2.2. Engine Assembly Components
Five main components that most frequently failed and caused warranty claims were chosen in (
Kumerow et al. 2014;
Shemyakin and Kniazev 2017) out of the available list of 60: the spark plug assembly (A), ignition coil assembly (B), computer assembly (C), crankshaft position sensor (D), and oxygen heated sensor (E). The spark plug assembly brings power to the spark plug, which provides the spark for the motor to start. The ignition coil assembly regulates the current to the spark plugs, helping to ignite the spark. The computer assembly includes engine sensors, and it controls the electronics for fuel-injection emission controls and the ignition. The crankshaft position sensor controls ignition system timings and reads rpms. Finally, the oxygen heated sensor determines the gas-fuel mix ratio by analyzing the air from the exhaust and adjusting the ratio as needed. The latter two components are controlled by the computer assembly. A failure of one of the chosen components does not necessarily cause the other ones, yet all of these components are all closely related and could all need to be repaired or replaced if, for example, a single event caused the system to short out.
Records were available only for 32,667 cars from the dataset that had at least one of the five main components fail within the time frame of the warranty. However, this dataset is somewhat limited due to the fact that many cars did not experience failure of those parts within the warranty years. It would be desirable to include all cars, whether or not they had one of the main five components fail. Using full data would help us make the models for joint dependence more realistic; however, such a dataset is also more complicated to obtain. Thus, our main focus is on the cars for which component failures were registered. In the case of multiple repairs, only the date of the first repair of each component per vehicle was used, and all repeats were excluded.
A simultaneous failure of two or more components might indicate that in the course of diagnostics, a repair or replacement of several parts was recommended, and each of these parts was recorded as failing. The most important goal of the study is to be able to predict the failures of components based on the history of other components’ failure during the warranty period. The emphasis is made on joint failures happening early or late in the warranty period.
The ultimate goal of this paper is to suggest models for the joint distribution of times-to-failure of different pairs of components. We focus on the pairwise associations. It is established that the time-to-failure for an individual component can be effectively fitted to a parametric model (
Baik 2010;
Wu et al. 2000); thus, we will use full parametric modeling of the marginal distributions of individual components. In (
Shemyakin and Kniazev 2017), non-parametric analysis of the marginal was considered.
Notice also that with the warranty period for all cars in the sample being the same five years, we may either want to consider all 32,667 cars in the dataset (some cars had several claims) as providing right censored data (I) (
Schemper et al. 2013) or consider for each pair of components only the cases when both components fail during the warranty period, which represents conditioning to failure events in the warranty period (II) (
Shemyakin and Kniazev 2017). The first approach uses more complete information from the data, but with the extremely high percentage of censored observations (repairs are relatively rare events), it may also lead to erroneous values of correlation and tail dependence, thus misrepresenting the dependence structure. In particular, right tails corresponding to joint failures late in the warranty period, which might be of a special concern to the manufacturer, will not be captured with the censoring approach. In the meantime, the second approach may also overestimate the actual association between two TTF variables. In our context, we are mostly interested in related failures occurring during the warranty period. As we will see from the comparison of these two approaches in
Section 4, right censoring may not provide adequate models for such instances, and we recommend the second (conditional) approach for model selection in
Section 5 and
Section 6. In
Section 7, we will return to the first approach to discuss parametric estimation for more general five-dimensional models. This is necessitated by the fact that the failure of all five or even four components during the warranty period is an extremely rare event, and we did not have enough data to apply the second approach in higher dimensions.
Table 1 contains the sample sizes characterizing the counts of individual failures of the components (column “All”) and related failures of their pairs (Rows A–E, Columns B–E), registered during the warranty period.
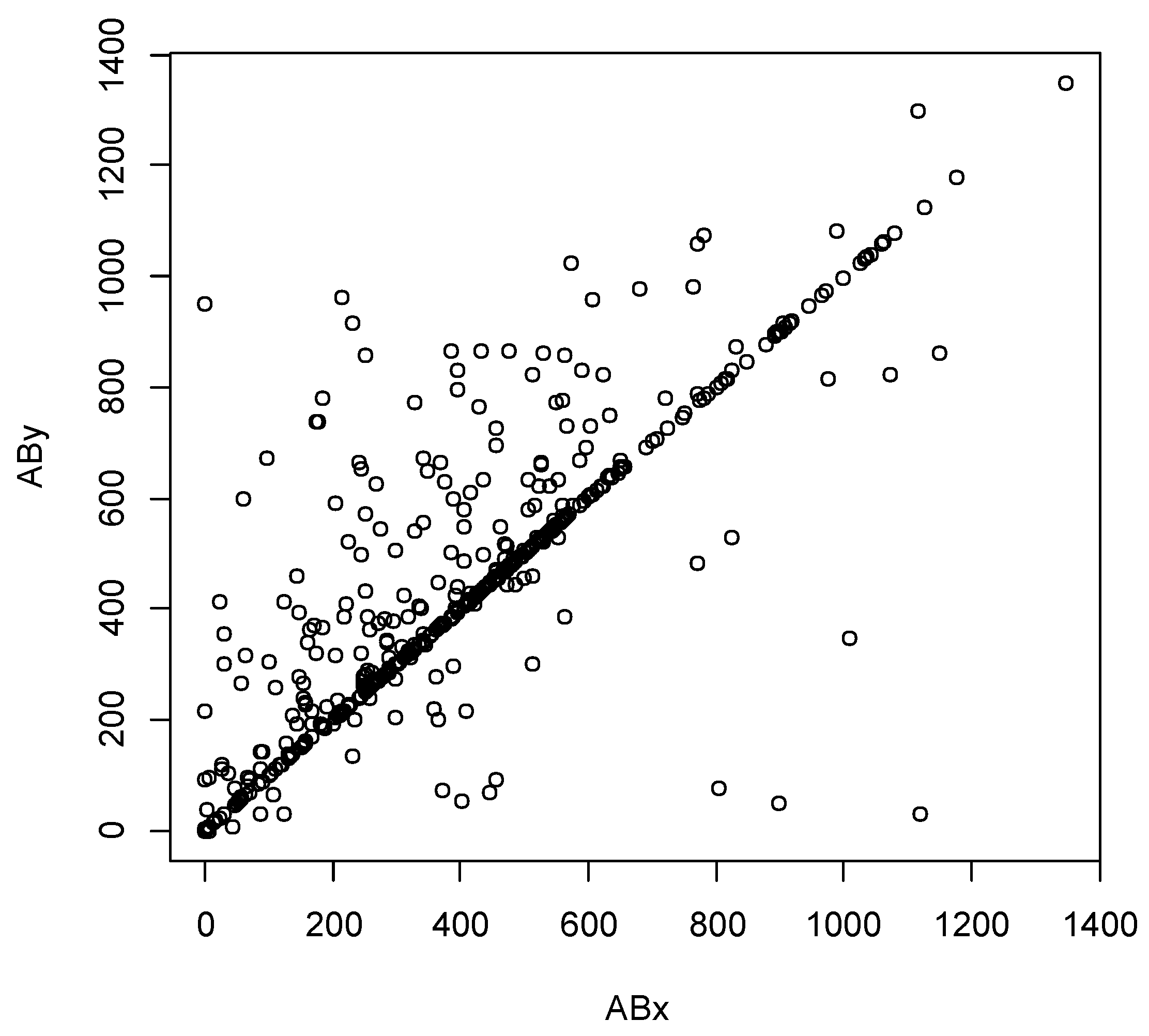
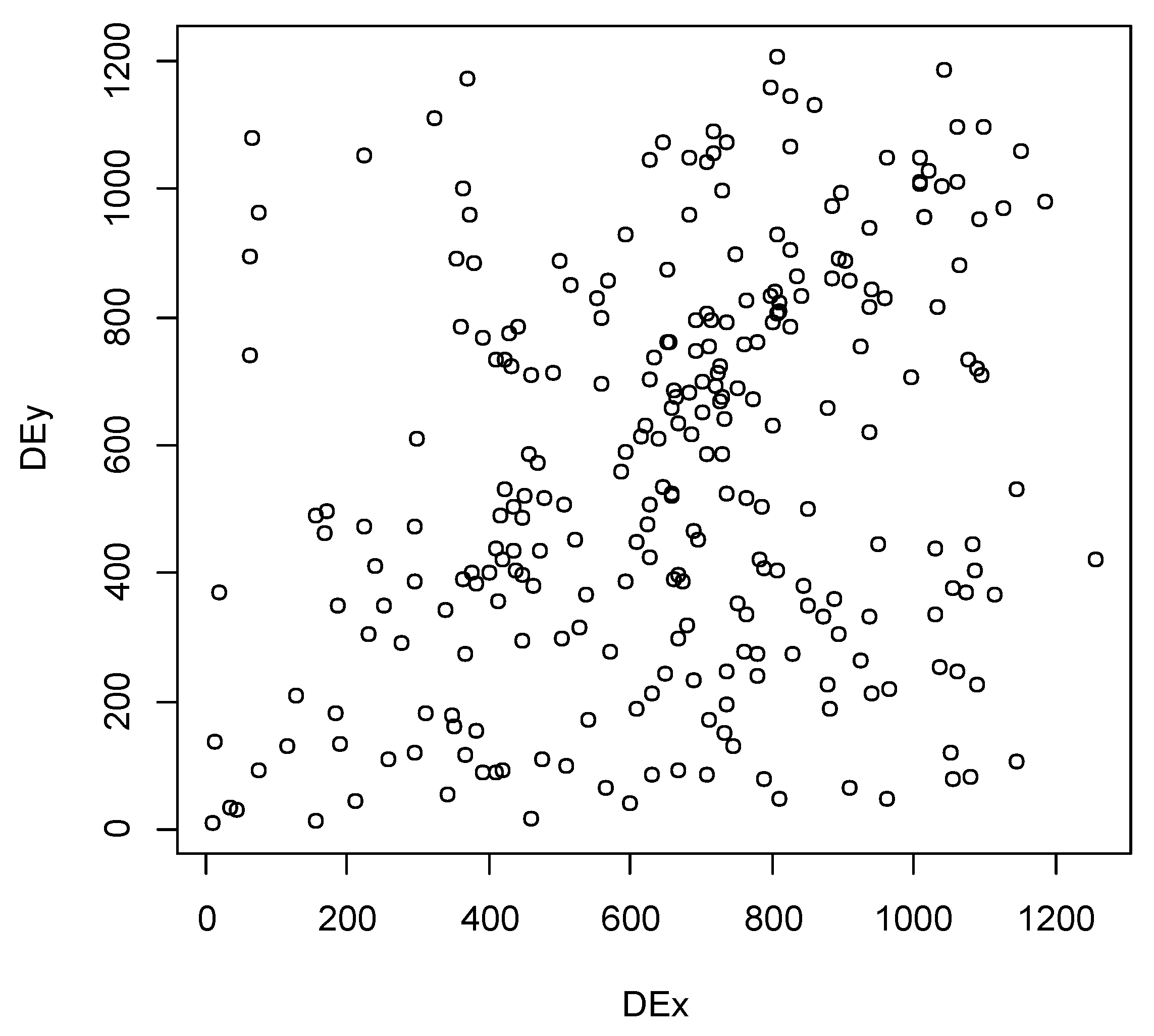
The scatterplots in
Figure 1 and
Figure 2 show the TTFs of one part versus the TTFs of another, given in days. The first scatterplot in
Figure 1 displays TTFs for the pair A and B, which exhibits the highest degree of dependence including multiple simultaneous failures (points on the main diagonal). That may correspond to the close functional relationship between the spark plug assembly (A) and ignition coil assembly (B), which results in the general recommendation to repair (replace) these parts simultaneously in the case of a failure of one of them. Notice a linear diagonal pattern in the upper right quadrant indicating upper tail dependence and, to a lesser extent, a similar diagonal pattern in the lower left quadrant suggesting lower tail dependence (to be further discussed in
Section 3).
The scatterplot in
Figure 2 shows the correlation between failures of the crankshaft position sensor (D) and oxygen heated sensor (E). While these components demonstrated the lowest association out of all ten pairs considered, they still exhibited some positive correlation. These two extreme examples of high and low association between failure times illustrated the variety of patterns we were trying to model.






{kind=link}
{kind=link}
{kind=link}
{kind=link}