The Importance of Economic Variables on London Real Estate Market: A Random Forest Approach



Abstract
:1. Introduction
2. The Model
2.1. Regression Tree Architecture
- The predictor space (i.e., the set of possible values for ) is divided into J distinct and non-overlapping regions, .
- For each observation that falls into the region , the algorithm provides the same prediction, which is the mean of the response values for the training observations in .
2.2. Random Forest
2.3. Variable Importance
3. Case Study
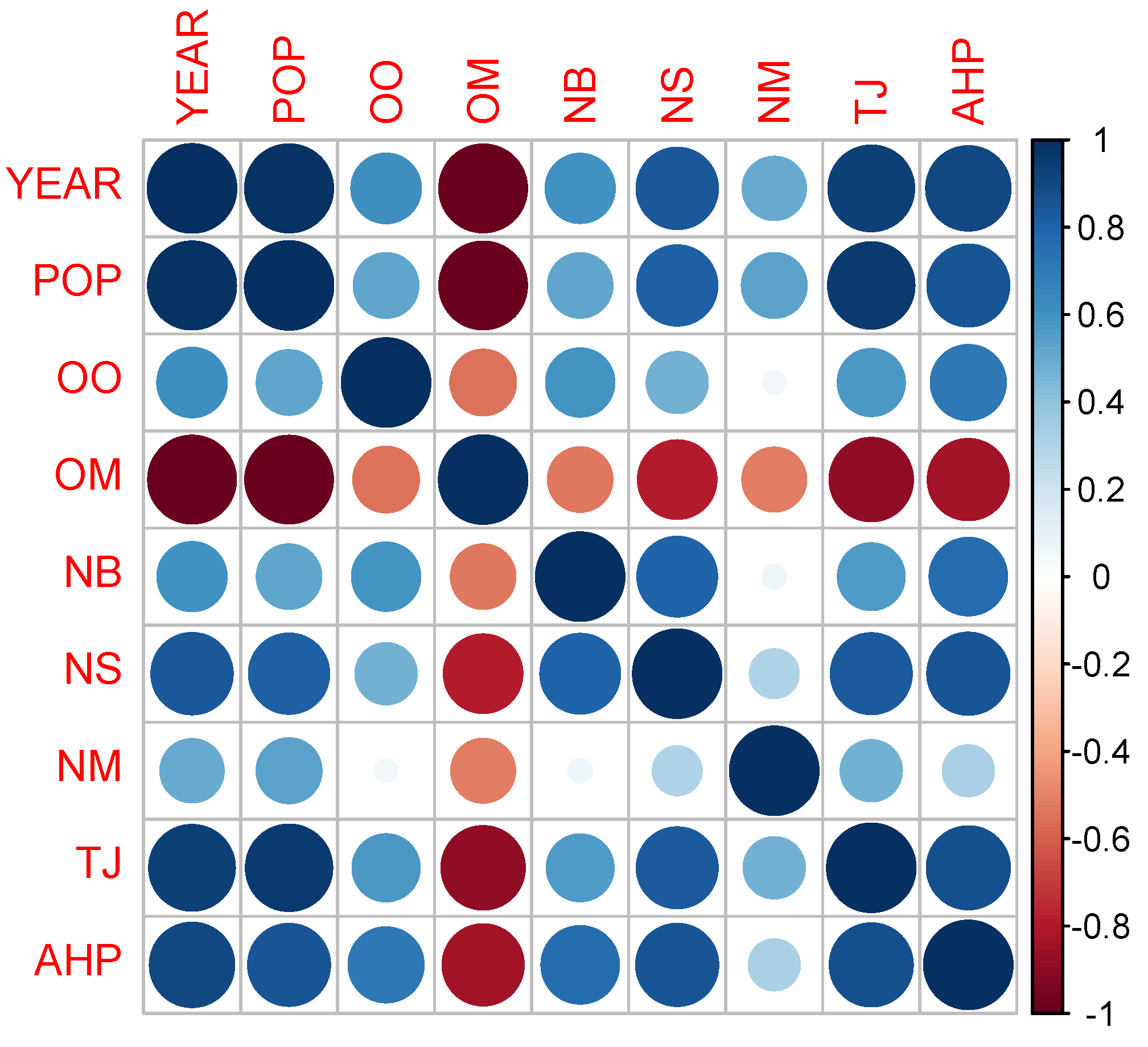
3.1. Data Description
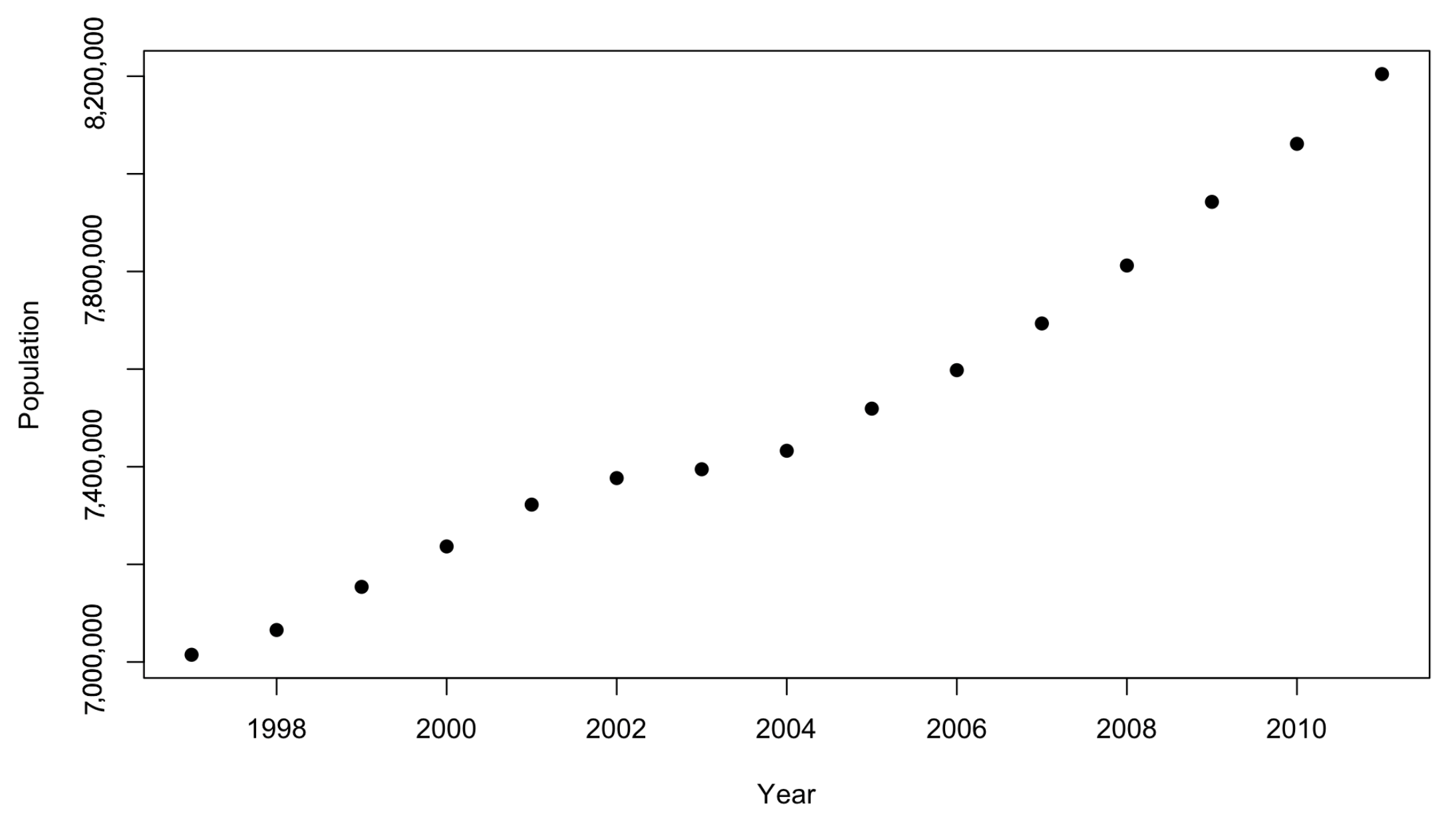
- POP: historic London population
- OO: annual trend in household tenure owned outright
- OM: annual trend in household tenure owned with mortgage
- NB: new build homes
- NS: net housing supply
- NM: net migration (domestic and international)
- TJ: trend of jobs in London
3.2. Regression Model and Main Statistics
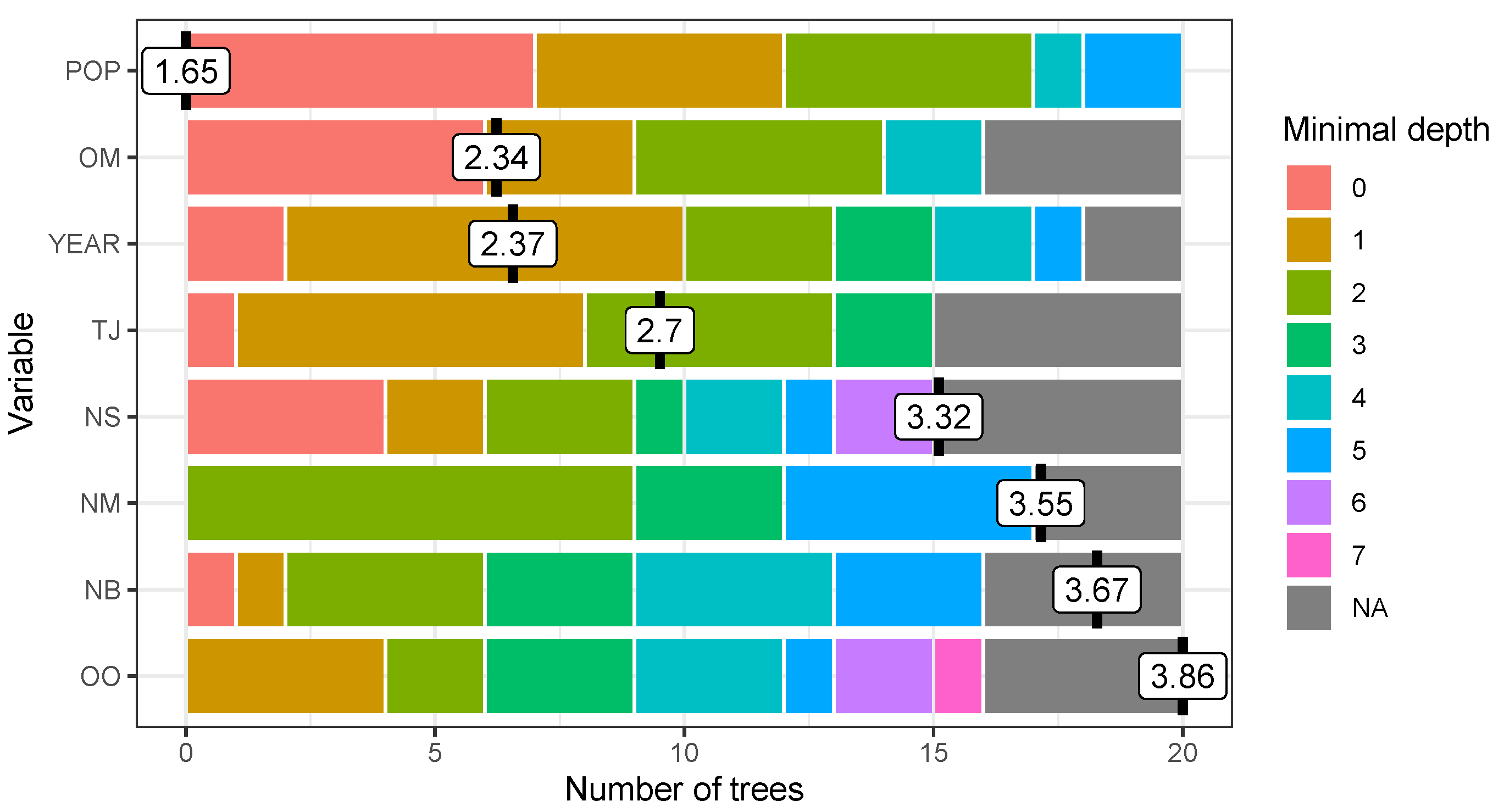
3.3. RF Estimation of
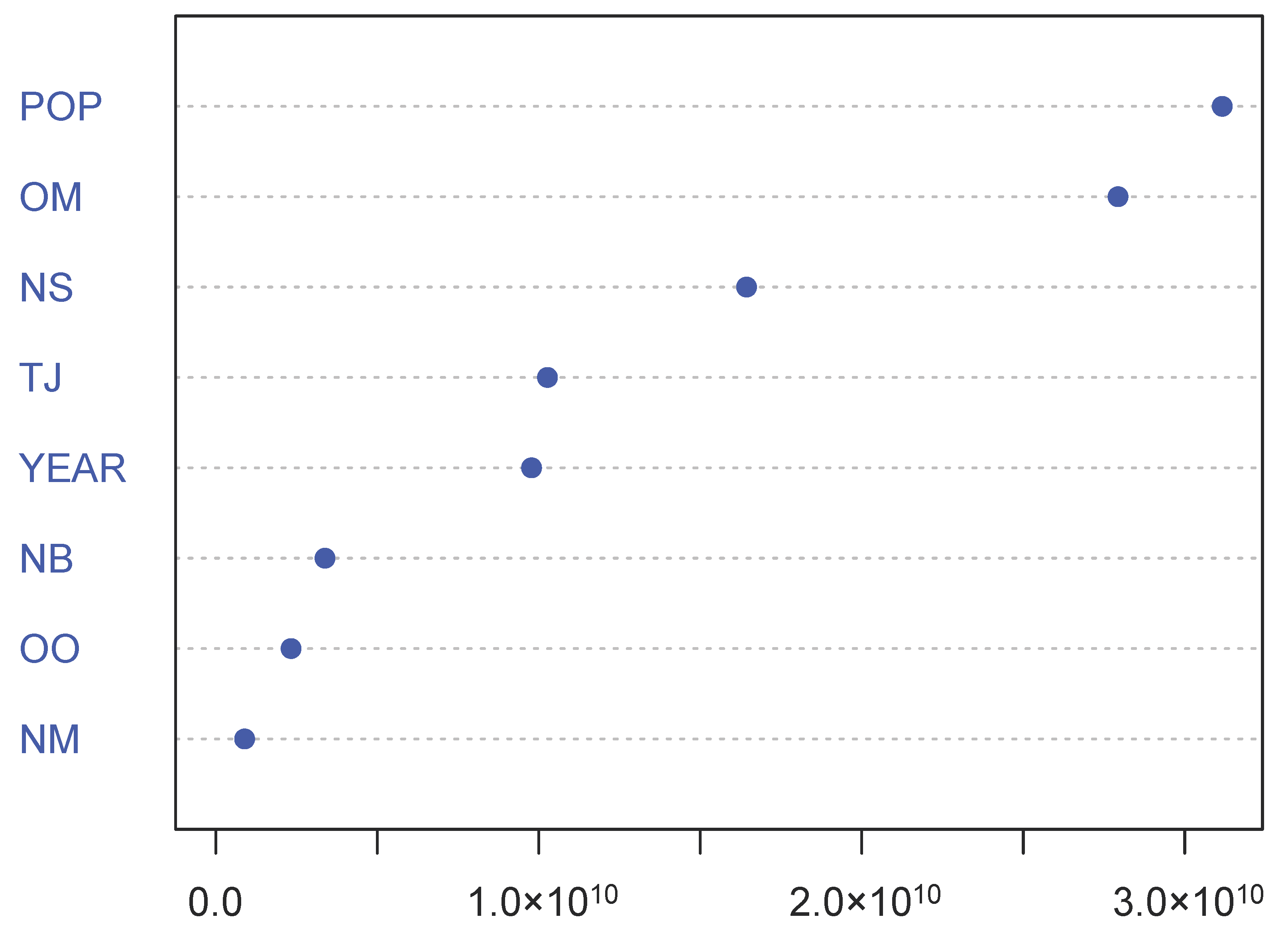
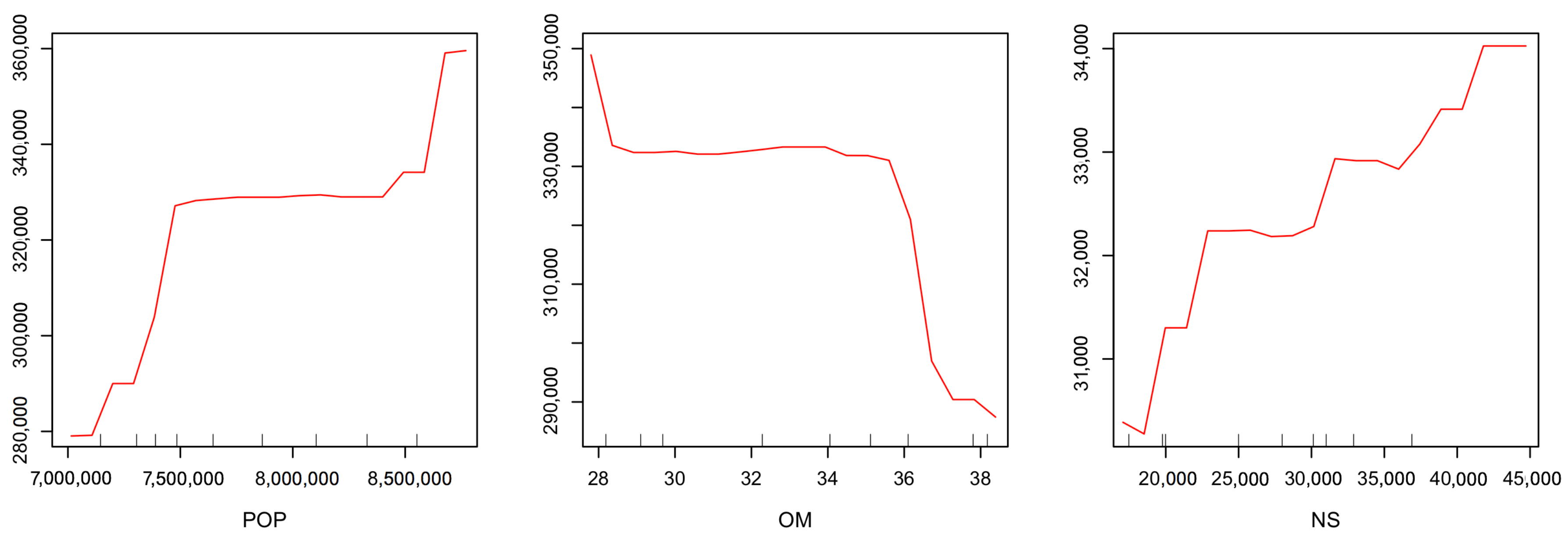
3.4. Sensitivity to Predictor
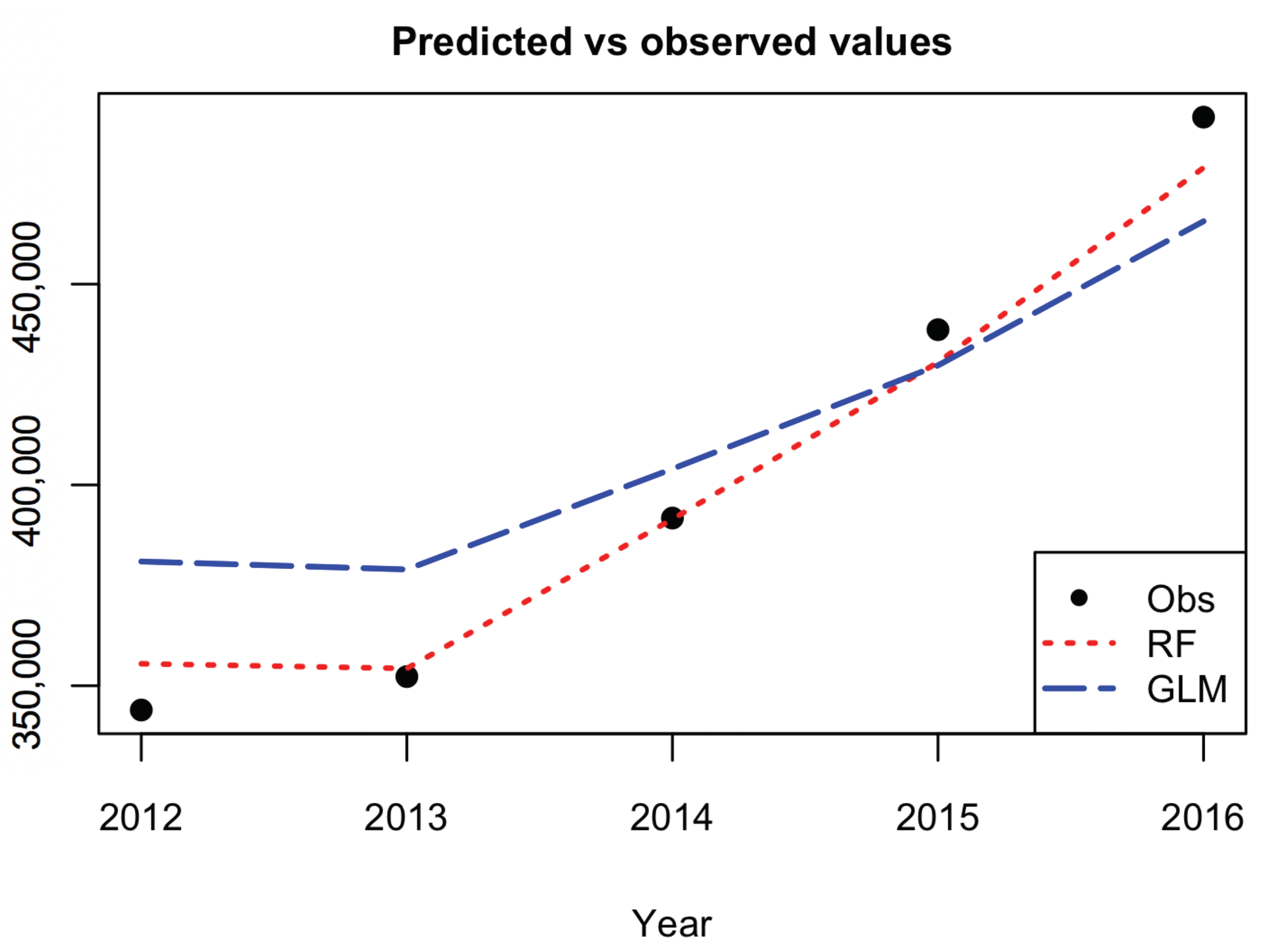
3.5. RF Predictive Performance and Comparison with GLM
4. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Alfiyatin, Adyan Nur, Ruth Ema Febrita, Hilman Taufiq, and Wayan Firdaus Mahmudy. 2017. Modeling House Price Prediction using Regression Analysis and Particle Swarm Optimization Case Study: Malang, East Java, Indonesia. International Journal of Advanced Computer Science and Applications 8. [Google Scholar] [CrossRef] [Green Version]
- Antipov, Evgeny A., and Elena B. Pokryshevskaya. 2012. Mass appraisal of residential apartments: An application of Random forest for valuation and a CART-based approach for model diagnostics. Expert Systems with Applications 39: 1772–78. [Google Scholar] [CrossRef] [Green Version]
- Arvanitidis, Pachalis A. 2014. The Economics of Urban Property Markets: An Institutional Economics Analysis. Series: Routledge Studies in the European Economy; London and New York: Routledge, Taylor & Francis Group, ISBN 9780415426824. [Google Scholar]
- Baldominos, Alejandro, Ivan Blanco, Antonio José Moreno, Rubén Iturrarte, Oscar Bernardez, and Carlos Alfonso. 2018. Identifying Real Estate Opportunities Using Machine Learning. Applied Science 8: 2321. [Google Scholar] [CrossRef] [Green Version]
- Beutel, Johannes, Sophia List, and Gregor von Schweinitz. 2019. Does machine learning help us predict banking crises? Journal of Financial Stability 45. [Google Scholar] [CrossRef]
- Bourassa, Steven C., Eva Cantoni, and Martin Hoesli. 2010. Predicting house prices with spatial dependence: A comparison of alternative methods. Journal of Real Estate Research 32: 139–59. [Google Scholar]
- Breiman, Leo. 1996. Bagging predictors. Machine Learning 24: 123–40. [Google Scholar] [CrossRef] [Green Version]
- Breiman, Leo. 2001. Random forests. Machine Learning 45: 5–32. [Google Scholar] [CrossRef] [Green Version]
- Case, Bradford, John Clapp, Robin Dubin, and Mauricio Rodriguez. 2004. Modeling spatial and temporal house price patterns: A comparison of four models. The Journal of Real Estate Finance and Economics 29: 167–91. [Google Scholar] [CrossRef]
- Čeh, Marian, Milan Kilibarda, Anka Lisec, and Branislav Bajat. 2018. Estimating the Performance of Random Forest versus Multiple Regression for Predicting Prices of the Apartments. ISPRS International Journal of Geo-Information 7: 168. [Google Scholar] [CrossRef] [Green Version]
- Chica-Olmo, Jorge. 2007. Prediction of Housing Location Price by a Multivariate Spatial Method. Cokriging, Journal of Real Estate Research 29: 91–114. [Google Scholar]
- Coen, Alan, Patrick Lecomte, and Dorra Abdelmoula. 2018. The Financial Performance of Green Reits Revisited. Journal of Real Estate Portfolio Management 24: 95–105. [Google Scholar] [CrossRef]
- Crampton, Graham, and Alan Evans. 1992. The economy of an agglomeration: The case of London. Urban Studies 29: 259–71. [Google Scholar] [CrossRef]
- Del Giudice, Vincenzo, Pierfrancesco de Paola, and Giovanni Battista Cantisani. 2017a. Valuation of Real Estate Investments through Fuzzy Logic. Buildings 7: 26. [Google Scholar] [CrossRef]
- Del Giudice, Vincenzo, Benedetto Manganelli, and Pierfrancesco de Paola. 2017b. Hedonic analysis of housing sales prices with semiparametric methods. International Journal of Agricoltural and Environmental Information System 8: 65–77. [Google Scholar] [CrossRef] [Green Version]
- Diebold, Francis X., and Roberto S. Mariano. 1995. Comparing Predictive Accuracy. Journal of Business and Economic Statistics 13: 253–63. [Google Scholar]
- Di Lorenzo, Emilia, Gabriella Piscopo, Marilena Sibillo, and Roberto Tizzano. 2020a. Reverse Mortgages: Risks and Opportunities. In Demography of Population Health, Aging and Health Expenditures. Edited by Christos Skiadas and Charilaos Skiadas. Springer Series on Demographic Methods and Population Analysis; Cham: Springer, pp. 435–42. ISBN 978-3-030-44695-6. [Google Scholar]
- Di Lorenzo, Emilia, Gabriella Piscopo, Marilena Sibillo, and Roberto Tizzano. 2020b. Reverse mortgages through artificial intelligence: New opportunities for the actuaries. Decision in Economics and Finance. [Google Scholar] [CrossRef]
- Gao, Guangliang, Zhifeng Bao, Jie Cao, A. K. Quin, and Timos Sellis. 2019. Location Centered House Price Prediction: A Multi-Task Learning Approach. arXiv arXiv:1901.01774. [Google Scholar]
- Gerek, Ibrahim Halil. 2014. House selling price assessment using two different adaptive neuro fuzzy techniques. Automation in Construction 41: 33–39. [Google Scholar] [CrossRef]
- Ghosal, Indrayudh, and Giles Hooker. 2018. Boosting random forests to reduce bias; One step boosted forest and its variance estimate. arXiv arXiv:1803.08000. [Google Scholar] [CrossRef]
- Glaeser, Edward L., Joseph Gyourko, Eduardo Morales, and Charles G. Nathanson. 2014. Housing dynamics: An urban approach. Journal of Urban Economics 81: 45–56. [Google Scholar] [CrossRef]
- Greater London Authority, Housing in London. 2018. The Evidence Base for the Mayor’s Housing Strategy. London: Greater London Authority, City Hall. [Google Scholar]
- Greenstein, Shane M., Catherine E. Tucker, Lynn Wu, and Erik Brynjolfsson. 2015. The Future of Prediction: How Google Searches Foreshadow Housing Prices and Sales. In Economic Analysis of the Digital Economy. Chicago: The University of Chicago Press, pp. 89–118. [Google Scholar]
- Grum, Bojan, and Darja Kobe Govekar. 2016. Influence of Macroeconomic Factors on Prices of Real Estate in Various Cultural Environments: Case of Slovenia, Greece, France, Poland and Norway. Procedia Economics and Finance 39: 597–604. [Google Scholar] [CrossRef] [Green Version]
- Gu, Jirong, Mingcang Zhu, and Jiang Liuguangyan. 2011. Housing price forecasting based on genetic algorithm and support vector machine. Expert Systems with Applications 38: 3383–86. [Google Scholar] [CrossRef]
- Guan, Jian, Jozef M. Zurada, and Alan S. Levitan. 2008. An Adaptive Neuro-Fuzzy Inference System Based Approach to Real Estate Property Assessment. Journal of Real Estate Research 30: 395–422. [Google Scholar]
- Guan, Jian, Donghui Shi, Jozef M. Zurada, and Alan S. Levitan. 2014. Analyzing Massive Data Sets: An Adaptive Fuzzy Neural Approach for Prediction, with a Real Estate Illustration. Journal of Organizational Computing and Electronic Commerce 24: 94–112. [Google Scholar] [CrossRef]
- Hong, Jengei, Heeyoul Choi, and Woo-sung Kim. 2020. A house price valuation based on the random forest approach: The mass appraisal of residential property in South Korea. International Journal of Strategic Property Management 24: 140–52. [Google Scholar] [CrossRef]
- James, Gareth, Daniela Witten, Trevor Hastie, and Robert Tibshirani. 2017. An Introduction to Statistical Learning: With Applications in R. Springer Texts in Statistics. Cham: Springer Publishing Company, Incorporated, ISBN 10: 1461471370. [Google Scholar]
- Krol, Anna. 2013. Application of hedonic methods in modelling real estate prices in Poland. In Data Science, Learning by Latent Structures and Knowledge Discovery. Berlin: Springer, pp. 501–11. [Google Scholar]
- Liang, Jiang, Peter C. B. Phillips, and Jun Yu. 2015. A New Hedonic Regression for Real Estate Prices Applied to the Singapore Residential Market. Journal of Banking and Finance 61: 121–31. [Google Scholar]
- Liaw, Andy. 2018. Package. Randomforest. Available online:https://cran.r-project.org/web/packages/randomForest/randomForest.pdf (accessed on 20 April 2020).
- Loh, Wei-Yin. 2011. Classification and regression trees. Wiley Interdisciplinary Reviews: Data Mining and Knowledge Discovery 1. [Google Scholar] [CrossRef]
- Lopez-Alcala, Mario. 2016. The Crisis of Affordability in Real Estate. London: MSCI. McKinsey Global Institute. [Google Scholar]
- Manganelli, Benedetto, Pierfrancesco de Paola, and Vincenzo Del Giudice. 2016. Linear Programming in a Multi-Criteria Model for Real Estate Appraisal. Paper presented at the International Conference on Computational Science and Its Applications, Part I, Beijing, China, July 4–7. [Google Scholar]
- Manjula, Raja, Shubham Jain, Sharad Srivastava, and Pranav Rajiv Kher. 2017. Real estate value prediction using multivariate regression models. In IOP Conf. Ser.: Materials Science and Engineering. Bristol: IOP Publishing. [Google Scholar]
- McKinsey Global Institute. 2016. People on the Move: Global Migration’s Impact and Opportunity. London: McKinsey Global Institute. [Google Scholar]
- Miller, Norm G., Dave Pogue, Quiana D. Gough, and Susan M. Davis. 2009. Green Buildings and Productivity. Journal of Sustainable Real Estate 1: 65–89. [Google Scholar]
- Montero, José Maria, Roman Minguez, and Gema Fernandez Avilés. 2018. Housing price prediction: Parametric versus semiparametric spatial hedonic models. Journal of Geographical Systems 20: 27–55. [Google Scholar] [CrossRef]
- Morrison, Doug, Adam Branson, Mike Phillips, Jane Roberts, and Stuart Watson. 2019. Emerging Trend in Real Estate. Creating an Impact. Washington: PwC and Urban Land Institute. [Google Scholar]
- National Geographic. 2018. How London became the centre of the world. National Geographic, October 27. [Google Scholar]
- Nghiep, Nguyen, and Al Cripps. 2001. Predicting Housing Value: A Comparison of Multiple Regression Analysis and Artificial Neural Networks. Journal of Real Estate Research 22: 313–36. [Google Scholar]
- Ozdenerol, Esra, Ying Huang, Farid Javadnejad, and Anzhelika Antipova. 2015. The Impact of Traffic Noise on Housing Values. Journal of Real Estate Practice and Education 18: 35–54. [Google Scholar] [CrossRef]
- Pai, Ping-Feng, and Wen-Chang Wang. 2020. Using Machine Learning Models and Actual Transaction Data for Predicting Real Estate Prices. Applied Sciences 10: 5832. [Google Scholar] [CrossRef]
- Park, Byeonghwa, and Jae Kwon Bae. 2015. Using machine learning algorithms for housing price prediction: The case of fairfax county, virginia housing data. Expert Systems with Applications 42: 2928–34. [Google Scholar] [CrossRef]
- Quinlan, John Ross. 1986. Induction of decision trees. Machine Learning 1: 81–106. [Google Scholar] [CrossRef] [Green Version]
- Rahadi, Raden Aswin, Sudarso Wiryono, Deddy Koesrindartotoor, and Indra Budiman Syamwil. 2015. Factors influencing the price of housing in Indonesia. International Journal of House Market Analysis 8: 169–88. [Google Scholar] [CrossRef]
- Sarip, Abdul Ghani, Muhammad Burhan Hafez, and Md Nasir Daud. 2016. Application of Fuzzy Regression Model for Real Estate Price Prediction. The Malaysian Journal of Computer Science 29: 15–27. [Google Scholar] [CrossRef] [Green Version]
- Selim, Hasan. 2009. Determinants of house prices in turkey: Hedonic regression versus artificial neural network. Expert Systems with Applications 36: 2843–52. [Google Scholar] [CrossRef]
- Tanaka, Katsuyuki, Takuo Higashide, Takuji Kinkyo, and Shigeyuki Hamori. 2019. Analyzing industry-level vulnerability by predicting financial bankruptcy. Economic Inquiry 57: 2017–34. [Google Scholar] [CrossRef]
- Tanaka, Katsuyuki, Takuo Kinkyo, and Shigeyuki Hamori. 2016. Random Forests-based Early Warning System for Bank Failures. Economics Letters 148: 118–21. [Google Scholar] [CrossRef]
- United Nations. 2019. World Population Prospects: The 2017 Revision, Key Findings & Advance Tables. Working Paper No. ESA/P/WP/248. New York: United Nations. [Google Scholar]
- Van Doorn, Lisette, Amanprit Arnold, and Elizabeth Rapoport. 2019. In the Age of Cities: The Impact of Urbanisation on House Prices and Affordability. In Hot Property. Edited by Rob Nijskens, Melanie Lohuis, Paul Hilbers and Willem Heeringa. Cham: Springer. [Google Scholar]
- Wang, Xibin, Junhao Wen, Yihao Zhang, and Yubiao Wang. 2014. Real estate price forecasting based on svm optimized by pso. Optik-International Journal for Light and Electron Optics 125: 1439–43. [Google Scholar] [CrossRef]
- Winson Geideman, Kimberly. 2018. Sentiments and Semantics: A Review of the Content Analysis Literature in the Era of Big Data. Journal of Real Estate Literature 26: 1–12. [Google Scholar]
- Wright, Marvin, Andreas Ziegler, and Inke König. 2016. Do little interactions get lost in dark random forests? BMC Bioinformatics 17: 145. [Google Scholar] [CrossRef] [Green Version]
- Xu, Yun, and Roystone Goodacre. 2018. On Splitting Training and Validation Set: A Comparative Study of Cross-Validation, Bootstrap and Systematic Sampling for Estimating the Generalization Performance of Supervised Learning. Journal of Analysis and Testing 2: 249–62. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Yacim, Joseph Awoamim, and Douw Boshoff. 2018. Impact of Artificial Neural Networks Training Algorithms on Accurate Prediction of Property Values. Journal of Real Estate Research 40: 375–418. [Google Scholar]
- Yacim, Joseph Awoamim, Douw Boshoff, and Abdullah Khan. 2016. Hybridizing Cuckoo Search with Levenberg Marquardt Algorithms in Optimization and Training Of ANNs for Mass Appraisal of Properties. Journal of Real Estate Literature 24: 473–92. [Google Scholar]
- Zurada, Jozef, Alan Levitan, and Jian Guan. 2011. A Comparison of Regression and Artificial Intelligence Methods in a Mass Appraisal Context. Journal of Real Estate Research 33: 349–87. [Google Scholar]
| 1. | e.g., k-fold cross-validation where the original sample is randomly partitioned into k equal size subsamples, leave-p-out cross-validation (LpOCV) which considers p observations as the validation set and the remaining observations as the training set, or Leave-one-out cross-validation (LOOCV) that is a particular case of the previous method with p = 1). |








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Variable | Summary Statistics | ||
|---|---|---|---|
| POP | = 7,776,538.90 | = 554,808 | CV = 7.13% |
| OO | = 21.56 | = 1.00 | CV = 4.64% |
| OM | = 33.33 | = 3.96 | CV = 11.88% |
| NB | = 18,385.00 | = 3695.46 | CV = 20.10% |
| NS | = 27,314.00 | = 7929.26 | CV = 29.03% |
| NM | = 23,752.40 | = 24,129.15 | CV = 101.59% |
| TJ | = 4,857,200.00 | = 424,621.52 | CV = 8.74% |
| AHP | = 320,045.95 | = 89,380.52 | CV = 27.93% |
| Indicator | Value |
|---|---|
| RSS | 94.01% |
| MSR | 454,451,969 |
| YEAR | POP | OM | NS | POP + OM | POP + NS | OM + NS | Obs. |
|---|---|---|---|---|---|---|---|
| 1997 | 183,781 | 177,594 | 220,706 | 177,349 | 199,614 | 202,211 | 149,616 |
| 1998 | 193,924 | 173,391 | 225,909 | 157,184 | 214,491 | 198,730 | 170,720 |
| 1999 | 211,542 | 212,472 | 208,978 | 198,043 | 202,130 | 229,106 | 179,888 |
| 2000 | 217,570 | 178,742 | 201,503 | 203,084 | 195,192 | 187,088 | 217,691 |
| 2001 | 236,617 | 205,580 | 199,442 | 237,029 | 228,907 | 208,593 | 243,062 |
| 2002 | 264,721 | 317,158 | 190,907 | 328,907 | 254,313 | 273,101 | 272,549 |
| 2003 | 271,452 | 301,789 | 215,949 | 275,967 | 261,350 | 262,067 | 322,936 |
| 2004 | 331,517 | 342,420 | 354,699 | 339,730 | 352,269 | 342,233 | 332,406 |
| 2005 | 348,727 | 334,189 | 346,321 | 331,844 | 341,708 | 332,266 | 342,173 |
| 2006 | 346,830 | 347,434 | 349,716 | 353,006 | 352,616 | 339,709 | 344,887 |
| 2007 | 343,530 | 351,773 | 377,760 | 354,995 | 377,016 | 368,037 | 369,225 |
| 2008 | 361,114 | 363,370 | 373,558 | 359,544 | 357,437 | 354,736 | 395,803 |
| 2009 | 364,396 | 365,626 | 350,713 | 355,699 | 349,910 | 353,876 | 335,008 |
| 2010 | 352,958 | 345,881 | 344,328 | 343,831 | 341,911 | 340,788 | 357,004 |
| 2011 | 351,097 | 346,328 | 340,926 | 348,378 | 339,996 | 354,018 | 349,730 |
| Predictor | RSS |
|---|---|
| POP | 91.29% |
| OM | 86.74% |
| NS | 69.08% |
| POP + OM | 87.53% |
| POP + NS | 84.77% |
| OM + NS | 82.41% |
| Coefficient | z Value | |||
|---|---|---|---|---|
| (Intercept) | 0.00789 ** | |||
| YEAR | 3.302 | 0.00705 ** | ||
| POP | 0.15363 | |||
| OO | 0.39640 | |||
| OM | 0.862 | 0.40706 | ||
| NB | 1.606 | 3.738 | 0.430 | 0.67569 |
| NS | 2.453 | 0.74467 | ||
| NM | 0.24538 | |||
| TJ | 0.715 | 0.48958 |
| Measure | RF | GLM |
|---|---|---|
| RMSE | 8505 | 24,416 |
| MAPE | 1.68% | 5.75% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Levantesi, S.; Piscopo, G. The Importance of Economic Variables on London Real Estate Market: A Random Forest Approach. Risks 2020, 8, 112. https://doi.org/10.3390/risks8040112
Levantesi S, Piscopo G. The Importance of Economic Variables on London Real Estate Market: A Random Forest Approach. Risks. 2020; 8(4):112. https://doi.org/10.3390/risks8040112
Chicago/Turabian StyleLevantesi, Susanna, and Gabriella Piscopo. 2020. "The Importance of Economic Variables on London Real Estate Market: A Random Forest Approach" Risks 8, no. 4: 112. https://doi.org/10.3390/risks8040112
APA StyleLevantesi, S., & Piscopo, G. (2020). The Importance of Economic Variables on London Real Estate Market: A Random Forest Approach. Risks, 8(4), 112. https://doi.org/10.3390/risks8040112