
Deep Learning Approach to Mechanical Property Prediction of Single-Network Hydrogel



Abstract
:1. Introduction
2. Methodology
2.1. Derivation of the Constitutive Model of Hydrogel
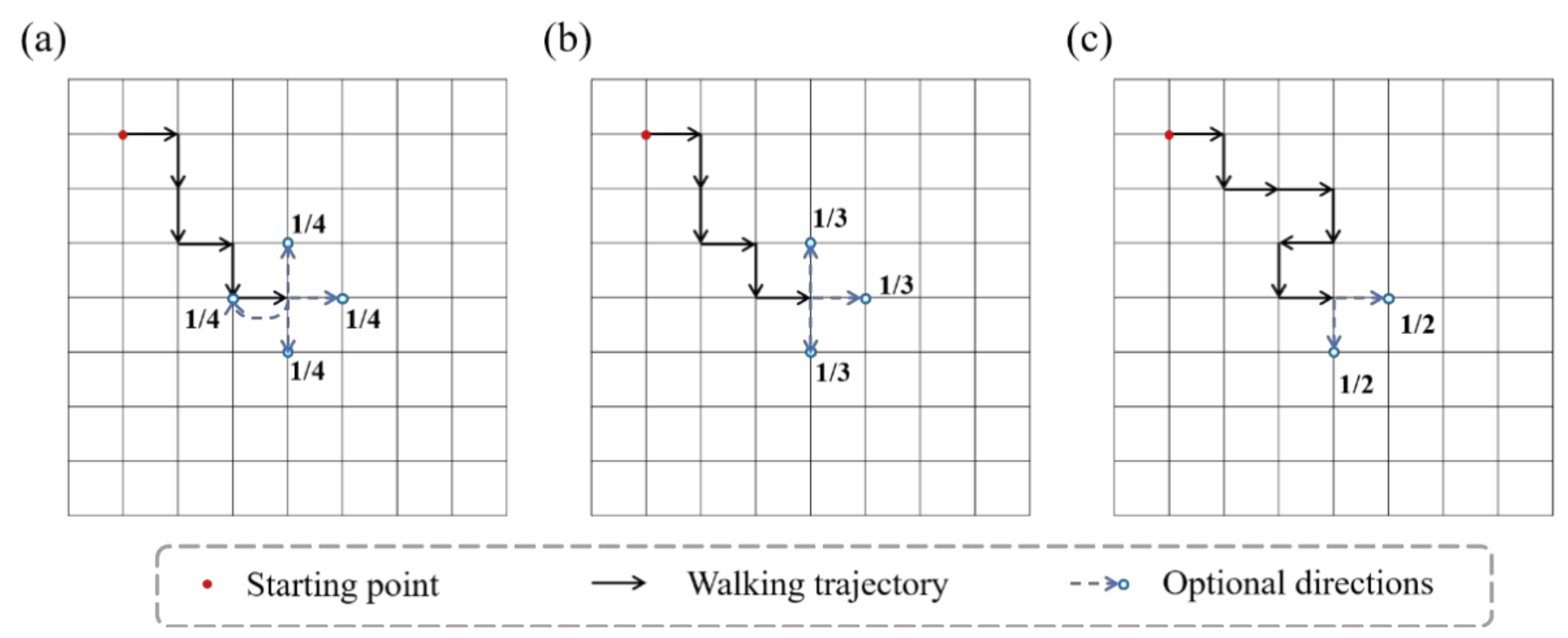
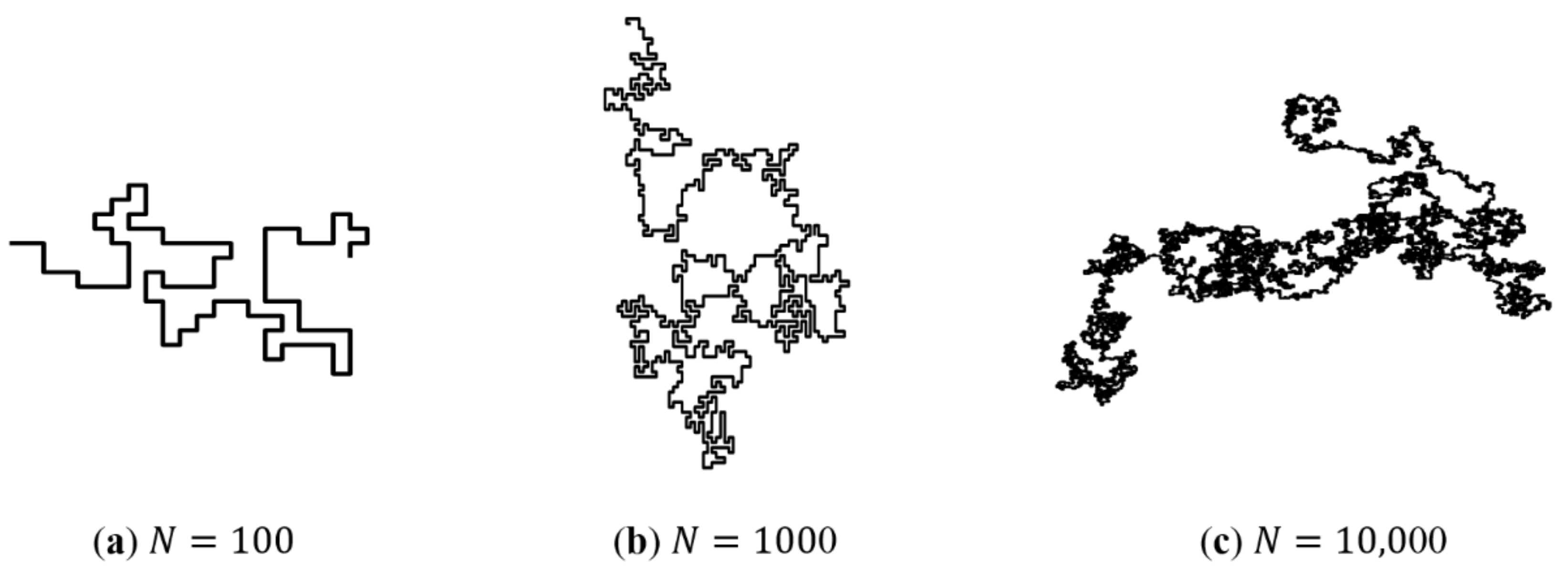
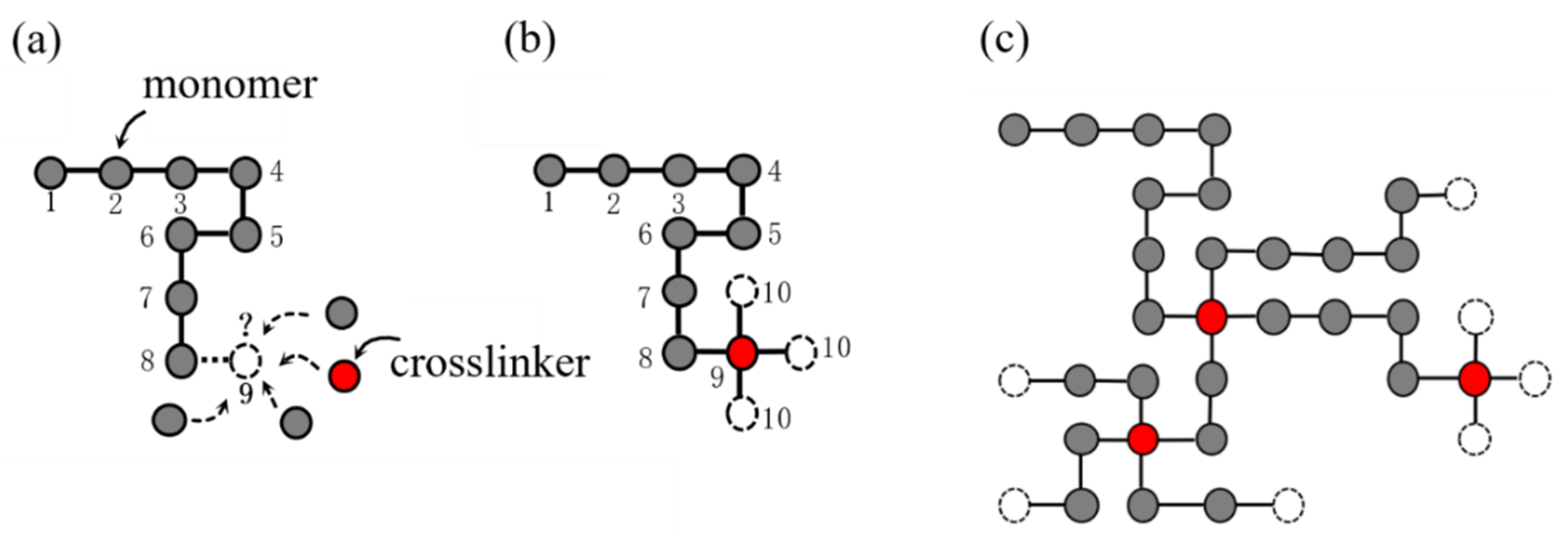
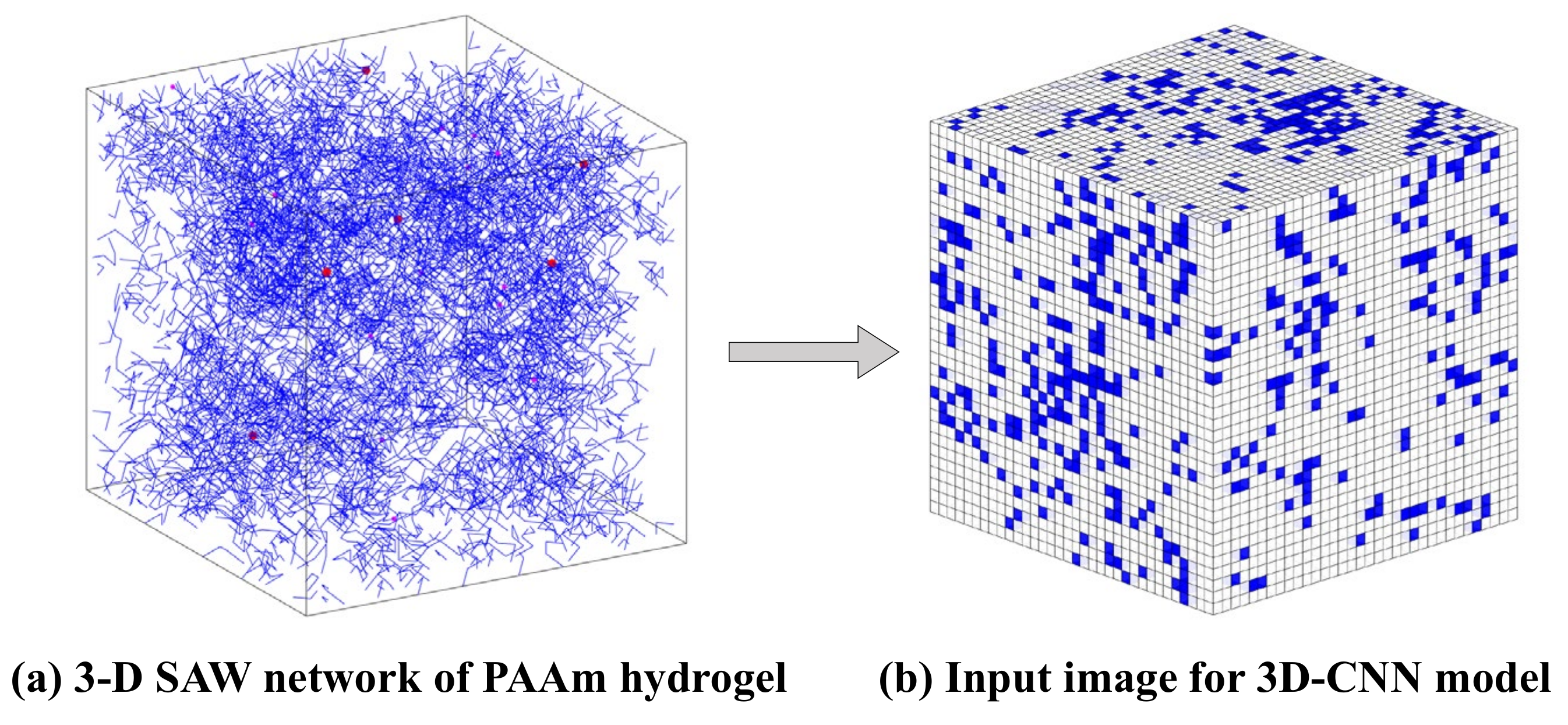
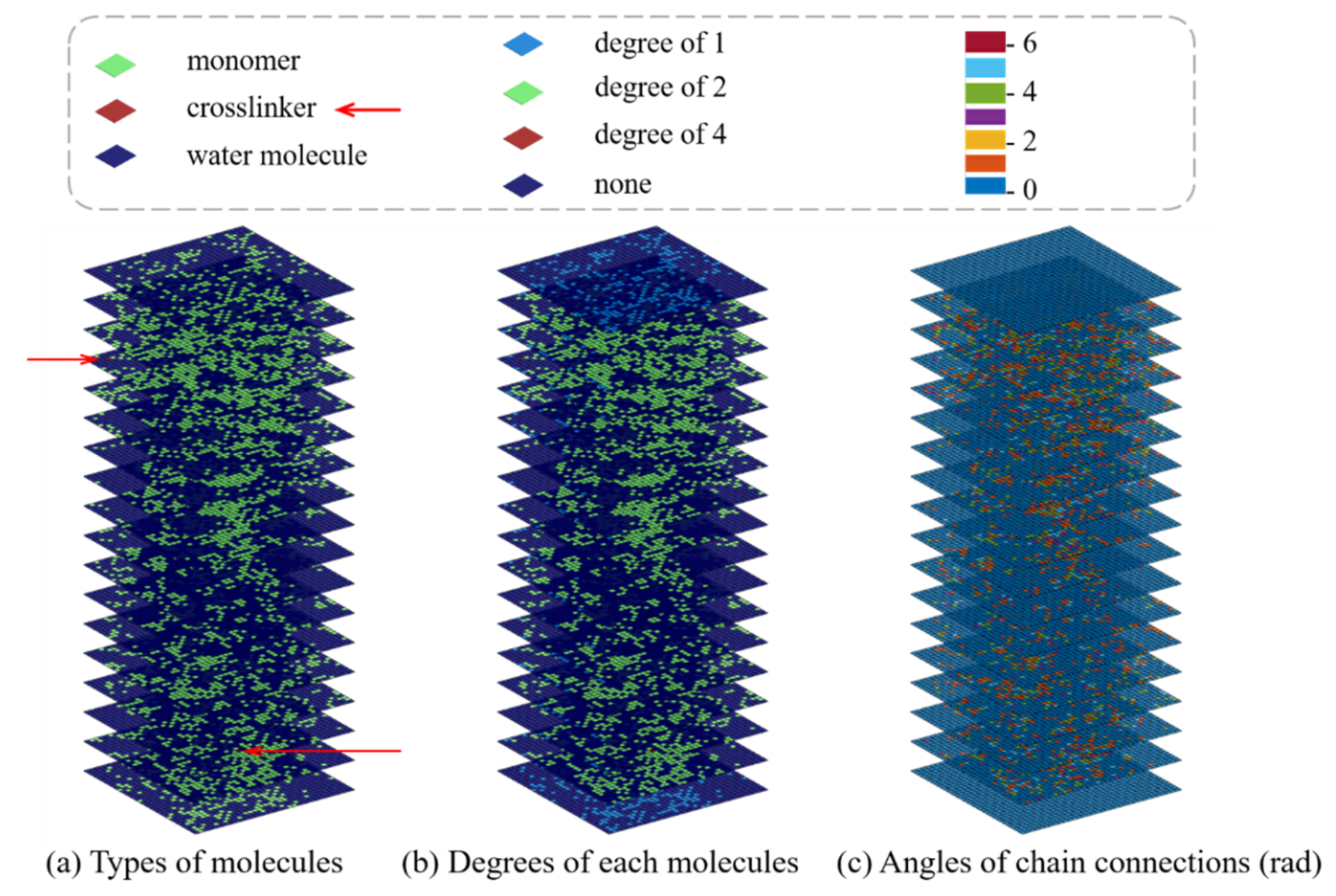
2.2. Network Generation Model of Single-Network Hydrogel
2.3. Deep Learning Algorithms and Approaches
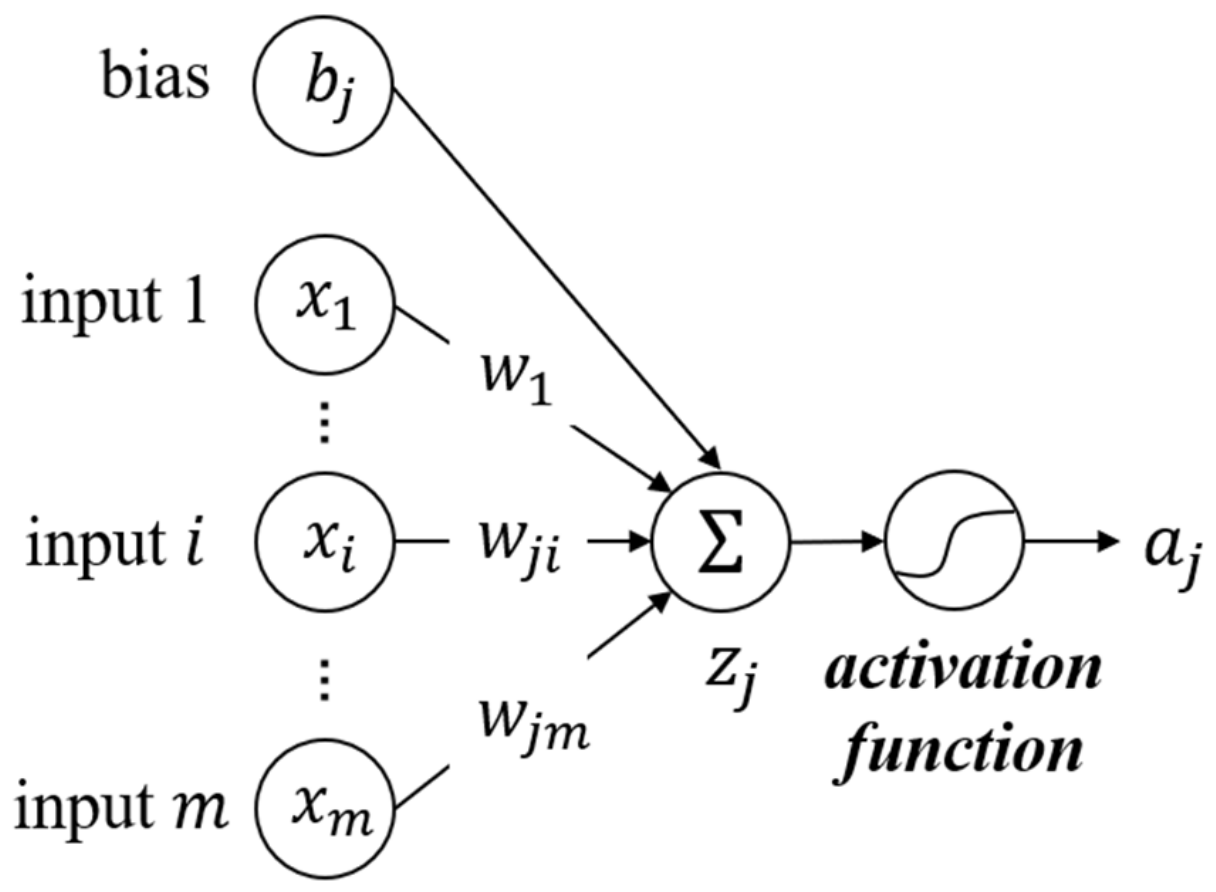
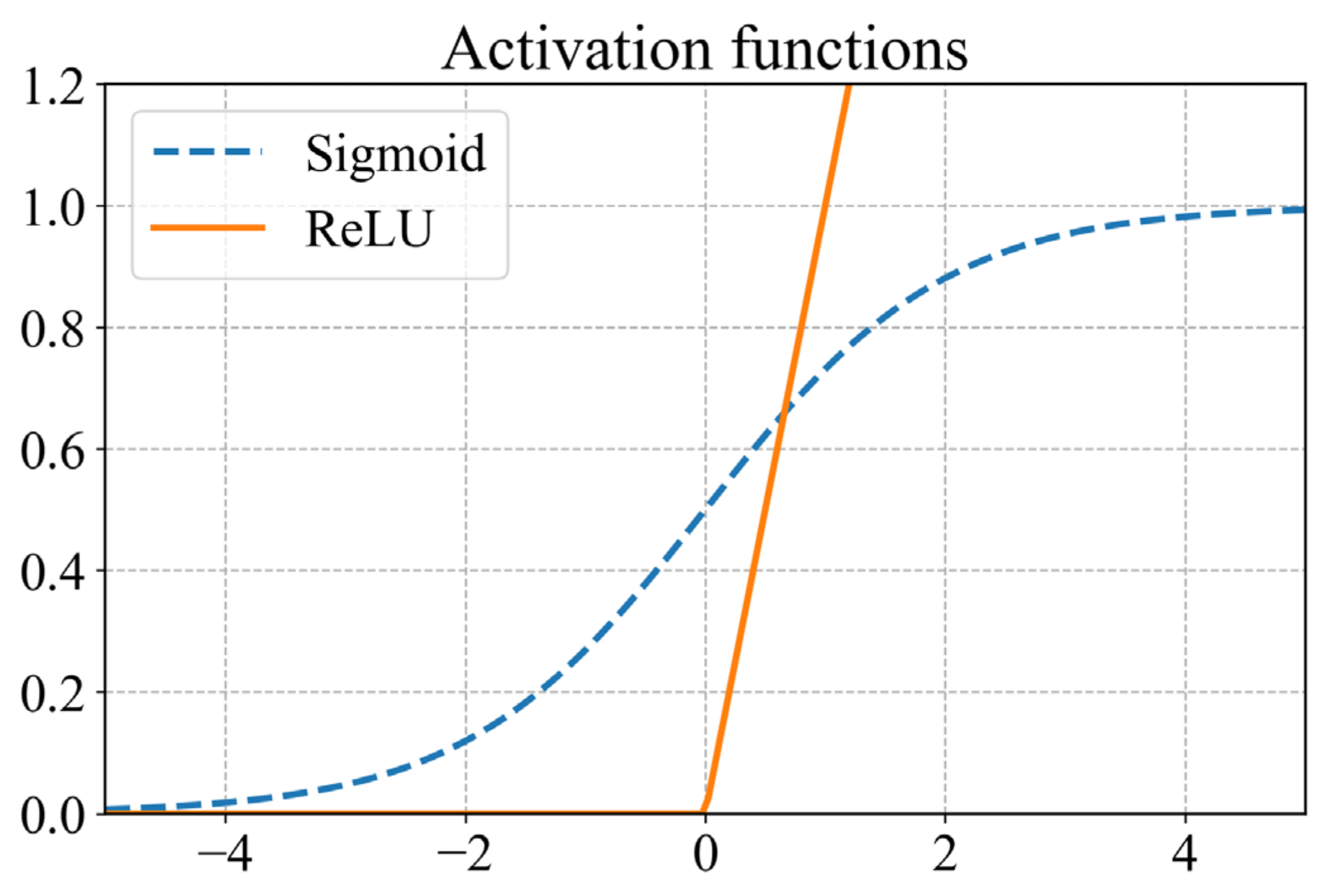
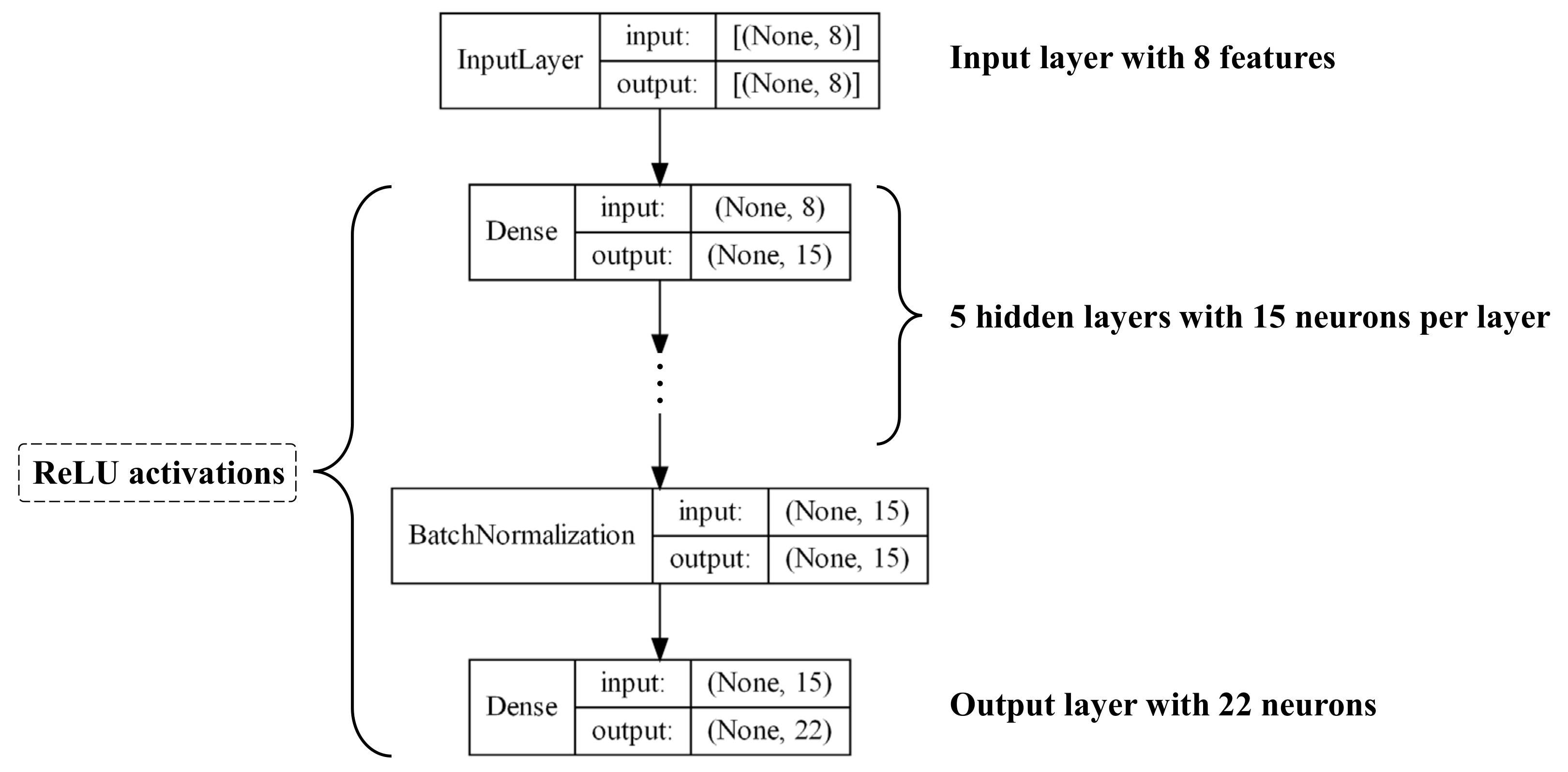
2.3.1. Multilayer Perceptron
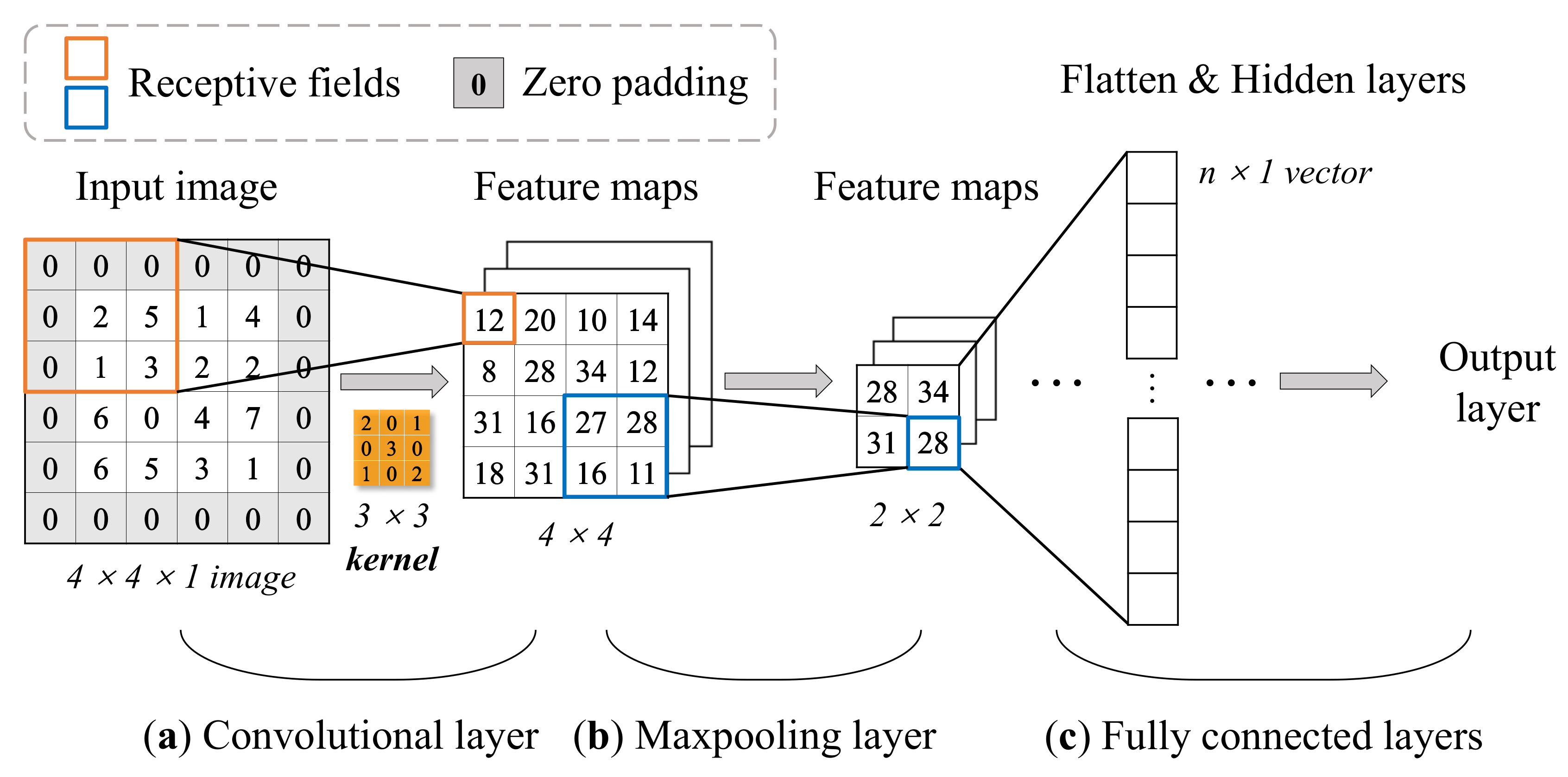
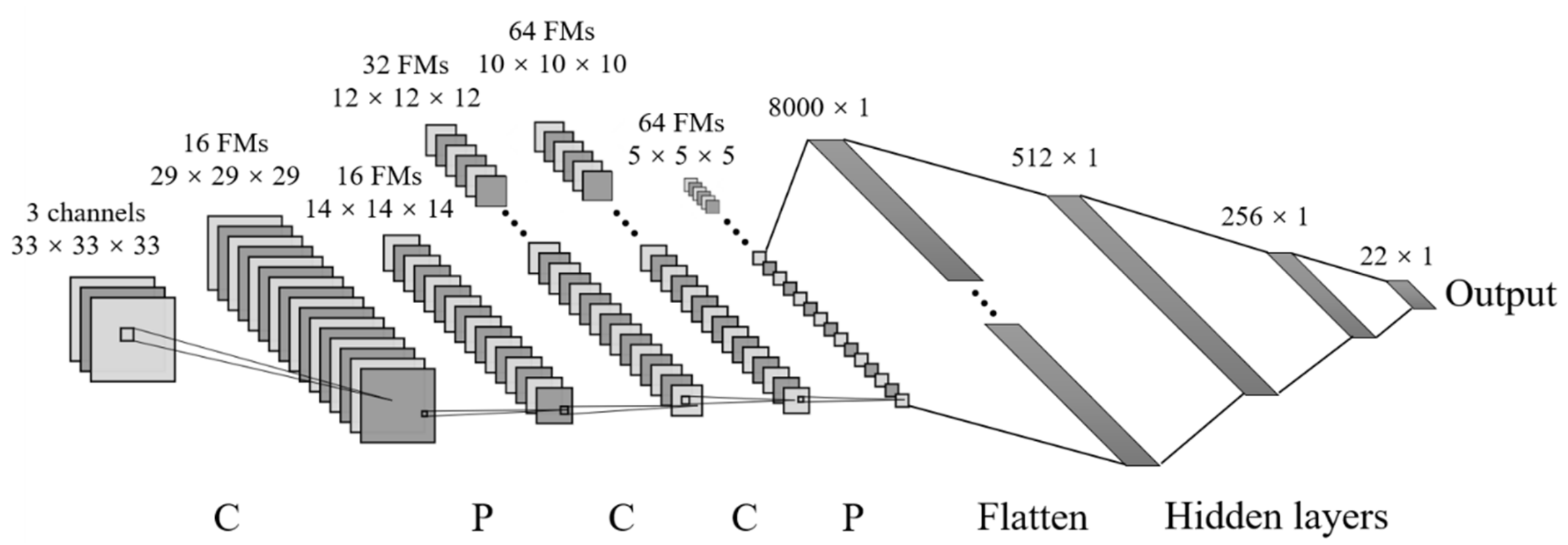
2.3.2. Convolutional Neural Network
3. Deep Learning Modeling Framework for Single-Network Hydrogel
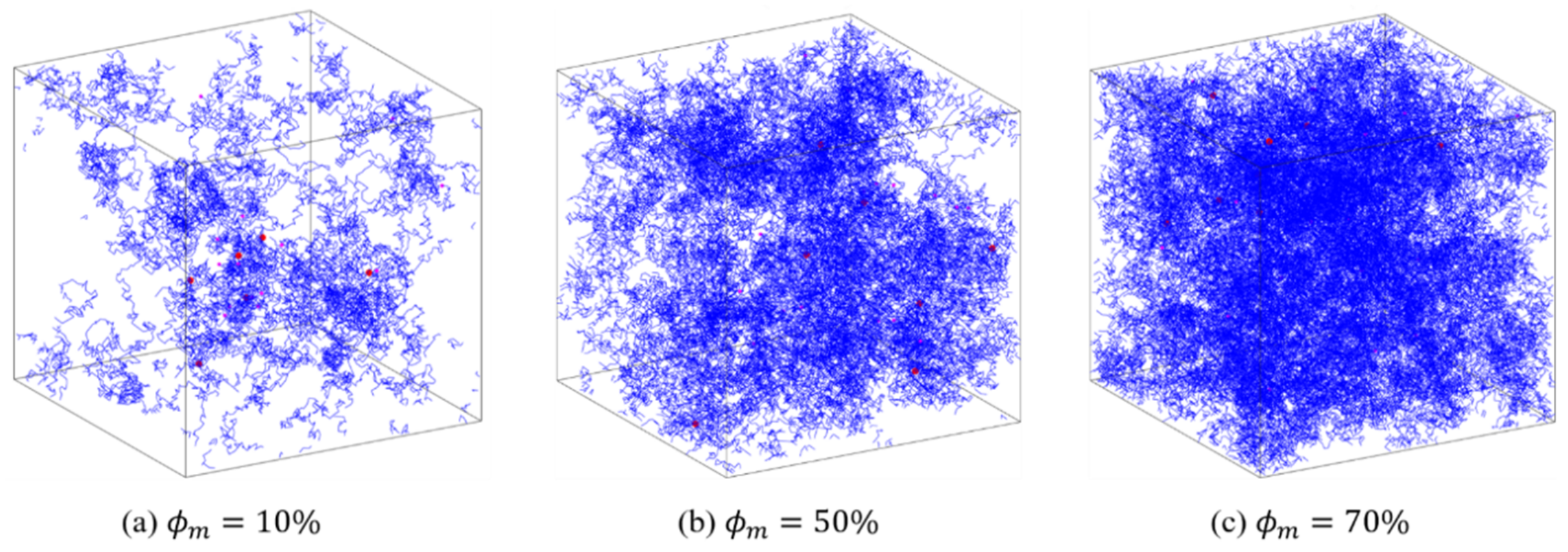
3.1. Dataset Generation and Preprocessing
3.2. Framework of Deep Learning Models
4. Results and Discussions
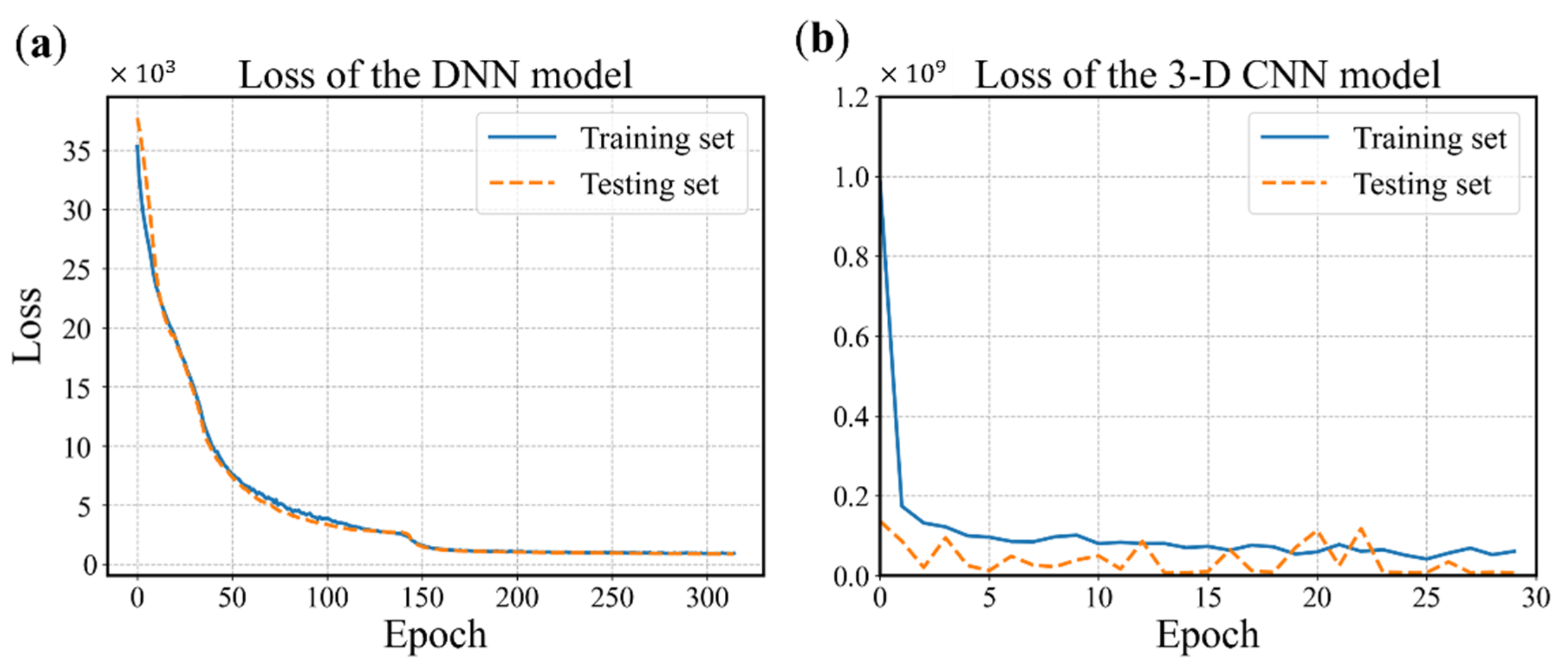
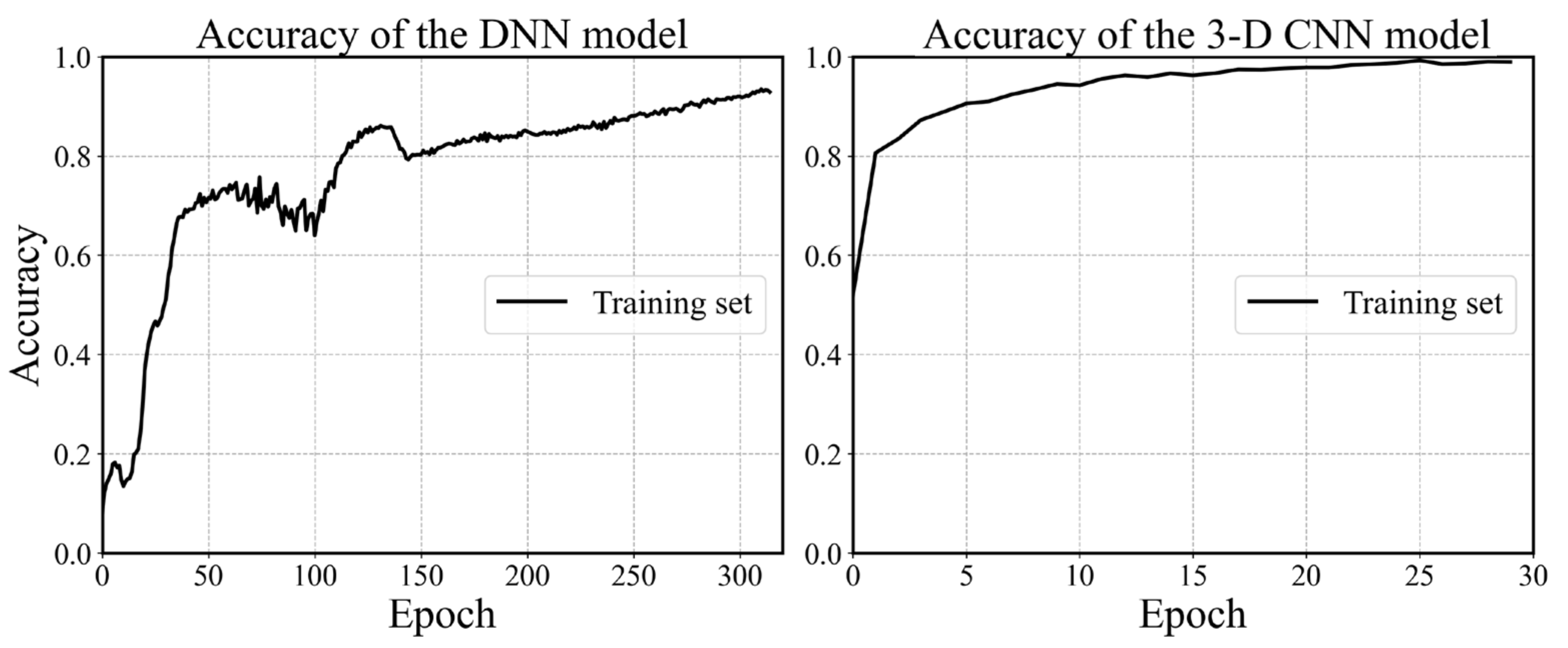
4.1. Analysis and Comparison of Model Performance
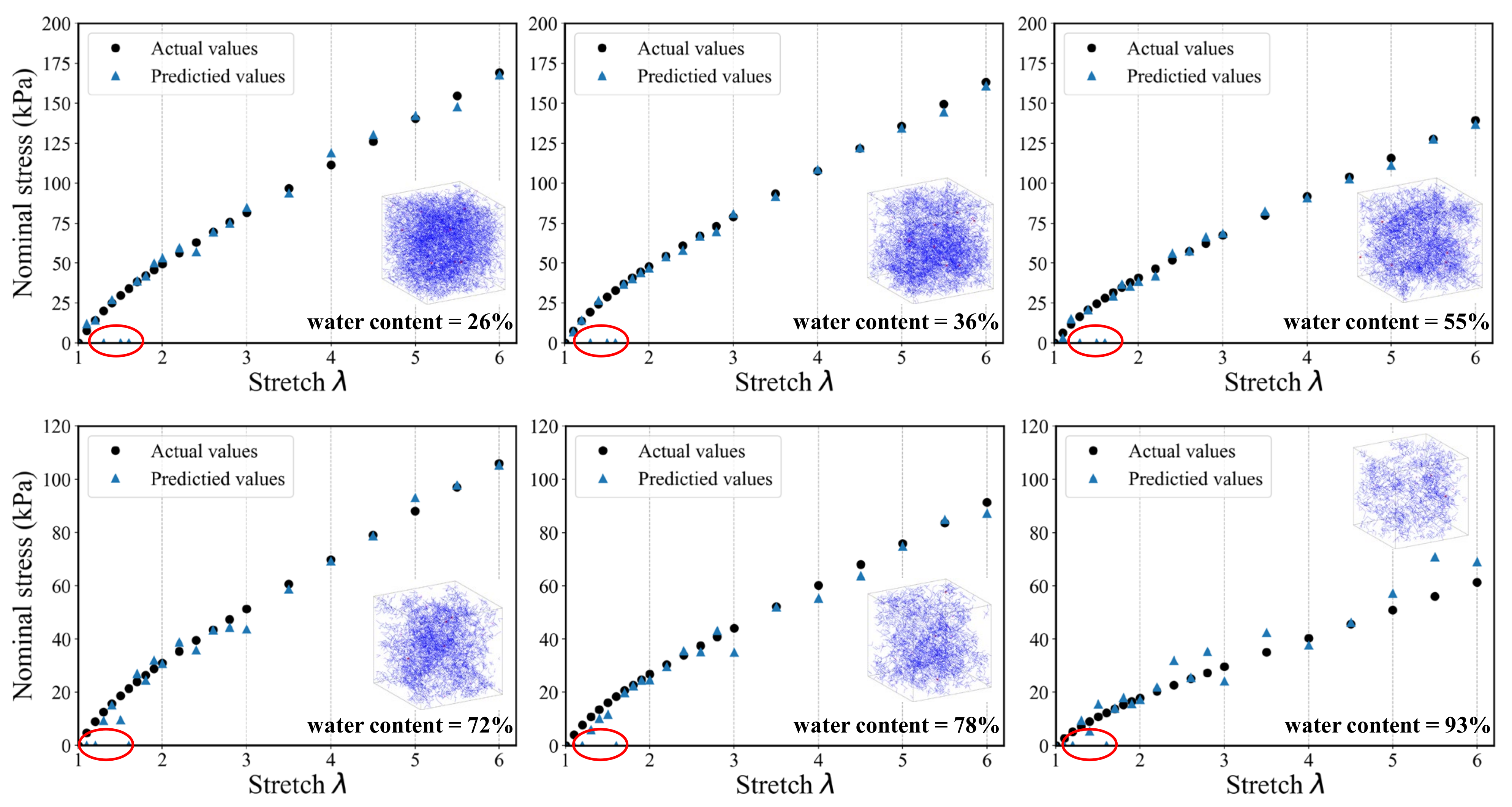
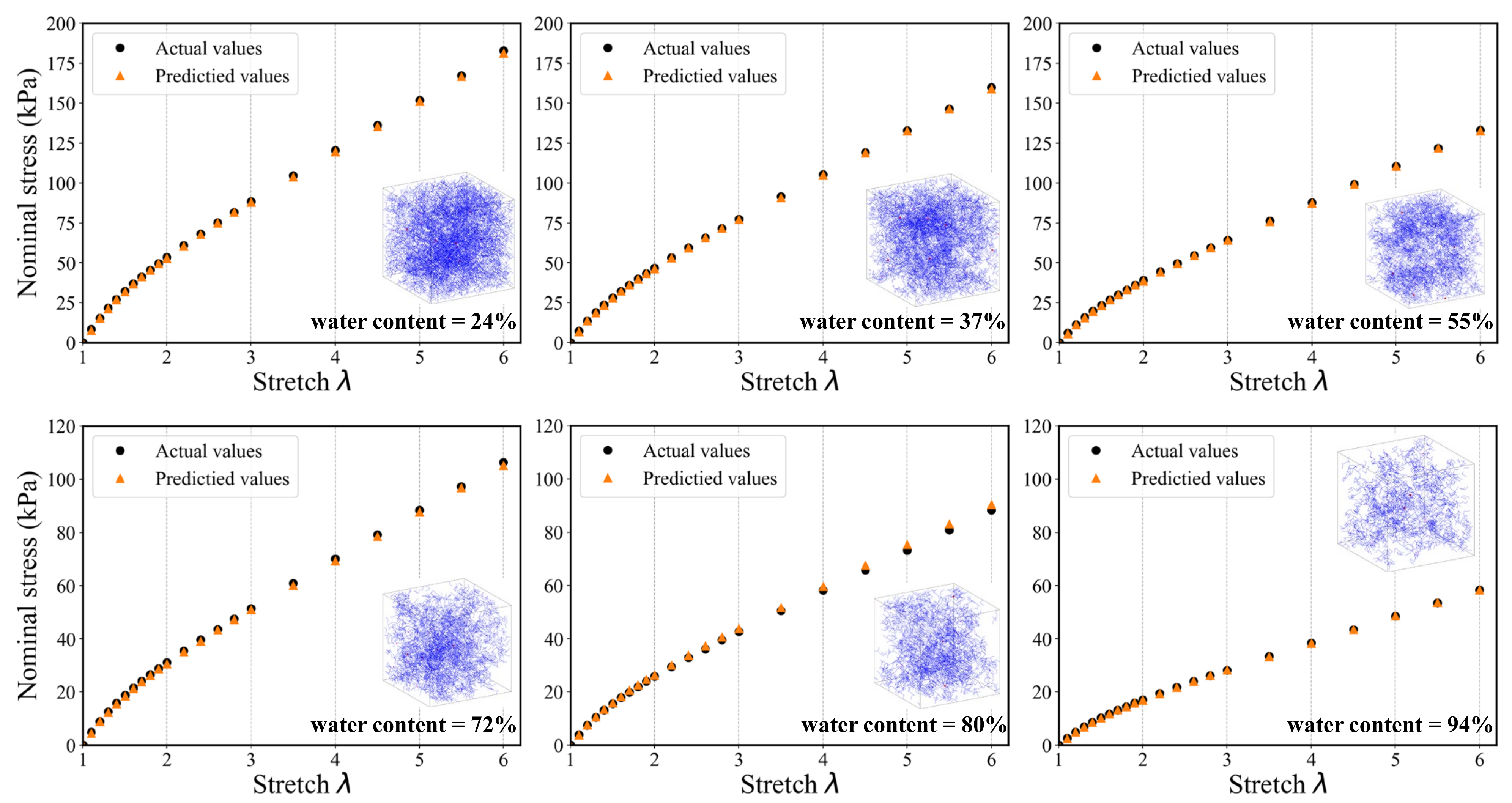
4.2. Evaluation of Model Generalization
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Conflicts of Interest
References
- Liu, Z.; Toh, W.; Ng, T.Y. Advances in Mechanics of Soft Materials: A Review of Large Deformation Behavior of Hydrogels. Int. J. Appl. Mech. 2015, 7, 1530001. [Google Scholar] [CrossRef]
- Huang, R.; Zheng, S.; Liu, Z.; Ng, T.Y. Recent Advances of the Constitutive Models of Smart Materials—Hydrogels and Shape Memory Polymers. Int. J. Appl. Mech. 2020, 12, 2050014. [Google Scholar] [CrossRef] [Green Version]
- Sun, J.Y.; Zhao, X.H.; Illeperuma, W.R.K.; Chaudhuri, O.; Oh, K.H.; Mooney, D.J.; Vlassak, J.J.; Suo, Z.G. Highly stretchable and tough hydrogels. Nature 2012, 489, 133–136. [Google Scholar] [CrossRef] [PubMed]
- Wei, Z.; Yang, J.H.; Liu, Z.Q.; Xu, F.; Zhou, J.X.; Zrinyi, M.; Osada, Y.; Chen, Y.M. Novel Biocompatible Polysaccharide-Based Self-Healing Hydrogel. Adv. Funct. Mater. 2015, 25, 1352–1359. [Google Scholar] [CrossRef]
- Taylor, D.L.; Panhuis, M.I.H. Self-Healing Hydrogels. Adv. Mater. 2016, 28, 9060–9093. [Google Scholar] [CrossRef] [PubMed]
- Gong, J.P. Why are double network hydrogels so tough? Soft Matter 2010, 6, 2583–2590. [Google Scholar] [CrossRef]
- Li, J.; Mooney, D.J. Designing hydrogels for controlled drug delivery. Nat. Rev. Mater. 2016, 1, 16071. [Google Scholar] [CrossRef]
- Liu, L.; Li, X.; Ren, X.; Wu, G.F. Flexible strain sensors with rapid self-healing by multiple hydrogen bonds. Polymer 2020, 202, 122657. [Google Scholar] [CrossRef]
- Tian, K.; Bae, J.; Bakarich, S.E.; Yang, C.; Gately, R.D.; Spinks, G.M.; Panhuis, M.I.H.; Suo, Z.; Vlassak, J.J. 3D Printing of Transparent and Conductive Heterogeneous Hydrogel-Elastomer Systems. Adv. Mater. 2017, 29, 1604827. [Google Scholar] [CrossRef] [Green Version]
- Yuk, H.; Varela, C.E.; Nabzdyk, C.S.; Mao, X.; Padera, R.F.; Roche, E.T.; Zhao, X. Dry double-sided tape for adhesion of wet tissues and devices. Nature 2019, 575, 169–174. [Google Scholar] [CrossRef]
- Lyu, Y.; Azevedo, H.S. Supramolecular Hydrogels for Protein Delivery in Tissue Engineering. Molecules 2021, 26, 873. [Google Scholar] [CrossRef] [PubMed]
- Censi, R.; Di Martino, P.; Vermonden, T.; Hennink, W.E. Hydrogels for protein delivery in tissue engineering. J. Control. Release 2012, 161, 680–692. [Google Scholar] [CrossRef] [PubMed]
- Xing, J.; Yang, B.; Dang, W.; Li, J.; Bai, B. Preparation of Photo/Electro-Sensitive Hydrogel and Its Adsorption/Desorption Behavior to Acid Fuchsine. Water Air Soil Pollut. 2020, 231, 231. [Google Scholar] [CrossRef]
- Shuai, S.; Zhou, S.; Liu, Y.; Huo, W.; Zhu, H.; Li, Y.; Rao, Z.; Zhao, C.; Hao, J. The preparation and property of photo- and thermo-responsive hydrogels with a blending system. J. Mater. Sci. 2020, 55, 786–795. [Google Scholar] [CrossRef]
- Chen, X.; Li, H.; Lam, K.Y. A multiphysics model of photo-sensitive hydrogels in response to light-thermo-pH-salt coupled stimuli for biomedical applications. Bioelectrochemistry 2020, 135, 107584. [Google Scholar] [CrossRef] [PubMed]
- Xiao, R.; Qian, J.; Qu, S. Modeling Gel Swelling in Binary Solvents: A Thermodynamic Approach to Explaining Cosolvency and Cononsolvency Effects. Int. J. Appl. Mech. 2019, 11, 1950050. [Google Scholar] [CrossRef]
- Ghareeb, A.; Elbanna, A. An adaptive quasicontinuum approach for modeling fracture in networked materials: Application to modeling of polymer networks. J. Mech. Phys. Solids 2020, 137, 103819. [Google Scholar] [CrossRef] [Green Version]
- Tauber, J.; Kok, A.R.; van der Gucht, J.; Dussi, S. The role of temperature in the rigidity-controlled fracture of elastic networks. Soft Matter 2020, 16, 9975–9985. [Google Scholar] [CrossRef]
- Yin, Y.; Bertin, N.; Wang, Y.; Bao, Z.; Cai, W. Topological origin of strain induced damage of multi-network elastomers by bond breaking. Extrem. Mech. Lett. 2020, 40, 100883. [Google Scholar] [CrossRef]
- Lei, J.; Li, Z.; Xu, S.; Liu, Z. Recent advances of hydrogel network models for studies on mechanical behaviors. Acta Mech. Sin. 2021, 37, 367–386. [Google Scholar] [CrossRef]
- Lei, J.; Li, Z.; Xu, S.; Liu, Z. A mesoscopic network mechanics method to reproduce the large deformation and fracture process of cross-linked elastomers. J. Mech. Phys. Solids 2021, 156, 104599. [Google Scholar] [CrossRef]
- Dong, J.; Qin, Q.-H.; Xiao, Y. Nelder-Mead Optimization of Elastic Metamaterials via Machine-Learning-Aided Surrogate Modeling. Int. J. Appl. Mech. 2020, 12, 2050011. [Google Scholar] [CrossRef]
- Jie, Y.; Rui, X.; Qun, H.; Qian, S.; Wei, H.; Heng, H. Data-driven Computational Mechanics:a Review. Chin. J. Solid Mech. 2020, 41, 1–14. [Google Scholar]
- Bessa, M.A.; Bostanabad, R.; Liu, Z.; Hu, A.; Apley, D.W.; Brinson, C.; Chen, W.; Liu, W.K. A framework for data-driven analysis of materials under uncertainty: Countering the curse of dimensionality. Comput. Methods Appl. Mech. Eng. 2017, 320, 633–667. [Google Scholar] [CrossRef]
- Ibanez, R.; Abisset-Chavanne, E.; Aguado, J.V.; Gonzalez, D.; Cueto, E.; Chinesta, F. A Manifold Learning Approach to Data-Driven Computational Elasticity and Inelasticity. Arch. Comput. Methods Eng. 2018, 25, 47–57. [Google Scholar] [CrossRef] [Green Version]
- Zheng, S.; Liu, Z. The Machine Learning Embedded Method of Parameters Determination in the Constitutive Models and Potential Applications for Hydrogels. Int. J. Appl. Mech. 2021, 13, 2150001. [Google Scholar] [CrossRef]
- Li, F.; Han, J.; Cao, T.; Lam, W.; Fan, B.; Tang, W.; Chen, S.; Fok, K.L.; Li, L. Design of self-assembly dipeptide hydrogels and machine learning via their chemical features. Proc. Natl. Acad. Sci. USA 2019, 116, 11259–11264. [Google Scholar] [CrossRef] [Green Version]
- Haghighat, E.; Raissi, M.; Moure, A.; Gomez, H.; Juanes, R. A physics-informed deep learning framework for inversion and surrogate modeling in solid mechanics. Comput. Methods Appl. Mech. Eng. 2021, 379, 113741. [Google Scholar] [CrossRef]
- Pavel, M.S.; Schulz, H.; Behnke, S. Object class segmentation of RGB-D video using recurrent convolutional neural networks. Neural Netw. 2017, 88, 105–113. [Google Scholar] [CrossRef]
- Yu, S.; Jia, S.; Xu, C. Convolutional neural networks for hyperspectral image classification. Neurocomputing 2017, 219, 88–98. [Google Scholar] [CrossRef]
- Shin, H.-C.; Roth, H.R.; Gao, M.; Lu, L.; Xu, Z.; Nogues, I.; Yao, J.; Mollura, D.; Summers, R.M. Deep Convolutional Neural Networks for Computer-Aided Detection: CNN Architectures, Dataset Characteristics and Transfer Learning. IEEE Trans. Med Imaging 2016, 35, 1285–1298. [Google Scholar] [CrossRef] [Green Version]
- Khan, A.; Sohail, A.; Zahoora, U.; Qureshi, A.S. A survey of the recent architectures of deep convolutional neural networks. Artif. Intell. Rev. 2020, 53, 5455–5516. [Google Scholar] [CrossRef] [Green Version]
- Zobeiry, N.; Reiner, J.; Vaziri, R. Theory-guided machine learning for damage characterization of composites. Compos. Struct. 2020, 246, 112407. [Google Scholar] [CrossRef]
- Abueidda, D.W.; Almasri, M.; Ammourah, R.; Ravaioli, U.; Jasiuk, I.M.; Sobh, N.A. Prediction and optimization of mechanical properties of composites using convolutional neural networks. Compos. Struct. 2019, 227, 111264. [Google Scholar] [CrossRef] [Green Version]
- Yang, C.; Kim, Y.; Ryu, S.; Gu, G.X. Prediction of composite microstructure stress-strain curves using convolutional neural networks. Mater. Des. 2020, 189, 108509. [Google Scholar] [CrossRef]
- Yang, Z.; Yabansu, Y.C.; Al-Bahrani, R.; Liao, W.-K.; Choudhary, A.N.; Kalidindi, S.R.; Agrawal, A. Deep learning approaches for mining structure-property linkages in high contrast composites from simulation datasets. Comput. Mater. Sci. 2018, 151, 278–287. [Google Scholar] [CrossRef]
- Cecen, A.; Dai, H.; Yabansu, Y.C.; Kalidindi, S.R.; Song, L. Material structure-property linkages using three-dimensional convolutional neural networks. Acta Mater. 2018, 146, 76–84. [Google Scholar] [CrossRef]
- Yang, Z.; Papanikolaou, S.; Reid, A.C.E.; Liao, W.K.; Choudhary, A.N.; Campbell, C.; Agrawal, A. Learning to Predict Crystal Plasticity at the Nanoscale: Deep Residual Networks and Size Effects in Uniaxial Compression Discrete Dislocation Simulations. Sci. Rep. 2020, 10, 8262. [Google Scholar] [CrossRef] [PubMed]
- Pandey, A.; Pokharel, R. Machine learning based surrogate modeling approach for mapping crystal deformation in three dimensions. Scr. Mater. 2021, 193, 1–5. [Google Scholar] [CrossRef]
- Herriott, C.; Spear, A.D. Predicting microstructure-dependent mechanical properties in additively manufactured metals with machine- and deep-learning methods. Comput. Mater. Sci. 2020, 175, 109599. [Google Scholar] [CrossRef]
- Choi, J.; Quagliato, L.; Lee, S.; Shin, J.; Kim, N. Multiaxial fatigue life prediction of polychloroprene rubber (CR) reinforced with tungsten nano-particles based on semi-empirical and machine learning models. Int. J. Fatigue 2021, 145, 106136. [Google Scholar] [CrossRef]
- Douglass, M.J.J. Hands-on Machine Learning with Scikit-Learn, Keras, and Tensorflow, 2nd edition. Phys. Eng. Sci. Med. 2020, 43, 1135–1136. [Google Scholar] [CrossRef]
- Flory, P.J.; Rehner, J. Statistical mechanics of cross-linked polymer networks I Rubberlike elasticity. J. Chem. Phys. 1943, 11, 512–520. [Google Scholar] [CrossRef]
- Flory, P.J.; Rehner, J. Statistical mechanics of cross-linked polymer networks II Swelling. J. Chem. Phys. 1943, 11, 521–526. [Google Scholar] [CrossRef]
- Li, Z.; Liu, Z.; Ng, T.Y.; Sharma, P. The effect of water content on the elastic modulus and fracture energy of hydrogel. Extrem. Mech. Lett. 2020, 35, 100617. [Google Scholar] [CrossRef]
- Li, Z.; Liu, Z. Energy transfer speed of polymer network and its scaling-law of elastic modulus—New insights. J. Appl. Phys. 2019, 126, 215101. [Google Scholar] [CrossRef] [Green Version]
- Liu, R.; Kumar, A.; Chen, Z.; Agrawal, A.; Sundararaghavan, V.; Choudhary, A. A predictive machine learning approach for microstructure optimization and materials design. Sci. Rep. 2015, 5, 11551. [Google Scholar] [CrossRef] [Green Version]
- Reimann, D.; Nidadavolu, K.; ul Hassan, H.; Vajragupta, N.; Glasmachers, T.; Junker, P.; Hartmaier, A. Modeling Macroscopic Material Behavior With Machine Learning Algorithms Trained by Micromechanical Simulations. Front. Mater. 2019, 6, 181. [Google Scholar] [CrossRef] [Green Version]
- Bag, S.; Mandal, R. Interaction from structure using machine learning: In and out of equilibrium. Soft Matter 2021, 17, 8322–8330. [Google Scholar] [CrossRef] [PubMed]
- Swaddiwudhipong, S.; Hua, J.; Harsono, E.; Liu, Z.S.; Ooi, N.S.B. Improved algorithm for material characterization by simulated indentation tests. Model. Simul. Mater. Sci. Eng. 2006, 14, 1347–1362. [Google Scholar] [CrossRef]
- Benitez, J.M.; Castro, J.L.; Requena, I. Are artificial neural networks black boxes? IEEE Trans. Neural Netw. 1997, 8, 1156–1164. [Google Scholar] [CrossRef] [PubMed]
- Hornik, K.; Stinchcombe, M.; White, H. Multilayer feedforward networks are universal approximators. Neural Netw. 1989, 2, 359–366. [Google Scholar] [CrossRef]
- Bergstra, J.; Bengio, Y. Random Search for Hyper-Parameter Optimization. J. Mach. Learn. Res. 2012, 13, 281–305. [Google Scholar]
- Santurkar, S.; Tsipras, D.; Ilyas, A.; Madry, A. How Does Batch Normalization Help Optimization? In Proceedings of the 32nd International Conference on Advances in Neural Information Processing Systems 31 (NIPS 2018), Montreal, QC, Canada, 3–8 December 2018. [Google Scholar]
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Hyperparameters | Model | |
|---|---|---|
| DNN | 3D CNN | |
| Number of epochs | 315 | 30 |
| Batch size | 32 | 32 |
| Learning rate | 5.6 × 10−3 | 1 × 10−3 |
| Optimizer | SGD | Nadam |
| Loss function | MSE | MSE |
| Trainable weights | 1477 | 430,872,6 |
| Activation functions | ReLU | ReLU |
| Model | Values of Indicators | |||||
|---|---|---|---|---|---|---|
| Training Set | Testing Set | |||||
| MSE | MSPE | MSE | MSPE | |||
| DNN | 9.3 × 103 kPa | 3.61% | 92.87% | 9.1 × 104 kPa | 3.55% | 91.00% |
| 3D CNN | 7.1 × 103 kPa | 0.30% | 99.23% | 5.7 × 103 kPa | 0.24% | 99.65% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhu, J.-A.; Jia, Y.; Lei, J.; Liu, Z. Deep Learning Approach to Mechanical Property Prediction of Single-Network Hydrogel. Mathematics 2021, 9, 2804. https://doi.org/10.3390/math9212804
Zhu J-A, Jia Y, Lei J, Liu Z. Deep Learning Approach to Mechanical Property Prediction of Single-Network Hydrogel. Mathematics. 2021; 9(21):2804. https://doi.org/10.3390/math9212804
Chicago/Turabian StyleZhu, Jing-Ang, Yetong Jia, Jincheng Lei, and Zishun Liu. 2021. "Deep Learning Approach to Mechanical Property Prediction of Single-Network Hydrogel" Mathematics 9, no. 21: 2804. https://doi.org/10.3390/math9212804
APA StyleZhu, J. -A., Jia, Y., Lei, J., & Liu, Z. (2021). Deep Learning Approach to Mechanical Property Prediction of Single-Network Hydrogel. Mathematics, 9(21), 2804. https://doi.org/10.3390/math9212804