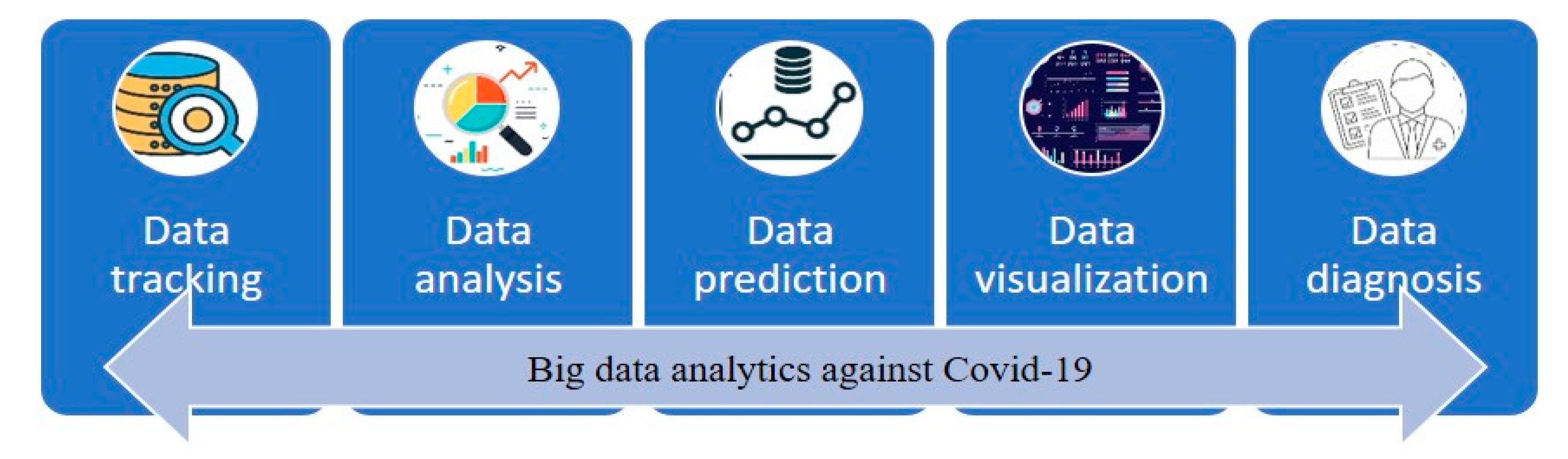
1. Introduction to COVID-19 and Diagnosis
The widespread COVID-19 pandemic constitutes a severe threat to global health. Therefore, most new research has used tools and techniques for tracking COVID-19 and discovering various infection areas to minimize the risk of its spread. Because of the massive quantity of data available every day for COVID-19 infection, spread, detection, deaths, etc., there is a need for big data analytics, storage, and security in NoSQL database management systems [
1,
2]. Machine learning and AI approaches can evaluate large quantities of COVID-19 data to create new models and techniques for diagnosing COVID-19. Big data analysis techniques are crucial to analyze more data in less time, as time is a critical factor for treating COVID-19 infection cases. Furthermore, AI techniques enable a global visualization of the analyzed big data of COVID-19. The visualization uses AI to present an overview of global health and confirmed cases of COVID-19. In addition, the presented images of the lungs can indicate the presence of COVID-19. Therefore, the tracking of COVID-19 diseases to enhance community health needs comprehensive data and intelligent computational instruments. In a variety of approaches, numerous researchers have employed big data and AI tools to track COVID-19 disorders, as shown in
Figure 1.
COVID-19 is an infectious disease where coronaviruses are a large family of viruses that can affect both humans and animals and cause respiratory difficulties [
1]. Historically, 2020 was considered a volatile year for humans worldwide compared to previous years because of COVID-19, as it is a massive threat to global health. As of March 2021, there have been more than 128 million confirmed illnesses and approximately 3 million deaths worldwide [
2]. Therefore, the number of infected subjects is increasing, with more than 150 countries reportedly having at least one case [
3].
Image scanning is helpful to diagnose COVID-19 for infected subjects. Patients that have been exposed and have terrible symptoms of the virus may not be identified by the outcome of RT-PCR tests [
4,
5,
6] that can still be non-deterministic. Image scanning includes X-rays (CXR), and computed tomography (CT) images. CT scans have proven to be one of the most accurate methods of diagnosis for COVID-19 [
7]. However, there are several significant drawbacks [
8], such as the high cost and not being conducive to bedside testing [
9]. Consequently, it is not usually used in COVID-19 diagnosis, and it is also not necessary for the progression of specific cases to be observed, especially in seriously ill patients [
10]. On the contrary, the X-ray technique is a less sensitive method than CT for COVID-19 detection, with a reported baseline hypersensitivity of 69 percent [
11]. The X-ray is also a cheaper, faster option and can be used in many healthcare centers. Positive X-ray results reduce the need for CT screening if there is a strong clinical suspicion of COVID-19 infection [
11]. However, this presents limitations for patients, including pregnant women, since it can affect the fetus [
12]. In both lungs, radiologists also examine multiple patchy, segmental, or sub-segmental shadows in the ground glass density when analyzing X-ray images to diagnose COVID-19 [
13]. This can be automated to assist experts in making a decision [
14,
15,
16].
Therefore, big data and AI technology offer an essential role in the battle against COVID-19. Both tools might help doctors to diagnose COVID-19 cases more quickly and accurately. Accordingly, computer-based models for predicting, foretelling, analyzing, and distributing SARS-CoV-2 drugs have been designed and developed, allowing machine learning, computer vision, and robotic technology to be applied. In addition, AI and big data tools include visualization to illustrate information that supports regional transmission and risk allocation.
Different studies [
17,
18] were carried out based on in-depth learning technologies to diagnose and classify various diseases, such as viral pneumonia and organ tumors. Today, deep learning technologies have been used widely in the healthcare domain. This study makes the following contributions:
A deep learning sample-efficient algorithm for the diagnosis of COVID-19 based on CXR and CT scans.
Three COVID-19 datasets were used to train and test the proposed CAD. The datasets include 4001 positive CT scans of COVID-19 clinical results and 3835 positive CXR images. It is the most widely accessible CT dataset for COVID-19 as far as we are aware.
An extensive analysis of the results of COVID-19 transition was planned and conducted; informative conclusions are presented through developing various transfer techniques.
Self-controlled learning with transfer learning was utilized to learn strong, impartial representations of features to reduce the chance of over-fitting to learn from restricted labeled information.
Detailed studies were carried out to show that our CAD was successful. The results, on average, were a 99.18% accuracy, 99.69% recall, and 99.4% precision on the COVID-19 CXR and CT imaging datasets.
This paper discusses the most recent research in
Section 2.
Section 3 presents an overview of the methods and techniques used. The proposed model is presented in
Section 4.
Section 5 gives a brief description of the dataset used and explains the computer system configuration, parameter settings, and performance metrics.
Section 6 presents the experiment and discussion. Finally,
Section 7 concludes the paper with an outline of future work.
2. Background on Machine Learning and Deep Learning
Deep learning (DL) is a subset of the machine learning (ML) branch, the third generation of artificial neural networks. The principal objective of DL is the simulation of high-level data abstractions [
19,
20,
21]. Different DL utilizes numerous layers to remove upper-level functions progressively from the raw data. DL produces several neuron layers, organized layer per layer.
For computer vision and image processing, there are numerous architectures of various types, such as generative adversarial networks (GANs) [
22], convolutional neural networks (CNNs) [
23,
24], and DE convolutional networks [
25].
CNNs are mainly utilized for images. CNNs are new deep learning algorithms suggested by Badrinarayana [
24]. CNN lines distinguish among the weights of different artifacts in the image. This approach needs less pre-processing comparing with other shallow classification algorithms [
26]. For input images, a CNN uses filters to capture spatial and time dependencies [
27]. In CNNs, the height, m, and width, n, and r correspond to the channel number or depth. The input is separated by m and r instead of the three input components,
. There are several kernels of size
k in every convolution layer [
28]. As mentioned previously, the filtering is the base of relations, along with the development of k maps of each size (
m,
m, 1), each with the same parameters. The convergence layer calculates the point product, similar to MLP, among weights and inputs, except for a small amount of the original volume of the input, as shown in Equation (1). In addition, an activation function for the non-linearity function activates the contribution of the convolutional layers [
27]:
The output of the current k-layer is denoted by
, the kernel or weight of the current layer is indicated by
,
presents the output of the previous layer, and
represents the current bias of the current layer. The number of computational parameters is an essential indicator of a deep learning model’s complexity. The output characteristic maps can be described according to the following formula [
27]:
The input map dimensions are denoted by N and filter dimensions or receptive area by F, while M refers to output map dimensions and S to the stride length. Usually, padding is used to guarantee input and output during convolution operations that are the same size.
The padding number varies according to the kernel size. The number of rows and columns for padding is calculated in Equation (3) [
29].
where the amount of padding is symbolized by
, and
F represents the dimensions of the kernels.
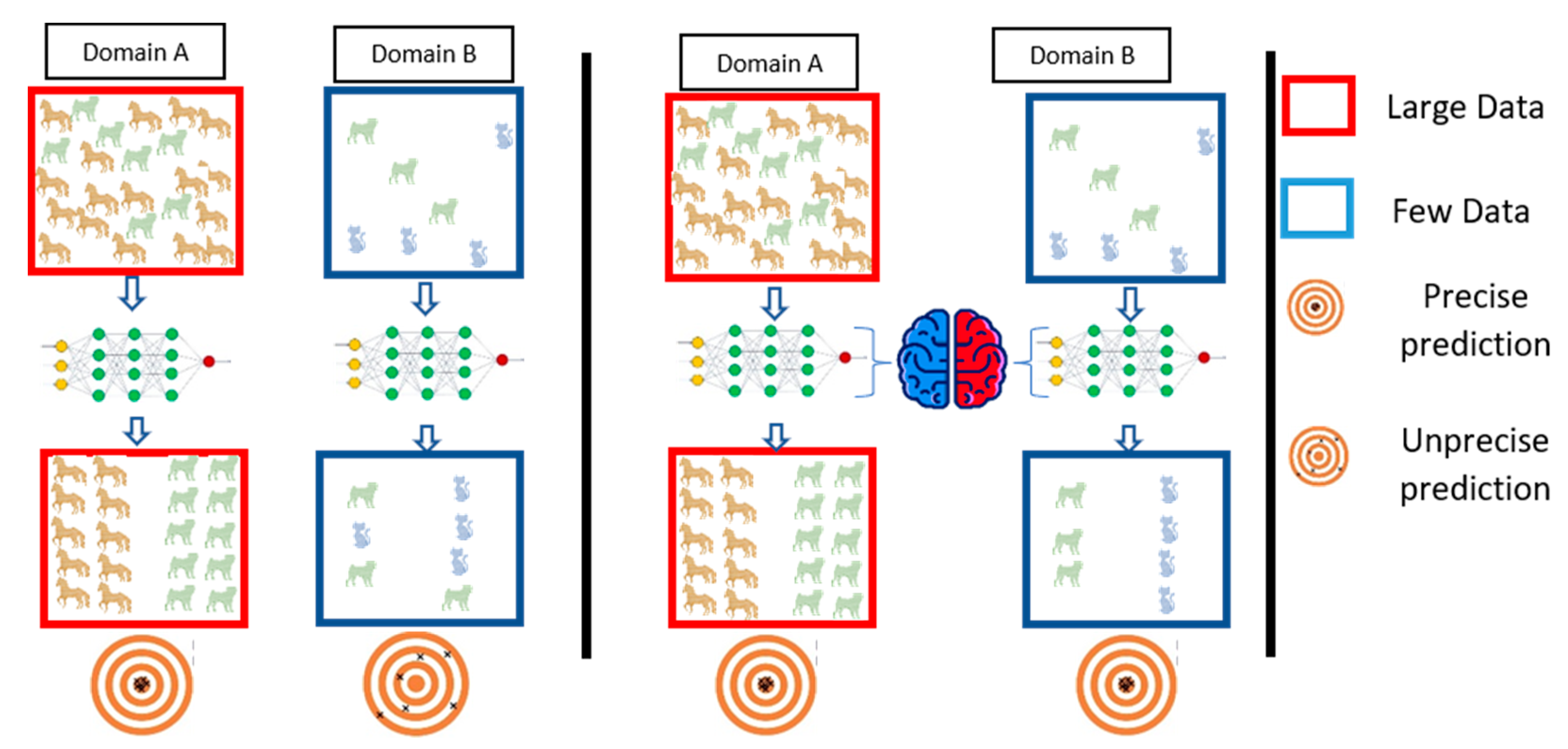
One of the most important principles in computer engineering is the reusability of components. In turn, many architectures have been introduced, including AlexNet, ResNet-50, ResNet-101, VGG-16, and VGG-19 [
27,
30]. Therefore, we intend to reuse the model regards to transfer learning guidelines. The transfer learning process reuses information from the source domain in the target domain [
31]. See
Figure 2 for extra explanation. Parameter optimization, structural reformulation, regularization, etc., are different improvement categories that were interested by many research communities. However, the main drive in CNN performance improvement appears to have come from the rearrangement of processing units and the design of new blocks. The majority of advancements in CNN designs have been carried out in the areas of depth and spatial exploitation to develop an excellent internal representation from raw pixels without requiring extensive processing.
AlexNet is considered as a type of feed-forward CNN with depth of eight layers and a spatial exploitation architecture [
32]. It has five convolution layers (conv1 through conv5) as well as three completely connected layers (fc6, fc7, fc8) [
33]. It was trained by classifying 1 million photos into 1000 different categories [
23].
VGG-16 was trained using the same training set used for AlexNet. It contains three fully connected layers (fc6, fc7, fc8) and five convolutional blocks comprising 13 convolutional layers [
34]. On the other hand, VGG-19 comprises 19 layers, including five convolutional blocks of 16 convolutional layers and three fully connected layers (fc6, fc7, and fc8).
Each ResNet type, such as ResNet-50 and ResNet-101, has its residual block. ResNet-50 is a 50-layer network that is cascaded from a convolution layer to 16 residual blocks within the network and finally to a fully linked layer. ResNet-101 has a total of 101 layers and 33 residual blocks [
35].
Table 1 shows how contemporary models compare in terms of error, network parameters, the maximum number of connections, and more.
Machine learning (ML) algorithms are known for learning underlying relationships in data and making decisions without the need for explicit instructions. The capacity of a CNN to utilize spatial or temporal correlation in data is one of its most appealing features. A support vector machine (SVM) is a shallow classification algorithm developed by Vapnik [
36]. The SVM is classification algorithm reduces learning steps and offers a quicker solution than other common algorithms [
37,
38]. The SVM classifier is built on the concept of the most appropriate hyper-planes, which are used to differentiate between two classes, positive or negative as shown in Equation (4) [
39] by including the central function.
3. Brief Coverage of Previous Works
Many researchers are currently encouraged to establish early detection models to detect COVID-19 infection before outbreak:
Zhou Tao et al. [
40] proposed EDL_COVID (an ensemble deep learning model) to detect COVID-19 disease from 2933 CT images. The proposed model depends on the three ensemble models AlexNet, GoogleNet, and ResNet.
An ensemble strategy was proposed by Rohit Kundu et al. [
41] for detecting COVID-19 in CT scan images for human lungs. They employed two datasets of CT scan images to create decision scores for the proposed ensemble model utilizing three CNN models: VGG-11, ResNet-50-2, and Inception v3.
The authors proposed a deep convolutional 3D neural network called DeCoVNet to identify COVID-19 from CT images [
15]. Thus, when COVID-19 was diagnosed, the algorithm worked in a black box because it focused on DL and was still at an early stage of explanatory ability.
COVNET [
16] has developed and tested the efficiency of COVID-19 detection utilizing chest CT. The researchers have proposed a 3D deep learning system. The robustness evaluation of the model included community-acquired pneumonia (CAP) and other non-pneumonia exams.
In contrast with the RT-PCR assay of COVID-19, Yang et al. [
18] assessed the agnostic and consistency value of chest CT. They suggested that chest CT should be considered, particularly in epidemic areas with a high preliminary possibility of disease for screening of COVID-19, comprehensive assessment, and follow-up.
Horri et al. [
32] used three different methods of physician imaging (X-ray, ultrasound, and CT) for diagnosing COVID-19 stably and automatically. They utilized a deep VGG transmission learning network to refine their analysis. The accuracy of their classification was stated to be 86 percent, 84 percent, and 100 percent for three different datasets.
Ying et al. obtained a 94% accuracy and a 99% AUC with CT images utilizing a deep model based on ResNet50, known as DRE-Net [
42]. They also considered an approach for target identification, i.e., indicating the areas of concern with bounding boxes [
43]. VGG architecture [
44] has been used to diagnose symptomatic lung regions [
34]. A suggested method distinguishes cases of pneumonia (CAP) and non-pneumonia from COVID-19 (NP) in the population.
Jiang et al. [
15] proposed an early screening strategy using pulmonary CT imaging to distinguish COVID-19 mutations from viral influenza pneumonia and stable cases. Several CNN models were suggested and utilized to identify the CT image datasets and quantify the risk of infection with COVID-19. The results may be beneficial in deep learning technologies for the early screening of COVID-19 patients. In the classic ResNet for feature extraction, the authors have proposed a location-attention mechanism.
The AIMDP model was suggested [
42] for use with mutable artificial intelligent techniques to improve the model’s diagnosis and predictive role. The authors [
32] developed a framework focused on the deep learning of the detection of CT viral pneumonia.
The authors in [
44] also provide an overview of the most recent artificial intelligence systems in X-ray images for COVID-19 diagnostics. However, they used X-ray images, as their work was based on this only. To estimate COVID-19 diagnostics, Ghoshal et al. [
45] presented a Bayesian convolutional neural network, differentiating between COVID-19 and non-COVID-19 cases, with a 92.9 percent accuracy. Binary classification was carried out by Narin et al. [
46] for detecting COVID-19 to achieve the best accuracy of 98.0% with ResNet50 models, compared to the various deep learning (DL) models. Zhang et al. [
47] submitted the COVID-19 (0.952 AUC) ResNet model to illustrate the pneumonia areas affected by applying the Grad-CAM approach for the gradient activation.
Finally, Wang et al. [
48] suggest a deep CNN rated as 83.5 percent accurate between the VCOVID-19, non-COVID-19, and uninfected cases.
These studies have provided detailed solutions for combating the pandemic COVID-19. However, there are certain drawbacks to be taken into account. In the best case, researchers used small datasets of fewer than 400 images of COVID-19. In some cases, only 10 X-ray images were used for the COVID-19 class to validate the framework. Furthermore, there was no ground for comparison or medical surveillance with the obtained results, which can suggest not only COVID-19 identification but also the location of influenced areas in the lungs. For iteratively sliced COVID-19 identification using X-ray pictures, a deep learning model ensemble is proposed [
49]. This research made use of a CNN and a set of pre-trained models. The proposed algorithm enhances memory efficiency while reducing complexity.
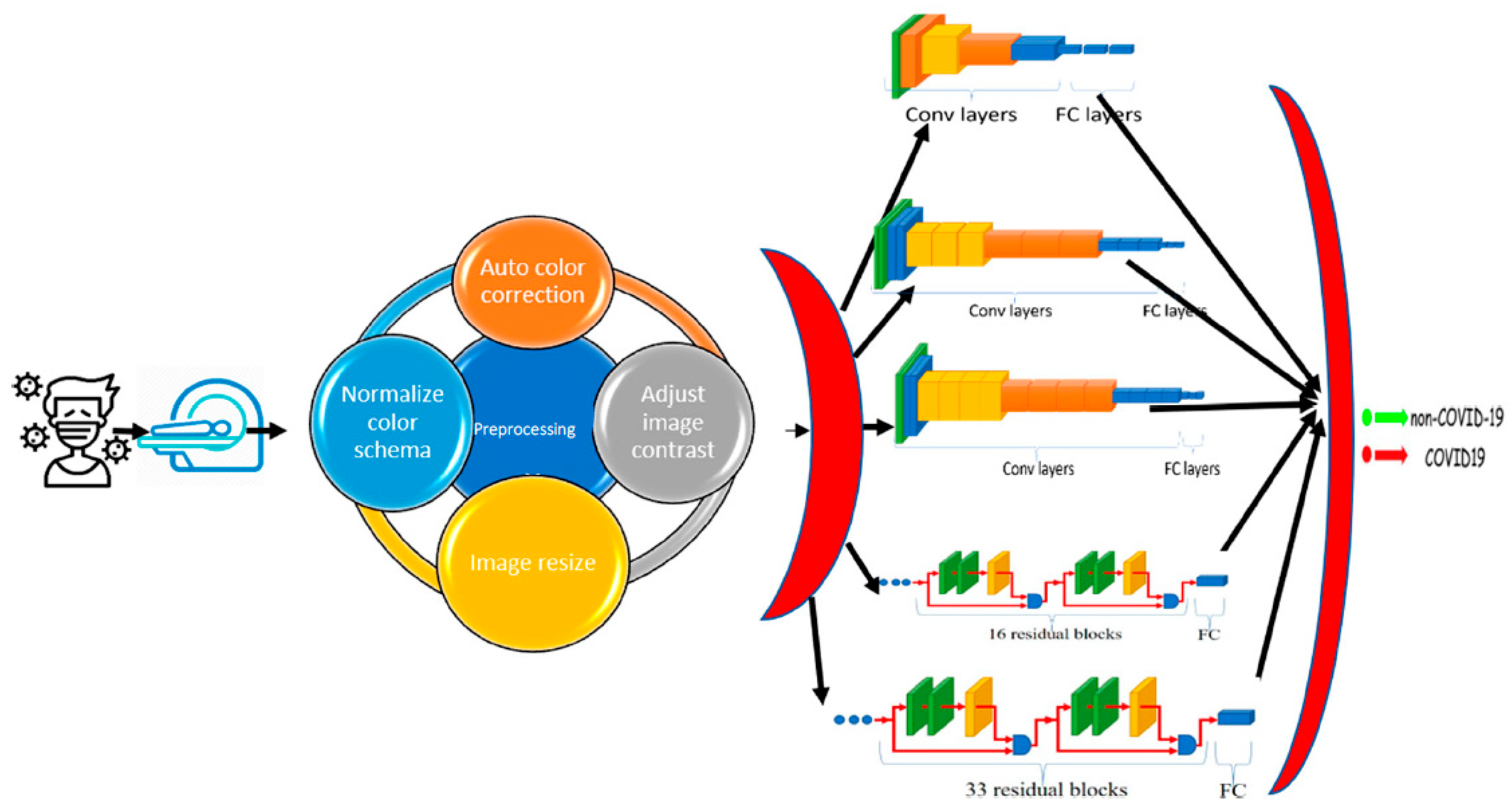
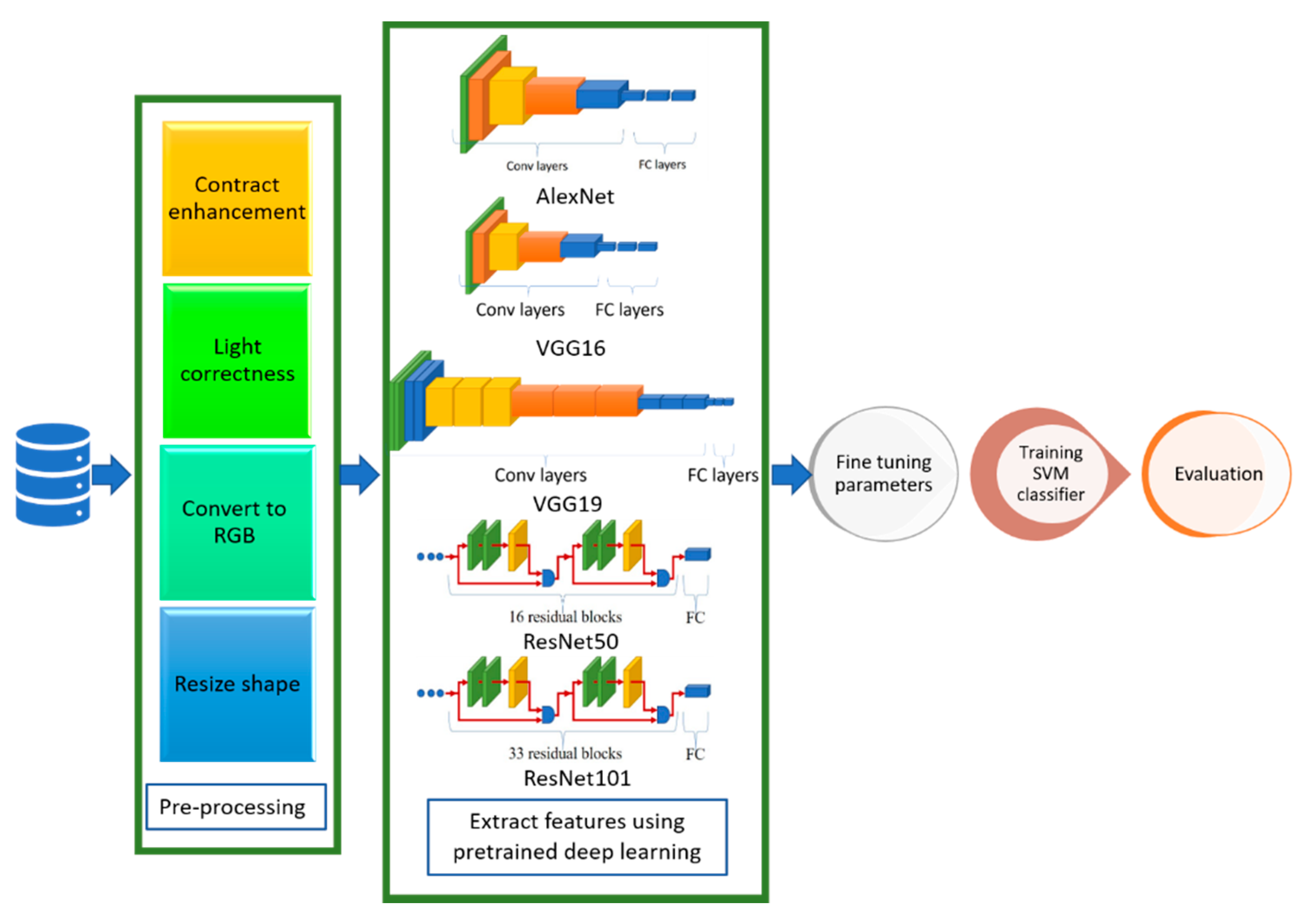
4. Architecture of the Smart CAD System
The proposed CAD system depends on deep learning, transfer learning, and shallow machine learning. In deep learning, multi-hidden layers are stacked for learning objects. These layers require a training process including “fine-tuning” to slightly adjust the weights of the DNN found in pre-training during the backpropagation procedure. Hence, DL nets can extract, classify the features, and effectively make a precise decision after an efficient training process. Transfer learning is used in the proposed CAD system to optimize multiple CNN architectures for datasets. However, the transfer-learning methodology generates optimal fitted CNNs for the datasets capable of classifying and diagnosing infection of COVID-19 scan images. In addition, these fine-tuned models can extract the feature set usable by the different shallow classifiers.
Figure 3 shows a context diagram starting from scanning the image of the inspected case until detecting the infection response using the proposed smart CAD system, in which there are key components comprising the proposed CAD system, including:
Scanning: The source of the input image used to check the status of COVID-19 infection. The supported format of scans can be either CT or CXR images.
Pre-processing: A set of procedures performed for every newly scanned image before investigating the diagnosis process. It comprises auto color correction, auto contrast enhancement, resizing the image to the standard size, and normalizing color channels.
Diagnosing: A key component of the medical CAD system to detect, assist, and advise the doctors in their inspection and symptom analysis during the examination process. It can be divided into:
- ✓
Classification: A vital component of the smart CAD system in which different architectures can be alternately used. These models are responsible for extracting the features and the classification.
- ✓
Decision Unit: This depends on the most common and powerful DL activation function, ReLu. It is a subsequent responsibility of the classification component to make a decision.
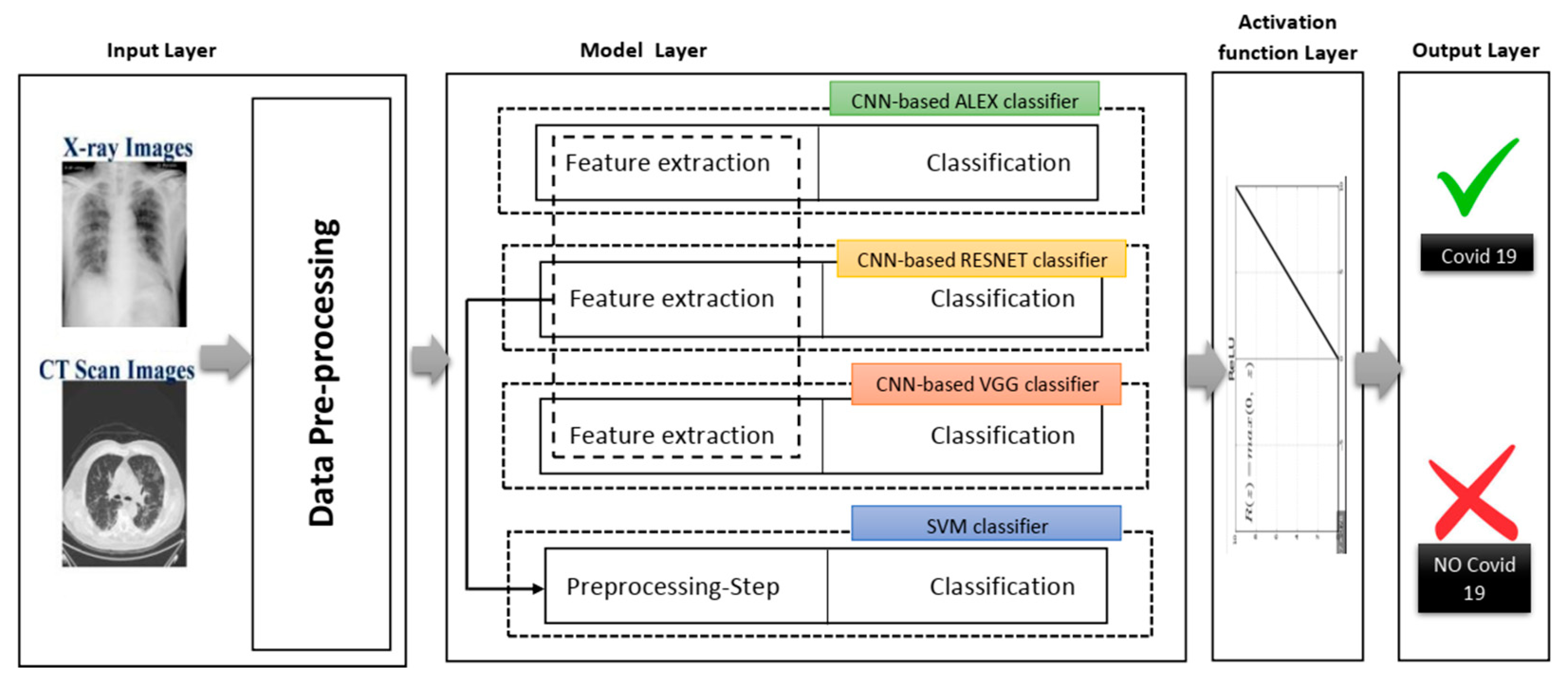
Figure 4 shows different phases of the proposed system in a layered sub-black box style, in which the essential layers are briefly described for the proposed smart CAD system. According to current knowledge, all COVID-19 detection systems consist of a few significant layers: input data, model layer, activation layer, and model layer output for CXR or CT scan image analysis. In turn, the classification and decision in every CAD system using deep learning must include a collection of these different layers. Each group of these layers with a specific order is called a network architecture starting from input layer to output layer (e.g., AlexNet, VGG-16, VGG-19). Next, a brief description defining each role is discussed in detail along with its importance for the medical CAD system.
4.1. Input Layer
This layer reads the image data collection in advance. In other words, the CXR and the CT scan images are pre-processed independently. In the pre-processing phase, the images are reconstructed and resized. The images are taken from various sources, and their dimensions vary since the taken images from medical instruments were created from several letters, arts and crafts, and medical symbols. Moreover, the model layer of each of these products needs separate image dimensions to be managed. Therefore, the input image size was adjusted to fit the templates used in this analysis rather than cutting the lung and chest area as far as possible.
4.2. Model Layer
This layer represents the leading layer of the proposed smart CAD system, in which most calculations are carried out. The calculations include extracting image dataset features and preserving the spatial relationship between image pixels. Next, the data are moved from the input layer to the model layer. This layer contains four sub-black boxes. The CNN-based AlexNet was used with the aim of utilizing AlexNet’s pre-trained approach to diagnose COVID-19. The second sub-layer is the CNN-based RESNET of two versions RESNET50 and RESNET101, distinguished from other architectures by adding to the model blocks that feed the values into their following layers. This value changes the device value as described by adding a block every two layers between the linear and the ReLu activation codes. However, ResNet101 architecture uses more layers than the blocks of ResNet50 with three layers. The ResNet50 model offers fast training and considerable benefit because image residuals are learned rather than functionality [
35].
The third sub-layer is the VGG sub-layer based on the CNN. Although it is a single model, the main advantage related to previous versions is that the CNN models are commonly used, so they are organized more thoroughly and accompanied by two- or three-color layers. VGG has a strong representation of features, and the model can serve as a helpful extractor for new images [
34]. The last sub-layer is the SVM classification. Since the SVM is a good classification algorithm, it can be used to classify features that have already extracted. The methods used for feature extraction were derived from previous sub-layers (see
Figure 5).
4.3. Activation Layer
This layer is a non-linear map of CNN architectures that works at the end of the learning phase to replace negative pixel values with zero in the convolved functions.
4.4. Output Layer
Based on the output score of the activation layer, the final response of classification is provided as an output label. The resulting label can be numerically categorized or encoded; for example, “0” is marked with COVID-19 (i.e., the positive event), “1” is marked with regular cases, and “2” is marked with other cases of pneumonia, etc.
7. Discussion
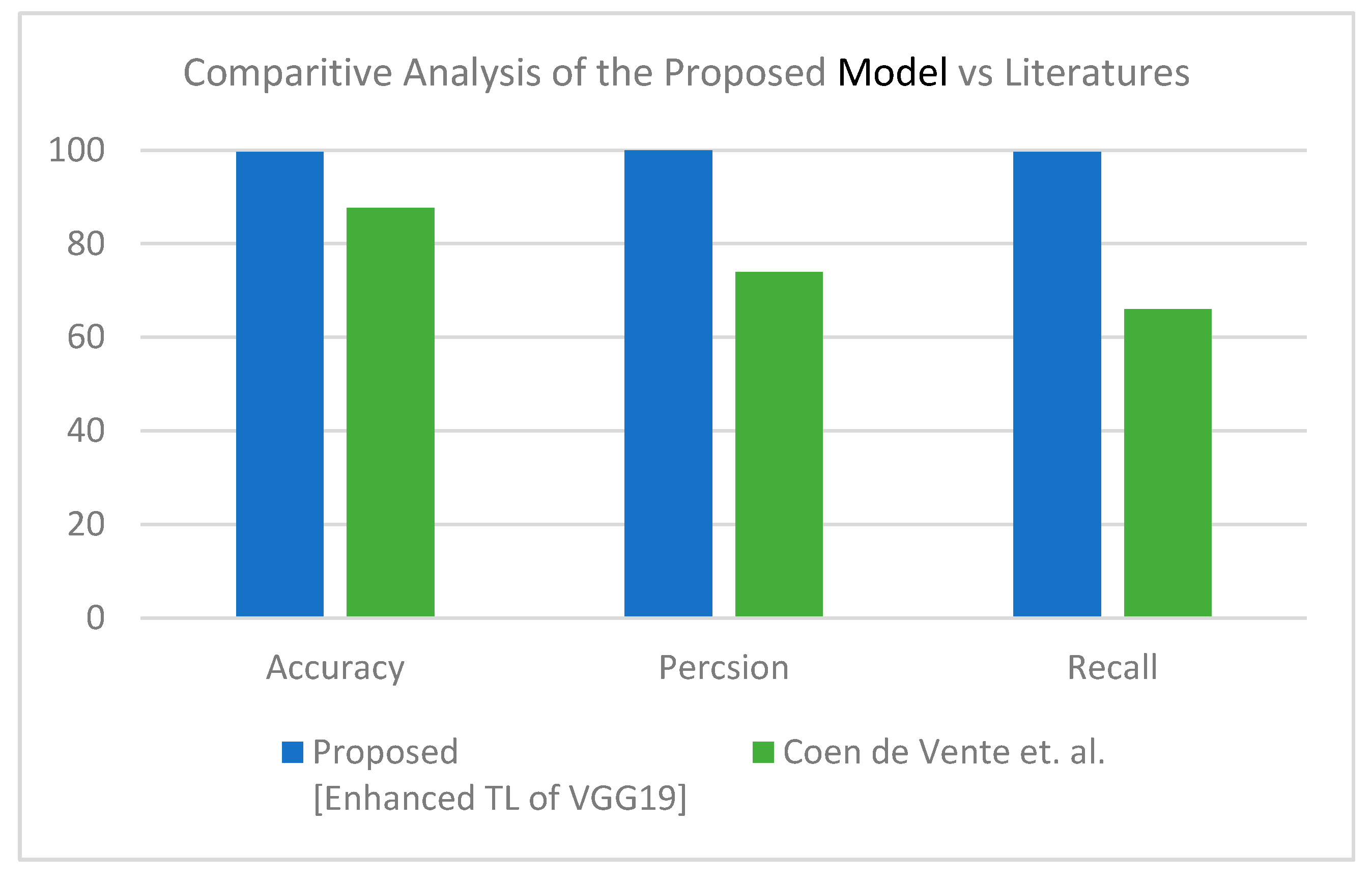
This section discusses the superiority of the proposed models versus the related models in recent literature studies. The proposed model has multi-source scan images based on modularity, including CT scan and X-ray images. First, for the CT scan,
Table 10 shows our proposed model deducted from the comparative study in
Table 4 and the literature for the same dataset and inputs—results of this experiment are visualized in
Figure 8. The second scenario was performed on the three-class label for the same dataset. All comparative results were replicated according to the three-class label dataset, as shown in
Table 11 and
Figure 9. In turn, the experiments were carried out in which the end-to-end VGG16 with the binary class demonstrated its superiority to the hybrid model. With three classes, the hybrid model achieved better results, and both showed better results than the comparative study from the literature.
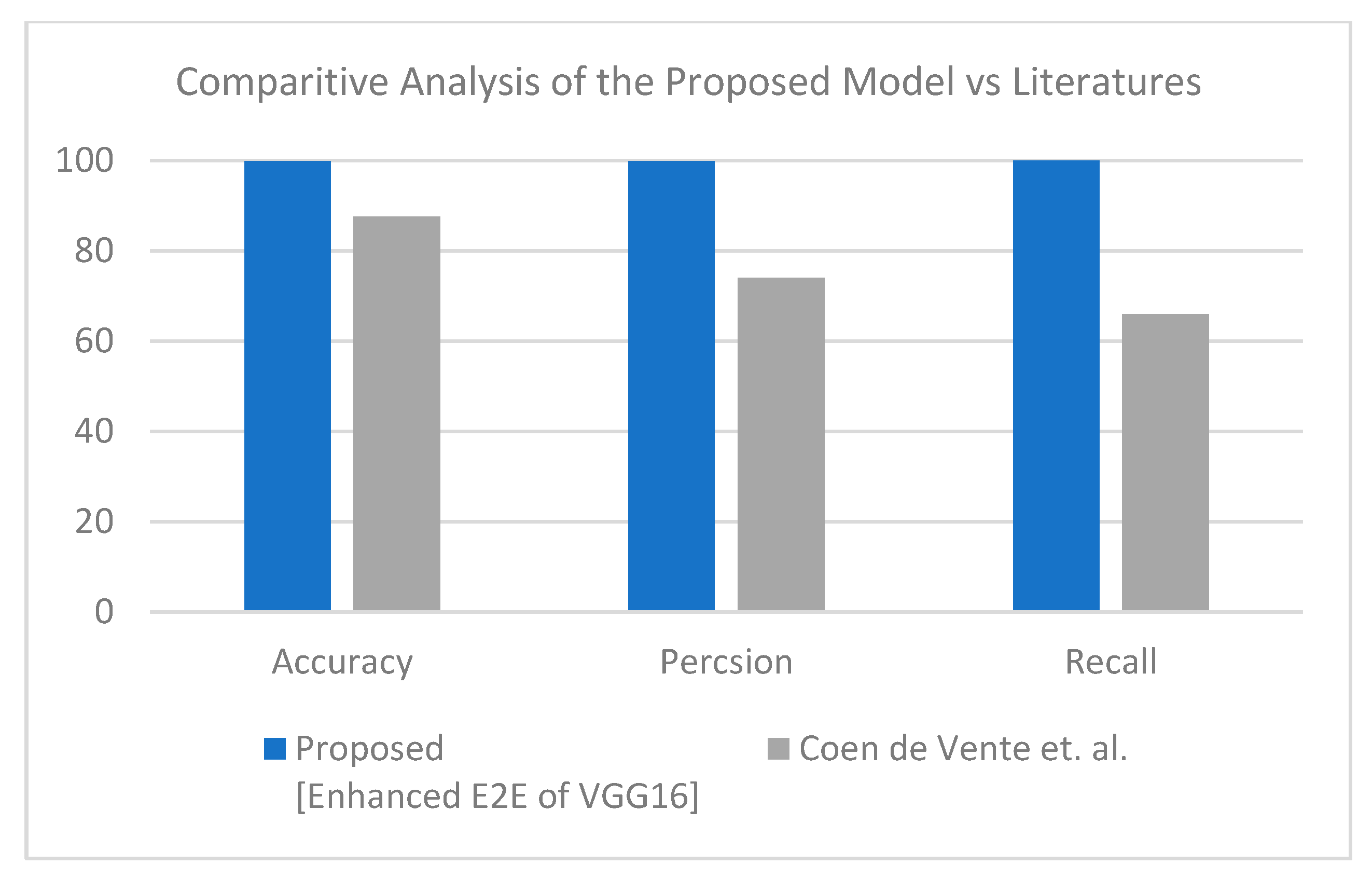
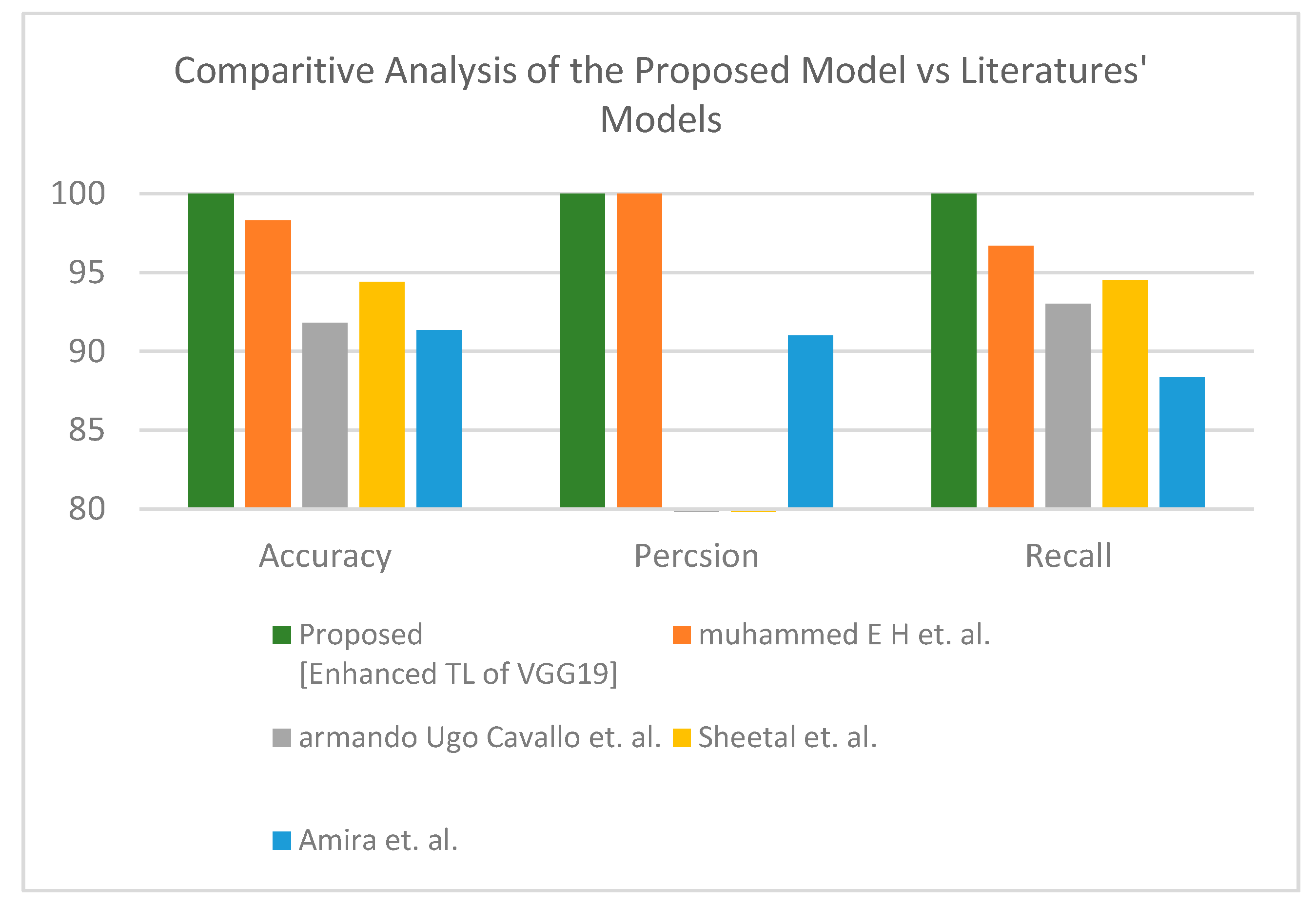
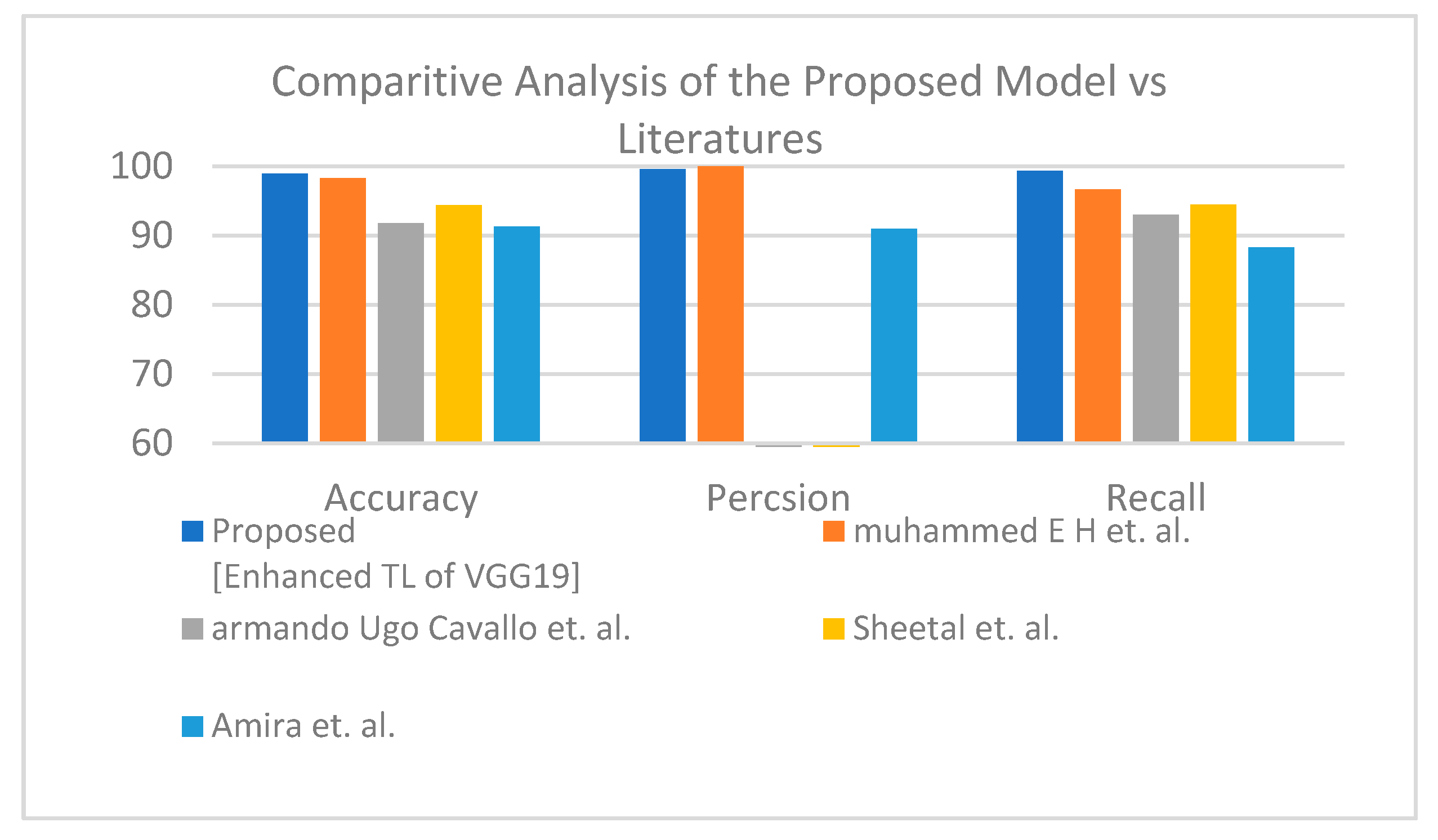
Second is the first X-ray dataset where the proposed model obtained accuracy lower than Muhammed E.H. et al. [
51] of around 0.89%, and the proposed model achieves a much more reasonable recall rate. Consequently, our proposed model does not stick in under-fit or over-fit with regards to a specific label (see
Table 12). The proposed model satisfies the balance classification rates between different labels in the given dataset. Furthermore, the proposed model achieves a notable enhancement compared to others in terms of accuracy, precision, and recall by a significant rate as illustrated in
Figure 10 for binary classification.
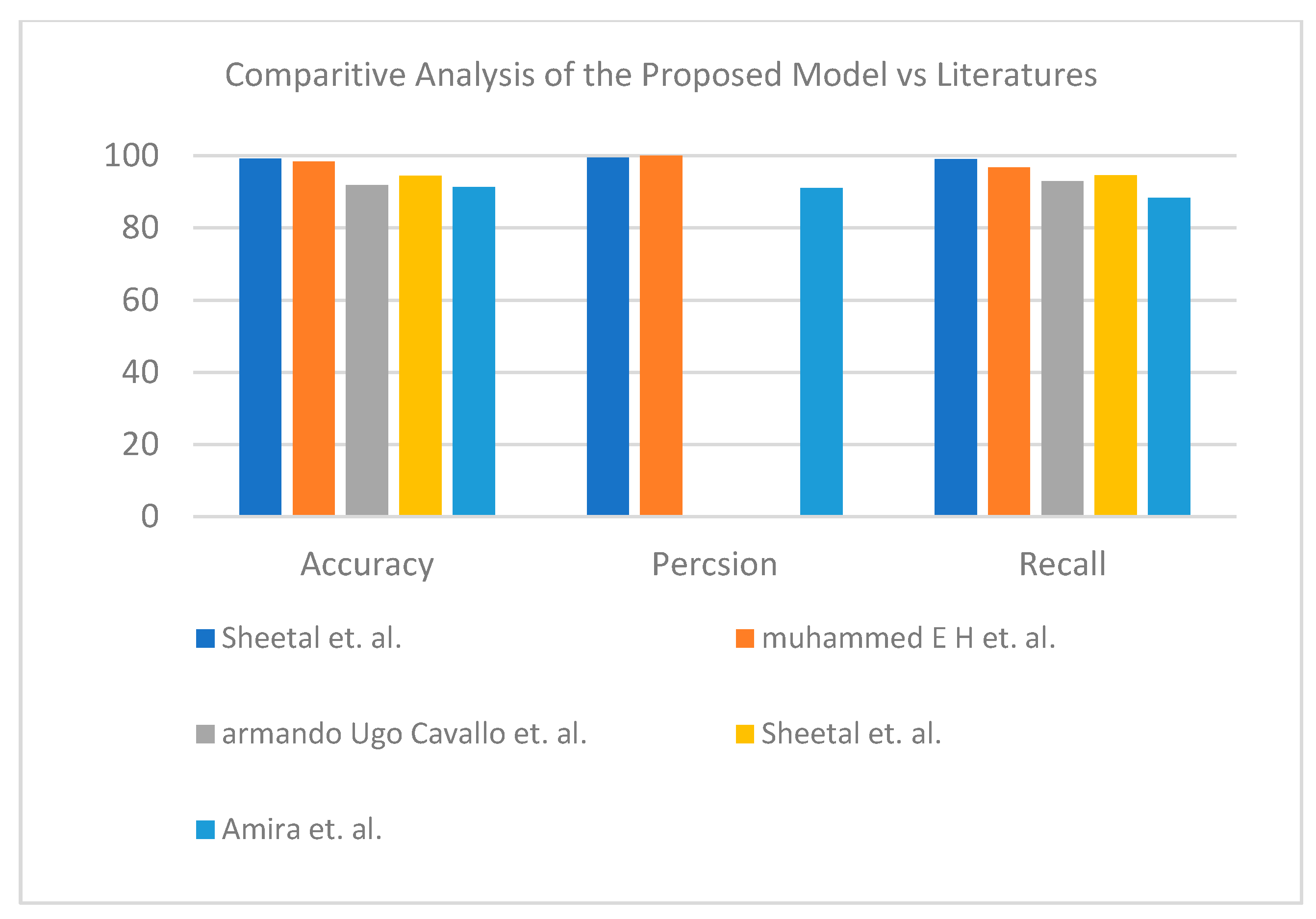
Table 13 and
Figure 11 demonstrate the superiority of the proposed model versus the models in the literature for three classes.
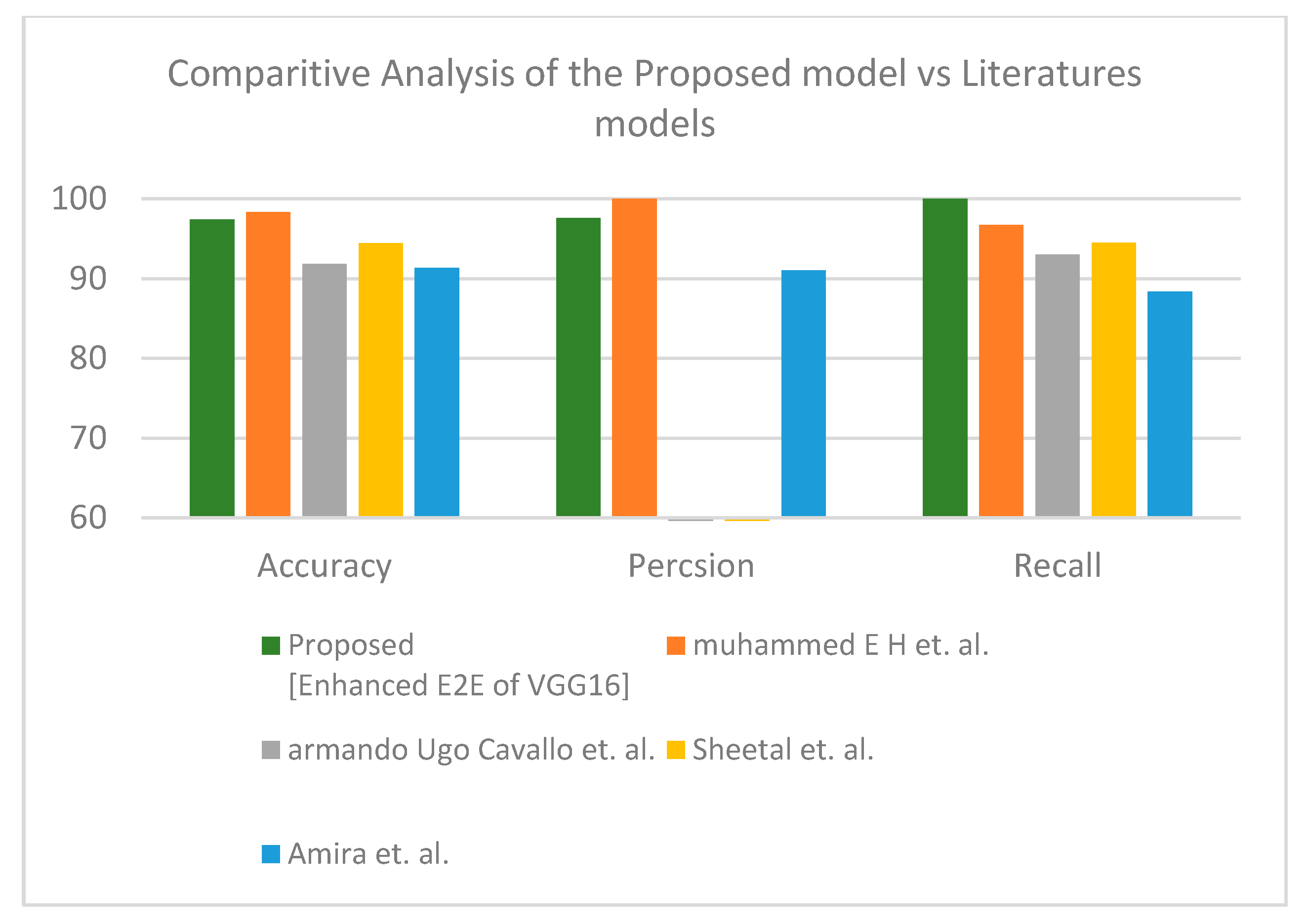
In the third dataset, the hybrid learning solution provided better results than fully deep learning. For the binary label, the proposed enhanced TL VGG16+SVM demonstrated its superiority (see
Table 14).
Figure 12 represents the visual analysis of the proposed model for binary classifier in terms of accuracy, precision, and recall. The proposed enhanced TL VGG19+SVM showed its effectiveness for the three-class label dataset (see
Table 15).
Figure 13 shows a graphical bar chart analysis of the proposed model versus the models in the literature; both binary and multiclass models show improvements in accuracy compared to those in the literature.
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}