4.1. Experiment 1: General Evaluation
This experiment was performed with 20 participants, aged between 10 and 18, with a neurotypical profile (no known cognitive disorders). They were recruited with the help of one of the co-authors, and they were unfamiliar with the technology presented to them.
The goal of this experiment was to evaluate the system on a quantitative level. For this, we focused on performance and emotion recognition, to gain an understanding of the technological issues that the system has, and where it would need improvement. This phase corresponded to the interaction between the participant and MAmIoTie.
The experiment began by explaining the collected data to parents and the children who would be performing the experiment, assuring that no personal data would be collected. After obtaining consent, we proceeded to tell the participants that the experiment would consist of interaction. We explained that they would need to speak clearly, and to wait for the conversation to be started by MAmIoTie, and gave no further instructions.
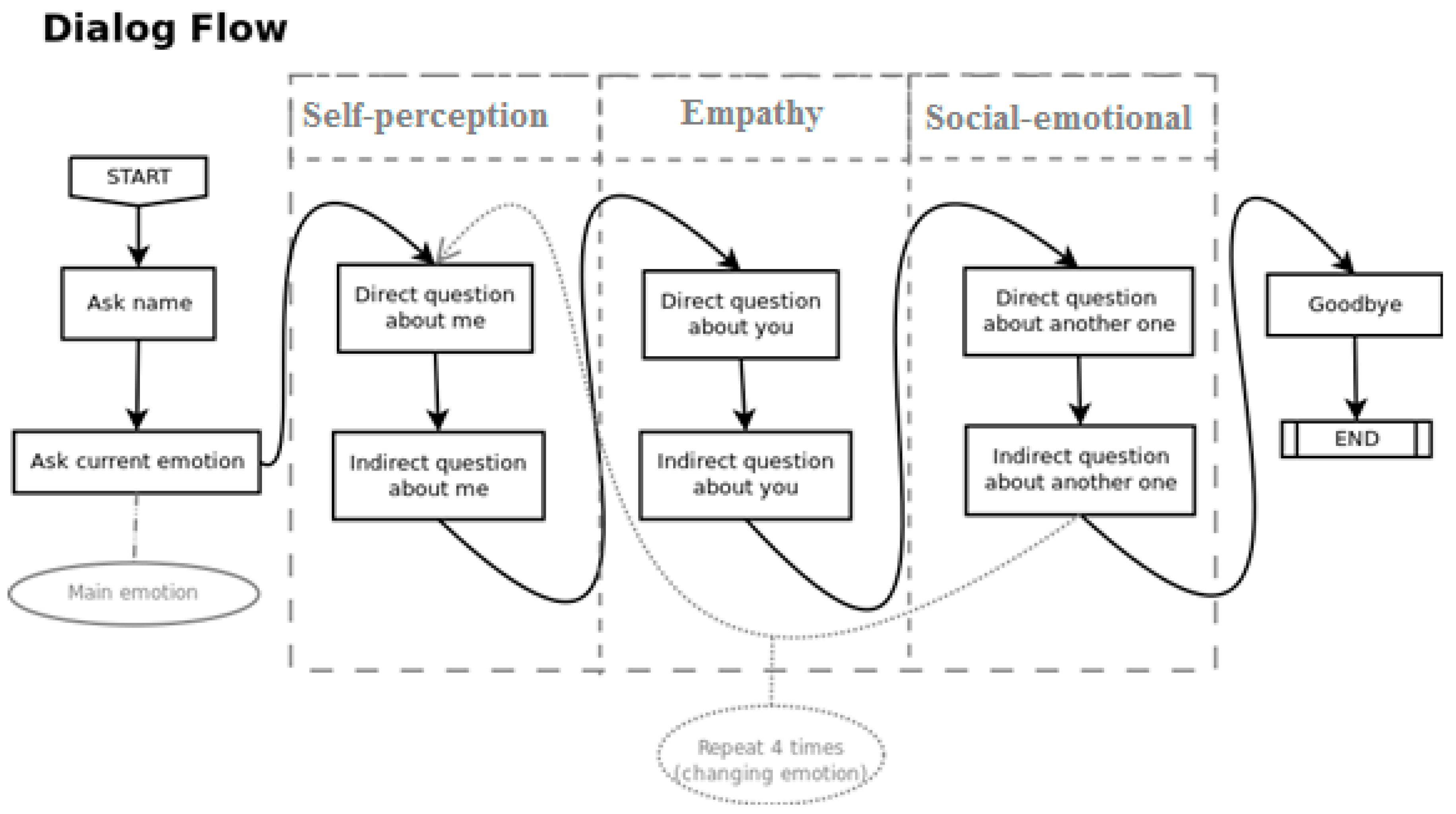
Then, MAmIoTie began the interaction by asking the participant for their name. This time spent in silence before the start of the dialogue served to determine a sound threshold (described in
Section 3.2) to better identify the level of noise when the participant was talking. It also helped to establish familiarity between the participant and MAmIoTie. After the name had been given, MAmIoTie asked a question to determine the participant’s emotional state. Depending on which emotion was detected, the dialogue started accordingly, and then went through the rest of the questions, as seen previously in
Figure 4, in
Section 3.2.
The data collected during this phase of the evaluation were inserted into the generated CSV (comma separated values). These data were the dialogue sentences that were spoken by MAmIoTie, the transcription and translation (for metric purposes) of the participant’s answer, and the expected and detected emotion to each of those questions. We also recorded if the question asked was direct or indirect, as well as if it was related with self-perception, empathy, or social-communication skills.
The results for this part of the experiment measured the performance on a technical level. There was a total of 18 participants with valid results, and 2 of the participants were discarded, as their results were not recorded adequately (more details in
Section 5). With the recorded data, we measured accuracy, word error rate [
37], and emotion recognition. We started by looking at the word error rate (WER), which is a common metric used to measure the performance of speech recognition or machine translation. This formula can be seen below in Equation (1).
where
N is the total number of the transcribed words;
Substitutions are the words substituted from the original sentence;
Insertions are any words inserted that were not in the original sentence;
Eliminations deals with words not present in the original sentence.
We later also employed a similar metric to measure the accuracy for the translation of the transcribed text. The result from this calculation gave a result where, the closer it was to zero, the better that was, as it implied a low number of substitutions, insertions, and eliminations. These two aspects were critical for the later emotional recognition, as IBM Watson’s tone analyzer service works only in English. We first analyzed the results for the speech-to-text WER, and then analyzed it for the translation service results.
With a total of transcribed words of N = 770, we observed a WER of 0.24675. Looking more closely at
Table 1, we observe that the main issue that contributed to the value of the WER were the substitutions of words that could be slightly misunderstood, or because the participant did not speak clearly or loudly enough.
As for the WER value for the translation aspect, we obtained N = 756, with a value of 0.17596, where the results per user as well as the total can be seen in
Table 2. An observation on this value was the fact that translating one or two words may change the meaning of the entire sentence. A fairly common occurrence was the translation of “because” for “why”, which then affected the sentence to be understood as a question. The implications of this are discussed in the next section.
As we can see from both tables, substitutions were the biggest contributor to mistakes further on in the process. During the translation, we also see that there were several eliminations. However, this aspect was slightly more subjective, as the comparison was done with the translation of the transcribed text a native would have done. This meant that there could have been ways to say the same thing, with less words.
At the same time that we obtained the transcriptions and translations for what the participant was saying, we also recorded the results of what tone those words had, according to IBM Watson’s tone analyzer service. We obtained this from the end-user interactions, from which we had an 87.63% accuracy rate between recognized and expected emotion. This meant that if we expected a negative emotion, and a negative emotion was detected, we counted that as accurate. It is important to distinguish how many times the system was not able to obtain an emotion from the captured text. This number was 67 “none” of the total 186 detected emotions, which implied 36% of the total emotions recognized. This information can be more easily seen in
Table 3 below. If we were to disregard the number of “none” from the calculation of accuracy percentage, we would obtain an accuracy of 80.67%.
As we discussed in the previous section, the data the tone analyzer received as input went through both the speech-to-text service, as well as the translator service, since it did not work with Spanish input. As previously seen, speech-to-text had a few transcription problems, with the main issue being the substitution of words that sounded similar enough, but had very different meanings. With those issues going uncorrected and being fed into the Translator service, other issues were added, such as “because” being translated for “why”, which ended up being understood as a question. All of this meant that those sentences lost part of their meaning, so they were either misunderstood, and therefore the emotion was mislabeled, or they were not labeled at all. One plain example is where participants answered to a question with “triste” (“sad” in English), which speech-to-text transcribed to “viste” (“saw” or “dress” in English), and then translated to “dress” (one of the options). Thus, there was a similar effect to the very commonly played “telephone game”, where a person whispers a word, and it gets changed, so by the time it reaches the last person, it rarely ever resembles what was initially said.
However, we have observed the effects of this to the overall recognition were small, as can be seen in
Table 4 below.
As can be seen, there was a slight increase of mismatched emotions, lowering the accuracy rate by less than 3%. However, there were also a few less instances of “none”, implying there were some of sentences that were understood better without the loss of meaning from the translator; however, the detected emotion did not match what was expected. Having done this, we compiled the instances where the expected and detected emotions were matched. In the cases where they did not match, we could also see which emotion it detected. This left us with a total of 71 emotions that matched perfectly, 48 in which there was emotion confusion, and 67 instances of no recognized emotion. Out of those 48 instances of emotion confusion, 23 of those were classed as mismatched emotions (joy confused with sadness, any of the negative emotions confused with joy, and sadness or anger confused with fear), leaving 25 to be classed as matching emotions. These results can be seen in
Table 5 below, where the left column shows the expected emotions, and the top row, the detected emotions.
As stated above, we can see that the main problem was mixing any emotion for no emotion at all. There were two other standout data, which were the confusion of anger with sadness, and fear with sadness. In truth, we did not consider the “confusion” of anger with sadness a problem, as they were on a similar spectrum. We also acknowledge that different people can feel differently about certain situations, but within a range. For the questions posed in this experiment, it seemed to stem from a specific one, where the child was asked how they would feel if they were to be grounded, and we set “anger” as the expected emotion. However, many of the participants replied with answers that were then read as “sadness” by the tone analyzer, which was still a very valid feeling for such a scenario. Fear being confused with sadness came from a similar question, where MAmIoTie asked how the participant thinks he feels when lost in a forest.
Initially, the latency of the overall system was, on average, 5.49 s. This time was measured from the moment MAmIoTie spoke a sentence, until it asked the next one, going through the full cycle of interaction that can be seen in
Figure 3. In subsequent tests and after reimplementation of the system, with an alternative design in the use of cognitive services, latency was reduced to less than 1.5 s; still somewhat high, but sufficient for fluent conversation.
4.2. Experiment 2: Panel of Experts
For the second part the experiment, applicability was the aspect that was measured, which gave us an understanding of how those issues could impact the system being applied in a therapy session. For this, the panel engaged in a focus group after testing MAmIoTie. This was followed by filling out a questionnaire based on the system usability scale model [
38]. Most of the questions were the same as in the original model, where the only modification was to ask about MAmIoTie. The question which was more heavily modified was question 1, which had to be adapted to the context of this experiment. The adapted SUS (Systems Usability Scale) questionnaire can be seen in
Appendix A (
Figure A1). The overall session gave us results that could be explored both quantitatively (SUS-adapted questionnaire) and qualitatively (comments and discussions after group session).
The panel of experts was formed by five professionals in the areas of psychology and technology. In the panel, there were two psychologists who work with children and adolescents, both neurotypical and non-neurotypical. There were also two researchers familiar with human–computer interaction applied to health. Finally, there was a researcher familiar with human–computer interaction, who has also undergone the study of a B.Sc. in Psychology. The importance of having psychologists in the panel came from the fact that they would be the participants who would decide whether to integrate this system into their sessions. They were also the participants who could tell us issues with our system that researchers might not have insight to, as their field of work is interacting with the other set of participants who would directly use the system.
The protocol for this experiment started very similarly to Experiment 1 (
Section 4.1), where the panel was asked to interact with MAmIoTie. Specifically, all participants of this experiment were asked to get together at the same time and place, and choose one participant to interact with MAmIoTie, while the rest observed. This was so that the panel could gain an understanding of how children and adolescents in therapy sessions would interact with MAmIoTie.
After doing this, the panel engaged in a focus group, where they all discussed together in a group setting any issues that our current model may have had, as well as the potential of the system to be used for the intended purpose of supporting the diagnosis and treatment of mood disorders. Along with the group session, which was recorded for later analysis, they also filled out questionnaires that were adapted from the system usability scale [
35], to fit our experiment and system.
The results from the SUS model (which we have called MUS for the MAmIoTie usability scale, and can be seen in
Appendix A) were an average of 77.5 points. According to a study [
39], a score over 68 points was considered to be above average, which implied our system was well scored and had good reception. The answers were towards either extremes of the scale, making it easy to identify any outliers, or any strong opinions in general. From observing the results of the questionnaires, the impressions were in agreement with the positive statements (i.e., communicating with MAmIoTie is simple), and disagreed with the more negative statements (i.e., communicating with MAmIoTie is complicated). One of the experts (researcher) disagreed with the statement “MAmIoTie has a fluent conversation”, stating that it could be improved with a knowledge base gained from conversational experience. Another expert (psychologist) answered to a lot of the questions with a “neither agree nor disagree” approach, and provided the comment that it would be very positive to employ in a therapy session, with some improvements.
Some of those improvements were discussed during the group session of the evaluation. They agreed on the applicability of MAmIoTie for the goals we had thought, and provided some interesting insights. They agreed that a more personalized approach would be important to implement, to make it seem more like a conversation, and less like it was just going through a series of questions, i.e., having a more fluent conversation, in terms of having those questions be more related to each other, and therefore having a more natural flow to the conversation itself. There were also comments on the technical aspects of MAmIoTie, such as the time spent between asking one question and the next. The panel seemed to think it could have potentially positive applications, particularly to exercise patience, and to have a “think before you speak” example. Some of the specific comments made by the panel during the session are listed below, divided into technical or application comments, concerns, or insights.
Technical comments:
Connect ideas, have more connection options in the dialogue. This would make dialogues more dynamic;
Parameterize the dialogue options, meaning to make the dialogue options general, and have the possibility to specify for different cases;
Have more content, and extract content from conversations to include in a knowledge base;
An LED light to indicate when it is listening, and when it is thinking, would be very useful.
Application comments:
Fit itself to age profiles, as children are not as inclined to follow up questions with other questions for the patient. It could develop patience, as they have to wait for MAmIoTie to answer;
Working with a toy is different, because children do not feel like it would tell their parents;
Children do not ask as much as adults, and do not tie in conversations as much;
It would be good for children, as dialogue with them is much more straightforward.
4.3. Experiment 3: Professional Evaluation
In order to determine the validity of this proposed solution for the professionals, we performed an evaluation with several professionals, of different backgrounds. The professionals were sent an online form which contained demonstration videos of the use of MAmIoTie, as well as an explanation of its goal. After seeing these videos, they could fill out a form with questions. This form had some of the elements of the SUS scale used in the previous experiment, but was modified to obtain more information from the professionals filling it out. Apart from the SUS-based questionnaire, they also filled out their profession and job title, as well as their opinion on MAmIoTie, and which mood disorders they thought it could be applied to. This form was anonymous, and no personal information was collected.
There was a total of 23 responses, which included therapists, psychologists, speech language pathologists, and teachers, from specialized associations in both Spain and UK. This variety of responses gave us a better look at what different professionals felt they needed from a sensorized toy, from different perspectives, giving us a more complete picture of both the good points of the toy, as well as the improvements that were needed.
After watching an example video of use of the toy, as well as two explanatory videos about MAmIoTie, its goal, and its details, they filled out a questionnaire, which resulted in an average score of 64.35 points. As a matter of fact, the first question, which was “I think I could use MAmIoTie frequently in therapy”, obtained the highest average score. This was particularly good, as it was the main aim of this proposal.
The SUS determined that a score above 68 indicated a good usability, and therefore, this solution came close to that score, but did not quite reach it. In order to better evaluate possible reasons for this score, we looked more closely at the responses from the test.
One of the observations we could make was to see if there were any differences in scores according to the profession. As can be seen in
Table 6, there were notable differences in the average score depending on the profession, with teachers giving a score of 34, followed by speech language pathologists (SLP) of 60, psychologists of 69, and finally therapists of 74. This meant that the participants who were more closely related to treating mood disorders (psychologists and therapists) gave it the highest scores (69 and 74, respectively). Those scores were also above the 68 mark that the SUS determined to be the indicator of a usable system.
In order to better understand the scores, we also obtained the average, mode, and standard deviation for each one of the answers to the questions of the tests.
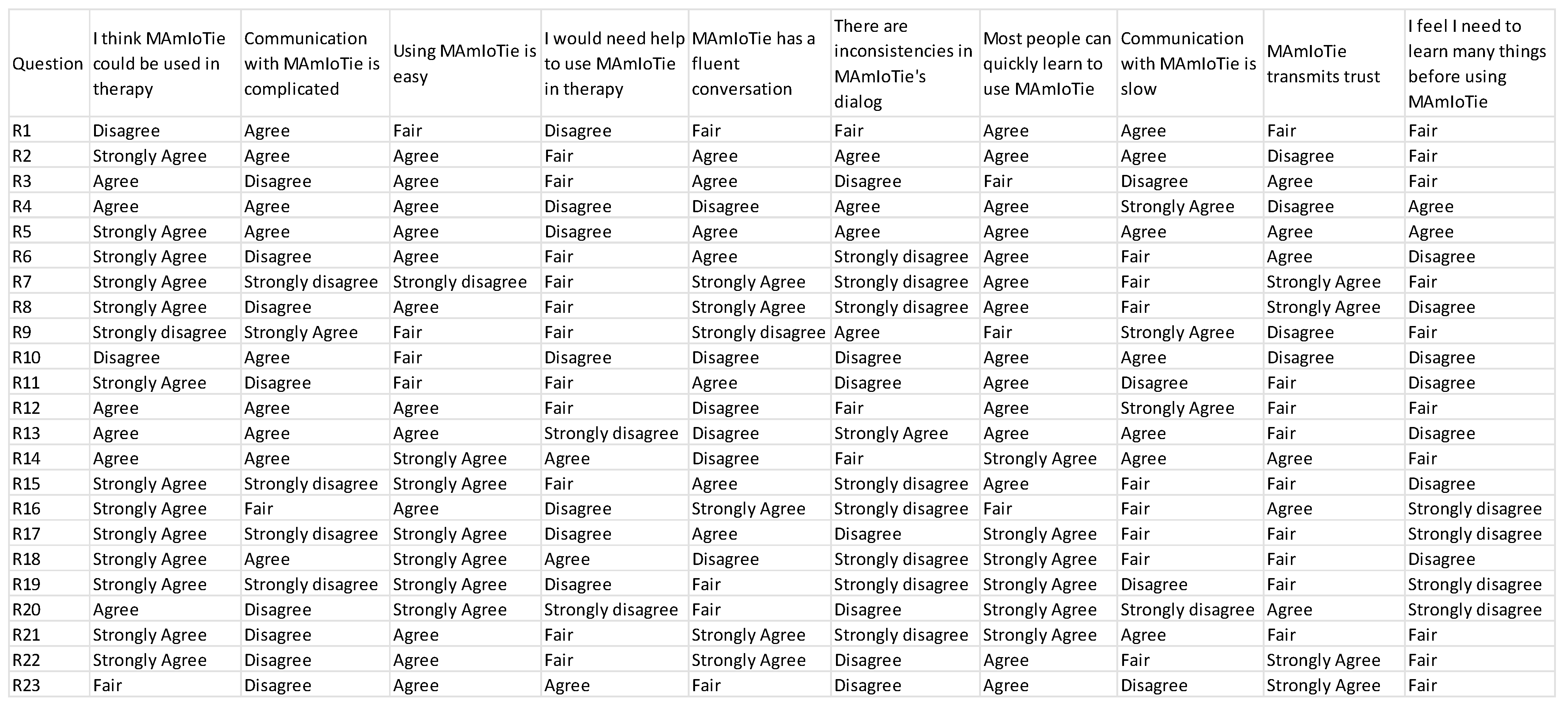
As can be seen in
Table 7 below, there are several conclusions that can be extracted. Firstly, we observed that Q2, pertaining the complexity of the communication with MAmIoTie, had the worst results. The average score was closer to 3 (2.7), whereas the mode was actually 4. However, it can be seen that there was a wide range of results, due to the standard deviation also being the highest in any of the questions. This would imply that some people disagreed on the complexity, but others agreed more. On the other side of this, we had several questions (Q1, Q3, Q5, Q6, and Q7) with scores that were closer to what would be considered positive results (close to 2 for Q6, and close to 5 for Q1, Q3, Q5, and Q7) according to the scale used in the questionnaire. The specific answers of each participant to this questionnaire can be seen in
Appendix B, Questionnaire results (
Figure A2).
On the one hand, Q3, Q5, and Q7 were questions regarding the use of MAmIoTie, fluency of communication, and learning speed. The other question (Q6) dealt with inconsistencies in MAmIoTie’s dialogue, which also happened to have the lowest average score (2.26), with a mode of 1, and a standard deviation of 1.22. While the standard deviation was high, this indicated that some experts disagreed, and they answered with a high score, but not a high enough number that the average and mode would shift to presenting this as an issue in MAmIoTie.
The highest average score was for Q1 (4.2), with a mode of 5, and a standard deviation of 1.1. From this, we can infer that many experts agreed that MAmIoTie was a solution that could be used in therapy, which was the main goal of this proposal and evaluation.
Given this last answer to Q1, the question that arose was for what cases of mood disorders would professionals use this sensorized toy with. This was the reason why we added a multiple-choice question as part of the questionnaire. This asked the professionals for which of the disorders would they use MAmIoTie, giving several options, and adding a blank answer, in case they could think of a case we had not contemplated.
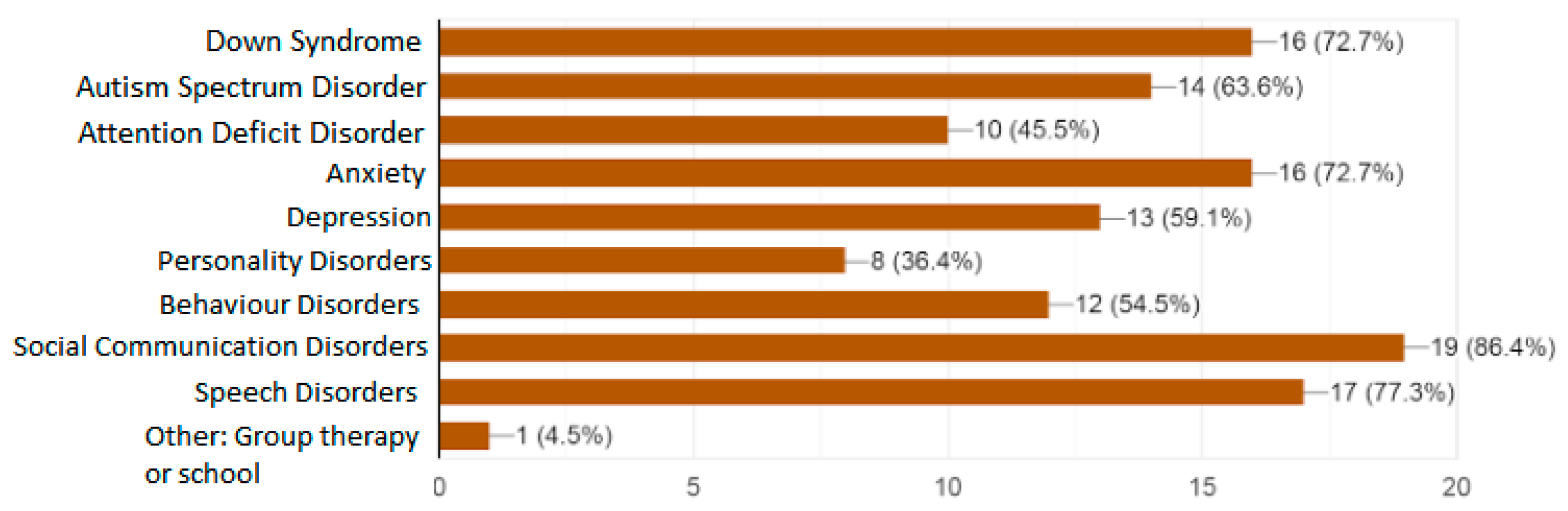
These answers were recorded and displayed as a graph, which can be seen in
Figure 5.
As can be seen, the most selected option was social communication disorders, followed closely by speech disorders, and a tie between Down syndrome and anxiety. On the lower end, some professionals selected personality disorders, attention deficit disorders, behavior disorder, and depression. One person selected “Other”, and specified a possible use of MAmIoTie in group therapy, or use in schools, to teach about empathy. From this, we can gather that not only would several professionals use this toy, but that there are several different cases and options to use MAmIoTie, including some we had not initially considered (such as group therapy).
Lastly, just as in Experiment 2 with the panel, we included a long-answer question, where the professionals were asked to add anything they thought was needed, whether it be feedback from the existing proposed solution, improvements, or any other comments. In total, there were 13 responses, with several of those responses having common concerns.
The most typical one was in regard to the voice of MAmIoTie, which professionals said was “not friendly enough”, “too deep”, “should be more friendly”, etc. This was also a comment that was heard from the children from Experiment 1, and which led to a first modification, though clearly it was still deemed as “too deep”.
Another recurring comment was that of the communication, where the professionals pointed out that it should be “more fluid and quick”, while they also understood that it was likely due to having to analyze the answers of the patient. Other comments said the questions and answers of MAmIoTie were repetitive, and could lead to comprehension problems. Finally, some of the other comments were about specific aspects of MAmIoTie, such as how to change the dialogue, as well as words of congratulations. All these comments can be seen in
Table 8 below.

 ,
, 









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}