3.2. Comparison with the Other Methods
In this paper, the proposed method is compared with the methods of Arham et al. [
3], Yao et al. [
22], and Kumar et al. [
16]. Similarity and correlation between pixels belonging to each class are increased using multilevel thresholding, and the difference between the pixels decreases. As a result, inserting a few layers of data creates less distortion in the image.
Because, in the proposed method, all of the values of zero and positive differences are expanded to insert the data, in the first insertion layer and higher insertion layers, it has a higher insertion capacity and PSNR than the methods of Arham et al. [
3], Yao et al. [
30], and Kumar et al. [
24]. As a result, the resulting distortion in the marked image for the proposed method is less than that in the methods of Arham et al. [
3], Yao et al. [
30], and Kumar et al. [
24].
Table 2 shows the values of insertion capacity maxima for different images per thresholds
and
at 0 ≤ Th ≤ +32. The values of
and
are set by the SMA.
Table 3 shows the values of processing time (seconds) for different images per thresholds
and
at 0 ≤ Th ≤ +32.
As can be seen from
Table 2 and
Table 3, for the two thresholds and
in the first insertion layer, the proposed method has more insertion capacity and more PSNR for all images than the methods of Arham et al. [
3] and Kumar et al. [
24].
According to
Table 2, the insertion capacity of the first insertion layer in the proposed method for the Airplane, Baboon, Barbara, Ship, Lena, Lake, Bridge, Cameraman, and Peppers images is 834 bits (0.0032 bpp), 1689 bits (0.0064 bpp), 766 bits (0.0029 bpp), 1561 bits (0.0059 bpp), 2241 bits (0.0085 bpp), 1604 bits (0.0061 bpp), 4402 bits (0.0168 bpp), 4794 bits (0.0183 bpp), and 1571 bits (0.0061 bpp), respectively—more than in the method of Arham et al. [
3].
In the proposed method, the Lena image has the highest increase in capacity (0.0085 bpp), while the Barbara image has the lowest increase in capacity (0.0029 bpp), compared to the method of Arham et al. [
3]. Therefore, on average, the capacity of the first insertion layer in the proposed method is 0.0058 bpp more than that of the method of Arham et al. [
3]. The average processing time for the proposed method is 173.2367 s, while that for the method of Arham et al. [
3] is 150.8417 s. Therefore, the proposed method is slower than the method of Arham et al. [
3], due to the use of the SMA and its repetitions to obtain optimal thresholds.
Moreover, the proposed method is better than the method of Kumar et al. [
24] in terms of PSNR and embedding capacity values, as can be seen in
Table 2 and
Table 3, but in terms of execution time it is slower compared to the methods of Kumar et al. [
24] and Arham et al. [
3]. Furthermore, the proposed method, compared to the method of Kumar et al. [
24] for the Lake, Bridge, Cameraman, Airplane, Baboon, Barbara, Ship, Lena, and Peppers images, yields 82,485 bits (3145 bpp), 11,874 bits (0.0324 bpp), 40,762 bits (0.1581 bpp), 5000 bits (0.0191 bpp), 85,000 bits (0.3242 bpp), 34,232 bits (0.1306 bpp), 36,144 bits (0.1379 bpp), 9000 bits (0.0343 bpp) and 18,985 bits (0.0724 bpp), respectively, showing greater capacity.
Table 4 also compares the PSNR values of the proposed method with the method of Arham et al. [
3] for different capacities of 0.1 bpp, 0.2 bpp, 0.3 bpp, 0.4 bpp, 0.5 bpp, 0.6 bpp, and 0.7 bpp in the first insertion layer. As can be seen from
Table 4, the average PSNR of the proposed method for different capacities is higher than that of the method of Arham et al. [
3].
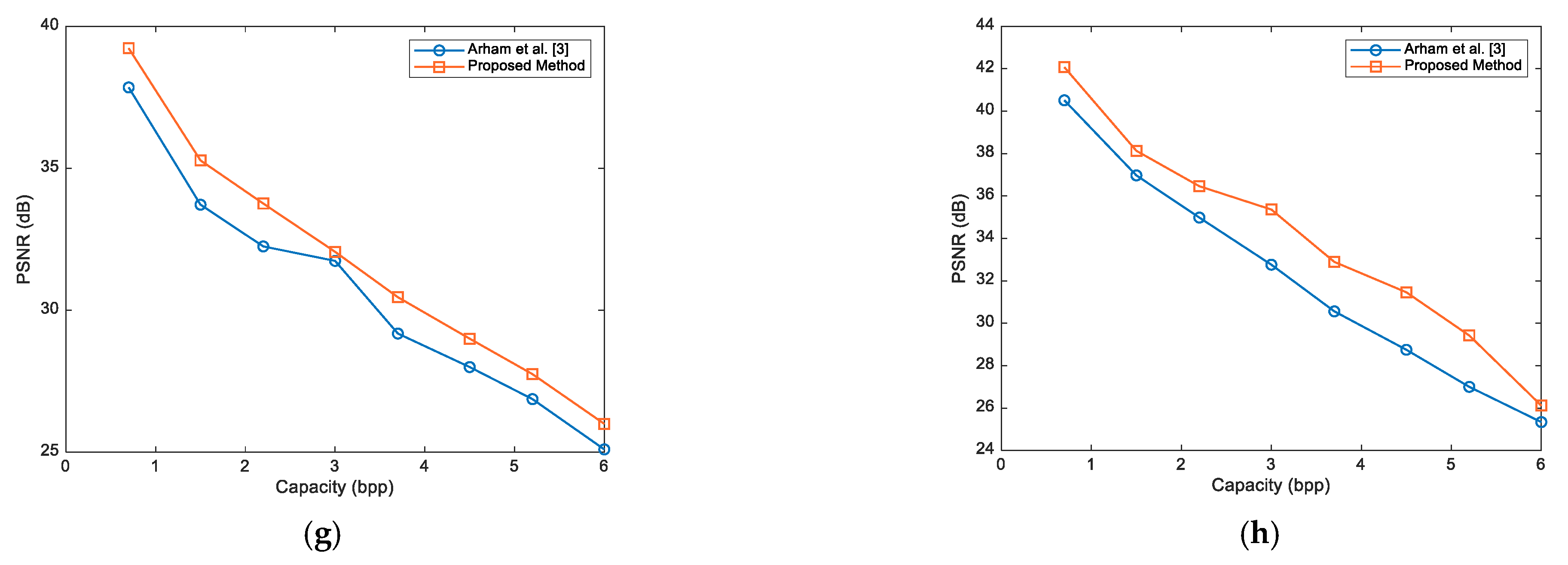
Figure 6 shows the PSNR comparison diagram of the proposed method with the method of Arham et al. [
3] for different images under the same capacities drawn using the data shown in
Table 4 and
Table 5. As can be seen from the diagrams in
Figure 6, the proposed method has a higher PSNR value for all images than the method of Arham et al. [
3]. For the first insertion layer, the Airplane image for the capacities of 0.1 bpp, 0.2 bpp, 0.3 bpp, 0.4 bpp, 0.5 bpp, 0.6 bpp, and 0.7 bpp shows increases in quality compared to the method of Arham et al. [
3] of 0.8200 dB, 0.8500 dB, 1.1400 dB, 1.04 dB, 1.6200 dB, 1.6700 dB, and 0.94 dB, respectively.
Moreover, the Baboon image for the capacities of 0.1 bpp, 0.2 bpp, 0.3 bpp, 0.4 bpp, 0.5 bpp, 0.6 bpp, and 0.7 bpp, compared to the method of Arham et al. [
3], shows increases in quality of 1.0600 dB, 0.9600 dB, 0.9000 dB, 0.3900 dB, 0.6300 dB, 0.5700 dB and 1.4900 dB, respectively. Meanwhile, the Barbara image for the capacities of 0.1 bpp, 0.2 bpp, 0.3 bpp, 0.4 bpp, 0.5 bpp, 0.6 bpp, and 0.7 bpp increases in quality by 1.4500 dB, 0.7000 dB, 0.610.0 dB, 1.1900 dB, 0.1400 dB, 1.1100 dB, and 1.0600 dB, respectively, compared to the method of Arham et al. [
3].
The Ship image for the capacities of 0.1 bpp, 0.2 bpp, 0.3 bpp, 0.4 bpp, 0.5 bpp, 0.6 bpp, and 0.7 bpp increases in quality by 1.1400 dB, 1.6000 dB, 1.6300 dB, 1.0600 dB, 1.2300 dB, 1.1800 dB, and 1.5900 dB, respectively, compared to the method of Arham et al. [
3].
The Lena image for capacities of 0.1 bpp, 0.2 bpp, 0.3 bpp, 0.4 bpp, 0.5 bpp, 0.6 bpp and 0.7 bpp, compared to the method of Arham et al. [
3], has an increase in quality of 0.4800 dB, 1.8100 dB, 0.8700 dB, 0.4000 dB, 1.2700 dB, 1.5800 dB, and 1.2800 dB, respectively. The Peppers image for capacities of 0.1 bpp, 0.2 bpp, 0.3 bpp, 0.4 bpp, 0.5 bpp, 0.6 bpp, and 0.7 bpp, compared to the method of Arham et al. [
3], has an increase in quality of 1.6500 dB, 1.8200 dB, 1.3300 dB, 1.50 dB, 0.5900 dB, 1.1700 dB, and 1.3500 dB, respectively. The Lake image for the capacities of 0.1 bpp, 0.2 bpp, 0.3 bpp, 0.4 bpp, 0.5 bpp, 0.6 bpp, and 0.7 bpp increases in quality by 1.4700 dB, 1.2100 dB, 1.1000 dB, 1.0700 dB, 1.1300 dB, 1.1400 dB, and 0.6900 dB, respectively, compared to the method of Arham et al. [
3].
The Cameraman image for capacities of 0.1 bpp, 0.2 bpp, 0.3 bpp, 0.4 bpp, 0.5 bpp, 0.6 bpp and 0.7 bpp, compared to the method of Arham et al. [
3], has an increase in quality of 1.9400 dB, 1.3800 dB, 1.6900 dB, 1.2900 dB, 1.5500 dB, 1.1100 dB, and 1.0600 dB, respectively. The Bridge image for capacities of 0.1 bpp, 0.2 bpp, 0.3 bpp, 0.4 bpp, 0.5 bpp, 0.6 bpp, and 0.7 bpp, compared to the method of Arham et al. [
3], has an increase in quality of 1.4500 dB, 1.8200 dB, 0.9600 dB, 1.2400 dB, 1.5000 dB, 0.8400 dB, and 1.0600 dB, respectively.
The proposed method has more insertion capacity than that of Arham et al. [
3] for the first and higher insertion layers.
Table 5 shows the PSNR comparison of the proposed method and the method of Arham et al. [
3] for the eight insertion layers. As the number of insertion layers increases, the total insertion capacity increases. As shown in
Table 5, the values of insertion capacity and PSNR for the proposed method are higher than those in the method of Arham et al. [
3]. According to
Table 5, the average insertion capacity increase in the eight insertion layers in the proposed method is 0.625 bpp, and in the method of Arham et al. [
3] it is 0.572 bpp. In insertion layer eight, the Peppers, Lena, Barbara, and Baboon images have the highest increase in capacity, while the Airplane, Ship, Lake, Bridge, and Cameraman images have the slightest increase in capacity, compared to the method of Arham et al. [
3].
In insertion layer eight, the Baboon image has the highest increase in PSNR (1.25 dB), while the Barbara image has the lowest increase in PSNR (1 dB), compared to the method of Arham et al. [
3]. In insertion layer eight, the average insertion capacity of the proposed method and the method of Arham et al. [
3] is 6.33 bpp and 6 bpp, respectively, while the average PSNR in the proposed method and the method of Arham et al. [
3] is 29.75 dB and 28.88 dB, respectively. In insertion layer eight, the proposed method has an average capacity increase of 0.33 bpp and an average quality increase of 1.63 dB compared to the method of Arham et al. [
3].
Figure 7 shows a comparison diagram of the capacity and PSNR values of the proposed method and the method of Arham et al. [
3] for eight insertion layers drawn using the data shown in
Table 5.
Table 6 shows the SSIM values of the proposed method and the methods of Arham et al. [
3] and Kumar et al. [
16] for maximum embedding capacity (bits). According to
Table 6, due to its nature, the proposed method has a higher SSIM than the compared methods, while the capacity of the proposed method is also more than that of the compared methods.
Table 7 shows the method proposed by Arham et al. [
3], using the SSIM evaluation metric, which compares one embedding layer and several embedding layers. As can be seen in
Table 7, the proposed method has superior performance for different capacities (bpp) compared to the method of Arham et al. [
3], with a higher SSIM value. As the capacity value increases in bpp, the SSIM value for the proposed method and the method of Arham et al. [
3] decreases. Still, in any case, the proposed method compared is superior to the method of Arham et al. [
3] in terms of SSIM value.
Table 8 shows the PSNR and SSIM values for the proposed method and the method of Yao et al. [
30] for capacities of 30,000 and 50,000 bits. As can be seen from
Table 8, the proposed method has higher SSIM and PSNR values compared to the method of Yao et al. [
30].
In this paper, a multilayer RDH method based on the multilevel thresholding technique is proposed, aiming to increase the insertion capacity and reduce the distortion after data embedding by improving the correlation between consecutive pixels of the image. Firstly, the SMA is applied to find the optimal thresholds of host image segmentation. Next, according to the specified threshold, image pixels located in different image areas are classified into different categories. Finally, the difference between two consecutive pixels is reduced in each class, and then the data are embedded via DE.

 ,
, 












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}