1. Introduction
Continual increase in longevity worldwide remains a serious concern for pension plan sponsors and annuity providers. The major issue is the presence of longevity risk, which is the risk of paying more than expected because of unanticipated mortality improvements. Broadly speaking, there are three ways to mitigate longevity risk (e.g.,
Cairns et al. 2008). The first is to transfer the unwanted risk to an insurer or reinsurer by paying a premium. The problem of this usual approach is that insurers and reinsurers may also have limited appetite, and that a failure of a major player could cause disastrous systemic outcomes. The second way is natural hedging, which makes use of the opposite movements between the values of annuities and life insurances arising from changes in mortality levels (e.g.,
Li and Haberman 2015). Although certain large institutions may have the resources and economies of scale to offer both lines of products and so exploit this hedging effect, many other financial entities do not have such necessary conditions to follow suit.
The third way is the use of capital market solutions, such as insurance securitization (e.g.,
Cowley and Cummins 2005), and mortality- and longevity-linked securities (e.g.,
LCP 2012;
Coughlan et al. 2007). The former involves packaging insurance and business risks into securities, such as bonds with coupon and principal payments depending on the performance of the underlying portfolio. The latter has two types of transactions, bespoke and index-based. Bespoke transactions are tailored to individual circumstances, for example, pension buy-ins, buy-outs, and longevity swaps. In contrast, index-based solutions are constructed such that the cashflows are linked to the values of selected mortality indices. As noted in
Zhou and Li (
2016), there is an imbalance between demand and supply in longevity risk transfer. The insurance industry alone cannot generate sufficient supply for accepting the risk due to capital constraints. Accordingly, an important, recent idea is to design standardized products based on well-specified mortality indices, in order to draw more investors’ interest and develop market liquidity.
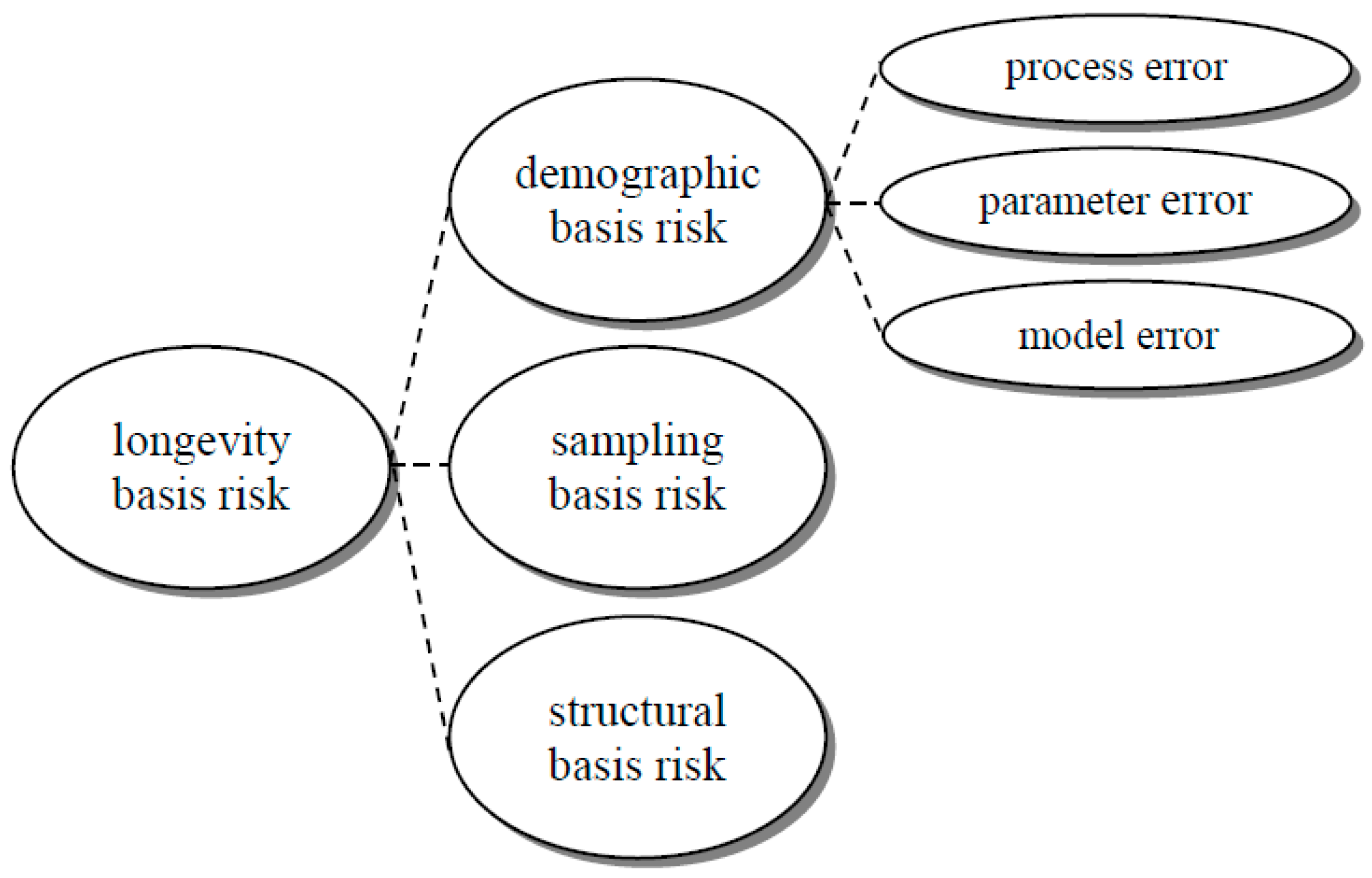
One significant challenge in implementing index-based hedging in practice is the existence of longevity basis risk, i.e., there is a mismatch or discrepancy between the hedging instruments (linked to a
reference population) and the pension or annuity portfolio being hedged (with the underlying
book population).
Haberman et al. (
2014) established a mortality modeling framework incorporating three fundamental sources of longevity basis risk. They include
demographic basis risk which comes from demographic or socioeconomic differences between the book and reference populations,
sampling basis risk due to the randomness of outcomes of individual lives, and
structural basis risk in terms of how the payoff structures differ between the hedging instruments and the portfolio to be hedged.
Li et al. (
2017) then adopted the framework and focused on assessing longevity basis risk in realistic scenarios under practical circumstances. The major finding is that for a large portfolio, about 50% to 80% of its longevity risk can often be reduced via index-based longevity swaps, while for a small portfolio, the risk reduction is usually less than 50%.
In particular, from a modeling viewpoint, or a regulatory perspective such as Solvency II (
CEIOPS 2010), demographic basis risk can further be divided into process error, parameter error, and model error (or process risk, parameter uncertainty, model uncertainty, respectively). Process error refers to the variability in the time series, parameter error arises from the uncertainty in estimating model parameters, and model error reflects the uncertainty in model selection.
Figure 1 below provides a graphical summary of all these risk components. Although several authors proposed different ways to allow for both process error and parameter error in index-based hedging (e.g.,
Li and Luo 2012;
Cairns 2013;
Tan et al. 2014;
Haberman et al. 2014), relatively little attention has been given to assessing model error. Most of the studies covered process error only or considered both process error and parameter error, while some compared the hedging results briefly between a few different mortality projection models.
Li et al. (
2016) took a step further by examining the effectiveness of a hedging strategy based on a particular model but under a simulated environment produced from another model, and found that coherence is a critical assumption in measuring the hedge effectiveness.
Li et al. (
2017) conducted a detailed sensitivity analysis by changing various modeling assumptions. They noted that the most important ones were the coherence property, behavior of simulated future variability, simulation method, and additional model features such as structural mortality changes.
In this paper, we perform a more elaborate investigation on model error in an attempt to supplement the current literature from two perspectives. Firstly, we assess the hedge effectiveness based on three broad “families” of mortality projection models, a range of time series processes under each model, and several simulation methods for each combination. Many of these combinations have not been tested or studied in detail in the literature. Secondly, we adopt the modified semi-parametric bootstrapping approach in
Yang et al. (
2015) and incorporate all the three errors in an integrated manner. From these two different perspectives, we attempt to obtain better insights into the potential impact of selecting an inappropriate model in hedging longevity risk with index-based solutions.
This paper is organized as follows. In
Section 2, we set forth a list of two-population mortality projection models, time series processes, and simulation approaches selected for our analysis. In
Section 3, we examine the hedge effectiveness under different model settings and assumptions and simulated scenarios, and provide a discussion on the impact of model uncertainty. Finally, we give our concluding remarks and set forth some suggestions for future research in
Section 4.
2. Mortality Modeling and Simulations
Recently, there is an emerging branch of literature that focuses on modeling multiple populations jointly.
Haberman et al. (
2014) and
Li et al. (
2014) provide a comprehensive review of several multi-population mortality projection models for measuring longevity basis risk. Although there are probably more than 30 models proposed in the literature, we select the ones below for our analysis, as they can be deemed as “key representatives” of the major “families” of mortality projection models.
The first belongs to the
Lee and Carter (
1992) family, in which there are some possible options (noted as Model 1a, Model 1b, Model 1c, and Model 1d respectively) for modeling the time-varying parameters:
with
or
or
or
The term
is the central death rate at age
in year
of population
, in which
refers to the reference population and
refers to the book population. The parameter
is the general age schedule,
is the mortality index over time,
, and
is the age sensitivity of the log death rate to the mortality index. The cohort parameter
is added when there are significant patterns in the residuals against cohort year (e.g.,
Haberman and Renshaw 2011). It can be modeled with an autoregressive integrated moving average (ARIMA) process for future projections and simulations, though this is not required in the analysis in the next section. Following
Cairns et al. (
2009), the first and last five cohorts are excluded from the fitting procedure due to a lack of data.
The first method suggested in
Carter and Lee (
1992) is fitting the Lee–Carter model to each population separately and then modeling the relationship between the two resulting mortality indices. This approach involves the use of a bivariate random walk with drift (1a) naturally, in which
is the vector drift term and
is the Gaussian vector error term. In contrast, the third method in
Carter and Lee (
1992) is treating the two mortality indices as a co-integrated process (1b), where
,
, and
are the parameters of the process, and
and
are independent Gaussian error terms. Moreover,
Yang and Wang (
2013) proposed using a vector error correction model (VECM) of order
(1c), in which
is the vector constant term,
and
are the matrix components, and
is the Gaussian vector error term. Finally, we also consider a vector autoregressive integrated moving average (VARIMA) process (1d), which has been explored by
Chan et al. (
2014) in modeling other mortality indices. The order chosen is (
, 1, 0),
is the vector constant term,
is the autoregressive matrix, and
is the Gaussian vector error term. The VARIMA in (1d) is in line with the VECM in (1c) and serves as an extension of the random walk in (1a) and (1b) in terms of allowing for more flexibility in modeling the various mortality indices, for comparison purposes. Please note that all the options (1a) to (1d) would generally lead to non-coherence in mortality projections, i.e., the ratio of projected death rates (central estimates) between the two populations at each age group does not converge to a constant over time (e.g.,
Cairns et al. 2011).
The second is the
Li and Lee (
2005) family, which is an extension of the Lee–Carter model and assumes a common factor for the two populations. Again, there are a few possible choices (noted as Model 2a, Model 2b, Model 2c, and Model 2d respectively) in modeling the temporal parameters:
with
or
or
or
The parameter
is the general age schedule of population
,
is the mortality index of the common factor for both populations with age sensitivity
, and
is the time component of the
jth additional factor for population
with age sensitivity
. The common mortality index is modeled as a random walk with drift as usual, with
as the drift and
as the Gaussian error. Originally,
Li and Lee (
2005) used only one additional factor; later,
Li (
2013) proposed using
additional factors where necessary, and
Yang et al. (
2016) further suggested adding different cohort parameters such as
.
Li and Lee (
2005) assumed that
followed an autoregressive (AR) process of order one, and that the error terms are independent between the populations (2a). On the other hand,
Li (
2013) tested a more general AR(
) process for each
(2b), and
Zhou and Li (
2016) assumed that the error terms
’s are correlated between the populations (2c). The parameters
and
are the constant and autoregressive terms respectively. Lastly, we also include a vector autoregressive (VAR) process of order
for
(2d), which has been adopted by
Haberman et al. (
2014) for modeling some other mortality indices. The notation
is the vector constant term,
is the autoregressive matrix, and
is the Gaussian vector error term. All the choices (2a) to (2d) can result in coherence in mortality projections, i.e., the ratio of projected death rates between the two populations at each age group tends to a constant over time, if the selected time series processes are weakly stationary. More technical details of time series modeling can be found in
Tsay (
2002).
The final one is an extension of the Cairns-Blake-Dowd (CBD) model by
Cairns et al. (
2006) and is proposed by
Haberman et al. (
2014), being referred to as the M7-M5 model. There are also several possible time series processes to choose from (noted as Model 3a, Model 3b, Model 3c, and Model 3d respectively) under this model:
with
or
or
or
The term
is the mortality rate at age
in year
of the reference population,
,
, and
represent the level, slope, and curvature of the mortality curve in year
(e.g.,
Cairns et al. 2009), and
is the cohort parameter. The difference in the logit mortality rate between the book and reference populations (i.e.,
) is then modeled with another CBD structure of
and
, which explain the differences between the two populations, together with another cohort parameter
. Please note that the original M7-M5 model has a common cohort parameter for both populations, while we use a separate cohort parameter for each population in order to allow for the different cohort effects in our data. The notation
is the average age of the age range in the data, and
is the average value of
.
In contrast to families (1) and (2) above, where both populations are modeled in parallel,
Haberman et al. (
2014) fitted the reference population first and then the differences between the two populations. One major argument for this treatment is that there are usually much more data for the reference population than for the book, and so it would be more appropriate to base the main trends on the reference population and consider the differences of the book population afterwards.
Haberman et al. (
2014) assumed that
follows a multivariate random walk with drift,
follows a VAR(1) process, and
and
are independent, whereas we adopt a more general VAR(
) process here for
(3a). Accordingly, we also consider three other alternatives. First, similar to replacing the option (1a) with (1d), we replace the multivariate random walk with drift with a VARIMA(
, 1, 0) process for
(3b). Second, we replace the VAR(
) process with a bivariate random walk without drift for
(3c), as we have seen in our analysis that the calculated
and
fluctuate around a constant level in many cases. Moreover, in line with the options (2b) and (2c), we test the correlation assumption between
and
(3d). All the vectors and matrices of parameters and error terms have similar meanings as previously. Please note that the options (3a), (3b) and (3d) can generate coherence in the projected mortality rates approximately if the selected VAR process is weakly stationary.
Besides the central estimates’ coherence, the simulated future variability is also a significant feature, as the relative potential movements between the book mortality and reference mortality is one main driver of longevity basis risk. This issue, however, has largely been overlooked in the current literature, which usually focuses on the mortality projection models and the (weak) stationarity of the time series processes, but not on the simulated future variability resulting from time series modeling. Based on the M7-M5 model and the CAE+Cohorts model (which is an extension of the Lee–Carter model),
Li et al. (
2017) found that the behavior of simulated future variability of the “book minus reference” component is the most important time series modeling assumption. It should be noted that while the random walk and integrated autoregressive processes above produce increasing variability over time in the simulations, the autoregressive processes (not integrated ones) generate bounded variability instead. The combined or alternative use of these time series processes would give rise to varying hedging results, as shown in the next section.
In addition to the Lee–Carter, Li-Lee, and CBD families described above, there are also several other similar approaches for modeling longevity basis risk (e.g.,
Plat 2009;
Coughlan et al. 2011;
Ngai and Sherris 2011;
Tsai et al. 2011;
Cairns 2013;
Li et al. 2016). Furthermore, while there is an abundant amount of time series processes developed in econometric studies, it appears that only a handful of them would actually turn out to be useful for modeling longevity basis risk in practice, due to the usually short length and small amount of annual book data being available.
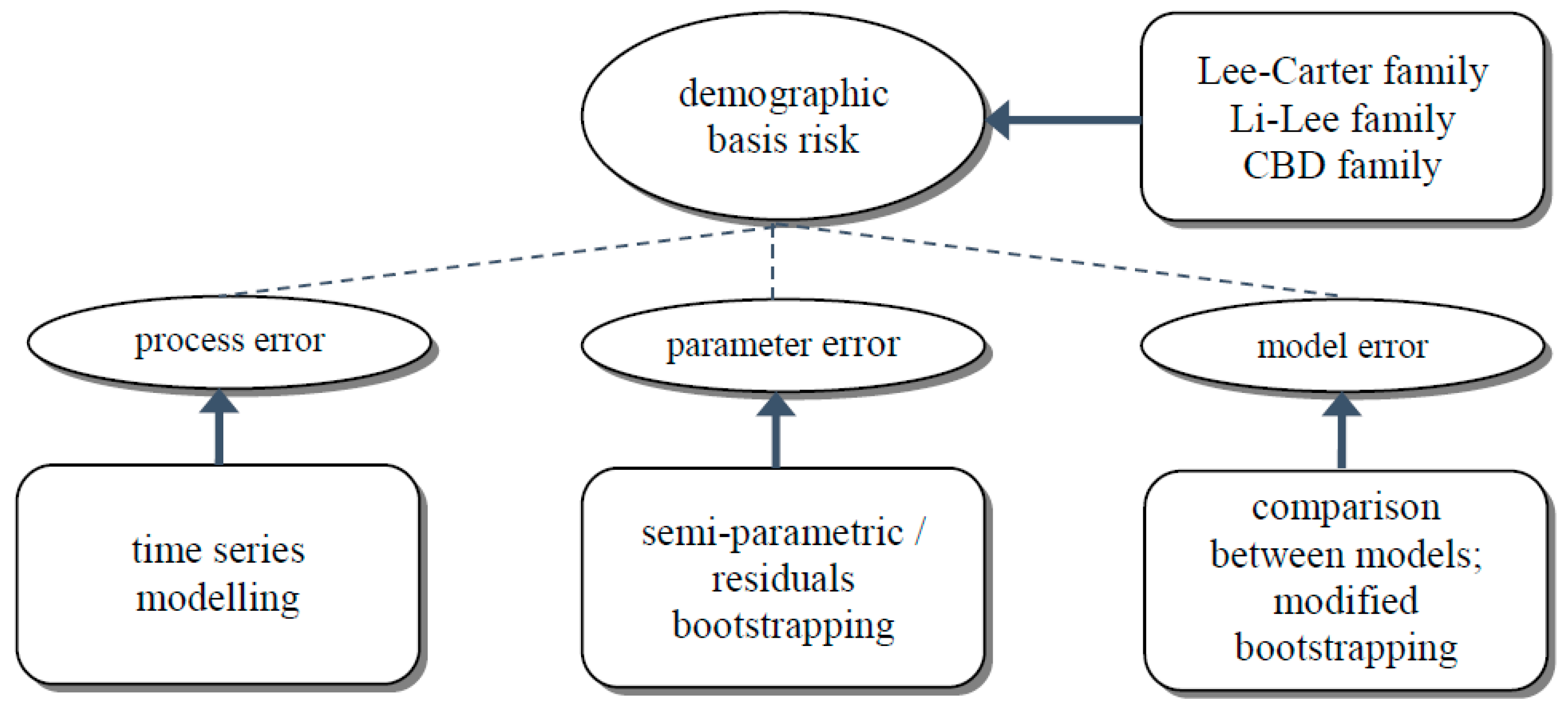
Regarding the simulation methods, we consider four different choices (e.g.,
Li 2014). The first is simply Monte Carlo simulation as in
Lee and Carter (
1992), where only process error is allowed for. The second is the semi-parametric bootstrapping approach proposed in
Brouhns et al. (
2005), and the third is the residuals bootstrapping approach suggested by
Koissi et al. (
2006), both of which include process error and also parameter error. These simulation methods have initially been catered for single-population mortality projection models, and some adaptations are needed for the two-population models in this paper. In particular, in addition to the choice of resampling the reference and book residuals separately, we also group together the two populations’ residuals in each age-time cell as an individual (bivariate) data point for resampling, such that more information about the relationships between the two populations may be embedded into the simulated samples (
Li and Haberman 2015).
Apart from measuring the hedge effectiveness by testing various models and investigating different simulated scenarios, we also adopt the modified semi-parametric bootstrapping approach in
Yang et al. (
2015) and incorporate process error, parameter error, and model error simultaneously. It is effectively an extension of the bootstrapping approach suggested by
Brouhns et al. (
2005). First, a pseudo-sample of the number of deaths is simulated from the Poisson distribution with the observed number of deaths as the mean. Suppose there are two or more competing model candidates under consideration. Each model in turn is fitted to the pseudo-data sample and the corresponding model parameters are estimated. Based on some pre-determined model selection criteria, the most “optimal” model is selected for this particular pseudo-data sample. The time series of the selected model’s temporal parameters are then simulated into the future. Lastly, future death rates are produced from the estimated and simulated parameters of the selected model. So far in this process, the pseudo-data sample is used for generating only one future scenario via one selected model. The entire process above can then be repeated iteratively to create, say, 5000 future scenarios in total
1, in which different models may be chosen in different scenarios. In this way, all the three errors are embedded in the simulated future death rates. This modified bootstrapping approach provides a different perspective to understand the impact of model uncertainty, though we acknowledge that the simulation time can be significantly lengthened, especially when more competing models and selection criteria are included in the process. Again, the bootstrapping process needs to be properly adapted to the two-population models.
Figure 2 below gives a list of the modeling techniques we experiment with to tackle the different error components. In the next section, we will discuss in detail the similarities and differences between the results on some hypothetical hedging scenarios generated by all these modeling and simulation methods.
3. Hedge Effectiveness
We have collected two sets of data for the book and reference populations. The first set is composed of the male assured lives and pensioners data (book) from the Continuous Mortality Investigation (CMI), and England and Wales male data (reference) from the Human Mortality Database (
HMD 2017), for the period from 1983 to 2006. The second set comprises Australia, New Zealand, Japan, Taiwan, Hong Kong (
Census and Statistics Department 2017), and Singapore (
Department of Statistics 2017) male data from the HMD and governmental statistics departments, for the years 1980 to 2016. Since Asia–Pacific insured data are scarce, we use the data of New Zealand, Taiwan, and Singapore, with relatively smaller sizes, as a proxy for the book population, and the data of their larger neighbors for the reference population. The age range considered is from 60 to 89.
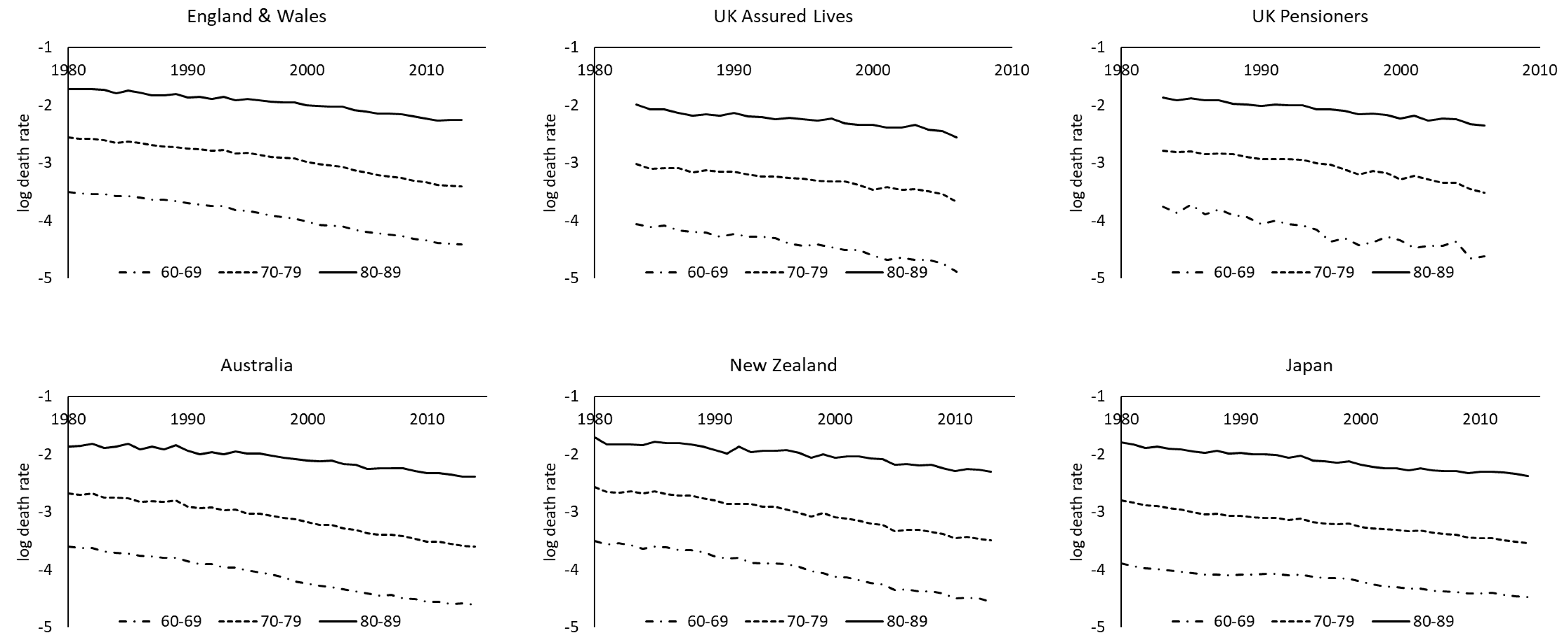
Figure 3 plots the log central death rates of three age groups over time. It can be seen that the mortality declining trends of different populations or regions are roughly in line with one another in the past few decades. In general, the death rates of the assured lives and pensioners are lower than those of English and Wales. One potential problem of the assured lives and pensioners data is that there may have been different contributors to the data over the period and there would then be some extent of heterogeneity or inconsistency. Judging simply from the graphs below, it seems that the issue may not be overly significant. Australian death rates are slightly lower than New Zealand death rates, and Japan has experienced lower mortality levels than Taiwan. Hong Kong has had lower mortality experience than Singapore, while the latter is catching up fairly quickly in the last decade.
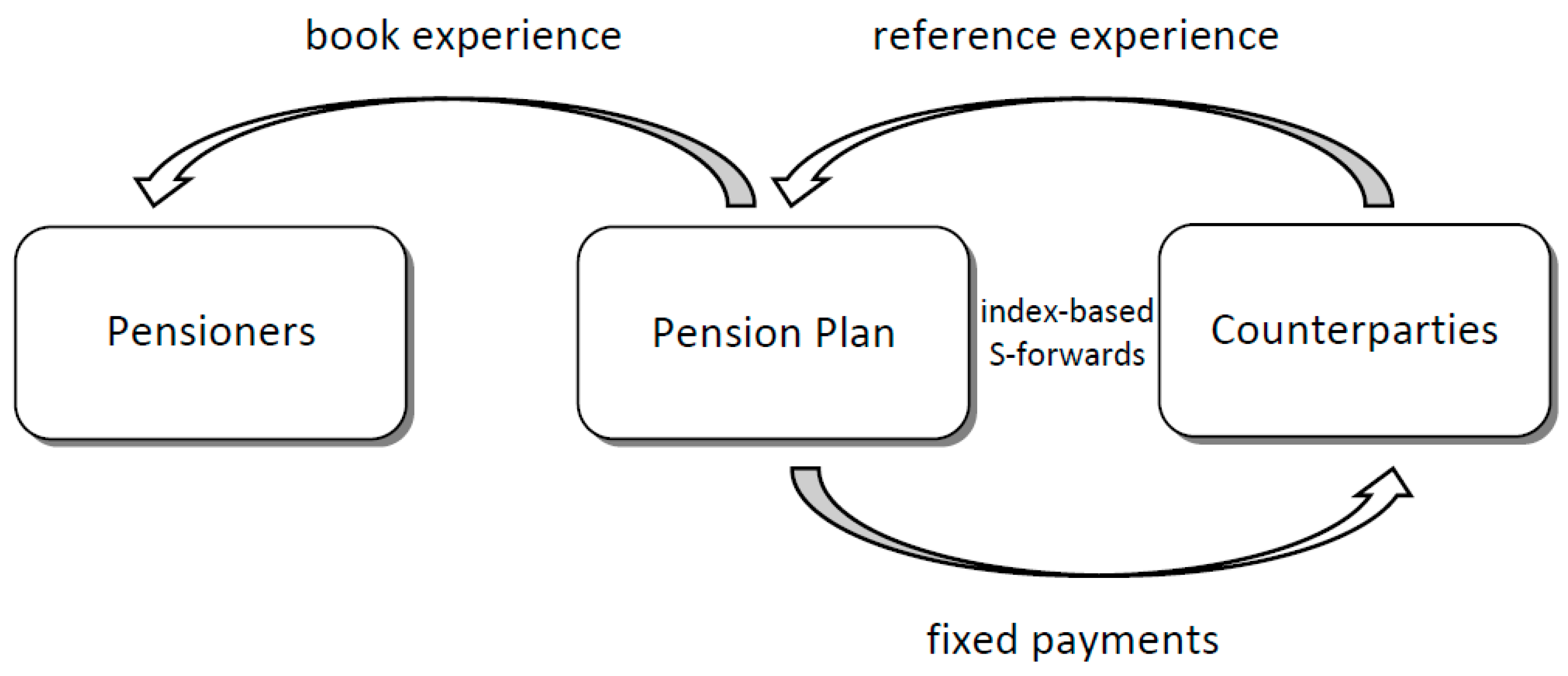
We mainly consider a hypothetical situation of a large pension plan with 10,000 members for a particular cohort. All the pensioners are aged 65 and every pensioner receives
$1 on survival of each year in the next 25 years. Suppose that the pension plan financier attempts to minimize its longevity risk exposure by building a longevity hedge with index-based S-forwards (e.g.,
LLMA 2010), and that the S-forward at every future age is available for the same birth cohort as the pensioners. For a floating rate receiver, the payoff on maturity of a S-forward is equal to the actual survivor index (observed on maturity) minus the forward survivor index (set at time 0), in which the survivor index is the percentage of the reference population who are still alive on maturity. Assume that the current forward values are equal to the central estimates, setting a zero risk premium for convenience, and that the interest rate is constant at 1% p.a. throughout the period, considering the current low interest rate environment. The valuation date is taken as just after the end of the data period.
After fitting the above-mentioned models to the data and carrying out the simulations as in the previous section, we use the simulated future death rates of the book population and the binomial distribution to further simulate the number of surviving pensioners in each future year (e.g.,
Haberman et al. 2014). We can then obtain random samples of the present value of the pension plan liability. On the other hand, we use the simulated future death rates of the reference population to determine the random S-forwards payoffs, which are discounted to the valuation date. The notional amounts of the S-forwards are calculated by numerical optimization in order to maximize the level of hedge effectiveness (e.g.,
Li et al. 2017). The weights are mostly in the range of 0.6 to 1.1 (per person) in different cases of our analysis.
Figure 4 demonstrates the longevity hedging scheme based on the use of index-based S-forwards. Please note that the counterparties can be a financial exchange or intermediary that brings the market investors (hedge providers) and the pension plan (hedger) into conducting standardized transactions.
Table 1 lists the BIC (Bayesian Information Criterion) values of fitting the three two-population mortality projection models to the various datasets via an iterative updating scheme based on Newton’s method. In the mortality forecasting literature, the BIC is much more popular than the Akaike Information Criterion (AIC), as it is generally perceived that the BIC imposes a higher penalty on the use of parameters and can point to more parsimonious models. For the first three hedging scenarios, the M7-M5 model (3) produces the lowest BIC values (the italic figures). For the Taiwan pension plan hedged by a Japan index, and also the Singapore pension plan hedged by a Hong Kong index, the bivariate Lee–Carter model (1) gives the lowest BIC, followed very closely by the common factor model (2). Although the BIC is probably the most frequently used selection criterion in the mortality projection modeling literature, it is fundamentally a measure on how good the past patterns are being captured under parsimonious use of parameters, which may or may not lead to accurate or reasonable future predictions. Moreover, as noted earlier, there is always some level of uncertainty in model selection, and the BIC alone (and even together with residuals examination) may point to a less appropriate model given the random fluctuations in the data and the lack of information on possible outliers. In fact, several other model aspects should also be considered (e.g.,
Cairns et al. 2009). In terms of allowing for longevity basis risk, the most relevant model aspects would be the coherence property, behavior of simulated future variability, and simulation method.
Table 2 summarizes the behavior of the central estimates and simulated variability of each time series process considered.
Table 3 provides the details of the selected orders of the fitted time series processes for all the datasets.
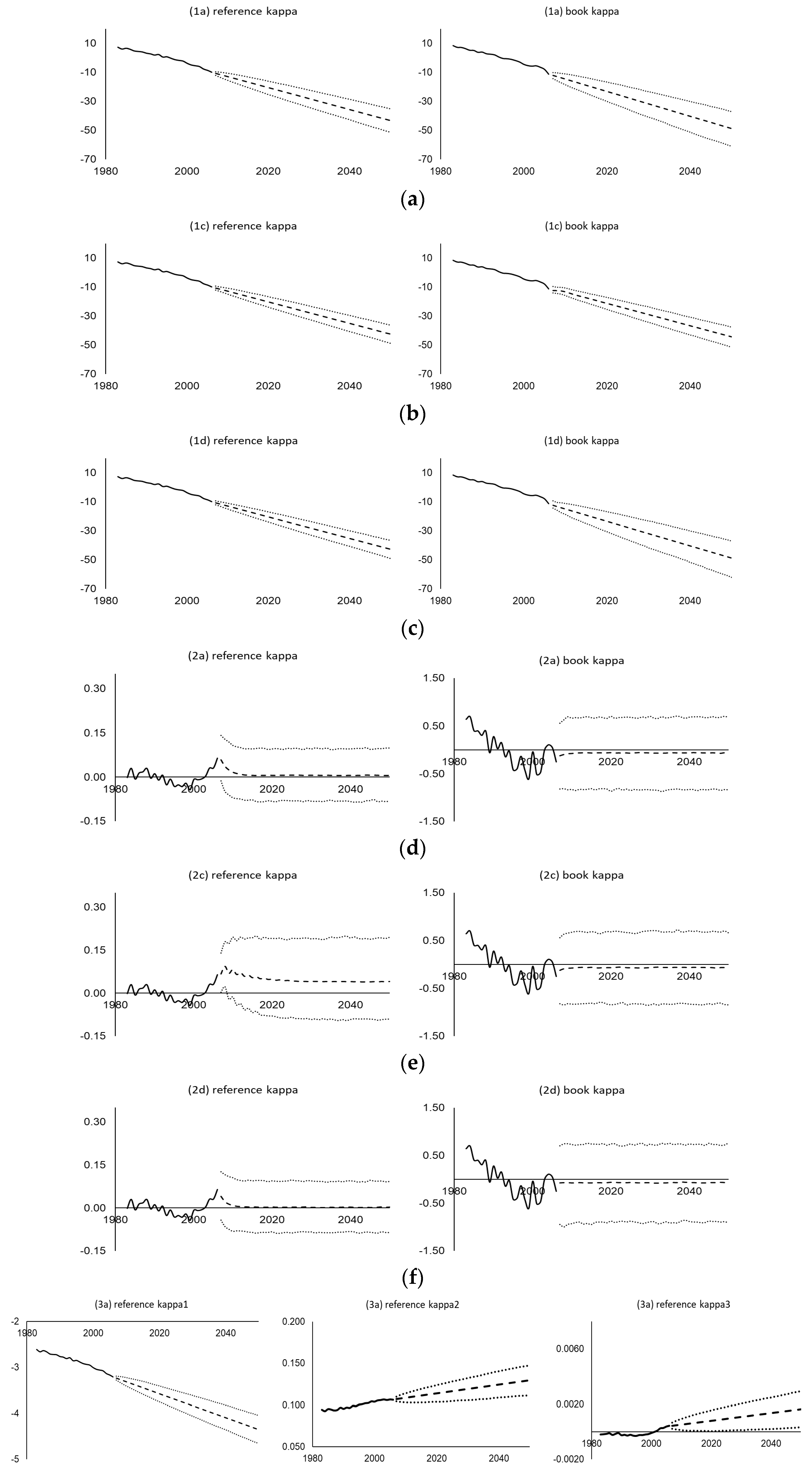
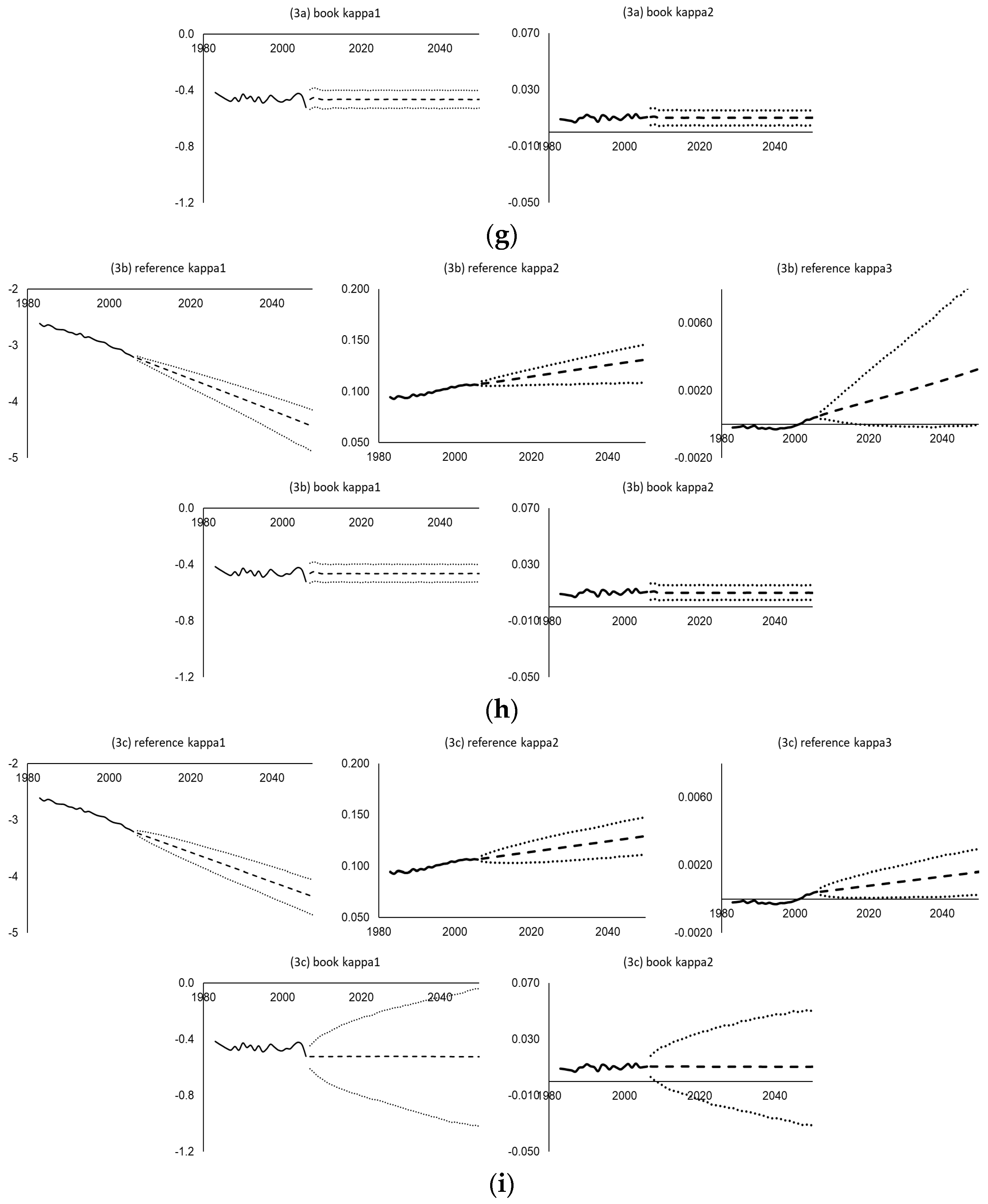
Figure 5 then shows the various time-varying parameters estimated (solid lines), their central estimate projections (dashed lines), and their simulated 95% prediction intervals (dotted lines) using the UK assured lives data under different mortality projection models and time series processes. As shown, the random walk, co-integrated, VECM, and integrated autoregressive processes all produce linear projected (central estimate) trends and increasing variability across time in the simulations, whereas the (weakly stationary) autoregressive processes show convergence and bounded variability. The widths of the prediction intervals vary between different time series processes. For example, within the Lee–Carter family, the VECM(2) generates narrower intervals for both
and
, and the VARIMA(1,1,0) produces wider intervals for
but narrower intervals for
. For the Li-Lee family, the AR(3) yields wider (bounded) intervals for
compared to the AR(1) and VAR(1). For the CBD family, the VARIMA(2,1,0) leads to wider intervals for
,
, and
compared to the multivariate random walk with drift, and the bivariate random walk without drift leads to unbounded intervals for
and
, in contrast to the bounded intervals from the VAR(2). Some goodness-of-fit test results of the fitted time series processes are given in the
Appendix A.
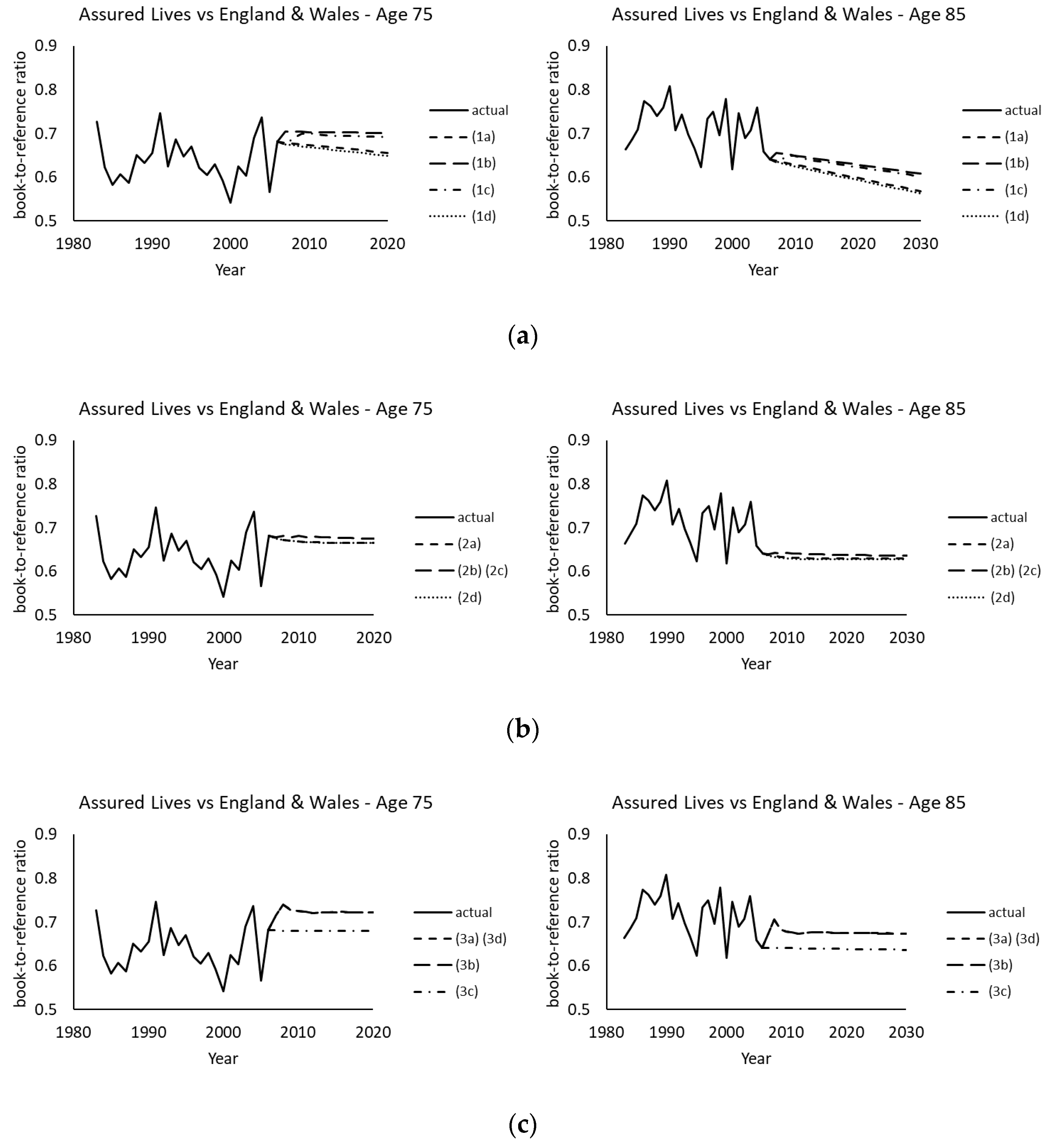
Figure 6 plots the corresponding book-to-reference ratios of projected death rates at ages 75 and 85. In agreement with the descriptions in the previous section, models (1a) to (1d) produce divergent ratios of projected death rates between the two populations. Moreover, the projected ratios diverge in various directions at different ages even under the same model. By contrast, models (2a) to (2d) and (3a) to (3d) yield convergent ratios of projected death rates at each age, which are in the range of around 0.6 to 0.7 as illustrated in the plots.
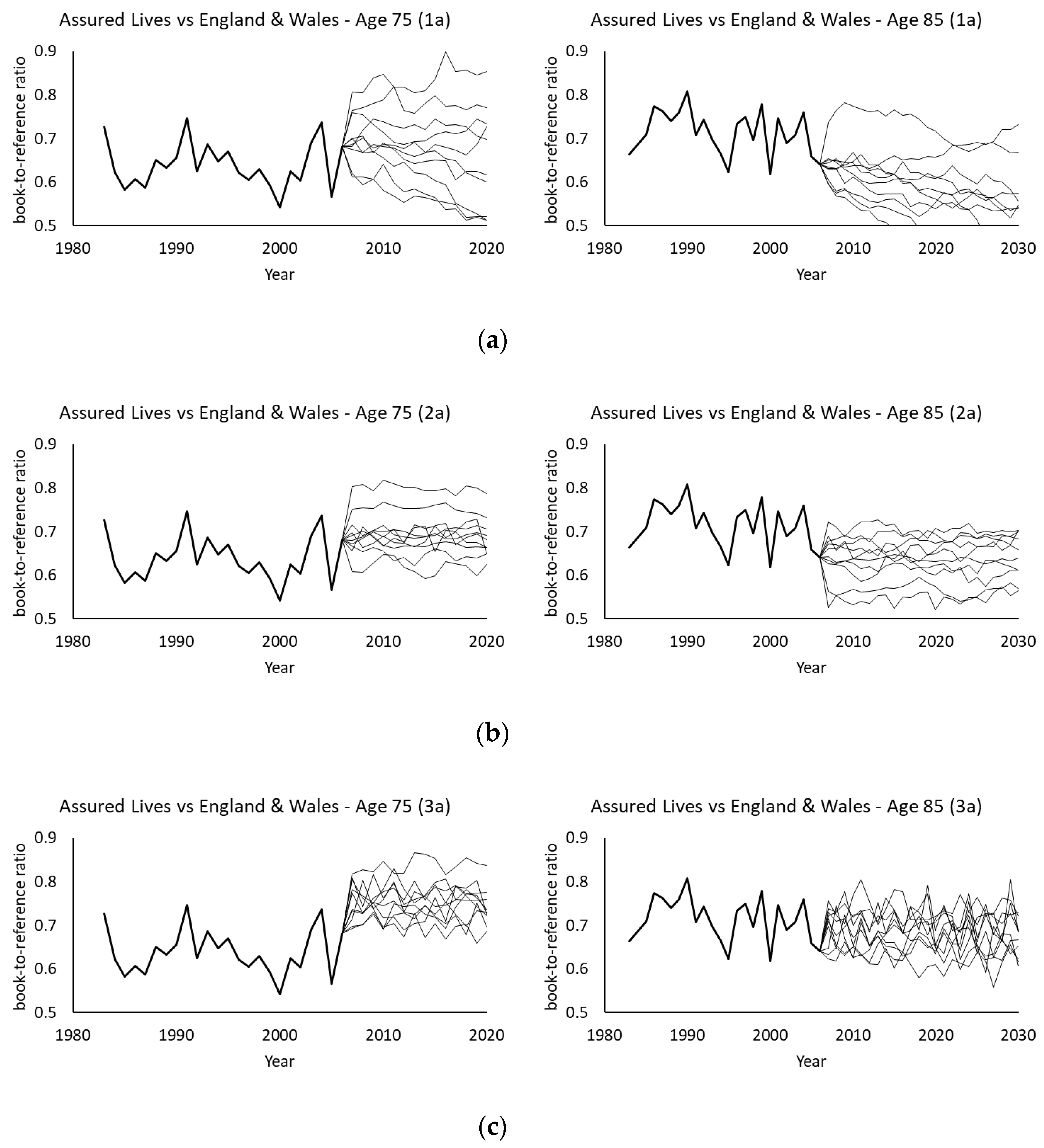
Figure 7 then displays some simulated ratios using 10 randomly picked simulated paths. There are clear differences between model (1a) and models (2a) and (3a). Under model (1a), the simulated ratios can move to values very different from the projected ones over time, while under models (2a) and (3a), the simulated ratios fluctuate around the projected levels. The potential variations under model (1a) are much greater than those under models (2a) and (3a), in which model (3a) demonstrates more obvious fluctuations but within a shorter distance from the projected values than model (2a). Since demographic basis risk arises from possible deviations between the book and reference mortality movements (due to demographic or socioeconomic differences), the behavior of these simulated ratios of death rates would have a significant implication on the calculated levels of hedge effectiveness, which will be discussed in the following numerical analysis.
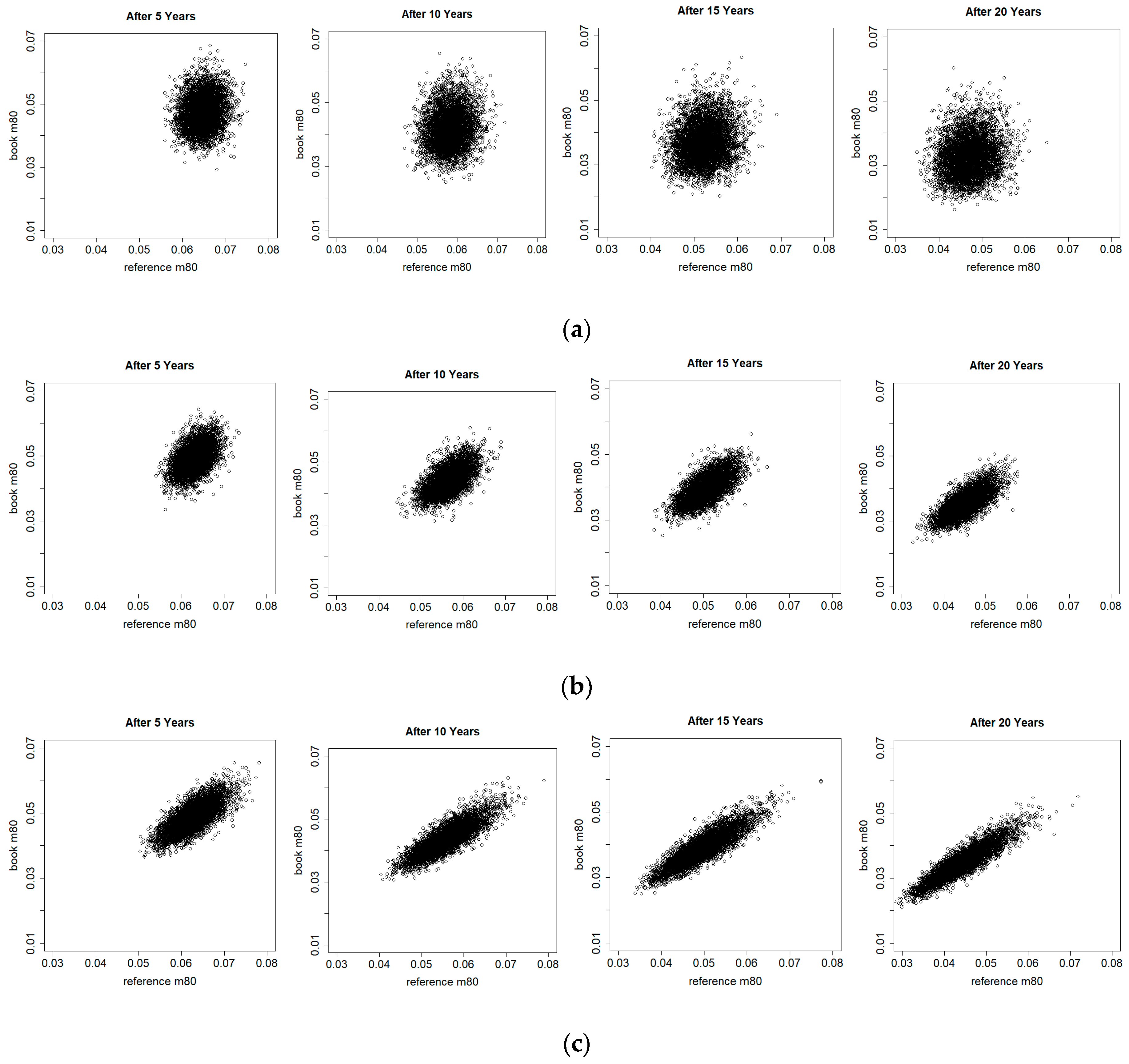
Figure 8 offers a different view on the simulated book and reference death rates at age 80 at different points of time using the UK pensioners data. It can be seen that over time, the simulated death rates move to the southwest direction due to mortality improvements, and the simulated variability (both the vertical and horizontal ranges) increases because of higher uncertainty in more distant future. However, again, there are significant differences between the three models. For models (2a) and (3a), the dependence between the simulated book and reference death rates increases gradually with time, whereas for model (1a), the weak dependence appears to remain at a low level. It means that for the former the two death rates are very unlikely to deviate significantly further from each other in the long term, but for the latter the two death rates can move in varying directions. The different model structures clearly have a large impact on the resulting association between the two populations in the simulations. The discussion of the numerical study below will explore the underlying reasons for these observations. These simulated differences in the dependence would affect the calculation of basis risk and hedge effectiveness significantly, as shown later.
Table 4 sets out the estimates of the standard deviation and the 99.5% Value-at-Risk (VaR) (minus the mean) of the present value of the pension plan liability, as a percentage of the expected present value of the liability. On average, the standard deviation is about 1.7% and the 99.5% VaR is around 4.3% of the mean, in which the ratio between the two measures is close to that of a standard normal distribution. For the assured lives and pensioners datasets, the bootstrapping approaches generally give larger VaR estimates than those from Monte Carlo simulation (the cells within borders), while for the other datasets, the differences are less obvious. The potential heterogeneity issue of the former may be the reason they demonstrate a greater effect of parameter uncertainty. The simulated variability from the Li-Lee family (2a, 2b, 2c, 2d) (the shaded rows), but not the other two families, is fairly robust to the selection of time series process. Model (3c) produces by far the largest estimates (the bolded figures) among all the models. It appears that the bivariate random walk for
together with the multivariate random walk for
in model (3c) produces much more variability in the book simulations compared with the other models.
In line with
Coughlan et al. (
2011) and
Li et al. (
2017), the level of hedge effectiveness is defined as [1 –
riskhedged/
riskunhedged] × 100%. The two quantities
riskunhedged and
riskhedged are the pension plan’s longevity risk exposure before and after implementing the hedge. This measure gives the proportion of the original longevity risk exposure that is being transferred away. The remaining risk can then be seen as a result of longevity basis risk. We consider the longevity risk exposure as the standard deviation and the 99.5% VaR minus the mean of the present value of the pension plan liability. Please note that the 99.5% VaR measure is highly relevant to the Solvency Capital Requirement (SCR) calculation under Solvency II. It is a very important consideration for insurance practitioners and regulators in Europe.
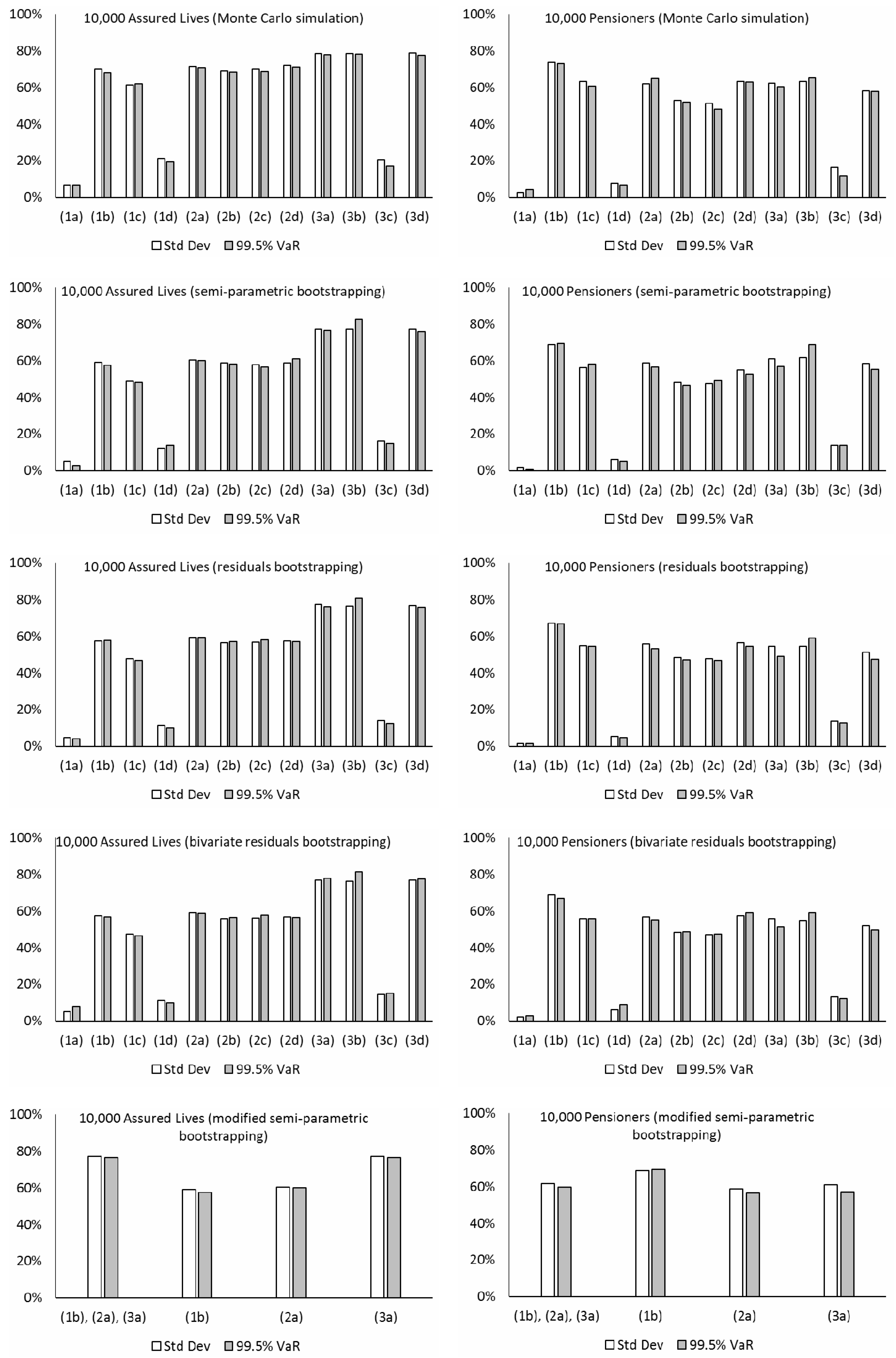
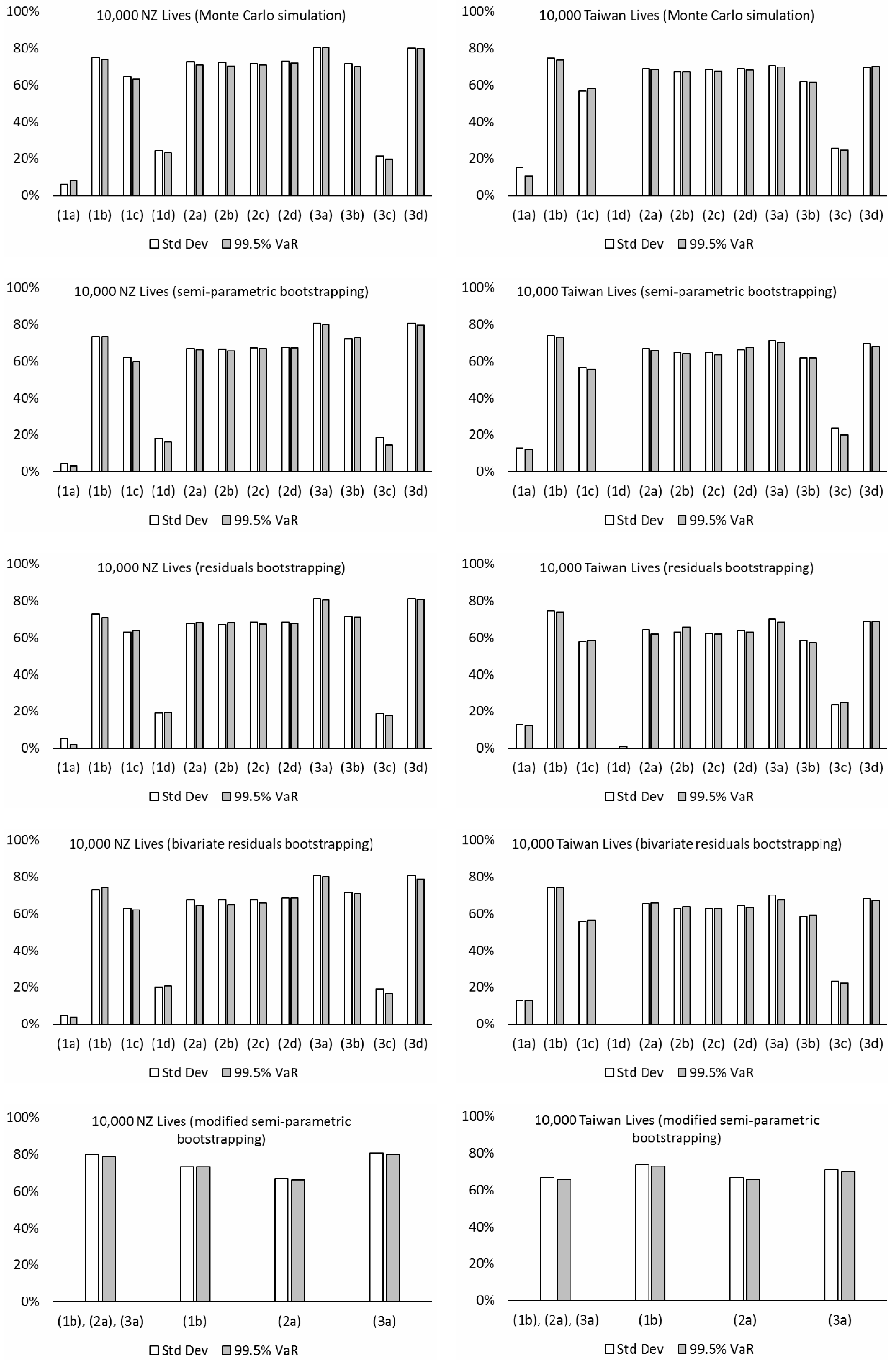
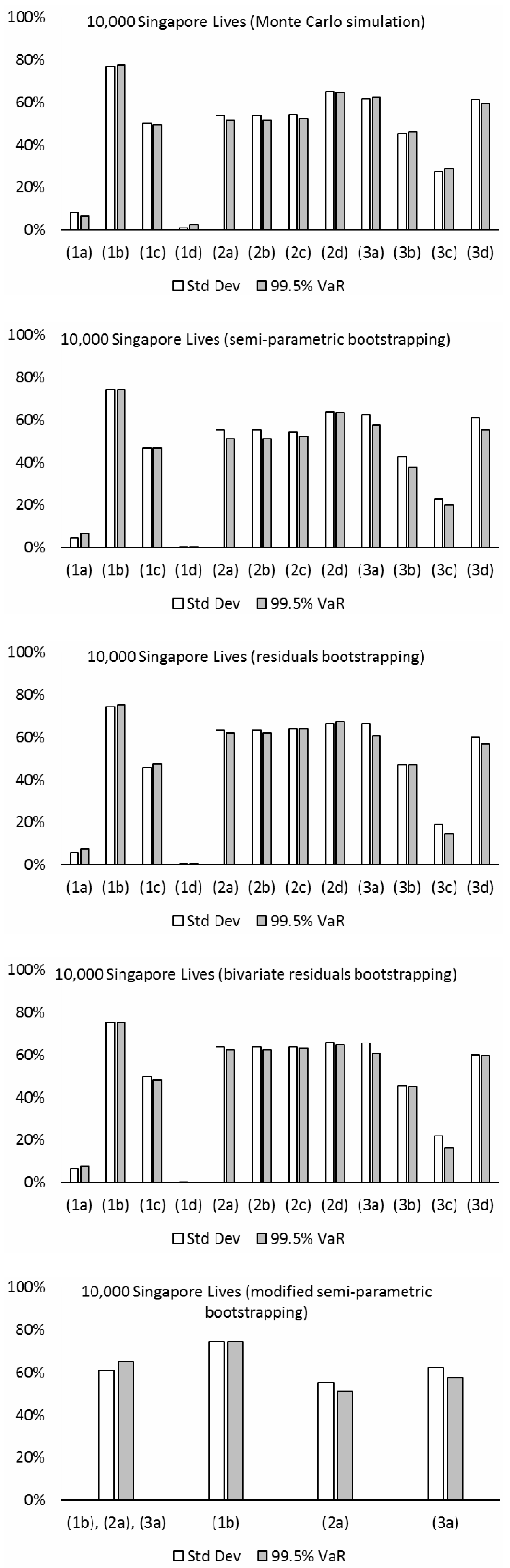
Figure 9 presents the levels of hedge effectiveness (i.e., the proportion of the initial risk that is reduced) under various models and simulation methods using different datasets. The major observations and implications from the numerical results are listed below:
The estimated levels of hedge effectiveness are largely between 50% to 80%. The clear exceptions include those produced from models (1a), (1d), and (3c), which are about 20% or lower. The first two of these three cases are non-coherent and generate increasing variability in the time-varying parameters’ future simulations for both the book and reference populations. Although the estimated correlations in their Gaussian error terms are quite high (about 0.3 or greater), the relationship between the book and reference mortality levels under the two models looks too weak, when considering their past movements in the data (see
Figure 3), and there is an overestimation of longevity basis risk. Comparatively, while models (1b) and (1c) are also non-coherent, their co-integration and error correction structures lead to some extent of co-movements between the two populations in the simulations, which is reflected in the estimated hedge effectiveness. The last exception, model (3c), is coherent, but it produces increasing simulated variability over time for the “book minus reference” component’s time-varying parameters. The resulting effect is that the simulated book and reference mortality movements could deviate significantly from each other, progressively so over the long run, leading to an overestimation of longevity basis risk and so an underestimation of hedge effectiveness. By contrast, the other model choices do not suffer from this problem.
The results from the Li-Lee family (2a, 2b, 2c, 2d) are generally quite robust to the choice of time series modeling, as long as the fitted time series processes are weakly stationary. Under the Li-Lee mortality structure, both populations are governed by the common factor, in which the common mortality index has increasing variability over time in the simulations, while the additional population-specific factors’ time-varying parameters have bounded variability in the simulations under all the four choices. Consequently, the former variability would dominate eventually, and any deviance between the simulated book and reference mortality movements is unlikely to continue to grow. The figures from models (2b) and (2c) are slightly lower than those from model (2a) (by only about 3% in magnitude on average; more obvious for the pensioners dataset), due to the higher selected orders in the former. However, in general there is not much difference in the results between models (2b) and (2c), and also between models (2a) and (2d), which suggest that the additional dependence (via correlation or vector autoregression) is unlikely to have a material impact on assessing longevity basis risk. Besides, though the common factor provides a convenient way to capture the link between the two populations, the common factor model (2) requires using the same data length for both populations in maximum likelihood estimation. In practice, the length of book data is usually shorter, and approximation methods or Bayesian techniques may be adopted to fit the model under the presence of missing data.
The figures from models (3a), (3b), and (3d) of the CBD family tend to be higher than those from models (2a) and (2d) (by about 10% in magnitude or more) for the assured lives and the New Zealand portfolios, while the two sets of results differ more randomly for the other datasets. Under these models, the reference component’s temporal parameters have increasing simulated variability over time, while the “book minus reference” component’s temporal parameters have bounded simulated variability instead. The variability in the reference component would then dominate in the long term, whereas the variability in the second component would become less influential comparatively. The consequence is that the book and reference mortality movements cannot deviate indefinitely in the simulated scenarios. The results are about the same between models (3a) and (3d), which again suggest that the additional dependence (via correlation) does not have an obvious effect on measuring longevity basis risk. For model (3b), as noted previously, the prediction intervals for , , and based on the VARIMA process are often different to those based on the multivariate random walk with drift in model (3a). Some subsequent effect can be seen in the differences between the figures from models (3a) and (3b), in which the latter ones tend to be lower.
The hedging results estimated from Monte Carlo simulation tend to be higher than those from the bootstrapping approaches (by about 7% in magnitude on average) for the assured lives and pensioners datasets. Since performing Monte Carlo simulation directly on the error terms of the time series processes allows for only process error but not parameter error, there would be an underestimation of longevity basis risk and hence an overestimation of hedge effectiveness. But for the other datasets (New Zealand, Taiwan, and Singapore), there are no such obvious differences, which indicate that the effect of parameter uncertainty is not material for these proxy book data with a large size and more stable population compositions and mortality patterns. In addition, there are no clear, significant differences between the results estimated from the two residuals bootstrapping approaches, in which one involves resampling the reference and book residuals separately and the other groups together the two sets of residuals in each age-time cell as an individual data point for resampling. It means that the additional dependence from linking the residuals does not appear to have any effect on longevity basis risk calculation. Some random differences in the results between the semi-parametric bootstrapping and the residuals bootstrapping can also be seen, but most of them are small and do not show any particular patterns.
For a demonstration of applying the modified semi-parametric bootstrapping approach, we integrate models (1b), (2a), and (3a) which have earlier been shown to produce more reasonable estimates of hedge effectiveness. Following
Yang et al. (
2015), the optimal model for each pseudo-data sample in the bootstrapping process is selected based on the BIC. That is, the BIC values of fitting the three mortality projection models are compared, and the one with the lowest value is chosen for that pseudo-data. Note that besides a single statistical criterion, a mix of other quantitative and even qualitative criteria may also be used, though the selection rules will then be more complex, and the computation time will lengthen.
Table 5 gives the proportions of different models being chosen out of 5000 scenarios in each case. For the assured lives, pensioners, and New Zealand datasets, model (3a) dominates in all the simulated scenarios. For the Taiwan portfolio, model (2a) is selected in 99% of the scenarios and model (1b) is selected in only 1%. For the Singapore portfolio, models (2a) and (1b) share a split of 58% and 42%. Furthermore, as shown in
Figure 9 (last row), regarding the Singapore portfolio, the final hedging results from this approach may be perceived as a “weighted” average of those calculated separately from models (1b) and (2a), in which the “weights” are determined by how well the two models are fitted to each of the 5000 pseudo-data samples.
The estimated levels of hedge effectiveness are quite close between using the standard deviation and 99.5% VaR in most cases. This observation may result from the fact that the simulated distributions of the pension plan liability are fairly symmetric and do not have a heavy tail, under all the mortality projection models, time series processes, and simulation methods considered, both before and after hedging. We have also checked the results based on the 95% VaR and the observations are similar.
When the size of the pension plan is reduced to 1000 members, the levels of hedge effectiveness estimated from those coherent models drop to mostly around 20% to 40% (not shown here). By contrast, when the pension plan size is infinite (i.e., the step of using the binomial distribution to simulate the number of lives is omitted), the estimated levels of hedge effectiveness largely rise by about 10% or more in magnitude from the initial setting of 10,000 members. The effect of sampling basis risk is significant, which pinpoints that index-based longevity hedging would be more feasible for either very large pension plans, foundations joined by small pension plans, or reinsurers who have accumulated sizable longevity risk exposures from smaller insurers and pension plans.
There are some differences in the hedging results between using the five datasets. On average, after integrating both process error and parameter error via the bootstrapping approaches, the highest level of hedge effectiveness is given by using the New Zealand dataset, followed by the Taiwan, assured lives, Singapore, and pensioners datasets. It has been mentioned earlier that parameter error would be immaterial for book data with stable population compositions and mortality patterns, which may explain some of the results here. Another possible reason for the greater hedge effectiveness shown by the New Zealand pension plan hedged by an Australia index is the geographical and cultural closeness between Australia and New Zealand. Both neighbors are island nations in the South Pacific and have very close connections historically, socially, and economically, and they would tend to have more concurrent mortality movements than otherwise.
Under models (2a), (2b), (2c), (2d), (3a), (3b), and (3d), the calculated levels of hedge effectiveness of the annual cash flows (not the present value; not shown here) are indeed very low in the early years, but then increase significantly across time, i.e., the dependence between the two populations’ mortality levels grows with time in the simulations. For the Li-Lee model types, the common mortality index has increasing variability, while the additional time-varying parameters have bounded variability. Similarly, for the M7-M5 model types, the reference component’s time-varying parameters have increasing variability, but the book component’s time-varying parameters have bounded variability. The resulting model effect is that the simulated variability of the differences between both populations would have lesser impact gradually. Hence the association between the two populations increases over time (see
Figure 8).
The weights of the S-forwards are numerically optimized to maximize the hedge effectiveness. Excluding models (1a), (1d), and (3c) which generate unreasonable simulations, for the assured lives dataset, the weights are roughly about 0.5 (per person) in the first half of the age range, 0.7 in the third quarter, and 0.9 in the last quarter. For the pensioners dataset, the weights are around 0.7 in the first half of the age range and 0.9 in the second half. For the New Zealand, Taiwan, and Singapore datasets, most of the weights are approximately equal to one for the whole range. Interestingly, the major patterns in the weights estimated are not too different between the various models. It should be noted that these weights are subject to the technical limitations of the optimization process, uncertainty of the model choice, and random variations in the simulated samples. In addition, in practice, it would be impossible to enter into such numerically precise amounts of S-forward positions due to liquidity issues. Accordingly, we have also tested the hedging results using the approximate weights noted above, and we realize that the corresponding reductions in the levels of hedge effectiveness are actually quite small, mostly being a few percent in magnitude.



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}












