1. Introduction
Credit risk is generally understood as the potential that a borrower or counterparty will fail to meet its contractual obligations. Banks need to estimate the probability of such events occurring and set aside capital to absorb contingent losses. Loan loss provision estimates are constantly updated based on the bank’s potential customer defaults. These estimates are usually calculated based on a probability of default (PD) model, as applied to historical default data. Credit risk evaluation is crucial not only for internal credit decisions but also for regulatory purposes (BCBS [
1,
2]). In July 2014, the International Accounting Standards Board (IASB) issued the final version of the International Financial Reporting Standard 9 (IFRS 9)—Financial Instruments. The IFRS 9 introduced an expected credit loss (ECL) framework concerning how banks should recognize and manage potential credit losses for financial statement–reporting purposes. IFRS 9 defines principles but grants freedom in choosing which models and approaches banks use to estimate their potential losses. These estimates are then used to determine how much capital is to be set aside as buffers against loss. This ECL practice is aligned with internal ratings–based regulatory practices for determining financial institutions’ regulatory capital requirements in Basel III.
Effective from 1 January 2018, the IFRS 9 mandates for the measurement of impairment loss allowances to be based on a forward-looking ECL accounting model rather than on an incurred loss accounting model. The ECL model, which incorporates current and predicted macroeconomic factors, such as expectations in changes in the GDP growth rate, is designed to yield more accurate predictions of credit losses. As a standard of financial reporting purposes, however, the ECL model can result in volatile credit loss estimation following unexpected events, such as the COVID-19 pandemic.
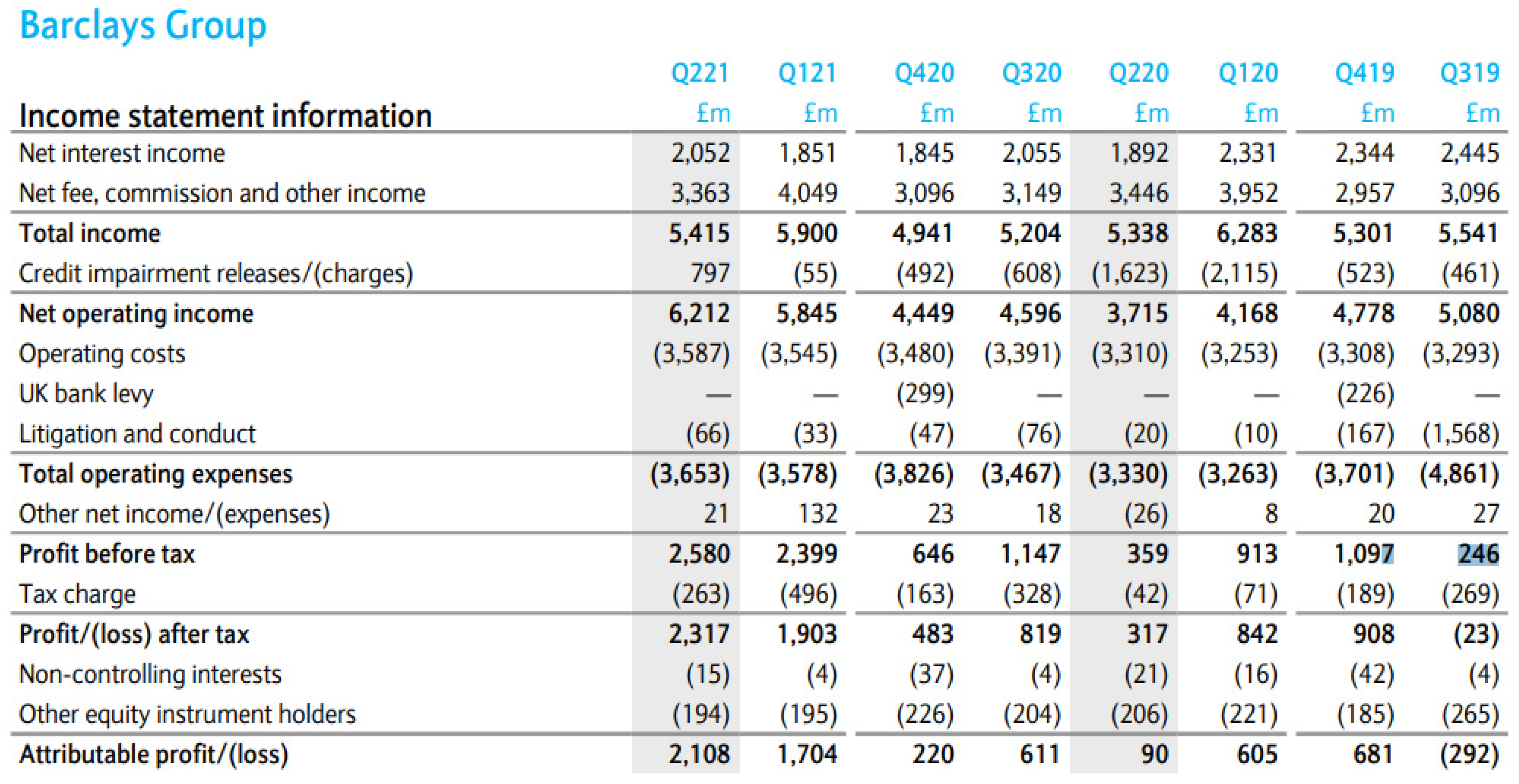
The income information statement from the Barclays Group 2nd Quarter Financial Report provides an example of this (
Figure 1). It stated that a total of £1097 million in profit in Q419 decreased to £359 million in Q220. Conversely, the credit impairment charge increased more than fourfold, from £523 million, in Q419, to £2115 million, in Q120. In Q220, it remained substantially higher than that at Q419, at £1623 million. After Q220, the amount accrued decreased back to £608 million in Q320 and £492 million in Q420. Moreover, due to the economic recovery from the COVID-19 pandemic, £797 million of credit impairment was released in Q221 and the single-quarter profit thus increased to £2580 million. The point-in-time characteristics of forward-looking ECL estimation resulted in great volatility in the bank’s profit data.
Barclays’ credit cost percentage, which is defined as the credit impairment cost divided by total income, is illustrated in
Figure 2. Between Q319 and Q221, the credit cost percentage changed considerably, with a high of 34% (
2115/6283), in Q120, and a low of −15% (
−797/5415), in Q221. The ECL method was designed to improve the accuracy of credit cost predictions. However, when one considers the accounting principle of matching cost with revenue, excessive change in the credit cost percentage can confound inter-period analysis and confuse investors.
Motivated by observing the fluctuated credit impairment estimation and credit cost percentage exhibited in
Figure 1 and
Figure 2, the main aim of this paper is to explore the robustness of the PD model with a GDP determinant. ECL is generally calculated as the PD-weighted average of credit losses, specifically ECL = PD × (exposure at default) × (loss given default). A key factor generally adopted in a PD model is GDP growth. However, this approach may lead to dramatic changes in accounting or financial profit and loss and, thus, result in excessive fluctuations in ECL estimates. As noted, this phenomenon was especially evident during the COVID-19 pandemic in 2020. In this paper, we also explore the usage of a credit default swap index (CDX) determinant in a PD model in place of a GDP determinant to reach a less volatile credit loss estimation. The remainder of this paper is structured as follows:
Section 2 reviews the literature on the PD model.
Section 3 describes the empirical results of PD models with versus without the COVID-19 data.
Section 4 concludes the paper.
2. Literature Review
The Basel III framework and the IFRS 9 were introduced following the financial crisis and European debt crisis. Basel III regulates bank capital, whereas IFRS 9 specifies how banks should classify their assets and estimate their future credit losses. Under IFRS 9, as a part of lifetime ECL calculations for stage 2 credit assets, banks must estimate multiperiod lifetime PDs. Under the Basel accord, PDs are commonly estimated as through-the-cycle to neutralize economic fluctuations and achieve lower volatility in credit risk capital requirements. Conversely, under the IFRS 9, PD estimates should be point-in-time and include forward-looking information, especially for macroeconomic forecasts [
4,
5]. The COVID-19 pandemic is the first stressful economic scenario since the implementation of IFRS 9 in 2018. In this study, we focus on the effect of COVID-19 on the robustness of PD estimation.
2.1. Logistic Regression PD Model
PDs are of interest to practitioners in financial institutions, as well as to regulators. Logistic regression has been widely adopted for PD models because of its simplicity and amenability to intuition and explanation (Crook et al. [
6]). For example, one of the most popular credit risk models is the credit portfolio view model, which is analyzed using logistic regression and contains macroeconomic factors, such as the GDP, as the systematic explanatory variables.
Logistic regression is a common classification method when the response variable is binary, such as whether a default or nondefault occurs. A sound logistic regression model should feature high interpretability, high predictive power, and robustness to data outliers and default sparsity. Given a binary response variable
L and a set of covariates
x, the basic setup of the logistic regression model is as follows: Conditional on
x, the response variable
L is assumed to be Bernoulli distributed; that is,
Bernoulli (
) for some
. The goal of logistic regression is to fit a predictive model for the binary response variable. Let the random variable
be defined as:
and the PD for a rating class in the same year is assumed to be constant. The observation of
credit exposures can be written as
In the case of binomial data, the random variables
are assumed to be independent and
, the number of defaults observed, is defined as:
As
are
independent and identically distributed trials, it can be inferred that, conditional on
,
follows the binomial distribution
where
is the number of years in the default data set. By utilizing the logit relationship
in terms of the logistic density function, the conditional probability of default number at year
is
The likelihood function, assuming that all the observations
are independent and binomially distributed, is defined as
and the log-likelihood function that is defined as
is maximized using various optimization techniques, such as the gradient descent method. Furthermore, the associated Akaike information criterion (AIC) is defined as
where
is the number of model parameters and
is the maximum value of the log-likelihood function in Equation (2). As the equation expresses a property of the penalty (negative) function, a smaller AIC value suggests a better fit.
2.2. PD Model with a GDP Determinant
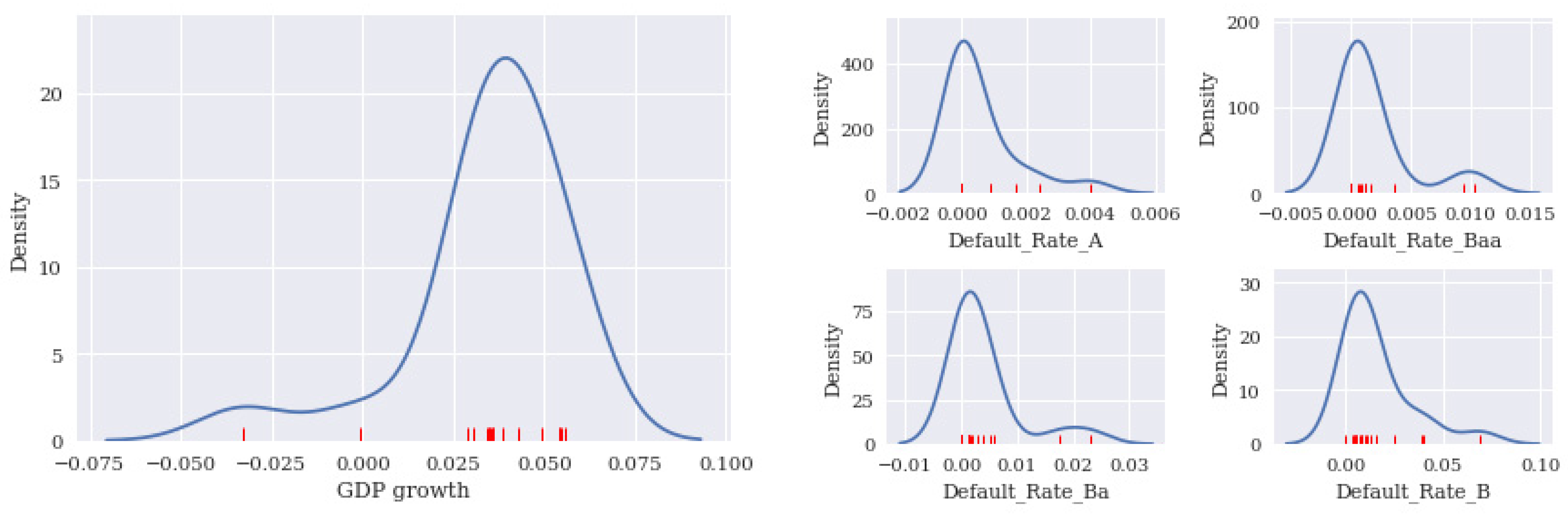
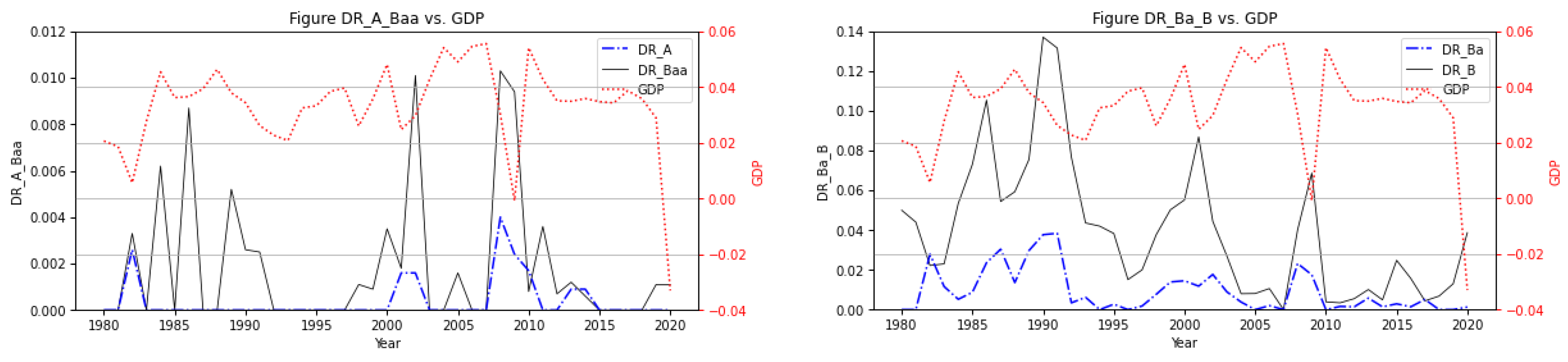
This study primarily aimed to explore the robustness of a PD model with a GDP covariate versus that of a PD model with a CDX covariate. Estimating PDs is challenging due to the limited availability of data and the sparsity of defaults. We explored the logit model with GDP growth as a macroeconomic parameter. The relationship between PD and various macroeconomic variables has been modeled in many applications. Most of the papers discussed in this subsection have demonstrated that GDP growth is significantly related to the default rate (DR).
For the banking sector, Jabra [
7] used a binomial logit model and demonstrated how much bank default in the European banking system can be explained, not only by CAMELS (capital adequacy, asset quality, management quality, earnings potential, liquidity, and sensitivity to market risk) variables, but also by GDP growth. Bonjini et al. [
8] discovered that bank defaults in developing countries increase with the severity of macroeconomic shocks. Arena [
9] and Männasoo and Mayes [
10] demonstrated that increased GDP growth (as a macroeconomic indicator) significantly reduced bank PD. Ortolano and Angelini [
11] noted that the highest correlation between PD and various adopted GDP covariates was −24%. The negative value corroborated the finding of a relationship between GDP and banking credit risk assessment reported by Jabra, Mighri, and Mansouri [
12].
With regard to the corporate sector, Simons and Rolwes [
13] provided robust evidence for a relationship between macroeconomic variables and GDP growth in the default behavior of Dutch firms. This observation led to the implementation of econometric models that describe PD in terms of macroeconomic variables. Couderc and Renault [
14] demonstrated that GDP growth is a significant macroDR of firms listed in the Standard and Poor’s 500 index and Jakubik [
15] demonstrated the same for Finnish firms in 1988–2003 in addition to reporting that interest rate was a nonsignificant macroeconomic variable. By studying the relationship between the credit cycle and macroeconomic variables using data on the rating changes and defaults of US corporations, Koopman et al. [
16] demonstrated that many of the variables that were conventionally thought to explain the credit cycle were nonsignificant, with the exception of GDP growth. Virolainen [
17] used Finnish data and reported a significant relationship between corporate sector DR and several macroeconomic factors, including GDP. Using data on nonfinancial corporate bond DRs over 150 years, Giesecke et al. [
18] studied the relationship between credit default and macroeconomic variables and determined that change in GDP is a strong predictor of DR. Penikas [
19] reported that default correlation tends to align with systemic factors, such as the GDP growth rate.
2.3. Robustness of a Model
Anscombe [
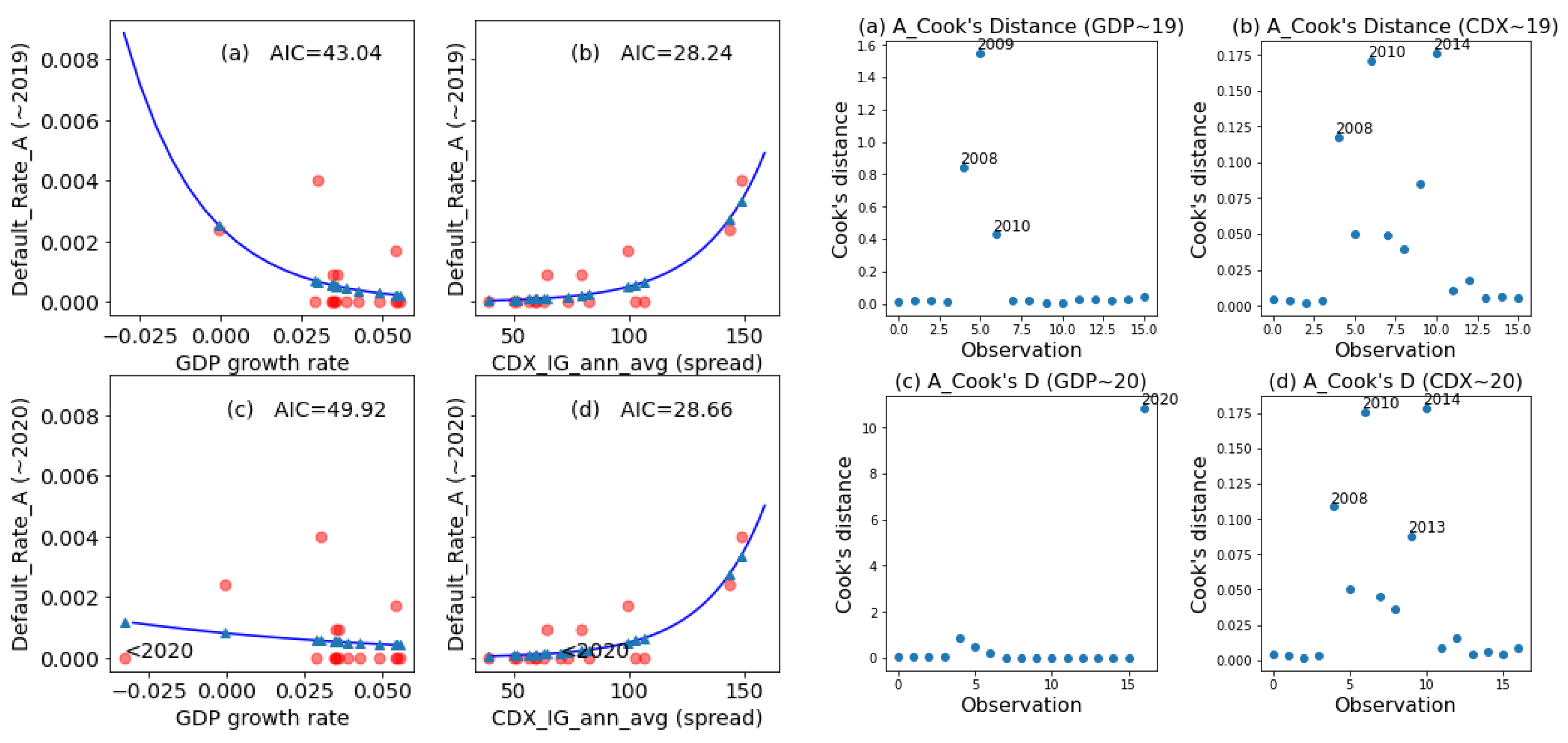
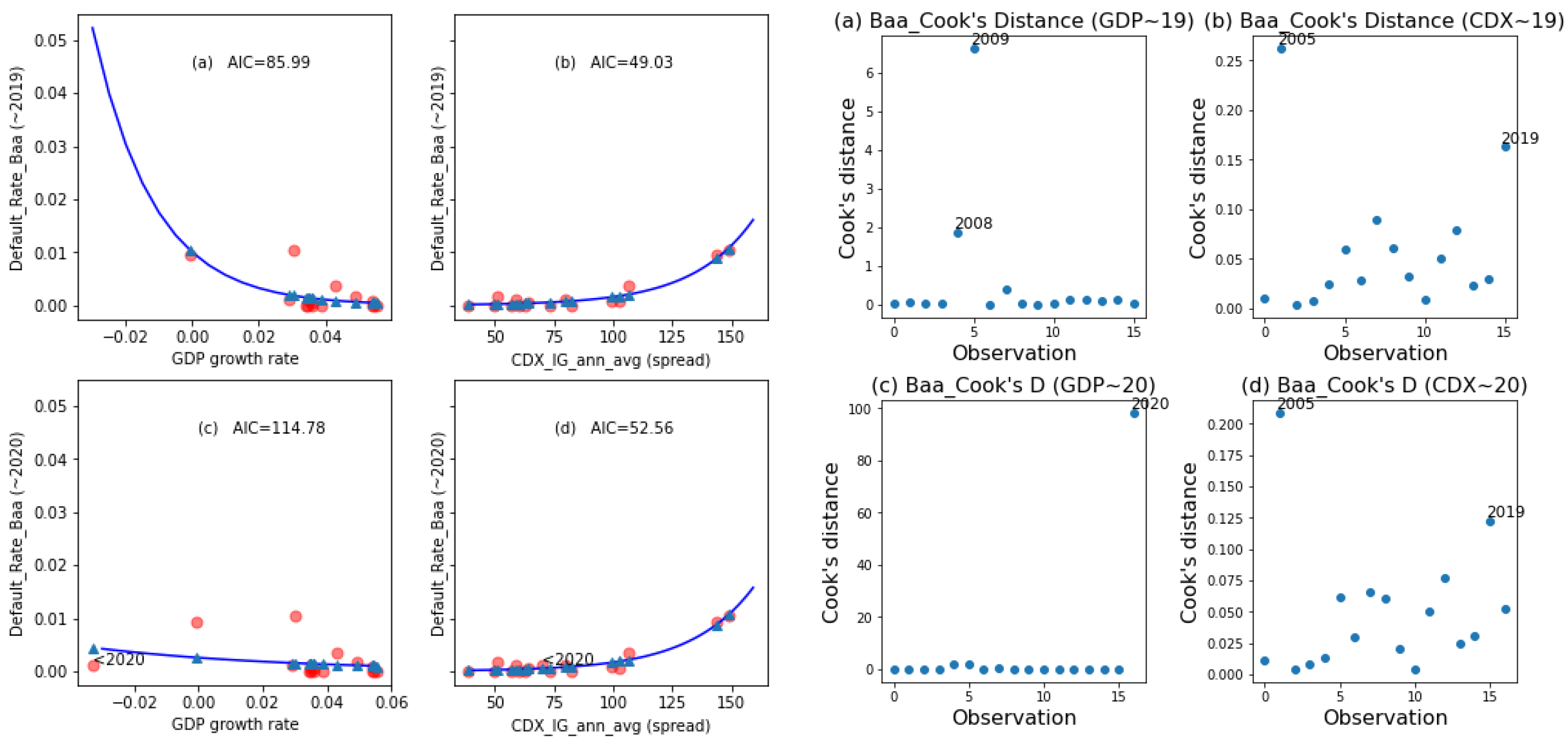
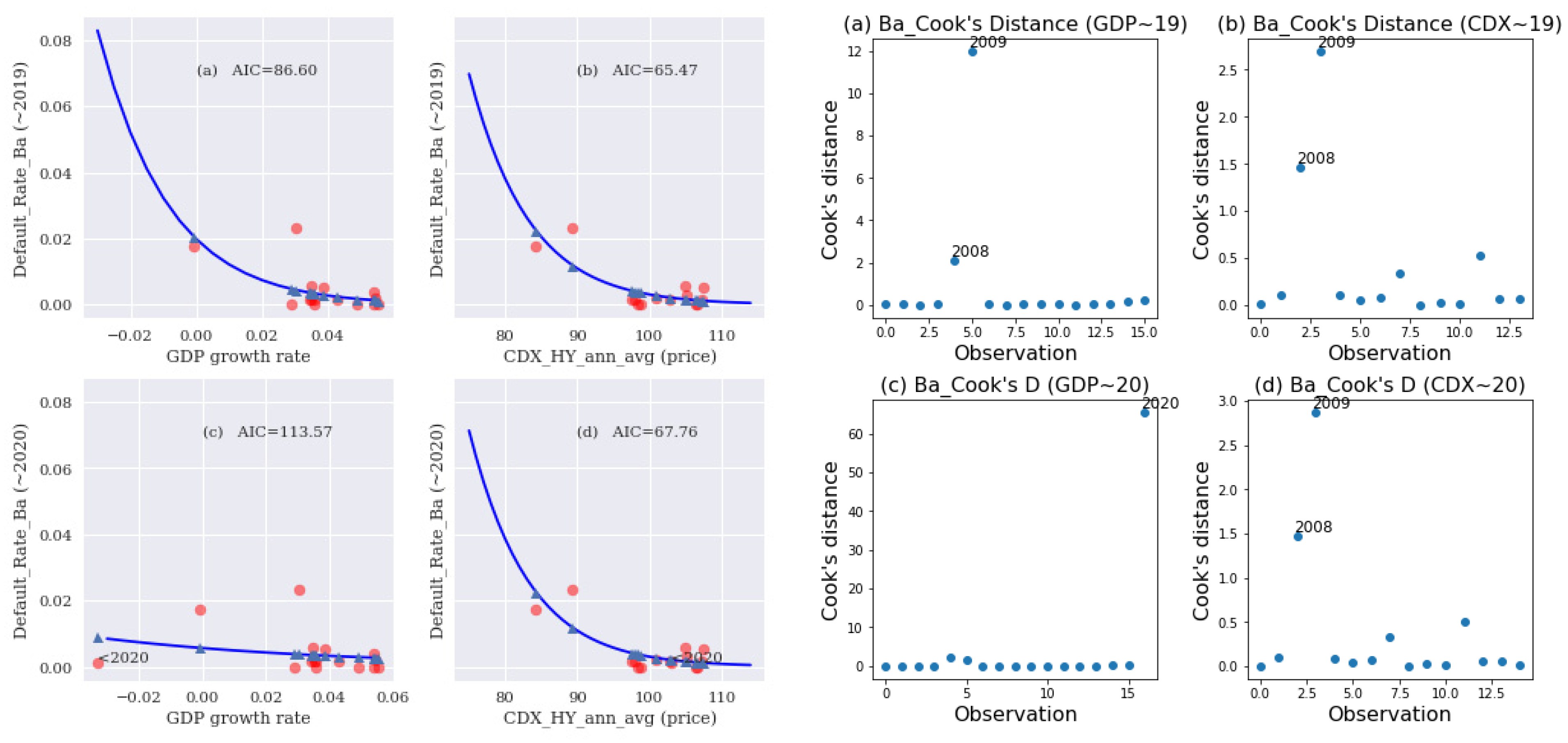
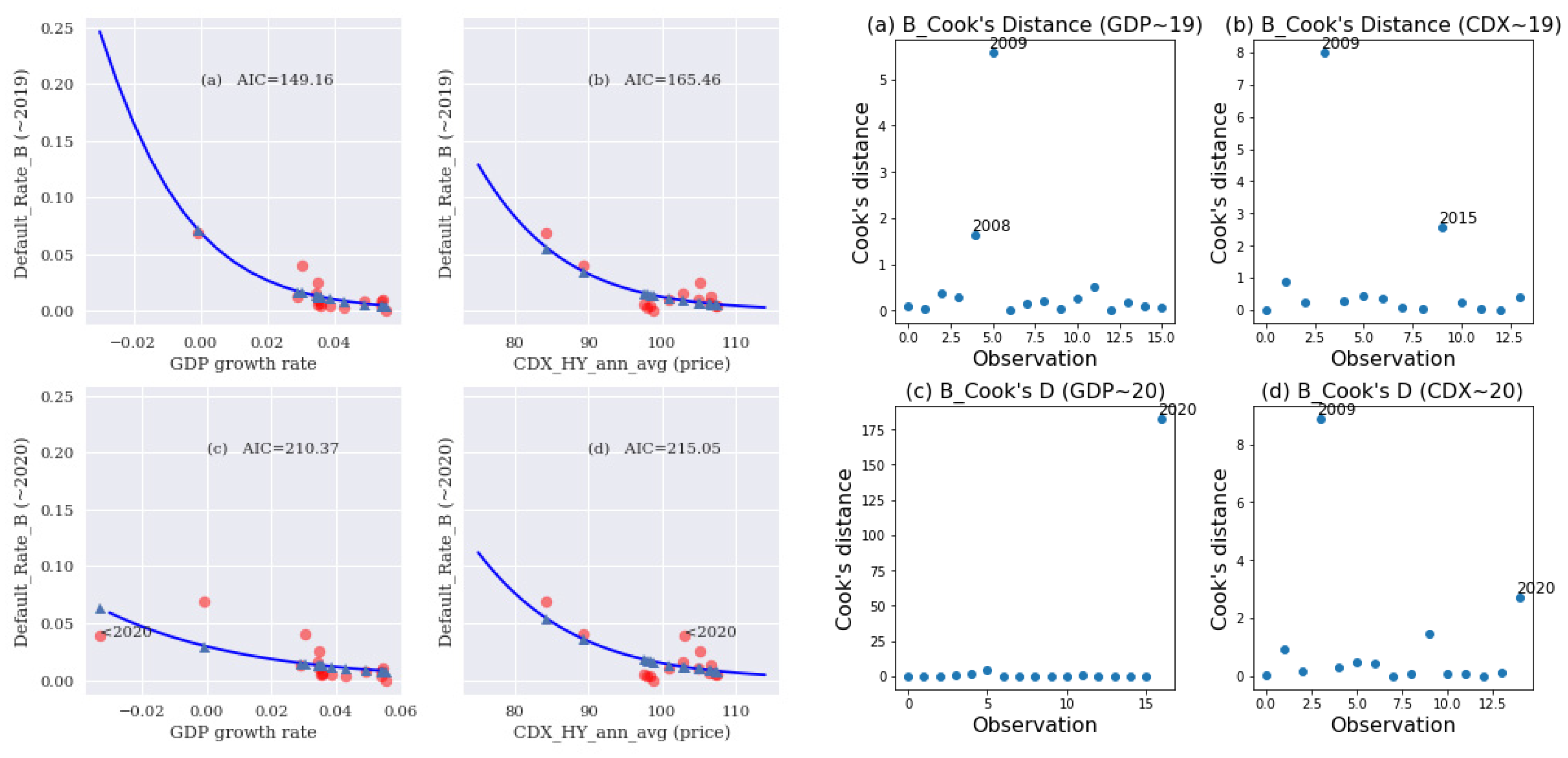
20] constructed four data sets that yielded the exact same linear regression outputs, namely, the number of observations, mean of the independent variable, mean of the dependent variable, estimated regression coefficient, regression sum of squares, residual sum of squares, estimated standard error of the regression coefficient, and coefficient of determination. However, the four data sets had different characteristics due to the presence of various types of outliers. Intuitively, an outlier is an observation that appears to be “different” from other observations in a data set. An outlier can come in one of three forms: (a) outlier with respect to the dependent variable; (b) outlier with respect to the independent variable (a leverage point); and (c) outlier with respect to both the dependent and independent variables. An outlier can be influential or not influential. An influential observation is an observation whose inclusion in the data set would greatly change the analytical result.
To measure the degree of influence the
ith data point has on the analytical result, a natural step is to compute the difference in the fitted results when the
ith data point is included and when it is excluded. Cook’s distance [
21] is based on such an idea for a generalized linear model. An approximation of Cook’s distance measure of influence has also been also formulated (Fox [
22]). Outliers can distort estimates of binary logit models and linear regression models. In this study, logistic regression diagnostics were performed using the statsmodels package [
23] in Python [
24]. This measure was computed based on a one-step approximation of the results after one observation was deleted. The diagnostic analytics can also be conducted by means of the local influence method [
25].
2.4. CDX as a Determinant in the PD Model
All the studies reviewed in
Section 2.2 demonstrated a significant negative relationship between DR and GDP growth. However, using an estimation framework presentation of lifetime PD in accordance with the IFRS 9, Đurović [
26] reported that the state of the macroeconomy had a small effect on PD development. He argued that PD development is mainly affected by a rapidly changing marketplace and a constant increase in the number of market participants. Obeid [
27] examined data from 40 commercial banks in the Arab world and reported a nonsignificant effect of GDP on bank defaults. Chortareasab et al. [
28] performed a meta-analysis of 56 empirical studies on the effect of GDP on nonperforming loans. Their results revealed that GDP performance does not have a predictable effect on credit quality.
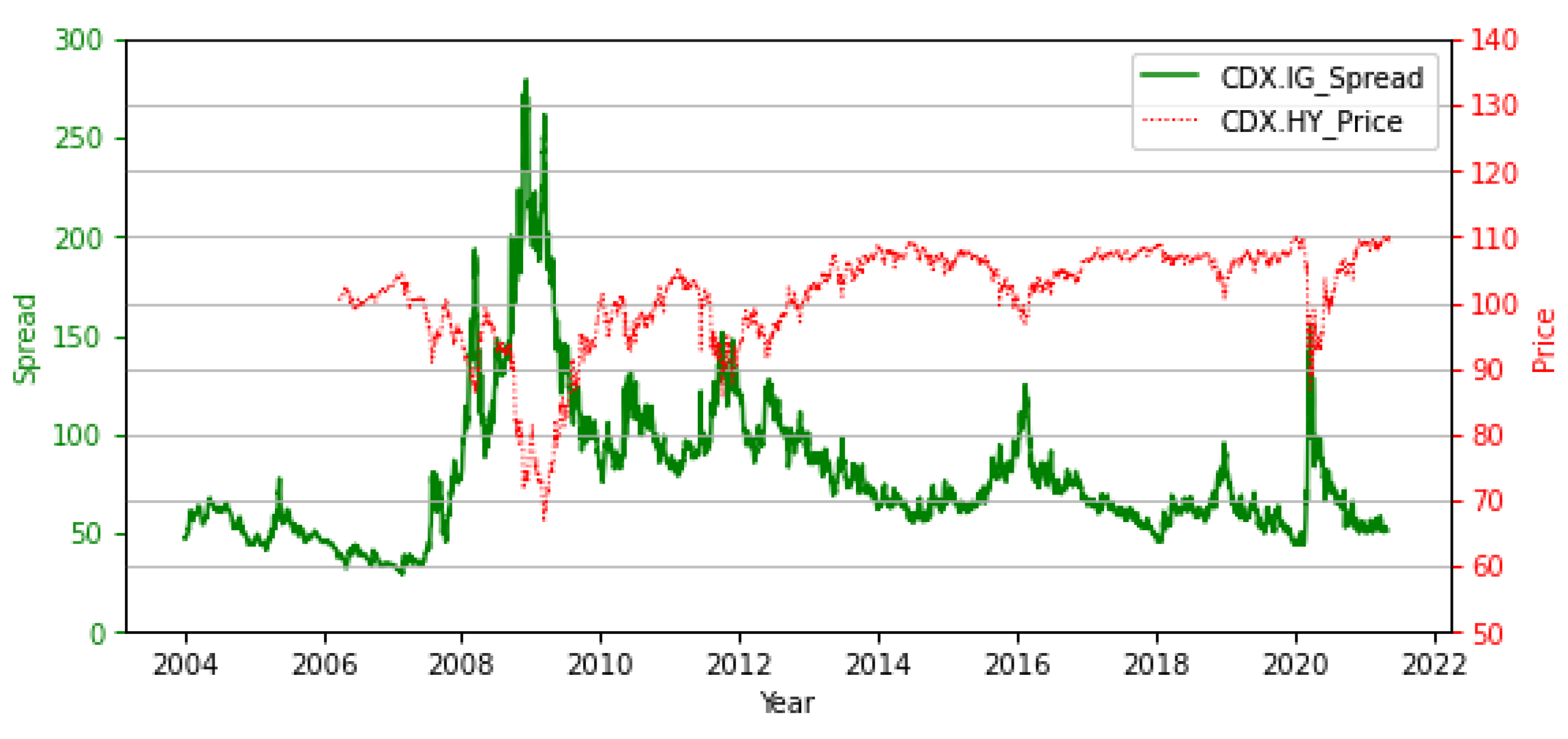
Using a regime-switching model, Giesecke et al. [
18] reported that change in GDP is a strong predictor of DRs. Surprisingly, however, they also reported that credit spreads do not adjust to current DRs or macroeconomic conditions. Conversely, in studying the effect of credit default swap (CDS) spread determinants on the probability of default, Ortolano and Angelini [
11] demonstrated that the price of CDSs is a sound indicator of banks’ creditworthiness. By contrast, Collin-Dufresne et al. [
29] demonstrated that credit spreads are driven by factors that are difficult to explain using a standard credit model. Fu et al. [
30] revealed that firm performance and macroeconomic conditions play a significant role in explaining CDS spreads.
In studying the fit performance of a PD model, Hu et al. [
31] concluded that high-rated companies exhibit a greater need to use market-traded information, such as the CDX, to capture changes in the DR. The similarities and differences between this paper and that of Hu et al. [
31] are as follows. A logistic regression model was used as the underlying PD model in both papers. In addition, Moody’s DR and the IMF’s GDP datasets were used in both papers with different time periods. The paper from Hu et al. [
31] was motivated by observing the poorly fitted results of the PD model with GDP determinants, whereas this paper is motivated by observing the extreme mismatch between the behaviour of GDP and DR over 2020. The main criteria of model comparison used by Hu et al. [
31] were
p values and AIC, whereas we primarily use Cook’s distance and AIC increasing ratio (see
Section 3.2). The empirical results registered by Hu et al. [
31] related to goodness-of-fit, especially for the companies from higher rated classes, whereas we, mainly, have determined the impact on PD and, thus, ECL estimation through outlier observation. In other words, the results of the PD model (with GDP determinant) revealed a serious lack of robustness in the 2020 data originating from COVID-19.
To explore the robustness of the PD model with a GDP determinant, we compared the fitted results and influence measures of a PD model using a GDP covariate to that of a PD model using a CDX covariate in the following empirical study.
4. Conclusions and Remarks
Overall, the test model functioned well for normal economic conditions (with data through 2019) but was less robust following the COVID-19 pandemic. The test model had a considerably greater ratio of increase in the AIC than the alternative model in comparisons of fit performance when the 2020 data point (representing the onset of the COVID-19 pandemic) was included versus when it was excluded. Furthermore, the Cook’s distance of the 2020 data point of the test model was significantly greater than that of the alternative model. In conclusion, the test model exhibited serious problems with robustness in terms of outliers, such as a global pandemic, especially for high-rated classes, whereas the alternative model was much more robust. These findings echo those of a recent IMF working paper (Roch and Roldán [
34]) that examined why countries have issued sovereign state–contingent bonds on only a modest scale and traded them at a large discount, despite the well-known benefits discussed in the literature. They discovered that, for state-contingent bond structures such as the GDP-linked bond issued by Argentina in 2005, a model lacking robustness generates ambiguity premia in bond spreads that are labeled as novelty premia. Their findings rationalize the scarcity of state-contingent debt instruments in practice. A PD model of sovereign default with robustness is required to avoid the novelty premium and increase market liquidity.
The impact of the 2020 data point in this analysis is similar to that of a case introduced in Anscombe’s Quartet [
20], which indicates that a model fit is predominantly determined by an influential data point. In the present case, we determined that the PD model based on GDP growth was non-robust after the COVID-19 pandemic’s commencement on the basis of an additional data point in 2020 (applied to each rating group). However, in the theoretical sense, the 2020 data point involved an observation of a binomial distribution with parameters
, which was formed from
Bernoulli trials (default or nondefault) with
as the number of the rated companies in 2020 for each rating class. From a practical perspective, on the other aspect, the ECL estimation occurred on both monthly and quarterly bases (e.g., see
Figure 1). However, in this paper, the reported results were based only on the yearly observations due to the data availability constraints of the DRs. The DRs in 2020 were presumably lower than they would have been if governments had not intervened. Therefore, the 2020 DRs may not reflect the true economic situation indicated by the GDP drop. The problem is that whether (and if so, when) government support programs, such as QE, will intervene in the market is unknown.
One limitation of this study is the use of a single-factor model instead of a multi-factor model because our main purpose was to illustrate the robustness of using a GDP versus CDX determinant in a PD model. Furthermore, the analyzed data represented default only as a binary variable (default or nondefault). However, especially within the Basel framework, banks use rating systems with multiple rating grades. Using multiple rating grades would force the adjustment of default probabilities as well as the consideration of the transition probabilities between rating grades. Therefore, future studies can use Markov chains to capture this phenomenon. Furthermore, our PD estimation was based on realized GDP growth. However, the difference between predicted and realized GDP growth may lead to greater fluctuation in the estimation of credit loss. For example, IMF-predicted 2020 GDP growth was less than −5%, in contrast to the realized −3.3% used in this study. The use of the predicted value in estimating ECL would have caused more serious robustness issue of the PD model. Hence, we argue that some market-based index should be introduced into the PD model. Accordingly, the fluctuating ECL scenario exhibited in
Figure 1 and
Figure 2 may be at least partially resolved.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}