The Linear Link: Deriving Age-Specific Death Rates from Life Expectancy

 , , and
, , and 
Abstract
:
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
1. Introduction
2. Data and Methods
2.1. Data
2.2. The Model
2.3. Algorithm
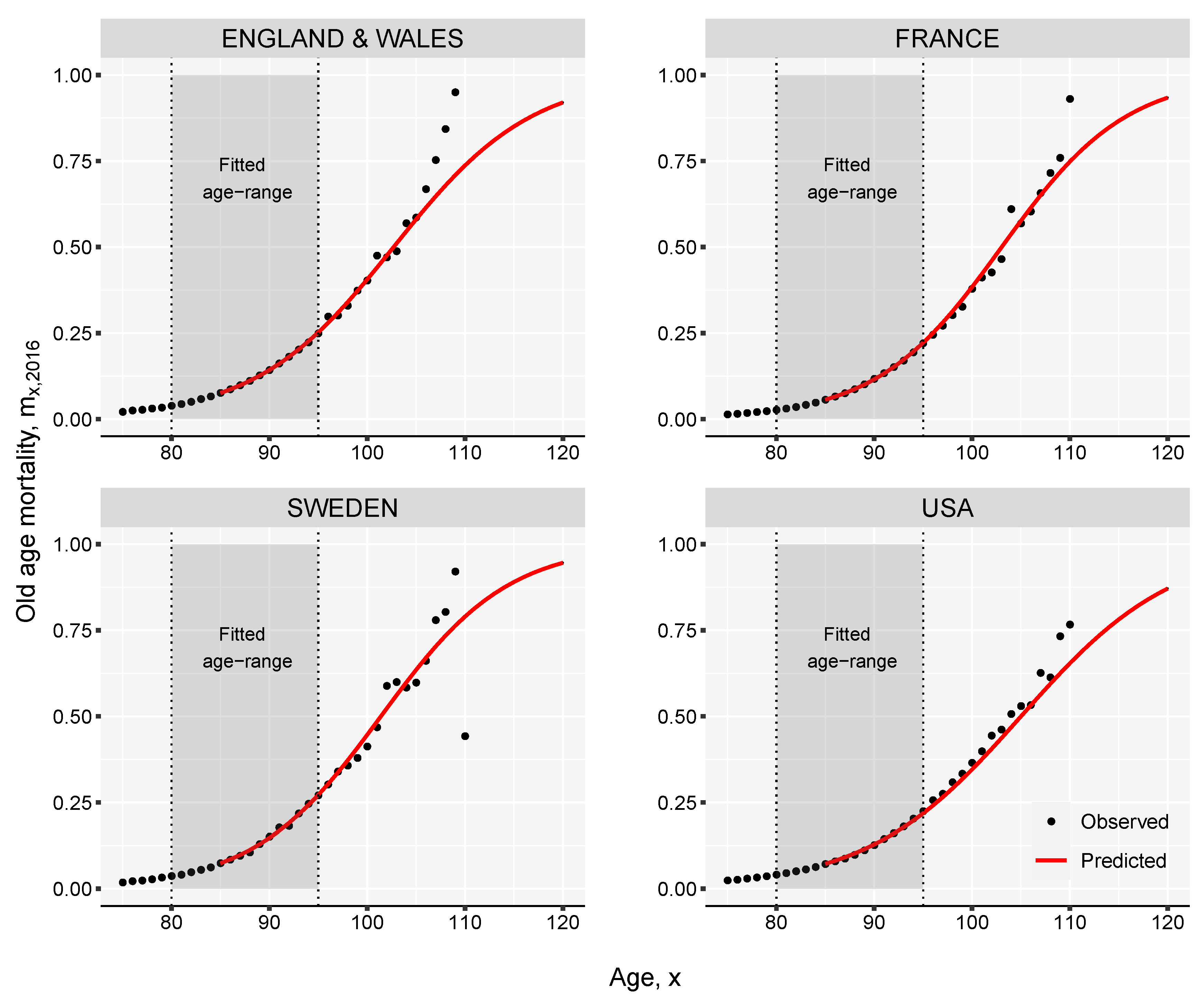
- Using the Kannisto mortality model (see Appendix A) extend to higher age groups up to age for all times t. The highest attainable age, , can be set for example to 120.
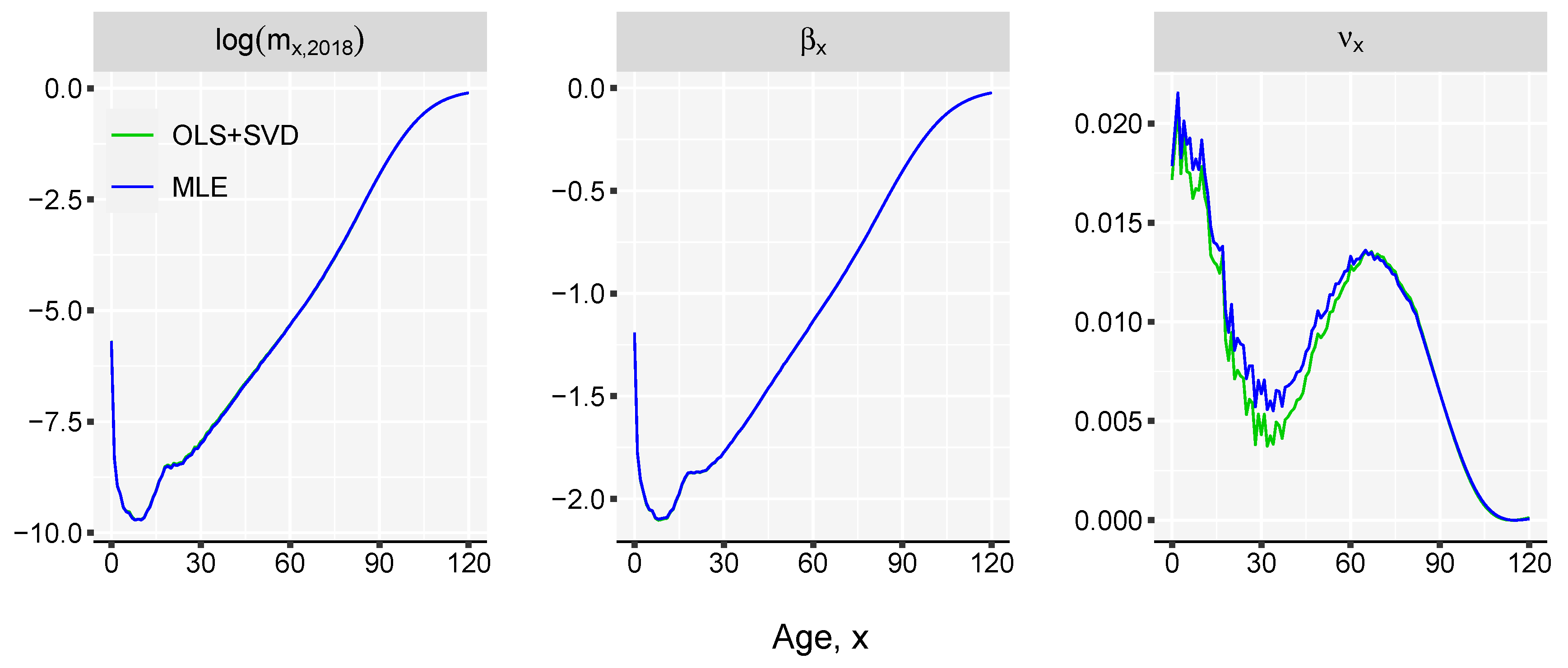
- Estimate the slope of the linear relation between life expectancy and the death-rates, , over the observation time t. This is done by using the method of the least squares approach, by minimizing the sum of squared residuals:Alternatively, the parameters of the model can be estimated by assuming that deaths follow a Poisson distribution (Brillinger 1986; Brouhns et al. 2002), , with . In order to use this approach death counts () and central exposure data () are needed. Sensitivity analysis shows that the difference between the two fitting procedure return minor discrepancies (see Appendix B in the Appendix for more details).
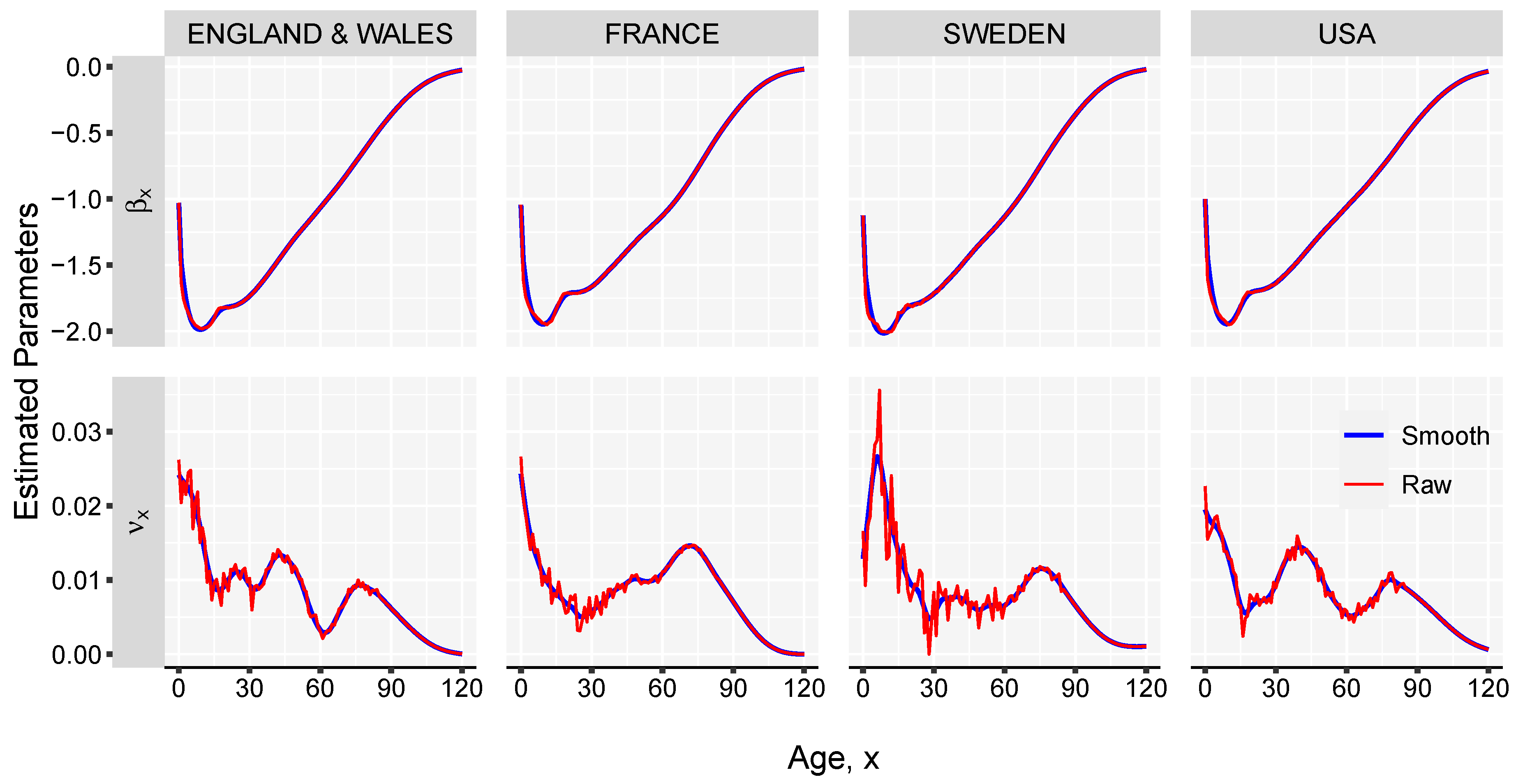
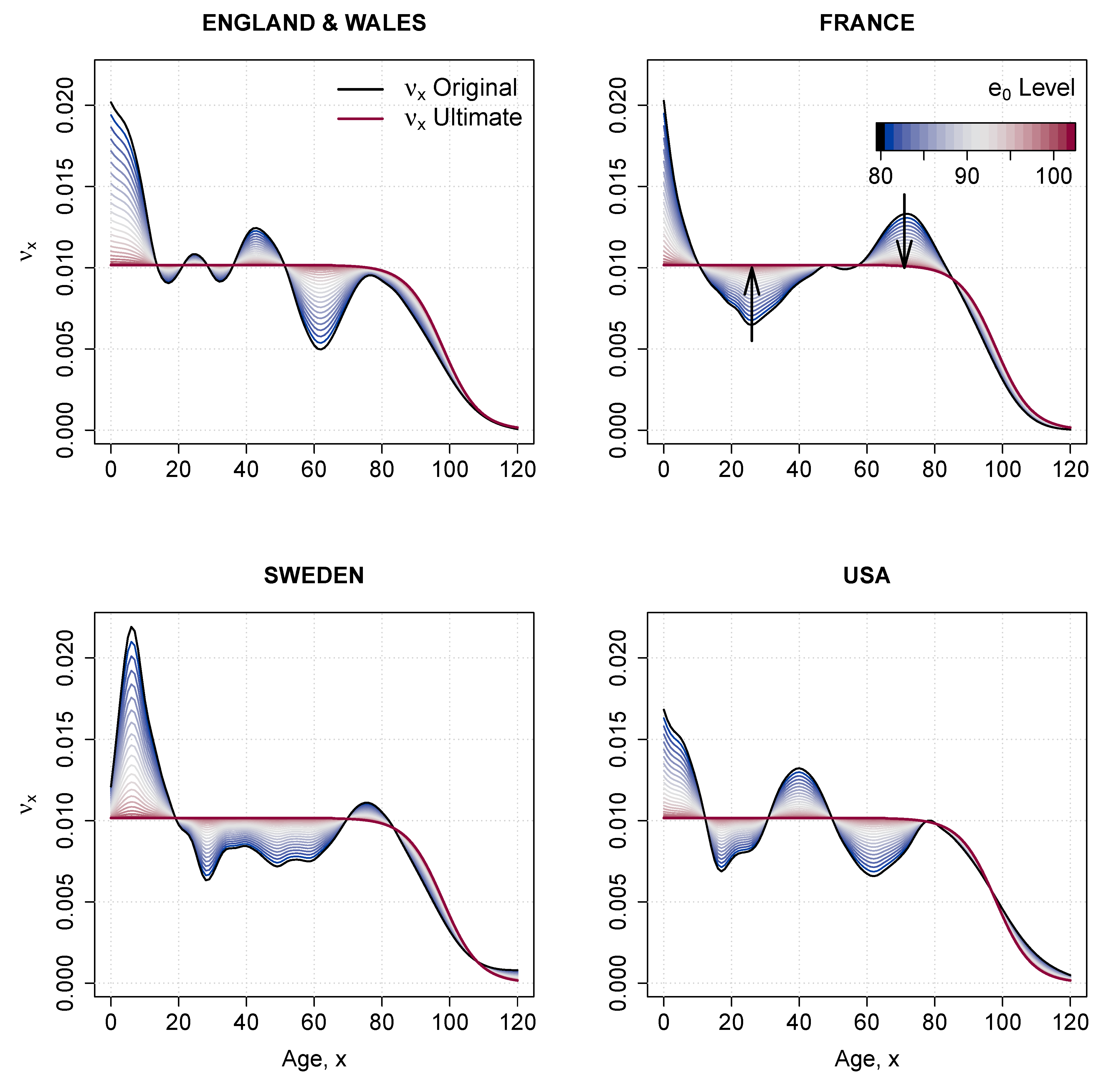
- Estimate the parameter by computing the singular value decomposition (SVD) of the matrix of regression residuals, , obtained in the previous step,whereand are matrices of left and right singular vectors, and is a diagonal matrix with singular values along the diagonal. The fist term of the , , is used for obtaining the estimates of . Parameter can be interpreted as the rate of mortality improvement over age.
- Smooth the and parameters using splines. This step is important to obtain graduated mortality curves and avoid projecting age-specific noise in the jump-off life table. However, if the graduation is not of interest or if the input data-set is large enough, this step can be skipped.
- Compute the initial mortality rates1 by , where .
- Optimize the mortality curve given in the previous step by finding the value of k where the difference between target life expectancy and an estimated life expectancy is below a tolerance level, for example 0.001, where represents the level of life expectancy at birth computed based on the mortality rates obtained in step (5). Usually k will be in the range of depending on the length of the forecast window.
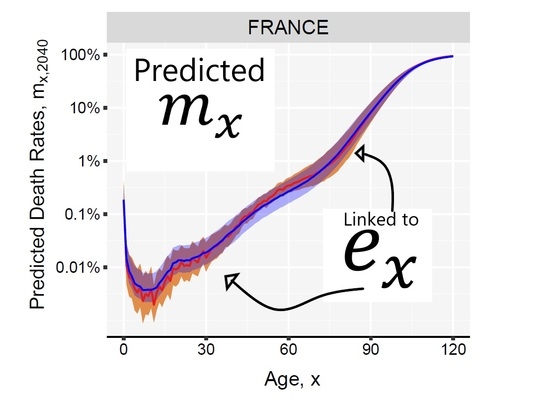
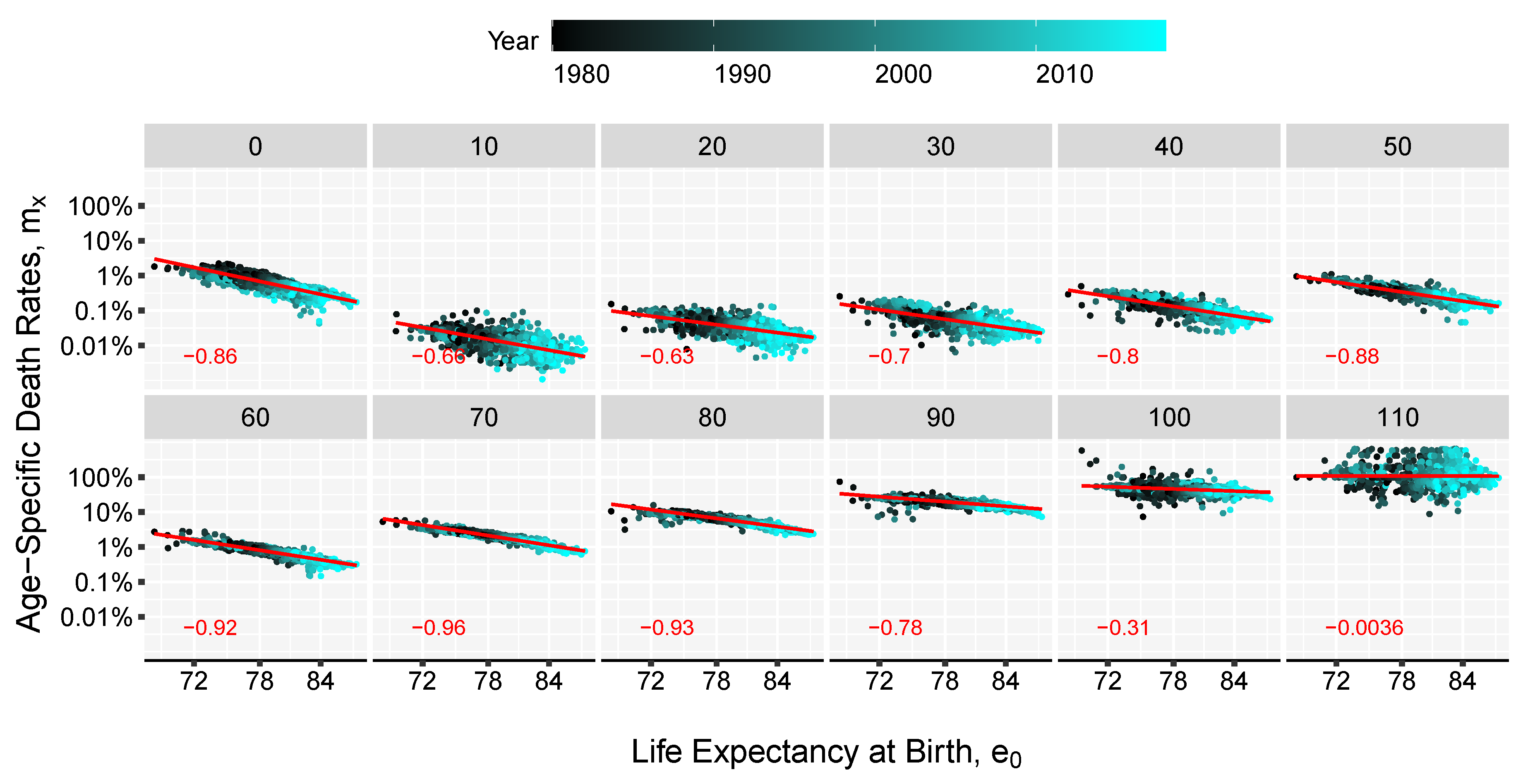
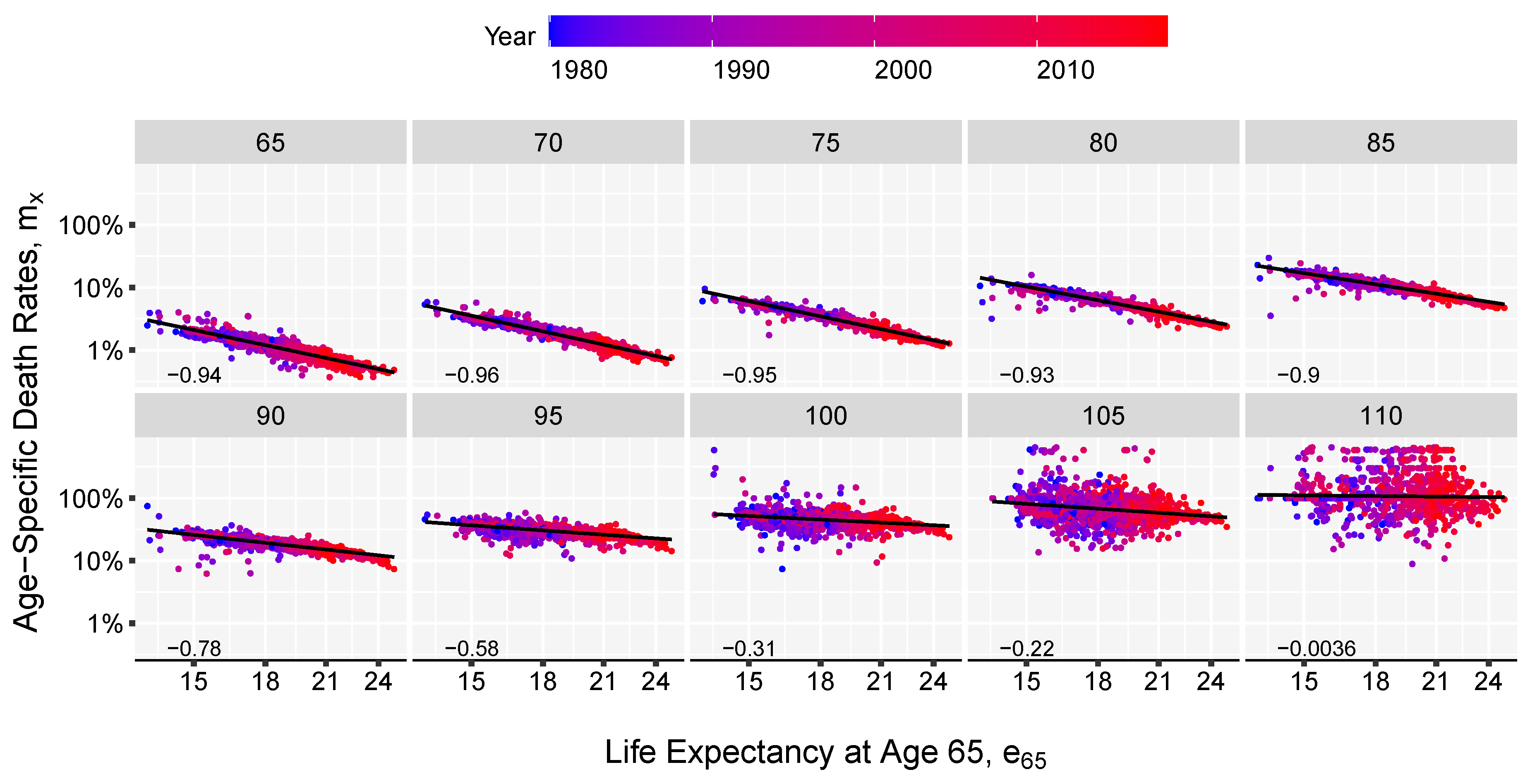
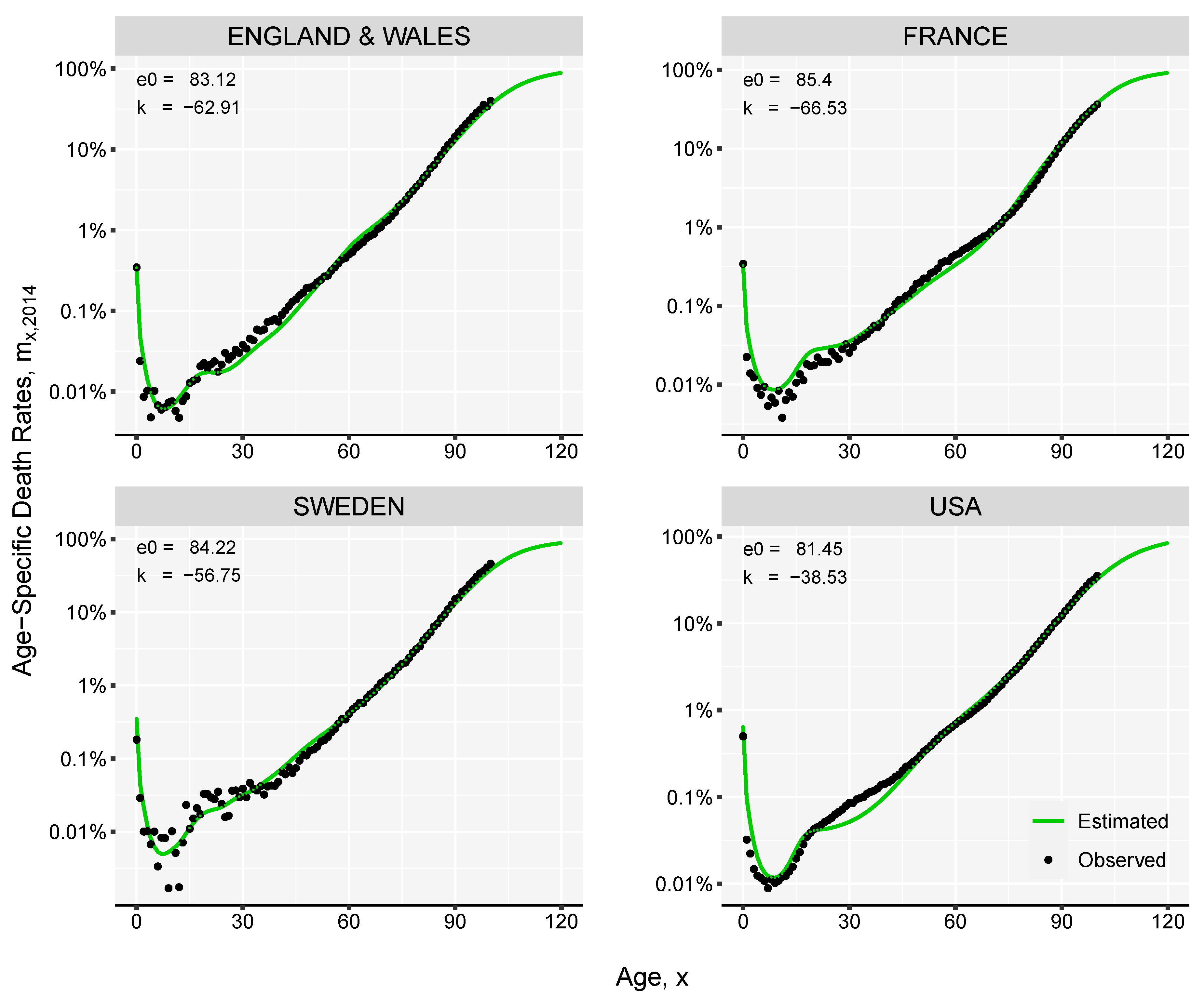
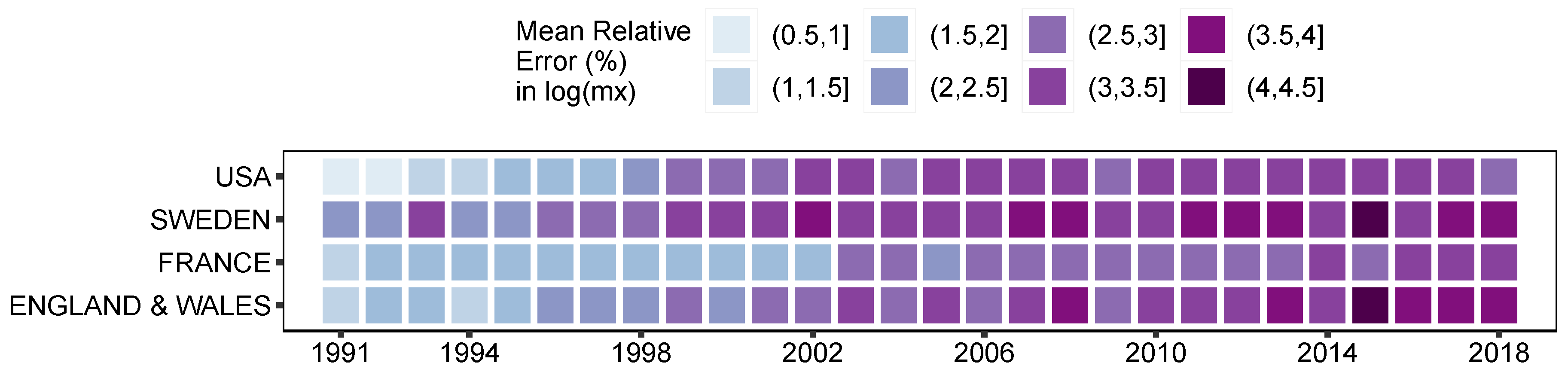
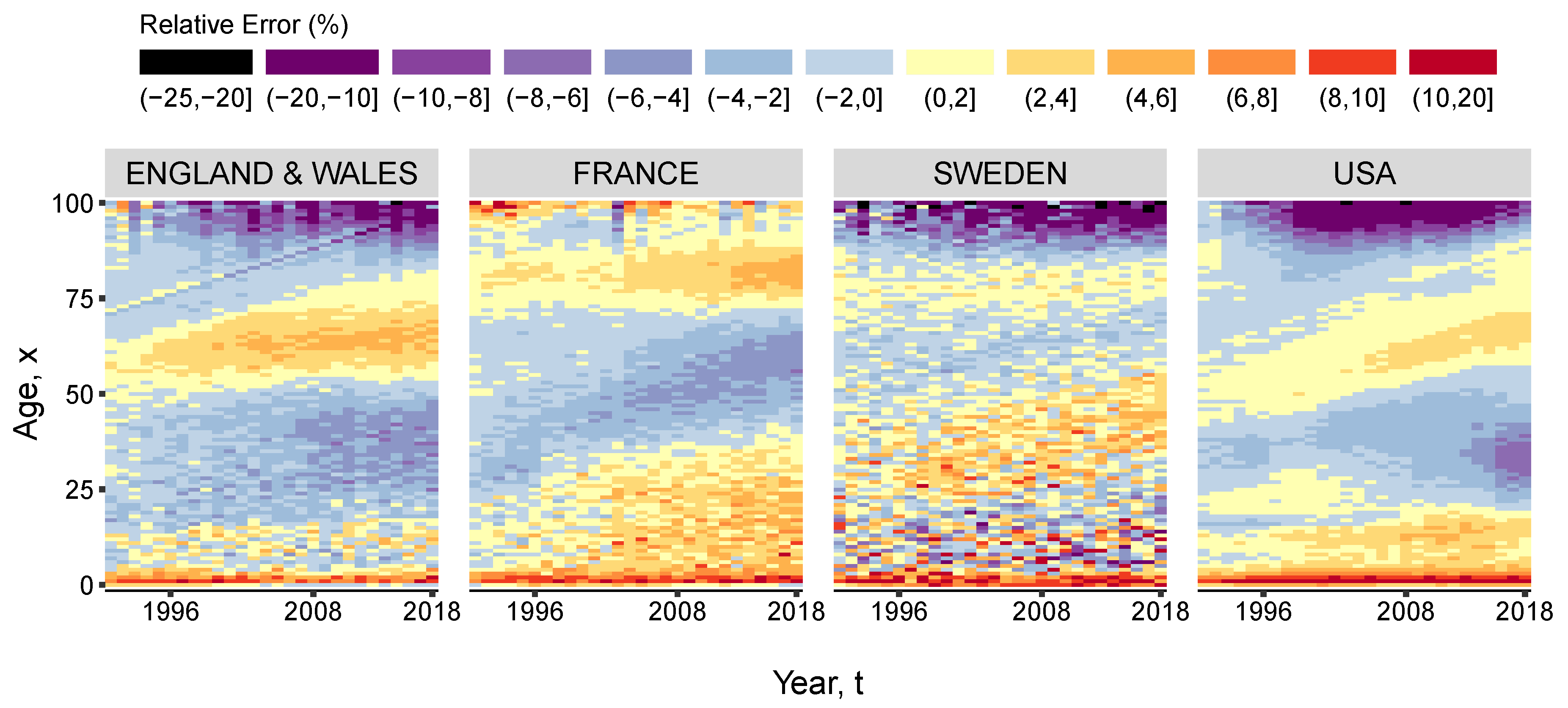
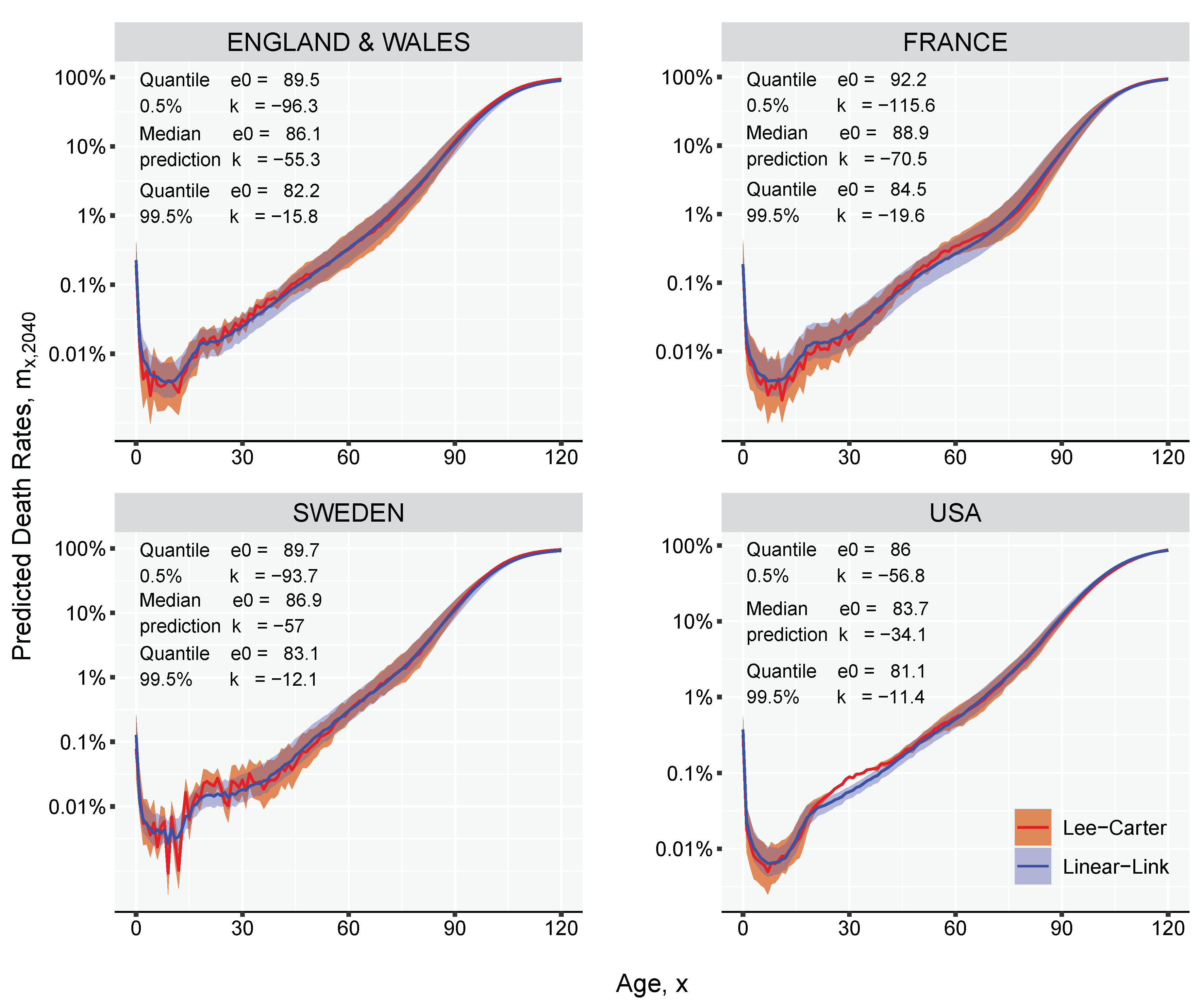
3. Results and Illustration
4. Discussion
5. Reproducible Research
Author Contributions
Funding
Conflicts of Interest
Appendix A. The Kannisto Model

Appendix B. Maximum Likelihood Estimation

Appendix C. Rotation of Mortality Improvements

References
- Alho, Juha M. 2000. The Lee-Carter method for forecasting mortality, with various extensions and applications, Ronald Lee, January 2000. North American Actuarial Journal 4: 91–93. [Google Scholar] [CrossRef]
- Bengtsson, Tommy. 2006. Linear increase in life expectancy: Past and present. Perspective on Mortality Forecasting. III. The Linear Rise in Life Expectancy: History and Present 3: 83–99. [Google Scholar]
- Bongaarts, John. 2005. Long-range trends in adult mortality: Models and projection methods. Demography 42: 23–49. [Google Scholar] [CrossRef]
- Brass, William. 1971. On the scale of mortality. Biological Aspects of Demography 10: 69–110. [Google Scholar]
- Brass, William, Ansley J. Coale, Paul Demeny, Don F. Heisel, Frank Lorimer, Anatole Romaniuk, and Etienne Van De Walle. 1968. The Demography of Tropical Africa. Princeton: Princeton University Press. [Google Scholar]
- Brillinger, David R. 1986. A biometrics invited paper with discussion: The natural variability of vital rates and associated statistics. Biometrics 42: 693–734. [Google Scholar] [CrossRef]
- Brouhns, Natacha, Michel Denuit, and Jeroen K. Vermunt. 2002. A poisson log-bilinear regression approach to the construction of projected lifetables. Insurance: Mathematics and Economics 31: 373–93. [Google Scholar] [CrossRef] [Green Version]
- Cairns, Andrew J.G., David Blake, and Kevin Dowd. 2006. A two factor model for stochastic mortality with parameter uncertainty: Theory and calibration. Journal of Risk and Insurance 73: 687–718. [Google Scholar] [CrossRef]
- Christensen, Kaare, Gabriele Doblhammer, Roland Rau, and James W. Vaupel. 2009. Ageing populations: The challenges ahead. The lancet 374: 1196–208. [Google Scholar] [CrossRef] [Green Version]
- Coale, Ansley J., and Paul George Demeny. 1966. Regional Model Life Tables and Stable Populations. Princeton: Princeton University Press. [Google Scholar]
- Coale, Ansley J., Paul George Demeny, and Barbara Vaughan. 1983. Models of mortality and age composition. In Regional Model Life Tables and Stable Population, 2nd ed. New York: Academic Press, vol.193, pp. 3–7. [Google Scholar]
- Dan Pascariu, Marius, Valdimir Canudas-Romo, and W. James Vaupel. 2018. The double-gap life expectancy forecasting model. Insurance: Mathematics and Economics 78: 339–350. [Google Scholar] [CrossRef]
- Dickson, David C. M., Mary R. Hardy, and Howard R. Waters. 2013. Actuarial Mathematics for Life Contingent Risks. Cambridge: Cambridge University Press. [Google Scholar]
- Ediev, Dalkhat M. 2011. Robust backward population projections made possible. International Journal of Forecasting 27: 1241–47. [Google Scholar] [CrossRef]
- Gabriel, K. R., and Ilana Ronen. 1958. Estimates of mortality from infant mortality rates. Population Studies 12: 164–69. [Google Scholar] [CrossRef]
- Kannisto, Vaino, Jens Lauritsen, A. Roger Thatcher, and James W. Vaupel. 1994. Reductions in mortality at advanced ages: Several decades of evidence from 27 countries. Population and Development Review 20: 793–810. [Google Scholar] [CrossRef]
- Ledermann, S. 1969. Nouvelles Tables-Types de Mortalité. Travaux et documents—Institut national d’études démographiques. Paris: Presses Universitaires de France. [Google Scholar]
- Lee, Ronald D., and Lawrence R. Carter. 1992. Modeling and forecasting U.S. mortality. Journal of the American Statistical Association 87: 659–71. [Google Scholar] [CrossRef]
- Li, Nan, Ronald Lee, and Patrick Gerland. 2013. Extending the Lee-Carter method to model the rotation of age patterns of mortality decline for long-term projections. Demography 50: 2037–51. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Mayhew, Les, and David Smith. 2013. A new method of projecting populations based on trends in life expectancy and survival. Population Studies 67: 157–70. [Google Scholar] [CrossRef] [Green Version]
- Møller, Thomas, and Mogens Steffensen. 2007. Market-Valuation Methods in Life and Pension Insurance. Cambridge: Cambridge University Press. [Google Scholar]
- Murray, Christopher J. L., Brodie D. Ferguson, Alan D. Lopez, Michel Guillot, Joshua A. Salomon, and Omar Ahmad. 2003. Modified logit life table system: Principles, empirical validation, and application. Population Studies 57: 165–82. [Google Scholar] [CrossRef]
- Oeppen, Jim, and James W. Vaupel. 2002. Broken limits to life expectancy. Science 296: 1029–31. [Google Scholar] [CrossRef] [Green Version]
- R Core Team. 2019. R: A Language and Environment for Statistical Computing. Vienna: R Foundation for Statistical Computing. [Google Scholar]
- Raftery, Adrian E., Nevena Lalic, and Patrick Gerland. 2014. Joint probabilistic projection of female and male life expectancy. Demographic Research 30: 795. [Google Scholar] [CrossRef] [Green Version]
- Rau, Roland, Eugeny Soroko, Domantas Jasilionis, and James W. Vaupel. 2008. Continued reductions in mortality at advanced ages. Population and Development Review 34: 747–68. [Google Scholar] [CrossRef]
- Ševčíková, Hana, Nan Li, Vladimíra Kantorová, Patrick Gerland, and Adrian E. Raftery. 2016. Age-specific mortality and fertility rates for probabilistic population projections. In Dynamic Demographic Analysis. Berlin and Heidelberg: Springer, pp. 285–310. [Google Scholar]
- Shkolnikov, Vladimir M., Dmitri A. Jdanov, Evgeny M. Andreev, and James W. Vaupel. 2011. Steep increase in best-practice cohort life expectancy. Population and Development Review 37: 419–34. [Google Scholar] [CrossRef]
- Stoeldraijer, Lenny, Coen van Duin, Leo van Wissen, and Fanny Janssen. 2013. Impact of different mortality forecasting methods and explicit assumptions on projected future life expectancy: The case of the netherlands. Demographic Research 29: 323–53. [Google Scholar] [CrossRef] [Green Version]
- Sullivan, Jeremiah M. 1972. Models for the estimation of the probability of dying between birth and exact ages of early childhood. Population Studies 26: 79–97. [Google Scholar] [CrossRef]
- Thatcher, A. Roger, Väinö Kannisto, and James W. Vaupel. 1998. The Force of Mortality at Ages 80 to 120. Odense: Odense University Press. [Google Scholar]
- Torri, Tiziana, and James W. Vaupel. 2012. Forecasting life expectancy in an international context. International Journal of Forecasting 28: 519–31. [Google Scholar] [CrossRef]
- United Nations. 1955. Age and Sex Patterns of Mortality: Model Life Tables for Under-Developed Countries; Population Studies, No. 22. New York: Department of Social Affairs.
- United Nations. 1967. Methods for Estimating Basic Demographic Measures from Incomplete Data: Manuals and Methods of Estimating Populations; Manual IV. Population Studies, No. 42. New York: Department of Social Affairs.
- United States Census Bureau. 2014. Methodology, Assumptions, and Inputs for the 2014 National Projections; Washington: Census Bureau.
- University of California Berkeley, USA and Max Planck Institute for Demographic Research, Germany. 2020. Human Mortality Database. 2020. Available online: https://www.mortality.org/ (accessed on 30 September 2020).
- Vaupel, James W. 1997. The remarkable improvements in survival at older ages. Philosophical Transactions of the Royal Society of London B: Biological Sciences 352: 1799–804. [Google Scholar] [CrossRef]
- Vaupel, James W., James R. Carey, Kaare Christensen, Thomas E. Johnson, Anatoli I. Yashin, Niels V. Holm, Ivan A. Iachine, Väinö Kannisto, Aziz A. Khazaeli, Pablo Liedo, and et al. 1998. Biodemographic trajectories of longevity. Science 280: 855–60. [Google Scholar] [CrossRef] [PubMed]
- White, Kevin M. 2002. Longevity advances in high-income countries, 1955–1996. Population and Development Review 28: 59–76. [Google Scholar] [CrossRef]
- Wilmoth, John, Sarah Zureick, Vladimir Canudas-Romo, Mie Inoue, and Cheryl Sawyer. 2012. A flexible two-dimensional mortality model for use in indirect estimation. Population Studies 66: 1–28. [Google Scholar] [CrossRef]
- Wilmoth, John R., K. Andreev, D. Jdanov, Dana A. Glei, C. Boe, M. Bubenheim, D. Philipov, V. Shkolnikov, and P. Vachon. 2007. Methods protocol for the human mortality database. University of California, Berkeley, and Max Planck Institute for Demographic Research, Rostock 9: 10–11. [Google Scholar]
- Wilmoth, John R., and Shiro Horiuchi. 1999. Rectangularization revisited: Variability of age at death within human populations. Demography 36: 475–95. [Google Scholar] [CrossRef]







| 1 | The change in age-specific death rates can be assumed to be constant over time, in which case the fitted is used in computing . Or, a shift in the speed of improvement can be imposed by “rotating” the coefficients. For more details see Section in the Appendix C. |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Pascariu, M.D.; Basellini, U.; Aburto, J.M.; Canudas-Romo, V. The Linear Link: Deriving Age-Specific Death Rates from Life Expectancy. Risks 2020, 8, 109. https://doi.org/10.3390/risks8040109
Pascariu MD, Basellini U, Aburto JM, Canudas-Romo V. The Linear Link: Deriving Age-Specific Death Rates from Life Expectancy. Risks. 2020; 8(4):109. https://doi.org/10.3390/risks8040109
Chicago/Turabian StylePascariu, Marius D., Ugofilippo Basellini, José Manuel Aburto, and Vladimir Canudas-Romo. 2020. "The Linear Link: Deriving Age-Specific Death Rates from Life Expectancy" Risks 8, no. 4: 109. https://doi.org/10.3390/risks8040109
APA StylePascariu, M. D., Basellini, U., Aburto, J. M., & Canudas-Romo, V. (2020). The Linear Link: Deriving Age-Specific Death Rates from Life Expectancy. Risks, 8(4), 109. https://doi.org/10.3390/risks8040109