In this section, we apply the proposed procedure on the log-returns of foreign exchange rates with respect to US dollars from Group of 20 (known as G20). Since US dollar is used as the underlying currency, there are 19 time series of exchange rates in total. The exchange rates of France, Germany and Italy are excluded from our analysis due to their perfect linear correlation with euros, which results in 16 time series of exchange rates available for our clustering analysis
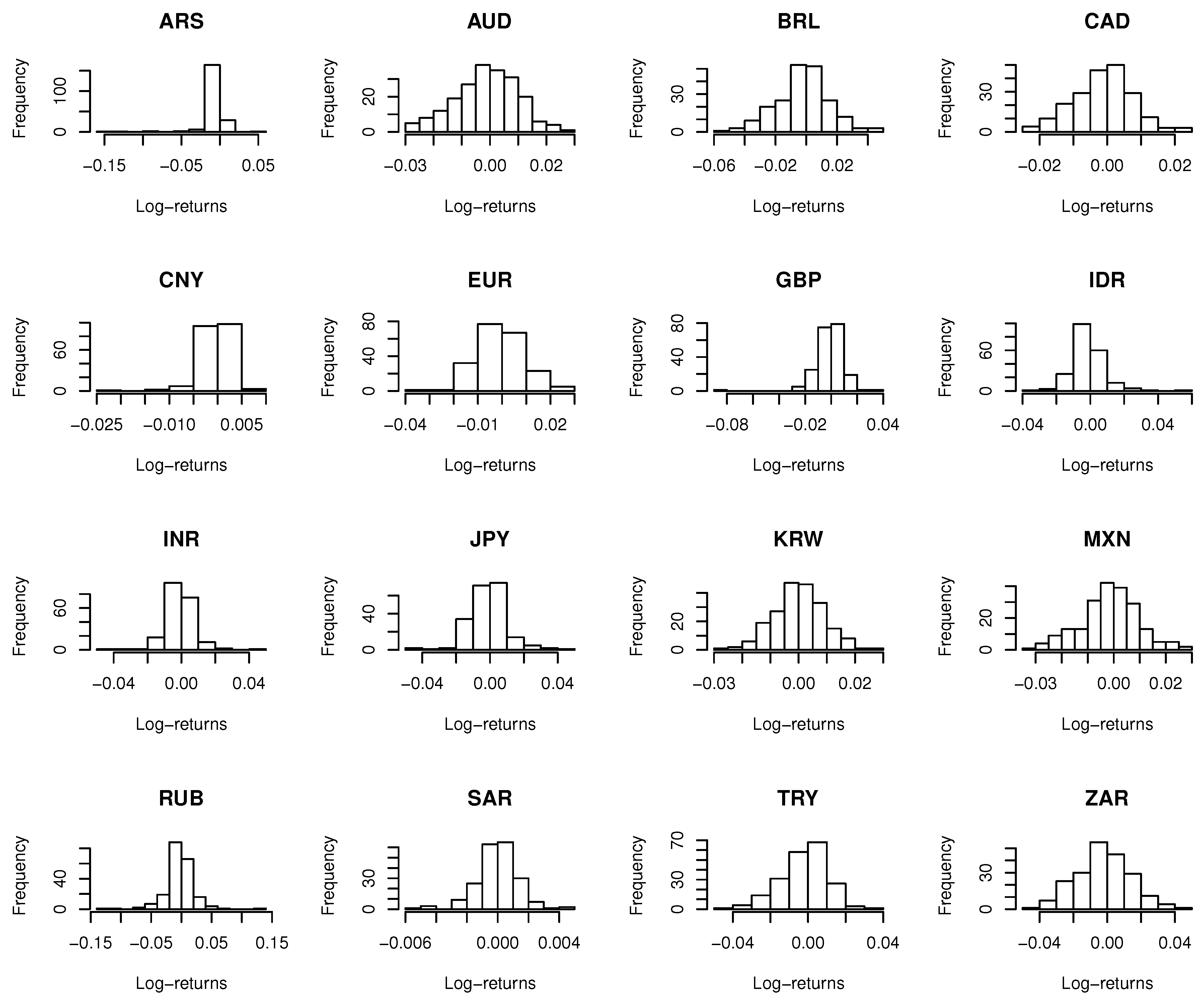
1. The data were collected weekly from 5 September 2012 to 17 August 2016, covering 207 × 16 active observations during these four years, which can be downloaded from “PACIFIC Exchange Rate Service”, 2016, by Werner Antweiler, University of British Columbia. The descriptive statistics and histograms of observations for the 16 currencies are given in
Table 3 and
Figure 7.
5.1. Preliminary Analysis
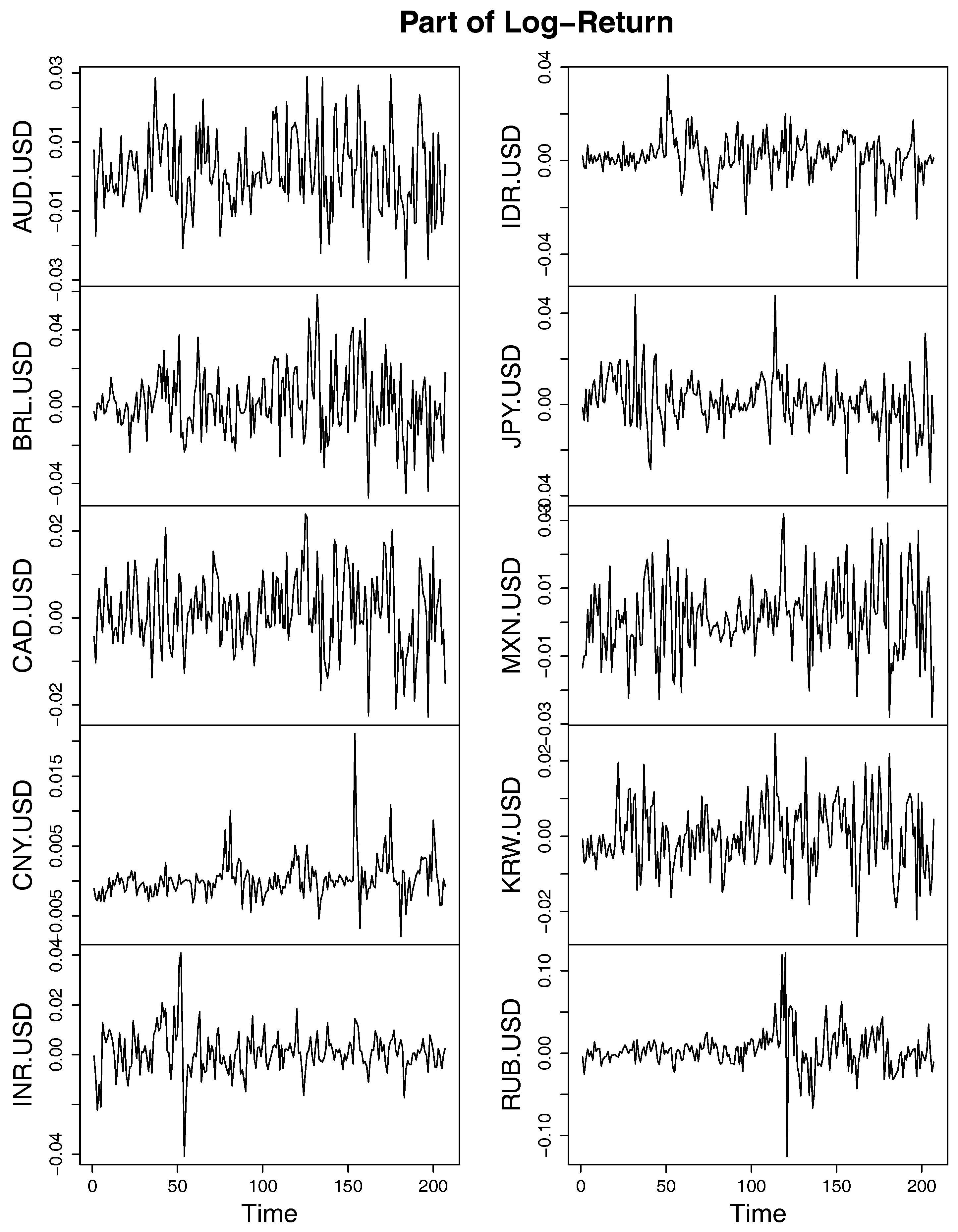
For each series of the exchange rates, the log-returns are obtained by taking logarithm of the fraction between two consecutive weekly exchange rates, part of which are shown in
Figure 8. To eliminate the potential autocorrelation and heteroskedasticity of the log-returns, a univariate
generalized error distribution (GED) ARMA-GARCH
model is applied to each time series of log-returns and the fitted standardized residuals are extracted for the purpose of clustering.
A preliminary test of correlation indicates that the standardized residuals of Argentine Pesos seem to be uncorrelated to those of all the other currencies. The details of the correlation tests are shown in
Table 4, from which we could see that all
p-values are greater than
. Thus, we suspect that all WLTMDs between the residuals of ARS and any other currency are approximately 0. To this end, let
where
X represents some currency and
is the random variable having the same distribution as the standard residuals obtained by fitting the log-returns of currency
X with GED ARMA-GARCH
model. Then, by
Coles et al. (
1999, eq. 4.2), we have
as
where
and
is the weak lower-tail dependence between the standard residuals of the log-returns of ARS and currency
X. Hence, our concern about whether
is equivalent to test
The test statistic, which is asymptotically standard normal, could be obtained using the improved OLS method given in
Gabaix and Ibragimov (
2011). When 50 pairs of observations are used, the resulting
p-values are all greater than
, as shown in
Table 4. Thus,
could not be rejected, which leads to
and hence
for all currencies other than ARS. Notice that by definition WLTMD should always be smaller than or equal to the corresponding weak lower-tail dependence, therefore the WLTMDs between the residuals of ARS and those of any other currency are approximately 0, which allows us to evaluate ARS as an isolated point that will not be taken into account in further analysis.
In fact, ARS is not the only currency that should be excluded from further clustering procedure. When testing the correlation between standardized residuals of the fitted GED ARMA-GARCH
model for log-returns, we discover that the residuals of SAR have negative correlation with majority of the residuals of the other currencies (see the columns entitled “Sign of estimated coefficients” in
Table 5). Furthermore, we can see in
Table 5 that only AUD, CNY, GBP and JPY are currencies whose standard residuals may not be negatively correlated with SAR. Unfortunately, none of the corresponding
p-values show significant correlation between the standardized residuals of these currencies and SAR. Therefore, it is reasonable to suspect the WLTMDs between the residuals of SAR and any other currency are approximately 0. As expected, the last column in
Table 5 verifies this result using the OLS test statistics with only 30 pairs of observations. Therefore, we do not include SAR in our next step of clustering procedure either.
Since there are no more currencies that could be evaluated as isolated points based on correlation tests or OLS test statistics, we retain all of the rest 14 exchange rates in our further clustering analysis.
5.2. Clustering the Exchange Rates Using WLTMD
For each pair of the residuals fitted from the log-return series, a bivariate Clayton copula function (see
Liebscher 2008, for instance) is adopted with the form of Equation (
3) on the estimated empirical distribution functions (pseudo observations), where
and
are unknown parameters to be specified. Notice that the Clayton-type copula defined in Equation (
3) relaxes the restriction
in the classical Clayton copula and hence is not necessarily symmetric. With this Clayton-type copula, the tail order of maximal dependence is proved to have the following analytic form:
(cf.
Furman et al. 2015, eq. 6.2). The parameters can be estimated by the maximum likelihood method, and hence the estimate of the lower tail of the maximal dependence is given by
. To measure the goodness-of-fit of the assumed copula, we employ a test based on the Rosenblatt transformation (see
Breymann et al. 2003) between two dependent random variables
and
, given by
where
denotes the standard normal c.d.f. and
the conditional copula. Then, the random variable
should have a
distribution if
C is the true copula, which can be tested by a Kolmogorov–Smirnov test between
S as a function of pseudo observations and
for each pair of the standardized residuals for different currencies. The test statistics are given in
Table A1 in
Appendix C. Notice that
in our situation, thus the
critical value for the Kolmogorov–Smirnov test is equal to
, indicating none of the fitted copulas should be rejected as the true copulas.
Using the fitted parameters
and
, we obtain the fitted tail order of maximal dependence
as well as the fitted WLTMD
. Then, we apply the
WNACut algorithm for the first stage of the clustering procedure and Ward1 method for the second stage on the affinity matrix constructed by the (
196)
s for
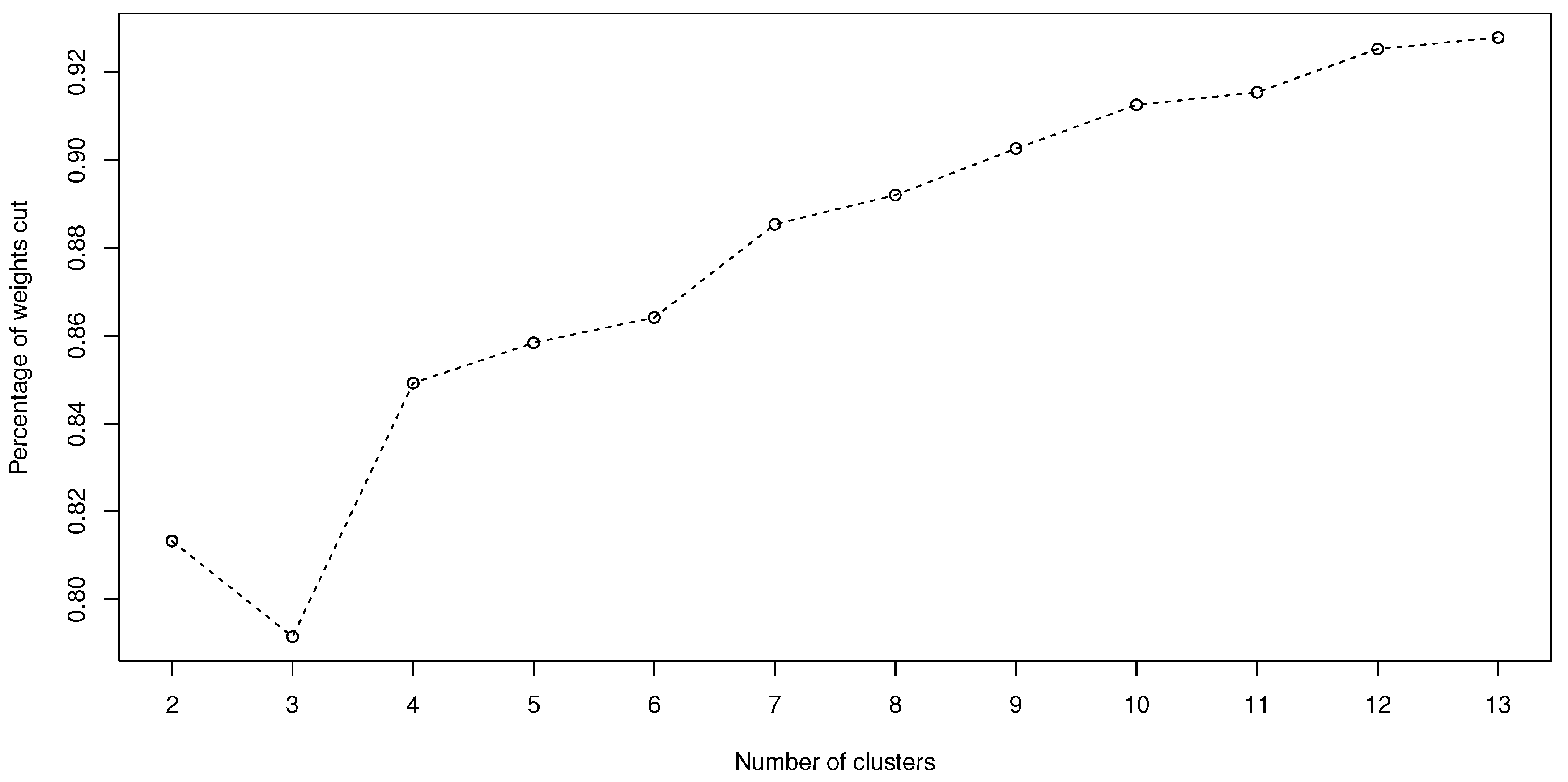
, respectively. The total weights for
WNACut is
k, and the percentages of weights cut of the total weights
against
k are shown in
Figure 9, which indicates that a relatively stable clustering result is obtained when the number of clusters
.
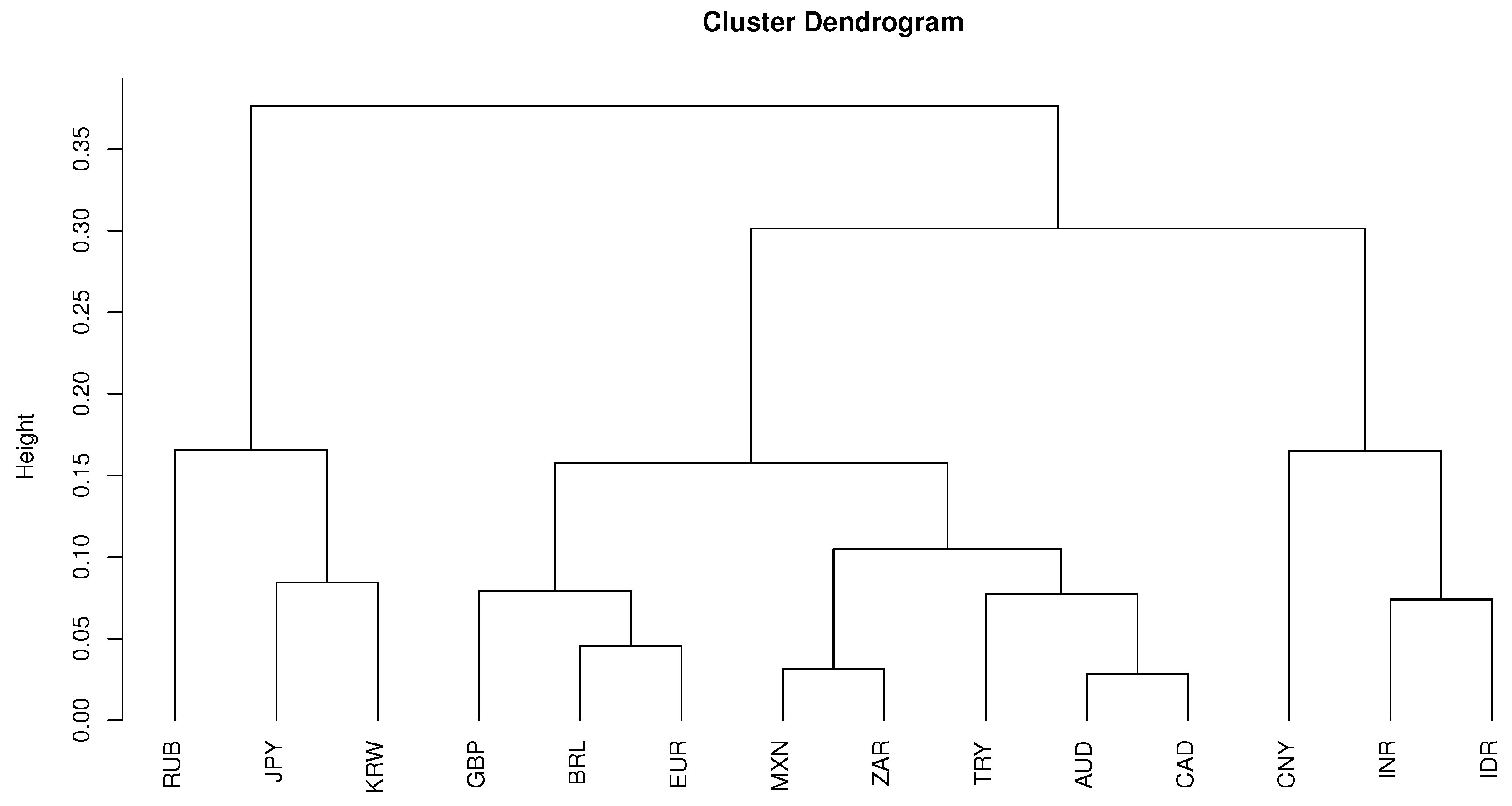
To get a closer look at the clustering result, first we consider the case
whose cluster dendrogram is given by
Figure 10.
The resulting clusters are listed in
Table 6 which provides a regional segmentation of the world: Northeast Asia, the East/Southeast Asia and the rest of the world. Obviously, such a cluster result has the lowest percentage of weighted cuts and seems to perform well for currencies of countries in the Northeast Asia, East Asia and Southeast Asia. However, it fails to distinguish the currencies of the rest of the world. For the purpose of comparison, in
Table 6, we also provide the clustering results given by the method of
De Luca and Zuccolotto (
2011) for
.
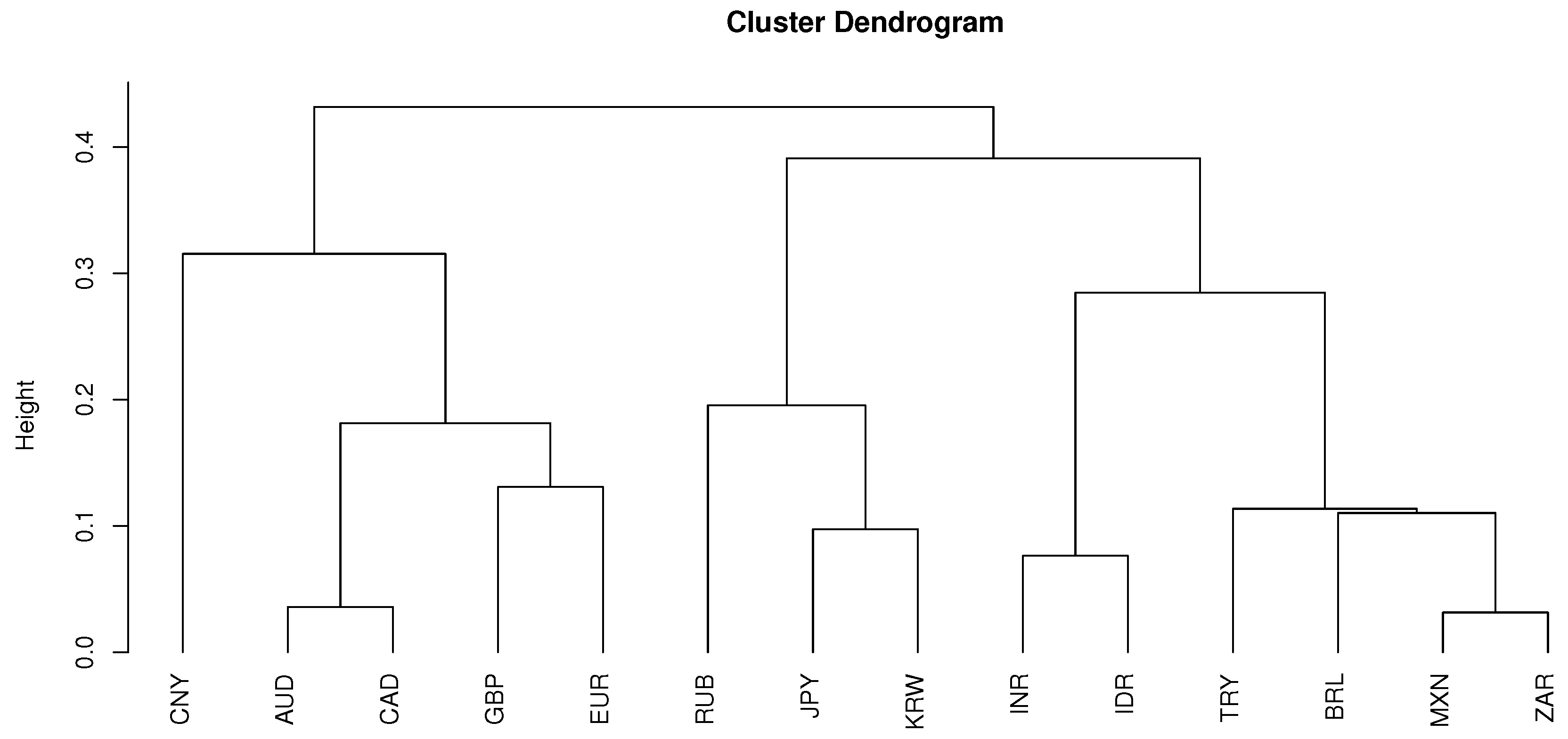
Next, we compare the clustering result for
to
. When
, the clustering dendrogram is given by
Figure 11.
The resulting clusters are listed in
Table 7 which preserves the regional characteristics for currencies of countries in East/Northeast Asia while the partition of the rest of the world in
Table A2 is provided by the IMF. For the purpose of comparison, in
Table 7, we also provide a clustering result given by the method of
De Luca and Zuccolotto (
2011) for
. Here are some remarks on the clustering outcomes obtained by our clustering procedure.
All economies in the first group have strong economic connections with the US (under certain type of free trade agreements). Besides, the nominal per capita GDPs of these economies are all above
(see
Table A2 in
Appendix D). Thus, it is reasonable to include currencies of these economies in one group.
The second group of economies have neither strong economic connection to the US nor high nominal per capita GDPs (less than
). Moreover, all of them are identified as emerging economies by IMF (see
Table A2 in
Appendix D).
China is the only member of the third group. Although there is no free trade agreements between US and China, it is well-acknowledged that China has a strong economic connection with the US. In addition, China has a very high nominal GDP (the third highest among all 20 economies) but very low nominal GDP per capita (less than ). As a result, it is reasonable to not include China in any other group.
It is reasonable to include the rest three economies in one group from the geographical perspective.
In conclusion, the clustering result for seems to more reasonable compared to that of . Besides, the clustering result for could not be obtained through further partition based on the clustering result for because it requires a combination of {Brazil, Mexico, South Africa, Turkey} and {India, Indonesia} as a new cluster. Therefore, the clustering result for seems not to be sufficiently stable from our perspective.
5.3. An Example of Portfolio Management with the Clustering
As stressed in
Section 1, one important application of time series clustering is risk management. Since the WLTMD represents the extreme co-movement downwards, the resulting clusters obtained through our proposed procedure represent groups of assets whose returns move in the same direction when both returns are extremely low. Hence, we should avoid including two assets from the same cluster in our portfolio. For instance, if we would like to construct a portfolio with four of the 14 aforementioned currencies, we may consider the following steps:
Perform our proposed clustering procedure for
. The clustering result is given in
Table 7.
From the clustering result in
Table 7, one has (
) 72 choices if he/she tries to avoid selecting two assets from the same cluster in his/her portfolio. All 72 resulting portfolios are listed in
Table A3 in
Appendix E.
Construct portfolio using Markowitz’s procedure (minimum variance criteria), namely, computing the sample covariance matrix
of the log-returns for any combination of currencies in
Table A3 and solving
subject to
and
for
, where
. The resulting weights corresponding to the 72 choices of currencies are also given in
Table A3 in
Appendix E.
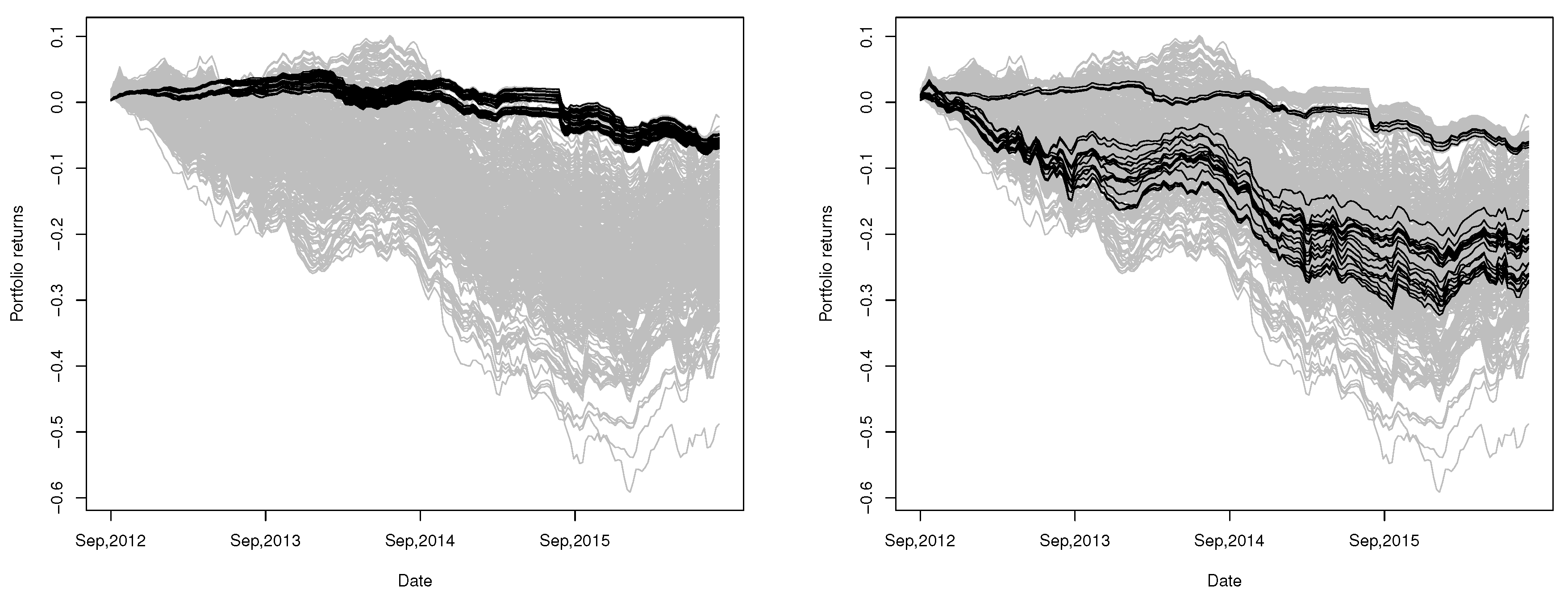
The paths of the returns for all 72 combinations are shown in
Figure 12. Notice that there are (
) 1001 different combinations of four currencies without considering the clustering result (the resulting weights as well as the mean and accumulative returns corresponding to these 1001 portfolios are listed in
Table S1 in the Supplementary Materials). We also construct portfolios using Equation (
5) for all of the 1001 combinations of currencies and plot the corresponding paths of returns in
Figure 12. In contrast, in
Figure 12, we also provide the paths of aggregated returns of all portfolios constructed by the method of
De Luca and Zuccolotto (
2011).
In
Figure 12, the portfolios constructed through our proposed procedure are shown to have uniformly exceptional performance among all possible ways to construct portfolios with four currencies for a long period (September 2012–August 2016). Compared with the portfolios constructed using the method of
De Luca and Zuccolotto (
2011), all of our portfolios outperform most of their portfolios. Besides, the paths of return provided by our portfolios do not vary significantly across the 72 combinations of currencies and seem to have better performance in the long run (the average and accumulative returns of these 72 portfolios on 17 August 2016 (the last date of the observation period) are also provided in
Table A3 in
Appendix E, from which we can see that the accumulative returns are from
to
, corresponding to the range shown in the left of
Figure 12).
We also show the path of risk adjusted returns provided by our portfolios in
Figure 13. The results also show that our portfolios have outstanding performance most of the time.
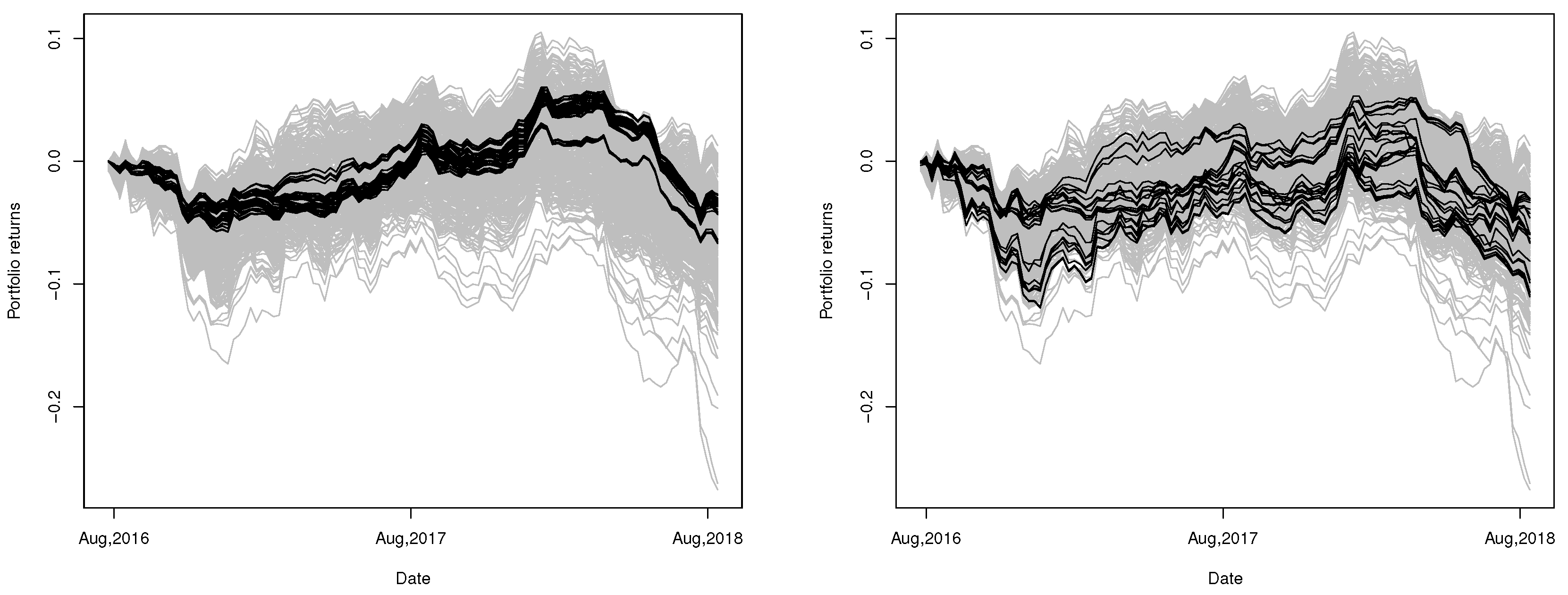
For a retrospective study, the performance of the proposed portfolios as well as all possible portfolios from 17 August 2016 to 10 September 2018 are plotted in
Figure 14. Although these portfolios fail to be the best choices again, the resulting returns are still shown to have very strong invulnerability against fluctuations and risks.
In contrast, in
Figure 14, we also provide the paths of aggregate returns of all portfolios constructed by the method of
De Luca and Zuccolotto (
2011). Obviously, the performances are quite inconsistent and the returns seem to vary when volatility increases.
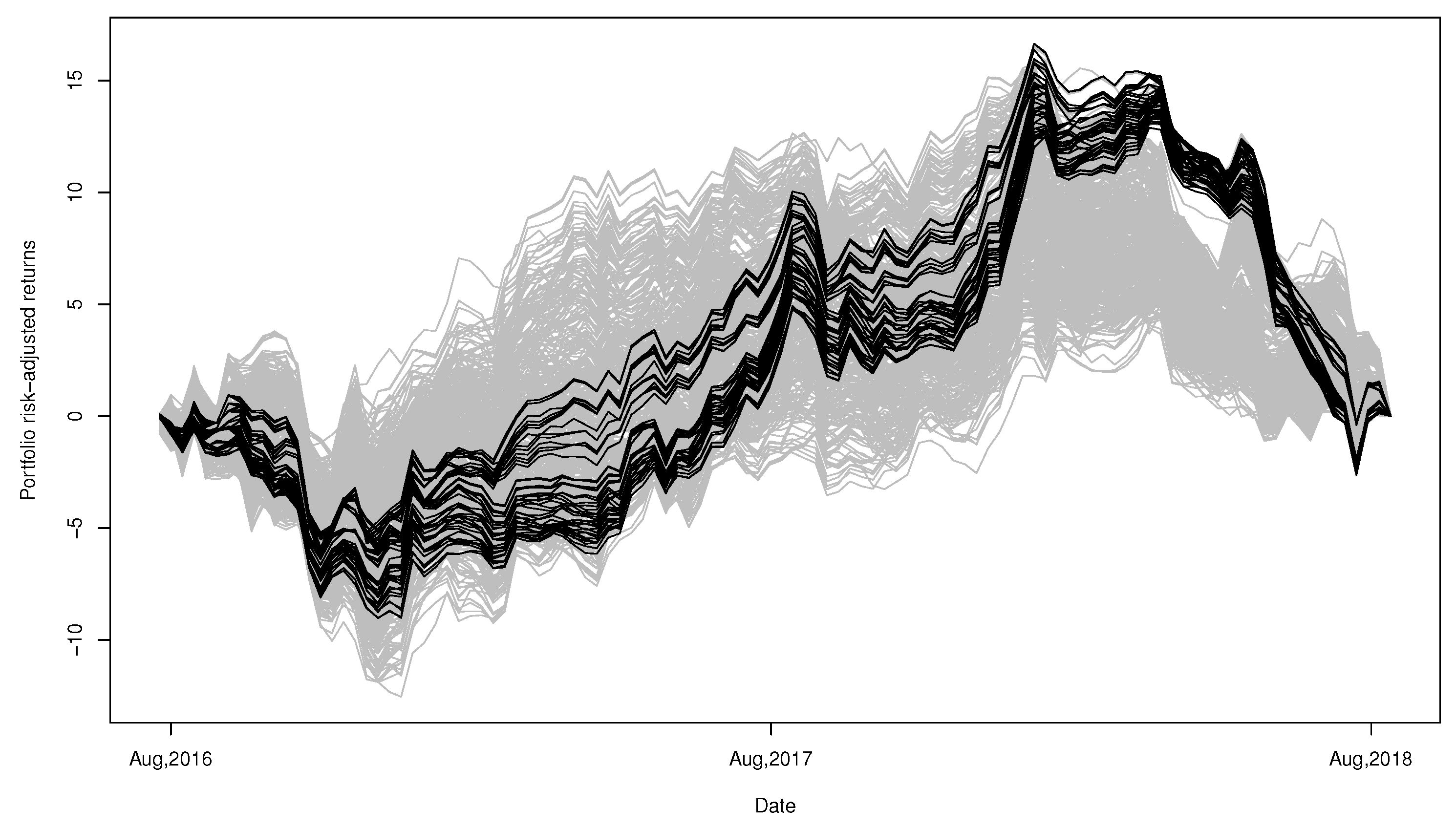
For the retrospective study, we also show the path of risk adjusted returns provided by our portfolios in
Figure 15. The performance of our portfolios seems to be very good during early 2018 but relatively poor during late 2016 to 2017.



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}














