
Development and Validation of an Artificial Neural-Network-Based Optical Density Soft Sensor for a High-Throughput Fermentation System



Abstract
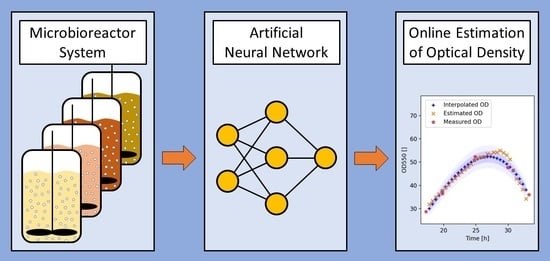
:
1. Introduction
2. Materials and Methods
2.1. High-Throughput-Microbioreactor System
2.2. Data Generation
2.3. Data Processing and Model Development
- (a)
- The training set contained 70% of all available fermentations and was used to fit the ANN models;
- (b)
- The validation set contained 15% of all available fermentations and was used to detect overfitting, in which case model training was stopped;
- (c)
- The test set contained 15% of all available fermentations and was used for model validation.
2.4. Artificial Neural Networks
3. Results
3.1. Overview of the Data
3.2. OD Soft Sensor Performance
3.3. Generalized OD Soft Sensor
3.4. Information Retention for Processes with Fewer Measurements
4. Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A
Appendix B

Appendix C

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Strain | Set | RMSE | Accuracy1 [%] | Estimations within σ [%] | Estimations within 2σ [%] |
|---|---|---|---|---|---|
| Strain 1 | Training | 2.70 | 94.18 | 64.22 | 91.37 |
| Validation | 2.01 | 95.68 | 71.60 | 93.20 | |
| Test | 2.09 | 95.50 | 68.00 | 96.80 | |
| Strain 2 | Training | 3.57 | 93.38 | 55.25 | 83.40 |
| Validation | 3.50 | 93.50 | 36.80 | 80.80 | |
| Test | 2.96 | 94.52 | 47.79 | 87.55 | |
| Strain 3 | Training | 2.51 | 94.03 | 56.74 | 95.98 |
| Validation | 2.28 | 94.58 | 67.06 | 96.76 | |
| Test | 2.45 | 94.17 | 67.06 | 94.05 | |
| Strain 4 | Training | 2.20 | 94.95 | 65.49 | 89.16 |
| Validation | 2.79 | 93.59 | 50.90 | 78.37 | |
| Test | 2.97 | 93.16 | 53.85 | 76.92 |
References
- Rathore, A.; Auclair, J.; Bhattacharya, S.; Sarin, D. Two-Dimensional Liquid Chromatography (2D-LC): Analysis of Size-Based Heterogeneities in Monoclonal Antibody–Based Biotherapeutic Products. LCGC North Am. 2022, 40, 27–31. [Google Scholar] [CrossRef]
- P&S Intelligence. Biopharmaceutical Market. Available online: https://www.psmarketresearch.com/market-analysis/biopharmaceuticals-market (accessed on 25 December 2022).
- GlobeNewswire. Biopharmaceutical Market. Available online: https://www.globenewswire.com/en/news-release/2022/09/28/2524510/0/en/Biopharmaceutical-Market-Size-Will-Attain-USD-853-Billion-by-2030-growing-at-11-3-CAGR-Exclusive-Report-by-Acumen-Research-and-Consulting.html (accessed on 25 December 2022).
- MordorIntelligence. Biopharmaceuticals Market. Available online: https://www.mordorintelligence.com/industry-reports/global-biopharmaceuticals-market-industry (accessed on 25 December 2022).
- Grand View Research. Monoclonal Antibodies Market Size. Available online: https://www.grandviewresearch.com/industry-analysis/monoclonal-antibodies-market#:~:text=Report%20Overview,11.30%25%20from%202022%20to%202030 (accessed on 25 December 2022).
- The Business Research Company. Monoclonal Antibodies MAbS Global Market Report. 2023. Available online: https://www.thebusinessresearchcompany.com/report/monoclonal-antibodies-global-market-report (accessed on 25 December 2022).
- Presedence Research. Monoclonal Antibodies Market Size to Hit US$ 524.68 Bn By 2030. Available online: https://www.globenewswire.com/news-release/2022/05/23/2448585/0/en/Monoclonal-Antibodies-Market-Size-to-Hit-US-524-68-Bn-By-2030.html (accessed on 25 December 2022).
- Berger, M.; Shankar, V.; Vafai, A. Therapeutic applications of monoclonal antibodies. Am. J. Med. Sci. 2002, 324, 14–30. [Google Scholar] [CrossRef] [PubMed]
- Quinteros, D.A.; Bermúdez, J.M.; Ravetti, S.; Cid, A.; Allemandi, D.A.; Palma, S.D. Therapeutic Use of Monoclonal Antibodies: General Aspects and Challenges for Drug Delivery. Nanostructures for Drug Delivery; Elsevier: Amsterdam, The Netherlands, 2017; pp. 807–833. [Google Scholar]
- Ahmad, Z.A.; Yeap, S.K.; Ali, A.M.; Ho, W.Y.; Alitheen, N.B.M.; Hamid, M. scFv antibody: Principles and clinical application. Clin. Dev. Immunol. 2012, 2012, 980250. [Google Scholar] [CrossRef] [PubMed]
- Hemmerich, J.; Noack, S.; Wiechert, W.; Oldiges, M. Microbioreactor systems for accelerated bioprocess development. Biotechnol. J. 2018, 13, 1700141. [Google Scholar] [CrossRef]
- Zheng, X.; Xing, X.-H.; Zhang, C. Targeted mutagenesis: A sniper-like diversity generator in microbial engineering. Synth. Syst. Biotechnol. 2017, 2, 75–86. [Google Scholar] [CrossRef] [PubMed]
- Bareither, R.; Pollard, D. A review of advanced small—Scale parallel bioreactor technology for accelerated process development: Current state and future need. Biotechnol. Prog. 2011, 27, 2–14. [Google Scholar] [CrossRef]
- Funke, M.; Buchenauer, A.; Schnakenberg, U.; Mokwa, W.; Diederichs, S.; Mertens, A.; Müller, C.; Kensy, F.; Büchs, J. Microfluidic biolector—Microfluidic bioprocess control in microtiter plates. Biotechnol. Bioeng. 2010, 107, 497–505. [Google Scholar] [CrossRef] [PubMed]
- Huber, R.; Ritter, D.; Hering, T.; Hillmer, A.-K.; Kensy, F.; Müller, C.; Wang, L.; Büchs, J. Robo-Lector–a novel platform for automated high-throughput cultivations in microtiter plates with high information content. Microb. Cell Factories 2009, 8, 42. [Google Scholar] [CrossRef] [Green Version]
- Zanzotto, A.; Szita, N.; Boccazzi, P.; Lessard, P.; Sinskey, A.J.; Jensen, K.F. Membrane—Aerated microbioreactor for high—Throughput bioprocessing. Biotechnol. Bioeng. 2004, 87, 243–254. [Google Scholar] [CrossRef]
- Velez—Suberbie, M.L.; Betts, J.P.J.; Walker, K.L.; Robinson, C.; Zoro, B.; Keshavarz—Moore, E.; Velez-Suberbie, M.L.; Keshavarz-Moore, E. High throughput automated microbial bioreactor system used for clone selection and rapid scale—Down process optimization. Biotechnol. Prog. 2018, 34, 58–68. [Google Scholar] [CrossRef]
- Lee, H.L.T.; Boccazzi, P.; Ram, R.J.; Sinskey, A.J. Microbioreactor arrays with integrated mixers and fluid injectors for high-throughput experimentation with pH and dissolved oxygen control. Lab Chip 2006, 6, 1229–1235. [Google Scholar] [CrossRef]
- Janzen, N.H.; Striedner, G.; Jarmer, J.; Voigtmann, M.; Abad, S.; Reinisch, D. Implementation of a fully automated microbial cultivation platform for strain and process screening. Biotechnol. J. 2019, 14, 1800625. [Google Scholar] [CrossRef] [Green Version]
- Newton, J.; Oeggl, R.; Janzen, N.H.; Abad, S.; Reinisch, D. Process adapted calibration improves fluorometric pH sensor precision in sophisticated fermentation processes. Eng. Life Sci. 2020, 20, 331–337. [Google Scholar] [CrossRef] [PubMed]
- Velugula-Yellela, S.R.; Kohnhorst, C.; Powers, D.N.; Trunfio, N.; Faustino, A.; Angart, P.; Berilla, E.; Faison, T.; Agarabi, C. Use of high-throughput automated microbioreactor system for production of model IgG1 in CHO cells. JoVE 2018, 139, e58231. [Google Scholar] [CrossRef] [Green Version]
- Kager, J.; Fricke, J.; Becken, U.; Herwig, C.; Center, E.A. A generic biomass soft sensor and its application in bioprocess development. Eppend-Appl. Note 2017, 357, 1–8. [Google Scholar]
- Gopakumar, V.; Tiwari, S.; Rahman, I. A deep learning based data driven soft sensor for bioprocesses. Biochem. Eng. J. 2018, 136, 28–39. [Google Scholar] [CrossRef]
- Bayer, B.; von Stosch, M.; Melcher, M.; Duerkop, M.; Striedner, G. Soft sensor based on 2D—Fluorescence and process data enabling real—Time estimation of biomass in Escherichia coli cultivations. Eng. Life Sci. 2020, 20, 26–35. [Google Scholar] [CrossRef] [Green Version]
- Brunner, V.; Siegl, M.; Geier, D.; Becker, T. Biomass soft sensor for a Pichia pastoris fed—Batch process based on phase detection and hybrid modeling. Biotechnol. Bioeng. 2020, 117, 2749–2759. [Google Scholar] [CrossRef]
- Ohadi, K.; Legge, R.L.; Budman, H.M. Development of a soft—Sensor based on multi—Wavelength fluorescence spectroscopy and a dynamic metabolic model for monitoring mammalian cell cultures. Biotechnol. Bioeng. 2015, 112, 197–208. [Google Scholar] [CrossRef]
- Von Stosch, M.; Oliveira, R.; Peres, J.; de Azevedo, S.F.; Feyo de Azevedo, S. Hybrid semi-parametric modeling in process systems engineering: Past, present and future. Comput. Chem. Eng. 2014, 60, 86–101. [Google Scholar] [CrossRef] [Green Version]
- Kroll, P.; Hofer, A.; Stelzer, I.V.; Herwig, C. Workflow to set up substantial target-oriented mechanistic process models in bioprocess engineering. Process Biochem. 2017, 62, 24–36. [Google Scholar] [CrossRef]
- Golabgir, A.; Herwig, C. Combining mechanistic modeling and Raman spectroscopy for real—Time monitoring of fed—Batch Penicillin production. Chem. Ing. Tech. 2016, 88, 764–776. [Google Scholar] [CrossRef]
- Mulrennan, K.; Donovan, J.; Creedon, L.; Rogers, I.; Lyons, J.G.; McAfee, M. A soft sensor for prediction of mechanical properties of extruded PLA sheet using an instrumented slit die and machine learning algorithms. Polym. Test. 2018, 69, 462–469. [Google Scholar] [CrossRef]
- Liukkonen, M.; Hälikkä, E.; Hiltunen, T.; Hiltunen, Y. Dynamic soft sensors for NOx emissions in a circulating fluidized bed boiler. Appl. Energy 2012, 97, 483–490. [Google Scholar] [CrossRef]
- Rogina, A.; Šiško, I.; Mohler, I.; Ujević, Ž.; Bolf, N. Soft sensor for continuous product quality estimation (in crude distillation unit). Chem. Eng. Res. Des. 2011, 89, 2070–2077. [Google Scholar] [CrossRef]
- Bayer, B.; Striedner, G.; Duerkop, M. Hybrid modeling and intensified doe: An approach to accelerate upstream process characterization. Biotechnol. J. 2020, 15, 2000121. [Google Scholar] [CrossRef]
- Narayanan, H.; Sokolov, M.; Morbidelli, M.; Butté, A. A new generation of predictive models: The added value of hybrid models for manufacturing processes of therapeutic proteins. Biotechnol. Bioeng. 2019, 116, 2540–2549. [Google Scholar] [CrossRef]
- Von Stosch, M.; Davy, S.; Francois, K.; Galvanauskas, V.; Hamelink, J.-M.; Luebbert, A.; Mayer, M.; Oliveira, R.; O’Kennedy, R.; Rice, P.; et al. Hybrid modeling for quality by design and PAT—Benefits and challenges of applications in biopharmaceutical industry. Biotechnol. J. 2014, 9, 719–726. [Google Scholar] [CrossRef] [Green Version]
- Hou, S.; Zhang, X.; Dai, W.; Han, X.; Hua, F. Multi-model-and soft-transition-based height soft sensor for an air cushion furnace. Sensors 2020, 20, 926. [Google Scholar] [CrossRef] [Green Version]
- Von Stosch, M.; Hamelink, J.-M.; Oliveira, R. Hybrid modeling as a QbD/PAT tool in process development: An industrial E. coli case study. Bioprocess Biosyst. Eng. 2016, 39, 773–784. [Google Scholar] [CrossRef] [Green Version]
- Golabgir, A.; Hoch, T.; Zhariy, M.; Herwig, C. Observability analysis of biochemical process models as a valuable tool for the development of mechanistic soft sensors. Biotechnol. Prog. 2015, 31, 1703–1715. [Google Scholar] [CrossRef] [PubMed]
- Reichelt, W.N.; Thurrold, P.; Brillmann, M.; Kager, J.; Fricke, J.; Herwig, C. Generic biomass estimation methods targeting physiologic process control in induced bacterial cultures. Eng. Life Sci. 2016, 16, 720–730. [Google Scholar] [CrossRef]
- Alom, M.Z.; Taha, T.M.; Yakopcic, C.; Westberg, S.; Sidike, P.; Nasrin, M.S.; van Esesn, B.C.; Awwal, A.A.S.; Asari, V.K. The history began from alexnet: A comprehensive survey on deep learning approaches. arXiv 2018, arXiv:1803.01164. [Google Scholar]
- Géron, A. Hands-On Machine Learning with Scikit-Learn, Keras, and Tensorflow: Concepts, Tools, and Techniques to Build Intelligent Systems, 2nd ed.; O’Reilly Media: Newton, MA, USA, 2019; ISBN 1492032611. [Google Scholar]
- Sak, H.; Senior, A.; Beaufays, F. Long short-term memory based recurrent neural network architectures for large vocabulary speech recognition. arXiv 2014, arXiv:1402.1128. [Google Scholar]
- Howard, A.G. Some improvements on deep convolutional neural network based image classification. arXiv 2013, arXiv:1312.5402. [Google Scholar]
- Bojarski, M.; Yeres, P.; Choromanska, A.; Choromanski, K.; Firner, B.; Jackel, L.; Muller, U. Explaining how a deep neural network trained with end-to-end learning steers a car. arXiv 2017, arXiv:1704.07911. [Google Scholar]
- Choi, K.; Fazekas, G.; Sandler, M. Text-based LSTM networks for automatic music composition. arXiv 2016, arXiv:1604.05358. [Google Scholar]
- Goh, A.T.C.; Goh, A. Back-propagation neural networks for modeling complex systems. Artif. Intell. Eng. 1995, 9, 143–151. [Google Scholar] [CrossRef]
- Zhu, Y.-H.; Rajalahti, T.; Linko, S. Application of neural networks to lysine production. Chem. Eng. J. Biochem. Eng. J. 1996, 62, 207–214. [Google Scholar] [CrossRef]
- Murugan, C.; Natarajan, P. Estimation of fungal biomass using multiphase artificial neural network based dynamic soft sensor. J. Microbiol. Methods 2019, 159, 5–11. [Google Scholar] [CrossRef]
- Melcher, M.; Scharl, T.; Spangl, B.; Luchner, M.; Cserjan, M.; Bayer, K.; Leisch, F.; Striedner, G. The potential of random forest and neural networks for biomass and recombinant protein modeling in Escherichia coli fed—Batch fermentations. Biotechnol. J. 2015, 10, 1770–1782. [Google Scholar] [CrossRef]
- Zhu, X.; Rehman, K.U.; Wang, B.; Shahzad, M. Modern soft-sensing modeling methods for fermentation processes. Sensors 2020, 20, 1771. [Google Scholar] [CrossRef] [Green Version]
- Harris, C.R.; Millman, K.J.; van der Walt, S.J.; Gommers, R.; Virtanen, P.; Cournapeau, D.; Wieser, E.; Taylor, J.; Berg, S.; Smith, N.J. Array programming with NumPy. Nature 2020, 585, 357–362. [Google Scholar] [CrossRef]
- McKinney, W. Data Structures for Statistical Computing in Python. In Proceedings of the 9th Python in Science Conference, No. 1, Austin, TX, USA, 28 June–3 July 2010; Volume 445. [Google Scholar]
- Hunter, J.D. Matplotlib: A 2D graphics environment. Comput. Sci. Eng. 2007, 9, 90–95. [Google Scholar] [CrossRef]
- Bar-Joseph, Z.; Gerber, G.; Gifford, D.K.; Jaakkola, T.S.; Simon, I. A New Approach to Analyzing Gene Expression Time Series Data. In Proceedings of the Sixth Annual International Conference on Computational Biology, Washington, DC, USA, 18–21 April 2002; Association for Computing Machinery: Washington, DC, USA, 2002; pp. 39–48, ISBN 1581134983. [Google Scholar]
- Virtanen, P.; Gommers, R.; Oliphant, T.E.; Haberland, M.; Reddy, T.; Cournapeau, D.; Burovski, E.; Peterson, P.; Weckesser, W.; Bright, J. SciPy 1.0: Fundamental algorithms for scientific computing in Python. Nat. Methods 2020, 17, 261–272. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Maas, A.L.; Hannun, A.Y.; Ng, A.Y. Rectifier nonlinearities improve neural network acoustic models. Proc. ICML 2013, 30, 1–6. [Google Scholar]
- Mishkin, D.; Matas, J. All you need is a good init. arXiv 2015, arXiv:1511.06422. [Google Scholar]
- Abadi, M.; Agarwal, A.; Barham, P.; Brevdo, E.; Chen, Z.; Citro, C.; Corrado, G.S.; Davis, A.; Dean, J.; Devin, M. Tensorflow: Large-scale machine learning on heterogeneous distributed systems. arXiv 2016, arXiv:1603.04467. [Google Scholar]
- Dozat, T. Incorporating Nesterov Momentum into Adam. OpenReview.Net, 18 February 2016; pp. 1–4. Available online: https://openreview.net/pdf/OM0jvwB8jIp57ZJjtNEZ.pdf (accessed on 25 December 2022).
- He, K.; Zhang, X.; Ren, S.; Sun, J. Delving Deep into Rectifiers: Surpassing Human-Level Performance on Imagenet Classification. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015. [Google Scholar]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Lundberg, S.M.; Lee, S.-I. A unified approach to interpreting model predictions. In Proceedings of the Advances in Neural Information Processing Systems 30 (NIPS 2017), Long Beach, CA, USA, 4–9 December 2017; Volume 30. [Google Scholar]
- Friedman, J.H. Multivariate adaptive regression splines. Ann. Stat. 1991, 19, 1–67. [Google Scholar] [CrossRef]
- Friedman, J.H. Greedy function approximation: A gradient boosting machine. Ann. Stat. 2001, 29, 1189–1232. [Google Scholar] [CrossRef]





| Parameter | Value/Type |
|---|---|
| Architecture | Feed-forward neural network |
| Number of hidden layers | 3 |
| Number of neurons of input and hidden layers | 40 |
| Activation function for all neurons | Leaky ReLU (α = 0.2) [56] |
| Loss metric | MSE |
| Optimization algorithm | Nesterov-accelerated Adaptive moment estimation [59] |
| Learning rate | 0.00015 |
| Beta 1 | 0.9 |
| Beta 2 | 0.999 |
| Batch size | 32 |
| Maximum number of epochs | 1000 |
| Number of epochs | Determined by early stopping |
| Early stopping metric | Validation loss |
| Patience | 30 epochs |
| Initializer | He normal [60] |
| Strain | Mean OD | 1. Quartile | 3. Quartile | Maximum | Minimum |
|---|---|---|---|---|---|
| Strain 1 | 55.6 ± 6.7 | 52.8 | 59.8 | 71.2 | 30.8 |
| Strain 2 | 65.6 ± 6.6 | 61.8 | 70.0 | 79.1 | 48.2 |
| Strain 3 | 53.4 ± 8.3 | 50.5 | 59.0 | 66.8 | 31.6 |
| Strain 4 | 35.5 ± 11.8 | 26.9 | 41.4 | 65.5 | 21.3 |
| Strain | Type | Normalized Standard Deviation at Measurement | ||||
|---|---|---|---|---|---|---|
| # 1 [%] | # 2 [%] | # 3 [%] | # 4 [%] | # 5 [%] | ||
| Strain 1 | OD | 0 | 5.03 | 6.93 | 6.75 | 11.44 |
| Cumulative base addition | 0 | 3.59 | 3.88 | 3.47 | 9.49 | |
| Strain 2 | OD | 0 | 10.32 | 7.30 | 8.03 | 7.33 |
| Cumulative base addition | 0 | 2.28 | 3.74 | 5.36 | 5.29 | |
| Strain 3 | OD | 0 | 7.42 | 5.67 | 8.23 | 10.56 |
| Cumulative base addition | 0 | 2.37 | 2.53 | 2.07 | 9.69 | |
| Strain 4 | OD | 0 | 9.38 | 7.46 | 11.39 | 8.74 |
| Cumulative base addition | 0 | 4.22 | 2.58 | 8.96 | 5.53 | |
| Set | RMSE | Accuracy 1 [%] | Estimations within σ [%] | Estimations within 2σ [%] |
|---|---|---|---|---|
| Training | 2.97 | 96.60 | 75.21 | 93.35 |
| Validation | 3.07 | 94.69 | 56.80 | 85.20 |
| Test | 2.81 | 95.14 | 57.96 | 89.39 |
| Model | Set | RMSE | Accuracy 1 [%] | Estimations within σ [%] | Estimations within 2σ [%] |
|---|---|---|---|---|---|
| Model 2 | Training | 2.73 | 94.93 | 60.19 | 93.10 |
| Validation | 3.03 | 94.38 | 50.40 | 82.40 | |
| Test | 3.04 | 94.36 | 54.40 | 88.80 | |
| External Test | 7.82 | 84.32 | 25.63 | 51.04 | |
| Model 24 | Training | 2.68 | 95.17 | 60.25 | 91.16 |
| Validation | 3.17 | 94.29 | 57.23 | 83.19 | |
| Test | 3.26 | 94.17 | 50.84 | 83.12 | |
| External Test | 5.01 | 89.36 | 42.72 | 70.01 | |
| Model 124 | Training | 2.43 | 95.79 | 65.40 | 93.06 |
| Validation | 2.96 | 94.88 | 57.35 | 88.34 | |
| Test | 2.76 | 95.22 | 59.25 | 88.26 | |
| External Test | 3.63 | 91.37 | 47.41 | 80.31 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Medl, M.; Rajamanickam, V.; Striedner, G.; Newton, J. Development and Validation of an Artificial Neural-Network-Based Optical Density Soft Sensor for a High-Throughput Fermentation System. Processes 2023, 11, 297. https://doi.org/10.3390/pr11010297
Medl M, Rajamanickam V, Striedner G, Newton J. Development and Validation of an Artificial Neural-Network-Based Optical Density Soft Sensor for a High-Throughput Fermentation System. Processes. 2023; 11(1):297. https://doi.org/10.3390/pr11010297
Chicago/Turabian StyleMedl, Matthias, Vignesh Rajamanickam, Gerald Striedner, and Joseph Newton. 2023. "Development and Validation of an Artificial Neural-Network-Based Optical Density Soft Sensor for a High-Throughput Fermentation System" Processes 11, no. 1: 297. https://doi.org/10.3390/pr11010297
APA StyleMedl, M., Rajamanickam, V., Striedner, G., & Newton, J. (2023). Development and Validation of an Artificial Neural-Network-Based Optical Density Soft Sensor for a High-Throughput Fermentation System. Processes, 11(1), 297. https://doi.org/10.3390/pr11010297