Large Scale Advanced Data Analytics on Skin Conditions from Genotype to Phenotype

Abstract
:1. Introduction
2. Related Work
3. Material and Method
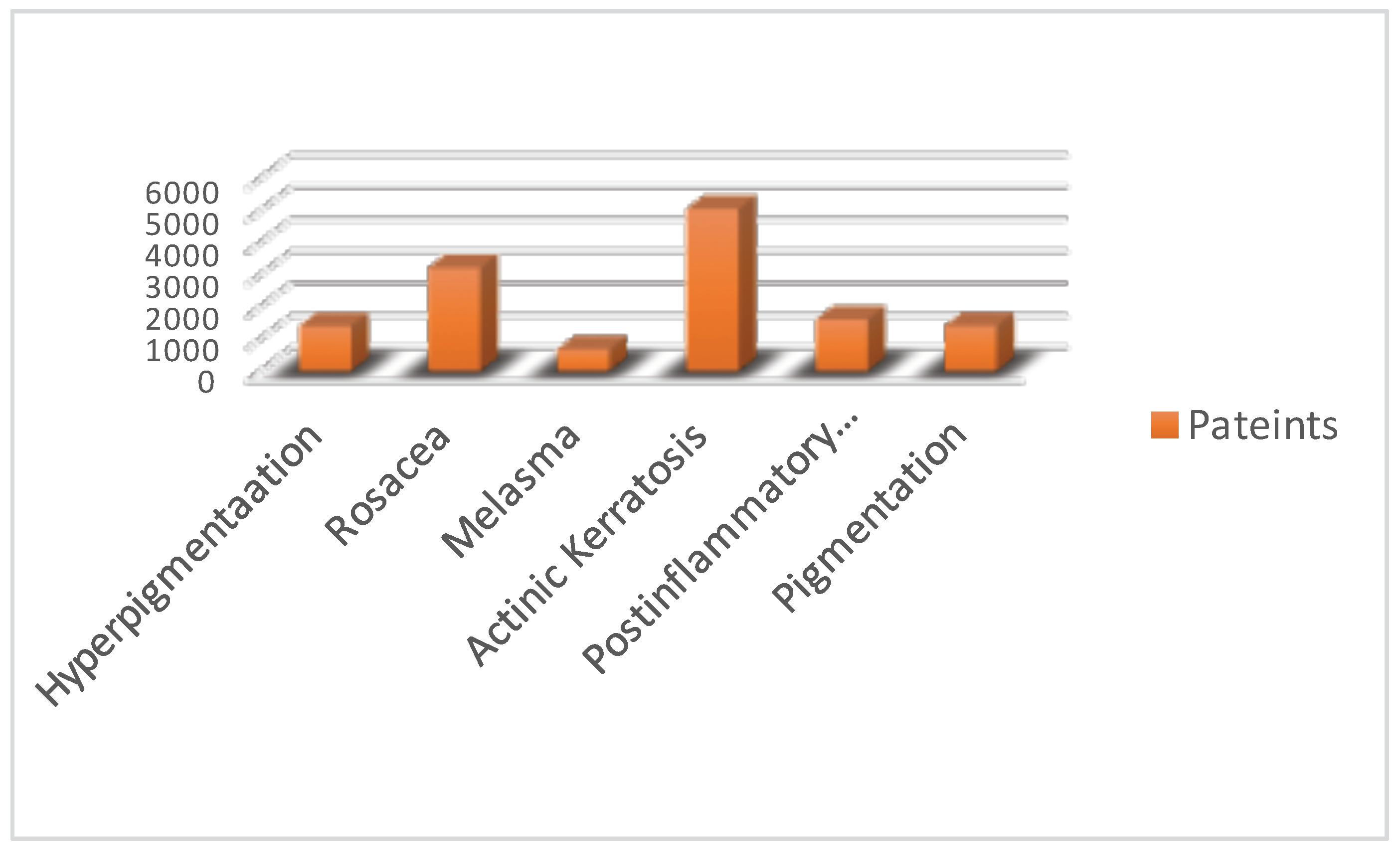
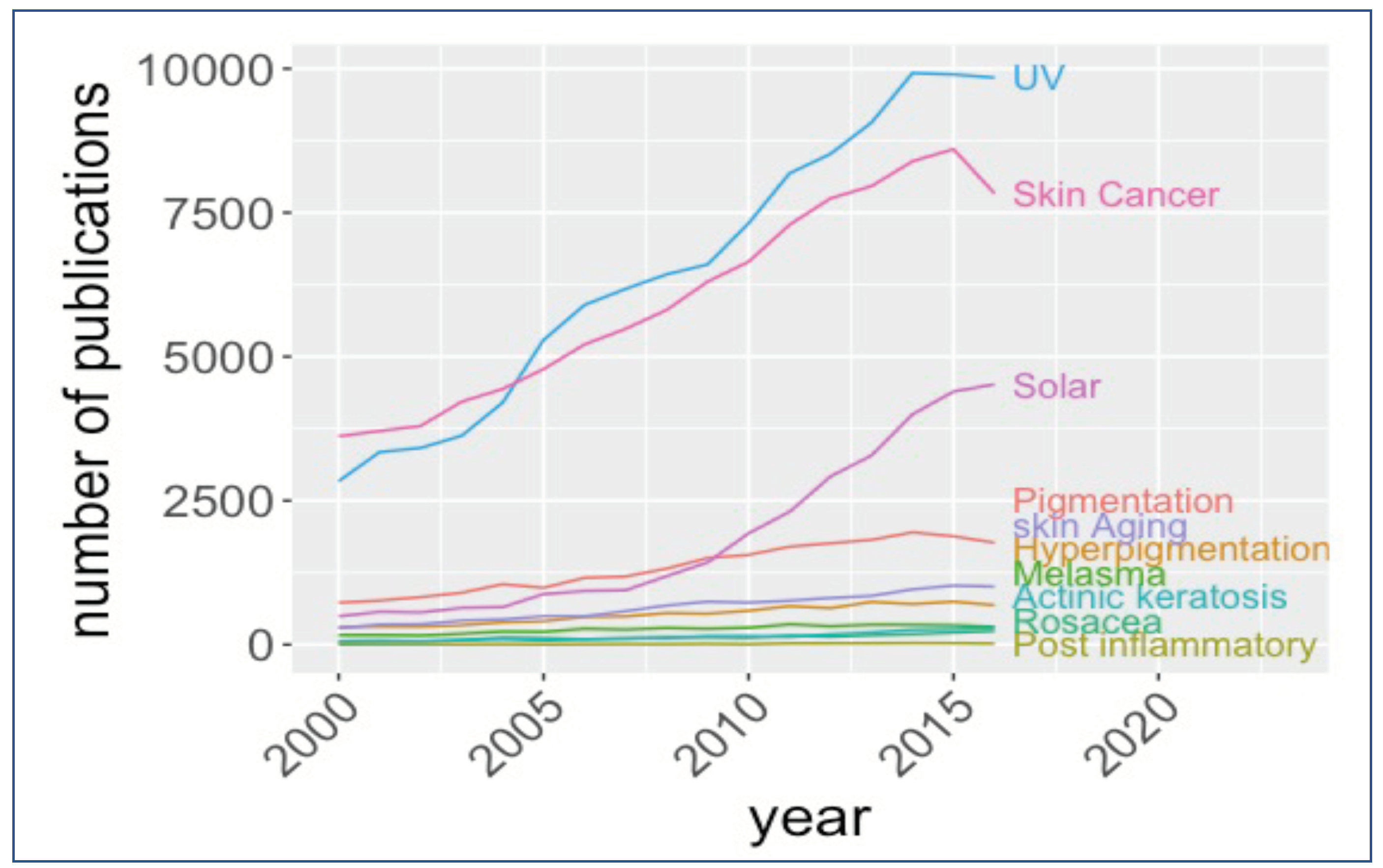
3.1. Data Collection
3.2. Feature Selection
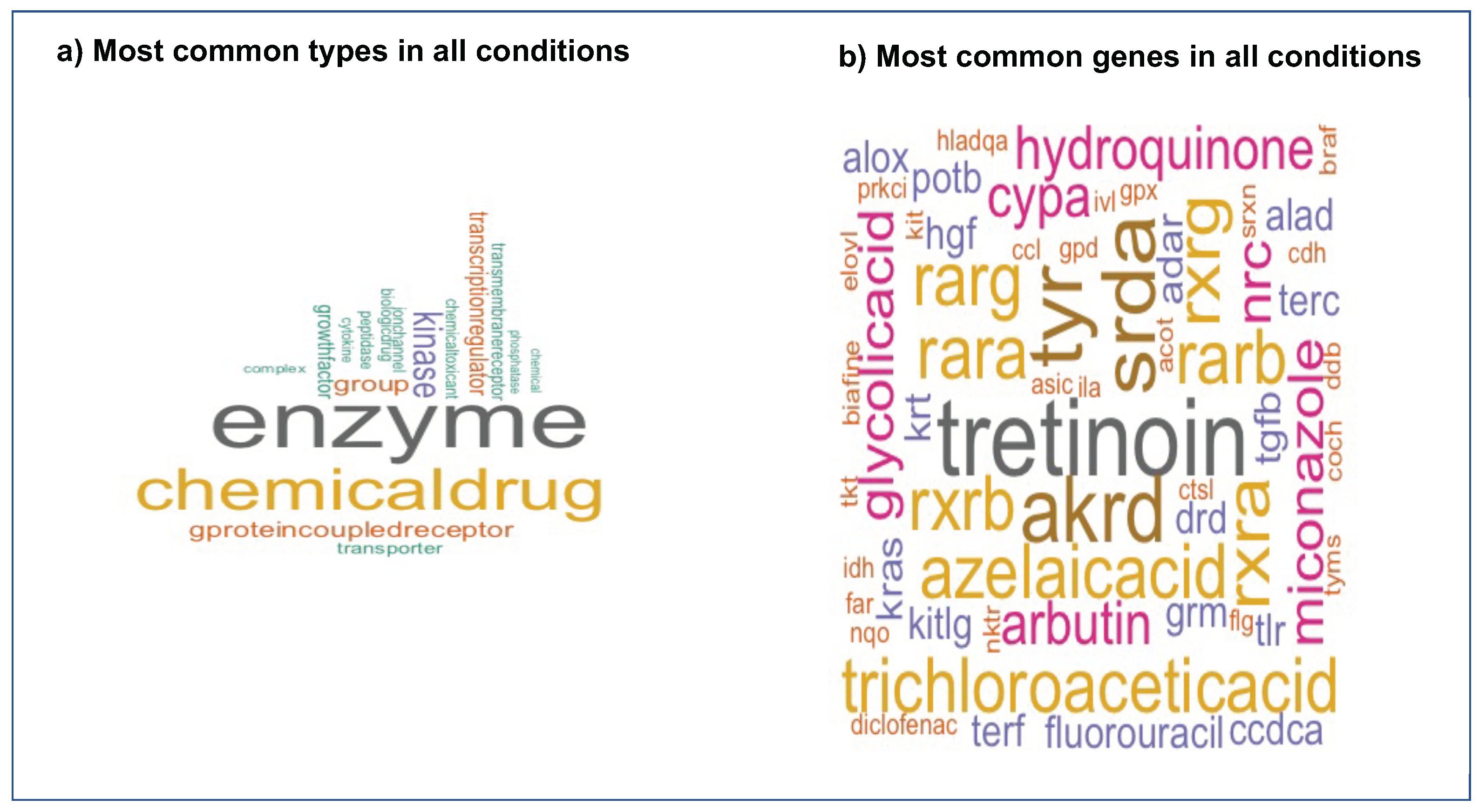
3.3. Ingenuity Pathway Analysis (IPA) and Advanced Data Analytics (ADA)
4. Results and Discussion
5. Conclusions and Future Work
Author Contributions
Funding
Conflicts of Interest
References
- van Zuuren, E.J. Rosacea. N. Engl. J. Med. 2017, 377, 1754–1764. [Google Scholar] [CrossRef] [PubMed]
- Gallo, R.; Granstein, R.; Kang, S.; Mannis, M.; Steinhoff, M.; Tan, J.; Thiboutot, D. Standard classification and pathophysiology of rosacea: The 2017 update by the National Rosacea Society Expert Committee. J. Am. Acad. Dermatol. 2018, 78, 148–155. [Google Scholar] [CrossRef] [PubMed]
- Wu, I.; Lambert, C.; Lotti, T.M.; Hercogová, J.; Sintim-Damoa, A.; Schwartz, A.R. Melasma. G. Ital. Dermatol. Venereol. 2012, 147, 413–418. [Google Scholar] [PubMed]
- Lee, B.W.; Schwart, R.A. Melasma. G. Ital. Dermatol. Venereol. 2017, 152, 36–45. [Google Scholar] [PubMed]
- Panahiazar, M.; Taslimitehrani, V.; Jadhav, A.; Pathak, J. Empowering personalized medicine with big data and semantic web technology: Promises, challenges, and use cases. In Proceedings of the 2014 IEEE International Conference on Big Data, Washington, DC, USA, 27–30 October 2014. [Google Scholar]
- Elston, D.M. Fitzpatrick’s color atlas & synopsis of clinical dermatology. J. Am. Acad. Dermatol. 2010, 62, 166. [Google Scholar]
- Ingenuity Pathway Analysis Webpage. Available online: https://www.qiagenbioinformatics.com/products/ingenuity-pathway-analysis/ (accessed on 17 October 2018).
- Ortonne, J.P.; Passeron, T. Melanin pigmentary disorders: Treatment update. Dermatol. Clin. 2005, 23, 209–226. [Google Scholar] [CrossRef] [PubMed]
- Choi, J.K.; Yu, U.; Kim, S.; Yoo, O.J. Combining multiple microarray studies and modeling interstudy variation. Bioinformatics 2003, 19, i80–i90. [Google Scholar] [CrossRef]
- Yin, L.; Coelho, S.G.; Valencia, J.C.; Ebsen, D.; Mahns, A.; Smuda, C.; Miller, S.A.; Beer, J.Z.; Kolbe, L.; Hearing, V.J. Identification of Genes Expressed in Hyperpigmented Skin Using Meta-Analysis of Microarray Data Sets. J. Investig. Dermatol. 2015, 135, 2455–2463. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Barrett, T.; Wilhite, S.E.; Ledoux, P.; Evangelista, C.; Kim, I.F.; Tomashevsky, M.; Marshall, K.A.; Phillippy, K.H.; Sherman, P.M.; Holko, M.; et al. NCBI GEO: Archive for functional genomics data sets—Update. Nucleic Acids Res. 2012, 41, D991–D995. [Google Scholar] [CrossRef] [PubMed]
- Inkeles, M.S.; Scumpia, P.O.; Swindell, W.R.; Lopez, D.; Teles, R.M.B.; Graeber, T.G.; Meller, S.; Homey, B.; Elder, J.T.; Gilliet, M.; et al. Comparison of molecular signatures from multiple skin diseases identifies mechanisms of immunopathogenesis. J. Investig. Dermatol. 2015, 135, 151–159. [Google Scholar] [CrossRef] [PubMed]
- National Human Genome Reserach Institute Webpage. Available online: https://www.genome.gov (accessed on 31 July 2018).
- Kramer, A.; Green, J.; Pollard, J.J.; Tugendreich, S. Causal analysis approaches in Ingenuity Pathway Analysis. Bioinformatics 2013, 30, 523–530. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- IPA. QIAGEN Inc. Available online: https://www.qiagenbioinformatics.com/products/ingenuity- pathway-analysis (accessed on 31 July 2018).
- Hadley, D.; Pan, J.; El-Sayed, O.; Aljabban, J.; Aljabban, I.; Azad, T.D.; Hadied, M.O.; Raza, S.; Rayikanti, B.A.; Chen, B.; et al. Precision annotation of digital samples in NCBI’s gene expression omnibus. Sci. Data 2017, 4, 170125. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Webmd Webpage. Available online: https://www.webmd.com (accessed on 31 July 2018).
- Panahiazar, M.; Dumontier, M.; Gevaert, O. Context Aware Recommendation Engine for Metadata Submission. In Proceedings of the First International Workshop on Capturing Scientific Knowledge, Palisades, NY, USA, 7 October 2015; pp. 3–7. [Google Scholar]
- Posch, L.; Panahiazar, M.; Dumontier, M.; Gevaert, O. Predicting structured metadata from unstructured metadata. Database 2016, baw080. [Google Scholar] [CrossRef] [PubMed]
- Taslimitehrani, V.; Dong, G.; Pereira, N.L.; Panahiazar, M.; Pathak, J. Developing EHR-driven heart failure risk prediction models using CPXR (Log) with the probabilistic loss function. J. Biomed. Inform. 2016, 60, 260–269. [Google Scholar] [CrossRef] [PubMed]
- Panahiazar, M.; Taslimitehrani, V.; Pereira, N.; Pathak, J. Using EHRs and Machine Learning for Heart Failure Survival Analysis. MedInfo 2015, 2015, 40–44. [Google Scholar]
- Panahiazar, M.; Dumontier, M.; Gevaert, O. Predicting biomedical metadata in CEDAR: A study of Gene Expression Omnibus (GEO). J. Biomed. Inform. 2017, 72, 132–139. [Google Scholar] [CrossRef] [PubMed]
- Reactome Webpage. Available online: https://reactome.org (accessed on 31 July 2018).
- Kegg Webpage. Available online: https://www.genome.jp/kegg/pathway.html (accessed on 31 July 2018).
- Pathway Tools Webpage. Available online: http://bioinformatics.ai.sri.com/ptools/ (accessed on 31 July 2018).





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Synonyms: | albino, ATN, CMM8, Dopa oxidase, |
| OCA1, OCA1A, OCAIA, SHEP3, … | |
| Entrez Gene ID for Human: | TYR EG:7299 |
| Entrez Gene ID for Mouse: | TYR EG:22173 |
| Functions/ Functional Domains: | copper ion binding, cytoplasmic domain, |
| cytosolic tail domain, enzyme, … | |
| Subcellular Location: | cell periphery, cell |
| membrane, cytoplasm, | |
| endosomes, melanosomes, … | |
| Canonical Pathway: | Aryl Hydrocarbon Receptor |
| Signaling; Eumelanin Biosynthesis, … | |
| Targeted By miRNA Cluster: | miR-1208 (miRNAs w/seed CACUGUU), |
| miR-1229-3p (miRNAs w/seed UCUCACC), … | |
| Regulates: | melanin, L-tyrosine, TYR, |
| L-dopa, KLRD1, KLRC1, … | |
| Regulated By: | POMC, MITF, forskolin, ASIP, PD98059, |
| cyclic AMP, ciglitazone, KITLG, … | |
| Binds To: | CANX, CALR, HSPA5, TYRP1, SYVN1, … |
| Role in the Cell: | proliferation, pigmentation, |
| melanogenesis in, shape change, … | |
| Related Diseases: | oculocutaneous albinism, melasma, |
| rosacea, acne vulgaris, cancer, melanosis, … | |
| Molecular Function: | copper ion binding; monooxygenase |
| activity; oxidoreductase activity; … | |
| Biological Process: | eye pigment biosynthetic |
| process; melanin biosynthetic process; | |
| pigmentation; … | |
| Cellular Component: | cytoplasm; cytosol; Golgi- |
| associated vesicle; melanosome; nucleus; … | |
| Targeting Drug: | azelaic acid, hydroquinone |
| Actinic keratosis: | aspririn | paclitaxel | docetaxel | acetaminophen |
| Melasma: | tretinoin | prednisone | rituximab | cyclophosphamide |
| Post inflammatory: | azelaic acid | dutasteride | finasteride | tamsulosin |
| Pigmentation: | tretinoin | prednisone | sorafenib | rituximab |
| Hyperpigmentation: | examethasone | tretinoin | prednisone | cyclophosphamide |
| Rosacea: | phenylephrine | tretinoin | chlorpheniramine | epinephrine |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Panahiazar, M.; Fadavi, D.; Aljabban, J.; Safeer, L.; Aljabban, I.; Hadley, D. Large Scale Advanced Data Analytics on Skin Conditions from Genotype to Phenotype. Informatics 2018, 5, 39. https://doi.org/10.3390/informatics5040039
Panahiazar M, Fadavi D, Aljabban J, Safeer L, Aljabban I, Hadley D. Large Scale Advanced Data Analytics on Skin Conditions from Genotype to Phenotype. Informatics. 2018; 5(4):39. https://doi.org/10.3390/informatics5040039
Chicago/Turabian StylePanahiazar, Maryam, Darya Fadavi, Jihad Aljabban, Laraib Safeer, Imad Aljabban, and Dexter Hadley. 2018. "Large Scale Advanced Data Analytics on Skin Conditions from Genotype to Phenotype" Informatics 5, no. 4: 39. https://doi.org/10.3390/informatics5040039
APA StylePanahiazar, M., Fadavi, D., Aljabban, J., Safeer, L., Aljabban, I., & Hadley, D. (2018). Large Scale Advanced Data Analytics on Skin Conditions from Genotype to Phenotype. Informatics, 5(4), 39. https://doi.org/10.3390/informatics5040039