RadViz++: Improvements on Radial-Based Visualizations



Abstract
:1. Introduction
- R1
- Be scalable in both the number of variables and instances;
- R2
- Decrease and/or explain visual ambiguities they create in data-to-variable analyses;
- R3
- Show unambiguously variable relations to support variable-to-variable analyses;
- R4
- Separate data clusters well to support data-to-data analyses.
2. Related Work
2.1. Concepts and Background
2.2. Related Methods
3. RadViz++ Proposal
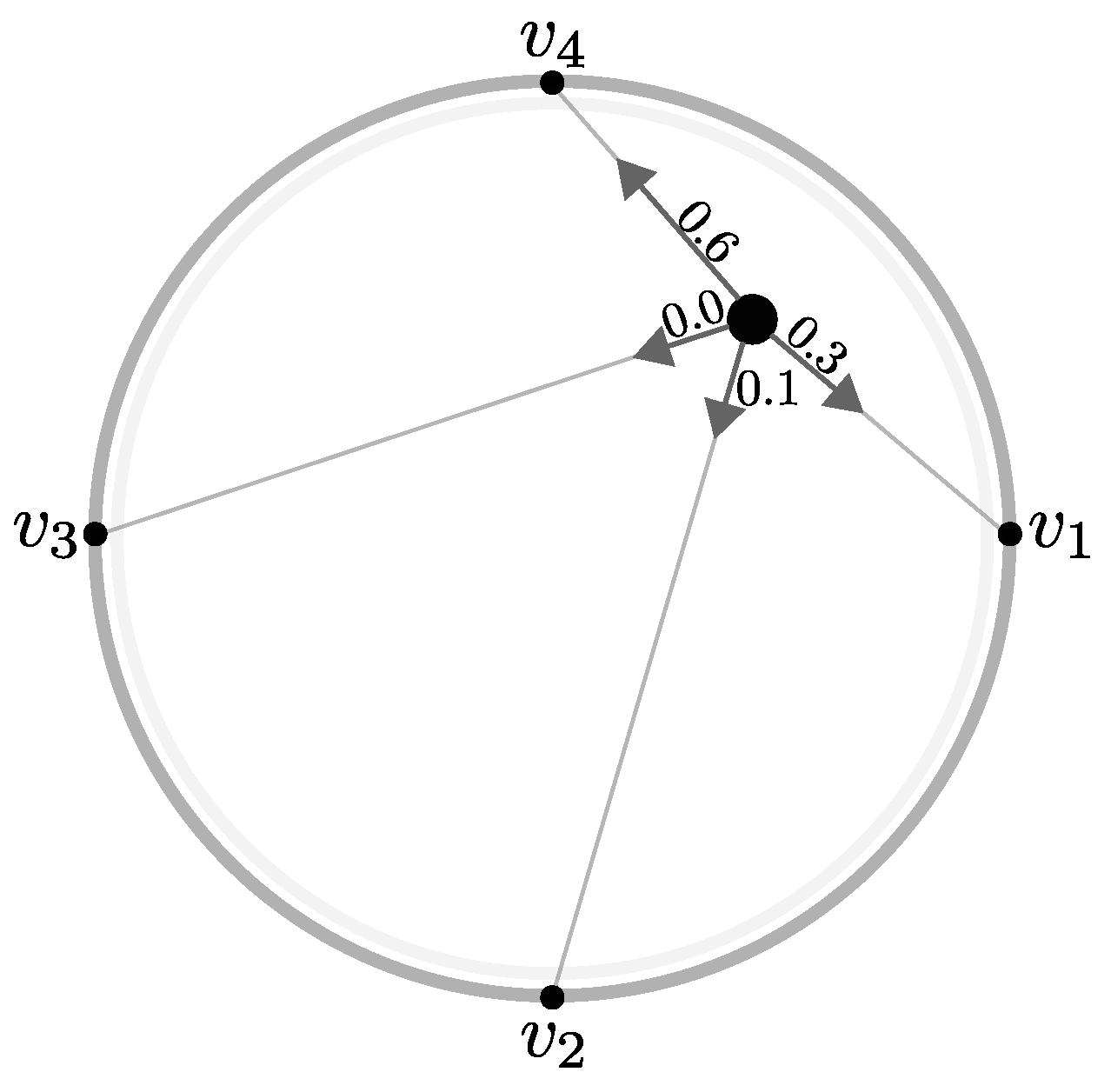
3.1. Anchor Placement
3.2. Variable-to-Variable Analysis
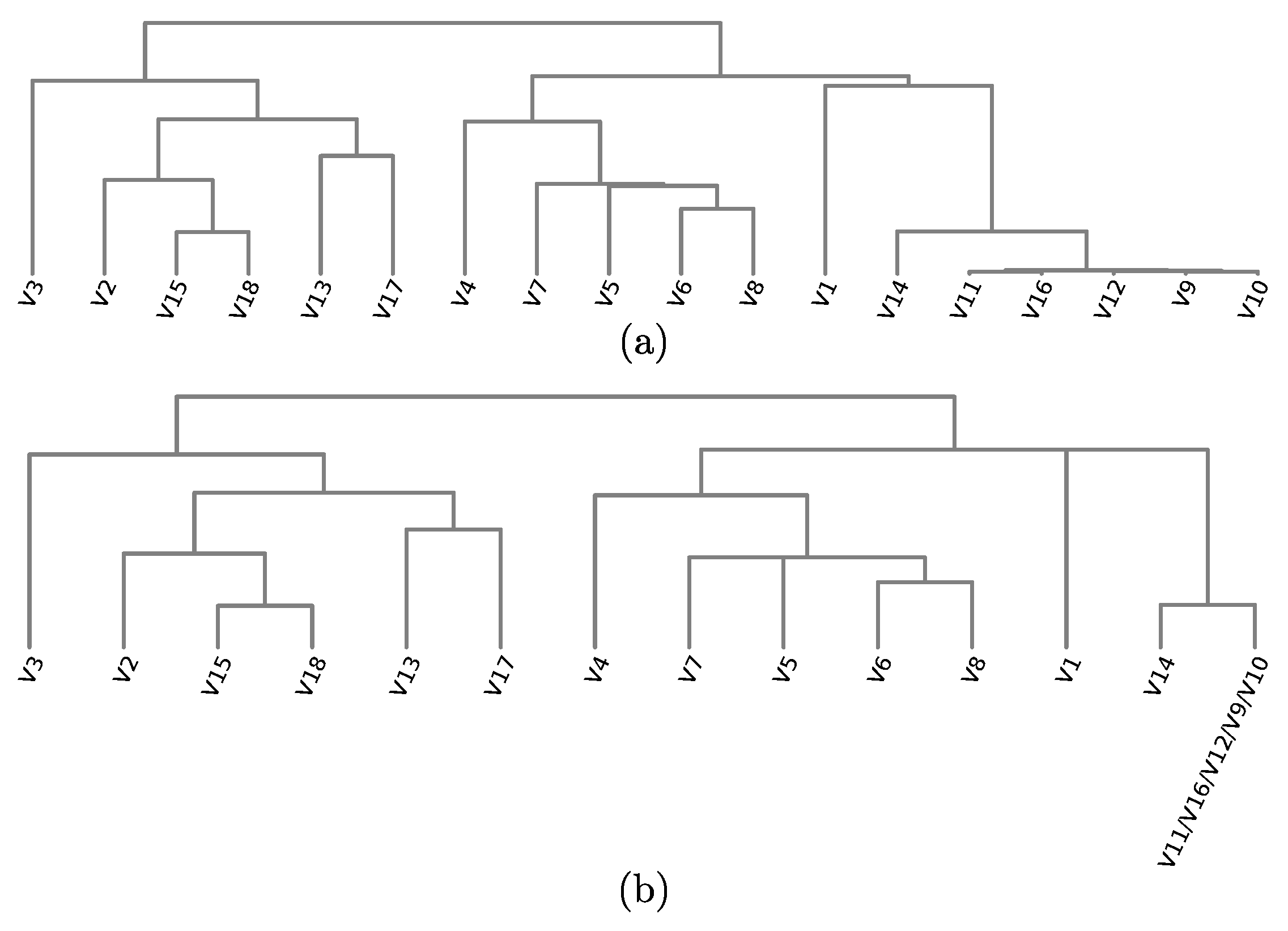
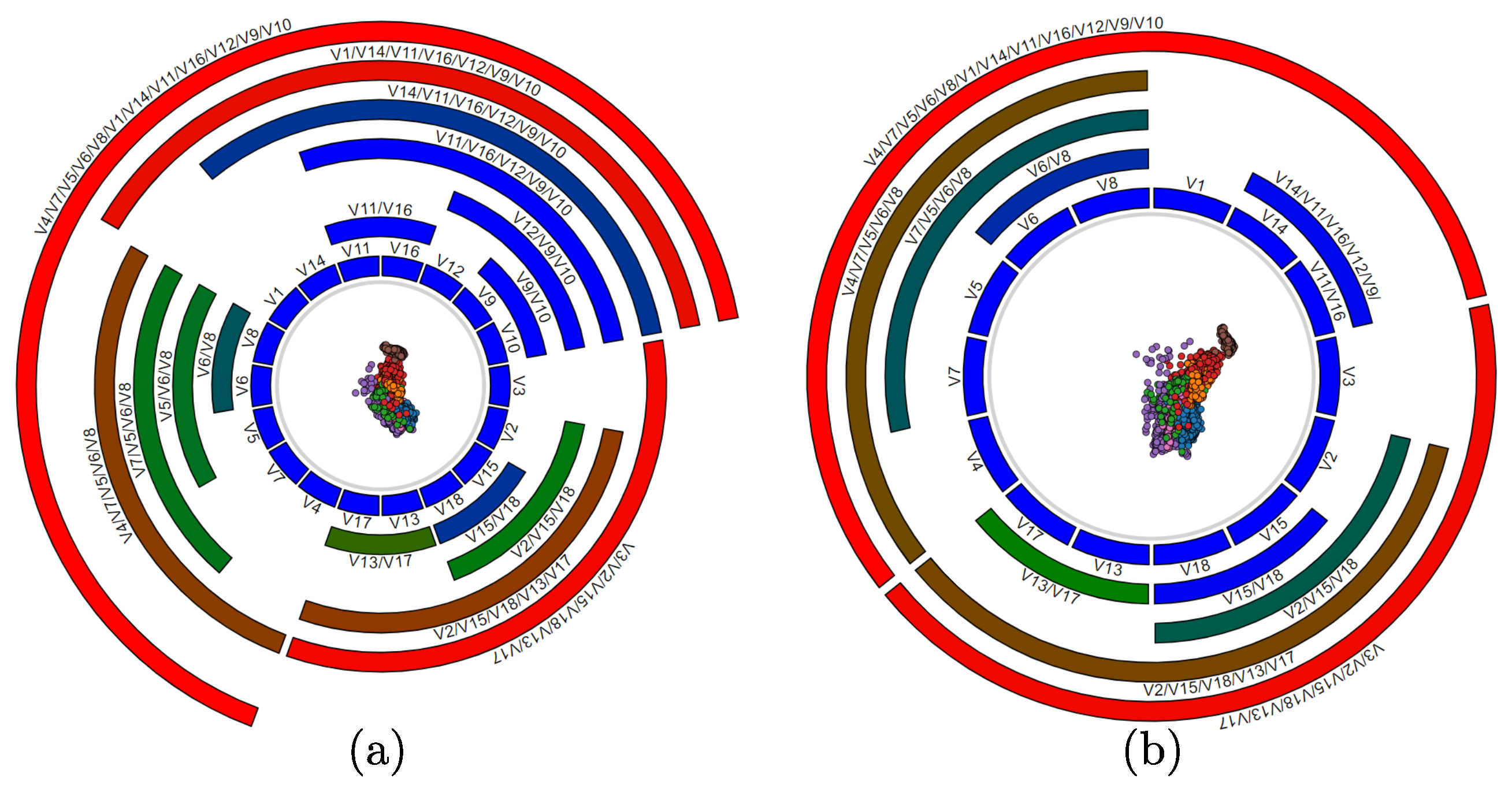
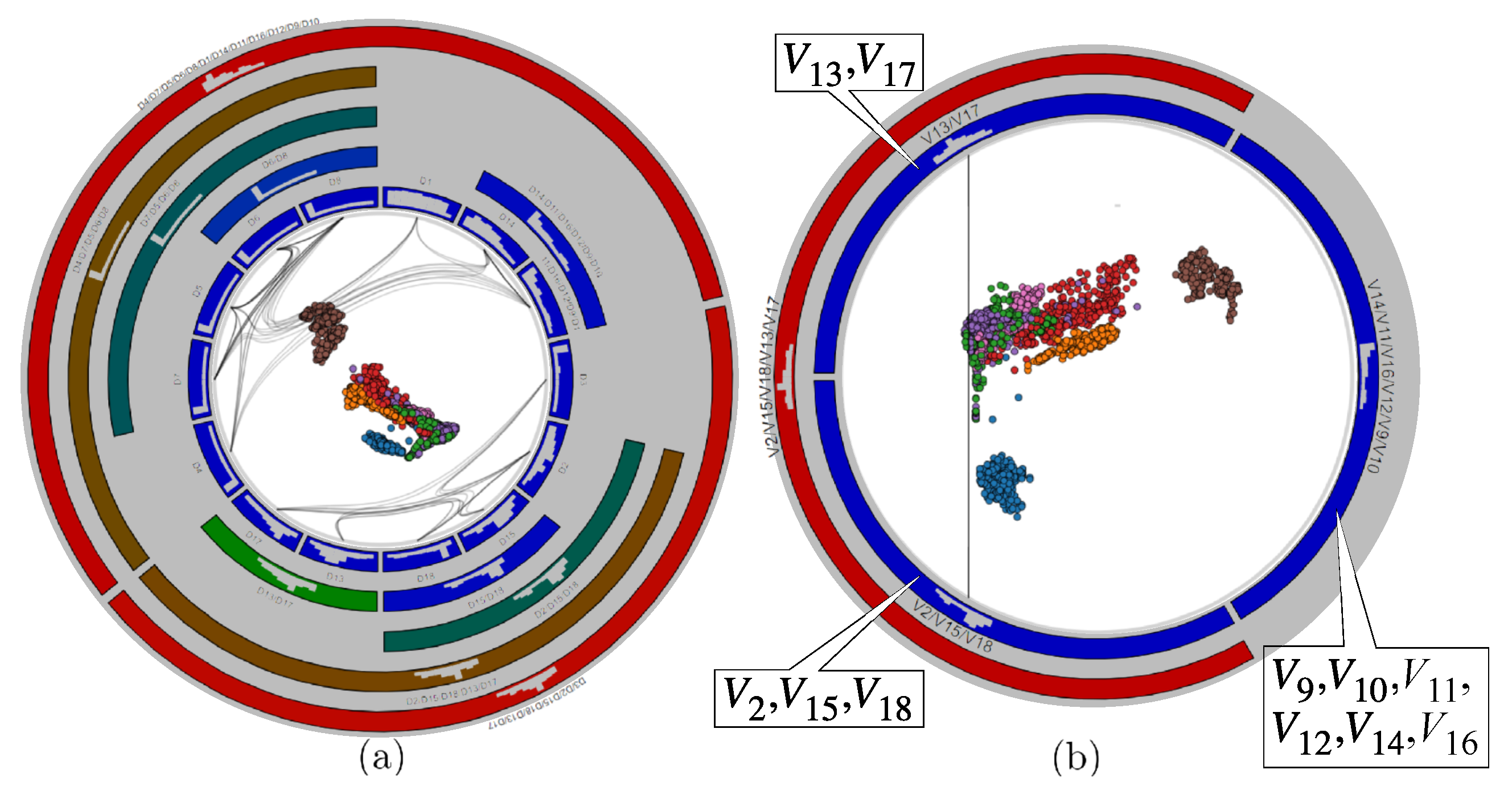
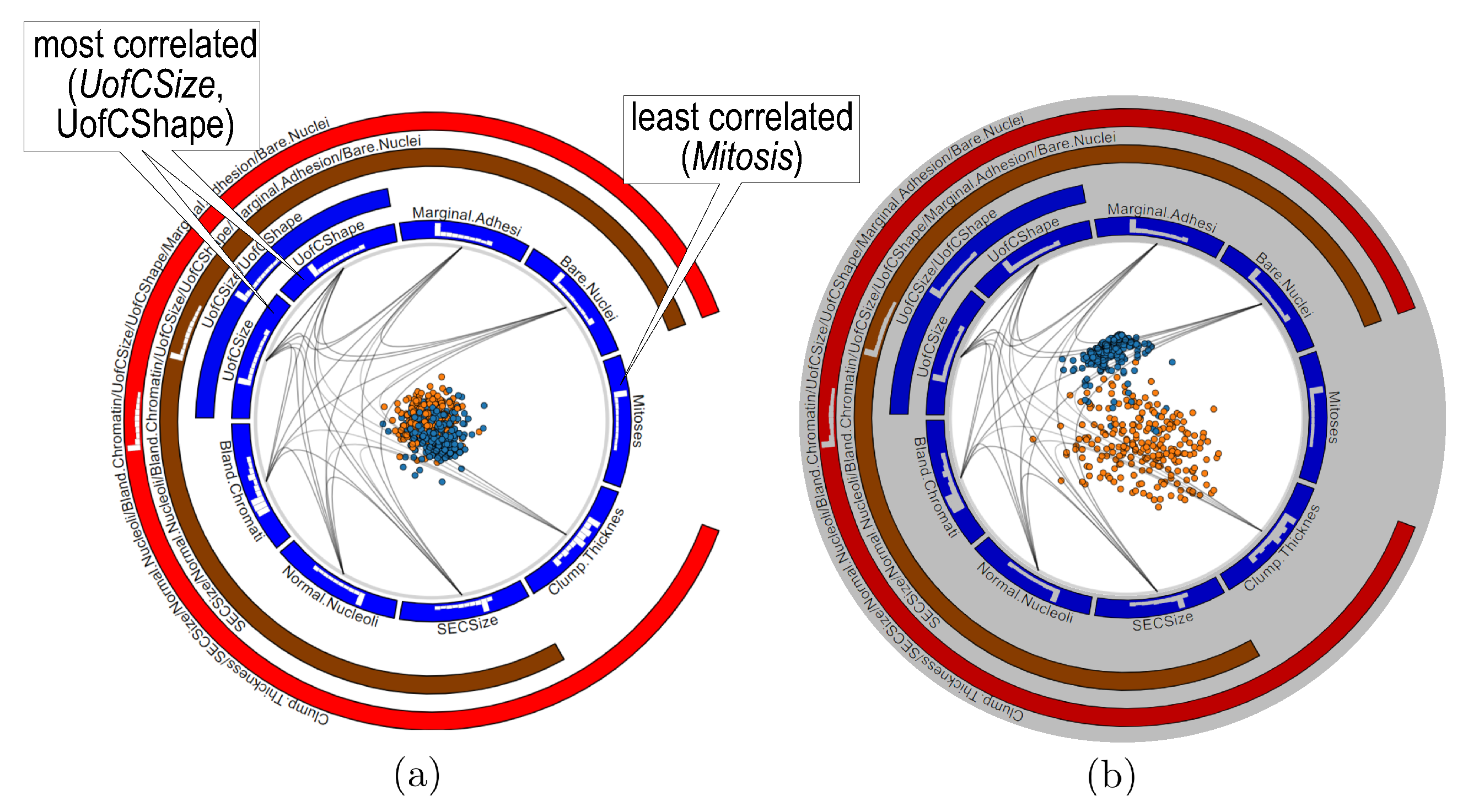
3.2.1. Variable Hierarchy
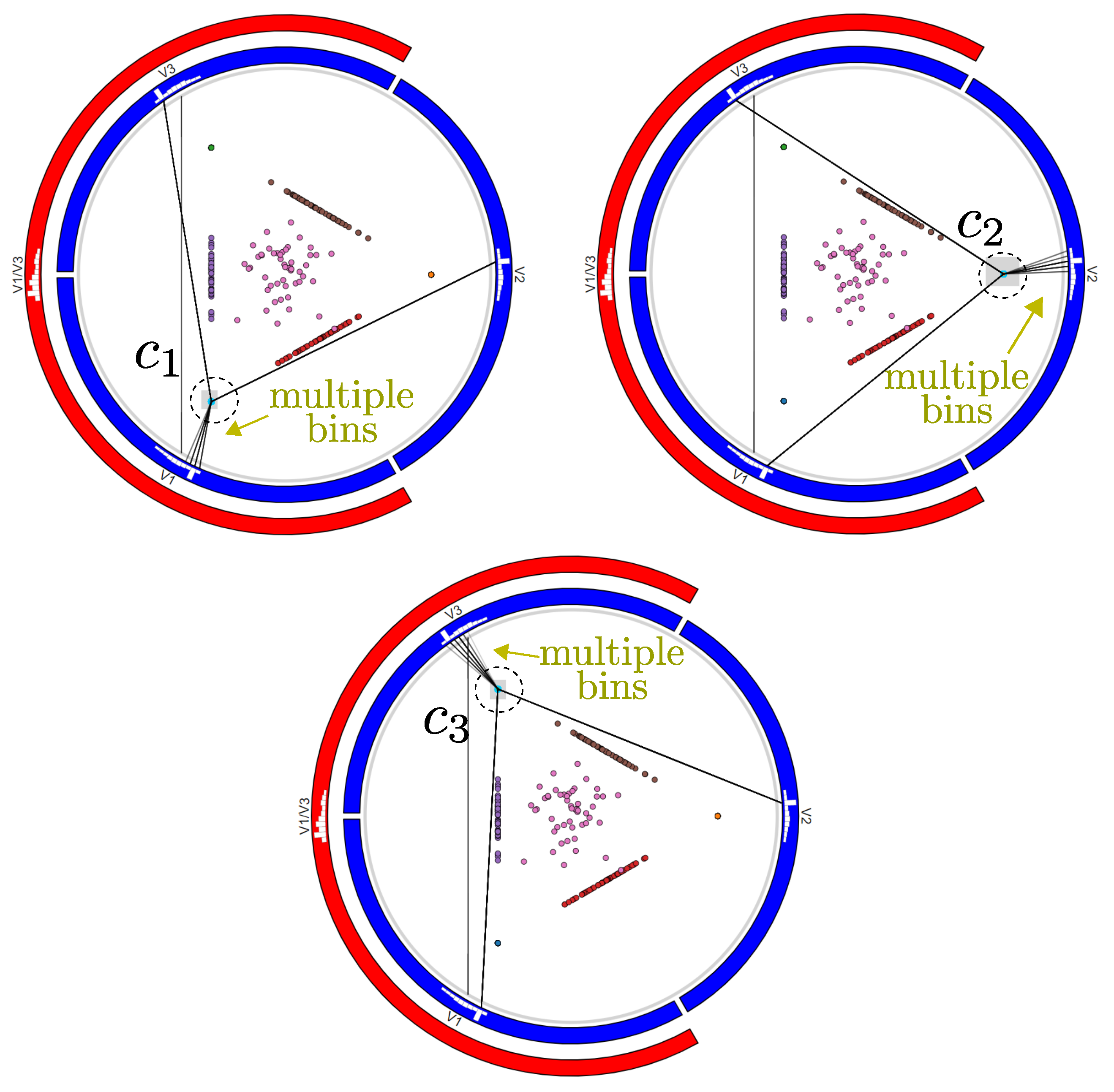
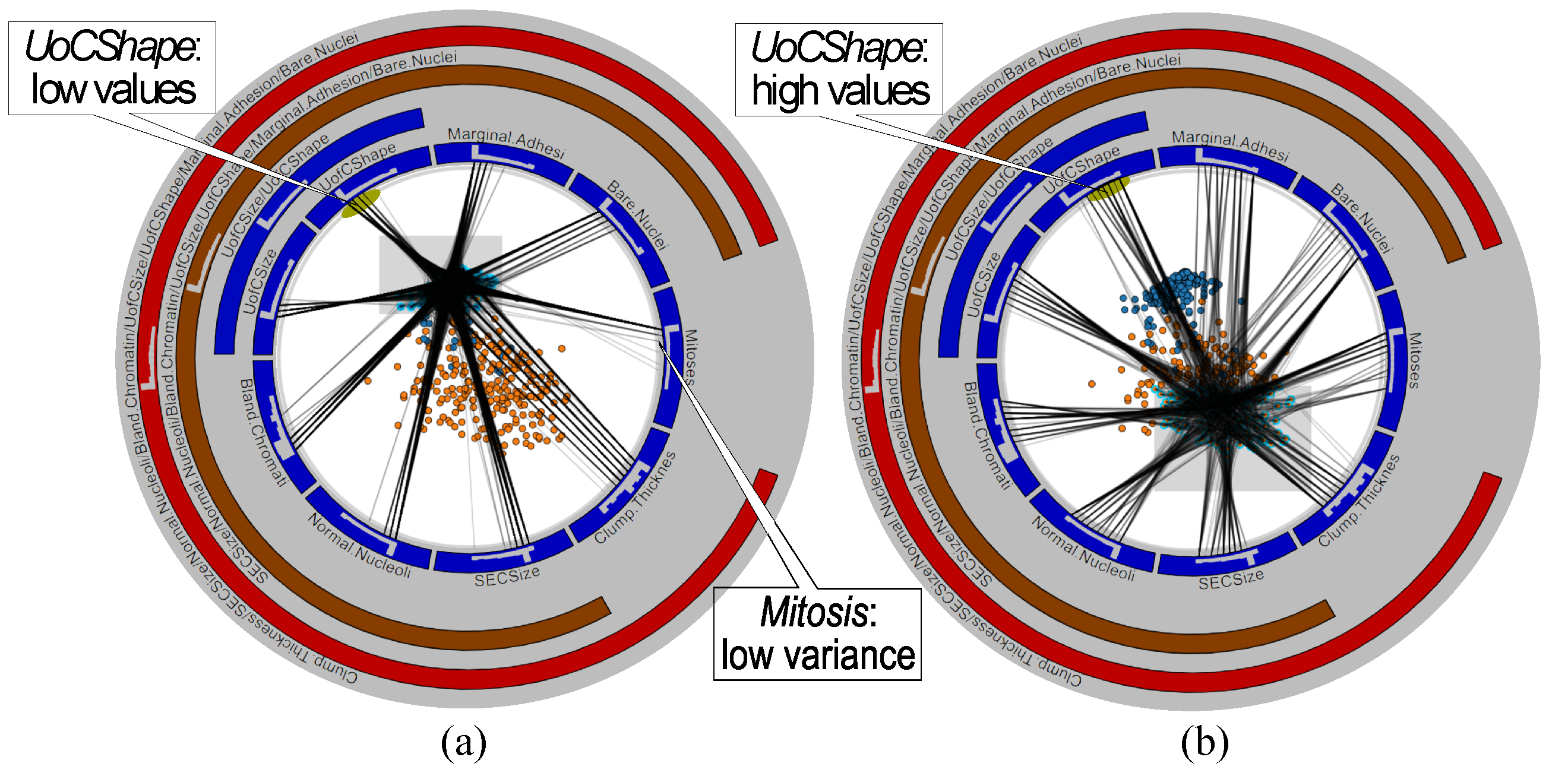
3.2.2. Similarity Disambiguation
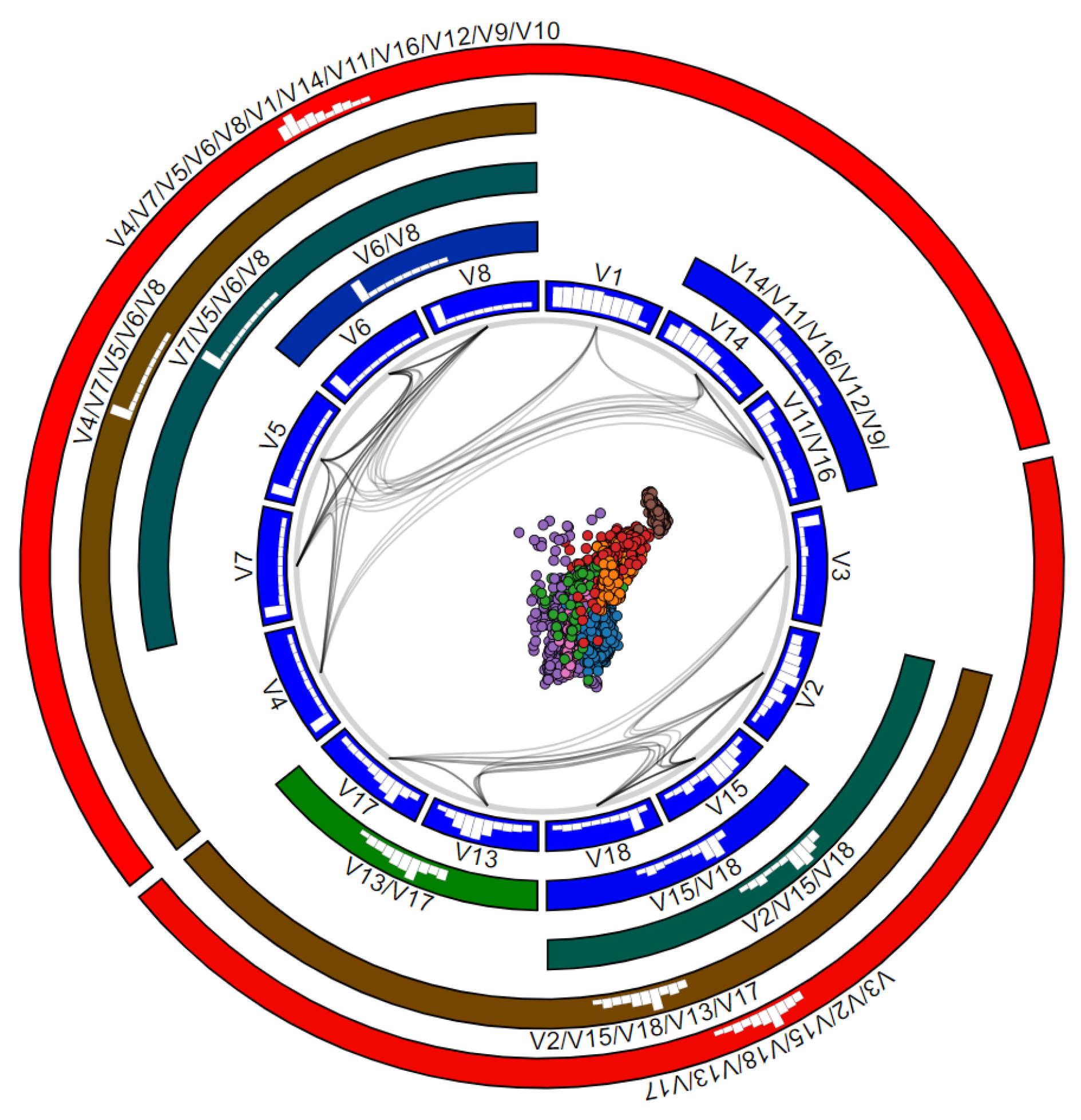
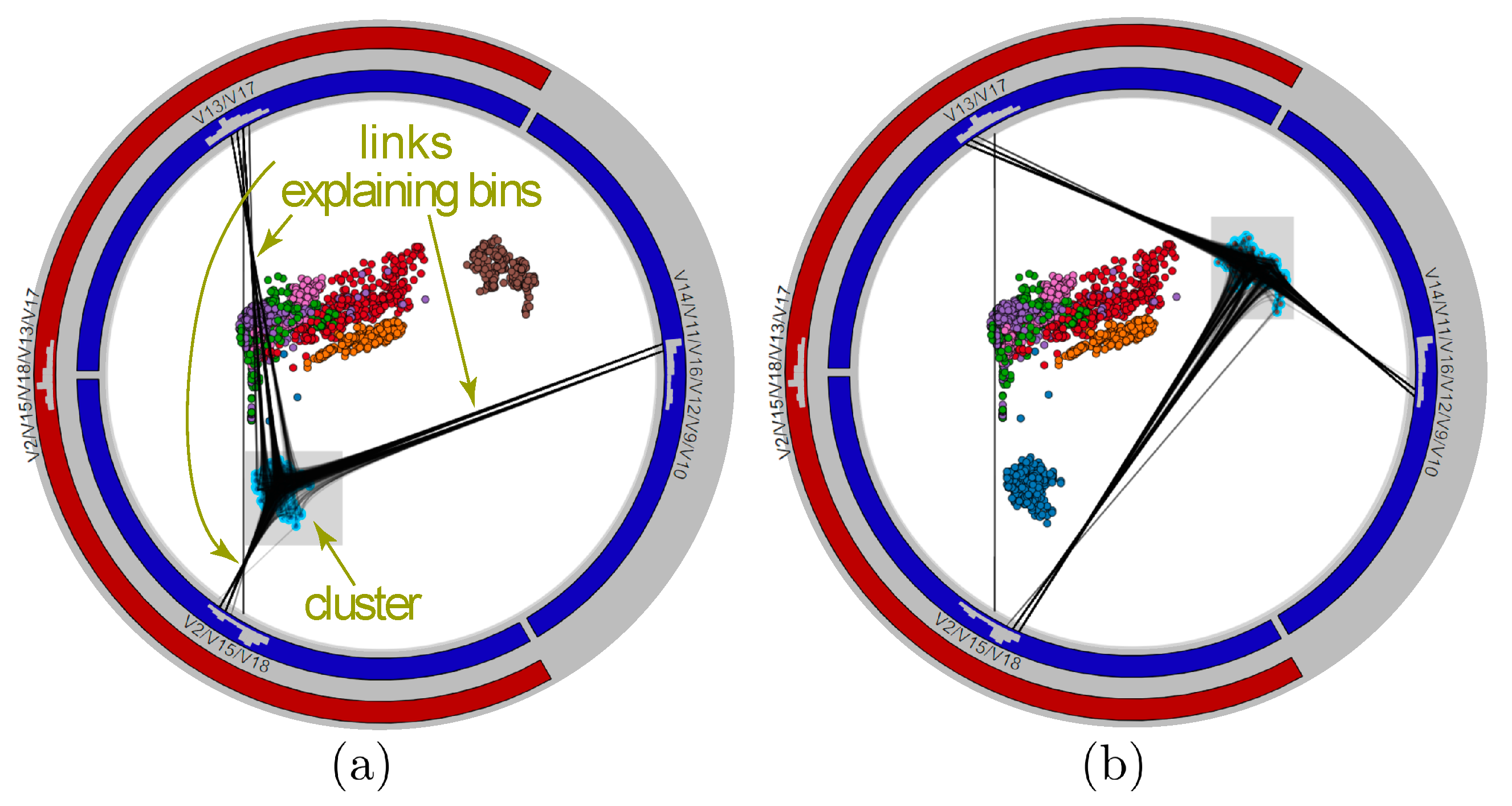
3.3. Analyzing Variable Values
3.4. Scalability and Level-of-Detail
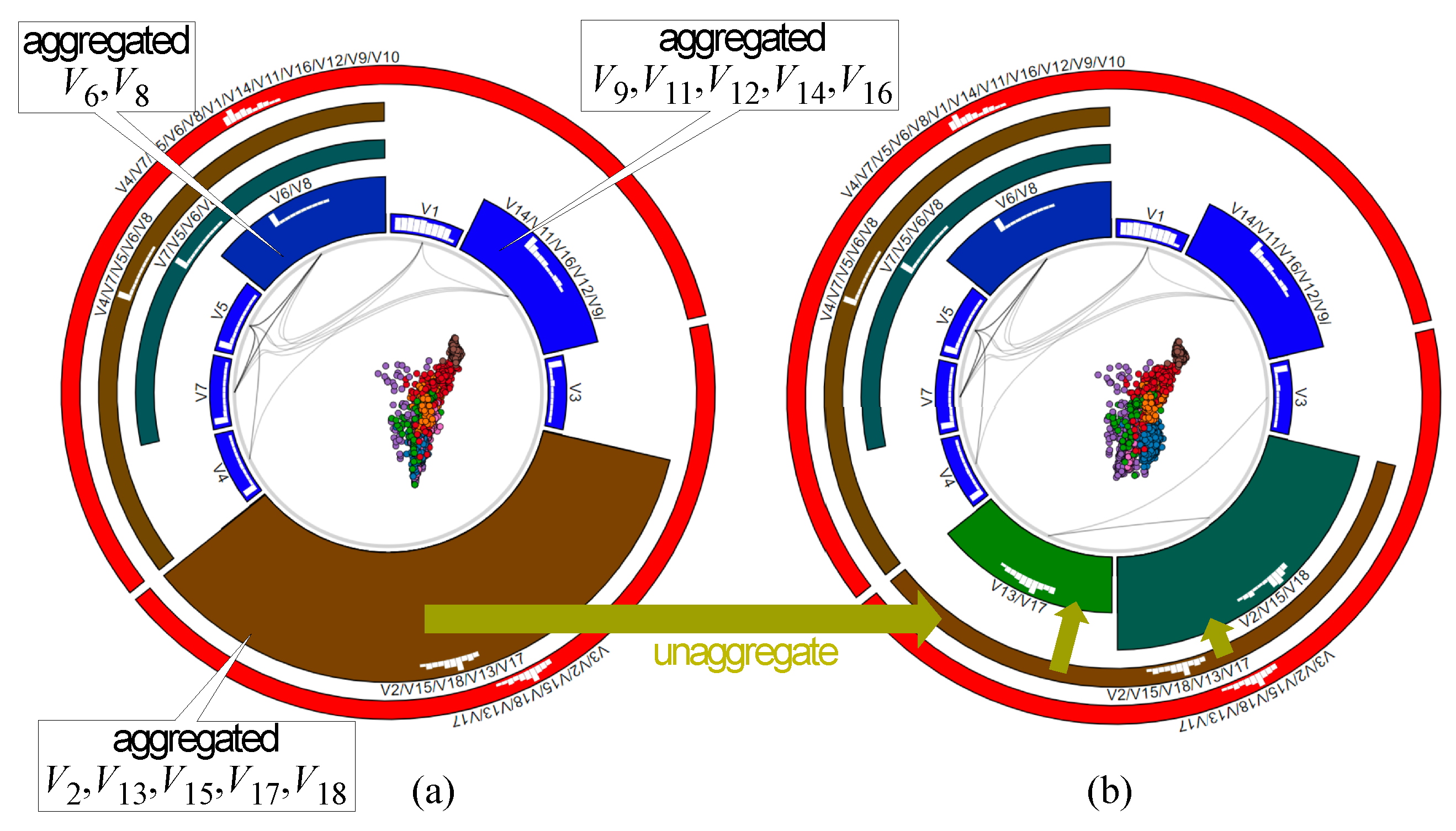
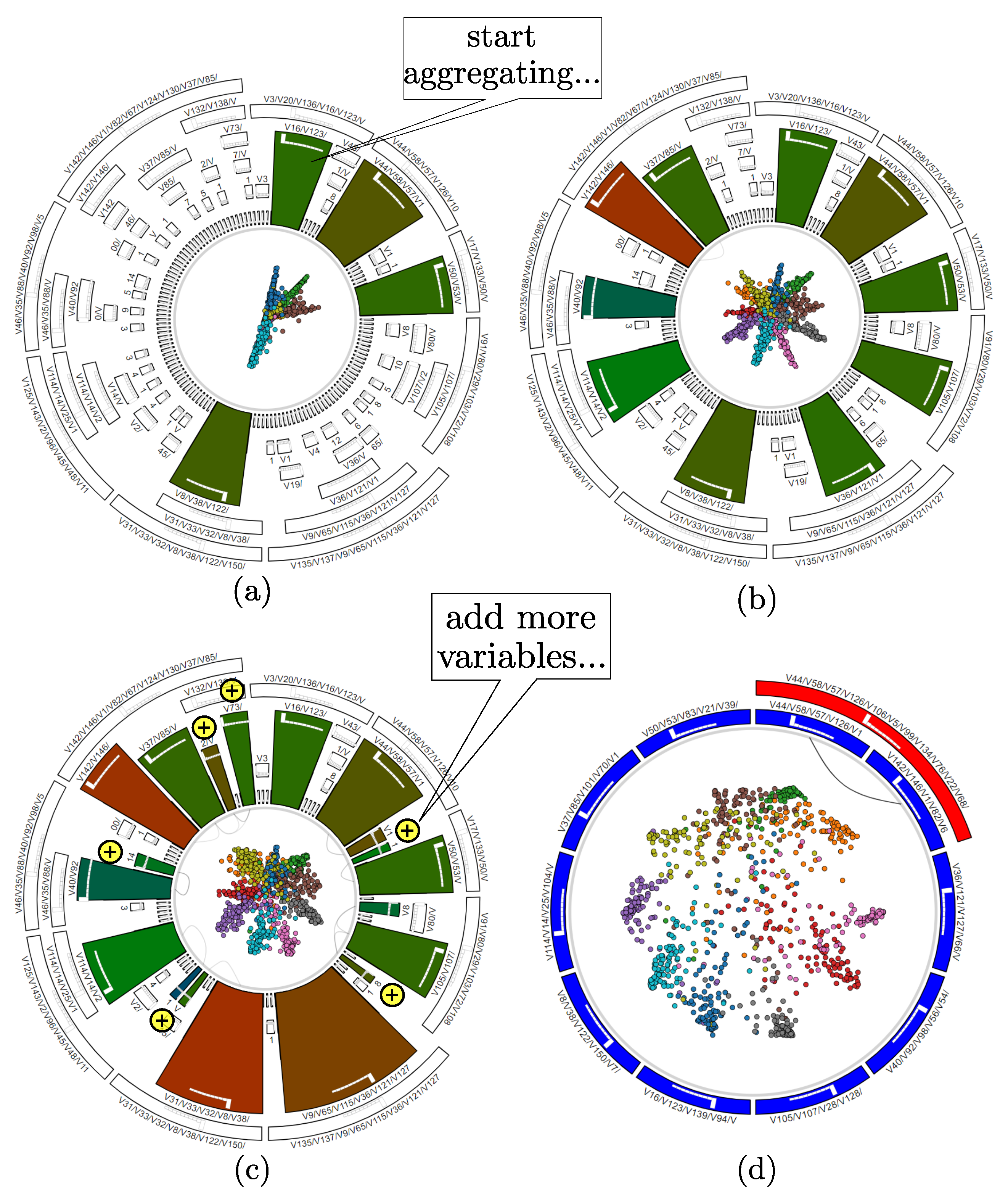
3.4.1. Aggregating Variables
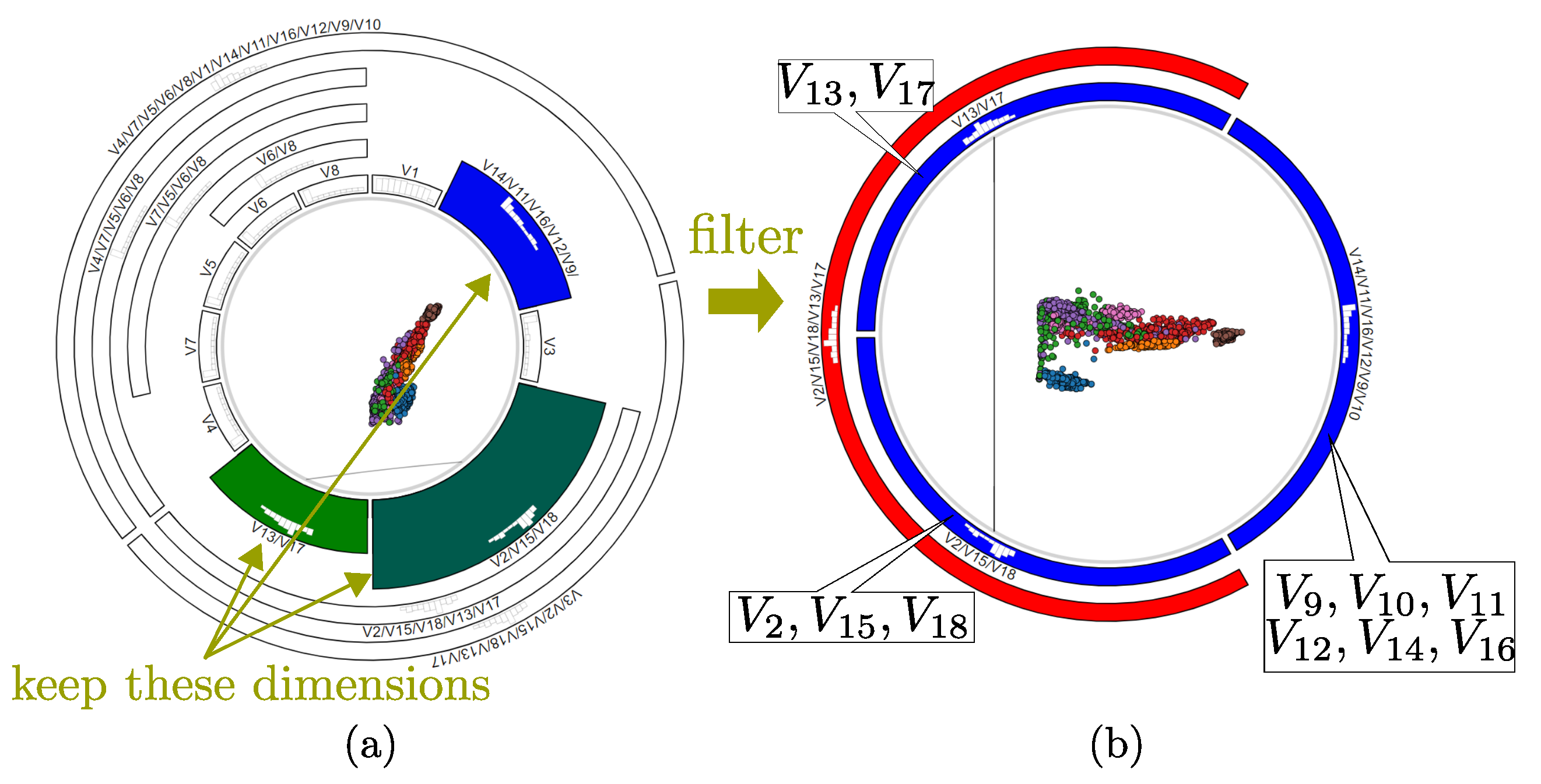
3.4.2. Variable Filtering
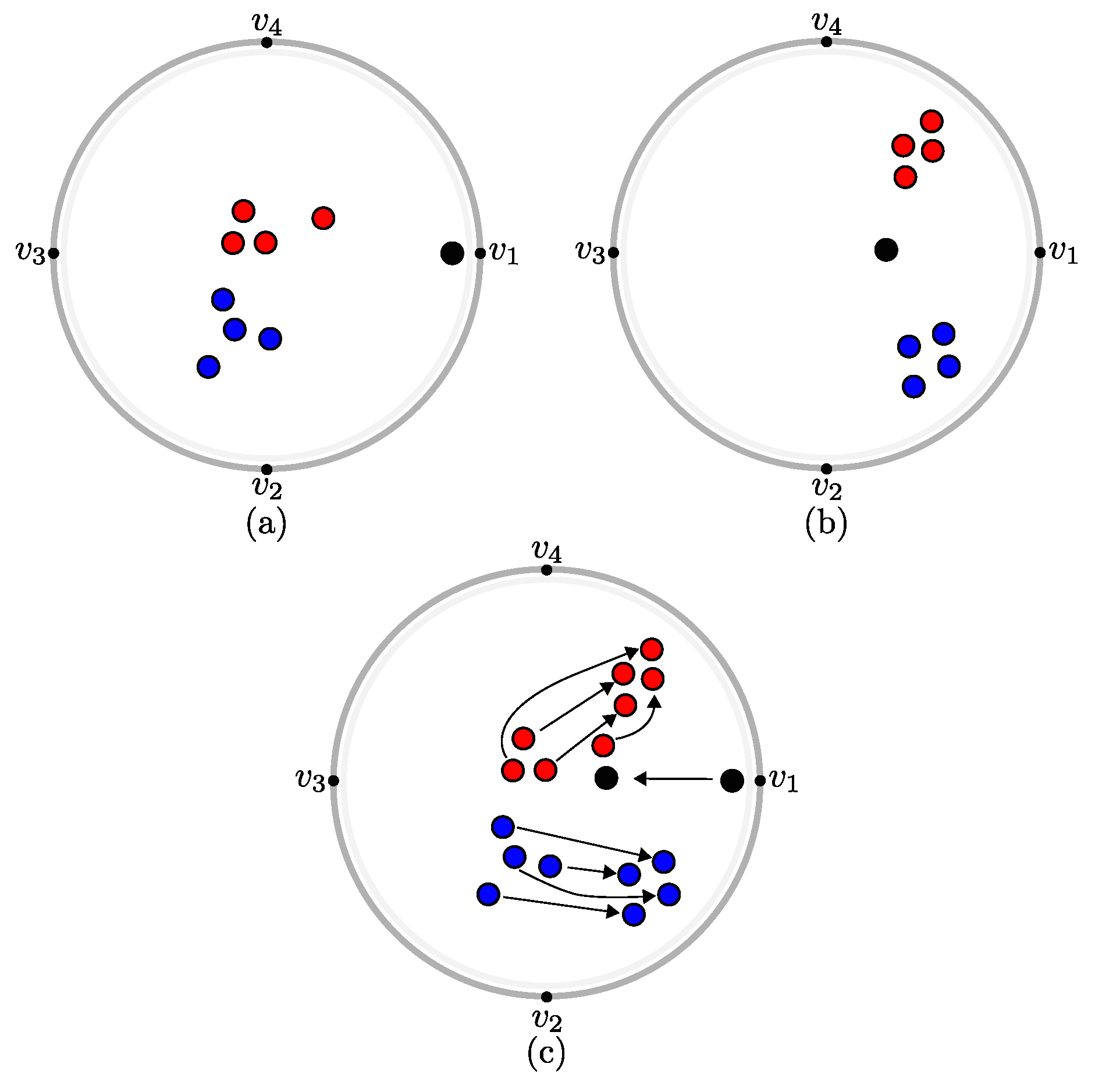
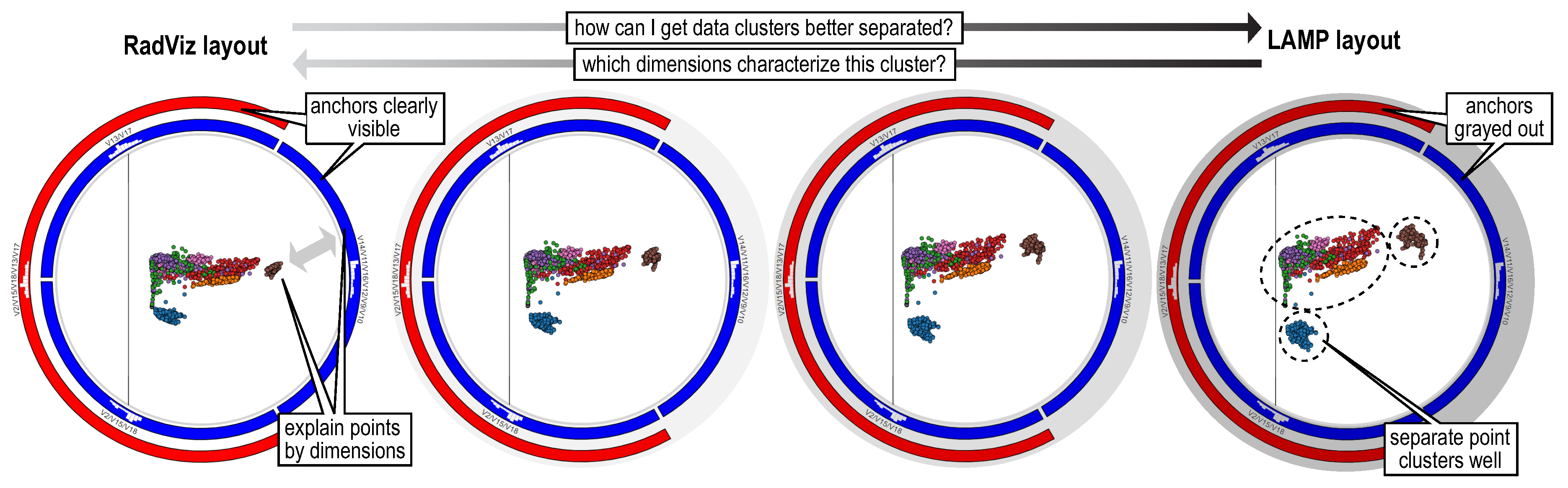
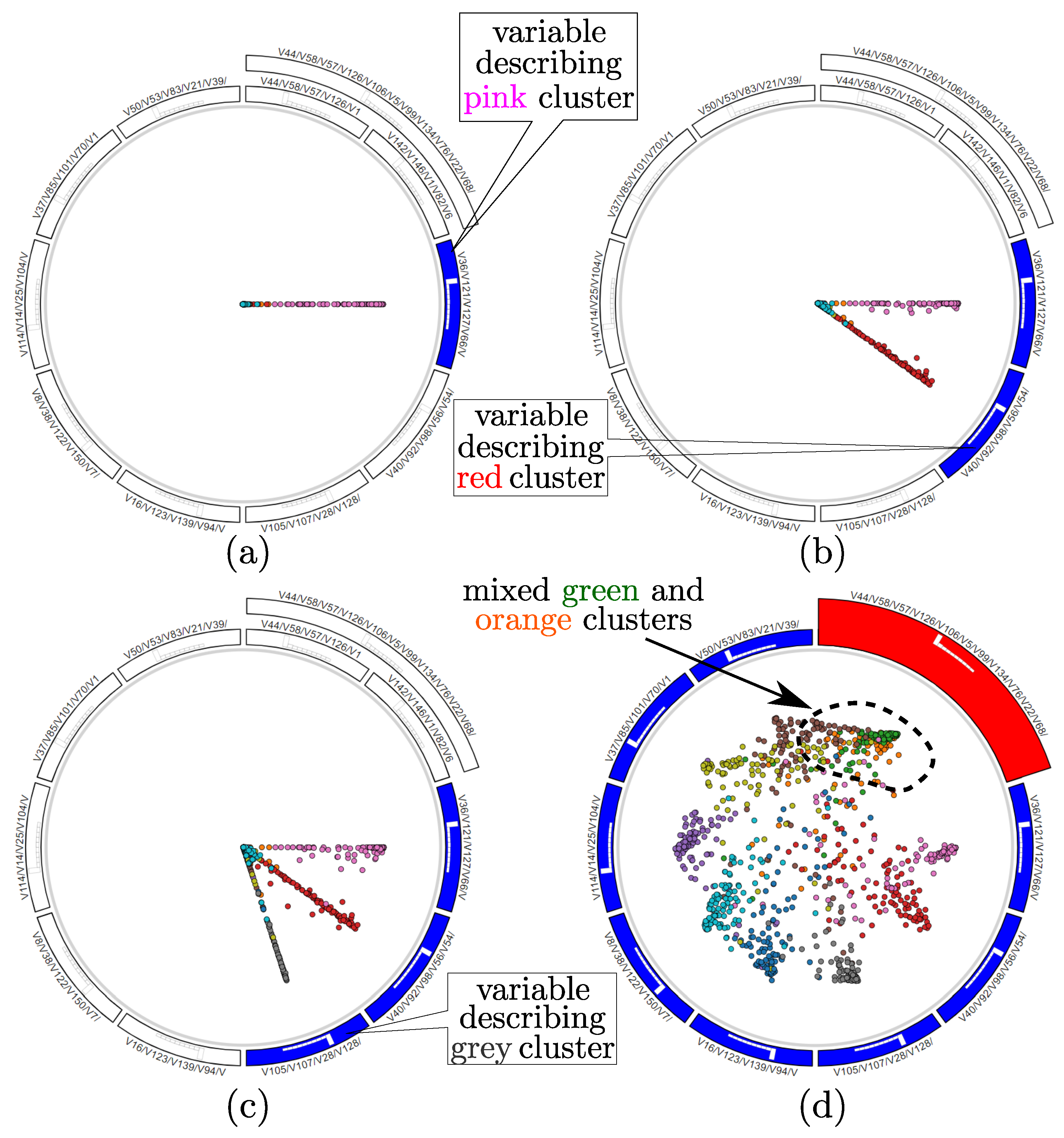
3.5. Data-to-Data and Data-to-Variable Analysis
4. Experiments
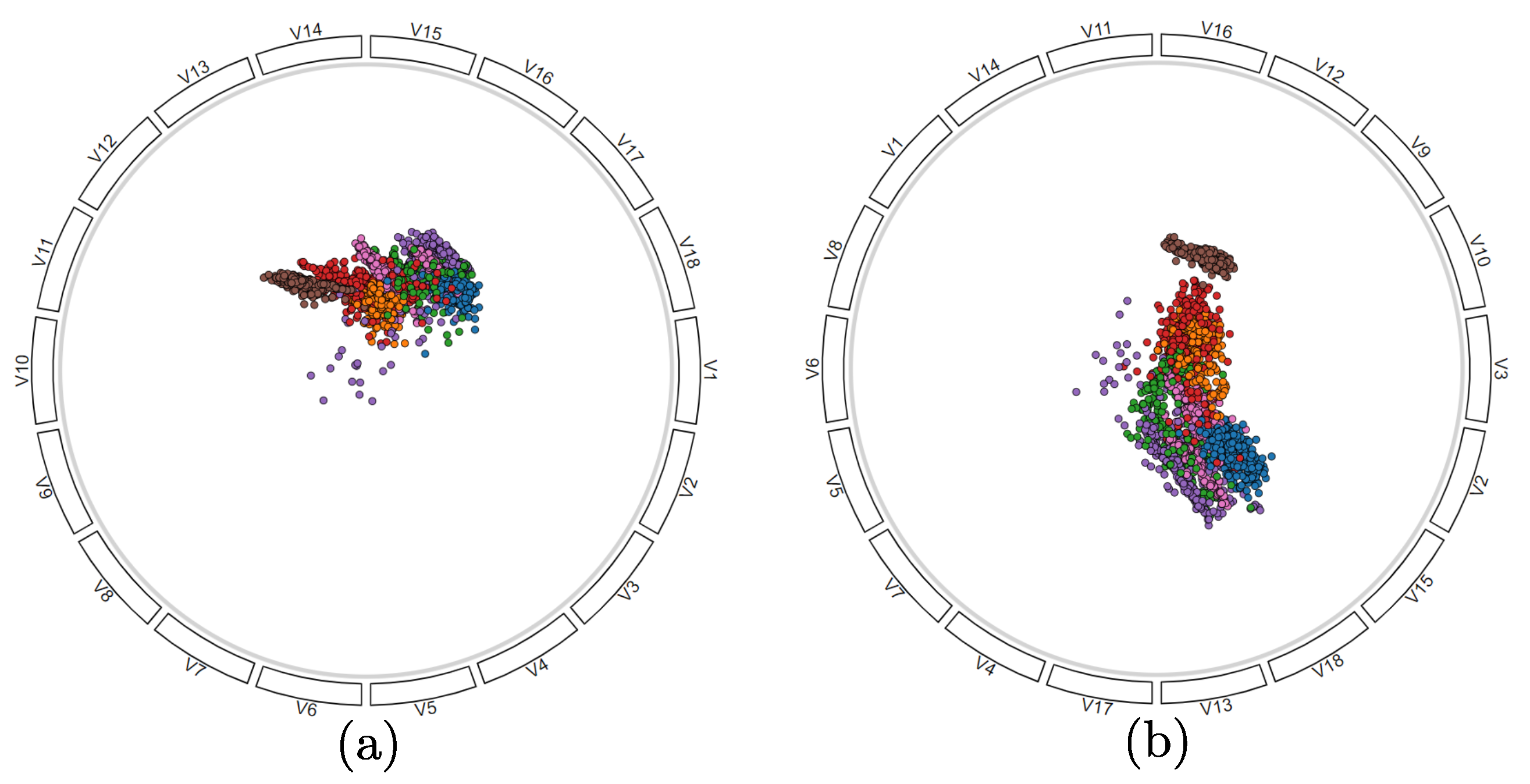
4.1. Validation on Synthetic Data
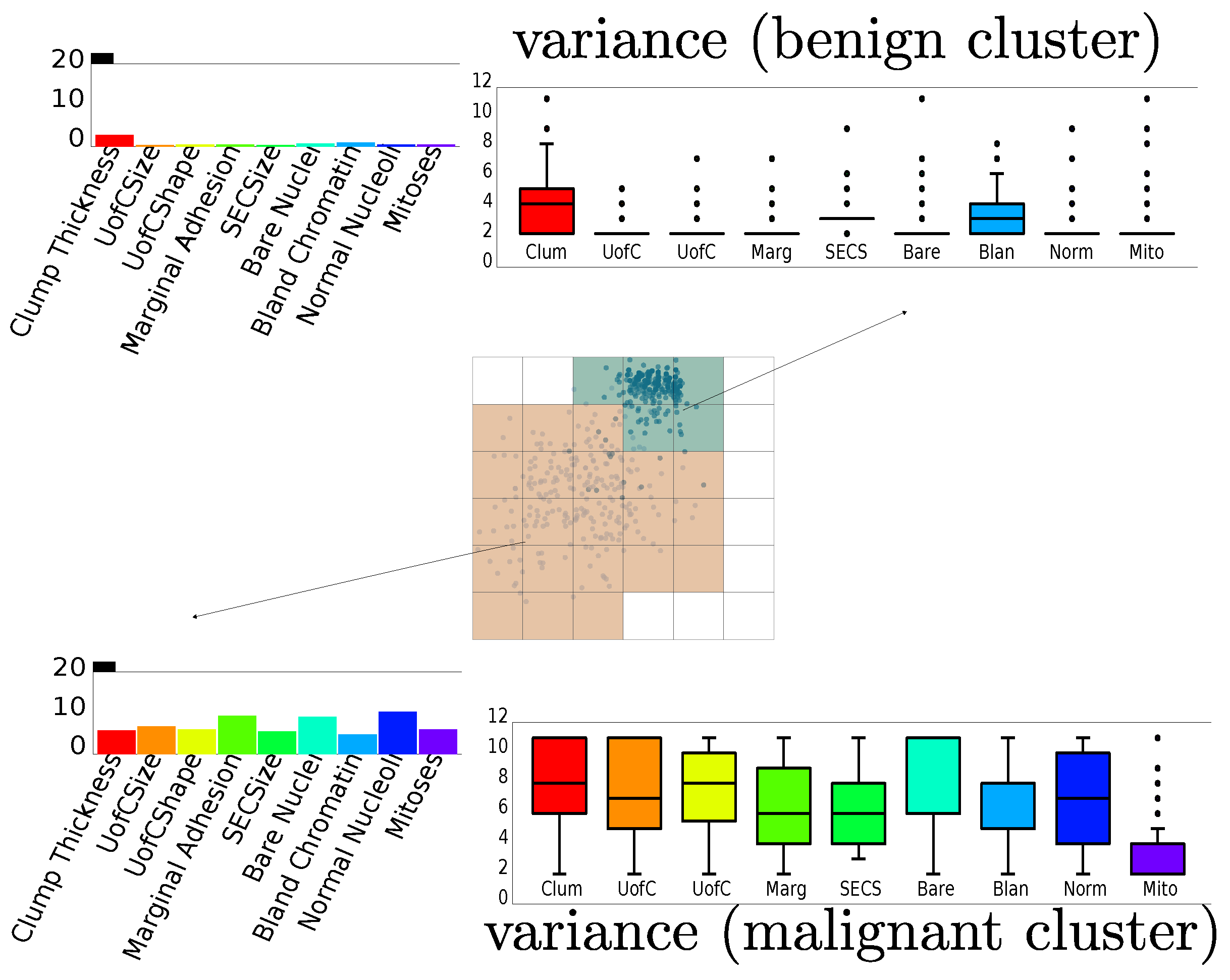
4.2. Wisconsin Breast Cancer
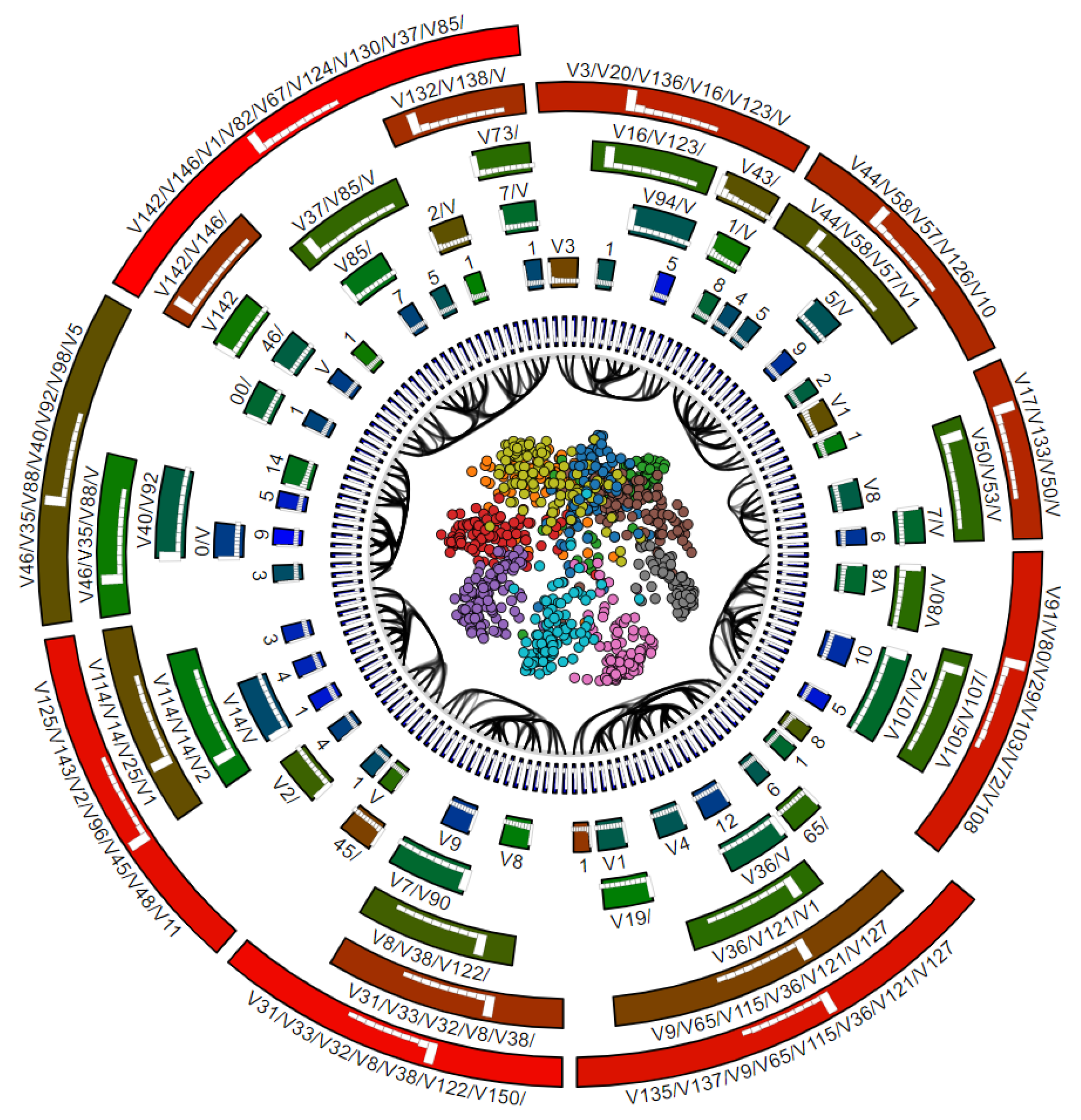
4.3. Corel Dataset
5. Discussion
Limitations
6. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Van Leeuwen, T.; Jewitt, C. The Handbook of Visual Analysis; SAGE Publications: Thousand, CA, USA, 2000. [Google Scholar]
- Nonato, L.; Aupetit, M. Multidimensional Projection for Visual Analytics: Linking Techniques with Distortions, Tasks, and Layout Enrichment. IEEE Trans. Vis. Comput. Graph. 2018. [Google Scholar] [CrossRef]
- da Silva, R.R.O.; Rauber, P.E.; Martins, R.M.; Minghim, R.; Telea, A. Attribute-based Visual Explanation of Multidimensional Projections. In Proceedings of the EuroVis Workshop on Visual Analytics, Cagliari, Italy, 25–26 May 2015. [Google Scholar]
- Coimbra, D.; Martins, R.; Neves, T.; Telea, A.; Paulovich, F. Explaining three-dimensional dimensionality reduction plots. Inf. Vis. 2016, 15, 154–172. [Google Scholar] [CrossRef]
- Pagliosa, L.; Pagliosa, P.; Nonato, L.G. Understanding Attribute Variability in Multidimensional Projections. In Proceedings of the 2016 29th SIBGRAPI Conference on Graphics, Patterns and Images, Sao Paulo, Brazil, 4–7 October 2016; pp. 297–304. [Google Scholar]
- Inselberg, A. Parallel Coordinates: Visual Multidimensional Geometry and Its Applications; Springer: Berlin/Heidelberg, Germany, 2009. [Google Scholar]
- Telea, A.C. Data Visualization: Principles and Practice, 2nd ed.; A. K. Peters, Ltd.: Bew York, NY, USA, 2014. [Google Scholar]
- McGill, R.; Tukey, J.W.; Larsen, W.A. Variations of Box Plots. Am. Stat. 1978, 32, 12–16. [Google Scholar]
- Hoffman, P.; Grinstein, G.; Marx, K.; Grosse, I.; Stanley, E. DNA visual and analytic data mining. In Proceedings of the Visualization ’97, Phoenix, AZ, USA, 24 October 1997; pp. 437–441. [Google Scholar]
- Bertini, E.; Dell’Aquila, L.; Santucci, G. SpringView: Cooperation of radviz and parallel coordinates for view optimization and clutter reduction. In Proceedings of the Coordinated and Multiple Views in Exploratory Visualization, London, UK, 5 July 2005. [Google Scholar]
- Rubio-Sanchez, M.; Raya, L.; Díaz, F.; Sanchez, A. A comparative study between RadViz and Star Coordinates. IEEE Trans. Vis. Comput. Graph. 2015, 22, 619–628. [Google Scholar] [CrossRef]
- Kruskal, J.B.; Landwehr, J.M. Icicle Plots: Better Displays for Hierarchical Clustering. Am. Stat. 1983, 37, 162–168. [Google Scholar]
- Holten, D. Hierarchical Edge Bundles: Visualization of Adjacency Relations in Hierarchical Data. IEEE Trans. Vis. Comput. Graph. 2006, 12, 741–748. [Google Scholar] [CrossRef] [PubMed]
- Cheng, S.; Xu, W.; Mueller, K. RadViz Deluxe: An Attribute-Aware Display for Multivariate Data. Processes 2017, 5, 75. [Google Scholar] [CrossRef]
- Nováková, L.; Štěpánková, O. Visualization of trends using RadViz. J. Intell. Inf. Syst. 2011, 37, 355. [Google Scholar] [CrossRef]
- Ankerst, M.; Berchtold, S.; Keim, D. Similarity clustering of dimensions for an enhanced visualization of multidimensional data. In Proceedings of the IEEE Symposium on Information Visualization, Research Triangle, CA, USA, 19–20 October 1998; pp. 52–60. [Google Scholar]
- Nováková, L.; Štěpánková, O. RadViz and Identification of Clusters in Multidimensional Data. In Proceedings of the 2009 13th International Conference Information Visualisation, Barcelona, Spain, 15–17 July 2009; pp. 104–109. [Google Scholar]
- Zhou, F.; Huang, W.; Li, J.; Huang, Y.; Shi, Y.; Zhao, Y. Extending Dimensions in Radviz based on mean shift. In Proceedings of the 2015 IEEE Pacific Visualization Symposium, Hangzhou, China, 14–17 April 2015; pp. 111–115. [Google Scholar]
- Dunn, J.C. Well-Separated Clusters and Optimal Fuzzy Partitions. J. Cybern. 1974, 4, 95–104. [Google Scholar]
- Sharko, J.; Grinstein, G.; Marx, K.A. Vectorized Radviz and Its Application to Multiple Cluster Datasets. IEEE Trans. Vis. Comput. Graph. 2008, 14, 1444–1427. [Google Scholar] [CrossRef]
- Ono, J.; Sikansi, F.; Correa, D.C.; Paulovich, F.V.; Paiva, A.; Nonato, L.G. Concentric RadViz: Visual Exploration of Multi-task Classification. In Proceedings of the 2015 28th SIBGRAPI Conference on Graphics, Patterns and Images, Salvador, Brazil, 26–29 August 2015; pp. 165–172. [Google Scholar]
- Di Caro, L.; Frias-Martinez, V.; Frias-Martinez, E. Analyzing the Role of Dimension Arrangement for Data Visualization in Radviz. In Proceedings of the Pacific-Asia Conference on Knowledge Discovery and Data Mining, Hyderabad, India, 21–24 June 2010; pp. 125–132. [Google Scholar]
- Kandogan, E. Star Coordinates: A Multi-dimensional Visualization Technique with Uniform Treatment of Dimensions. In Proceedings of the IEEE Information Visualization Symposium, Salt Lake City, UT, USA, 9–10 October 2000; pp. 9–12. [Google Scholar]
- Zanabria, G.G.; Nonato, L.G.; Gomez-Nieto, E. iStar (i*): An interactive star coordinates approach for high-dimensional data exploration. Comput. Graph. 2016, 60, 107–118. [Google Scholar] [CrossRef]
- Grira, N.; Crucianu, M.; Boujemaa, N. Unsupervised and Semi-supervised Clustering: A Brief Survey. Rev. Mach. Learn. Techn. Process. Multimedia Content 2004, 1, 9–16. [Google Scholar]
- Wang, L.; Zhang, J.; Li, H. An Improved Genetic Algorithm for TSP. In Proceedings of the 2007 International Conference on Machine Learning and Cybernetics, Hong Kong, China, 19–22 August 2007; Volume 2, pp. 925–928. [Google Scholar]
- Gower, J.C.; Hand, D.J. Biplots; CRC Press: Boca Raton, FL, USA, 1995. [Google Scholar]
- Greenacre, M. Biplots in Practice; Fundacion BBVA: Fundación, Colombia, 2010. [Google Scholar]
- Gower, J.C.; Lubbe, S.; Roux, N. Understanding Biplots; Wiley: Hoboken, NJ, USA, 2011. [Google Scholar]
- Rubio-Sánchez, M.; Sanchez, A.; Lehmann, D.J. Adaptable Radial Axes Plots for Improved Multivariate Data Visualization. Comput. Graph. Forum 2017, 36, 389–399. [Google Scholar] [CrossRef]
- Bollobás, B.; Frieze, A.M.; Fenner, T.I. An Algorithm for Finding Hamilton Paths and Cycles in Random Graphs. Combinatorica 1987, 7, 327–341. [Google Scholar] [CrossRef]
- Tejada, E.; Minghim, R.; Nonato, L.G. On Improved Projection Techniques to Support Visual Exploration of Multidimensional Data Sets. Inf. Vis. 2003, 2, 218–231. [Google Scholar] [CrossRef]
- Joia, P.; Coimbra, D.; Cuminato, J.A.; Paulovich, F.V.; Nonato, L.G. Local Affine Multidimensional Projection. IEEE Trans. Vis. Comput. Graph. 2011, 17, 2563–2571. [Google Scholar] [CrossRef]
- Martins, R.M.; Coimbra, D.B.; Minghim, R.; Telea, A. Visual analysis of dimensionality reduction quality for parameterized projections. Comput. Graph. 2014, 41, 26–42. [Google Scholar] [CrossRef]
- Dua, D.; Karra Taniskidou, E. UCI Machine Learning Repository, 2019.
- Tung, A.; Xu, X.; Ooi, B.C. CURLER: Finding and visualizing nonlinear correlation clusters. In Proceedings of the 2005 ACM SIGMOD international conference on Management of data, Baltimore, MD, USA, 14–16 June 2005; pp. 233–245. [Google Scholar]
- Fraser, A.M.; Swinney, H.L. Independent coordinates for strange attractors from mutual information. Phys. Rev. 1986, 33, 1134–1140. [Google Scholar] [CrossRef]
- Müller, M. Dynamic Time Warping. In Information Retrieval for Music and Motion; Springer: Berlin/Heidelberg, Germany, 2007; pp. 69–84. [Google Scholar]
- Box, G.E.P.; Jenkins, G.M. Time Series Analysis: Forecasting and Control, 5th ed.; Wiley: Hoboken, NJ, USA, 2015. [Google Scholar]
- Benesty, J.; Chen, J.; Huang, Y.; Cohen, I. Pearson Correlation Coefficient. In Noise Reduction in Speech Processing; Springer: Berlin/Heidelberg, Germany, 2009; pp. 1–4. [Google Scholar]
- Rokach, L.; Maimon, O. Clustering Methods. In Data Mining and Knowledge Discovery Handbook; Springer: Berlin/Heidelberg, Germany, 2005; pp. 321–352. [Google Scholar]
- Carlsson, G.; Mémoli, F. Classifying clustering schemes. Found. Comput. Math. 2013, 13, 221–252. [Google Scholar] [CrossRef]
- van der Maaten, L.; Hinton, G. Visualizing Data using t-SNE. J. Mach. Learn. Res. 2008, 9, 2579–2605. [Google Scholar]
- Kruiger, J.; Hassoumi, A.; Schulz, H.J.; Telea, A.C.; Hurter, C. Multidimensional Data Exploration by Explicitly Controlled Animation. Informatics 2017, 4, 26. [Google Scholar] [CrossRef]
- Hurter, C.; Carpendale, S.; Telea, A. Color Tunneling: Interactive Exploration and Selection in Volumetric Datasets. In Proceedings of the 2014 IEEE Pacific Visualization Symposium, Yokohama, Japan, 4–7 March 2014. [Google Scholar]
- Hurter, C.; Telea, A.; Ersoy, O. MoleView: An Attribute and Structure-Based Semantic Lens for Large Element-Based Plots. IEEE Trans. Vis. Comput. Graph. 2011, 17, 2600–2609. [Google Scholar] [CrossRef] [PubMed]
- Brosz, J.; Nacenta, M.A.; Pusch, R.; Carpendale, S.; Hurter, C. Transmogrification: Causal manipulation of visualizations. In Proceedings of the 26th Annual ACM Symposium on User Interface Software and Technology, St. Andrews, UK, 8–11 October 2013; pp. 97–106. [Google Scholar]
- Hurter, C. Image-Based Visualization: Interactive Multidimensional Data Exploration. Synth. Lect. Vis. 2015, 3, 1–127. [Google Scholar] [CrossRef]
- Hoogendorp, H.; Ersoy, O.; Reniers, D.; Telea, A. Extraction and Visualization of Call Dependencies for Large C/C++ Code Bases: A Comparative Study. In Proceedings of the 2009 5th IEEE International Workshop on Visualizing Software for Understanding and Analysis, Edmonton, AB, Canada, 25–26 September 2009; pp. 121–130. [Google Scholar]
- Reniers, D.; Voinea, L.; Ersoy, O.; Telea, A. The Solid* Toolset for Software Visual Analytics of Program Structure and Metrics Comprehension: From Research Prototype to Product. Sci. Comput. Program. 2014, 79, 224–240. [Google Scholar] [CrossRef]
- Broeksema, B.; Baudel, T.; Telea, A. Decision Exploration Lab: A Visual Analytics Solution for Decision Management. Comput. Graph. Forum 2013, 32, 158–169. [Google Scholar] [CrossRef]




















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Instance | V1 | V2 | V3 | V4 |
|---|---|---|---|---|
| 0 | ||||
| 20 | 40 | 80 | 80 | |
| 2 | 4 | 8 | 8 | |
| 0 | 0 | 0 | 0 | |
| 20 | 1 | 20 | 1 | |
| 100 | 5 | 100 | 5 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Pagliosa, L.d.C.; Telea, A.C. RadViz++: Improvements on Radial-Based Visualizations. Informatics 2019, 6, 16. https://doi.org/10.3390/informatics6020016
Pagliosa LdC, Telea AC. RadViz++: Improvements on Radial-Based Visualizations. Informatics. 2019; 6(2):16. https://doi.org/10.3390/informatics6020016
Chicago/Turabian StylePagliosa, Lucas de Carvalho, and Alexandru C. Telea. 2019. "RadViz++: Improvements on Radial-Based Visualizations" Informatics 6, no. 2: 16. https://doi.org/10.3390/informatics6020016
APA StylePagliosa, L. d. C., & Telea, A. C. (2019). RadViz++: Improvements on Radial-Based Visualizations. Informatics, 6(2), 16. https://doi.org/10.3390/informatics6020016