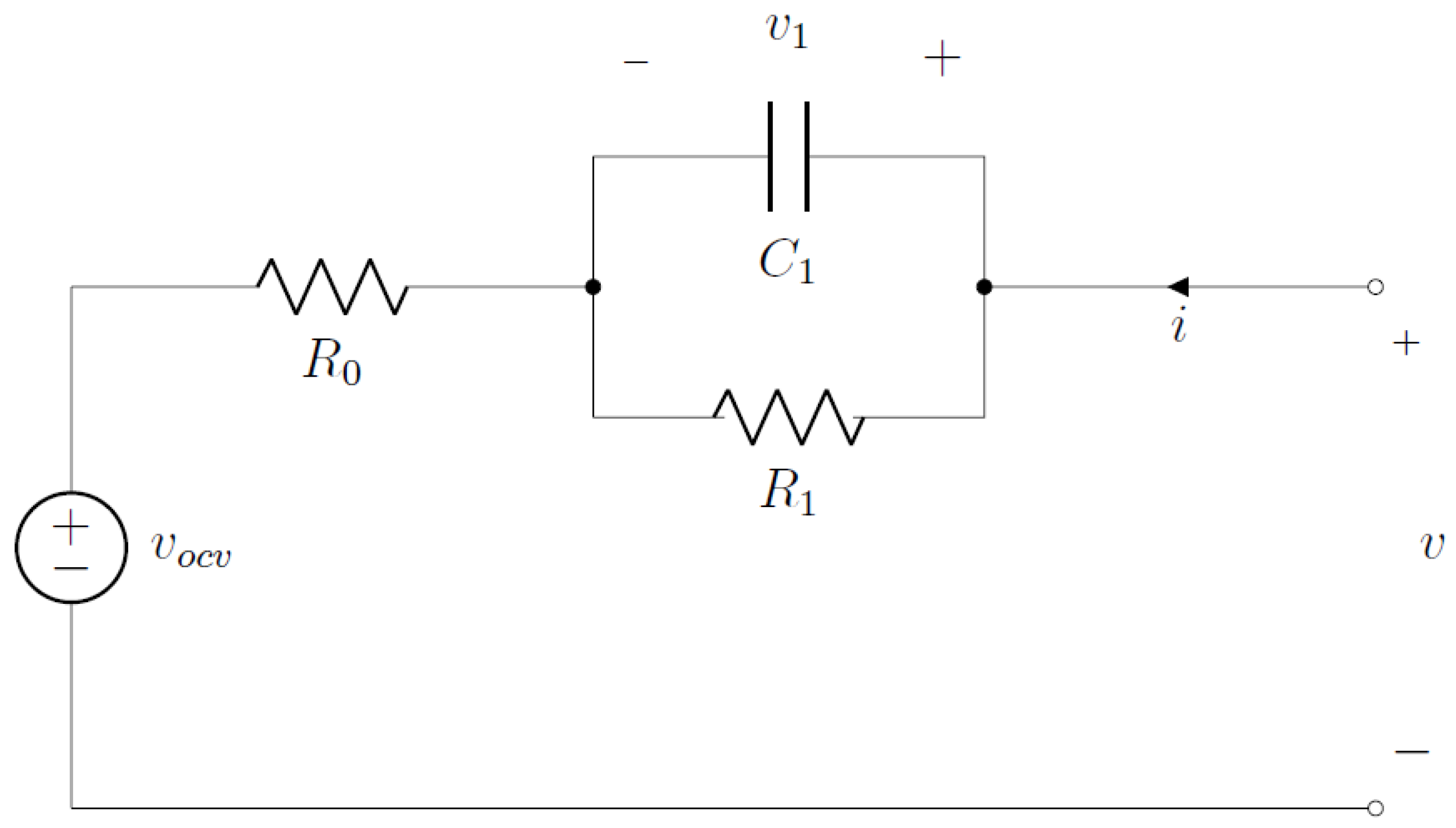
Within this section, we look at the CC framework based on the gPC approximation within the OCP that should approximate the probability of not being the failure event, i.e.,
. In
Section 3.1, the general formulation of CCs in the deterministic OCP is introduced. Afterwards,
Section 3.2 introduces a differentiable approximation of the sharp CCs and a homotopy strategy to iteratively sharpen the differentiable CC representation. The SubSim method and its incorporation within CC–OC to calculate rare-event failure probabilities are described in
Section 3.3.
3.1. Derivation of Chance Constraint Formulation
Sampling techniques such as the Metropolis–Hastings algorithm (MHA) [
21] or importance sampling [
22] are frequently used to approximate the probability of an event (in this case: fulfilling a CC) when its pdf is difficult to sample from or integrate. A drawback of these methods is a non-deterministic evaluation procedure of the probability. Generally, this study still tries to apply sampling-based algorithms to estimate the probability
in the OCP (Equation (6)). Additionally, rare events should be covered, which makes SubSim a viable choice [
12]. The basic SubSim method uses a modified Metropolis–Hastings algorithm (MMHA), i.e., random sampling, to explore the failure region and calculate the failure probability. Here, a further issue arises when using direct methods to solve OCPs with Newton-type NLP solvers: the samples cannot be redrawn in each iteration of the NLP solution process as this would yield a stochastic Newton-type optimization procedure. Generally, this would be necessary in the context of sampling techniques, such as SubSim, which ultimately results in problems defining accurate step-sizes and exit criteria in the NLP. Thus, this study uses a homotopy strategy to cope with these issues that move the creation of new samples from the NLP iteration to a homotopy step.
In order to apply the mentioned sampling techniques, we need a good approximation for the probabilistic quantity, i.e., the quantity with respect to whom the CC is defined, depending on the stochastic disturbance. When applying gPC, the gPC expansion in Equation (3) provides this approximation. Thus, in cases where the expansion coefficients are available within the NLP, as e.g., in Equation (6) (remember that Equations (2), (3) and (5) can be applied to calculate the expansions coefficients for any output quantity based on the known physical trajectories at the SC nodes for the states used in Equation (6)), we can sample the gPC expansion for thousands of samples via a matrix-vector operation in an MCA-type way, but with improved efficiency due to the simple evaluation as follows: consider
random samples obtained from the pdf of
, labeled
. It should be noted that these samples can now be drawn randomly in contrast to the SC method as we are not trying to approximate the integral in Equation (4), but the probability of the CC. These samples for the uncertain parameters yield corresponding samples for the output
, given by:
such that the output samples are provided from a simple matrix-vector multiplication operating on the expansion coefficients
, which are part of the OCP formulation due to Equations (2), (3) and (5). With the samples available from Equation (10), the general equation for fulfilling, i.e., not being in the failure set, a CC is given as follows:
Here,
is the indicator function, defined as:
It should be noted that the indicator function
is trivial to evaluate but non-differentiable, and can therefore create difficulties when used in the context of a Newton-type NLP solver. Thus, we introduce a smooth approximation
s of the indicator functions having the following properties:
3.2. Approximation of Chance Constraints by Sigmoids
A group of functions that can be used for the approximation of an indicator function that must fulfill the conditions given in Equation (13) are the logistics functions. An example for this class of functions is the sigmoid function, which is defined as follows for a scalar output
y:
The parameters
and
are the scaling and offset parameter of the sigmoid, respectively. These are used to shape the sigmoid in order to suitably approximate the desired CC domain. Their design using a homotopy strategy while solving the CC–OC problem is illustrated in Algorithm 1.
| Algorithm 1 Implemented homotopy strategy for sigmoid scaling and offset parameter in CC–OC framework. |
Require: Define the homotopy factor and the desired final sigmoid parameter .
- 1:
Initialize sigmoid parameter a and confidence level . - 2:
Define the bound value of the sigmoid (i.e., the bound value of the CC) - 3:
whiledo - 4:
Calculate the sigmoid values: - 5:
- 6:
- 7:
Solve the CC–OC problem including SubSim in Algorithm 4. - 8:
Increase a by homotopy factor: . - 9:
end while - 10:
return Robust optimal trajectory.
|
Furthermore, the sigmoid in Equation (14) has a very simple derivative that can be used to efficiently calculate the gradient that is necessary for OC. It is given as follows:
The sigmoid in Equation (14) can be combined by multiplication in order to approximate the indicator function for
being an interval in
. This is depicted in
Figure 1, which shows the multiplication of two sigmoids (solid blue) with one gradual descend (dashed green; number 1) and one steep ascend (dashed red; number 2) to approximate a box constraint on a scalar output. Here, one sigmoid
describes the lower bound, while the other sigmoid
describes the upper bound.
For the sake of simplicity, we further assume box constraints on all our CCs, i.e., we assume that is a hyper-rectangle with lower and upper bounds on dimension . This is a viable assumption for most OCP applications, as box constraints are very prominent in OC. The proposed approach can be trivially extended to any set that can be described by a set of smooth inequality constraints.
We can then form the hyper-rectangle by applying the basic sigmoid in Equation (14) as follows:
Here,
and
are simplifying notations. Take into account that the derivative of Equation (16) can be formed using the chain rule and Equation (15).
In order to calculate the probability, we must only sum up the function values of the multidimensional sigmoid in Equation (16) and divide it by the number of samples as follows:
This approximation can now be used within the OCP (Equation (6)). In order to include rare failure events, the next subsection introduces the SubSim method that elaborates on the CC modeling of this subsection.
3.3. Subset Simulation in Chance-Constrained Optimal Control
The probability approximation in Equations (11) and (17) converges for reasonably low choices of
only if rather loose bounds on the probability (e.g., domain of
) are considered. For tighter bounds typically used for rare events, as often required in e.g., reliability engineering (where
is common), better suited algorithms to calculate and sample the probability are required. Indeed, a reliable estimation of the probability of rare events normally requires a very large number of samples. A classical approach to circumvent this difficulty is the use of SubSim, which is tailored to evaluate the probability of rare events [
11,
12,
23].
SubSim methods are based on an MCMC algorithm typically relying on a MMHA, which ensures that the failure region is properly covered by the samples. To that end, it stratifies the choice of samples iteratively in order to draw significantly more samples from the failure region than a classical MCA sampling would. SubSim methods are based on an expansion of the failure probability as a series of conditional probabilities:
In Equation (18),
is the set of failure events and
is a sequence of set of events with decreasing probability of occurrence. The conditional probability
describes the probability that an event in
occurs assuming that an event in
has already occurred. Thus, instead of evaluating the rare event
, one can evaluate a chain of relatively likely conditional probabilities
, each of which is relatively easy to evaluate via sampling.
The evaluation of the conditional probabilities is the main task in SubSim, achieved using e.g., the MMHA approach. The MMHA, working on each component of a random vector (i.e., vector of one–dimensional random variables) (RVec), is introduced in Algorithm 2 [
11,
12,
24].
| Algorithm 2 Modified Metropolis–Hastings algorithm for subset simulation for each component of the random vector to create new sample for random parameter (after [11]). |
Require: Current sample for the random parameter: .- 1:
Define a symmetric proposal pdf, , centered around the current random sample . - 2:
Generate candidate sample from and calculate the system response (e.g., by Equations (1), (3), or (6)) of this candidate. - 3:
Calculate the ratio between the proposed and the candidate sample evaluated at the target pdf, e.g., with (this is the stationary pdf according to the central limit theorem ([ 17], p. 23)). - 4:
Set the acceptance ratio of the candidate sample as follows: and accept it with this probability. - 5:
Draw a random sample from the uniform distribution as follows: . - 6:
ifthen - 7:
Set: - 8:
else - 9:
Set: - 10:
end if - 11:
Update the new sample by the rule: - 12:
ifthen - 13:
Set: - 14:
else - 15:
Set: - 16:
end if - 17:
return New sample for the random parameter: .
|
Normally, the MCMC algorithm based on the MMHA in Algorithm 2 is fast converging as especially the sampling of new candidates is done locally around the current sample point. Thus, the acceptance rate is normally very high and progress is made quite fast. An issue of the MMHA is the choice of an appropriate proposal distribution
. Here, generally a Uniform or a Gaussian pdf is chosen, in order to have a simple evaluation and the symmetric property. The general behavior of the MMHA in SubSim can be visualized as in
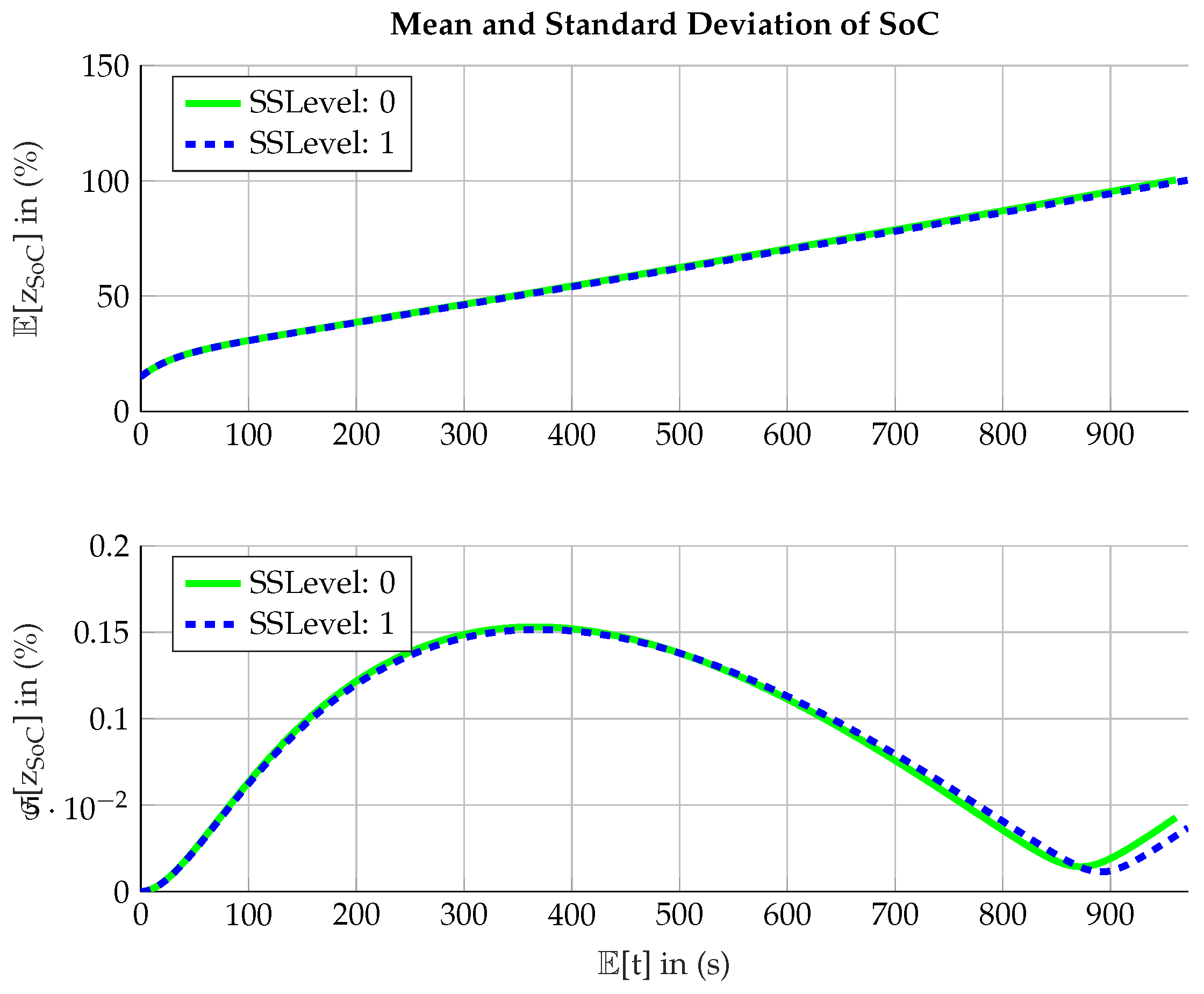
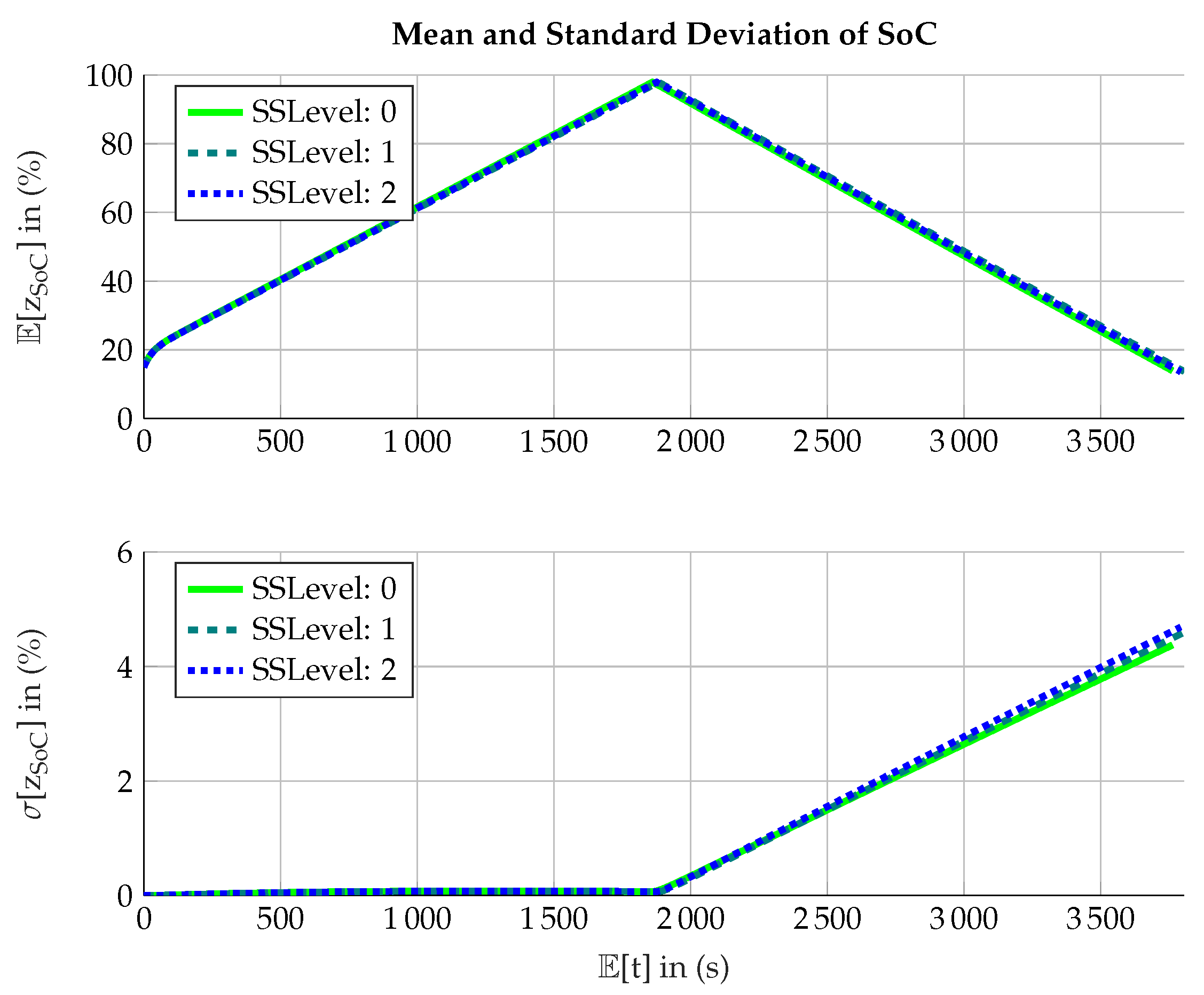
Figure 2: it can be seen that after the random sampling by MCA in level 0, the samples get shifted to the failure domain, which are the arcs in the corners of the domain. This is done until a sufficient amount of samples is located in the failure domain.
We detail the SubSim method as in Algorithm 3 [
11,
12]. The SubSim starts with a general MCA and afterwards subsequently evaluates the failure region yielding the chain of conditional probabilities. It should be noted that the choice of the intermediate failure events
is critical for the convergence speed of the SubSim. In [
11], the “critical demand-to-capacity ratio” is introduced that is based on normalized intermediate threshold values. Based on this ratio, it is common to choose the thresholds adaptively such that the conditional probabilities are equal to a fixed, pre-defined value ([
12], p. 158). This is done by appropriately ordering the previous samples and their result. An often and a normally very efficient conditional probability value is
[
11].
Finally, we can estimate the failure probability of the SubSim regarding the desired threshold
b and the
Markov chain element, which is the last one of the SubSim as follows ([
12], p. 179) (see Algorithm 3 line 12):
| Algorithm 3 General algorithm used for a subset simulation in connection with generalized polynomial chaos (after [12], p. 158ff). |
Require: Define the number of samples per level , the conditional probability , and the critical threshold b.- 1:
Calculate the number of Markov chains and the number of samples for each of the chains. - 2:
Initialize the SubSim by creating the random sample set . - 3:
Calculate the output set by Equation (3) related to . - 4:
Sort in ascending order to create . Here, is an estimate of the exceedance probability . - 5:
Set and corresponding to as the threshold and the seeds for the next level. - 6:
for i=1...m-1 do - 7:
Use e.g., the MMHA (Algorithm 2) to generate the samples of the conditional pdf for each seed . This creates Markov chains with samples. - 8:
Calculate the output set by Equation (3) related to . - 9:
Sort in ascending order to create . Here, is an estimate of the exceedance probability . - 10:
Set and corresponding to as the threshold and the seeds for the next level. - 11:
end for - 12:
Calculate the failure probability based on Equation (19) - 13:
return Failure probability .
|
It should be noted that, for the OCP in Equation (1) or Equation (6), the calculated probability in Equation (19) must be subtracted from 1 as the CC in Equation (6) is defined for not being in the failure set. Here,
is the complementary indicator function from Equation (12) defined for the failure region:
Take into account that the accuracy of Equation (19) can be quantified using the coefficient of variation (c.o.v.):
Here,
is given by Equation (19), while the standard deviation of the failure probability can be calculated by a Beta pdf fit as proposed in ([
25], p. 293). Overall, we can compare the resulting c.o.v. with literature values [
24] to access the viability. Generally, a small c.o.v. indicates that the standard deviation of our failure probability estimation is smaller than our expected/mean value. Thus, the goal is to have a small c.o.v. as then the dispersion of the data is small and we can be certain about the CC being fulfilled.
In this study, we propose to introduce the SubSim algorithm in the CC–OC algorithm. Our procedure is to calculate the subset samples based on the analytic response surface of the gPC expansion (Equation (3)), which is based on the initial solution of the OCP (Equation (1)) by MCA. The samples are then used to run a new optimization fulfilling the desired rare event probability. A new response surface is calculated from which new samples are generated using a SubSim. This procedure is repeated until both the SubSim probability (Equation (19)) as well as the probability level assigned to the constraint (Equation (6)) in the OCP fulfill the desired rare event probability . The procedure is described in Algorithm 4. It should be noted that this procedure can generally be applied as long as the underlying OCP in Equation (6) can be solved.
| Algorithm 4 Basic strategy of the subset simulation algorithm within CC–OC framework. |
Require: OCP as in Equation (6) with initial guess for decision variables .- 1:
Calculate an optimal solution for a likely failure (e.g., ) using MCA. - 2:
Obtain the subset probability and samples, based on the analytic gPC response surface (Equation (3)) and by applying Algorithm 3. - 3:
whiledo - 4:
Assign the SubSim samples to the evaluation routine of the CC within the OCP. - 5:
Solve the CC–OC problem (Equation (6)). - 6:
if Optimization not successful then - 7:
Reduce the probability of the constraint to relax the OCP (e.g., by factor of 10). - 8:
else - 9:
if then - 10:
Increase the constraint probability within the OCP (e.g., factor of 10). - 11:
end if - 12:
end if - 13:
Obtain the new subset probability from Equation (19) and samples based on the new analytic gPC response surface and using Algorithm 3. - 14:
end while - 15:
return Optimal decision variables .
|
Regarding the homotopy strategy, it should be noted that, by using the SubSim samples calculated from the last optimal solution within the new optimization, we might introduce a bias as the samples drawn from the Markov chain are based on the optimal results created by the last NLP solution. Generally, they would have to adapted in each iteration of the NLP as the system response changes. As we do not update the samples within the NLP, but within the homotopy step after the optimal solution has been calculated, we technically solve the CC and its rare event probability using biased samples compared to the ones that would be calculated within the SubSim. We cope with this issue in this paper by checking the fulfillment of the CC both in the OCP as well as after the OCP is solved by the SubSim, i.e., with the new response surface. Thus, the CC–OC is only solved if both results show that the CC is fulfilled to the desired level. Within this paper, the OCP converges fine, but further studies should explore the effects and influences of this bias and how to reduce it (e.g., by importance sampling).
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}