Multivariate Analysis and Machine Learning for Ripeness Classification of Cape Gooseberry Fruits

 ,
,  ,
,  ,
,  ,
,  , ,
, ,  and
and
Abstract
:1. Introduction
2. Ripeness Classification
2.1. Methods for Color Selection and Extraction
2.2. Principal Component Analysis (PCA)
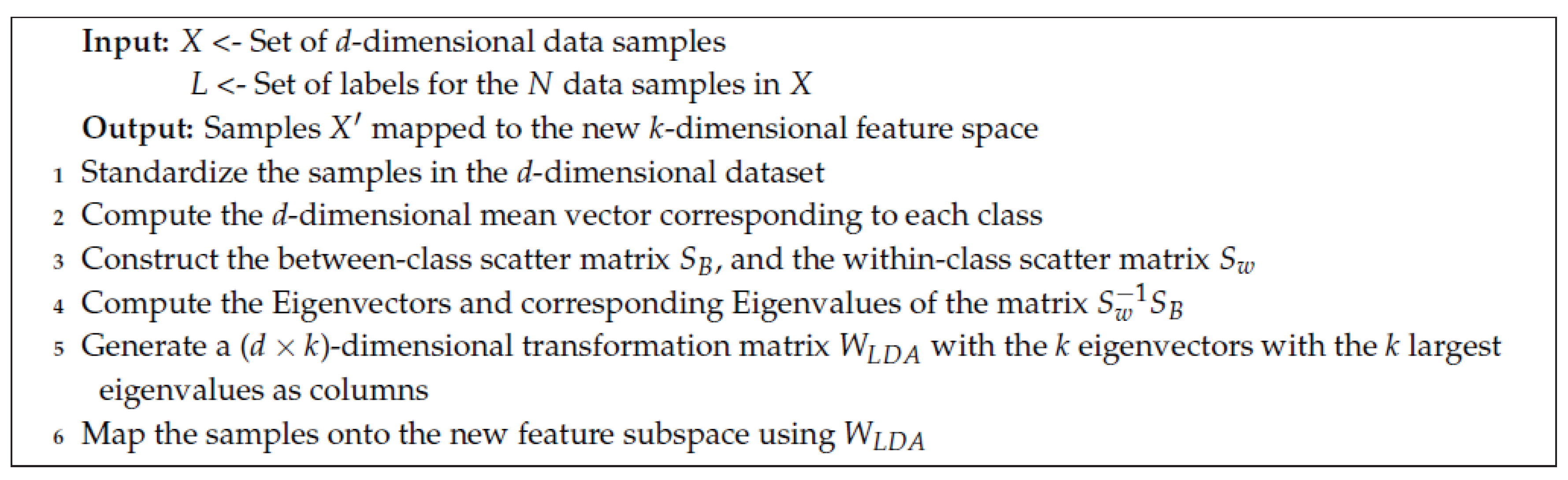
2.3. Linear Discriminant Analysis (LDA)
2.4. Independent Component Analysis (ICA)
2.5. Eigenvector Centrality Feature Selection (ECFS)
2.6. Multi Cluster Feature Selection (MCFS)
2.7. Classification for Fruit Sorting
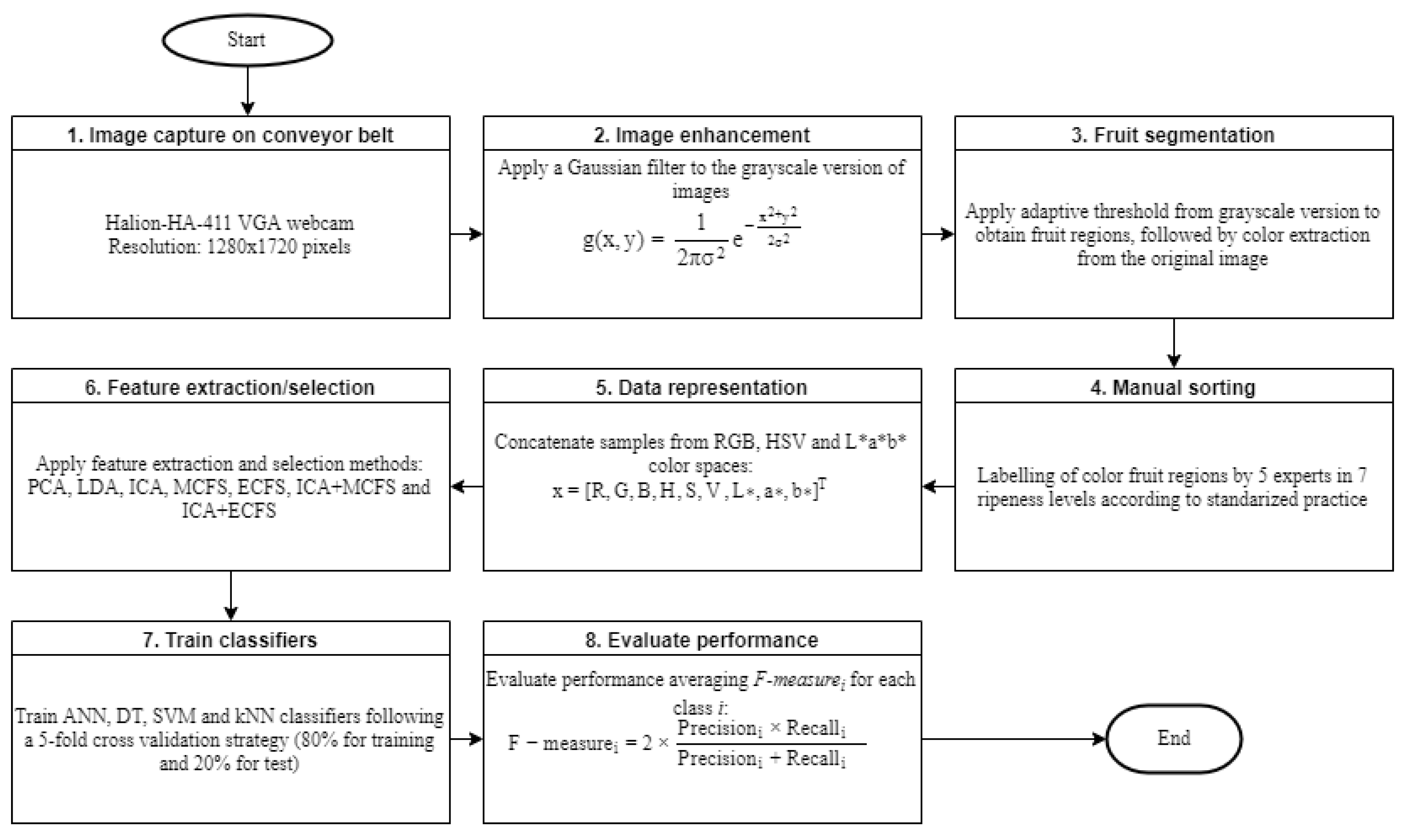
3. Materials and Methods
4. Experimental Results
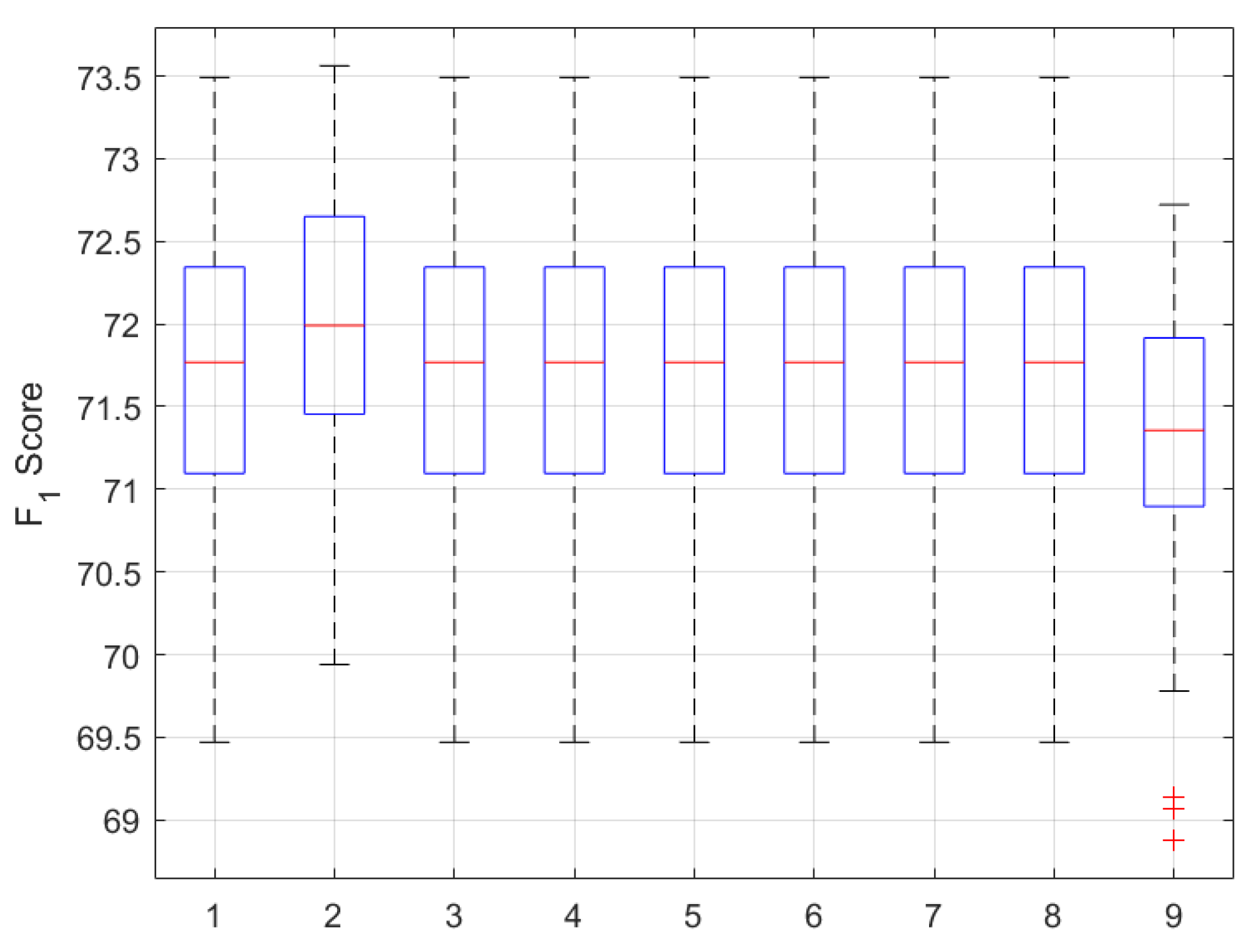
4.1. Analysis of Feature Spaces
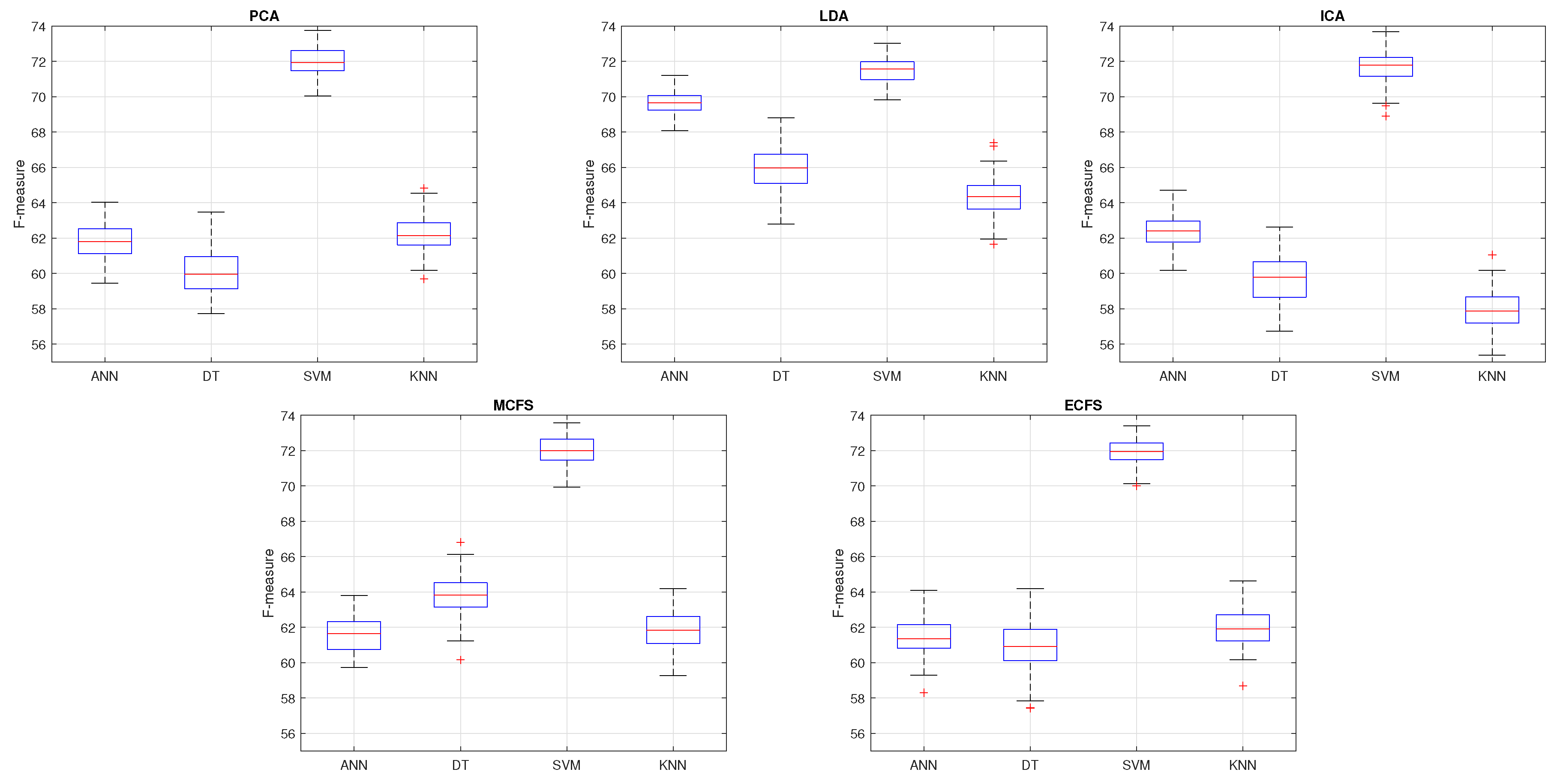
4.2. Performance across Classifiers
5. Conclusions and Future Work
Author Contributions
Funding
Conflicts of Interest
References
- Bader, F.; Rahimifard, S. Challenges for Industrial Robot Applications in Food Manufacturing. In Proceedings of the 2nd International Symposium on Computer Science and Intelligent Control, Stockholm, Sweden, 21–23 September 2018; ACM: New York, NY, USA, 2018; pp. 37:1–37:8. [Google Scholar]
- Zhang, B.; Huang, W.; Li, J.; Zhao, C.; Fan, S.; Wu, J.; Liu, C. Principles, developments and applications of computer vision for external quality inspection of fruits and vegetables: A review. Food Res. Int. 2014. [Google Scholar] [CrossRef]
- Castro, W.; Oblitas, J.; De-La-Torre, M.; Cotrina, C.; Bazan, K.; Avila-George, H. Classification of Cape Gooseberry Fruit According to its Level of Ripeness Using Machine Learning Techniques and Different Color Spaces. IEEE Access 2019. [Google Scholar] [CrossRef]
- De-la Torre, M.; Avila-George, H.; Oblitas, J.; Castro, W. Selection and Fusion of Color Channels for Ripeness Classification of Cape Gooseberry Fruits. In Trends and Applications in Software Engineering; Mejia, J., Muñoz, M., Rocha, Á., A. Calvo-Manzano, J., Eds.; Springer International Publishing: Berlin/Heidelberg, Germany, 2019; pp. 219–233. [Google Scholar]
- Nandi, C.; Tudu, B.; Koley, C. A machine vision-based maturity prediction system for sorting of harvested mangoes. IEEE Trans. Instrum. Meas. 2014. [Google Scholar] [CrossRef]
- Du, C.; Sun, D. Multi-classification of pizza using computer vision and support vector machine. J. Food Eng. 2008. [Google Scholar] [CrossRef]
- Taghadomi-Saberi, S.; Omid, M.; Emam-Djomeh, Z.; Faraji-Mahyari, K. Determination of cherry color parameters during ripening by artificial neural network assisted image processing technique. J. Agric. Sci. Technol. 2015, 17, 589–600. [Google Scholar]
- Abdulhamid, U.; Aminu, M.; Daniel, S. Detection of Soya Beans Ripeness Using Image Processing Techniques and Artificial Neural Network. Asian J. Phys. Chem. Sci. 2018. [Google Scholar] [CrossRef]
- Hadfi, I.; Yusoh, Z. Banana ripeness detection and servings recommendation system using artificial intelligence techniques. J. Telecommun. Electron. Comput. Eng. 2018, 10, 83–87. [Google Scholar]
- Schwarz, M.; Cowan, W.; Beatty, J. An Experimental Comparison of RGB, YIQ, LAB, HSV, and Opponent Color Models. ACM Trans. Graph. (TOG) 1987. [Google Scholar] [CrossRef]
- Bora, D.; Gupta, A.; Khan, F. Comparing the Performance of L*A*B* and HSV Color Spaces with Respect to Color Image Segmentation. Int. J. Emerg. Technol. Adv. Eng. 2015, 5, 192–203. [Google Scholar]
- Zou, X.; Zhao, J.; Li, Y. Apple color grading based on organization feature parameters. Pattern Recognit. Lett. 2007, 28, 2046–2053. [Google Scholar] [CrossRef]
- Cárdenas-Pérez, S.; Chanona-Pérez, J.; Méndez-Méndez, J.; Calderón-Domínguez, G.; López-Santiago, R.; Perea-Flores, M.; Arzate-Vázquez, I. Evaluation of the ripening stages of apple (Golden Delicious) by means of computer vision system. Biosyst. Eng. 2017, 159, 46–58. [Google Scholar] [CrossRef]
- Guerrero, E.; Benavides, G. Automated system for classifying Hass avocados based on image processing techniques. In Proceedings of the 2014 IEEE Colombian Conference on Communications and Computing, COLCOM 2014—Conference Proceedings, Bogota, Colombia, 4–6 June 2014. [Google Scholar] [CrossRef]
- Mendoza, F.; Aguilera, J. Application of Image Analysis for Classification of Ripening Bananas. J. Food Sci. 2004, 69, E471–E477. [Google Scholar] [CrossRef]
- Paulraj, M.; Hema, C.; Sofiah, S.; Radzi, M. Color recognition algorithm using a neural network model in determining the ripeness of a banana. In Proceedings of the International Conference on Man-Machine Systems, Penang, Malaysia, 26–27 August 2009; Universiti Malaysia Perlis: Perlis, Malaysia, 2009; pp. 2B71–2B74. [Google Scholar]
- Li, H.; Lee, W.; Wang, K. Identifying blueberry fruit of different growth stages using natural outdoor color images. Comput. Electron. Agric. 2014, 106, 91–101. [Google Scholar] [CrossRef]
- Pourdarbani, R.; Ghassemzadeh, H.; Seyedarabi, H.; Nahandi, F.; Vahed, M. Study on an automatic sorting system for Date fruits. J. Saudi Soc. Agric. Sci. 2015, 14, 83–90. [Google Scholar] [CrossRef] [Green Version]
- Damiri, D.; Slamet, C. Application of Image Processing and Artificial Neural Networks to Identify Ripeness and Maturity of the Lime (citrus medica). Int. J. Basic Appl. Sci. 2012, 1, 175–179. [Google Scholar] [CrossRef] [Green Version]
- Vélez-Rivera, N.; Blasco, J.; Chanona-Pérez, J.; Calderón-Domínguez, G.; de Jesús Perea-Flores, M.; Arzate-Vázquez, I.; Cubero, S.; Farrera-Rebollo, R. Computer Vision System Applied to Classification of “Manila” Mangoes During Ripening Process. Food Bioprocess Technol. 2014, 7, 1183–1194. [Google Scholar] [CrossRef]
- Zheng, H.; Lu, H. A least-squares support vector machine (LS-SVM) based on fractal analysis and CIELab parameters for the detection of browning degree on mango (Mangifera indica L.). Comput. Electron. Agric. 2012, 83, 47–51. [Google Scholar] [CrossRef]
- Fadilah, N.; Mohamad-Saleh, J.; Halim, Z.; Ibrahim, H.; Ali, S. Intelligent color vision system for ripeness classification of oil palm fresh fruit bunch. Sensors 2012, 12, 14179–14195. [Google Scholar] [CrossRef]
- Elhariri, E.; El-Bendary, N.; Hussein, A.; Hassanien, A.; Badr, A. Bell pepper ripeness classification based on support vector machine. In Proceedings of the 2nd International Conference on Engineering and Technology, Cairo, Egypt, 19–20 April 2014; pp. 1–6. [Google Scholar] [CrossRef]
- Mohammadi, V.; Kheiralipour, K.; Ghasemi-Varnamkhasti, M. Detecting maturity of persimmon fruit based on image processing technique. Sci. Hortic. 2015, 184, 123–128. [Google Scholar] [CrossRef]
- El-Bendary, N.; El Hariri, E.; Hassanien, A.; Badr, A. Using machine learning techniques for evaluating tomato ripeness. Expert Syst. Appl. 2015, 42, 1892–1905. [Google Scholar] [CrossRef]
- Goel, N.; Sehgal, P. Fuzzy classification of pre-harvest tomatoes for ripeness estimation–An approach based on automatic rule learning using decision tree. Appl. Soft Comput. 2015, 36, 45–56. [Google Scholar] [CrossRef]
- Polder, G.; Van der Heijden, G. Measuring ripening of tomatoes using imaging spectrometry. In Hyperspectral Imaging for Food Quality Analysis and Control; Elsevier: Amsterdam, The Netherlands, 2010; pp. 369–402. [Google Scholar] [CrossRef]
- Rafiq, A.; Makroo, H.; Hazarika, M. Neural Network-Based Image Analysis for Evaluation of Quality Attributes of Agricultural Produce. J. Food Process. Preserv. 2016, 40, 1010–1019. [Google Scholar] [CrossRef]
- Shah Rizam, M.S.; Farah Yasmin, A.R.; Ahmad Ihsan, M.Y.; Shazana, K. Non-destructive watermelon ripeness determination using image processing and artificial neural network (ANN). Int. J. Electr. Comput. Eng. 2009, 3, 332–336. [Google Scholar]
- Abdullah, N.; Madzhi, N.; Yahya, A.; Rahim, A.; Rosli, A. ANN Diagnostic System for Various Grades of Yellow Flesh Watermelon based on the Visible light and NIR properties. In Proceedings of the 2018 4th International Conference on Electrical, Electronics and System Engineering (ICEESE), Kuala Lumpur, Malaysia, 8–9 November 2018; pp. 70–75. [Google Scholar] [CrossRef]
- Syazwan, N.; Rizam, M.; Nooritawati, M. Categorization of watermelon maturity level based on rind features. Procedia Eng. 2012, 41, 1398–1404. [Google Scholar] [CrossRef] [Green Version]
- Skolik, P.; Morais, C.; Martin, F.; McAinsh, M. Determination of developmental and ripening stages of whole tomato fruit using portable infrared spectroscopy and Chemometrics. BMC Plant Biol. 2019, 19, 236. [Google Scholar] [CrossRef] [PubMed]
- Du, D.; Wang, J.; Wang, B.; Zhu, L.; Hong, X. Ripeness Prediction of Postharvest Kiwifruit Using a MOS E-Nose Combined with Chemometrics. Sensors 2019, 19, 419. [Google Scholar] [CrossRef] [Green Version]
- Ramos, P.; Avendaño, J.; Prieto, F. Measurement of the ripening rate on coffee branches by using 3d images in outdoor environments. Comput. Ind. 2018, 99, 83–95. [Google Scholar] [CrossRef]
- Hyvärinen, A.; Erkki, O. Independent component analysis: Algorithms and applications. Neural Netw. 2000, 13, 411–430. [Google Scholar] [CrossRef] [Green Version]
- Roffo, G.; Melzi, S. Ranking to learn. In Proceedings of the International Workshop on New Frontiers in Mining Complex Patterns, Riva del Garda, Italy, 19 September 2016; Springer: Cham, Switzerland, 2016; pp. 19–35. [Google Scholar] [CrossRef]
- Cai, D.; Zhang, C.; He, X. Unsupervised feature selection for multi-cluster data. In Proceedings of the 16th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Washington, DC, USA, 25–28 July 2010; ACM: New York, NY, USA, 2010; pp. 333–342. [Google Scholar] [CrossRef] [Green Version]
- Duda, R.; Hart, P.; Stork, D. Pattern Classification; Wiley & Sons: New York, NY, USA, 2001. [Google Scholar]
- Pedreschi, F.; Leon, J.; Mery, D.; Moyano, P. Development of a computer vision system to measure the color of potato chips. Food Res. Int. 2006, 39, 1092–1098. [Google Scholar] [CrossRef]
- Fischer, G.; Miranda, D.; Piedrahita, W.; Romero, J. Avances en Cultivo, Poscosecha y Exportación de la Uchuva Physalis peruviana L.; Universidad Nacional de Colombia: Bogotá, Colombia, 2005. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Item | Colorspace | Classification Method | Accuracy | Ref |
|---|---|---|---|---|
| Apple | HSI | SVM | 95 | [12] |
| Apple | L*a*b* | MDA | 100 | [13] |
| Avocado | RGB | K-Means | 82.22 | [14] |
| Banana | L*a*b* | LDA | 98 | [15] |
| Banana | RGB | ANN | 96 | [16] |
| Blueberry | RGB | KNN and SK-Means | 85-98 | [17] |
| Date | RGB | K-Means | 99.6 | [18] |
| Lime | RGB | ANN | 100 | [19] |
| Mango | RGB | SVM | 96 | [5] |
| Mango | L*a*b* | MDA | 90 | [20] |
| Mango | L*a*b* | LS-SVM | 88 | [21] |
| Oil palm | L*a*b* | ANN | 91.67 | [22] |
| Pepper | HSV | SVM | 93.89 | [23] |
| Persimmon | RGB + L*a*b* | QDA | 90.24 | [24] |
| Tomato | HSV | SVM | 90.8 | [25] |
| Tomato | RGB | DT | 94.29 | [26] |
| Tomato | RGB | LDA | 81 | [27] |
| Tomato | L*a*b* | ANN | 96 | [28] |
| Watermelon | YCbCr | ANN | 86.51 | [29] |
| Soya | HSI | ANN | 95.7 | [8] |
| Banana | RGB | Fuzzy logic | NA | [9] |
| Banana | RGB | CNN | 87 | [9] |
| Watermelon | VIS/NIR | ANN | 80 | [30] |
| Watermelon | RGB | ANN | 73.33 | [31] |
| Tomato | FTIR | SVM | 99 | [32] |
| Kiwi | Chemometrics MOS E-nose | PLSR, SVM, RF | 99.4 | [33] |
| Coffee | RGB + L*a*b* + Luv + YCbCr + HSV | SVM | 92 | [34] |
| Cape Gooseberry | RGB + HSV + L*a*b* | ANN, DT, SVM and KNN | 93.02 | [3,4] |
| Method | 1D | 2D | 3D | 4D | 5D | 6D | 7D | 8D | 9D |
|---|---|---|---|---|---|---|---|---|---|
| PCA | 40.89 | 68.56 | 69.48 | 71.23 | 71.83 | 71.69 | 71.99 | 71.70 | 71.65 |
| (0.34) | (0.91) | (0.95) | (0.82) | (0.92) | (0.70) | (0.81) | (0.92) | (0.91) | |
| LDA | 52.43 | 69.10 | 69.48 | 70.05 | 70.02 | 71.48 | - | - | - |
| (0.81) | (1.24) | (1.17) | (1.00) | (1.05) | (0.74) | - | - | - | |
| ICA | 8.12 | 25.21 | 53.89 | 58.93 | 62.18 | 63.74 | 68.10 | 70.38 | 71.67 |
| (0.40) | (0.45) | (1.16) | (1.12) | (1.16) | (1.02) | (0.91) | (0.87) | (0.90) | |
| MCFS − 2 clusters | 64.74 | 65.67 | 70.04 | 70.72 | 71.02 | 71.92 | 71.99 | 71.83 | 71.66 |
| (0.70) | (0.68) | (1.13) | (1.04) | (0.96) | (0.76) | (0.79) | (0.89) | (0.87) | |
| Color channel | L*(7) | V(6) | H(4) | b*(9) | R(1) | G(2) | B(3) | S(5) | a*(8) |
| ECFS | 40.93 | 68.81 | 69.55 | 71.33 | 71.89 | 71.76 | 71.86 | 71.84 | 71.66 |
| (0.32) | (1.18) | (1.2) | (0.72) | (0.72) | (0.79) | (0.83) | (0.79) | (0.87) | |
| Color channel | G(2) | R(1) | a*(9) | b*(8) | H(4) | L*(7) | S(5) | V(6) | B(3) |
| ICA + ECFS | 23.21 | 25.18 | 28.82 | 36.14 | 51.84 | 51.70 | 61.22 | 62.71 | 71.67 |
| (0.41) | (0.46) | (0.54) | (0.71) | (0.79) | (0.74) | (0.73) | (0.75) | (0.90) | |
| IC | 2 | 1 | 9 | 8 | 4 | 7 | 5 | 6 | 3 |
| ICA + MCFS | 26.61 | 44.68 | 57.24 | 61.13 | 61.81 | 63.07 | 65.14 | 68.57 | 71.67 |
| (0.57) | (1.07) | (1.08) | (1.09) | (1.15) | (1.26) | (1.14) | (0.84) | (0.90) | |
| IC | 3 | 2 | 4 | 8 | 9 | 1 | 6 | 5 | 7 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
De-la-Torre, M.; Zatarain, O.; Avila-George, H.; Muñoz, M.; Oblitas, J.; Lozada, R.; Mejía, J.; Castro, W. Multivariate Analysis and Machine Learning for Ripeness Classification of Cape Gooseberry Fruits. Processes 2019, 7, 928. https://doi.org/10.3390/pr7120928
De-la-Torre M, Zatarain O, Avila-George H, Muñoz M, Oblitas J, Lozada R, Mejía J, Castro W. Multivariate Analysis and Machine Learning for Ripeness Classification of Cape Gooseberry Fruits. Processes. 2019; 7(12):928. https://doi.org/10.3390/pr7120928
Chicago/Turabian StyleDe-la-Torre, Miguel, Omar Zatarain, Himer Avila-George, Mirna Muñoz, Jimy Oblitas, Russel Lozada, Jezreel Mejía, and Wilson Castro. 2019. "Multivariate Analysis and Machine Learning for Ripeness Classification of Cape Gooseberry Fruits" Processes 7, no. 12: 928. https://doi.org/10.3390/pr7120928
APA StyleDe-la-Torre, M., Zatarain, O., Avila-George, H., Muñoz, M., Oblitas, J., Lozada, R., Mejía, J., & Castro, W. (2019). Multivariate Analysis and Machine Learning for Ripeness Classification of Cape Gooseberry Fruits. Processes, 7(12), 928. https://doi.org/10.3390/pr7120928