Author Contributions
Conceptualization, G.M.-F. and H.W.G.; methodology, H.W.G.; software, D.I.G. and G.M.-F.; validation, G.M.-F., H.W.G. and H.B.; formal analysis, G.M.-F., O.V. and H.W.G.; investigation, H.W.G., O.V. and G.M.-F.; writing—original draft preparation, G.M.-F. and D.I.G.; writing—review and editing, O.V. All authors have read and agreed to the published version of the manuscript.
Figure 1.
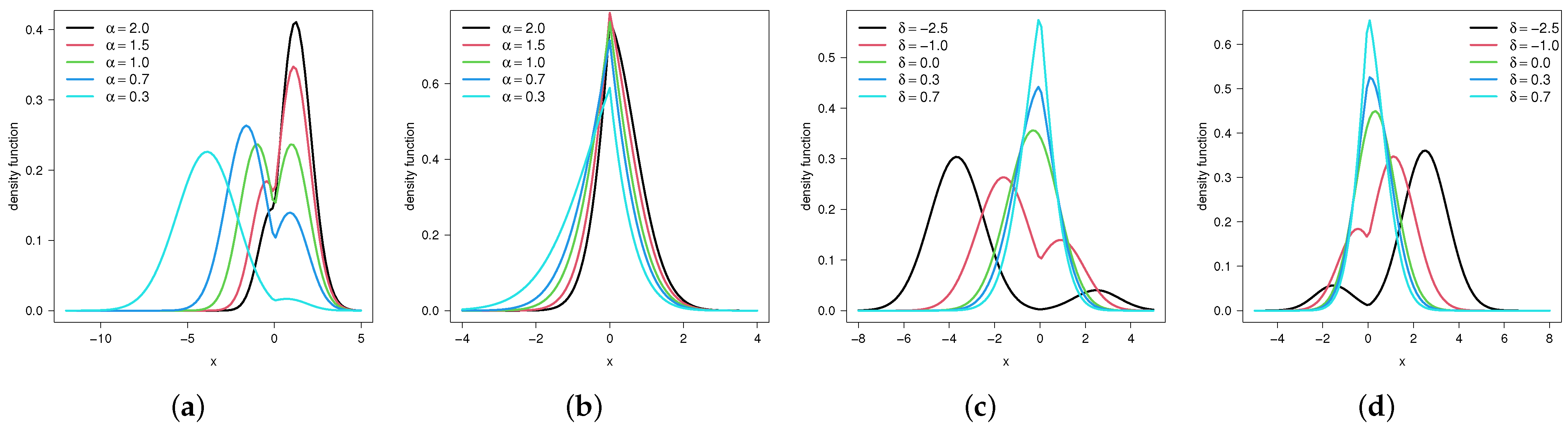
Pdf for FPN with different combinations of and : (a) FPN and varying ; (b) FPN and varying ; (c) FPN and varying ; and (d) FPN and varying .
Figure 1.
Pdf for FPN with different combinations of and : (a) FPN and varying ; (b) FPN and varying ; (c) FPN and varying ; and (d) FPN and varying .
Figure 2.
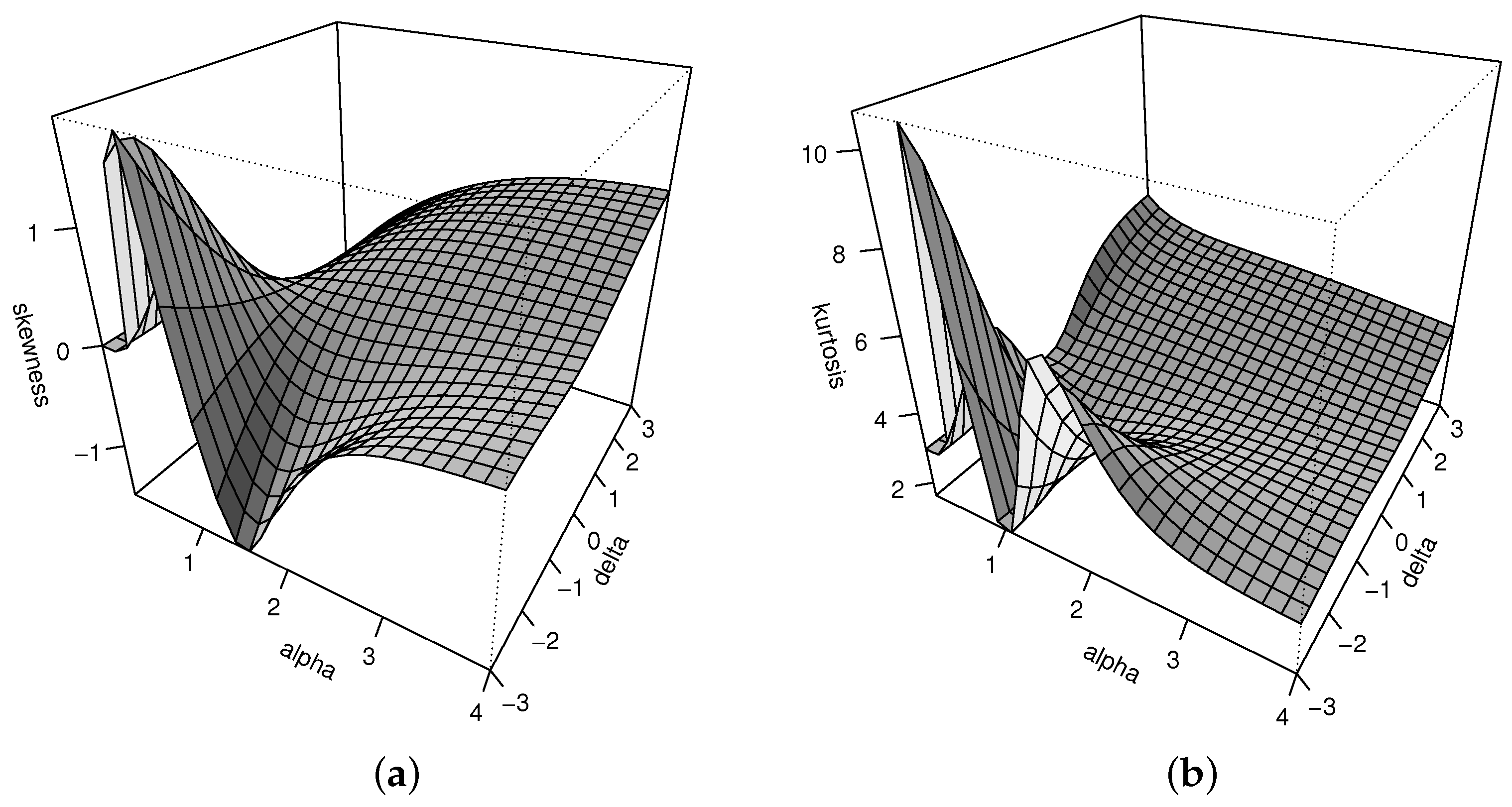
(a) Skewness and (b) kurtosis coefficients for the FPN model.
Figure 2.
(a) Skewness and (b) kurtosis coefficients for the FPN model.
Figure 3.
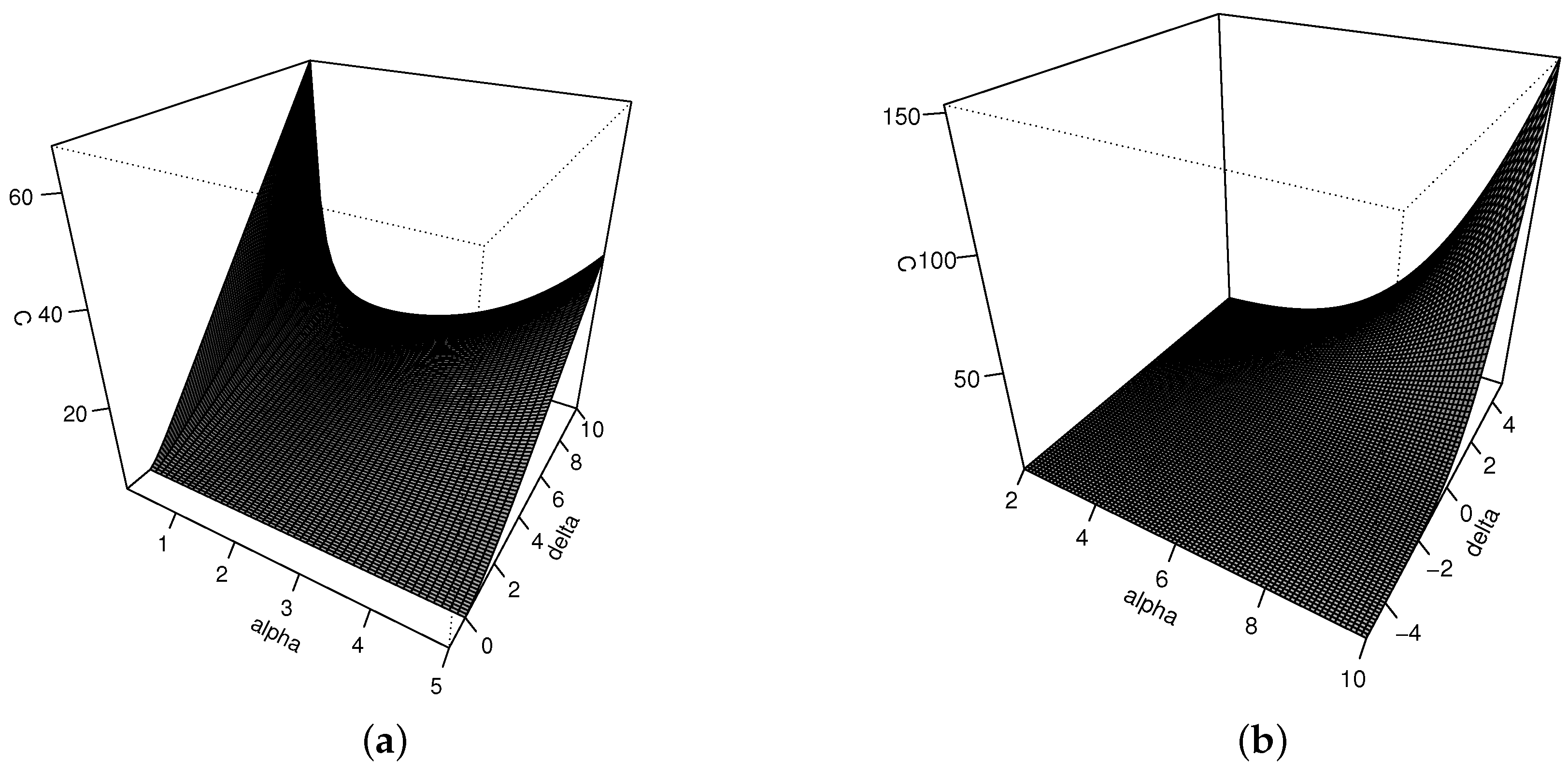
Constant C for the acceptance-rejection method to draw values from FPN model: (a) way 1 and (b) way 2.
Figure 3.
Constant C for the acceptance-rejection method to draw values from FPN model: (a) way 1 and (b) way 2.
Figure 4.
Ten thousand values simulated from the FPN model under different scenarios: (a) , and acceptance-rejection method: way 1; (b) and acceptance-rejection method: way 2; (c) and Metropolis-Hastings method.
Figure 4.
Ten thousand values simulated from the FPN model under different scenarios: (a) , and acceptance-rejection method: way 1; (b) and acceptance-rejection method: way 2; (c) and Metropolis-Hastings method.
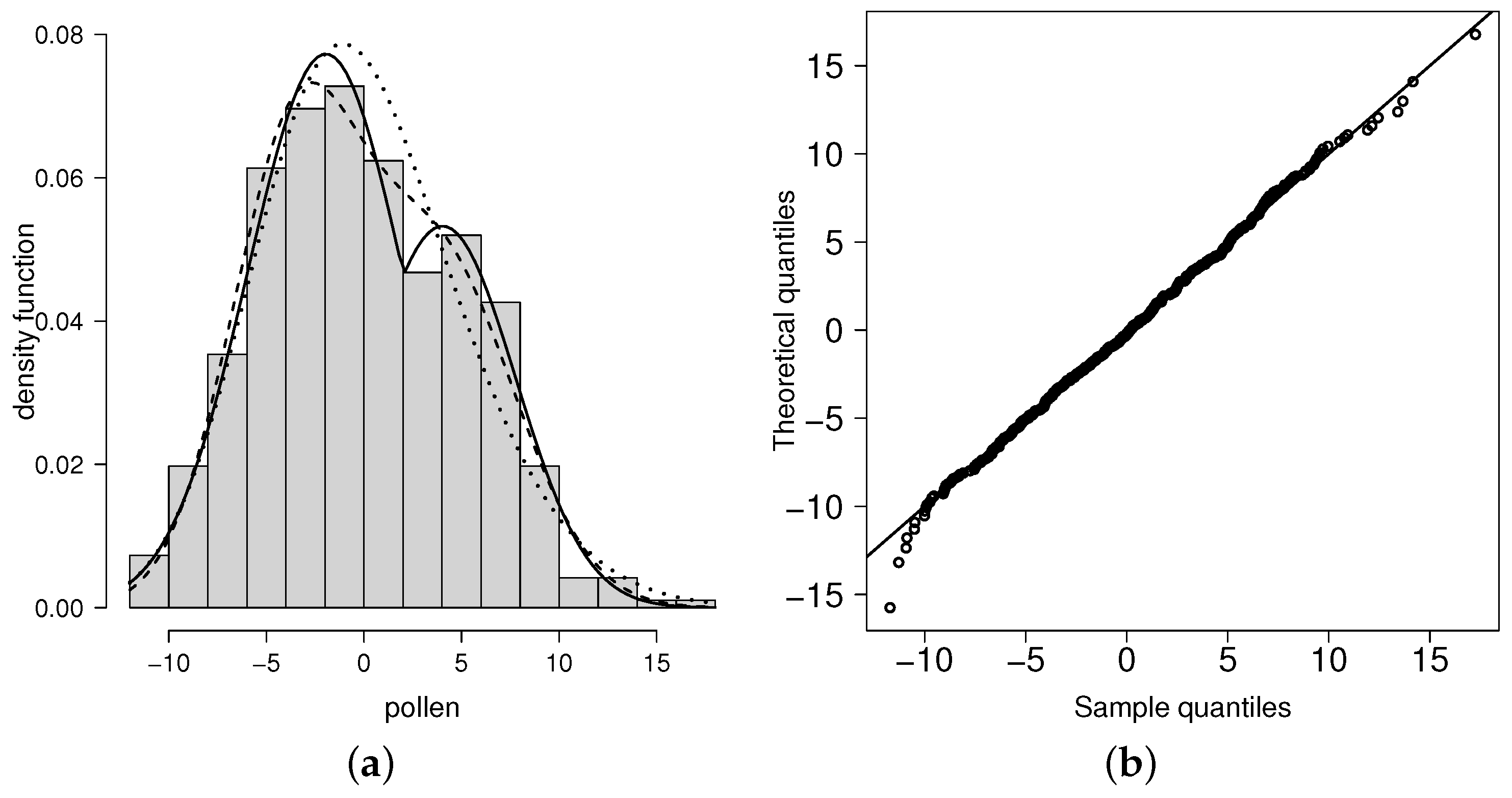
Figure 5.
(a) Fitted distributions: SN (dotted line), MN (dashed line) and FPN (solid line) models. (b) Simulated QQ-plot for the fitted FPN model and the variable pollen.
Figure 5.
(a) Fitted distributions: SN (dotted line), MN (dashed line) and FPN (solid line) models. (b) Simulated QQ-plot for the fitted FPN model and the variable pollen.
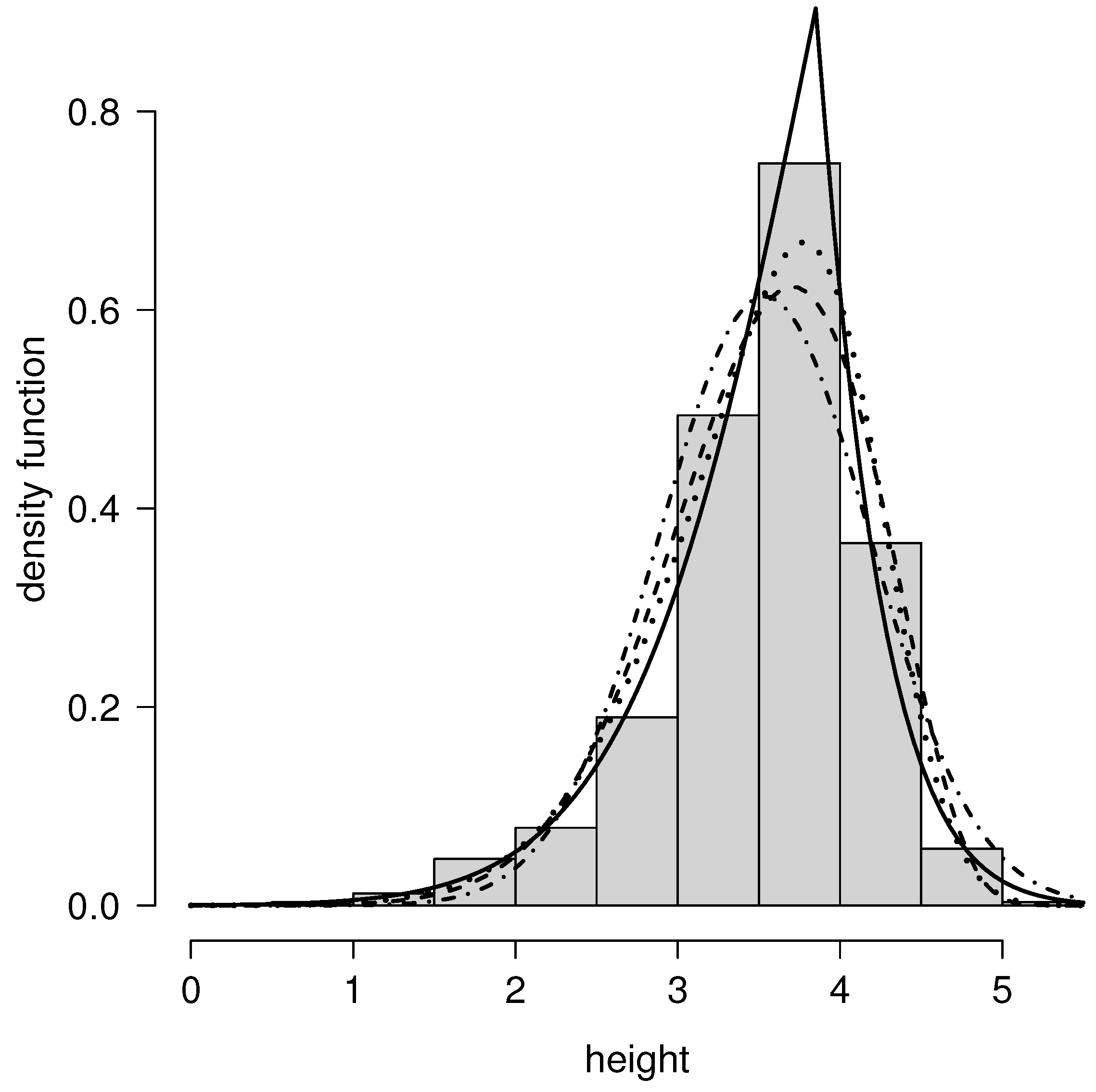
Figure 6.
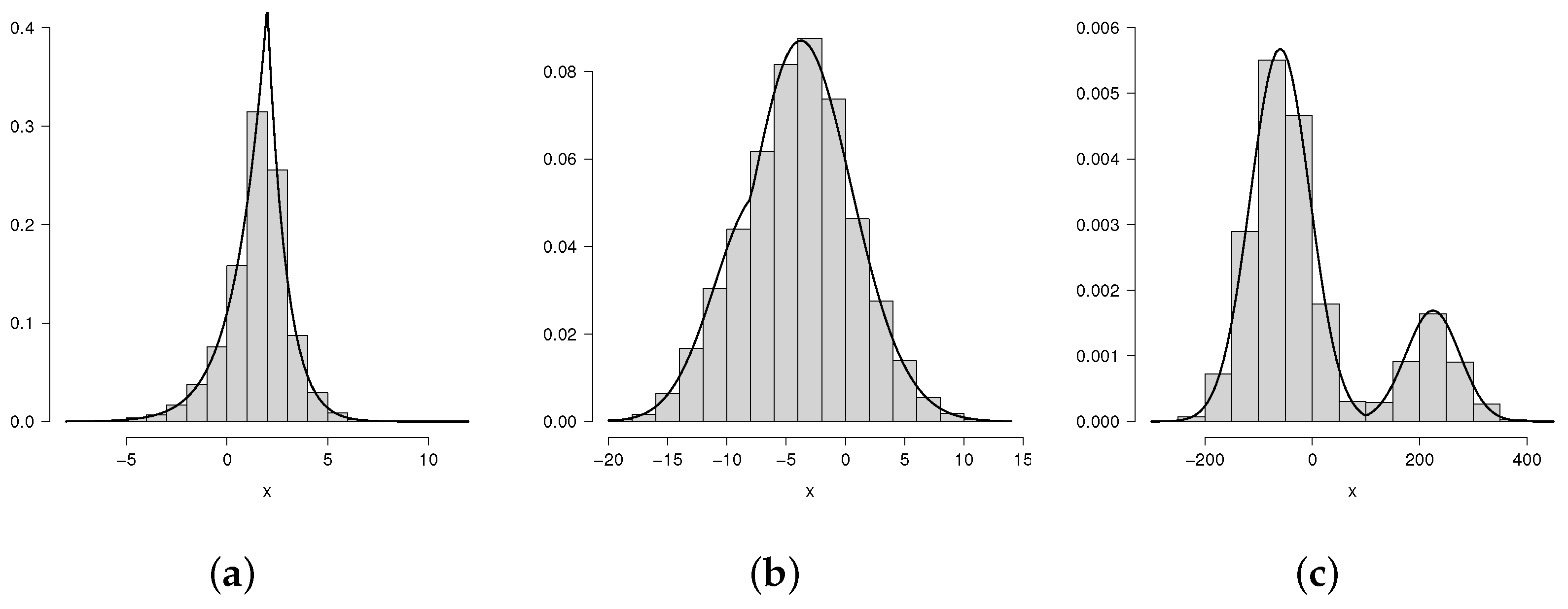
Histogram of heights dataset and fitted models N (dotted-dashed line), SN (dotted line), PN (dashed line) and FPN (solid line).
Figure 6.
Histogram of heights dataset and fitted models N (dotted-dashed line), SN (dotted line), PN (dashed line) and FPN (solid line).
Table 1.
Mean of the estimates and mean of the estimated standard errors (in parentheses) based on 1000 replicates for the FPN model. In all cases , are maintained and different sample sizes and values for and are considered.
Table 1.
Mean of the estimates and mean of the estimated standard errors (in parentheses) based on 1000 replicates for the FPN model. In all cases , are maintained and different sample sizes and values for and are considered.
| | Parameter | | | |
|---|
| | | | | | | |
|---|
| | 0.4861 (4.4259) | −0.2412 (2.0642) | −0.1071 (1.5502) | −0.0133 (1.2664) | −0.0065 (1.0174) | −0.0029 (0.8505) |
| | | 0.9068 (0.5161) | 0.9280 (0.4248) | 0.9340 (0.3629) | 0.9258 (0.3173) | 0.9382 (0.2802) | 0.9469 (0.2468) |
| | | 0.1195 (0.0990) | 0.1109 (0.0774) | 0.1136 (0.0719) | 0.1101 (0.0637) | 0.1093 (0.0640) | 0.1081 (0.0601) |
| | | −0.8799 (1.3637) | −0.6915 (0.6524) | −0.4955 (0.4797) | −0.3877 (0.3809) | −0.1621 (0.3485) | −0.0117 (0.3129) |
| | −0.022 (0.134) | 0.000 (0.085) | 0.054 (0.150) | 0.011 (0.124) | 0.000 (0.064) | −0.007 (0.031) |
| | | 0.971 (0.100) | 0.989 (0.065) | 0.923 (0.132) | 0.953 (0.090) | 0.977 (0.189) | 1.009 (0.118) |
| | | 0.835 (0.096) | 0.809 (0.060) | 0.846 (0.150) | 0.870 (0.123) | 0.895 (0.155) | 0.833 (0.079) |
| | | −0.587 (0.225) | −0.532 (0.145) | −0.163 (0.281) | −0.109 (0.181) | 0.450 (0.439) | 0.515 (0.277) |
| | 0.006 (0.126) | −0.007 (0.081) | 0.018 (0.129) | 0.017 (0.105) | −0.003 (0.069) | −0.013 (0.038) |
| | | 0.965 (0.108) | 0.984 (0.070) | 0.928 (0.135) | 0.947 (0.088) | 0.991 (0.206) | 1.008 (0.126) |
| | | 1.011 (0.112) | 1.009 (0.072) | 1.065 (0.178) | 1.058 (0.138) | 1.184 (0.352) | 1.060 (0.104) |
| | | −0.578 (0.243) | −0.540 (0.156) | −0.167 (0.309) | −0.122 (0.197) | 0.493 (0.516) | 0.510 (0.298) |
| | −0.003 (0.122) | 0.008 (0.079) | 0.050 (0.112) | −0.016 (0.096) | −0.016 (0.096) | −0.018 (0.03) |
| | | 0.970 (0.115) | 0.983 (0.074) | 0.921 (0.136) | 0.964 (0.092) | 0.963 (0.092) | 1.011 (0.126) |
| | | 1.515 (0.190) | 1.498 (0.115) | 1.479 (0.241) | 1.504 (0.207) | 1.604 (0.207) | 1.501 (0.154) |
| | | −0.584 (0.273) | −0.541 (0.173) | −0.175 (0.343) | −0.104 (0.228) | 0.545 (0.527) | 0.524 (0.330) |
Table 2.
Percentage of times where AIC and BIC choose the N, PN and FPN models based on 1000 replicates for different scenarios for the FPN model and sample size.
Table 2.
Percentage of times where AIC and BIC choose the N, PN and FPN models based on 1000 replicates for different scenarios for the FPN model and sample size.
| | | | |
|---|
| | | | −1.5 | −0.5 | 0.0 | 0.5 | 2.0 |
| | Fitted Model | AIC | BIC | AIC | BIC | AIC | BIC | AIC | BIC | AIC | BIC |
| 200 | 0.5 | N | 0.0 | 0.2 | 42.0 | 85.4 | 65.2 | 93.6 | 35.0 | 77.9 | 2.6 | 19.5 |
| | | PN | 2.2 | 6.6 | 8.9 | 3.7 | 25.0 | 6.1 | 16.0 | 9.4 | 0.9 | 1.3 |
| | | FPN | 97.8 | 93.2 | 49.1 | 10.9 | 9.8 | 0.3 | 49.0 | 12.7 | 96.5 | 79.2 |
| | 0.8 | N | 0.0 | 0.0 | 41.4 | 90.2 | 76.0 | 97.5 | 52.0 | 91.8 | 5.3 | 35.1 |
| | | PN | 0.1 | 0.1 | 9.3 | 1.8 | 12.7 | 2.1 | 9.0 | 2.1 | 1.6 | 1.3 |
| | | FPN | 99.9 | 99.9 | 49.3 | 8.0 | 11.3 | 0.4 | 39.0 | 6.1 | 93.1 | 63.6 |
| | 1.0 | N | 0.0 | 0.0 | 48.2 | 92.4 | 76.3 | 97.7 | 53.1 | 92.0 | 6.0 | 38.4 |
| | | PN | 0.0 | 0.0 | 10.9 | 3.1 | 12.9 | 1.9 | 10.2 | 2.9 | 2.3 | 2.6 |
| | | FPN | 100.0 | 100.0 | 40.9 | 4.5 | 10.8 | 0.4 | 36.7 | 5.1 | 91.7 | 59.0 |
| | 1.5 | N | 0.0 | 1.4 | 63.1 | 96.8 | 71.6 | 94.8 | 43.2 | 82.3 | 5.7 | 35.5 |
| | | PN | 4.1 | 9.9 | 11.5 | 2.1 | 16.7 | 4.8 | 25.7 | 12.3 | 6.1 | 9.3 |
| | | FPN | 95.9 | 88.7 | 25.4 | 1.1 | 11.7 | 0.4 | 31.1 | 5.4 | 88.2 | 55.2 |
| | 3.0 | N | 50.1 | 88.0 | 71.3 | 94.0 | 49.6 | 83.3 | 26.6 | 63.6 | 1.7 | 13.2 |
| | | PN | 19.3 | 11.1 | 20.5 | 6.0 | 37.7 | 15.6 | 48.2 | 33.8 | 25.7 | 48.7 |
| | | FPN | 30.6 | 0.9 | 8.2 | 0.0 | 12.7 | 1.1 | 25.2 | 2.6 | 72.6 | 38.1 |
| 500 | 0.5 | N | 0.0 | 0.0 | 11.8 | 69.2 | 47.9 | 87.2 | 10.7 | 52.8 | 0.1 | 0.4 |
| | | PN | 0.1 | 0.4 | 4.2 | 1.8 | 39.0 | 12.1 | 9.8 | 11.2 | 0.0 | 0.0 |
| | | FPN | 99.9 | 99.6 | 84.0 | 29.0 | 13.1 | 0.7 | 79.5 | 36.0 | 99.9 | 99.6 |
| | 0.8 | N | 0.0 | 0.0 | 13.6 | 76.3 | 72.2 | 97.6 | 25.6 | 82.6 | 0.0 | 1.4 |
| | | PN | 0.0 | 0.0 | 3.9 | 1.1 | 16.1 | 2.3 | 3.5 | 1.8 | 0.0 | 0.0 |
| | | FPN | 100.0 | 100.0 | 82.5 | 22.6 | 11.7 | 0.1 | 70.9 | 15.6 | 100.0 | 98.6 |
| | 1.0 | N | 0.0 | 0.0 | 17.4 | 80.8 | 77.4 | 98.4 | 25.4 | 84.0 | 0.0 | 2.2 |
| | | PN | 0.0 | 0.0 | 5.7 | 1.7 | 13.7 | 1.6 | 4.6 | 1.9 | 0.0 | 0.0 |
| | | FPN | 100.0 | 100.0 | 76.9 | 17.5 | 8.9 | 0.0 | 70.0 | 14.1 | 100.0 | 97.8 |
| | 1.5 | N | 0.0 | 0.0 | 41.3 | 95.2 | 60.6 | 94.1 | 15.7 | 68.5 | 0.0 | 2.1 |
| | | PN | 0.0 | 0.3 | 10.8 | 2.3 | 29.0 | 5.6 | 26.0 | 19.3 | 0.9 | 2.0 |
| | | FPN | 100.0 | 99.7 | 47.9 | 2.5 | 10.4 | 0.3 | 58.3 | 12.2 | 99.1 | 95.9 |
| | 3.0 | N | 27.6 | 91.3 | 53.1 | 93.5 | 18.3 | 61.1 | 3.1 | 25.5 | 0.0 | 0.3 |
| | | PN | 4.4 | 1.0 | 27.5 | 6.4 | 66.6 | 38.5 | 57.0 | 70.9 | 8.7 | 25.8 |
| | | FPN | 68.0 | 7.7 | 19.4 | 0.1 | 15.1 | 0.4 | 39.9 | 3.6 | 91.3 | 73.9 |
Table 3.
Summary statistics for precipitation data.
Table 3.
Summary statistics for precipitation data.
| n | Mean | Variance | | |
|---|
| 481 | −0.0483 | 26.9980 | 0.2329 | 2.5944 |
Table 4.
Parameter estimates (standard errors in parentheses) for N, SN, PN, MN and FPN models in the pollen dataset.
Table 4.
Parameter estimates (standard errors in parentheses) for N, SN, PN, MN and FPN models in the pollen dataset.
| Parameter | N | SN | PN | FPN | Parameter | MN |
|---|
| −0.0489 (0.2367) | −4.9482 (0.8164) | −11.8216 (7.2910) | −2.0300 (0.2797) | | −3.5847 (0.8948) |
| 5.1902 (0.1673) | 7.1379 (0.6058) | 8.4627 (1.8070) | 3.5192 (0.1982) | | 3.3009 (0.3662) |
| - | 1.6568 (0.4856) | 7.5132 (7.9838) | 0.7316 (0.0464) | | 3.8531 (1.5545) |
| - | - | - | −0.6946 (0.1316) | | 3.9516 (0.6768) |
| - | - | - | - | - | p | 0.5245 (0.1593) |
| Log-likelihood | −1474.64 | −1472.08 | −1472.24 | −1466.33 | | −1466.30 |
| AIC | 2953.28 | 2950.16 | 2950.47 | 2940.66 | | 2942.60 |
| BIC | 2961.63 | 2962.68 | 2963.00 | 2957.36 | | 2963.48 |
Table 5.
Summary statistics for roller data.
Table 5.
Summary statistics for roller data.
| n | Mean | Variance | | |
|---|
| 1150 | 3.535 | 0.422 | −0.986 | 4.855 |
Table 6.
Parameter estimates (standard errors in parentheses) for N, SN, PN and FPN models in roller dataset.
Table 6.
Parameter estimates (standard errors in parentheses) for N, SN, PN and FPN models in roller dataset.
| Parameter | N | SN | PN | FPN |
|---|
| 3.5347 (0.0192) | 4.2475 (0.0284) | 4.5494 (0.0570) | 3.8529 (0.0106) |
| 0.6497 (0.0135) | 0.9644 (0.0304) | 0.1983 (0.0279) | 0.7589 (0.0634) |
| - | −2.7578 (0.2529) | 0.0479 (0.0155) | 0.2082 (0.0568) |
| - | - | - | 1.3045 (0.2064) |
| Log-likelihood | −1135.87 | −1071.35 | −1085.24 | −1065.92 |
| AIC | 2275.73 | 2148.69 | 2176.84 | 2139.84 |
| BIC | 2285.83 | 2163.84 | 2191.98 | 2160.03 |


 ,
, 









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}