Multi-Class Imbalance in Text Classification: A Feature Engineering Approach to Detect Cyberbullying in Twitter



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
Significance of Research
2. Background—Features Engineering and Machine Learning
2.1. Feature Engineering
2.1.1. Network-Based Features
2.1.2. Activity Features
2.1.3. User Features
2.1.4. Content-Based Features
2.1.5. Personality Features
2.1.6. Master Feature (PMI-SO)
2.1.7. Features Summary
2.2. Machine Learning
3. Material and Methods
3.1. Data Input Step
3.1.1. Data Accessibility, Collection, and Annotation
3.1.2. Manual Data Annotation
3.2. Pre-Processing Step
3.3. Feature Extraction Step
3.4. Feature Generation Step
3.4.1. Pointwise Mutual Information
3.5. Feature Engineering
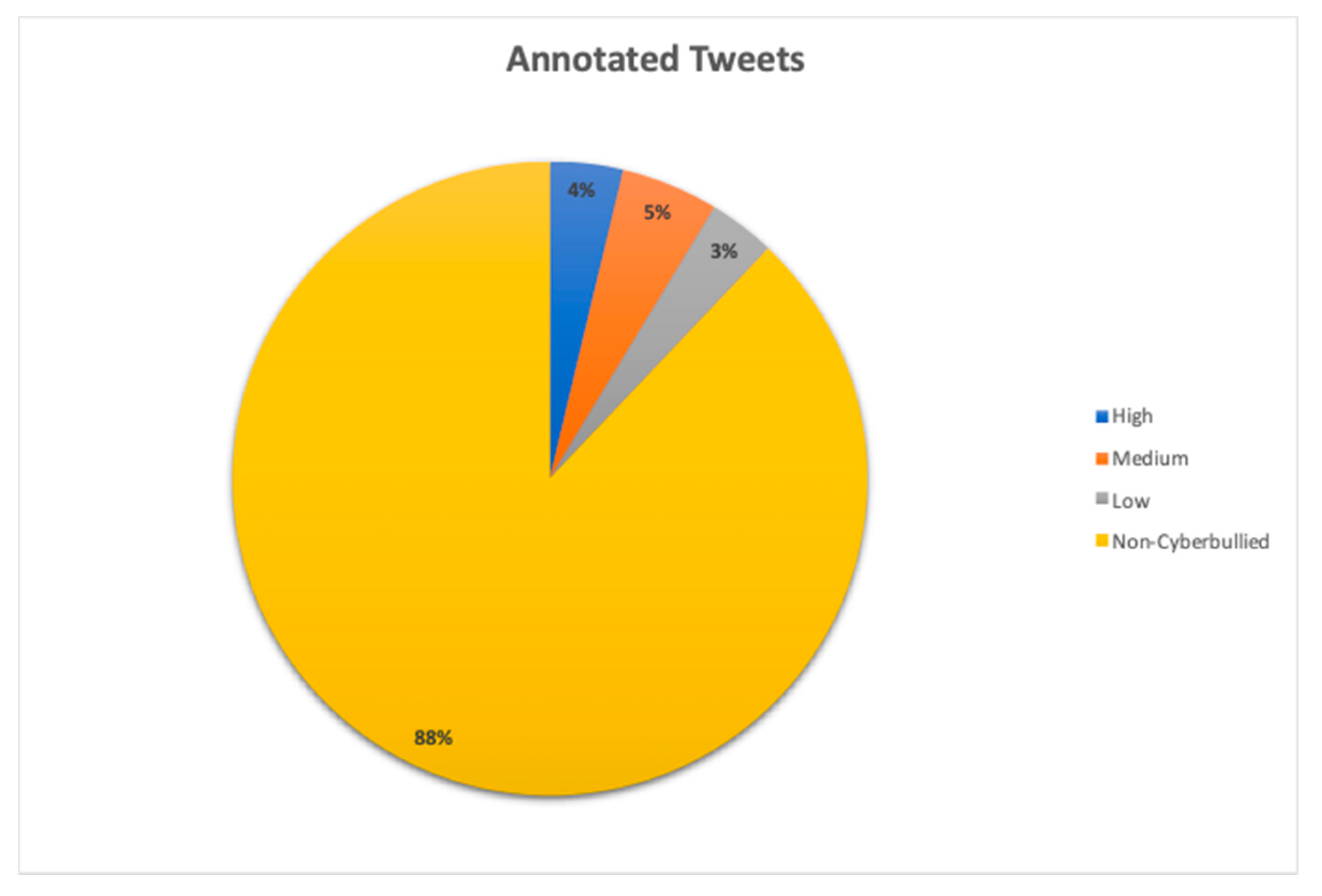
3.6. Class Imbalance Distribution
3.7. Feature Analysis
3.8. Machine Learning Algorithms
3.9. Performance Evaluation
4. Results and Discussion
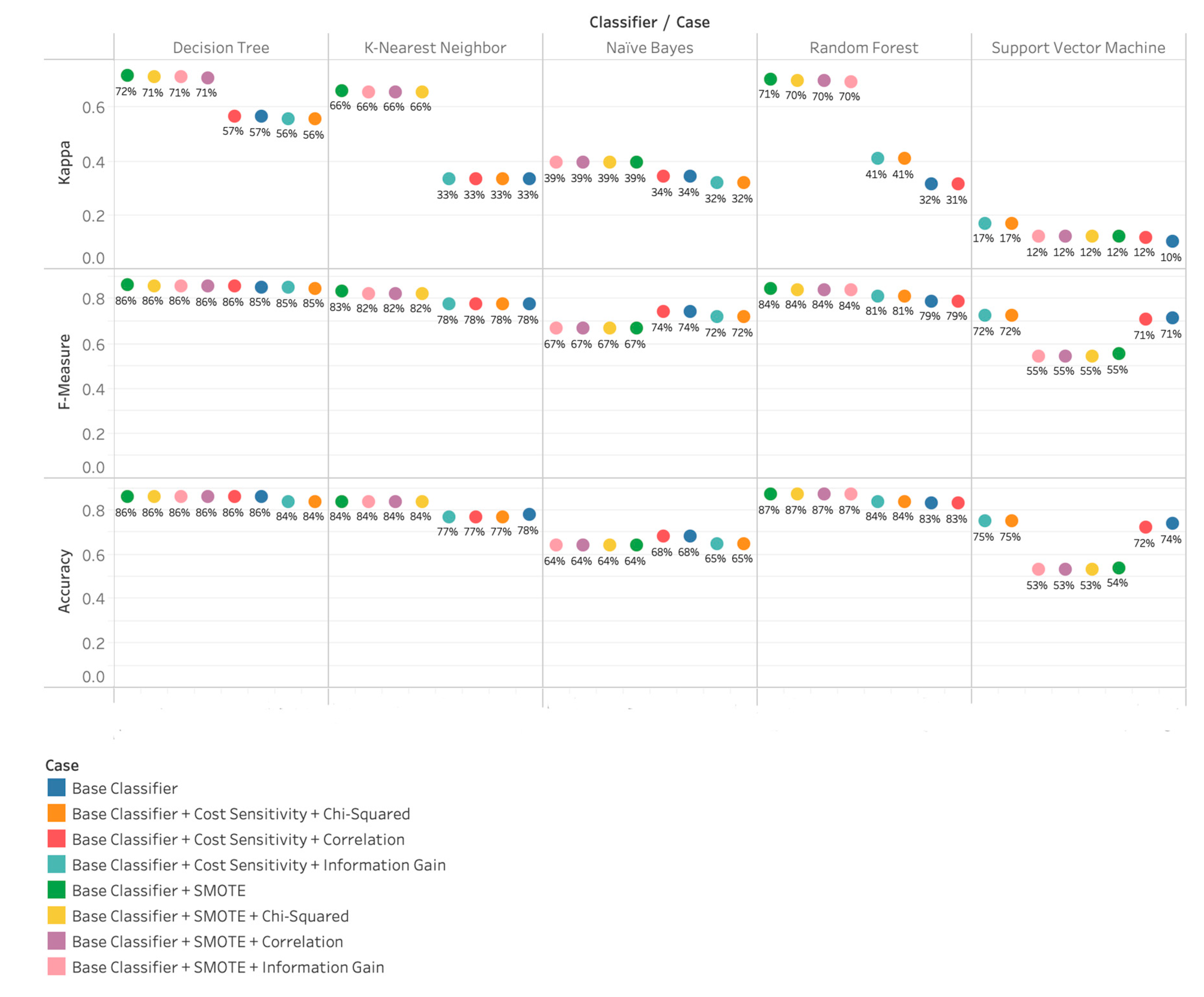
4.1. Results Achieved with Bag of Words (BoW) (Baseline 1)
4.2. Results Achieved with Word to Vector (Baseline 2)
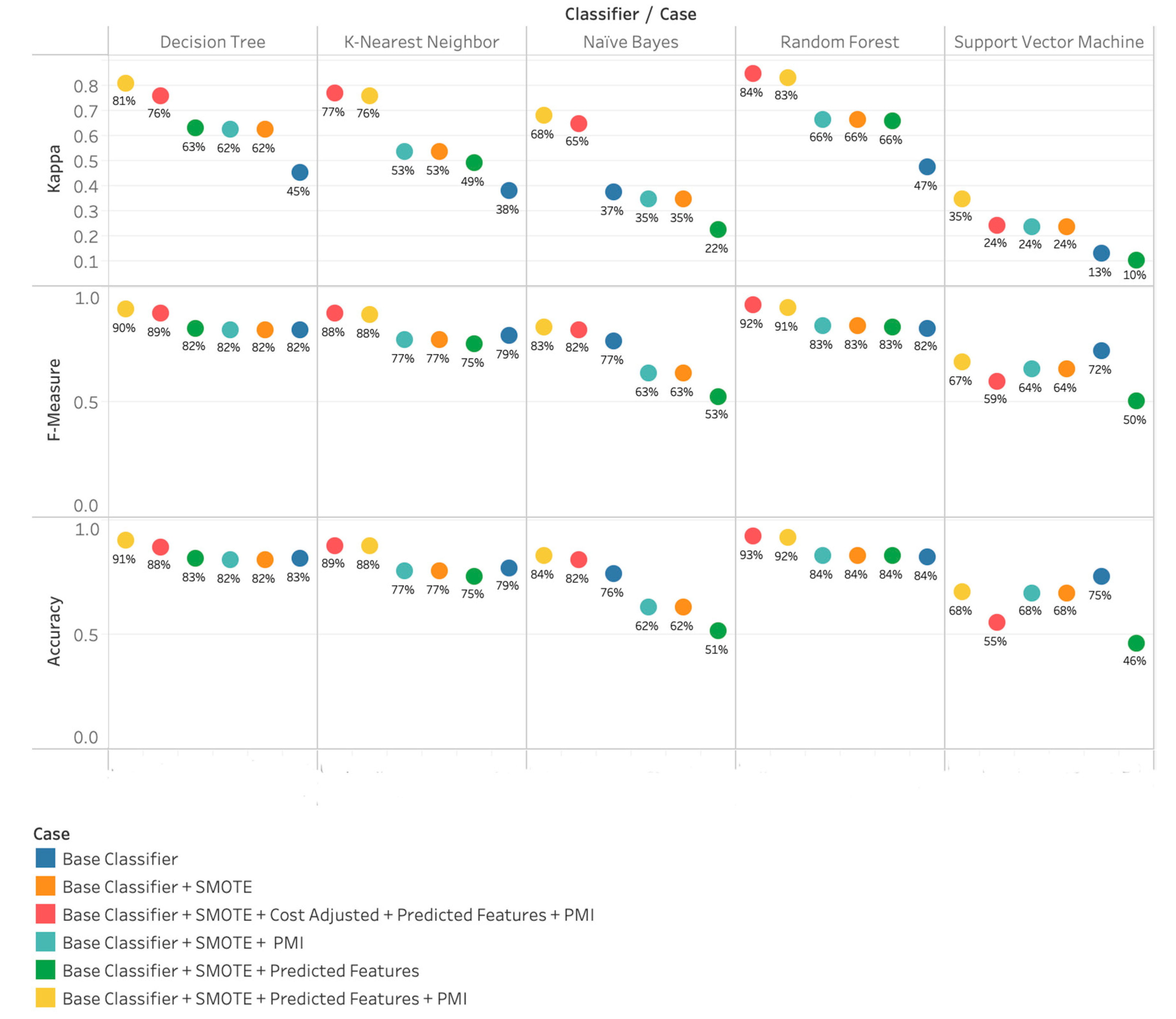
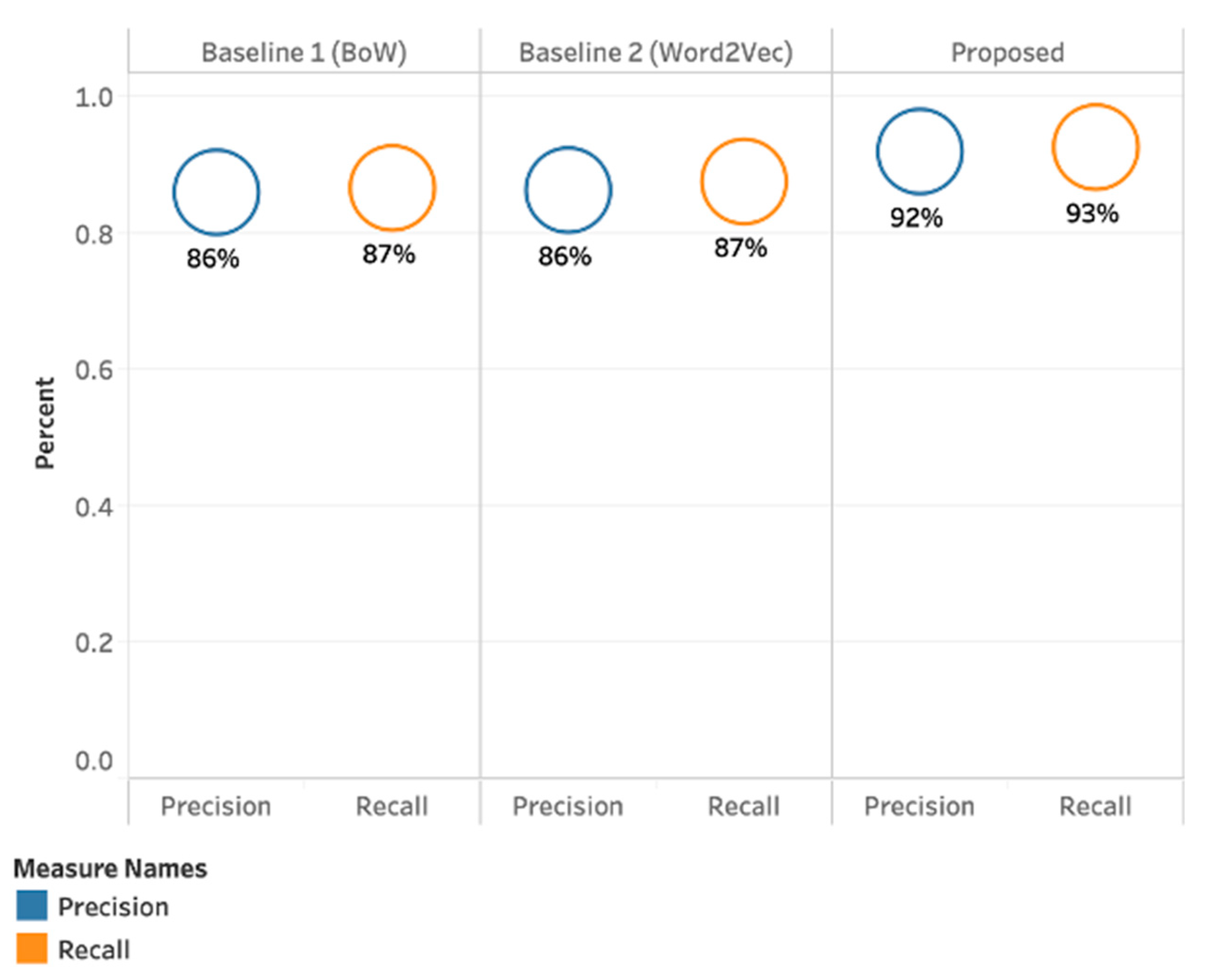
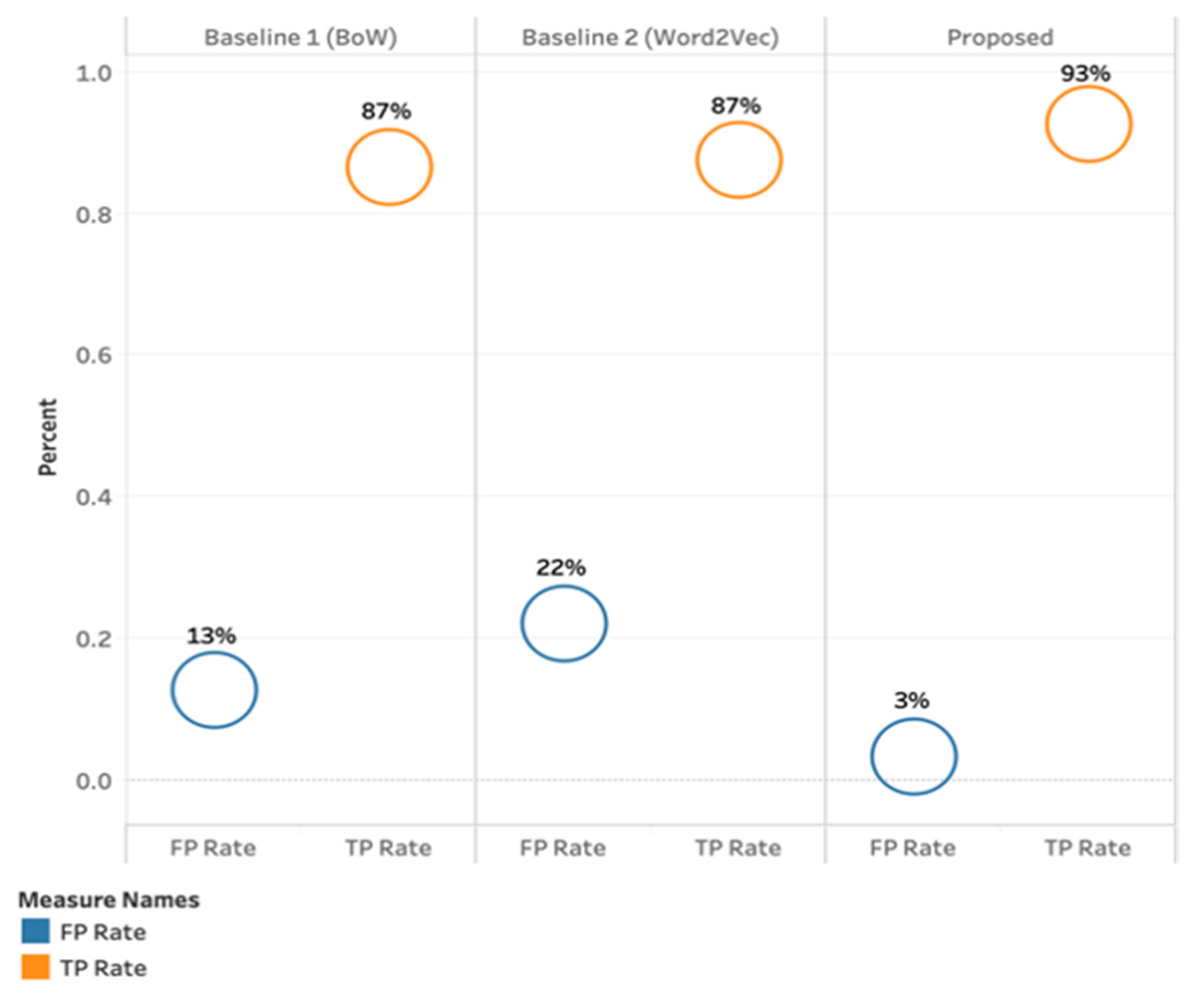
4.3. Results Achieved with our Proposed Method (PMI-SO)
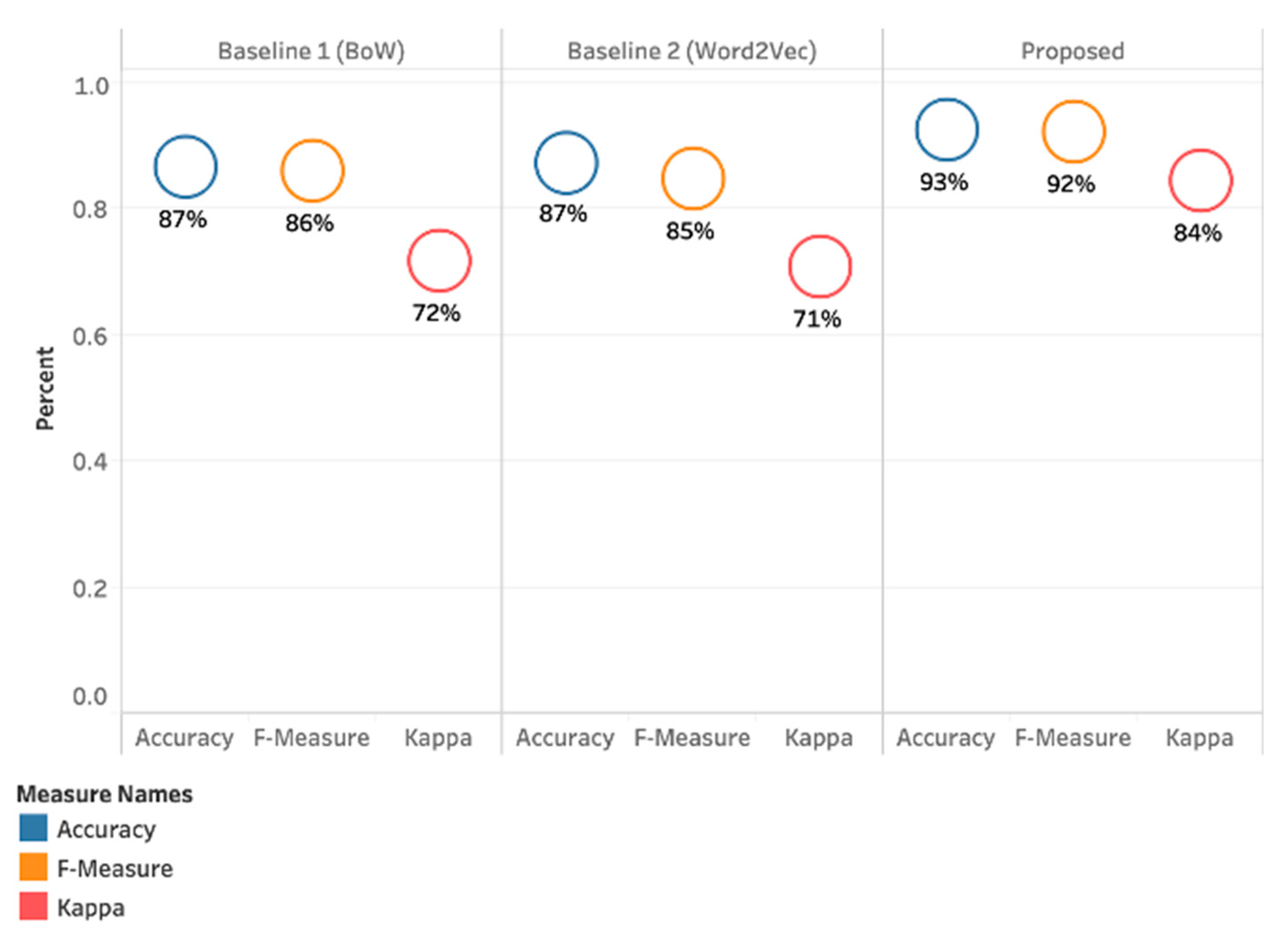
4.4. Results Summary
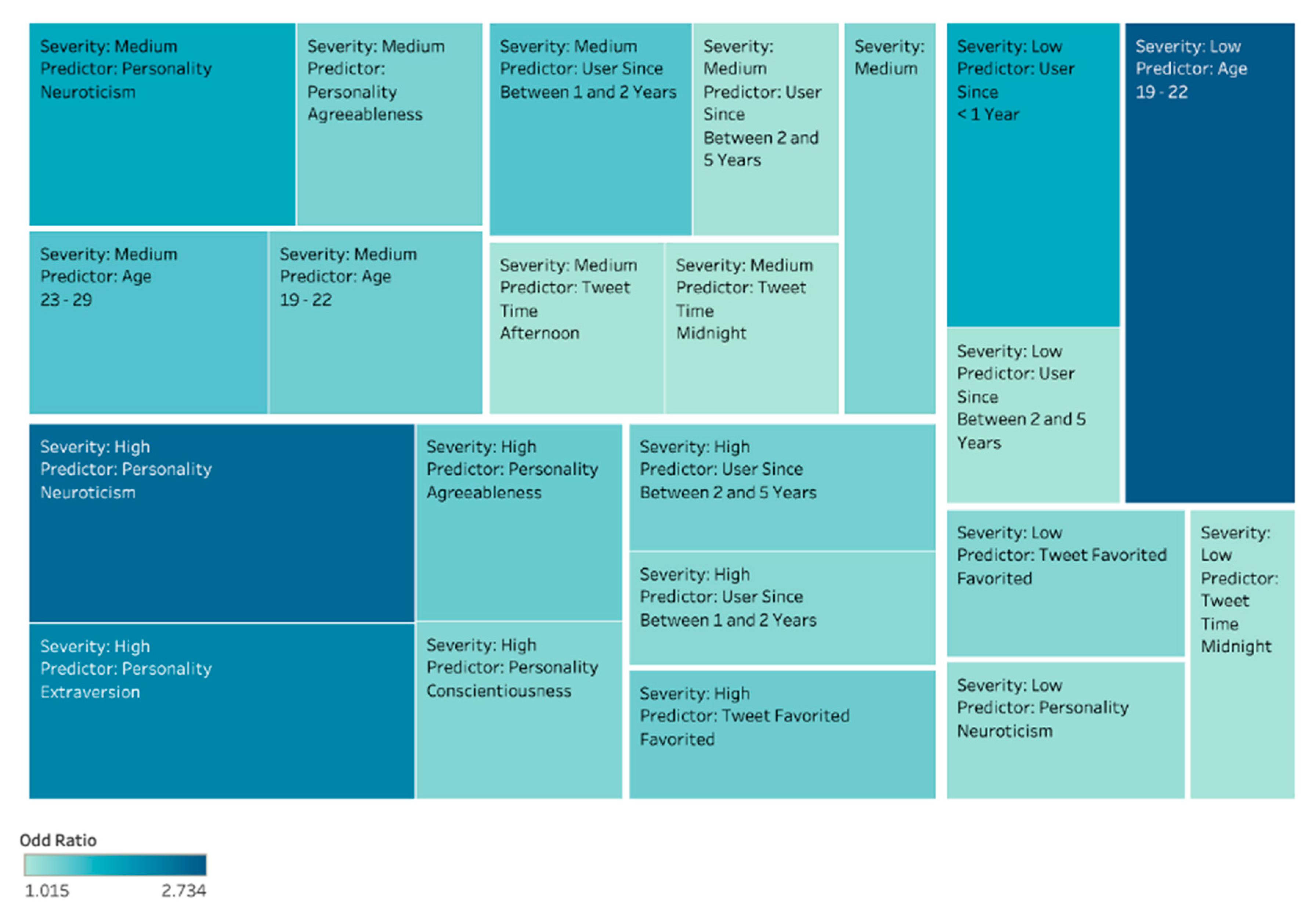
4.5. In-Depth Analysis of Results
- (a)
- What type of personality traits falls under different severity levels (Low, Medium, or High)?
- (b)
- What is their gender?
- (c)
- What age group do they belong to?
- (d)
- Since when the user has been using Twitter?
- (e)
- What time do they tweet post?
- (f)
- What makes their tweet cyberbullied?
4.5.1. Low-Level Cyberbullying Severity
4.5.2. Medium Cyberbullying Severity
4.5.3. High Cyberbullying Severity
5. Contribution and Limitations
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Huang, Q.; Singh, V.K.; Atrey, P.K. Cyber Bullying Detection Using Social and Textual Analysis. In Proceedings of the 3rd International Workshop on Socially-Aware Multimedia, Orlando, FL, USA, 7 November 2014; ACM: New York, NY, USA, 2014; pp. 3–6. [Google Scholar]
- Chatzakou, D.; Vakali, A.; Kafetsios, K. Detecting variation of emotions in online activities. Expert Syst. Appl. 2017, 89, 318–332. [Google Scholar] [CrossRef]
- Hoff, D.L.; Mitchell, S.N. Cyberbullying: Causes, effects, and remedies. J. Educ. Adm. 2009, 47, 652–665. [Google Scholar] [CrossRef]
- Patchin, J.W.; Hinduja, S. Cyberbullying and self-esteem. J. Sch. Health 2010, 80, 614–621, quiz 622–624. [Google Scholar] [CrossRef] [PubMed]
- Yao, M.; Chelmis, C.; Zois, D.-S. Cyberbullying detection on instagram with optimal online feature selection. In Proceedings of the 2018 IEEE/ACM International Conference on Advances in Social Networks Analysis and Mining, Barcelona, Spain, 28–31 August 2018; IEEE Press: Barcelona, Spain, 2018; pp. 401–408. [Google Scholar]
- Balakrishnan, V.; Khan, S.; Fernandez, T.; Arabnia, H.R. Cyberbullying detection on twitter using Big Five and Dark Triad features. Personal. Individ. Differ. 2019, 141, 252–257. [Google Scholar] [CrossRef]
- Galán-García, P.; de la Puerta, J.G.; Gómez, C.L.; Santos, I.; Bringas, P.G. Supervised machine learning for the detection of troll profiles in twitter social network: Application to a real case of cyberbullying. Log. J. Igpl. 2016, 24, 42–53. [Google Scholar] [CrossRef] [Green Version]
- Haidar, B.; Chamoun, M.; Serhrouchni, A. A Multilingual System for Cyberbullying Detection: Arabic Content Detection using Machine Learning. Adv. Sci. Technol. Eng. Syst. J. 2017, 2, 275–284. [Google Scholar] [CrossRef] [Green Version]
- Vyawahare, M.; Chatterjee, M. Taxonomy of Cyberbullying Detection and Prediction Techniques in Online Social Networks. In Data Communication and Networks; Jain, L.C., Tsihrintzis, G.A., Balas, V.E., Sharma, D.K., Eds.; Springer: Singapore, 2020; pp. 21–37. [Google Scholar]
- Domingos, P. A few useful things to know about machine learning. Commun. ACM 2012, 55, 78. [Google Scholar] [CrossRef] [Green Version]
- Myers, C.-A.; Cowie, H. Cyberbullying across the Lifespan of Education: Issues and Interventions from School to University. Int. J. Environ. Res. Public Health 2019, 16, 1217. [Google Scholar] [CrossRef] [Green Version]
- Modeling Detect. Textual Cyberbullying. Available online: https://web.media.mit.edu/~lieber/Publications/Cyberbullying-Barcelona.pdf (accessed on 15 November 2020).
- Isa, S.M.; Ashianti, L. Cyberbullying classification using text mining. In Proceedings of the 2017 1st International Conference on Informatics and Computational Sciences (ICICoS), Semarang City, Indonesia, 15–16 November 2017; 2017; pp. 241–246. [Google Scholar]
- Hosseinmardi, H.; Mattson, S.A.; Rafiq, R.I.; Han, R.; Lv, Q.; Mishra, S. Detection of cyberbullying incidents on the instagram social network. arXiv preprint 2015, arXiv:1503.03909. [Google Scholar]
- Sterner, G.; Felmlee, D. The social networks of cyberbullying on Twitter. Int. J. Technoethics 2017, 8, 1–15. [Google Scholar] [CrossRef]
- Al-garadi, M.A.; Varathan, K.D.; Ravana, S.D. Cybercrime detection in online communications: The experimental case of cyberbullying detection in the Twitter network. Comput. Hum. Behav. 2016, 63, 433–443. [Google Scholar] [CrossRef]
- Chatzakou, D.; Kourtellis, N.; Blackburn, J.; De Cristofaro, E.; Stringhini, G.; Vakali, A. Mean Birds: Detecting Aggression and Bullying on Twitter. In Proceedings of the Proceedings of the 2017 ACM on Web Science Conference, Troy, NY, USA., 25–28 June 2017; Association for Computing Machinery: Troy, NY, USA, 2017; pp. 13–22. [Google Scholar]
- Saravanaraj, A.; Sheeba, J.I.; Devaneyan, S.P. Automatic detection of cyberbullying from twitter. Int. J. Comput. Sci. Inf. Technol. 2016, 26–31. [Google Scholar] [CrossRef]
- Dadvar, M.; Trieschnigg, D.; Ordelman, R.; de Jong, F. Improving Cyberbullying Detection with User Context. In Advances in Information Retrieval; Serdyukov, P., Braslavski, P., Kuznetsov, S.O., Kamps, J., Rüger, S., Agichtein, E., Segalovich, I., Yilmaz, E., Eds.; Springer: Berlin/Heidelberg, Germany, 2013; pp. 693–696. [Google Scholar]
- Dadvar, M.; de Jong, F.M.G.; Ordelman, R.J.F.; Trieschnigg, R.B. Improved cyberbullying detection using gender information. In Proceedings of the Twelfth Dutch-Belgian Information Retrieval Workshop (DIR 2012), Ghent, Belgium, 24 February 2012; Ghent University: Ghent, Belgium, 2012; pp. 23–25. [Google Scholar]
- Salawu, S.; He, Y.; Lumsden, J. Approaches to Automated Detection of Cyberbullying: A Survey. IEEE Trans. Affect. Comput. 2018, 1-1. [Google Scholar] [CrossRef] [Green Version]
- Navarro, J.N.; Jasinski, J.L. Going Cyber: Using Routine Activities Theory to Predict Cyberbullying Experiences. Sociol. Spectr. 2012, 32, 81–94. [Google Scholar] [CrossRef]
- Galán-García, P.; de la Puerta, J.G.; Gómez, C.L.; Santos, I.; Bringas, P.G. Supervised Machine Learning for the Detection of Troll Profiles in Twitter Social Network: Application to a Real Case of Cyberbullying. In Proceedings of the International Joint Conference SOCO’13-CISIS’13-ICEUTE’13, Salamanca, Spain, 11–13 September 2013; Herrero, Á., Baruque, B., Klett, F., Abraham, A., Snášel, V., de Carvalho, A.C.P.L.F., Bringas, P.G., Zelinka, I., Quintián, H., Corchado, E., Eds.; Springer International Publishing: Berlin/Heidelberg, Germany, 2014; pp. 419–428. [Google Scholar]
- Rosa, H.; Pereira, N.; Ribeiro, R.; Ferreira, P.C.; Carvalho, J.P.; Oliveira, S.; Coheur, L.; Paulino, P.; Veiga Simão, A.M.; Trancoso, I. Automatic cyberbullying detection: A systematic review. Comput. Hum. Behav. 2019, 93, 333–345. [Google Scholar] [CrossRef]
- Peersman, C.; Daelemans, W.; Van Vaerenbergh, L. Predicting Age and Gender in Online Social Networks. In Proceedings of the 3rd International Workshop on Search and Mining User-Generated Contents, Glasgow, UK, 28 October 2011; ACM: New York, NY, USA, 2011; pp. 37–44. [Google Scholar]
- Hosseini, M.; Tammimy, Z. Recognizing users gender in social media using linguistic features. Comput. Hum. Behav. 2016, 56, 192–197. [Google Scholar] [CrossRef]
- Van Royen, K.; Poels, K.; Daelemans, W.; Vandebosch, H. Automatic monitoring of cyberbullying on social networking sites: From technological feasibility to desirability. Telemat. Inform. 2015, 32, 89–97. [Google Scholar] [CrossRef]
- O’Connor, S. A Study of Gender and Age Differences Concerning the Cyberbullying Experiences of Adolescents in Ireland; Dublin Business School: Dublin, Ireland, 2009. [Google Scholar]
- Zsila, Á.; Urbán, R.; Griffiths, M.D.; Demetrovics, Z. Gender Differences in the Association Between Cyberbullying Victimization and Perpetration: The Role of Anger Rumination and Traditional Bullying Experiences. Int. J. Ment. Health Addict. 2019, 17, 1252–1267. [Google Scholar] [CrossRef] [Green Version]
- Dilmaç, B. Psychological needs as a predictor of cyber bullying: A preliminary report on college students. Kuram Uygul. Egit. Bilimleri 2009, 9, 1307–1325. [Google Scholar]
- Sourander, A.; Klomek, A.B.; Ikonen, M.; Lindroos, J.; Luntamo, T.; Koskelainen, M.; Ristkari, T.; Helenius, H. Psychosocial Risk Factors Associated with Cyberbullying Among Adolescents: A Population-Based Study. Arch. Gen. Psychiatry 2010, 67, 720–728. [Google Scholar] [CrossRef] [Green Version]
- Kowalski, R.M.; Giumetti, G.W.; Schroeder, A.N.; Reese, H.H. Chapter 14 Cyber Bullying Among College Students: Evidence from Multiple Domains of College Life. Available online: https://www.emerald.com/insight/content/doi/10.1108/S2044-9968(2012)0000005016/full/html (accessed on 4 September 2019).
- Chung, C.; Pennebaker, J. The Psychological Functions of Function Words. In Social Communication; Frontiers of social psychology; Psychology Press: New York, NY, USA, 2007; pp. 343–359. [Google Scholar]
- Schwartz, H.A.; Eichstaedt, J.C.; Kern, M.L.; Dziurzynski, L.; Ramones, S.M.; Agrawal, M.; Shah, A.; Kosinski, M.; Stillwell, D.; Seligman, M.E.P.; et al. Personality, Gender, and Age in the Language of Social Media: The Open-Vocabulary Approach. PLoS ONE 2013, 8, e73791. [Google Scholar] [CrossRef] [PubMed]
- Slonje, R.; Smith, P.K. Cyberbullying: Another main type of bullying? Scand. J. Psychol. 2008, 49, 147–154. [Google Scholar] [CrossRef] [PubMed]
- Liu, W.; Ruths, D. What’s in a Name? Using First Names as Features for Gender Inference in Twitter. In Proceedings of the Analyzing Microtext: Papers from the 2013 AAAI Spring Symposium, Stanford, CA, USA, 25 March 2013; pp. 10–16. [Google Scholar]
- Carducci, G.; Rizzo, G.; Monti, D.; Palumbo, E.; Morisio, M. TwitPersonality: Computing Personality Traits from Tweets Using Word Embeddings and Supervised Learning. Information 2018, 9, 127. [Google Scholar] [CrossRef] [Green Version]
- Mahmud, J.; Zhou, M.X.; Megiddo, N.; Nichols, J.; Drews, C. Recommending targeted strangers from whom to solicit information on social media. In Proceedings of the 2013 international conference on Intelligent User Interfaces-IUI ’13, Santa Monica, CA, USA, 19–22 March 2013; ACM Press: Santa Monica, CA, USA, 2013; p. 37. [Google Scholar]
- Resett, S.; Gamez-Guadix, M. Traditional bullying and cyberbullying: Differences in emotional problems, and personality. Are cyberbullies more Machiavellians? J. Adolesc. 2017, 61, 113–116. [Google Scholar] [CrossRef]
- van Geel, M.; Goemans, A.; Toprak, F.; Vedder, P. Which personality traits are related to traditional bullying and cyberbullying? A study with the Big Five, Dark Triad and sadism. Personal. Individ. Differ. 2017, 106, 231–235. [Google Scholar] [CrossRef] [Green Version]
- Festl, R.; Quandt, T. Social Relations and Cyberbullying: The Influence of Individual and Structural Attributes on Victimization and Perpetration via the Internet. Hum Commun. Res. 2013, 39, 101–126. [Google Scholar] [CrossRef]
- Holtgraves, T. Text messaging, personality, and the social context. J. Res. Personal. 2011, 45, 92–99. [Google Scholar] [CrossRef]
- Kern, M.L.; Eichstaedt, J.C.; Schwartz, H.A.; Dziurzynski, L.; Ungar, L.H.; Stillwell, D.J.; Kosinski, M.; Ramones, S.M.; Seligman, M.E.P. The Online Social Self: An Open Vocabulary Approach to Personality. Assessment 2013. [Google Scholar] [CrossRef] [Green Version]
- Sumner, C.; Byers, A.; Boochever, R.; Park, G.J. Predicting Dark Triad Personality Traits from Twitter Usage and a Linguistic Analysis of Tweets. In Proceedings of the 2012 11th International Conference on Machine Learning and Applications, Boca Raton, FL, USA, 12–15 December 2012; pp. 386–393. [Google Scholar]
- Haidar, B.; Chamoun, M.; Yamout, F. Cyberbullying Detection: A Survey on Multilingual Techniques. In Proceedings of the 2016 European Modelling Symposium (EMS), Pisa, Italy, 28–30 November 2016; pp. 165–171. [Google Scholar]
- Reynolds, K.; Kontostathis, A.; Edwards, L. Using Machine Learning to Detect Cyberbullying. In Proceedings of the 2011 10th International Conference on Machine Learning and Applications and Workshops, Honolulu, HI, USA, 18–21 December 2011; Volume 2, pp. 241–244. [Google Scholar]
- Zhao, R.; Zhou, A.; Mao, K. Automatic Detection of Cyberbullying on Social Networks Based on Bullying Features. In Proceedings of the 17th International Conference on Distributed Computing and Networking, Singapore, 4–7 January 2016; ACM: New York, NY, USA, 2016; Volume 43, pp. 1–6. [Google Scholar]
- Morstatter, F.; Pfeffer, J.; Liu, H.; Carley, K.M. Is the Sample Good Enough? Comparing Data from Twitter’s Streaming API with Twitter’s Firehose. arXiv 2013, arXiv:1306.5204. [Google Scholar]
- Kwak, H.; Lee, C.; Park, H.; Moon, S. What is Twitter, a social network or a news media? In Proceedings of the 19th international Conference on World Wide Web-WWW ’10, Raleigh, NC, USA, 26–30 April 2010; ACM Press: Raleigh, NC, USA, 2010; p. 591. [Google Scholar]
- Bollen, J.; Mao, H.; Zeng, X.-J. Twitter mood predicts the stock market. J. Comput. Sci. 2011, 2, 1–8. [Google Scholar] [CrossRef] [Green Version]
- Eichstaedt, J.C.; Schwartz, H.A.; Kern, M.L.; Park, G.; Labarthe, D.R.; Merchant, R.M.; Jha, S.; Agrawal, M.; Dziurzynski, L.A.; Sap, M.; et al. Psychological Language on Twitter Predicts County-Level Heart Disease Mortality. Psychol. Sci. 2015, 26, 159–169. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Imran, M.; Mitra, P.; Castillo, C. Twitter as a Lifeline: Human-annotated Twitter Corpora for NLP of Crisis-related Messages. arXiv preprint 2016, arXiv:1605.05894. [Google Scholar]
- Java, A.; Song, X.; Finin, T.; Tseng, B. Why we twitter: Understanding microblogging usage and communities. In Proceedings of the 9th WebKDD and 1st SNA-KDD 2007 Workshop on Web Mining and Social Network Analysis-WebKDD/SNA-KDD ’07, San Jose, CA, USA, 2007, 12–15 August; ACM Press: San Jose, CA, USA, 2007; pp. 56–65. [Google Scholar]
- Preoţiuc-Pietro, D.; Eichstaedt, J.; Park, G.; Sap, M.; Smith, L.; Tobolsky, V.; Schwartz, H.A.; Ungar, L. The role of personality, age, and gender in tweeting about mental illness. In Proceedings of the 2nd Workshop on Computational Linguistics and Clinical Psychology: From Linguistic Signal to Clinical Reality, Denver, CO, USA, 5 June 2015; Association for Computational Linguistics: Denver, CO, USA, 2015; pp. 21–30. [Google Scholar]
- Sakaki, T.; Okazaki, M.; Matsuo, Y. Earthquake Shakes Twitter Users: Real-time Event Detection by Social Sensors. In Proceedings of the WWW2010, Raleigh, NC, USA, 26–30 April 2010; p. 10. [Google Scholar]
- Cheng, T.; Wicks, T. Event Detection using Twitter: A Spatio-Temporal Approach. PLoS ONE 2014, 9, e97807. [Google Scholar] [CrossRef] [PubMed]
- González-Bailón, S.; Wang, N.; Rivero, A.; Borge-Holthoefer, J.; Moreno, Y. Assessing the bias in samples of large online networks. Soc. Netw. 2014, 38, 16–27. [Google Scholar] [CrossRef]
- Rezvan, M.; Shekarpour, S.; Balasuriya, L.; Thirunarayan, K.; Shalin, V.L.; Sheth, A. A Quality Type-aware Annotated Corpus and Lexicon for Harassment Research. In Proceedings of the 10th ACM Conference on Web Science, Amsterdam, The Netherlands, 27–30 May 2018; ACM: New York, NY, USA, 2018; pp. 33–36. [Google Scholar]
- Einarsen, S.; Hoel, H.; Cooper, C. Bullying and Emotional Abuse in the Workplace: International Perspectives in Research and Practice; CRC Press: Boca Raton, FL, USA, 2002. [Google Scholar]
- Dadvar, M.; de Jong, F. Cyberbullying detection: A step toward a safer internet yard. In Proceedings of the 21st International Conference Companion on World Wide Web-WWW ’12 Companion, Lyon, France, 16–20 April 2012; ACM Press: Lyon, France, 2012; p. 121. [Google Scholar]
- Balakrishnan, V.; Khan, S.; Arabnia, H.R. Improving cyberbullying detection using Twitter users’ psychological features and machine learning. Comput. Secur. 2020, 90, 101710. [Google Scholar] [CrossRef]
- Gimpel, K.; Schneider, N.; O’Connor, B.; Das, D.; Mills, D.; Eisenstein, J.; Heilman, M.; Yogatama, D.; Flanigan, J.; Smith, N.A. Part-of-Speech Tagging for Twitter: Annotation, Features, and Experiments. In Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics: Human Language Technologies, Portland, OR, USA, 19–24 June 2011; Association for Computational Linguistics: Portland, OR, USA, 2011; pp. 42–47. [Google Scholar]
- Turney, P. Thumbs Up or Thumbs Down? Semantic Orientation Applied to Unsupervised Classification of Reviews. In Proceedings of the 40th Annual Meeting of the Association for Computational Linguistics, Philadelphia, PA, USA, 7–12 July 2002; Association for Computational Linguistics: Philadelphia, PA, USA, 2002; pp. 417–424. [Google Scholar]
- Bagheri, A.; Nadi, S. Sentiment Miner: A Novel Unsupervised Framework for Aspect Detection from Customer Reviews. Int. J. Comput. Linguist. Res. 2018, 9, 120. [Google Scholar] [CrossRef]
- Su, Q.; Xiang, K.; Wang, H.; Sun, B.; Yu, S. Using Pointwise Mutual Information to Identify Implicit Features in Customer Reviews. In Proceedings of the Computer Processing of Oriental Languages. Beyond the Orient: The Research Challenges Ahead, Singapore, 17–19 December 2006; Matsumoto, Y., Sproat, R.W., Wong, K.-F., Zhang, M., Eds.; Springer: Berlin/Heidelberg, Germany, 2006; pp. 22–30. [Google Scholar]
- Yasmina, D.; Hajar, M.; Hassan, A.M. Using YouTube Comments for Text-based Emotion Recognition. Procedia Comput. Sci. 2016, 83, 292–299. [Google Scholar] [CrossRef] [Green Version]
- Cai, K.; Spangler, S.; Chen, Y.; Zhang, L. Leveraging sentiment analysis for topic detection. Web Intell. Agent Syst. Int. J. 2010, 8, 291–302. [Google Scholar] [CrossRef]
- Cheng, S.-M.; Yu, C.-H.; Chen, H.-H. Chinese Word Ordering Errors Detection and Correction for Non-Native Chinese Language Learners. In Proceedings of the COLING 2014, the 25th International Conference on Computational Linguistics: Technical Papers, Dublin, Ireland, 25–29 August 2014; Dublin City University and Association for Computational Linguistics: Dublin, Ireland, 2014; pp. 279–289. [Google Scholar]
- Giachanou, A.; Ghanem, B. Bot and Gender Detection using Textual and Stylistic Information. In Proceedings of the CLEF 2019, Lugano, Switzerland, 9–12 September 2019. [Google Scholar]
- Pantel, P. Alias Detection in Malicious Environments. In Proceedings of the AAAI Fall Symposium on Capturing and Using Patterns for Evidence Detection, Arlington, VA, USA, 13–15 October 2006; pp. 14–20. [Google Scholar]
- Grzeszick, R.; Sudholt, S.; Fink, G.A. Weakly Supervised Object Detection with Pointwise Mutual Information. arXiv 2018, arXiv:1801.08747. [Google Scholar]
- Isola, P.; Zoran, D.; Krishnan, D.; Adelson, E.H. Crisp Boundary Detection Using Pointwise Mutual Information. In Computer Vision–ECCV 2014; Fleet, D., Pajdla, T., Schiele, B., Tuytelaars, T., Eds.; Lecture Notes in Computer Science; Springer International Publishing: Cham, Switzerland, 2014; Volume 8691, pp. 799–814. ISBN 978-3-319-10577-2. [Google Scholar]
- Meckbach, C.; Tacke, R.; Hua, X.; Waack, S.; Wingender, E.; Gültas, M. PC-TraFF: Identification of potentially collaborating transcription factors using pointwise mutual information. BMC Bioinform. 2015, 16, 400. [Google Scholar] [CrossRef] [Green Version]
- Garrett, M.; Kuiper, P.; Hood, K.; Turner, D. Leveraging Mutual Information to Generate Domain Specific Lexicons. In Proceedings of the International Conference on Social Computing, Behavioral-Cultural Modeling, & Prediction and Behavior Representation in Modeling and Simulation, Washington DC, USA, 18–21 October 2018; pp. 1–7. [Google Scholar]
- Pattnaik, P.K.; Rautaray, S.S.; Das, H.; Nayak, J. Progress in Computing, Analytics and Networking: Proceedings of ICCAN 2017; Springer: Berlin/Heidelberg, Germany, 2018; ISBN 978-981-10-7871-2. [Google Scholar]
- Mehta, R. Big Data Analytics with Java; Packt Publishing Ltd: Birmingham, UK, 2017; ISBN 978-1-78728-219-3. [Google Scholar]
- Talpur, B.A.; O’Sullivan, D. Cyberbullying severity detection: A machine learning approach. PLoS ONE 2020, 15, e0240924. [Google Scholar] [CrossRef] [PubMed]
- Duggan, M. Online Harassment. Pew Research Center Internet Science Technology. 2014. Available online: https://www.pewresearch.org/internet/2014/10/22/online-harassment/ (accessed on 15 November 2020).
- Moreo, A.; Esuli, A.; Sebastiani, F. Distributional Random Oversampling for Imbalanced Text Classification. In Proceedings of the 39th International ACM SIGIR conference on Research and Development in Information Retrieval-SIGIR ’16, Pisa, Italy, 17–21 July 2016; ACM Press: Pisa, Italy, 2016; pp. 805–808. [Google Scholar]
- He, H.; Garcia, E.A. Learning from Imbalanced Data. IEEE Trans. Knowl. Data Eng. 2009, 21, 1263–1284. [Google Scholar] [CrossRef]
- Sun, Y.; Wong, A.K.C.; Kamel, M.S. Classification of imbalanced data: A review. Int. J. Patt. Recogn. Artif. Intell. 2009, 23, 687–719. [Google Scholar] [CrossRef]
- Chawla, N.V.; Bowyer, K.W.; Hall, L.O.; Kegelmeyer, W.P. SMOTE: Synthetic Minority Over-sampling Technique. JAIR 2002, 16, 321–357. [Google Scholar] [CrossRef]
- Cohen, J. A Coefficient of Agreement for Nominal Scales. Educ. Psychol. Meas. 1960, 20, 37–46. [Google Scholar] [CrossRef]
- Ian, H.W.; Eibe, F.; Mark, A. Hall Data Mining: Practical Machine Learning Tools and Techniques; Elsevier: Amsterdam, The Netherlands, 2011; ISBN 978-0-12-374856-0. [Google Scholar]
- Vieira, S.M.; Kaymak, U.; Sousa, J.M.C. Cohen’s kappa coefficient as a performance measure for feature selection. In Proceedings of the International Conference on Fuzzy Systems, Barcelona, Spain, 18–23 July 2010; IEEE: Barcelona, Spain, 2010; pp. 1–8. [Google Scholar]
- Landis, J.R.; Koch, G.G. The measurement of observer agreement for categorical data. Biometrics 1977, 33, 159–174. [Google Scholar] [CrossRef] [Green Version]
- Hall, M.; Frank, E.; Holmes, G.; Pfahringer, B.; Reutemann, P.; Witten, I.H. The WEKA Data Mining Software: An Update. Sigkdd. Explor. Newsl. 2009, 11, 10–18. [Google Scholar] [CrossRef]
- Bravo-Marquez, F.; Frank, E.; Pfahringer, B.; Mohammad, S.M. AffectiveTweets: A Weka package for analyzing affect in tweets. J. Mach. Learn. Res. 2019, 20, 1–6. [Google Scholar]
- Alonso, C.; Romero, E. Aggressors and Victims in Bullying and Cyberbullying: A Study of Personality Profiles using the Five-Factor Model. Span J. Psychol. 2017, 20, E76. [Google Scholar] [CrossRef]
- Chavan, V.S.; Shylaja, S.S. Machine learning approach for detection of cyber-aggressive comments by peers on social media network. In Proceedings of the 2015 International Conference on Advances in Computing, Communications and Informatics (ICACCI), Kochi, India, 10–13 August 2015; pp. 2354–2358. [Google Scholar]
- Dinakar, K.; Jones, B.; Havasi, C.; Lieberman, H.; Picard, R. Common Sense Reasoning for Detection, Prevention, and Mitigation of Cyberbullying. ACM Trans. Interact. Intell. Syst. 2012, 2. [Google Scholar] [CrossRef] [Green Version]
- Mangaonkar, A.; Hayrapetian, A.; Raje, R. Collaborative detection of cyberbullying behavior in Twitter data. In Proceedings of the 2015 IEEE International Conference on Electro/Information Technology (EIT), Dekalb, IL, USA, 21–23 May 2015; pp. 611–616. [Google Scholar]
- Nahar, V.; Li, X.; Pang, C.; Zhang, Y. Cyberbullying Detection Based on Text-Stream Classification. In Proceedings of the Conferences in Research and Practice in Information Technology Series, Australian Computer Society, Canberra, Australia, 13–15 November 2013; Volume 146, pp. 49–58. [Google Scholar]
- Sugandhi, R.; Pande, A.; Agrawal, A.; Bhagat, H. Automatic Monitoring and Prevention of Cyberbullying. J. Netw. Comput. Appl. 2016, 144, 17–19. [Google Scholar] [CrossRef]
- Japkowicz, N.; Stephen, S. The class imbalance problem: A systematic study1. IDA 2002, 6, 429–449. [Google Scholar] [CrossRef]
- Mitsopoulou, E.; Giovazolias, T. Personality traits, empathy and bullying behavior: A meta-analytic approach. Aggress. Violent Behav. 2015, 21, 61–72. [Google Scholar] [CrossRef]
- Sun, T.; Gaut, A.; Tang, S.; Huang, Y.; ElSherief, M.; Zhao, J.; Mirza, D.; Belding, E.; Chang, K.-W.; Wang, W.Y. Mitigating Gender Bias in Natural Language Processing: Literature Review. arXiv 2019, arXiv:1906.08976. [Google Scholar]
- Zhao, J.; Wang, T.; Yatskar, M.; Ordonez, V.; Chang, K.-W. Men Also Like Shopping: Reducing Gender Bias Amplification using Corpus-level Constraints. arXiv 2017, arXiv:1707.09457. [Google Scholar]









Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Talpur, B.A.; O’Sullivan, D. Multi-Class Imbalance in Text Classification: A Feature Engineering Approach to Detect Cyberbullying in Twitter. Informatics 2020, 7, 52. https://doi.org/10.3390/informatics7040052
Talpur BA, O’Sullivan D. Multi-Class Imbalance in Text Classification: A Feature Engineering Approach to Detect Cyberbullying in Twitter. Informatics. 2020; 7(4):52. https://doi.org/10.3390/informatics7040052
Chicago/Turabian StyleTalpur, Bandeh Ali, and Declan O’Sullivan. 2020. "Multi-Class Imbalance in Text Classification: A Feature Engineering Approach to Detect Cyberbullying in Twitter" Informatics 7, no. 4: 52. https://doi.org/10.3390/informatics7040052
APA StyleTalpur, B. A., & O’Sullivan, D. (2020). Multi-Class Imbalance in Text Classification: A Feature Engineering Approach to Detect Cyberbullying in Twitter. Informatics, 7(4), 52. https://doi.org/10.3390/informatics7040052