
A Review on Text Steganography Techniques



Abstract
:1. Introduction
- presents a brief review of existing text steganography methods;
- summarizes text steganography classes: statistical and random generation, format-based methodologies, and linguistics, while identifying their methodologies from 2016 to 2021;
- recommends future work in the field of text steganography.
2. Materials and Methods
2.1. Data Sources
- Science Direct (www.sciencedirect.com (accessed on 25 January 2021)).
- Institute of Electrical and Electronics Engineers (IEEE) Xplore Digital Library (ieeexplore.ieee.org (accessed on 31 January 2021)).
- Springer Link (link.springer.com (accessed on 8 February 2021)).
- Taylor and Francis (www.taylorandfrancisgroup.com (accessed on 17 February 2021)).
- MDPI (www.mdpi.com (accessed on 25 February 2021)).
- Google scholar (www.scholar.google.com (accessed on 7 March 2021)).
2.2. Search Process
- (text steganography OR (text steganographic) OR (text AND hiding)) AND (format based OR linguistic OR random OR statistical).
- ((text data AND steganography) OR (text steganography AND method) OR (steganography AND text)) AND (neural network OR deep learning) OR (Natural language OR NLP).
2.3. Data Selection
- Was the research article published between the years 2016 and 2021?
- Is the research article reported in any of the referred data sources?
- Does the research article mention or discuss one of the text steganography categories?
2.4. Data Extraction
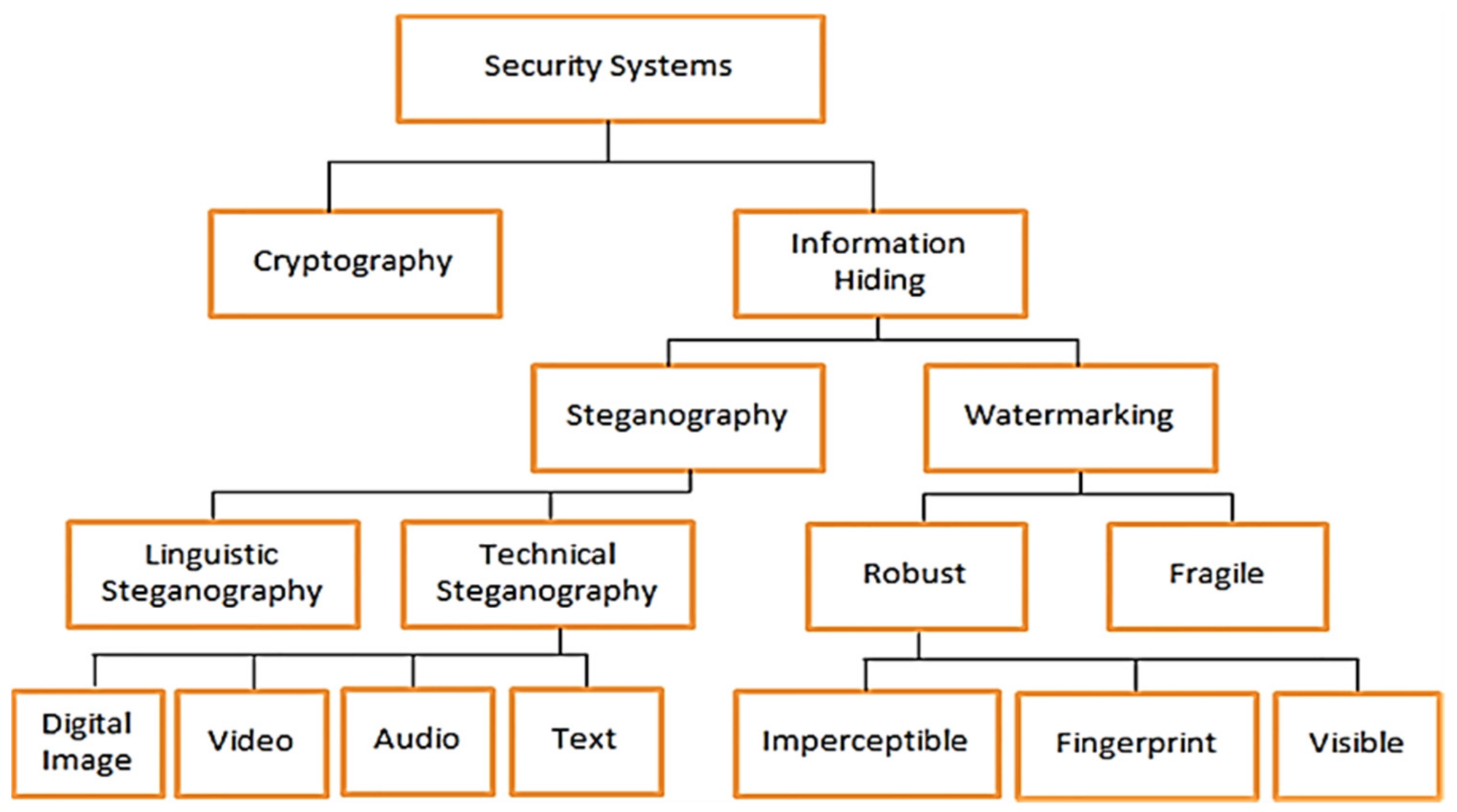
3. Background of Steganography
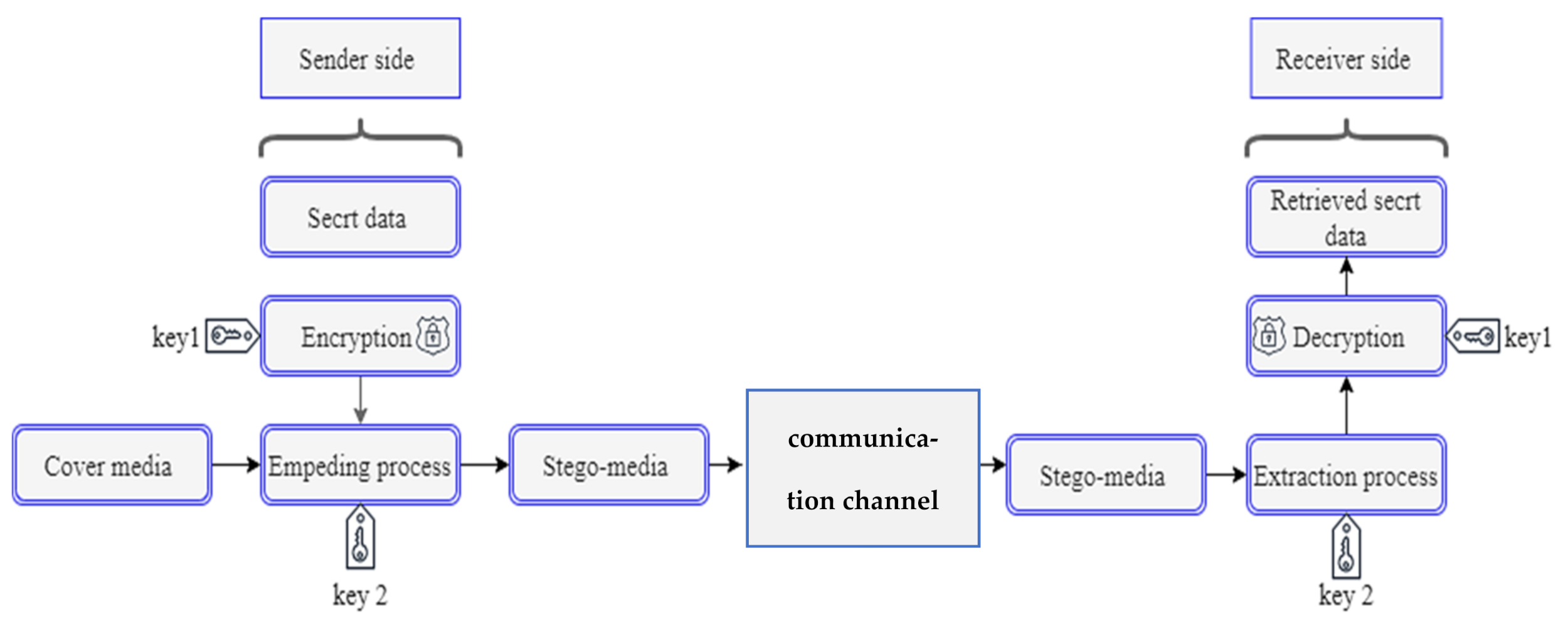
4. Steganography General Procedures
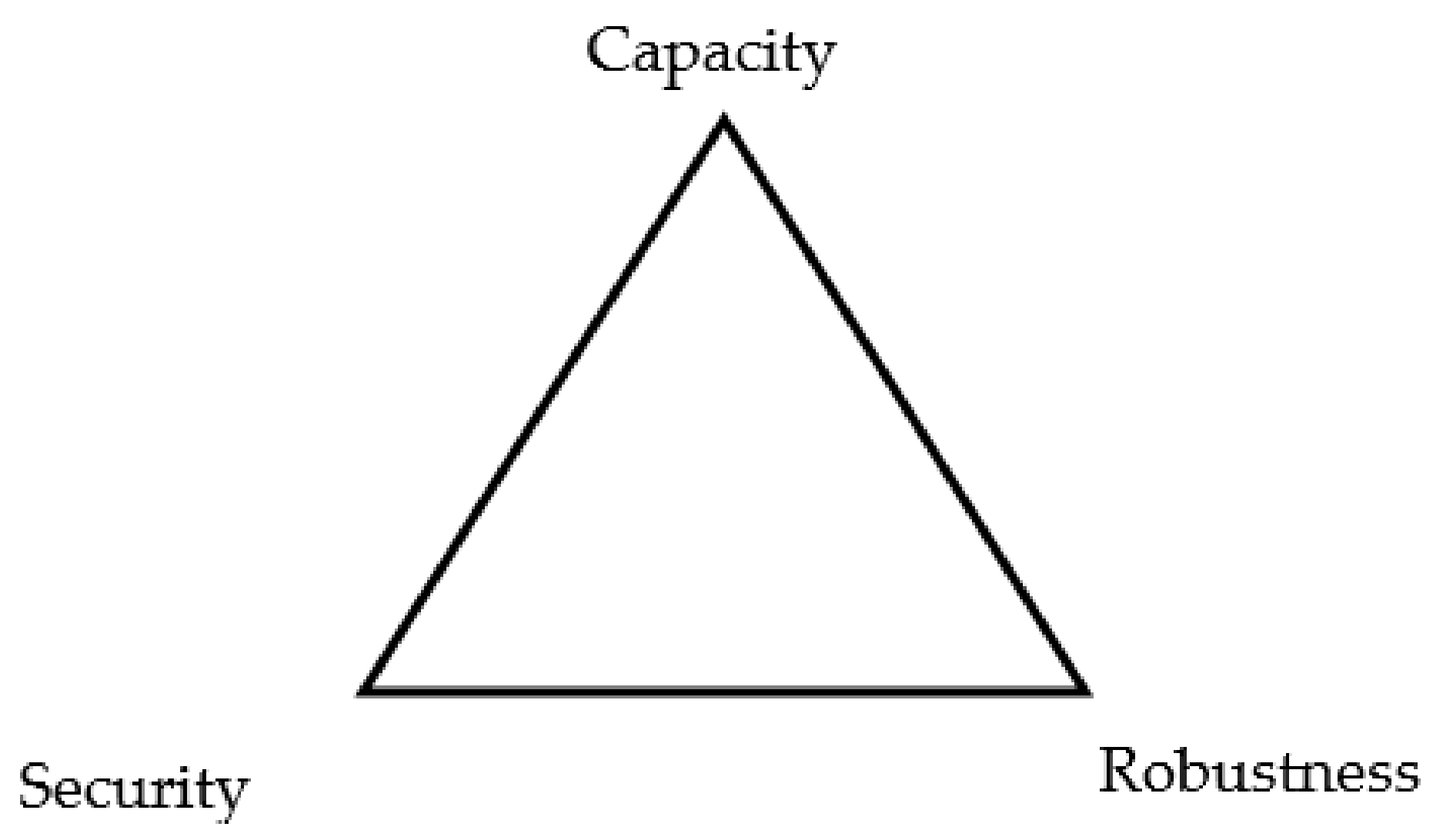
5. Attributes of Steganography
5.1. Imperceptibility
5.2. Security
5.3. Payload Capacity
5.4. Robustness
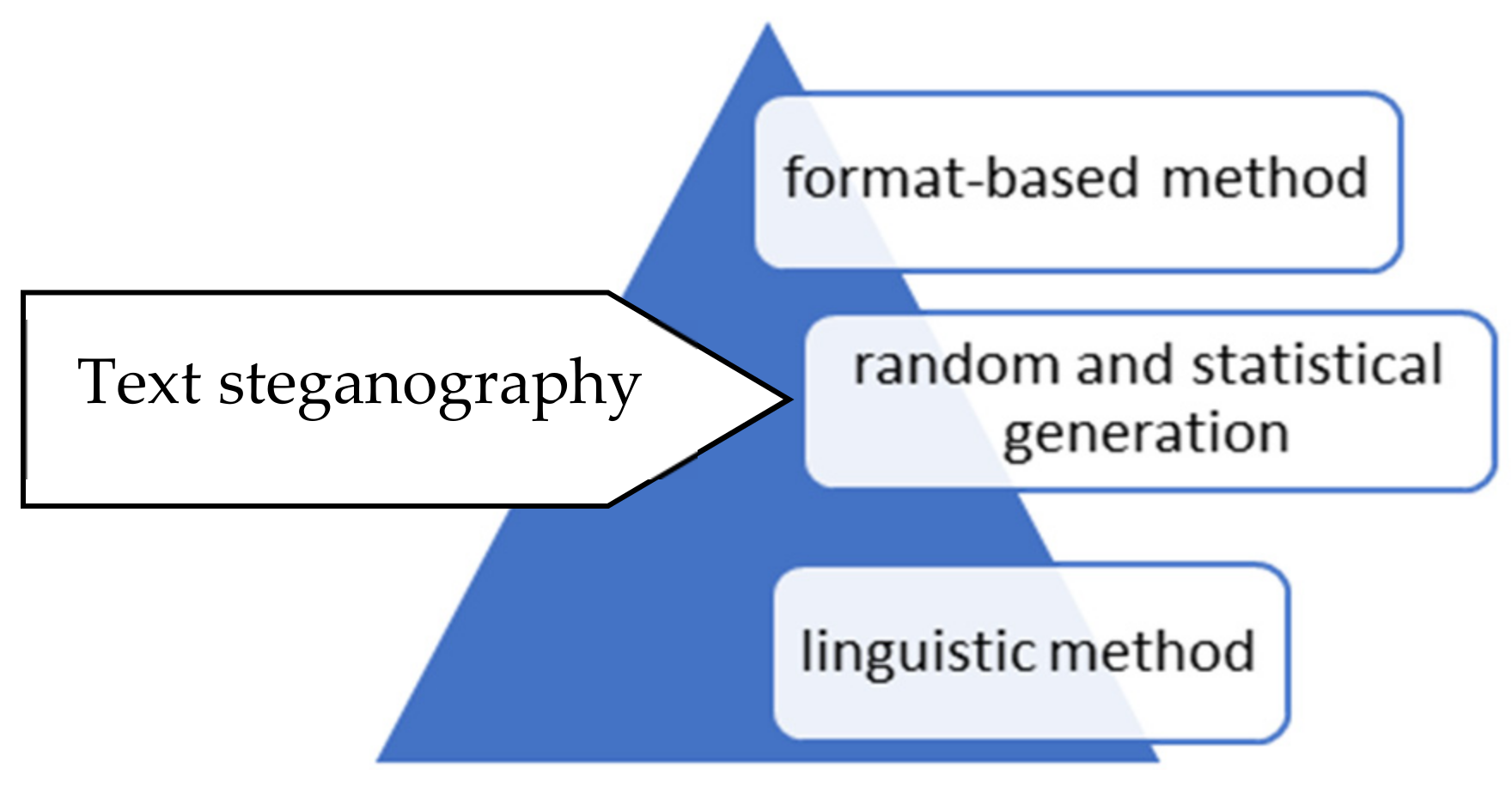
6. Text Steganography Categories
6.1. Format-Based Method
6.2. Linguistic
6.3. Random and Statistical Generation
7. Discussion and Future Directions
- A hybrid method from the classical approach and deep learning approaches;
- Semantic control through auto text generation by deep learning, particularly for long texts.
- Spatial format-based steganography using Unicode characters for data hiding with minimal stego file size.
- Few researchers have utilized compression to increase the effectiveness of their techniques because it decreases the amount of hidden information. This could be further examined.
- As a performance metric, several approaches have investigated hiding capacity, security, and robustness. However, there is a risk of attack if data is sent over untrusted channels. In addition to other metrics, the effectiveness of a well-designed algorithm against various attacks may be evaluated.
- Combining encryption and steganography techniques to provide an additional layer of security for the embedding algorithm. These combined methods can be studied further.
- Sequential selection of embedding positions makes the algorithm vulnerable to attack. Therefore, an extra security layer for embedding techniques that offers non-sequence or random embedding positions can be explored.
8. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Cheddad, A.; Condell, J.; Curran, K.; Mc Kevitt, P. Digital image steganography: Survey and analysis of current methods. Signal. Process. 2010, 90, 727–752. [Google Scholar] [CrossRef] [Green Version]
- Anderson, R.; Petitcolas, F. On the limits of steganography. IEEE J. Sel. Areas Commun. 1998, 16, 474–481. [Google Scholar] [CrossRef] [Green Version]
- Srikumar, R.; Malarvizhi, C.S. Strong encryption using steganography and digital watermarking. In Proceedings of the 22nd Picture Coding Symposium, Seoul, Korea, 25–27 April 2001; pp. 425–428. [Google Scholar]
- Al-Daweri, M.S.; Abdullah, S.; Ariffin, K.A.Z. A homogeneous ensemble based dynamic artificial neural network for solving the intrusion detection problem. Int. J. Crit. Infrastruct. Prot. 2021, 34, 100449. [Google Scholar] [CrossRef]
- Majeed, M.A.; Sulaiman, R. An improved LSB image steganography technique using BIT-inverse in 24 BIT colour image. J. Theor. Appl. Inf. Technol. 2015, 80, 2. [Google Scholar]
- Johnson, N.F.; Jajodia, S. Exploring steganography: Seeing the unseen. Computer 1998, 31, 26–34. [Google Scholar] [CrossRef]
- Premaratne, P.; DeSilva, L.C.; Burnett, I. Low frequency component-based watermarking scheme using 2D data matrix. Int. J. Inf. Technol. 2006, 12, 1–12. [Google Scholar]
- Le, T.H.N.; Nguyen, K.H.; Le, H.B. Literature survey on image watermarking tools, watermark attacks, and benchmarking tools. In Proceedings of the 2nd International Conference on Advance Multimedia, IEEE, Athens, Greece, 13–19 June 2010; pp. 67–73. [Google Scholar] [CrossRef]
- Cox, I.J.; Miller, M.L.; Bloom, J.A.; Fridrich, J.; Kalker, T. Digital Watermarking and Steganography; Morgan Kaufmann: Burlington, MA, USA, 2008. [Google Scholar] [CrossRef]
- Shih, F.Y. Digital Watermarking and Steganography: Fundamentals and Techniques; CRC Press: Boca Raton, FL, USA, 2017. [Google Scholar]
- Al-Naqeeb, A.B.; Nordin, M.J. Robustness Watermarking Authentication Using Hybridisation DWT-DCT and DWT-SVD. Pertanika J. Sci. Technol. 2017, 25, 73–86. [Google Scholar]
- Judge, J.C. Steganography: Past, Present, Future; Lawrence Livermore National Lab.: Livermore, CA, USA, 2001. [Google Scholar]
- Kamil, S.; Ayob, M.; Abdullah, S.N.H.S.; Ahmad, Z. Challenges in multi-layer data security for video steganography revisited. APIJTM 2018, 07, 53–62. [Google Scholar] [CrossRef]
- Stefan, K.; Fabien, A.P.P. Information Hiding Techniques for Steganography and Digital Watermarking (Artech House Computer Security Series); Artech House: London, UK, 2000. [Google Scholar]
- Mishra, M.; Mishra, P.; Adhikary, M.C. Digital image data hiding techniques: A comparative study. arXiv 2014, arXiv:1408.3564. [Google Scholar]
- Provos, N.; Honeyman, P. Hide and seek: An introduction to steganography. IEEE Secur. Priv. Mag. 2003, 1, 32–44. [Google Scholar] [CrossRef] [Green Version]
- Petitcolas, F.A.P.; Anderson, R.J.; Kuhn, M. Information hiding-a survey. Proc. IEEE 1999, 87, 1062–1078. [Google Scholar] [CrossRef] [Green Version]
- Du, J.-X.; Huang, D.-S.; Wang, X.-F.; Gu, X. Computer-aided plant species identification (CAPSI) based on leaf shape matching technique. Trans. Inst. Meas. Control 2006, 28, 275–285. [Google Scholar] [CrossRef]
- Zheng, C.-H.; Huang, D.-S.; Sun, Z.-L.; Lyu, M.R.; Lok, T.-M. Nonnegative independent component analysis based on minimizing mutual information technique. Neurocomputing 2006, 69, 878–883. [Google Scholar] [CrossRef]
- Bhattacharjya, A.K.; Ancin, H. Data embedding in text for a copier system. In Proceedings of the 2018 IEEE International Conference on Image Processing, Athens, Greece, 7–10 October 2018; pp. 245–249. [Google Scholar]
- Baawi, S.S.; Mokhtar, M.R.; Sulaiman, R. A comparative study on the advancement of text steganography techniques in digital media. ARPN J. Eng. Appl. Sci. 2018, 13, 1854–1863. [Google Scholar]
- Awais, M.; Müller, H.; Tang, T.B.; Meriaudeau, F. Reversible data embedding in Golomb Rice code. In Proceedings of the 2011 IEEE Inter-national Conference on Signal and Image Processing Applications, Kuala Lumpur, Malaysia, 16–18 November 2011; pp. 515–519. [Google Scholar] [CrossRef]
- Kadhim, I.J. A new audio steganography system based on auto-key generator. AL-Khwarizmi Eng. J. 2012, 8, 27–36. [Google Scholar]
- Santhi, B.; Radhika, G.; Reka, S.R. Information security using audio steganography—A survey. Res. J. Appl. Sci. Eng. Technol. 2012, 4, 2255–2258. [Google Scholar]
- Limkar, S.; Nemade, A.; Badgujar, A.; Kate, R. Improved Data Hiding Technique Based on Audio and Video Steganography. Smart Comput. Inform. 2017, 581–588. [Google Scholar] [CrossRef]
- Jeyasheeli, P.G.; Selva, J.J. A survey on DNA and image steganography. In Proceedings of the 2017 4th International Conference on Advanced Computing and Communication Systems (ICACCS), Coimbatore, India, 6–7 January 2017. [Google Scholar] [CrossRef]
- Haughton, D.; Balado, F. A modified watermark synchronisation code for robust embedding of data in DNA. In Proceedings of the 2013 IEEE International Conference on Acoustics, Speech and Signal Processing, Vancouver, BC, Canada, 26–31 May 2013; pp. 1148–1152. [Google Scholar] [CrossRef] [Green Version]
- Odeh, A.; Elleithy, K.; Faezipour, M.; Abdelfattah, E. Novel steganography over HTML code. In Innovations and Advances in Computing, Informatics, Systems Sciences, Networking and Engineering; Springer: Berlin/Heidelberg, Germany, 2015; pp. 607–611. [Google Scholar]
- Memon, A.G.; Khawaja, S.; Shah, A. Steganography: A new horizon for safe communication through xml. J. Theor. Appl. Inf. Technol. 2008, 4, 187–202. [Google Scholar]
- Zielińska, E.; Mazurczyk, W.; Szczypiorski, K. Trends in steganography. Common. ACM. 2014, 57, 86–95. [Google Scholar] [CrossRef]
- Subhedar, M.S.; Mankar, V.H. Current status and key issues in image steganography: A survey. Comput. Sci. Rev. 2014, 13–14, 95–113. [Google Scholar] [CrossRef]
- Li, B.; He, J.; Huang, J.; Shi, Y.Q. A survey on image steganography and steganalysis. J. Inf. Hiding Multimed. Signal Process. 2011, 2, 142–172. [Google Scholar]
- Marvel, L.M.; Retter, C.T.; Boncelet, C.G. A methodology for data hiding using images. In Proceedings of the IEEE Military Communications Conference, Los Angeles, CA, USA, 19–21 October 1998; pp. 1044–1047. [Google Scholar]
- Mathkour, H.; Al-Sadoon, B.; Touir, A. A new image steganography technique. In Proceedings of the 2008 4th International Conference on Wireless Communications, Networking and Mobile Computing, Dalian, China, 12–17 October 2008; pp. 1–4. [Google Scholar]
- Altaay, A.A.J.; Sahib, S.B.; Zamani, M. An introduction to image steganography techniques. In Proceedings of the 2012 International Conference on Advanced Computer Science Applications and Technologies (ACSAT), Kuala Lumpur, Malaysia, 26–28 November 2012; pp. 122–126. [Google Scholar]
- Ramu, P.; Swaminathan, R. Imperceptibility—Robustness tradeoff studies for ECG steganography using continuous ant colony optimization. Expert Syst. Appl. 2016, 49, 123–135. [Google Scholar] [CrossRef]
- Abraham, A.; Paprzycki, M. Significance of steganography on data security. In Proceedings of the ITCC 2004 International Conference on Information Technology: Coding and Computing, Las Vegas, NV, USA, 5–7 April 2004; pp. 347–351. [Google Scholar]
- Baawi, S.S.; Mokhtar, M.R.; Sulaiman, R. Enhancement of text steganography technique using lempel-ziv-welch algorithm and two-letter word technique. In Proceedings of the 3rd International Conference of Reliable Information and Communication Technology (IRICT 2018), Kuala Lumpur, Malaysia, 23–24 July 2018; pp. 525–537. [Google Scholar] [CrossRef]
- Li, L.; Qian, J.; Pan, J.-S. Characteristic region based watermark embedding with RST invariance and high capacity. AEU—Int. J. Electron. Commun. 2011, 65, 435–442. [Google Scholar] [CrossRef]
- Naharuddin, A.; Wibawa, A.D.; Sumpeno, S. A high capacity and imperceptible text steganography using binary digit mapping on ASCII characters. In Proceedings of the 2018 International Seminar on Intelligent Technology and Its Applications (ISITIA), Bali, Indonesia, 30–31 August 2018; pp. 287–292. [Google Scholar] [CrossRef]
- Malik, A.; Sikka, G.; Verma, H.K. A high capacity text steganography scheme based on LZW compression and color coding. Eng. Sci. Technol. Int. J. 2017, 20, 72–79. [Google Scholar] [CrossRef] [Green Version]
- Sadié, J.K.; Metcheka, L.M.; Ndoundam, R. A high capacity text steganography scheme based on permutation and color coding. arXiv 2020, arXiv:2004.00948. [Google Scholar]
- Al-Azzawi, A.F. A multi-layer arabic text steganographic method based on letter shaping. Int. J. Netw. Secur. Its Appl. (IJNSA) 2019, 11. Available online: https://ssrn.com/abstract=3759471 (accessed on 29 September 2021).
- Liang, O.W.; Iranmanesh, V. Information hiding using whitespace technique in Microsoft word. In Proceedings of the 2016 22nd International Conference on Virtual System & Multimedia (VSMM), Kuala Lumpur, Malaysia, 17–21 October 2016; pp. 1–5. [Google Scholar]
- Baawi, S.S.; Nasrawi, D.A. Improvement of “text steganography based on unicode of characters in multi-lingual” by custom font with special properties. In Proceedings of the IOP Conference Series: Materials Science and Engineering, Jonkoping, Sweden, 22–23 June 2020; Volume 870, p. 012125. [Google Scholar]
- Shah, S.T.A.; Khan, A.; Hussain, A. Text steganography using character spacing after normalization. Int. J. Sci. Eng. Res. 2020, 11, 949–957. [Google Scholar] [CrossRef]
- Taha, A.; Hammad, A.S.; Selim, M.M. A high capacity algorithm for information hiding in Arabic text. J. King Saud Univ. Comput. Inf. Sci. 2018, 32, 658–665. [Google Scholar] [CrossRef]
- Alanazi, N.; Khan, E.; Gutub, A. Inclusion of unicode standard seamless characters to expand arabic text steganography for secure individual uses. J. King Saud Univ. Comput. Inf. Sci. 2020. In press. [Google Scholar] [CrossRef]
- Al-Nofaie, S.; Gutub, A.; Al-Ghamdi, M. Enhancing Arabic text steganography for personal usage utilizing pseudo-spaces. J. King Saud Univ.-Comput. Inf. Sci. 2019, 33, 963–974. [Google Scholar] [CrossRef]
- Gutub, A.A.-A.; Alaseri, K.A. Refining Arabic text stego-techniques for shares memorization of counting-based secret sharing. J. King Saud Univ.-Comput. Inf. Sci. 2019. [Google Scholar] [CrossRef]
- Ditta, A.; Yongquan, C.; Azeem, M.; Rana, K.G.; Yu, H.; Memon, M.Q. Information hiding: Arabic text steganography by using Unicode characters to hide secret data. Int. J. Electron. Secur. Digit. Forensics 2018, 10, 61–78. [Google Scholar] [CrossRef]
- Ahvanooey, M.T.; Li, Q.; Hou, J.; Mazraeh, H.D.; Zhang, J. AITSteg: An innovative text steganography technique for hidden transmission of text message via social media. IEEE Access 2018, 6, 65981–65995. [Google Scholar] [CrossRef]
- Chaudhary, S.; Dave, M.; Sanghi, A. Aggrandize text security and hiding data through text steganography. In Proceedings of the 2016 IEEE 7th Power India International Conference (PIICON), Bikaner, India, 25–27 November 2016; pp. 1–5. [Google Scholar]
- Khosravi, B.; Khosravi, B.; Khosravi, B.; Nazarkardeh, K. A new method for pdf steganography in justified texts. J. Inf. Secur. Appl. 2019, 45, 61–70. [Google Scholar] [CrossRef]
- Kumar, R.; Malik, A.; Singh, S.; Kumar, B.; Chand, S. A space based reversible high capacity text steganography scheme using font type and style. In Proceedings of the 2016 International Conference on Computing, Communication and Automation (ICCCA), Greater Noida, India, 29–30 April 2016; pp. 1090–1094. [Google Scholar] [CrossRef]
- Ekodeck, S.G.R.; Ndoundam, R. PDF steganography based on Chinese Remainder Theorem. J. Inf. Secur. Appl. 2016, 29, 1–15. [Google Scholar] [CrossRef] [Green Version]
- Li, Y.; Zhang, J.; Yang, Z.; Zhang, R. Topic-aware neural linguistic steganography based on knowledge graphs. ACM/IMS Trans. Data Sci. 2021, 2, 1–13. [Google Scholar] [CrossRef]
- Yang, Z.; Xiang, L.; Zhang, S.; Sun, X.; Huang, Y. Linguistic generative steganography with enhanced cognitive-imperceptibility. IEEE Signal. Process. Lett. 2021, 28, 409–413. [Google Scholar] [CrossRef]
- Zhou, X.; Peng, W.; Yang, B.; Wen, J.; Xue, Y.; Zhong, P. Linguistic steganography based on adaptive probability distribution. IEEE Trans. Dependable Secur. Comput. 2021. [Google Scholar] [CrossRef]
- Zhang, S.; Yang, Z.; Yang, J.; Huang, Y. Provably secure generative linguistic steganography. arXiv 2021, arXiv:2106.02011. [Google Scholar]
- Yang, Z.-L.; Zhang, S.-Y.; Hu, Y.-T.; Hu, Z.-W.; Huang, Y.-F. VAE-Stega: Linguistic steganography based on variational auto-encoder. IEEE Trans. Inf. Forensics Secur. 2020, 16, 880–895. [Google Scholar] [CrossRef]
- Kang, H.; Wu, H.; Zhang, X. Generative text steganography based on LSTM network and attention mechanism with keywords. Electron. Imaging 2020, 2020, 291. [Google Scholar] [CrossRef]
- Yang, Z.-L.; Guo, X.; Chen, Z.-M.; Huang, Y.-F.; Zhang, Y.-J. RNN-Stega: Linguistic steganography based on recurrent neural networks. IEEE Trans. Inf. Forensics Secur. 2018, 14, 1280–1295. [Google Scholar] [CrossRef]
- Mahato, S.; Khan, D.A.; Yadav, D.K. A modified approach to data hiding in Microsoft Word documents by change-tracking technique. J. King Saud Univ.-Comput. Inf. Sci. 2020, 32, 216–224. [Google Scholar] [CrossRef]
- Yang, R.; Ling, Z.H. Linguistic Steganography by Sampling-based Language Generation. In Proceedings of the 2019 Asia-Pacific Signal and Information Processing Association Annual Summit and Conference (APSIPA ASC), Lanzhou, China, 18–21 November 2019; pp. 1014–1019. [Google Scholar]
- Chaw, A.A. Text steganography in Letter of Credit (LC) using synonym substitution based algorithm. Int. J. Adv. Res. Dev. 2019, 4, 59–63. [Google Scholar]
- Hamzah, A.A.; Khattab, S.; Bayomi, H. A linguistic steganography framework using Arabic calligraphy. J. King Saud Univ.-Comput. Inf. Sci. 2021, 33, 865–877. [Google Scholar] [CrossRef]
- Majumder, A.; Changder, S. A generalized model of text steganography by summary generation using frequency analysis. In Proceedings of the 7th International Conference on Reliability, Infocom Technologies and Optimization (Trends and Future Directions) (ICRITO), Noida, India, 29–31 August 2018; pp. 599–605. [Google Scholar] [CrossRef]
- Xiang, L.; Wu, W.; Li, X.; Yang, C. A linguistic steganography based on word indexing compression and candidate selection. Multimed. Tools Appl. 2018, 77, 28969–28989. [Google Scholar] [CrossRef]
- Naqvi, N.; Abbasi, A.T.; Hussain, R.; Khan, M.A.; Ahmad, B. Multilayer partially homomorphic encryption text steganography (Mlphe-ts): A zero-steganography approach. Wirel. Pers. Commun. 2018, 103, 1563–1585. [Google Scholar] [CrossRef]
- Liu, Y.; Wu, J.; Xin, G. Multi-keywords carrier-free text steganography based on part of speech tagging. In Proceedings of the 13th International Conference on Natural Computation, Fuzzy Systems and Knowledge Discovery (ICNC-FSKD), Guilin, China, 29–31 July 2017; pp. 2102–2107. [Google Scholar] [CrossRef]
- Wu, N.; Yang, Z.; Yang, Y.; Li, L.; Shang, P.; Ma, W.; Liu, Z. STBS-Stega: Coverless text steganography based on state transition-binary sequence. Int. J. Distrib. Sens. Netw. 2020, 16. [Google Scholar] [CrossRef] [Green Version]
- Alghamdi, N.; Berriche, L. Capacity investigation of Markov chain-based statistical text steganography: Arabic language case. In Proceedings of the 2019 Asia Pacific Information Technology Conference, Jeju Island, Korea, 25–27 January 2019; pp. 37–43. [Google Scholar]
- Wu, N.; Shang, P.; Fan, J.; Yang, Z.; Ma, W.; Liu, Z. Coverless Text Steganography Based on Maximum Variable Bit Embedding Rules. J. Phys. Conf. Ser. 2019, 1237, 022078. [Google Scholar] [CrossRef] [Green Version]
- Wu, N.; Shang, P.; Fan, J.; Yang, Z.; Ma, W.; Liu, Z. Research on coverless text steganography based on single bit rules. J. Physics Conf. Ser. 2019, 1237. [Google Scholar] [CrossRef]
- Yang, Z.; Jin, S.; Huang, Y.; Zhang, Y.; Li, H. Automatically generate steganographic text based on Markov model and Huffman coding. arXiv 2018, arXiv:1811.04720. [Google Scholar]
- Huanhuan, H.; Xin, Z.; Weiming, Z.; Nenghai, Y. Adaptive text steganography by exploring statistical and linguistical distortion. In Proceedings of the 2017 IEEE Second International Conference on Data Science in Cyberspace (DSC), Shenzhen, China, 26–29 June 2017; pp. 145–150. [Google Scholar]
- Jayapandiyan, J.R.; Kavitha, C.; Sakthivel, K. Enhanced least significant bit replacement algorithm in spatial domain of steganography using character sequence optimization. IEEE Access 2020, 8, 136537–136545. [Google Scholar] [CrossRef]
- Wang, K.; Gao, Q. A Coverless plain text steganography based on character features. IEEE Access 2019, 7, 95665–95676. [Google Scholar] [CrossRef]
- Wu, N.; Ma, W.; Liu, Z.; Shang, P.; Yang, Z.; Fan, J. Coverless Text Steganography Based on Half Frequency Crossover Rule. In Proceedings of the 2019 4th International Conference on Mechanical, Control and Computer Engineering (ICMCCE), Hohhot, China, 5–27 October 2019; pp. 726–7263. [Google Scholar] [CrossRef]
- Wu, N.; Liu, Z.; Ma, W.; Shang, P.; Yang, Z.; Fan, J. Research on coverless text steganography based on multi-rule language models alternation. In Proceedings of the 2019 4th International Conference on Mechanical, Control and Computer Engineering (ICMCCE), Hohhot, China, 5–27 October 2019; pp. 803–8033. [Google Scholar] [CrossRef]
- Maji, G.; Mandal, S. A forward email based high capacity text steganography technique using a randomized and indexed word dictionary. Multimedia Tools Appl. 2020, 79, 26549–26569. [Google Scholar] [CrossRef]
- Fateh, M.; Rezvani, M. An email-based high capacity text steganography using repeating characters. Int. J. Comput. Appl. 2021, 43, 226–232. [Google Scholar] [CrossRef]
- Alanazi, N.; Khan, E.; Gutub, A. Efficient security and capacity techniques for Arabic text steganography via engaging Unicode standard encoding. Multimed. Tools Appl. 2020, 80, 1403–1431. [Google Scholar]
- Bhat, D.; Krithi, V.; Manjunath, K.N.; Prabhu, S.; Renuka, A. Information hiding through dynamic text steganography and cryptography. Comput. Inform. 2017, 1826–1831. [Google Scholar] [CrossRef]
- Kumar, R.; Malik, A.; Singh, S.; Chand, S. A high capacity email based text steganography scheme using huffman compression. In Proceedings of the 2016 3rd International Conference on Signal Processing and Integrated Networks (SPIN), Noida, India, 11–12 February 2016; pp. 53–56. [Google Scholar]
- Khairullah, M. A novel steganography method using transliteration of Bengali text. J. King Saud Univ.-Comput. Inf. Sci. 2019, 31, 348–366. [Google Scholar] [CrossRef]
- Shanthi, S.; Kannan, R.; Santhi, S. Efficient secure system of data in cloud using steganography based cryptosystem with FSN. Mater. Today Proc. 2018, 5, 1967–1973. [Google Scholar] [CrossRef]
- Shi, S.; Qi, Y.; Huang, Y. An Approach to Text Steganography Based on Search in Internet. In Proceedings of the 2016 International Computer Symposium (ICS), Chiayi, Taiwan, 15–17 December 2016; pp. 227–232. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
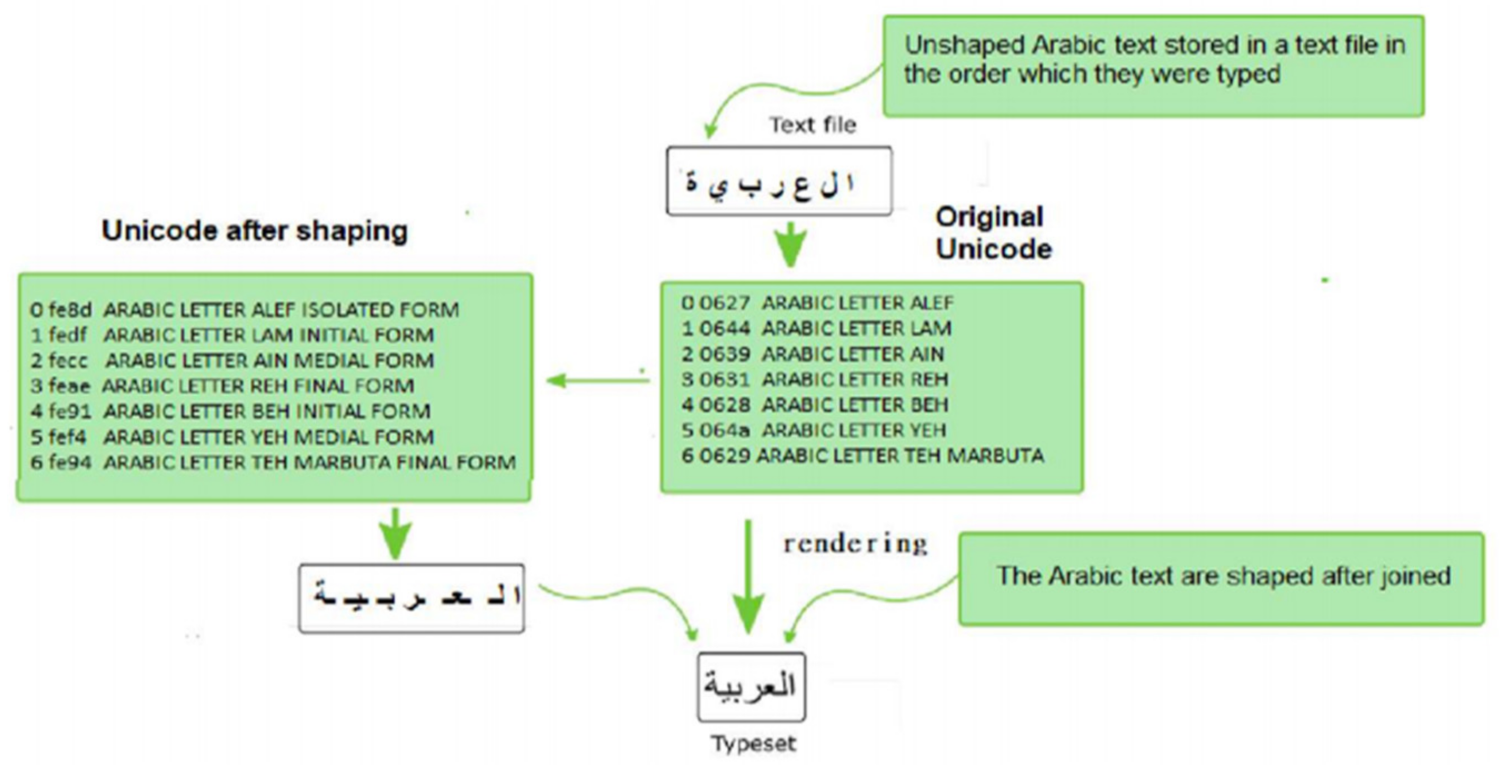{kind=link}
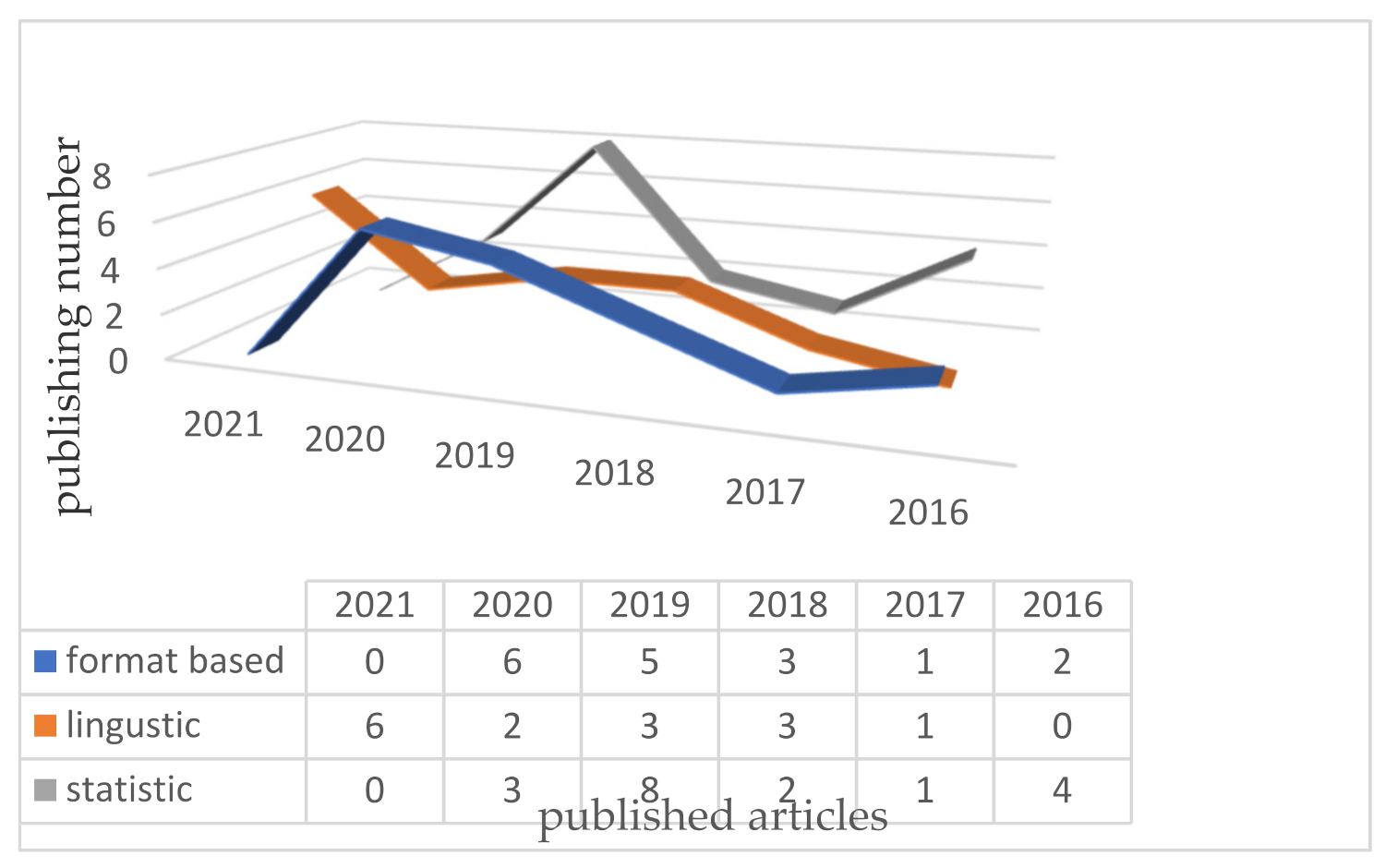{kind=link}
| Characteristics | Steganography | Watermarking | Cryptography |
|---|---|---|---|
| Goal | Protects secret data from discover | Protects legitimacy of the media | disorganizes the content of data |
| Cover Choosing | free cover choice | Limit | Not use |
| Challenges | Imperceptibility, security, and Capacity | Robustness | Robustness |
| Keyes | Possible | Possible | Necessary |
| Output | Stego-media | Watermarked-media | Encryption-text |
| Visibility | Definitely not | Occasionally | Constantly |
| The system is invalid if | Noticed | Detached or substituted | Decryption |
| Attacks | Steganalysis | image processing | Cryptanalysis |
| Letters | ASCII Code | Unicode | ||
|---|---|---|---|---|
| S = 00 | S = 01 | S = 10 | S = 11 | |
| e | 0065 | 0023 | 0026 | 002A |
| t | 0074 | 003C | 003D | 003E |
| a | 0061 | 005B | 005D | 005E |
| o | 006F | 007B | 007C | 007D |
| Title Name | Category | Technique Description | Year | Improvement | |
|---|---|---|---|---|---|
| 1 | Aitsteg: an innovative text steganography technique for hidden transmission of a text message via social media [52] | Format based | Innovative text steganography using the ZWC algorithm. | 2020 | Capacity |
| 2 | Improvement of “text steganography based on Unicode of characters in multilingual” by custom font with special properties [45] | Format based | Replaces the code of English symbols with other code that has the same glyph. Two bits are hidden at once based on the set of high-frequency letters SHFL in lower case letters. | 2020 | Capacity |
| 3 | Text steganography using character spacing after normalization [46] | Format based | Uses frequency modulation techniques, font attributes, and character spacing to embed secret data. | 2020 | Capacity |
| 4 | Two high-capacity text steganography schemes based on color coding [42] | Format based | Embeds the secret message in the cover text using colored based permutation and numeration systems. | 2020 | Capacity |
| 5 | A high-capacity algorithm for information hiding in Arabic text [47] | Format based | Unicode Arabic extension character Kashida with three small space characters: thin space, hair space, and six-PRE-EM space and use of Kashida and to use small space characters instead of the normal space character to hide the secret message. | 2020 | Capacity |
| 6 | Inclusion of Unicode standard seamless characters to expand Arabic text Steganography for secure individual uses [48] | Format based | Unicode standard seamless characters within Arabic text for secure individual uses, Unicode of whitespaces that are visible and invisible extra characters (such as Kashida, ZWJS, and (ZWNJS) are also used to hide secret bits. | 2020 | Capacity |
| 7 | Aggrandize text security and hiding data through text steganography [53] | Format based | Hides the secret message according to the shape of capital alphabets letters. | 2019 | Capacity |
| 8 | A multi-layer Arabic text steganographic method based on letter shaping [43] | Format based | Uses Unicode to hide a bit in each letter by reshaping the letters according to its position of the word or standalone. The hiding process is undertaken using a multi-embedding layer, where each layer contains all words with the same tag identified using the part of speech (POS) tagger. | 2019 | Capacity |
| 9 | A new method for pdf steganography in justified texts [54] | Format based | Justified text in a pdf file, by compressing the secret message using Huffman coding, then choosing special lines from the cover as host lines and replacing the added spaces with the normal spaces of the host lines. | 2019 | Capacity |
| 10 | Enhancing Arabic text steganography for personal usage utilizing Pseudo-spaces [49] | Format based | Uses two methods of pseudo-spaces alone and combines them with Unicode to maximize the use of spaces. | 2019 | Capacity |
| 11 | Refining Arabic text stego-techniques for shares memorization of Counting-based secret sharing [50] | Format based | Combines the counting-based secret sharing with steganography for personal remembrance using Kashida steganography. | 2019 | Capacity |
| 12 | A high capacity and imperceptible text steganography using binary digit mapping on ASCII characters [40] | Format based | Maps secret message binary digit onto binary digit of cover text using ASCII characters, involving spaces, punctuation, and symbols. | 2018 | Capacity |
| 13 | Information hiding Arabic text steganography by using Unicode characters to hide secret data [51] | Format based | Uses a combination of Unicode character’s zero-width-character and zero-width-joiner in the Arabic language. | 2018 | Capacity |
| 14 | An efficient, secure system of data in the cloud using steganography-based Cryptosystem with FSN [88] | Format based | Combines both steganography and cryptography, and aggregate decryption key (ADK) to generate the master-secret key, where it is used to share data to other users by transferring its ADK to those who are interested in accessing the contents through e-mail by the data owner. | 2018 | Security |
| 15 | A high-capacity text steganography scheme based on LZW compression and color coding [41] | Format based | Employs the LZW compression technique and color coding-based approach. The technique uses the forward mail platform to hide secret data. | 2017 | Security |
| 16 | A space-based reversible high-capacity text steganography scheme using font type and style [55] | Format based | Hides the secret data bits into the white spaces in MS word documents. | 2016 | Capacity |
| 17 | Information hiding using whitespace technique in Microsoft word [44] | Format based | Uses five whitespaces within a line to represent each character for embedding secret data, which is randomized based on a key in MS word. | 2016 | Capacity |
| 18 | Topic-aware Neural Linguistic Steganography Based on Knowledge Graphs [57] | Linguistic | Neural linguistic steganography generates a steganographic paragraph with a specific topic based on knowledge graphs. | 2021 | Security |
| 19 | Linguistic Generative Steganography with Enhanced Cognitive-Imperceptibility [58] | Linguistic | Uses categorical sampling to construct the candidate pool that samples the words according to the overall conditional probability distribution, to construct candidate pools in steganographic text generated by a neural network. | 2021 | Security |
| 20 | Linguistic Steganography Based on Adaptive Probability Distribution [59] | Linguistic | Automatically generated stego text based on adaptive probability distribution and generative adversarial network. | 2021 | Security |
| 21 | Provably Secure Generative Linguistic Steganography [60] | Linguistic | Improved embedded data imperceptibility by groups the tokens adaptively according to their possibility at each time step to embed secret information dynamically in stego text generated by a neural network. | 2021 | Security |
| 22 | VAE-Stega: Linguistic Steganography Based on Variational Auto-Encoder [61] | Linguistic | Automatically generate the stego text based on Variational Auto-Encoder (VAE-Stega) that learns the statistical distribution features of a huge number of regular texts to generate steganographic sentences. | Security | |
| 23 | Generative Text Steganography Based on LSTM Network and Attention Mechanism with Keywords [62]. | Linguistic | Generative text steganographic method based on long short-term memory (LSTM) network and uses a mechanism based on a large-scale regular text database to construct a language model. | Security | |
| 24 | RNN-Stega: linguistic steganography based on recurrent neural networks [63] | Linguistic | Automatically generated text covers secret bitstream based on recurrent neural networks (RNN). | 2020 | Capacity |
| 25 | A modified approach to data hiding in Microsoft word documents by Change-tracking technique [64] | Linguistic | Synonym substitution by redesigning the change tracking technique for hiding the secret message in Microsoft word document with Huffman’s codes. | 2020 | Capacity |
| 26 | Linguistic steganography by sampling-based Language generation [65] | Linguistic | Utilizes sampling-based language generation to improve the hiding rate. The arithmetic coding (AC) algorithm is adopted to embed messages in the cover text. Its performance is compared with fixed-length coding (FLC) and variable-length coding (VLC), which were designed for embedding messages during deterministic text generation. | 2019 | Capacity |
| 27 | Text steganography in the letter of credit (lc) using synonym Substitution based algorithm [66] | Linguistic | Replaces words with their synonyms to solve security risks in a letter of credit (LC) used in banking. LC information is sent online. | 2019 | Capacity |
| 28 | A linguistic steganography framework using Arabic calligraphy [67]. | Linguistic | Uses Arabic calligraphy to hide information using Arabic poetry and proverbs as datasets with one shape of Arabic letters (Naskh font) and a modified Aho–Corasick algorithm (ac*). | 2019 | Capacity |
| 29 | A generalized model of text steganography by summary generation using frequency analysis [68] | Linguistic | Check for common letter pairs or double letter pairs in keywords in the paragraphs to find sentences that generate a possible summary as a cover text. | 2018 | Capacity |
| 30 | Linguistic steganography based on word indexing compression and candidate selection [69] | Linguistic | Establishes word indexing compression algorithm (WIC) that can reduce the length of the practical embedded payload. The best stego text with high undetectability is selected from candidates using selection strategy and compressed the secret message by combining a minimum-maximum weight algorithm with Huffman coding. | 2018 | Capacity |
| 31 | Multilayer partially homomorphic encryption text steganography (Mlphe-ts): a zero-steganography approach [70] | Linguistic | Replaces a character of the secret message with a character of the cover message that converts the multi-variate secret message into alphabets through the alphabetic transformation process that resolves the problem of cover message selection. | 2018 | Capacity |
| 32 | Multi-keywords carrier-free text steganography based on the part of speech tagging [71] | Linguistic | Multi-keywords carrier-free text steganography based on the part of speech tagging. The hidden tags are selected from Chinese character components of words. | 2017 | Capacity |
| 33 | Stbs-Stega: coverless text steganography based on state transition-binary sequence [72] | Random and Statistical | Focuses on transition probability based on the Markov chain model, to create a state transition-binary sequence diagrams based on the concepts and used them to guide the generation of new texts with embedded secret information. | 2020 | Capacity |
| 34 | Enhanced least significant bit replacement algorithm in the spatial domain of steganography using character sequence optimization [78] | Random and statistical | Maps character sequences of ASCII values and their equivalent binary value while hiding secret data. | 2020 | Capacity |
| 35 | A forward email-based high-capacity text steganography technique using a randomized and indexed word dictionary [82] | Random and statistical | Uses a list of email addresses and forward email platform as a cover to increase the hiding capacity. Email addresses in the carbon copy (cc) field contain secret data that are encoded using a randomized index-based word dictionary. | 2020 | Capacity |
| 36 | Novel approaches to text steganography [84] | Random and statistical | Uses RSA algorithm to encrypt user data by generating subtle imperfections in the appearance of the characters included in the memo using both the public and private keys, thus making it robust to cyber-attacks and security breaches. | 2019 | Security |
| 37 | Coverless plain text steganography based on character features [79] | Random and statistical | Coverless steganography based on parity of Chinese characters’ stroke. | 2019 | Capacity |
| 38 | Coverless text steganography based on half frequency crossover rule [80] | Random and statistical | Coverless using Markov model and the half frequency crossover rule, which accords with the statistical characteristics of natural language. | 2019 | Capacity |
| 39 | Research on coverless text steganography based on multi-rule language models alternation [81] | Random and statistical | Coverless based on multi-rule language models that combines models under different language rules alternately and tries to extract more language features from the training text. | 2019 | Capacity |
| 40 | Capacity investigation of Markov chain-based statistical text steganography: Arabic language case [73] | Random and statistical | Implements a Markov chain combined with Huffman coding for Arabic text and computed an upper bound and a lower bound for the stego-text length that depends on the designed encoder/decoder parameters. | 2019 | Capacity |
| 41 | Coverless text steganography based on maximum variable Bit embedding rules [74] | Random and statistical | Uses the maximum variable bit embedding instead of the usual fixed bit embedding by the Markov chain model to generate steganographic text closer to the existing text, according to the characteristic and value of transition probability in the model. | 2019 | Capacity |
| 42 | Research on coverless text steganography based on single bit rules [75] | Random and statistical | Uses the single variable bit embedding instead of the usually fixed bit embedding by the Markov chain model to generate steganographic text closer to the existing text according to the model’s character and value of transition probability. | 2019 | Capacity |
| 43 | A novel steganography method using transliteration of Bengali text [87] | Random and statistic | Transliteration in the Bengali language by exploiting the special feature of Bengali phonetic keyboard layouts to hide secret information in the form of bits. | 2019 | Capacity |
| 44 | Email-based high-capacity text steganography using repeating characters [83] | Random and statistical | Uses email in which the secret message is hidden within several email addresses generated through the body of the email and use one of the lossless compression algorithms named Lempel-Ziv-Welch (LZW) to compress the secret message. | 2018 | Capacity |
| 45 | Automatically generate steganographic text based on Markov model and Huffman coding [76] | Random and statistical | Automatically generates confident text carrier in terms of secret information which need to be embedded based on the Markov chain model and Huffman coding that can learn from many samples written by people and obtain a good estimation of the statistical language model. | 2018 | Capacity |
| 46 | Adaptive text steganography by exploring statistical and linguistical distortion [77] | Random and statistical | Minimizes the cost caused by synonym substitution, which affects the cover texts’ statistical features, and minimize the distortion of synonym substitution. | 2017 | Capacity |
| 47 | Information hiding through dynamic text steganography and cryptography [85] | Random and statistical | Combination of steganography and cryptography using Data Encryption Standard (DES) to change the position of the hiding bit depending on the frequency of letters in the cover text. | 2016 | Security |
| 48 | A high-capacity email-based text steganography scheme using Huffman compression [86] | Random and statistical | Hides the secret data into the email IDs of a forward mail platform by Huffman compression, which is reversible in nature. | 2016 | Capacity |
| 49 | An approach to text steganography based on search on the internet [89] | Random and statistical | Analyzes the features of webpages on the internet. A search-based text steganography with a hypothesis that features of huge amount of data on the internet can create secret messages. | 2016 | Capacity |
| 50 | Pdf steganography based on Chinese Remainder theorem [56] | Random and statistical | Increases the amount of information that can be hidden in a cover pdf file based on the Chinese remainder theorem. While reducing the number of a 0’s insertions considerably in between-character locations in that file, thus reducing the weight difference between a cover file and a stego file in which a secret message is embedded. | 2016 | Capacity |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Majeed, M.A.; Sulaiman, R.; Shukur, Z.; Hasan, M.K. A Review on Text Steganography Techniques. Mathematics 2021, 9, 2829. https://doi.org/10.3390/math9212829
Majeed MA, Sulaiman R, Shukur Z, Hasan MK. A Review on Text Steganography Techniques. Mathematics. 2021; 9(21):2829. https://doi.org/10.3390/math9212829
Chicago/Turabian StyleMajeed, Mohammed Abdul, Rossilawati Sulaiman, Zarina Shukur, and Mohammad Kamrul Hasan. 2021. "A Review on Text Steganography Techniques" Mathematics 9, no. 21: 2829. https://doi.org/10.3390/math9212829
APA StyleMajeed, M. A., Sulaiman, R., Shukur, Z., & Hasan, M. K. (2021). A Review on Text Steganography Techniques. Mathematics, 9(21), 2829. https://doi.org/10.3390/math9212829