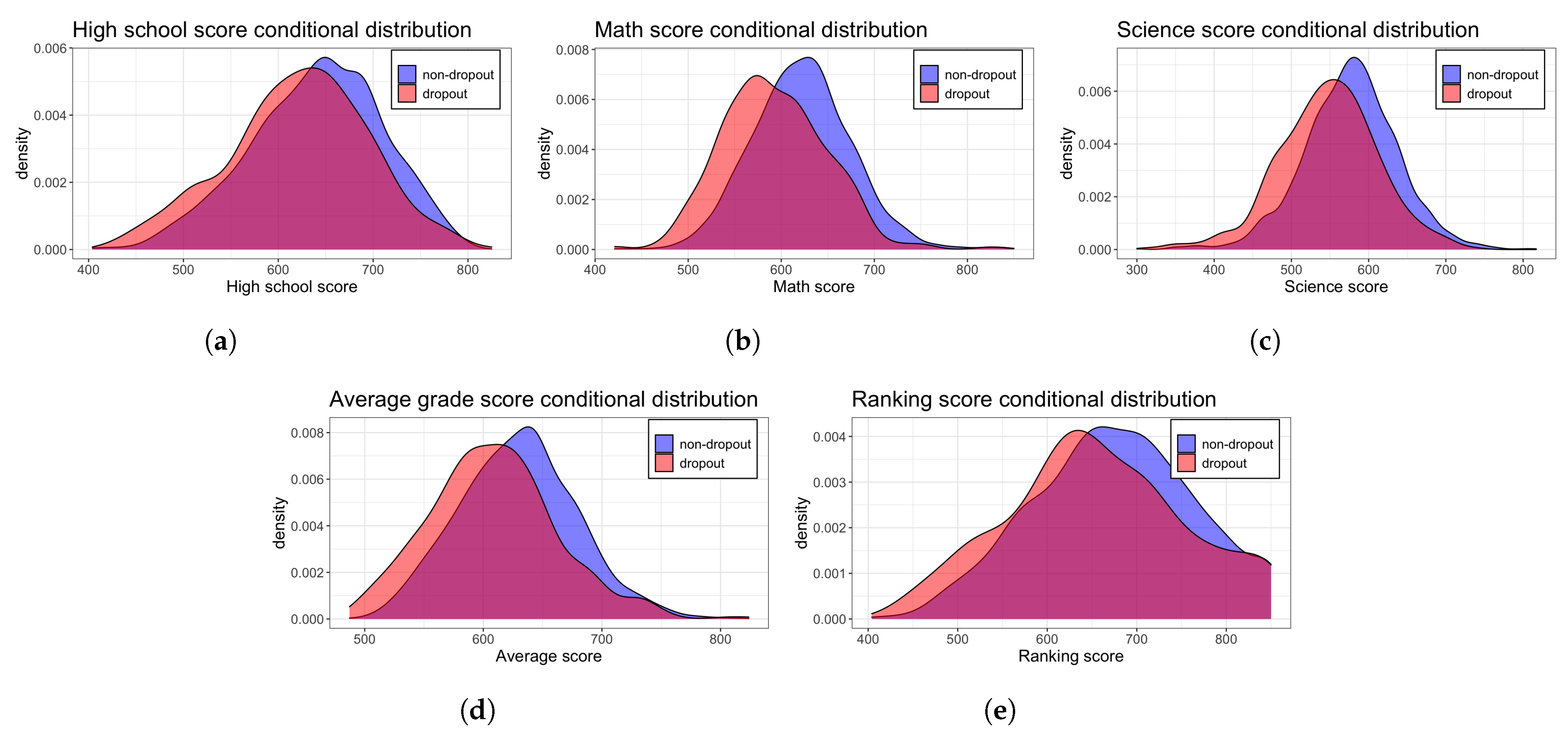
After an initial analysis of the variables conditioned by the DROPOUT variable, see
Figure 2, we observed that lower values in variables pps, mat, optional and ranking increase the probability of dropout. This could be expected since all these variables are related to the previous performance of the student. We also observed that lower family incomes and non-professional parents increase the probability of dropout. It is also important to note that the selected engineering degree also affects dropout probability. Specifically, computer, mining, and bioinformatics have higher dropouts than other degrees. For details about categorical variables, please refer to
Table A1 column U. Talca at
Appendix A.
4.3. Unification of Both Datasets
After the analysis of both datasets, we unified them by creating a new dataset containing the 14 shared variables. This new dataset contains 5951 observations, each with 14 variables. It is important to note that there are more observations from Universidad Adolfo Ibáñez (3750 observations); hence, this imbalance must be handled within the machine learning models.
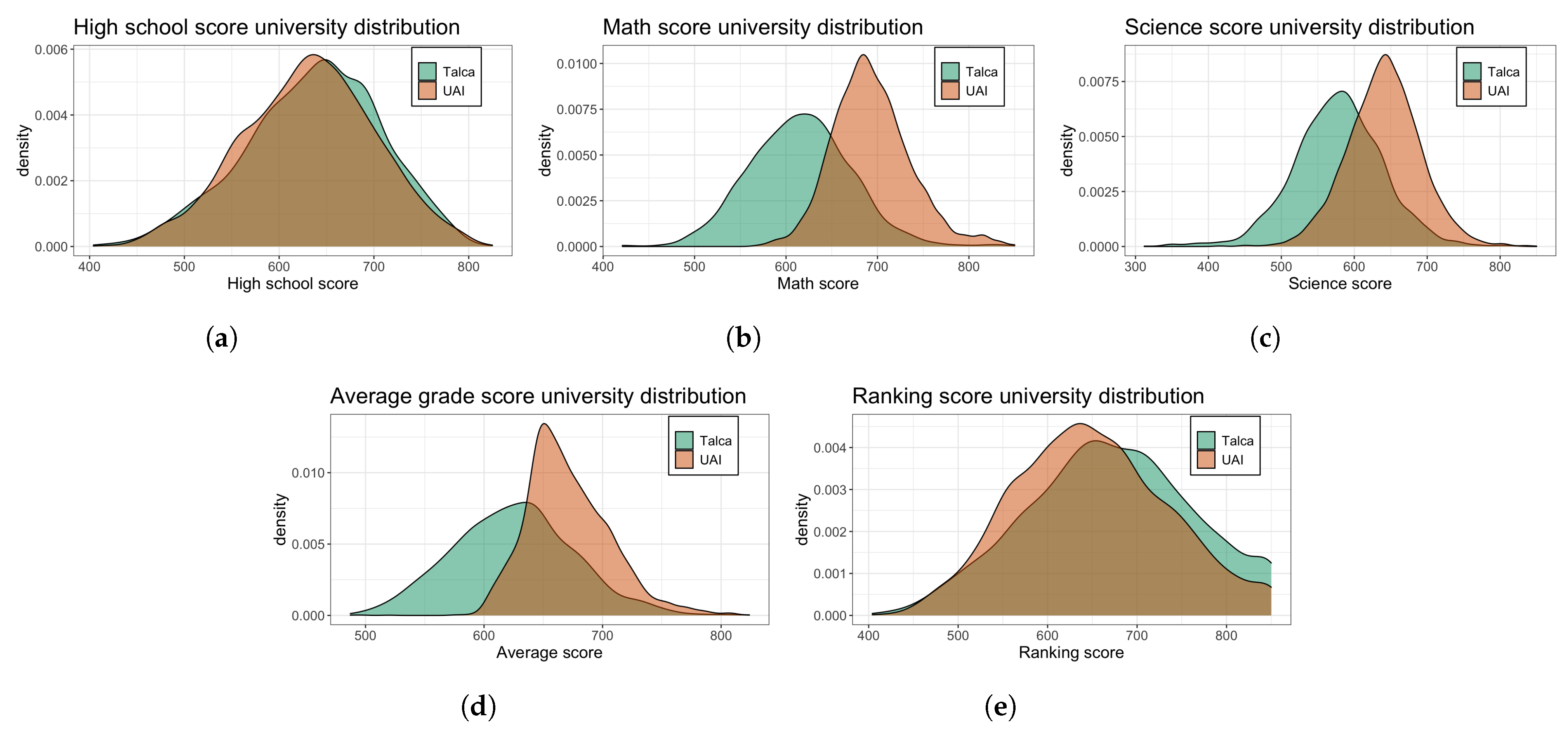
Figure 3 compares the score distributions of the student from both universities. Each plot shows an estimated distribution over the score used in this paper. As it can be observed, both students have very similar high school scores, see
Figure 3e). This could be explained because there is no standardization among the grades from different schools. This means that two schools could have very similar grades for their students, but the level of each school could be drastically different. UAI students have better scores in all standardized tests (
Figure 3a–d). In contrast, students from Universidad de Talca have better ranking scores, meaning that Universidad de Talca receives more top high school students than UAI.
Table 1 provides a list of the variables used within the datasets (combined dataset, UAI and U Talca datasets). For the U Talca dataset we can also include three additional variables only available for the said university. We refer to the dataset using these three additional variables as U Talca All.
6. Conclusions
This work compared the performance and learned patterns from machine learning models for two universities when predicting student dropout of first-year engineering students. Four different datasets were compared: combined dataset (students from both of the universities and shared variables), UAI dataset (students from this university and all variables, which are the same as the shared variables), U Talca (students from this university and the shared variables), and U Talca All (the same than Universidad de Talca, but includes non-shared variables).
From the numerical perspective, the results show similar performance among most models in each dataset. If it we were to select one model for implementing a dropout prevention system, we would prioritize the scores with the score + class measure, since the data were highly unbalanced. Considering this, the best option would be a gradient-boosting decision tree, since it showed the higher average score in the combined and UAI datasets, with good scores in the U Talca and U Talca All datasets. Following that priority, it would be reasonable to discard the decision tree based on its lower average score when using that measure. Note that the differences are minimal among models, showing that the capabilities of different models to predict first-year dropout are more heavily related to the sources of information than to the model itself.
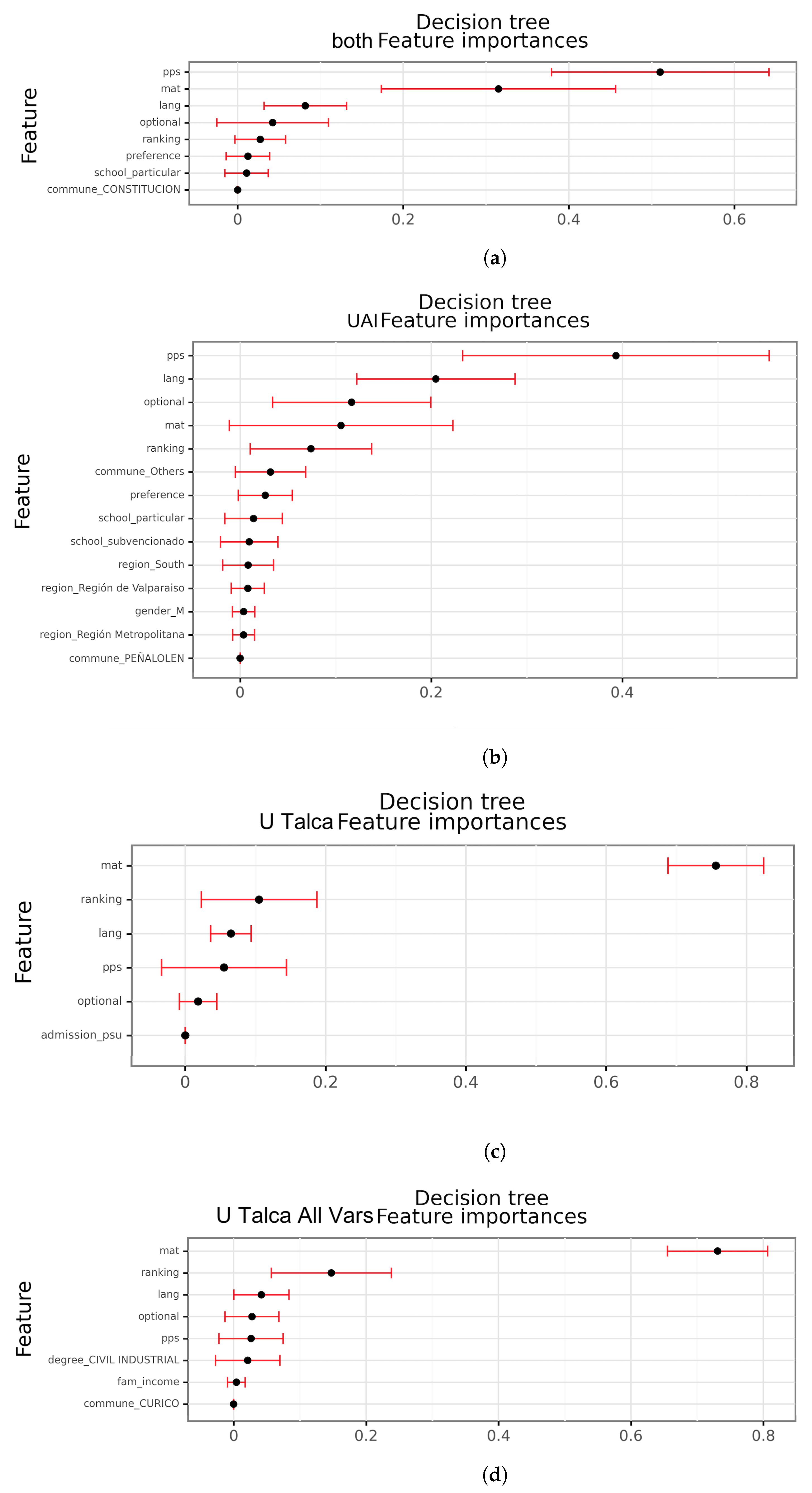
The interpretive models (decision tree, random forest, gradient boosting, naive Bayes, and logistic regression) showed that the most important variable is mat (mathematical test score from the national tests to enter university), since this variable was considered in almost every model and datasets. In all the cases, a higher score of this variable decreased the probability of dropout. The importance of this variable makes sense since many of the efforts done inside the universities during the first year are focused on courses such as calculus or physics, which are mathematically heavy courses (e.g., study groups organized by the university and student organizations). Moreover, these courses have high failure rates, which ultimately leads to dropout. Other variables, such as pps and ranking, were also considered by most models, and a higher score in them also decreased the probability of dropout. The variable lang was considered by some models too, but a higher score increased the probability of dropout, which could be explained by the fact that we were analyzing engineering students, and reading and writing skills are barely evaluated during first year. On the opposite, most categorical variables were not considered important by most of the models. The few exceptions are preference and admission in U Talca dataset, region in UAI and family income and degree as non-shared variables in U Talca All, where the last variable seems to replace the information of preference and admission, showing the limitations unifying datasets. Specifically, these non-shared variables were selected in many U Talca All models, suggesting differences between the universities.
Finally, when comparing among universities, the unification of datasets resulted in an intermediate performance (between the score of the two universities) in two of four measures, revealing that one university would become a limitation in the performance of the other when a general model is used. For that, it would be preferable to use a single model per university, instead of a general model. A single model would focus more accurately on the patterns of each university, while a general model may lose information when trying to generalize them. Moreover, and given the broad diversity of data collected among different universities, the application of common methods to ascertain dropout seems to be difficult or inadvisable.
As future work, it would be important to collect more (and different) variables to include in the models. A better model could be generated using data related to the adaptation and social integration information of the students, which was used in older studies. Additionally, if required to predict dropout during the semester (and not only after enrollment), it would be useful to collect day-to-day information through learning content managements such as Moodle, or the one available in the university of interest.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}





