2. Basic Concepts and Notation
In this section, we introduce basic concepts from formal language theory according to [
13,
14] and from stickers according to [
1] that we will use in the sequel.
An alphabet is a finite nonempty set of elements named symbols. A string defined over is a finite ordered sequence of symbols from . The infinite set of all the strings defined over is denoted by . Given a string we denote its length by . The empty string is denoted by and denotes . Given a string x we denote the reversal string of x by . Given two strings and , we denote the product (concatenation) of x by y as the string . A language L defined over is a set of strings over .
A grammar is a construct where N and are the alphabets of auxiliary and terminal symbols with , is the axiom of the grammar and P is a finite set of productions in the form , where and . The language of the grammar is denoted by and it is the set of terminal strings that can be obtained from S by applying symbol substitutions according to P. Formally, if , , and . We denote the reflexive and transitive closure of by . The language generated by G is defined by the set .
We say that a grammar is right (left) linear (regular) if every production in P is in the form () or with and . The class of languages generated by right (left) linear grammars is the class of regular languages and is denoted by . We say that a grammar is linear if every production in P is in the form or with and . The class of languages generated by linear grammars is denoted by . A well-known result from formal language theory is the inclusion .
A deterministic finite automata (DFA) is an abstract machine , where Q is a finite set of states, is an input alphabet, is a transition function, is an initial state, and is a set of final states. The extension of the transition function over strings is defined as , and for every , and . In the following, we will not distinguish between and , and its meaning will depend on the function arguments. The language accepted by a DFA A is the set . A classical result from formal language theory is that the class of languages accepted by deterministic finite automata is . For the case of non-deterministic finite automata, the transition function is defined as , where is the power set of Q. It is a classical result from formal language theory that the set of languages accepted by non-deterministic finite automata is again .
Regular languages can be defined by regular expressions. They are a language specification based on definition rules that consider letters of the alphabet, the union, product and closure operators, and the use of parentheses to reorder the priority of operators.
A homomorphism h is defined as a mapping where and are alphabets. We can extend the definition of homomorphisms over strings as and with and . The homomorphism over a language is defined as .
Given an alphabet , we use the symmetric (and injective) relation of complementarity . For any string , we denote by the string obtained by substituting the symbol a in x by the symbol b such that (remember that is injective) with .
Given an alphabet V, a sticker over V is the pair such that , with and . The sticker will be denoted by . A sticker will be a complete and complementary molecule if and . A complementary and complete molecule will be denoted as . The set of all complete and complementary molecules over V will be called the Watson-Crick domain and denoted by .
We define the following sets, where denotes the symmetric relation between the symbols in V:
,
,
.
In addition, we can consider the set . Observe that is included in each set from and .
Kari et al. [
9] defined the sticking operation
which can be considered as a product operation over stickers. Basically, given two stickers
x and
y, the operation
returns a new sticker by taking into account the complementarity relation
between the upper string in
x and the lower string in
y and vice versa.
Sticker systems were defined by Freund et al. in [
15] and by Kari et al. in [
9] as a generative model to apply the sticking operation
(a product-like operation over stickers) to obtain languages. At the same time, Păun and Rozenberg [
10] introduced some aspects which will be highly related to the present work such as the (bounded) delayed languages defined by sticker systems. A sticker system is defined by the tuple
, where
V is an alphabet,
is a symmetric (and injective) relation,
D is a finite subset of
where its elements are called dominoes, and
A is a finite subset of
which are the axioms of the system. The derivation relation ⇒ between stickers, according to a sticker system
, can be defined as follows:
iff such that .
Given that ⇒ is a relation between stickers subjected to a sticker system , we will denote the reflexive and transitive closure of ⇒ by . Now, we can define the language of complete and complementary molecules generated by the sticker system with no restrictions as follows:
.
In addition, the language generated by is defined as:
.
The family of languages generated by arbitrary sticker systems is denoted by .
The maximal length of an overhang in a sticker is called the delay of z. Observe that the delay of a sticker z is the maximal length of the right or left overhang located in the upper or lower strand. Formally, if , with , then the delay of z equals to the maximum value between and , where if or , and if or . The delay associated to a derivation in a sticker system is the maximal delay of the stickers that are produced during that derivation. For any sticker system , the language of strings generated by with a delay d is denoted by . A sticker system is said to have a bounded delay if there is such that · The family of languages generated by arbitrary sticker systems with a bounded delay is denoted by .
Watson-Crick finite automata (WKFA) were defined first by Freund et al. [
2] as an acceptance model to deal with stickers. It can be defined by the tuple
, where
Q and
V are disjoint alphabets (states and symbols),
is a symmetric (and injective) relation of complementarity,
is the initial state,
is a set of final states, and
. A transition step in an arbitrary WK finite automaton
M is denoted by
. So,
iff
, with
. The transitive and reflexive closure of
is denoted by
. We can use a normal form such that for every transition
then
. This normal form defines the so-called 1-
WK finite automata and they were proved to be equivalent to arbitrary ones [
2].
The language of complete and complementary molecules accepted by
M will be defined by the set
with
and
, while the upper strand language accepted by
M will be defined as:
The class of languages accepted by arbitrary WKFA in the upper strand is denoted by .
We can use a normal form such that for every transition
then
or
. This normal form defines the so called simple WKFA and they were proved to be equivalent to arbitrary ones [
2].
Now, we will relate the languages in with the languages generated by sticker systems through the following result.
Theorem 1. Let be a simple WKFA. Then there exists a sticker system , a morphism h and a regular language R which satisfies .
Proof. Let us take to be a simple WKFA with and . Observe that this restriction over WKFA does not affect the computational capacity of the model, given that simple is a normal form for WKFA. We can define the sticker system where the elements of are defined as follows:
, where ;
The set of axioms A is defined through the following rules:
This axiom places the initial state of M as the first state in the sequence defined to accept any string.
where
An axiom is created for every transition from the initial state of the WKFA, . The overhang end on the left lower strand of the axiom corresponds to the state of the WKFA that is reached from the initial state with a -movement.
if
If the initial state in the WKFA is final too, then this axiom is inserted. That is, the additional state is produced from the initial state without any input symbol.
The set D is defined by the pairs according to the following rules:
where and or .
That means that, in M, it is possible to transit from q to p with the pair .
where .
For each final state of the WKFA, these stickers mark the end of the state sequence in the WKFA to accept the input.
This rule is added to avoid overhang ends in the left side of the sticker system. When this rule is added there is no way to add another one according to the automata transitions.
Now, observe the following accepting computation in
M:
where
. The following derivation is hold in
:
and it can easily be shown that
iff
.
A regular set
R is defined by the regular expression:
The above regular expression guarantees that only strings containing a single symbol can be produced and, therefore, in the sticker system, the molecules obtained correspond only to those that have reached a final state in the WKFA. On the other hand, note that without the set R acting as a control set, the sticker system could generate molecules that would not be recognized in the automaton. In other words, nothing prevents the sticker system from continuing to add stickers that could complete new molecules once the molecule accepted by the automaton has been generated.
Finally, we can define the morphism
as follows:
Hence, , , and the theorem holds.
It can be observed that the sequence of states needed to accept any string x in M is defined by the reverse of the sequence of states between the # marks in the stickers obtained in . □
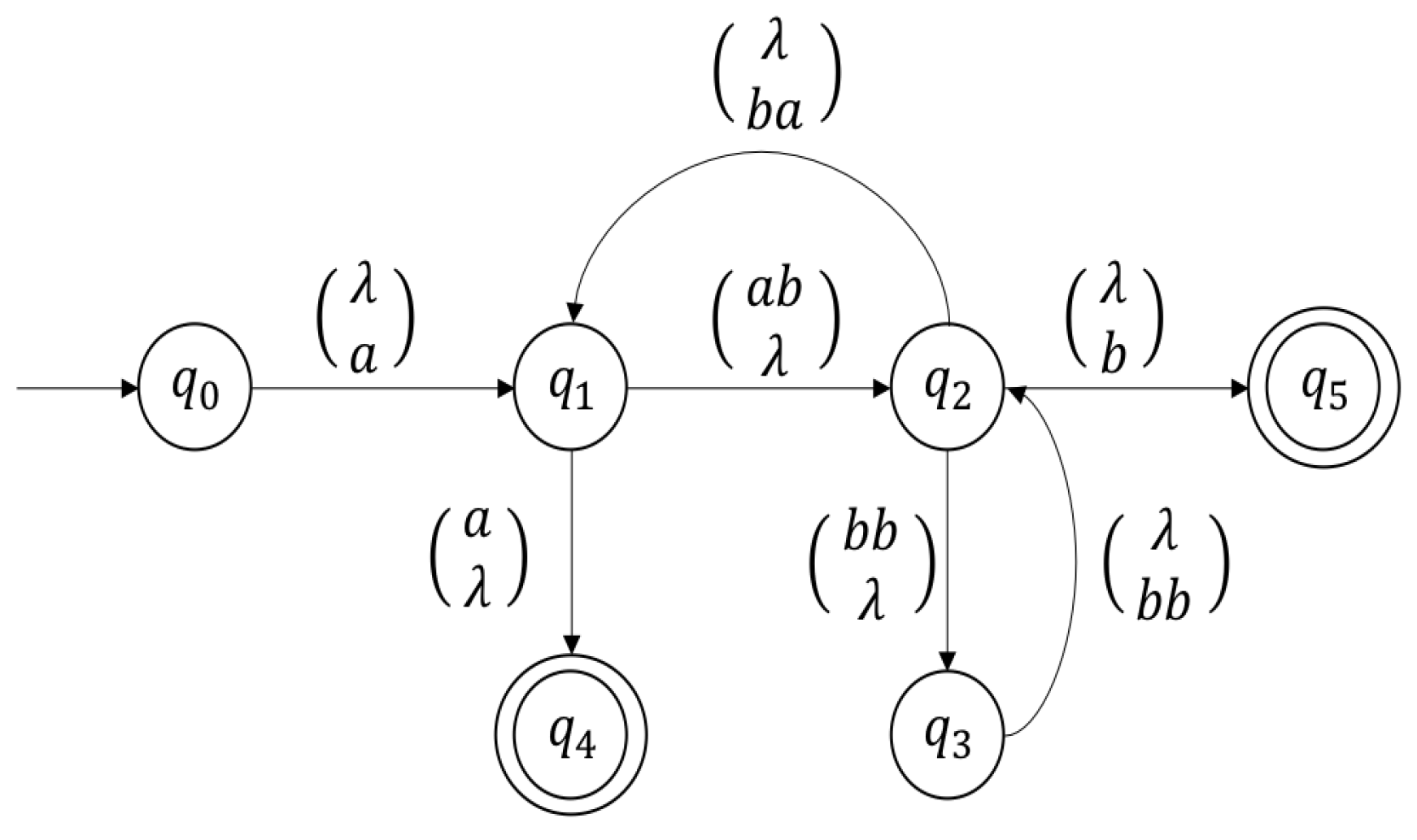
Example 1. Let us take the simple WKFA defined by the transition diagram in Figure 1. From the previous WKFA, we build a sticker system, such that A and D are defined as follows:
.
The regular expressión defined to control the stickers generation is defined as follows: 3. Accepting Languages with Bounded Delays in WKFA
In this section, we will introduce the delays during a WKFA computation in a way similar to sticker systems [
10].
Let us suppose that we consider the following computation in a WKFA
with
and
:
where
,
, if
, for
, and
then we say that
M accepts
with an upper bounded delay
d. If
, for
we say that
M accepts
with a lower bounded delay
d. If
, for
we say that
M accepts
with an arbitrary bounded delay
d. The language accepted by
M with upper (lower, arbitrary) bounded delay
d in the upper strand is denoted by
(
). The class of languages accepted by arbitrary WKFA in the upper strand with upper (lower, arbitrary) bounded delay equals to
d will be denoted by
(
,
).
The definition of delays in the computation of the automaton is a constraint that reduces the computational power of the model. This can be formalized by the following result.
Lemma 1. For every integer value , .
Proof. Let us consider the language
. This language belongs to
given that it can be accepted by the following WKFA.
| | |
| | |
| | |
with
and
. Observe that the automaton reads first in the upper strand the string
w until it reaches the symbol
c always being in the state
. Once the symbol
c has been read, the automaton changes its state and it then starts to match the string after the symbol
c with the string starting on the lower strand. If the symbol
c is found in the lower strand then it proceeds to read the rest of the input string in the lower strand.
It is easy to see that for any delay value , a string with will not be parsed with a delay less than or equal to d given that the automaton needs to read the string w first before arriving to the symbol c. In such a case, the automaton produces a delay greater than d given that . □
Now, we are going to consider the relationships between the upper, lower, and arbitrary delays. In this case, we will work with arbitrary WKFA and the identity as the relation
defined in the automata. Observe that this does not detract from the generality of our results since the complementarity relationship can be reduced to the identity as shown in [
16].
Lemma 2. For every integer value , .
Proof. Let be an arbitrary WKFA with being the identity relation, and L be the language accepted by with a bounded upper (lower) delay d. Then, from we can obtain the WKFA where if . It is easy to see that if w is accepted by with an upper (lower) delay d, then w is accepted by by a lower (upper) delay given that the relation is the identity and the transitions in swap the contents of the upper and lower strands. □
Lemma 3. .
Proof. Let
be an arbitrary WKFA and
. For every
there exists a computation in
M as follows:
Observe that is the identity relation and, we can assume that , . Then, from M we can obtain a non-deterministic finite automata , such that iff .
It is easy to see that . Hence, . In order to see that , we take any arbitrary deterministic finite automata , and we obtain the WKFA where is the identity relation, and iff . Again, it is easy to see that iff . Then, , and the lemma holds. □
A Sufficient Condition for Bounded Delays in WKFA
We have seen how delays during computation, regardless of whether they occur on the upper or lower strand, can be variable. That is, given a delay value
d, the computation can produce that delay incrementally (i.e., starting with a delay less than
d and then increasing it to the required value). In this section, we will propose a way to produce the required delay instantaneously. Informally, the approach we are going to propose requires producing the desired delay in the first movement of the computation and, subsequently, maintaining it until a point in time where it is completely reduced. This, without being a normal form, can be interesting when dealing with WKFA inductive inference as proposed in [
12].
We say that M accepts x in the upper strand with an initial delay k iff M applies the following transition sequences to accept . Remember that we can use the identity relation without loss of generality.
First movement (initial delay) Delay propagation such that
Final movement such that
Therefore,
M accepts
x in the upper strand by first processing
k symbols of the upper strand, and then processing alternately
k symbols of the lower and upper strand. When there are less than
k symbols left in the upper strand, all the remaining symbols are processed.
Figure 2 shows graphically how the stickers are organized as they are processed with initial delays.
Observe that the movements of the automata can adapted to be simple: The movement
, with
can be replaced by the following two movements
and
. Hence, the scheme to process the stickers in a simple WKFA with initial delays is shown in
Figure 3.
Observe that according to the previous figure, in the WKFA the delay always equals to k given that first it is produced in the upper strand and then the lower strand is completed. In the following we will work with simple WKFA with only initial delays.
4. Languages Accepted by WKFA with Only Initial Delays
Let M be a simple WKFA with only initial delay movements, and let d be the delay at every computation step in M. If a sticker system is built from M as established in Theorem 1, then . This is due to the fact that, according to the definition of a WKFA with an initial delay d, the length of the delay that may appear in any of the two strands when processing a sequence cannot be longer than d. Therefore, in the sticker system, during its construction, the overhang end in the right side cannot be longer than d, and, in the left side, longer than one.
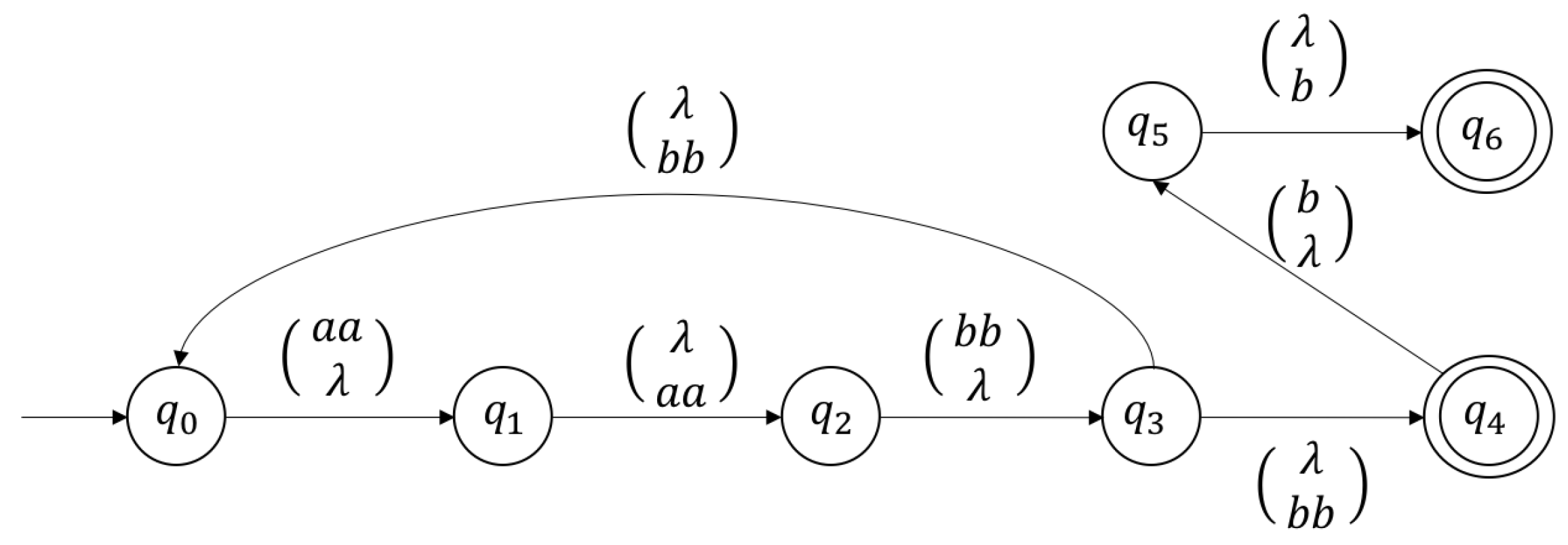
Example 2. Let us take the simple WKFA with initial delays defined by the transition diagram of Figure 4. Observe that the bounded delay in this case equals to 2. Observe that the bounded delay in this case equals to 2 and .
From the previous WKFA, we build a sticker system γ, such that A and D are defined as follows:
In this case, which can be defined by the regular expression:given that, once a molecule is completed in γ, after having reached the final state , there is no possibility of lengthening the molecule and completing a larger one, as the upper and lower strand would not be complementary. Thus, the definition of a regular expression for derivative control, as in the proof of Theorem 1, is completely unnecessary in the case of initial delays. This aspect will be formalized by the following theorem.
Theorem 2. Let be a simple WKFA with only initial delays. Then there exists a sticker system and a morphism h which satisfies .
Proof. Let be a simple WKFA with only initial delays. Then we define a sticker system and a morphism h as in the proof of Theorem 1. Observe that in this case, there is no way to keep on derivating a sticker once the pairs and have been applied given that the rest of elements in D do not preserve the complementarity since the relation is the identity. □
It is known that
(Theorem 4.3 in [
10]). That theorem is proven by building a linear grammar
from a sticker system
. In the grammar
G, the molecules are obtained by a derivation from the ends of the molecule until reaching its central part in a reverse process to the one that happens in the sticker system. We can take advantage of this result together with the results we have proven before to characterize the language accepted by the WKFA with only initial delays. It is established by the following result.
Theorem 3. Let be a simple WKFA with only initial delays. Then .
Proof. A sticker system
can be obtained from
M, according to the proof of Theorem 1. Let
and
be such a sticker system. Let
be a linear grammar built from
as described in [
10]. It can be observed that, for every production in
G in the form
the sticker
is defined from the symbols in
while the sticker
is defined from the symbols in
V.
Now, a left linear grammar can be constructed from G. The set of productions in is defined as follows:
where the morphism is defined as if and if . The language generated by the grammar is the result of removing the symbols in from the strings generated by G in the upper strand. These strings are the strings in . Since is a left linear grammar and then . □



{kind=link}
{kind=link}
{kind=link}
{kind=link}



