




Detection of Liver Tumour Using Deep Learning Based Segmentation with Coot Extreme Learning Model


Abstract
:1. Introduction
2. Related Works
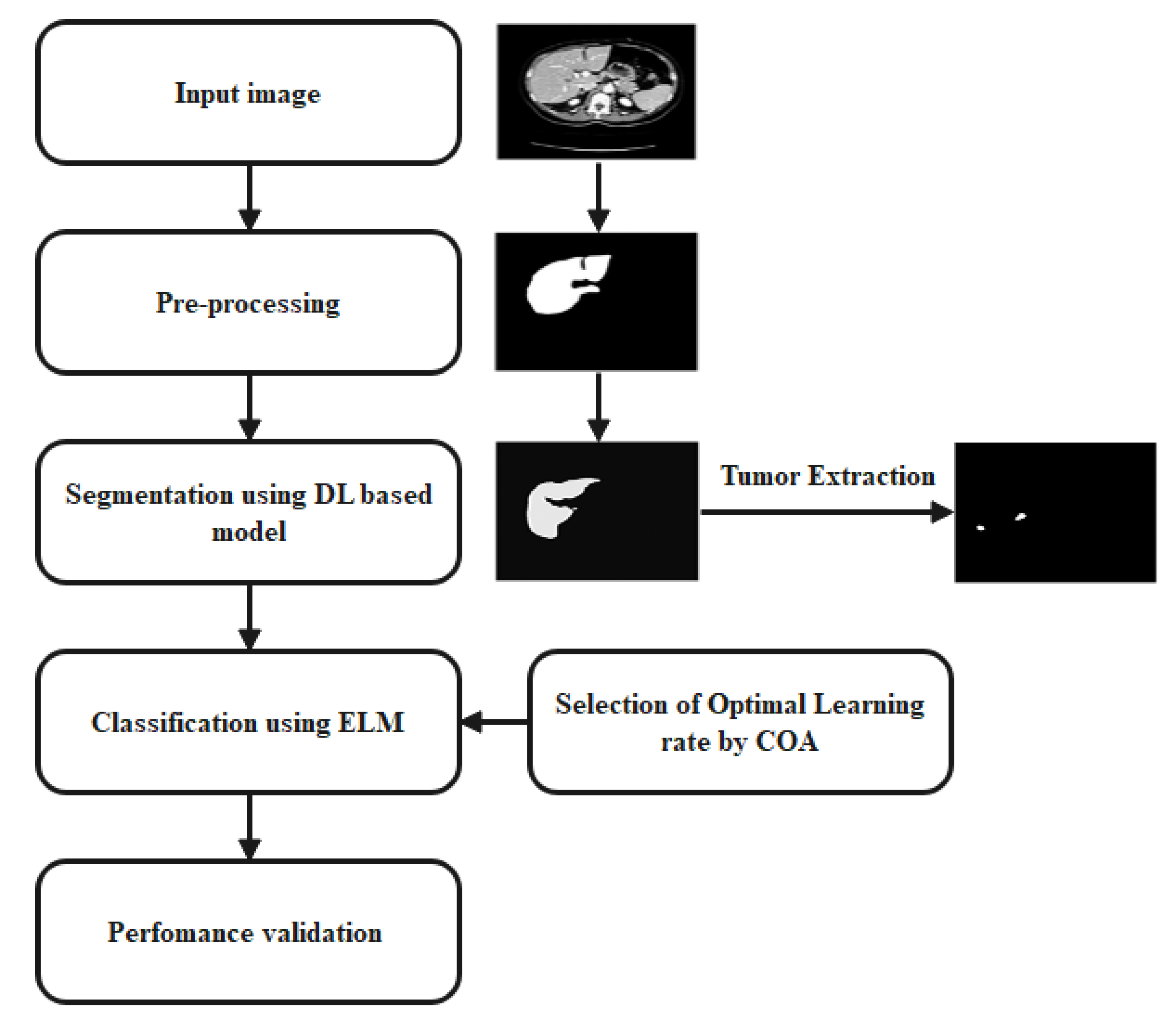
3. A Proposed System
3.1. Dataset Selection
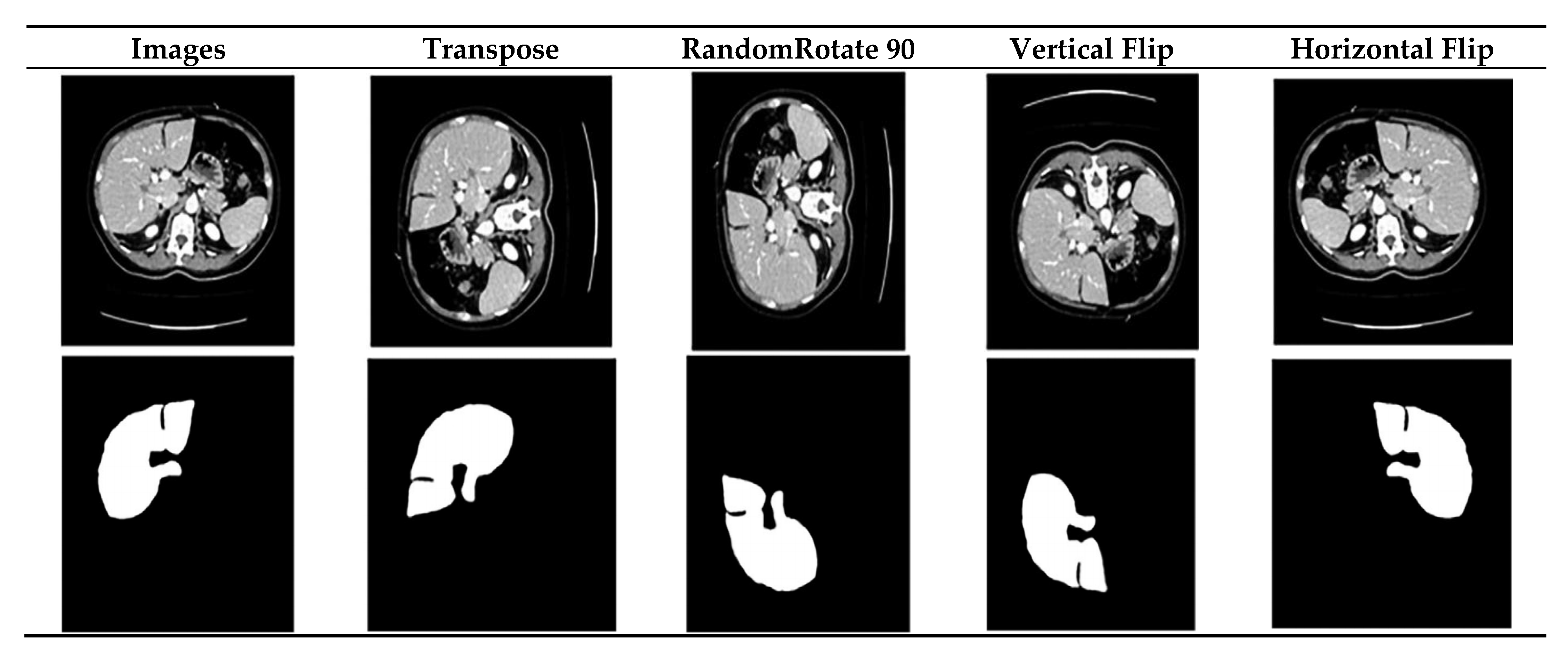
3.2. Data Augmentation
3.3. Data Normalization
3.4. Segmentation
3.4.1. Inner Margin Points
3.4.2. Exponentialized Geodesic Distance Transform
3.4.3. Early Segmentation Constructed on Cue Map and CNN
3.4.4. Refinement Constructed on Data Fusion among Preliminary Segmentation and Extra User Clicks
3.4.5. Gradient Computation
3.4.6. Dividing the Input Image into Cells and Blocks
3.4.7. Construction of the Histogram of Concerned with Gradient Using Selective Sum of Histogram Bins
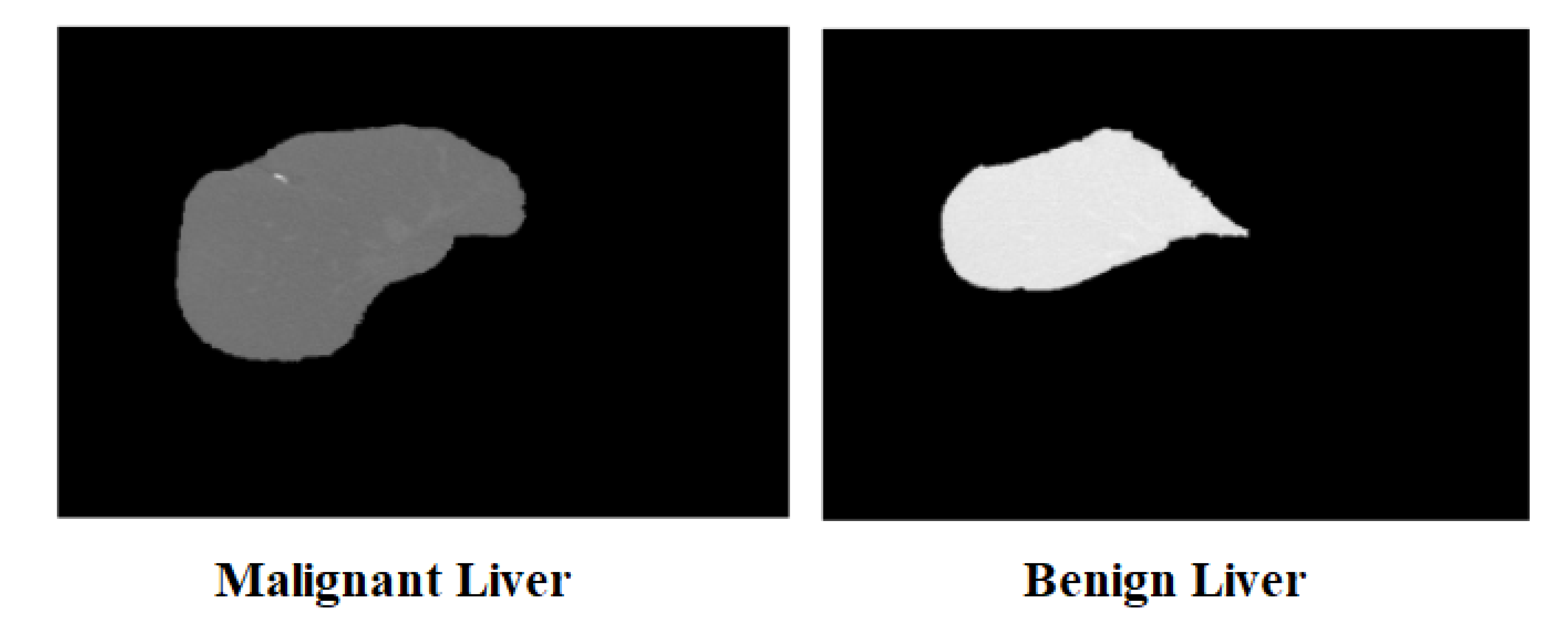
3.5. Classification Using Extreme Learning Machine
3.5.1. Coot Optimization Algorithm
| Algorithm 1: Pseudocode of the COA. |
4. Results and Discussion
4.1. Segmentation Analysis
- Dice Similarity Coefficient
- Jaccard Similarity Coefficient
- Accuracy
- Symmetric Volume Difference
- Sensitivity
- Specificity
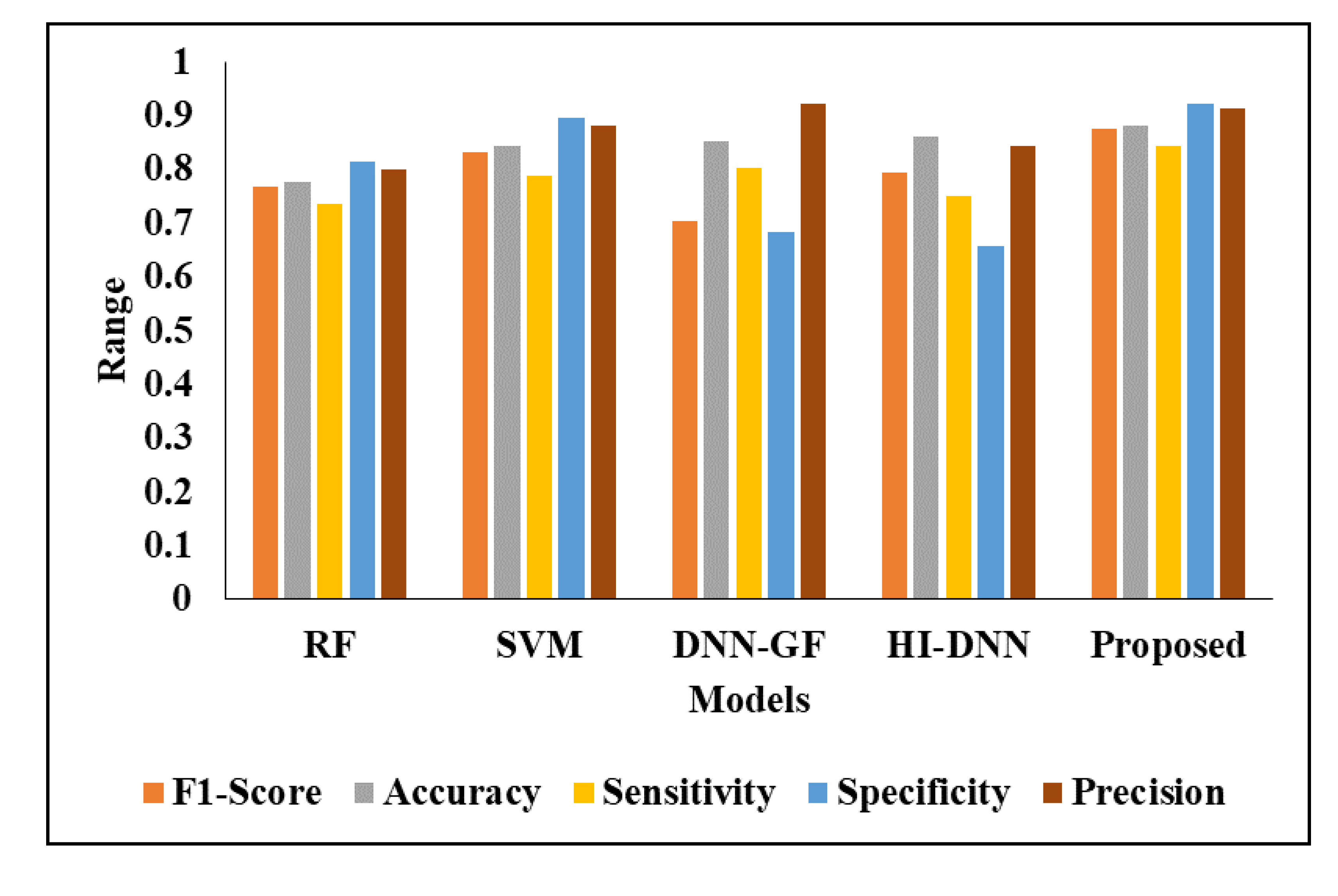
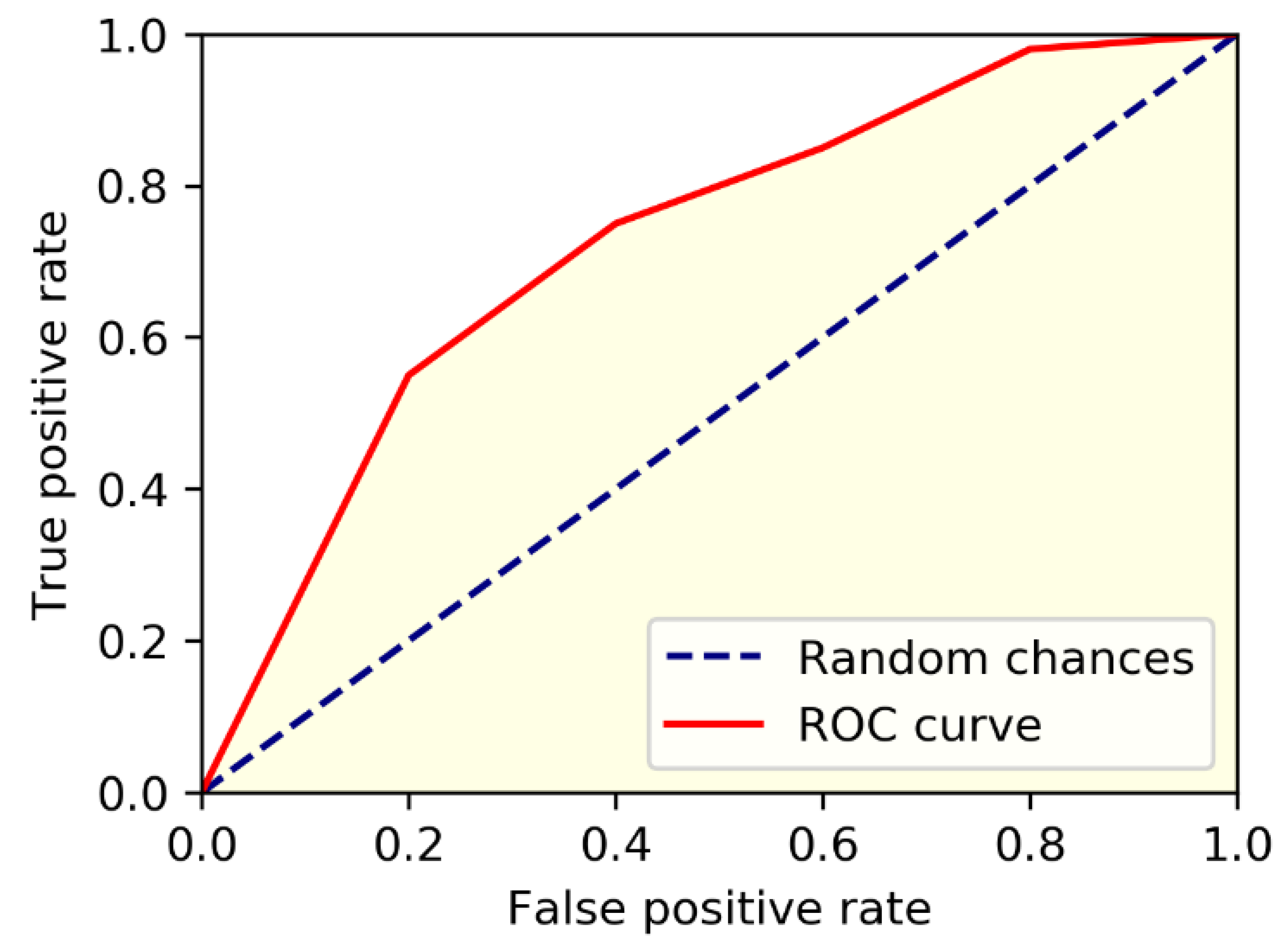
4.2. Classification Analysis
- Evaluation metrics
4.3. Cross-Valdiation Analysis
4.4. Analysis of Proposed Classifier Model on Silver07 Dataset
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Chen, M.; Zhang, B.; Topatana, W.; Cao, J.; Zhu, H.; Juengpanich, S.; Mao, Q.; Yu, H.; Cai, X. Classification and mutation prediction based on histopathology H&E images in liver cancer using deep learning. NPJ Precis. Oncol. 2020, 4, 1–7. [Google Scholar]
- Chaudhary, K.; Poirion, O.B.; Lu, L.; Garmire, L.X. Deep Learning–Based Multi-Omics Integration Robustly Predicts Survival in Liver CancerUsing Deep Learning to Predict Liver Cancer Prognosis. Clin. Cancer Res. 2018, 24, 1248–1259. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Gregory, J.; Burgio, M.D.; Corrias, G.; Vilgrain, V.; Ronot, M. Evaluation of liver tumour response by imaging. JHEP Rep. 2020, 2, 100100. [Google Scholar] [CrossRef]
- Kiani, A.; Uyumazturk, B.; Rajpurkar, P.; Wang, A.; Gao, R.; Jones, E.; Yu, Y.; Langlotz, C.P.; Ball, R.L.; Montine, T.J.; et al. Impact of a deep learning assistant on the histopathologic classification of liver cancer. NPJ Digit. Med. 2020, 3, 23. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Chennam, K.K.; Uma Maheshwari, V.; Aluvalu, R. Maintaining IoT Healthcare Records Using Cloud Storage. In IoT and IoE Driven Smart Cities; Springer: Cham, Switzerland, 2022; pp. 215–233. [Google Scholar]
- Wang, C.J.; Hamm, C.A.; Savic, L.J.; Ferrante, M.; Schobert, I.; Schlachter, T.; Lin, M.; Weinreb, J.C.; Duncan, J.S.; Chapiro, J.; et al. Deep learning for liver tumor diagnosis part II: Convolutional neural network interpretation using radiologic imaging features. Eur. Radiol. 2019, 29, 3348–3357. [Google Scholar] [CrossRef]
- Uma Maheswari, V.; Aluvalu, R.; Chennam, K.K. Application of machine learning algorithms for facial expression analysis. Mach. Learn. Sustain. Dev. 2021, 9, 77–96. [Google Scholar]
- Zhen, S.H.; Cheng, M.; Tao, Y.B.; Wang, Y.F.; Juengpanich, S.; Jiang, Z.Y.; Jiang, Y.K.; Yan, Y.Y.; Lu, W.; Lue, J.M.; et al. Deep learning for accurate diagnosis of liver tumor based on magnetic resonance imaging and clinical data. Front. Oncol. 2020, 10, 680. [Google Scholar] [CrossRef]
- Trivizakis, E.; Manikis, G.C.; Nikiforaki, K.; Drevelegas, K.; Constantinides, M.; Drevelegas, A.; Marias, K. Extending 2-D convolutional neural networks to 3-D for advancing deep learning cancer classification with application to MRI liver tumor differentiation. IEEE J. Biomed. Health Inform. 2018, 23, 923–930. [Google Scholar] [CrossRef] [PubMed]
- Sun, C.; Xu, A.; Liu, D.; Xiong, Z.; Zhao, F.; Ding, W. Deep learning-based classification of liver cancer histopathology images using only global labels. IEEE J. Biomed. Health Inform. 2019, 24, 1643–1651. [Google Scholar] [CrossRef]
- Gruber, N.; Antholzer, S.; Jaschke, W.; Kremser, C.; Haltmeier, M. A joint deep learning approach for automated liver and tumor segmentation. In Proceedings of the 2019 13th International Conference on Sampling Theory and Applications (SampTA), Bordeaux, France, 8–12 July 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 1–5. [Google Scholar]
- Alirr, O.I. Deep learning and level set approach for liver and tumor segmentation from CT scans. J. Appl. Clin. Med. Phys. 2020, 21, 200–209. [Google Scholar] [CrossRef]
- Rahman, A.S.; Shamrat, F.J.M.; Tasnim, Z.; Roy, J.; Hossain, S.A. A comparative study on liver disease prediction using supervised machine learning algorithms. Int. J. Sci. Technol. Res. 2019, 8, 419–422. [Google Scholar]
- Ibragimov, B.; Toesca, D.; Chang, D.; Yuan, Y.; Koong, A.; Xing, L. Development of deep neural network for individualized hepatobiliary toxicity prediction after liver SBRT. Med. Phys. 2018, 45, 4763–4774. [Google Scholar] [CrossRef] [PubMed]
- Budak, Ü.; Guo, Y.; Tanyildizi, E.; Şengür, A. Cascaded deep convolutional encoder-decoder neural networks for efficient liver tumor segmentation. Med. Hypotheses 2020, 134, 109431. [Google Scholar] [CrossRef] [PubMed]
- Amin, J.; Anjum, M.A.; Sharif, M.; Kadry, S.; Nadeem, A.; Ahmad, S.F. Liver tumor localization based on YOLOv3 and 3D-semantic segmentation using deep neural networks. Diagnostics 2022, 12, 823. [Google Scholar] [CrossRef]
- Ashreetha, B.; Devi, M.R.; Kumar, U.P.; Mani, M.K.; Sahu, D.N.; Reddy, P.C.S. Soft optimization techniques for automatic liver cancer detection in abdominal liver images. Int. J. Health Sci. 2022, 6, 10820–10831. [Google Scholar] [CrossRef]
- Ayalew, Y.A.; Fante, K.A.; Mohammed, M.A. Modified U-Net for liver cancer segmentation from computed tomography images with a new class balancing method. BMC Biomed. Eng. 2021, 3, 4. [Google Scholar] [CrossRef]
- Zheng, R.; Wang, Q.; Lv, S.; Li, C.; Wang, C.; Chen, W.; Wang, H. Automatic liver tumor segmentation on dynamic contrast enhanced mri using 4D information: Deep learning model based on 3D convolution and convolutional lstm. IEEE Trans. Med. Imaging 2022, 41, 2965–2976. [Google Scholar] [CrossRef] [PubMed]
- Araújo, J.D.L.; da Cruz, L.B.; Diniz, J.O.B.; Ferreira, J.L.; Silva, A.C.; de Paiva, A.C.; Gattass, M. Liver segmentation from computed tomography images using cascade deep learning. Comput. Biol. Med. 2022, 140, 105095. [Google Scholar] [CrossRef]
- Rela, M.; Suryakari, N.R.; Patil, R.R. A diagnosis system by U-net and deep neural network enabled with optimal feature selection for liver tumor detection using CT images. Multimed. Tools Appl. 2022, 82, 3185–3227. [Google Scholar] [CrossRef]
- Liu, L.; Wang, L.; Xu, D.; Zhang, H.; Sharma, A.; Tiwari, S.; Kaur, M.; Khurana, M.; Shah, M.A. CT image segmentation method of liver tumor based on artificial intelligence enabled medical imaging. Math. Probl. Eng. 2021, 2021, 9919507. [Google Scholar] [CrossRef]
- Sabir, M.W.; Khan, Z.; Saad, N.M.; Khan, D.M.; Al-Khasawneh, M.A.; Perveen, K.; Qayyum, A.; Azhar Ali, S.S. Segmentation of Liver Tumor in CT Scan Using ResU-Net. Appl. Sci. 2022, 12, 8650. [Google Scholar] [CrossRef]
- IRCAD. 2022. Available online: https://www.ircad.fr/research/3dircadb/ (accessed on 5 July 2022).
- Hinton, G.E.; Srivastava, N.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R.R. Improving neural networks by preventing co-adaptation of feature detectors. arXiv 2012, arXiv:1207.0580. [Google Scholar]
- Wan, L.; Zeiler, M.; Zhang, S.; Cun, Y.L.; Fergus, R. Regularization of neural networks using Dropconnect. In Proceedings of the International Conference on Machine Learning, Atlanta, GA, USA, 23–29 June 2013; pp. 1058–1066. [Google Scholar]
- Srivastava, N.; Hinton, G.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R.R. Dropout: A simple way to prevent neural networks from overfitting. J. Mach. Learn. Res. 2014, 15, 1929–1958. [Google Scholar]
- Wang, J.; Lu, S.; Wang, S.H.; Zhang, Y.D. A review on extreme learning machine. Multimed. Tools Appl. 2021, 81, 41611–41660. [Google Scholar] [CrossRef]
- Mostafa, R.R.; Hussien, A.G.; Khan, M.A.; Kadry, S.; Hashim, F.A. Enhanced coot optimization algorithm for dimensionality reduction. In Proceedings of the 2022 Fifth International Conference of Women in Data Science at Prince Sultan University (WiDS PSU), Riyadh, Saudi Arabia, 28–29 March 2022; IEEE: Piscataway, NJ, USA, 2022; pp. 43–48. [Google Scholar]
- Kuran, E.C.; Kuran, U.; Er, M.B. Sub-Image Histogram Equalization using Coot Optimization Algorithm for Segmentation and Parameter Selection. arXiv 2022, arXiv:2205.15565. [Google Scholar]
- Afzal, S.; Maqsood, M.; Nazir, F.; Khan, U.; Aadil, F.; Awan, K.M.; Mehmood, I.; Song, O.-Y. A data augmentation-based framework to handle class imbalance problem for Alzheimer’s stage detection. IEEE Access 2019, 7, 115528–115539. [Google Scholar] [CrossRef]
- Afzal, S.; Maqsood, M.; Mehmood, I.; Niaz, M.T.; Seo, S. An Efficient False-Positive Reduction System for Cerebral Microbleeds Detection. CMC Comput. Mater. Contin. 2021, 66, 2301–2315. [Google Scholar] [CrossRef]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| S. No | Gender | Voxel Dimensions | Slices | Tumours |
| 1 | F | 0.57 × 0.57 × 1.6 | 129 | 7 |
| 2 | F | 0.78 × 0.78 × 1.6 | 172 | 1 |
| 3 | M | 0.62 × 0.62 × 1.25 | 200 | 1 |
| 4 | M | 0.74 × 0.74 × 2.0 | 91 | 7 |
| 5 | M | 0.78 × 0.78 × 1.6 | 139 | 0 |
| 6 | M | 0.78 × 0.78 × 1.6 | 135 | 20 |
| 7 | M | 0.78 × 0.78 × 1.6 | 151 | 0 |
| 8 | F | 0.56 × 0.56 × 1.6 | 124 | 3 |
| 9 | M | 0.87 × 0.87 × 2.0 | 111 | 1 |
| 10 | F | 0.73 × 0.73 × 1.6 | 122 | 8 |
| 11 | M | 0.72 × 0.72 × 1.6 | 132 | 0 |
| 12 | F | 0.68 × 0.68 × 1.0 | 260 | 1 |
| 13 | M | 0.67 × 0.67 × 1.6 | 122 | 20 |
| 14 | F | 0.72 × 0.72 × 1.6 | 113 | 0 |
| 15 | F | 0.78 × 0.78 × 1.6 | 125 | 2 |
| 16 | M | 0.70 × 0.70 × 1.6 | 155 | 1 |
| 17 | M | 0.74 × 0.74 × 1.6 | 119 | 2 |
| 18 | F | 0.74 × 0.74 × 2.5 | 74 | 1 |
| 19 | F | 0.70 × 0.70 × 4.0 | 124 | 46 |
| 20 | F | 0.81 × 0.81 × 2.0 | 225 | 0 |
| Method | Dice Score | Jaccard | Accuracy | Specificity | Sensitivity | SVD |
|---|---|---|---|---|---|---|
| GW-CTO [21] | 67.5 ± 27.8% | 56.0 ± 30.7% | 92 ± 3.8% | 70.1 ± 29.6% | 64.8 ± 32.2% | 0.33 |
| Proposed | 77.11 ± 21.0% | 67.8 ± 26.9% | 93 ± 3.7% | 79.16 ± 20.56% | 76.03 ± 24.56% | 0.23 |
| Method | Dice Score | Jaccard | Accuracy | Specificity | Sensitivity | SVD |
|---|---|---|---|---|---|---|
| GW-CTO [21] | 70.7 ± 24.9 % | 69.5 ± 34.6% | 91 ± 3.9% | 73.5 ± 27.6% | 67.6 ± 33.26 | 0.25 |
| Proposed | 77.54 ± 21.5% | 65.5 ± 32.5% | 92 ± 3.9% | 80.36 ± 4.6% | 77.51 ± 25.66 | 0.22 |
| Metrics | RF | SVM | DNN-GF | HI-DNN | Proposed |
|---|---|---|---|---|---|
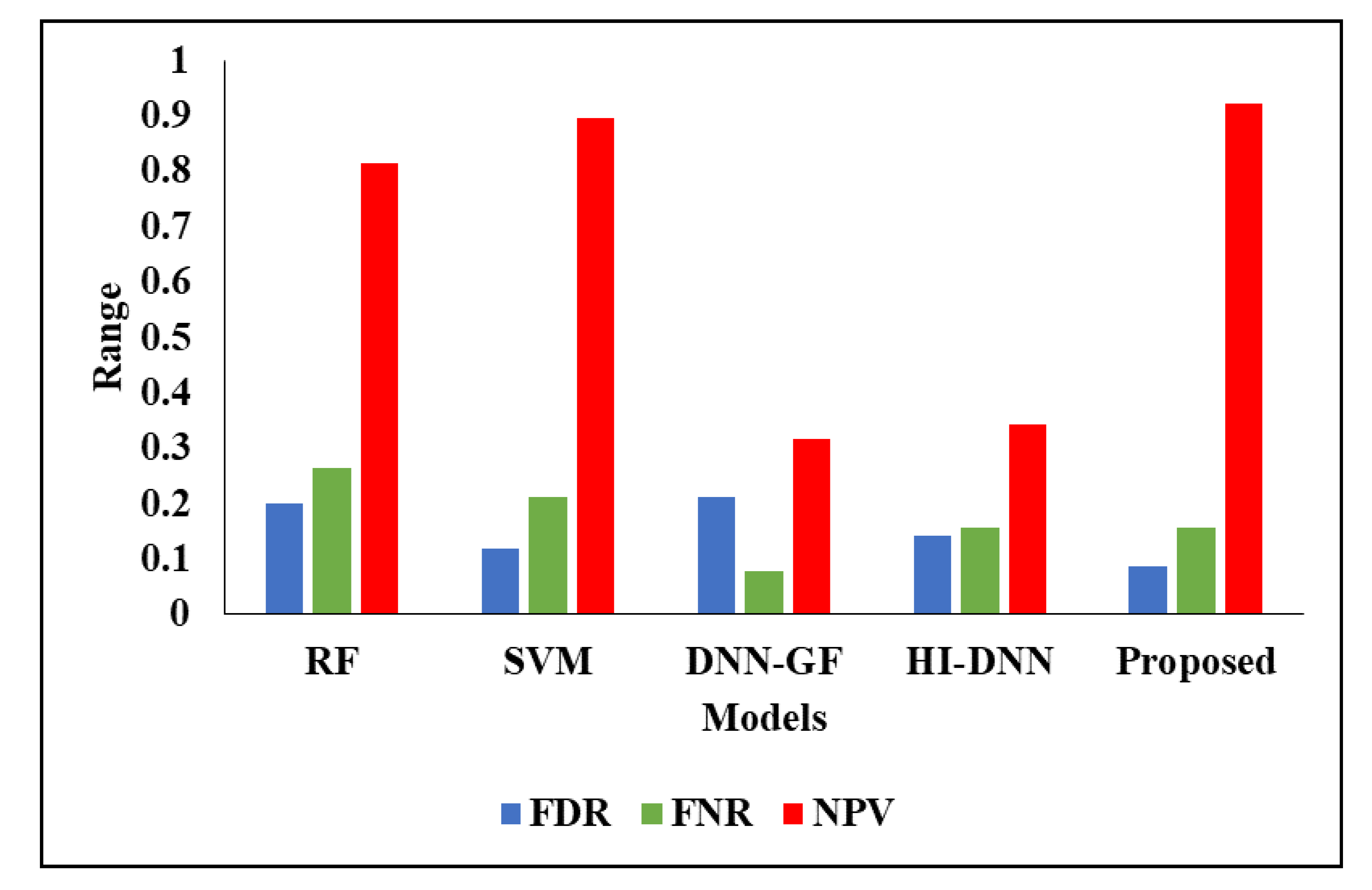
| FDR | 0.2 | 0.11765 | 0.2105 | 0.14211 | 0.085715 |
| F1-Score | 0.76712 | 0.83333 | 0.70345 | 0.79355 | 0.87672 |
| Accuracy | 0.77642 | 0.84211 | 0.85174 | 0.86241 | 0.88258 |
| Sensitivity | 0.73684 | 0.78947 | 0.80263 | 0.75 | 0.84212 |
| Specificity | 0.81579 | 0.89474 | 0.68421 | 0.65789 | 0.92105 |
| FNR | 0.26316 | 0.21053 | 0.078947 | 0.15789 | 0.15789 |
| NPV | 0.81579 | 0.89474 | 0.31579 | 0.34211 | 0.92105 |
| Precision | 0.8 | 0.88235 | 0.92105 | 0.84211 | 0.91429 |
| FPR | 0.18421 | 0.10526 | 0.89655 | 0.80645 | 0.078947 |
| MCC | 0.55436 | 0.68803 | 0.77612 | 0.72464 | 0.76555 |
| Metrics | RF | SVM | DNN-GF [17] | HI-DNN [21] | Proposed |
|---|---|---|---|---|---|
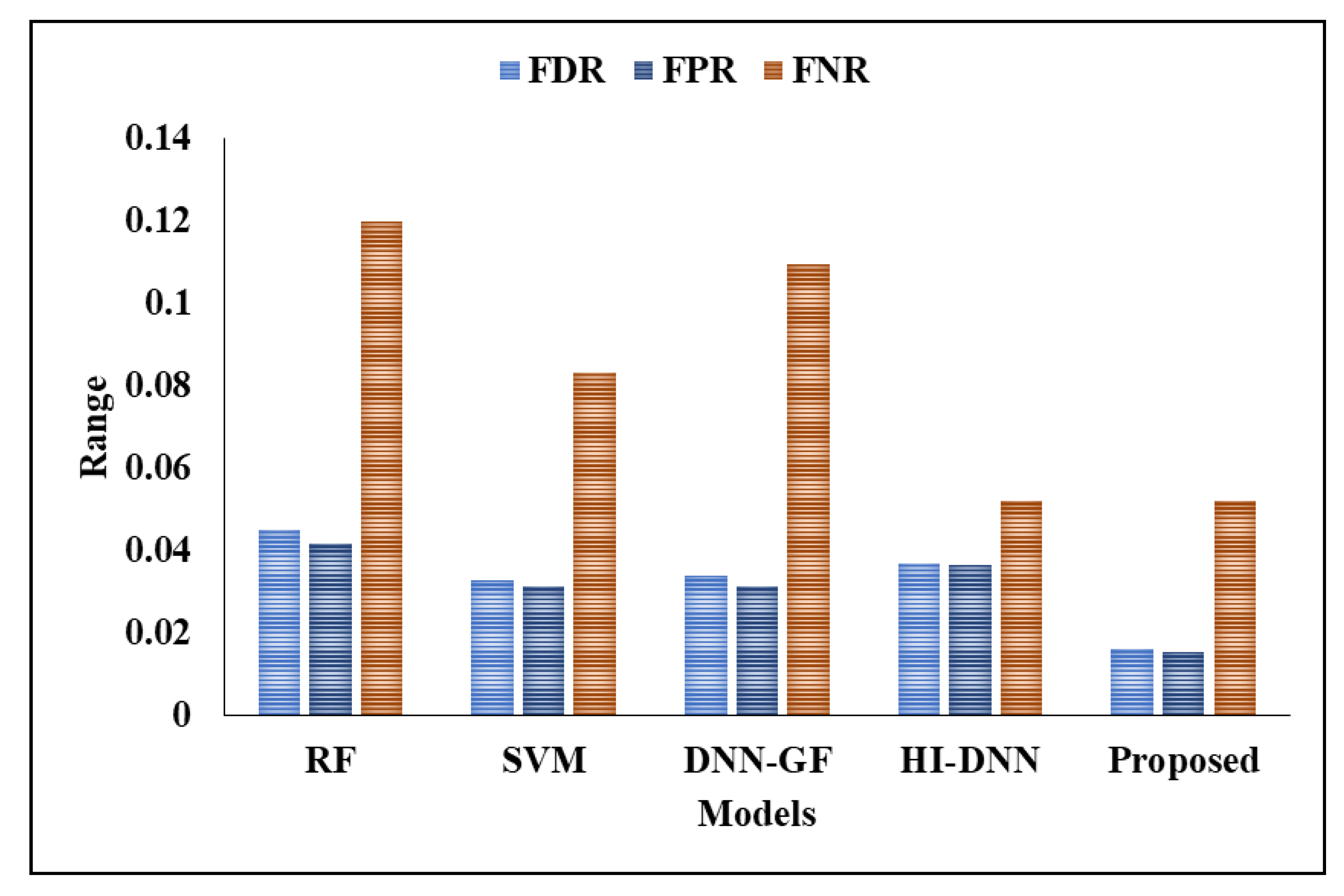
| FDR | 0.045198 | 0.032967 | 0.033898 | 0.037037 | 0.016216 |
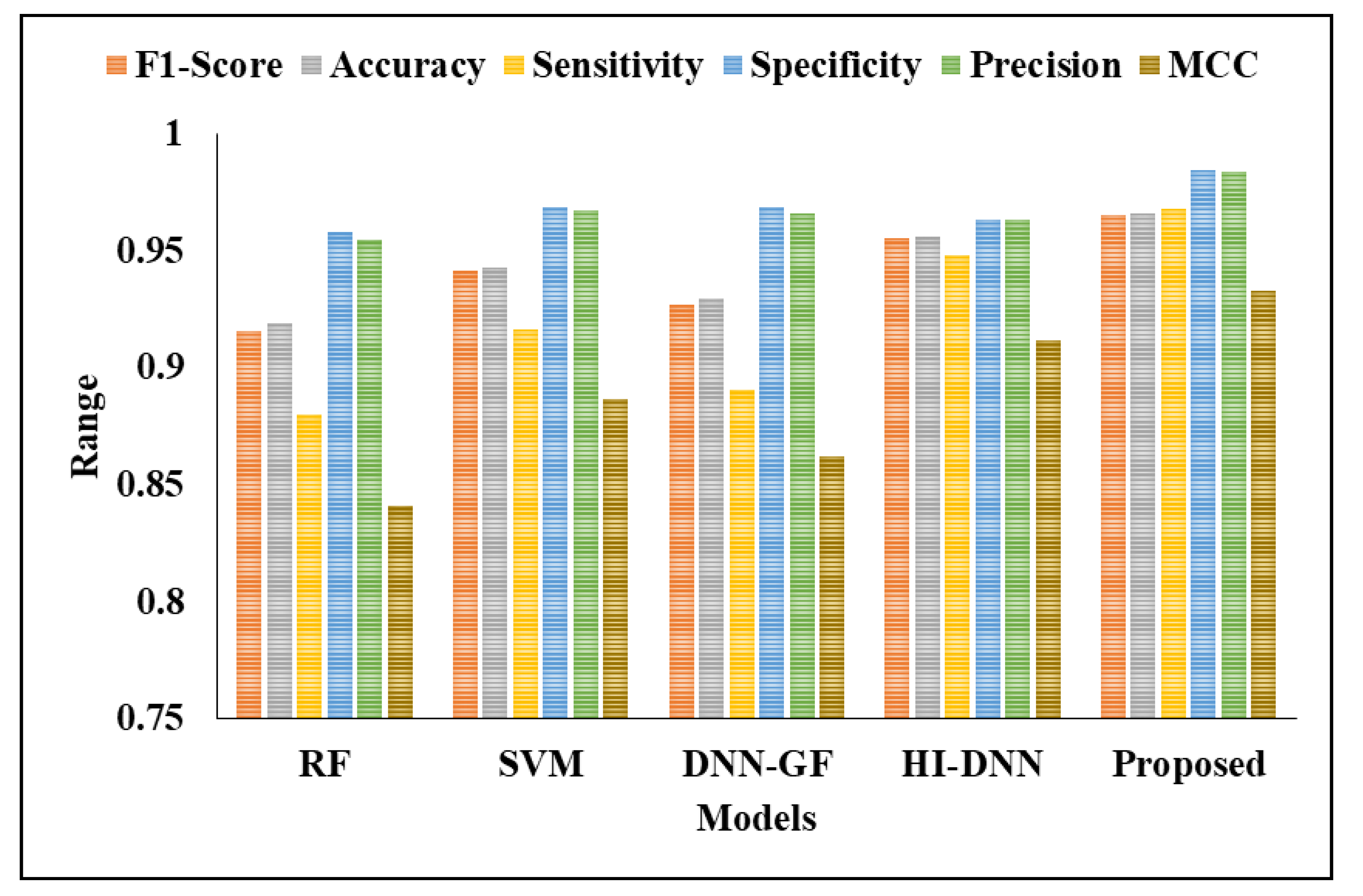
| F1-Score | 0.91599 | 0.94118 | 0.92683 | 0.95539 | 0.96553 |
| Accuracy | 0.91927 | 0.94271 | 0.92969 | 0.95573 | 0.96615 |
| Sensitivity | 0.88021 | 0.91667 | 0.89063 | 0.94892 | 0.96792 |
| Specificity | 0.95833 | 0.96885 | 0.96875 | 0.96354 | 0.98438 |
| Precision | 0.9548 | 0.96703 | 0.9661 | 0.96296 | 0.98378 |
| FPR | 0.041667 | 0.03125 | 0.03125 | 0.036458 | 0.01562 |
| FNR | 0.11979 | 0.083333 | 0.10948 | 0.052083 | 0.05208 |
| NPV | 0.95833 | 0.96875 | 0.96875 | 0.96354 | 0.98438 |
| MCC | 0.84111 | 0.88662 | 0.86201 | 0.91157 | 0.93291 |
| Model | 90-10 Split | 80-20 Split | 70-30 Split | Cross Validation |
|---|---|---|---|---|
| Proposed | 98.9 | 96.3 | 93.45 | 96.65 |
| HI-DNN | 97.4 | 95.4 | 91.0 | 95.57 |
| DNN-GF | 96.7 | 94.5 | 90.2 | 92.96 |
| SVM | 94.5 | 92.6 | 88.3 | 94.27 |
| RF | 93.3 | 91.4 | 86.1 | 91.92 |
| Model | Size (MB) | MACs (G) |
|---|---|---|
| Proposed | 237.89 | 0.71 |
| HI-DNN | 461.10 | 1.03 |
| DNN-GF | 370.88 | 1.14 |
| SVM | 270.87 | 1.13 |
| RF | 289.11 | 1.18 |
| Model | Training Time (s) | Testing Time (Image/s) |
|---|---|---|
| RF | 2804 | 38.7 |
| SVM | 2705 | 17.6 |
| DNN-GF | 2506 | 15.9 |
| HI-DNN | 2011 | 13.1 |
| Proposed model | 2103 | 10.3 |
| Metrics | RF | SVM | DNN-GF [17] | HI-DNN [21] | Proposed |
|---|---|---|---|---|---|
| FDR | 0.14286 | 0.21429 | 0.25625 | 0.083355 | 0.06587 |
| F1-Score | 0.82759 | 0.75862 | 0.69565 | 0.85631 | 0.84615 |
| Accuracy | 0.83871 | 0.77419 | 0.80645 | 0.838771 | 0.87097 |
| Sensitivity | 0.80000 | 0.73333 | 0.85204 | 0.93752 | 0.99368 |
| Specificity | 0.87525 | 0.8125 | 0.99965 | 0.98752 | 0.99787 |
| Precision | 0.85714 | 0.78571 | 0.99654 | 0.91667 | 0.99368 |
| FPR | 0.12525 | 0.1875 | 0.06548 | 0.0654 | 0.0587 |
| FNR | 0.22221 | 0.26667 | 0.46667 | 0.26651 | 0.21488 |
| NPV | 0.8741 | 0.8125 | 0.98756 | 0.9375 | 0.56845 |
| MCC | 0.67783 | 0.54812 | 0.60911 | 0.6825 | 0.76594 |
| Dataset | 3DIRCADb1 Dataset | Silver07 | ||
|---|---|---|---|---|
| Metrics | Without COA | With CoA | Without COA | With CoA |
| FDR | 0.057497 | 0.016216 | 0.098421 | 0.06587 |
| F1-Score | 0.68794 | 0.96553 | 0.75297 | 0.84615 |
| Accuracy | 0.87668 | 0.96615 | 0.81067 | 0.87097 |
| Sensitivity | 0.83458 | 0.96792 | 0.95485 | 0.99368 |
| Specificity | 0.96568 | 0.98438 | 0.98365 | 0.99787 |
| Precision | 0.95584 | 0.98378 | 0.94658 | 0.99368 |
| FPR | 0.17278 | 0.1562 | 0.19780 | 0.15687 |
| FNR | 0.15684 | 0.05208 | 0.86925 | 0.21488 |
| NPV | 0.70654 | 0.98438 | 0.46825 | 0.56845 |
| MCC | 0.61545 | 0.93291 | 0.41892 | 0.76594 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sridhar, K.; C, K.; Lai, W.-C.; Kavin, B.P. Detection of Liver Tumour Using Deep Learning Based Segmentation with Coot Extreme Learning Model. Biomedicines 2023, 11, 800. https://doi.org/10.3390/biomedicines11030800
Sridhar K, C K, Lai W-C, Kavin BP. Detection of Liver Tumour Using Deep Learning Based Segmentation with Coot Extreme Learning Model. Biomedicines. 2023; 11(3):800. https://doi.org/10.3390/biomedicines11030800
Chicago/Turabian StyleSridhar, Kalaivani, Kavitha C, Wen-Cheng Lai, and Balasubramanian Prabhu Kavin. 2023. "Detection of Liver Tumour Using Deep Learning Based Segmentation with Coot Extreme Learning Model" Biomedicines 11, no. 3: 800. https://doi.org/10.3390/biomedicines11030800
APA StyleSridhar, K., C, K., Lai, W. -C., & Kavin, B. P. (2023). Detection of Liver Tumour Using Deep Learning Based Segmentation with Coot Extreme Learning Model. Biomedicines, 11(3), 800. https://doi.org/10.3390/biomedicines11030800