Scheduling Two Identical Parallel Machines Subjected to Release Times, Delivery Times and Unavailability Constraints



Abstract
:1. Introduction
2. Problem Description
- Each machine can process only one job at a time, and all jobs are non-preemptive.
- If machine is unavailable (down for a PM action), it will not be capable of processing jobs until is finished.
- PM activities can be done early (before the end of the period ), but for the possibility of failure occurring, they cannot be delayed.
- The machines are available for processing again after the unavailable period (PM activity).
- The release time , delivery time , and processing time for each job are known in advance.
- The availability and unavailability periods of a particular machine are deterministic and known in advance.
- : number of jobs;
- : number of machines;
- : job’s index ();
- : machine’s index ();
- : processing time of job ;
- : release time of job ;
- : delivery time of job ;
- : starting time for processing job ;
- : machine available time;
- : machine unavailable time, the required time to perform a PM action;
- : completion time of job , ;
- : maximum completion time, max ().
3. Genetic Algorithm
3.1. Chromosome Encoding
3.2. Initial Population
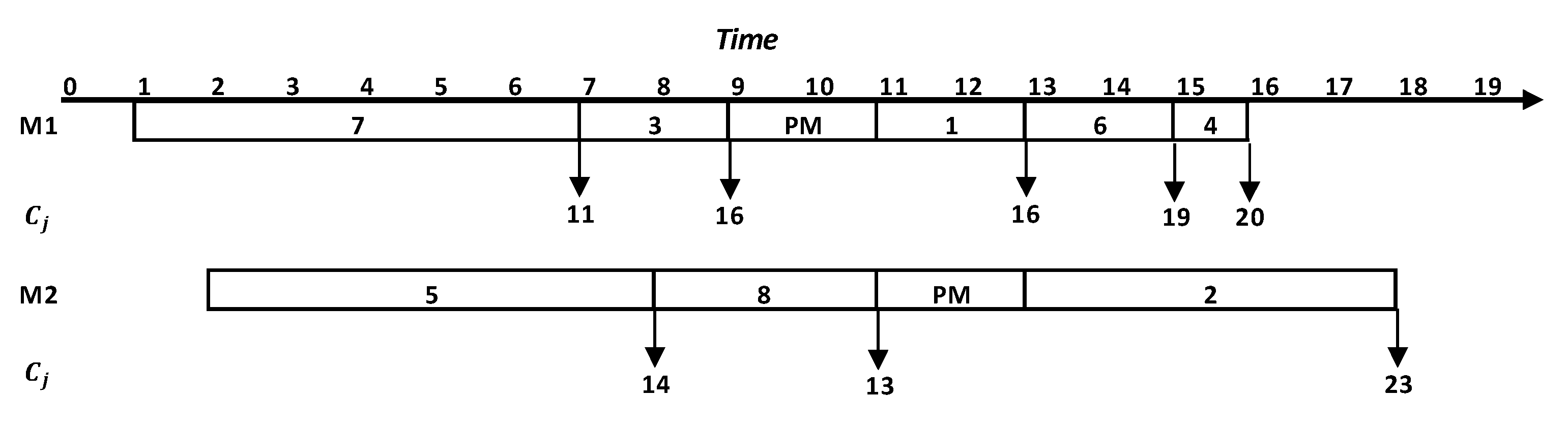
3.3. Chromosome Evaluation
3.4. Selection and Reproduction Process
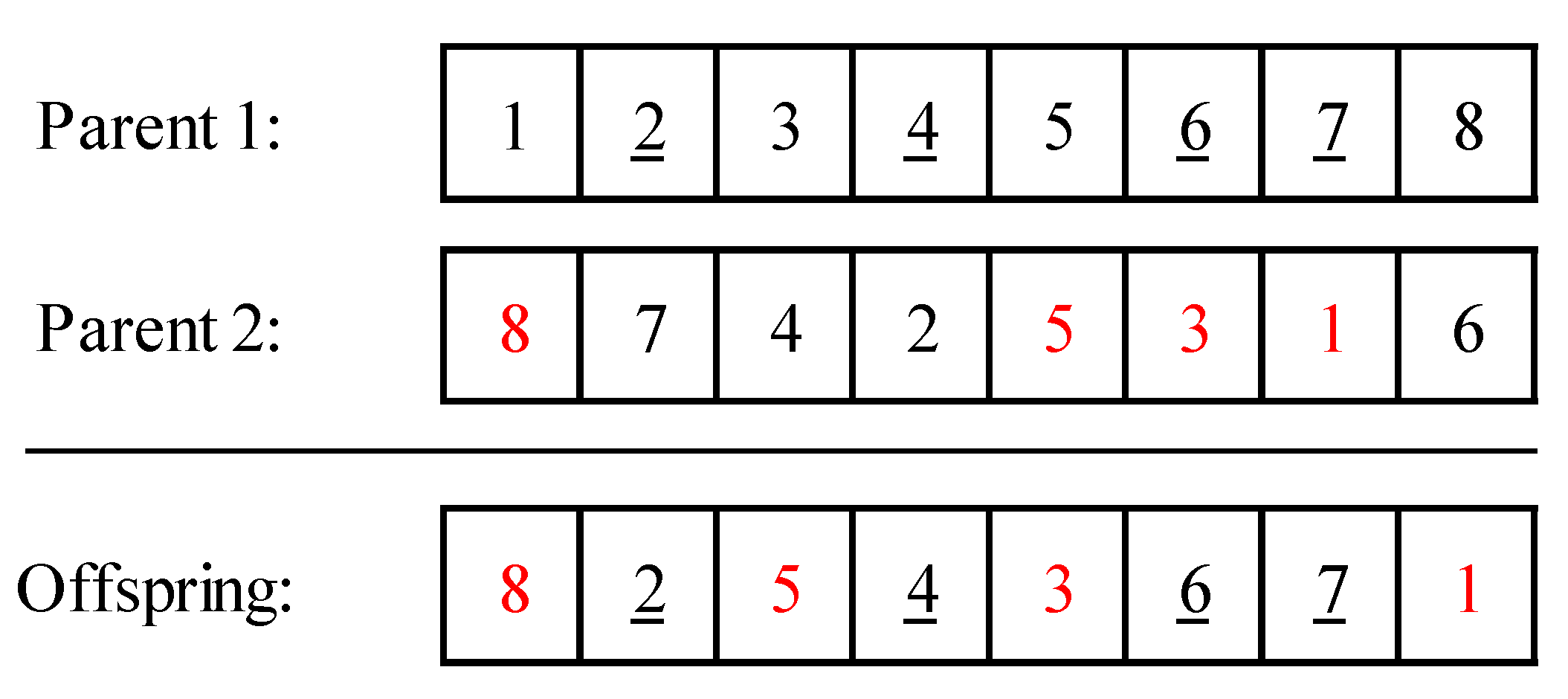
3.5. Crossover
| Procedure 1 Chromosome Evaluation | ||||
| 1 | Inputs: | |||
| is the number of jobs; is the number of machines, which is 2; are the processing times of each job; are the ready times of each job; are the delivery times of each job; is the machine available time; is the machine unavailable time; is the generated sequence (randomly generated as explained in Section 3.2); | ||||
| 2 | For , | |||
| ; and is the assigned machine; If is the 1st job in the assigned machine : | ||||
| If machine age + ; %% No PM action | ||||
| machine age = machine age + ; ; ; machine availability = ; | ||||
| Else%% PM action is required | ||||
| machine availability; ; machine availability = ; machine age = ; ; ; machine availability = ; | ||||
| End (if); | ||||
| Else | ||||
| If machine age + ; %% No PM action | ||||
| machine age = machine age + ; ; ; machine availability = ; | ||||
| Else%% PM action is required | ||||
| machine availability; ; machine availability = ; machine age = ; ; ; machine availability = ; | ||||
| End (if); | ||||
| End (if); | ||||
| End (for); | ||||
| 3 | Output: ; | |||
3.6. Mutation
3.7. Replacement and Termination Condition
4. Experimental Design
4.1. Indicator of the Evaluation
4.2. Description of Test Instances
4.3. Response Surface Methodology
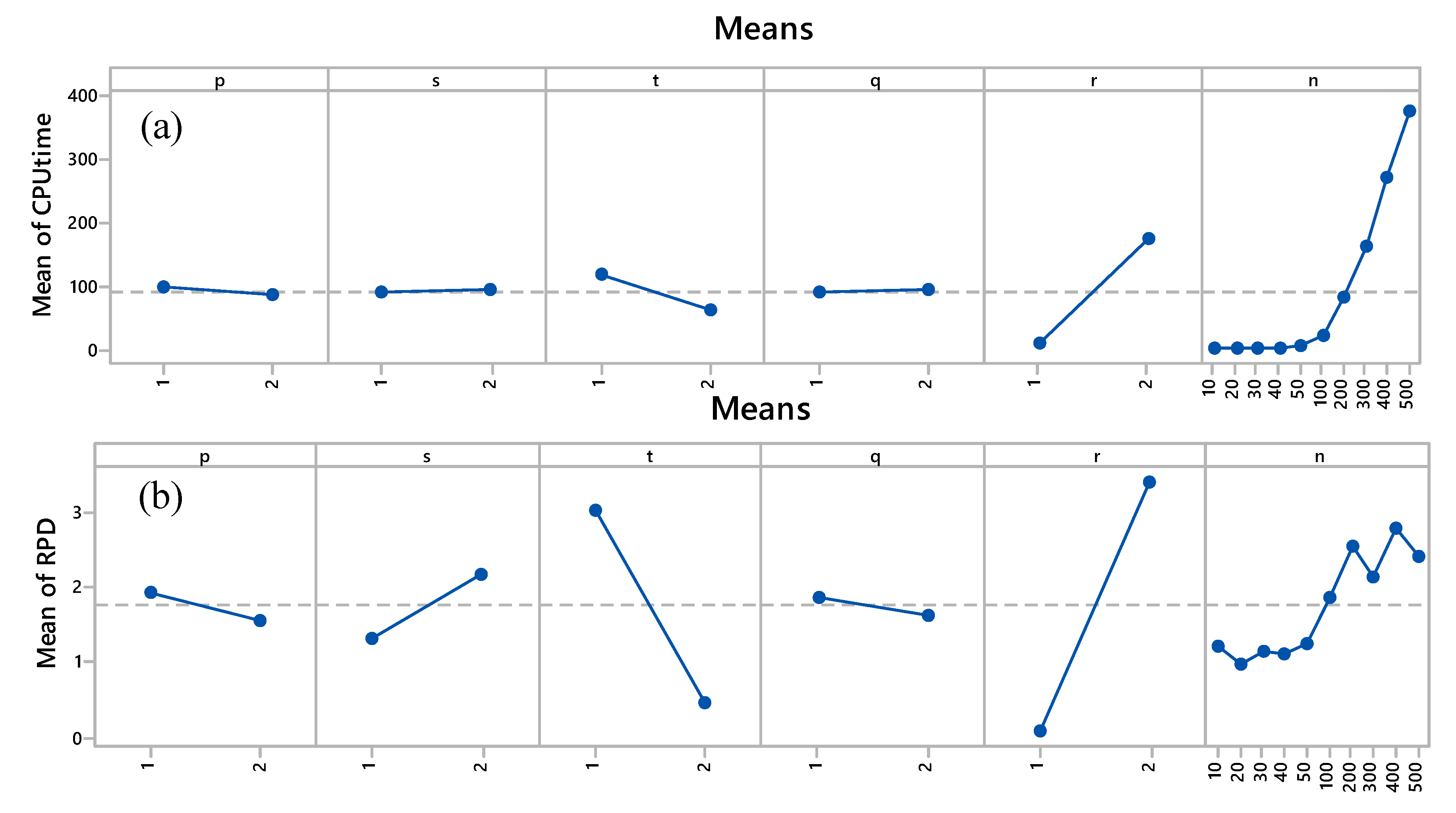
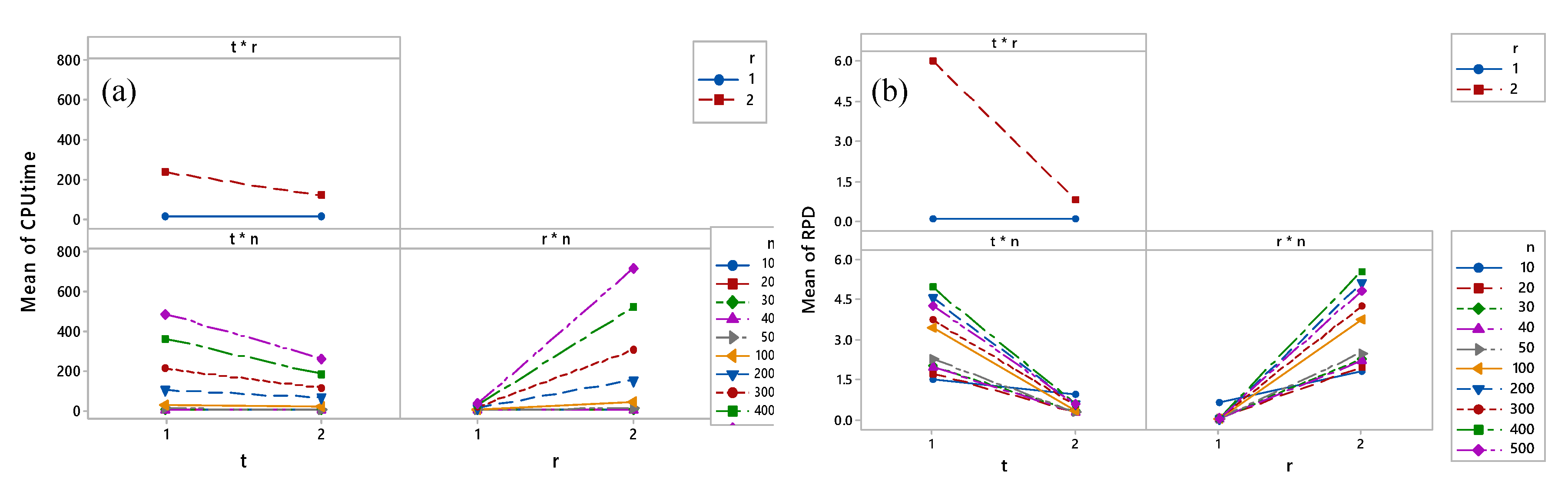
5. Results and Discussions
- denotes the number of jobs.
- 1,2 refer to the low and high levels, respectively, corresponding to variables p, r, q, t, and s.
- RPD-1 and RPD-2 refer to the RPD at low and high levels, respectively, corresponding to variables p, r, q, t, and s.
- CPU-1 and CPU-2 refer to the CPU time at low and high levels, respectively, corresponding to variables p, r, q, t, and s.
6. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Pinedo, M.; Chao, X. Operations Scheduling with Applications in Manufacturing and Services; McGraw Hill: New York, NY, USA, 1999. [Google Scholar]
- Kerzner, H. Project Management: A Systems Approach to Planning, Scheduling, and Controlling; John Wiley & Sons: Hoboken, NJ, USA, 2017. [Google Scholar]
- Callahan, M.T.; Quackenbush, D.G.; Rowings, J.E. Construction Project Scheduling; McGraw-Hill: New York, NY, USA, 1992. [Google Scholar]
- Barnhart, C.; Cohn, A.M.; Johnson, E.L.; Klabjan, D.; Nemhauser, G.L.; Vance, P.H. Airline crew scheduling. In Handbook of Transportation Science; Kluwer’s International Series; Springer: New York, NY, USA, 2003; pp. 517–560. [Google Scholar]
- Kaandorp, G.C.; Koole, G. Optimal outpatient appointment scheduling. Health Care Manag. Sci. 2007, 10, 217–229. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Malik, M.A.K. Reliable preventive maintenance scheduling. AIIE Trans. 1979, 11, 221–228. [Google Scholar] [CrossRef]
- Liu, Y.; Xu, X.; Zhang, L.; Wang, L.; Zhong, R.Y. Workload-based multi-task scheduling in cloud manufacturing. Robot. Comput.-Integr. Manuf. 2017, 45, 3–20. [Google Scholar] [CrossRef]
- Porto, A.F.; Henao, C.A.; López-Ospina, H.; González, E.R. Hybrid flexibility strategy on personnel scheduling: Retail case study. Comput. Ind. Eng. 2019, 133, 220–230. [Google Scholar] [CrossRef]
- Pinedo, M. Scheduling: Theory, Algorithms, and Systems; Springer: New York, NY, USA, 2012; Volume 5. [Google Scholar]
- Abedinnia, H.; Glock, C.H.; Grosse, E.H.; Schneider, M. Machine scheduling problems in production: A tertiary study. Comput. Ind. Eng. 2017, 111, 403–416. [Google Scholar] [CrossRef]
- Cheng, T.; Sin, C. A state-of-the-art review of parallel-machine scheduling research. Eur. J. Oper. Res. 1990, 47, 271–292. [Google Scholar] [CrossRef]
- Wang, S.; Wu, R.; Chu, F.; Yu, J. Identical Parallel Machine Scheduling with Assurance of Maximum Waiting Time for an Emergency Job. Comput. Oper. Res. 2020, 104918. [Google Scholar] [CrossRef]
- Li, K.; Yang, S.-l. Non-identical parallel-machine scheduling research with minimizing total weighted completion times: Models, relaxations and algorithms. Appl. Math. Model. 2009, 33, 2145–2158. [Google Scholar] [CrossRef]
- Vallada, E.; Ruiz, R. A genetic algorithm for the unrelated parallel machine scheduling problem with sequence dependent setup times. Euro. J. Oper. Res. 2011, 211, 612–622. [Google Scholar] [CrossRef] [Green Version]
- Anand, S.; Bringmann, K.; Friedrich, T.; Garg, N.; Kumar, A. Minimizing maximum (weighted) flow-time on related and unrelated machines. Algorithmica 2017, 77, 515–536. [Google Scholar] [CrossRef] [Green Version]
- Wang, J.-Y. Minimizing the total weighted tardiness of overlapping jobs on parallel machines with a learning effect. J. Oper. Res. Soc. 2019, 71, 910–927. [Google Scholar] [CrossRef]
- Chaudhry, I.A.; Elbadawi, I.A. Minimisation of total tardiness for identical parallel machine scheduling using genetic algorithm. Sādhanā 2017, 42, 11–21. [Google Scholar] [CrossRef] [Green Version]
- Zheng, F.; Huang, J. Uniform parallel-machine scheduling to minimize the number of tardy jobs in the MapReduce system. In Proceedings of the 2019 International Conference on Industrial Engineering and Systems Management (IESM), Shanghai, China, 25–27 September 2019; pp. 1–6. [Google Scholar]
- Ozturk, O.; Begen, M.A.; Zaric, G.S. A branch and bound algorithm for scheduling unit size jobs on parallel batching machines to minimize makespan. Int. J. Prod. Res. 2017, 55, 1815–1831. [Google Scholar] [CrossRef]
- Martello, S.; Soumis, F.; Toth, P. Exact and approximation algorithms for makespan minimization on unrelated parallel machines. Discret. Appl. Math. 1997, 75, 169–188. [Google Scholar] [CrossRef] [Green Version]
- Mansouri, S.A.; Aktas, E.; Besikci, U. Green scheduling of a two-machine flowshop: Trade-off between makespan and energy consumption. Eur. J. Oper. Res. 2016, 248, 772–788. [Google Scholar] [CrossRef] [Green Version]
- Dao, T.-K.; Pan, T.-S.; Pan, J.-S. Parallel bat algorithm for optimizing makespan in job shop scheduling problems. J. Intell. Manuf. 2018, 29, 451–462. [Google Scholar] [CrossRef]
- Bai, D.; Zhang, Z.-H.; Zhang, Q. Flexible open shop scheduling problem to minimize makespan. Comput. Oper. Res. 2016, 67, 207–215. [Google Scholar] [CrossRef]
- Shabtay, D.; Zofi, M. Single machine scheduling with controllable processing times and an unavailability period to minimize the makespan. Int. J. Prod. Econ. 2018, 198, 191–200. [Google Scholar] [CrossRef]
- Hamzadayi, A.; Yildiz, G. Modeling and solving static m identical parallel machines scheduling problem with a common server and sequence dependent setup times. Comput. Ind. Eng. 2017, 106, 287–298. [Google Scholar] [CrossRef]
- Lee, C.-Y. Parallel machines scheduling with nonsimultaneous machine available time. Discret. Appl. Math. 1991, 30, 53–61. [Google Scholar] [CrossRef] [Green Version]
- Kaabi, J.; Harrath, Y. Scheduling on uniform parallel machines with periodic unavailability constraints. Int. J. Prod. Res. 2019, 57, 216–227. [Google Scholar] [CrossRef]
- Pfund, M.; Fowler, J.W.; Gadkari, A.; Chen, Y. Scheduling jobs on parallel machines with setup times and ready times. Comput. Ind. Eng. 2008, 54, 764–782. [Google Scholar] [CrossRef]
- Al-harkan, I.M.; Qamhan, A.A. Optimize Unrelated Parallel Machines Scheduling Problems With Multiple Limited Additional Resources, Sequence-Dependent Setup Times and Release Date Constraints. IEEE Access 2019, 7, 171533–171547. [Google Scholar] [CrossRef]
- Mensendiek, A.; Gupta, J.N. Scheduling Identical Parallel Machines with a Fixed Number of Delivery Dates. In Operations Research Proceedings 2014; Springer: Cham, Switzerland, 2016; pp. 393–398. [Google Scholar]
- Hermès, F.; Ghédira, K. Scheduling Jobs with Releases Dates and Delivery Times on M Identical Non-idling Machines. In Proceedings of the ICINCO (1), Madrid, Spain, 26–28 July 2017; pp. 82–91. [Google Scholar]
- Hidri, L.; Al-Samhan, A.M.; Mabkhot, M.M. Bounding Strategies for the Parallel Processors Scheduling Problem With No-Idle Time Constraint, Release Date, and Delivery Time. IEEE Access 2019, 7, 170392–170405. [Google Scholar] [CrossRef]
- Liu, P.; Gu, M.; Li, G. Two-agent scheduling on a single machine with release dates. Comput. Oper. Res. 2019, 111, 35–42. [Google Scholar] [CrossRef]
- Schutten, J.M.; Leussink, R. Parallel machine scheduling with release dates, due dates and family setup times. Int. J. Prod. Econ. 1996, 46, 119–125. [Google Scholar] [CrossRef] [Green Version]
- Timkovsky, V.G. A polynomial-time algorithm for the two-machine unit-time release-date job-shop schedule-length problem. Discret. Appl. Math. 1997, 77, 185–200. [Google Scholar] [CrossRef] [Green Version]
- Bai, D.; Tang, L. Open shop scheduling problem to minimize makespan with release dates. Appl. Math. Model. 2013, 37, 2008–2015. [Google Scholar] [CrossRef]
- Gharbi, A.; Haouari, M. An approximate decomposition algorithm for scheduling on parallel machines with heads and tails. Comput. Oper. Res. 2007, 34, 868–883. [Google Scholar] [CrossRef]
- Woeginger, G.J. Heuristics for parallel machine scheduling with delivery times. Acta Inform. 1994, 31, 503–512. [Google Scholar] [CrossRef]
- Mastrolilli, M. Efficient approximation schemes for scheduling problems with release dates and delivery times. J. Sched. 2003, 6, 521–531. [Google Scholar] [CrossRef]
- Kacem, I.; Kellerer, H. Approximation algorithms for no idle time scheduling on a single machine with release times and delivery times. Discret. Appl. Math. 2014, 164, 154–160. [Google Scholar] [CrossRef]
- Das, K.; Lashkari, R.; Sengupta, S. Machine reliability and preventive maintenance planning for cellular manufacturing systems. Eur. J. Oper. Res. 2007, 183, 162–180. [Google Scholar] [CrossRef]
- Liao, C.-J.; Shyur, D.-L.; Lin, C.-H. Makespan minimization for two parallel machines with an availability constraint. Eur. J. Oper. Res. 2005, 160, 445–456. [Google Scholar] [CrossRef]
- Xu, D.; Cheng, Z.; Yin, Y.; Li, H. Makespan minimization for two parallel machines scheduling with a periodic availability constraint. Comput. Oper. Res. 2009, 36, 1809–1812. [Google Scholar] [CrossRef]
- Liao, C.; Chen, C.; Lin, C. Minimizing makespan for two parallel machines with job limit on each availability interval. J. Oper. Res. Soc. 2007, 58, 938–947. [Google Scholar] [CrossRef]
- Lin, C.-H.; Liao, C.-J. Makespan minimization for two parallel machines with an unavailable period on each machine. Int. J. Adv. Manuf. Technol. 2007, 33, 1024–1030. [Google Scholar] [CrossRef]
- Liu, M.; Zheng, F.; Chu, C.; Xu, Y. Optimal algorithms for online scheduling on parallel machines to minimize the makespan with a periodic availability constraint. Theor. Comput. Sci. 2011, 412, 5225–5231. [Google Scholar] [CrossRef] [Green Version]
- Xu, D.; Yang, D.-L. Makespan minimization for two parallel machines scheduling with a periodic availability constraint: Mathematical programming model, average-case analysis, and anomalies. Appl. Math. Model. 2013, 37, 7561–7567. [Google Scholar] [CrossRef]
- Hashemian, N.; Diallo, C.; Vizvári, B. Makespan minimization for parallel machines scheduling with multiple availability constraints. Ann. Oper. Res. 2014, 213, 173–186. [Google Scholar] [CrossRef]
- Huo, Y. Parallel machine makespan minimization subject to machine availability and total completion time constraints. J. Sched. 2017, 1–15. [Google Scholar] [CrossRef]
- Huang, H.; Xiong, Y.; Zhou, Y. A larger pie or a larger slice? Contract negotiation in a closed-loop supply chain with remanufacturing. Comput. Ind. Eng. 2020, 142, 106377. [Google Scholar] [CrossRef]
- Carlier, J. Scheduling jobs with release dates and tails on identical machines to minimize the makespan. Eur. J. Oper. Res. 1987, 29, 298–306. [Google Scholar] [CrossRef]
- Low, C.; Ji, M.; Hsu, C.-J.; Su, C.-T. Minimizing the makespan in a single machine scheduling problems with flexible and periodic maintenance. Appl. Math. Model. 2010, 34, 334–342. [Google Scholar] [CrossRef]
- Kundakcı, N.; Kulak, O. Hybrid genetic algorithms for minimizing makespan in dynamic job shop scheduling problem. Comput. Ind. Eng. 2016, 96, 31–51. [Google Scholar] [CrossRef]
- Osaba, E.; Carballedo, R.; Diaz, F.; Onieva, E.; De La Iglesia, I.; Perallos, A. Crossover versus mutation: A comparative analysis of the evolutionary strategy of genetic algorithms applied to combinatorial optimization problems. Sci. World J. 2014, 2014, 1–22. [Google Scholar] [CrossRef] [Green Version]
- Goldberg, D. Genetic Algorithms in Search, Optimization, and Machine learning; Addison-Wesley Pub. Co.: Boston, MA, USA, 1989; ISBN 0201157675. [Google Scholar]
- Abreu, L.R.; Cunha, J.O.; Prata, B.A.; Framinan, J.M. A genetic algorithm for scheduling open shops with sequence-dependent setup times. Comput. Oper. Res. 2020, 113, 104793. [Google Scholar] [CrossRef]
- Syswerda, G. Scheduling optimization using genetic algorithms. In Handbook of Genetic Algorithms; Van Nostrand Reinhold: New York, NY, USA, 1991. [Google Scholar]
- Derringer, G.; Suich, R. Simultaneous optimization of several response variables. J. Qual. Technol. 1980, 12, 214–219. [Google Scholar] [CrossRef]
- Kim, H.-Y. Statistical notes for clinical researchers: Assessing normal distribution (2) using skewness and kurtosis. Restor. Dent. Endod. 2013, 38, 52–54. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| j | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 1 | 1 | 2 | 4 | 2 | 3 | 1 | 2 | |
| 2 | 5 | 2 | 1 | 6 | 2 | 6 | 3 | |
| 3 | 5 | 7 | 4 | 6 | 4 | 4 | 2 |
| 9 | 2 |
| Input | Levels | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | |
| p | U(20,50) | U(20,100) | ||||||||
| r | U(1,a) | U(1,) | ||||||||
| q | U(1,0.5b) | U(1,1.5b) | ||||||||
| t | ||||||||||
| s | ||||||||||
| n | 10 | 20 | 30 | 40 | 50 | 100 | 200 | 300 | 400 | 500 |
| Parameter | −1 | 0 | 1 |
|---|---|---|---|
| Popsize | 20 | 210 | 400 |
| Pc | 0.1 | 0.695 | 0.99 |
| Pm | 0.1 | 0.5 | 0.9 |
| Mu | 0.001 | 0.1505 | 0.3 |
| Beta | 1 | 10 | 19 |
| Source | DF | Seq SS | Contribution | Adj SS | Adj MS | F-value | P-value |
|---|---|---|---|---|---|---|---|
| Model | 8 | 0.007765 | 90.14% | 0.007765 | 0.000971 | 49.16 | 0 |
| Linear | 4 | 0.006092 | 70.72% | 0.006092 | 0.001523 | 77.14 | 0 |
| Popsize | 1 | 0.005858 | 68.00% | 0.005858 | 0.005858 | 296.71 | 0 |
| Pm | 1 | 0 | 0.00% | 0 | 0 | 0.01 | 0.935 |
| Mu | 1 | 0.000131 | 1.52% | 0.000131 | 0.000131 | 6.61 | 0.014 |
| Beta | 1 | 0.000103 | 1.20% | 0.000103 | 0.000103 | 5.22 | 0.027 |
| Square | 1 | 0.00131 | 15.21% | 0.00131 | 0.00131 | 66.37 | 0 |
| Popsize2 | 1 | 0.00131 | 15.21% | 0.00131 | 0.00131 | 66.37 | 0 |
| Two-way interaction | 3 | 0.000363 | 4.21% | 0.000363 | 0.000121 | 6.13 | 0.001 |
| Popsize×Pm | 1 | 0.000229 | 2.66% | 0.000229 | 0.000229 | 11.61 | 0.001 |
| Popsize×Beta | 1 | 0.000091 | 1.06% | 0.000091 | 0.000091 | 4.6 | 0.038 |
| Pm×Mu | 1 | 0.000043 | 0.50% | 0.000043 | 0.000043 | 2.17 | 0.148 |
| Error | 43 | 0.000849 | 9.86% | 0.000849 | 0.00002 | ||
| Pure error | 9 | 0.00003 | 0.35% | 0.00003 | 0.000003 | ||
| Total | 51 | 0.008614 | 100.00% |
| Source. | DF | Seq SS | Contribution | Adj SS | Adj MS | F-Value | p-Value |
|---|---|---|---|---|---|---|---|
| Model | 8 | 572,596 | 82.45% | 572,596 | 71,574 | 25.26 | 0 |
| Linear | 4 | 322,331 | 46.42% | 322,331 | 80,583 | 28.44 | 0 |
| Popsize | 1 | 102,731 | 14.79% | 102,731 | 102,731 | 36.25 | 0 |
| Pc | 1 | 4120 | 0.59% | 4120 | 4120 | 1.45 | 0.234 |
| Pm | 1 | 131,009 | 18.87% | 131,009 | 131,009 | 46.23 | 0 |
| Mu | 1 | 84,471 | 12.16% | 84,471 | 84,471 | 29.81 | 0 |
| Two-way interaction | 4 | 250,265 | 36.04% | 250,265 | 62,566 | 22.08 | 0 |
| Popsize×Pc | 1 | 3960 | 0.57% | 3960 | 3960 | 1.4 | 0.244 |
| Popsize×Pm | 1 | 92,875 | 13.37% | 92,875 | 92,875 | 32.77 | 0 |
| Popsize×Mu | 1 | 71,356 | 10.28% | 71,356 | 71,356 | 25.18 | 0 |
| Pm×Mu | 1 | 82,074 | 11.82% | 82,074 | 82,074 | 28.96 | 0 |
| Error | 43 | 121,852 | 17.55% | 121,852 | 2834 | ||
| Pure error | 9 | 2039 | 0.29% | 2039 | 227 | ||
| Total | 51 | 694,448 | 100.00% |
| GA Parameters | Popsize | Pc | Pm | Mu | Beta |
|---|---|---|---|---|---|
| Best Settings | 200 | 0.90 | 0.14 | 0.001 | 1 |
| Input | n | |||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| p | r | q | t | s | 10 | 20 | 30 | 40 | 50 | 100 | 200 | 200 | 400 | 500 |
| 1 | 1 | 1 | 1 | 1 | 0.1 | 0 | 0.05 | 0.03 | 0.01 | 0.002 | 0.003 | 0.0008 | 0.003 | 0.003 |
| 2 | 0.29 | 0.04 | 0.03 | 0 | 0 | 0.016 | 0 | 0.001 | 0.001 | 0.003 | ||||
| 2 | 1 | 0.72 | 0.01 | 0 | 0 | 0.02 | 0.001 | 0.005 | 0.001 | 0.003 | 0.001 | |||
| 2 | 0.11 | 0.01 | 0 | 0 | 0.03 | 0.002 | 0.003 | 0.001 | 0.004 | 0.002 | ||||
| 2 | 1 | 1 | 0.23 | 0 | 0.05 | 0.01 | 0.02 | 0.032 | 0.021 | 0.008 | 0.008 | 0.008 | ||
| 2 | 1.11 | 0 | 0.01 | 0.01 | 0.05 | 0.012 | 0.014 | 0.008 | 0.013 | 0.008 | ||||
| 2 | 1 | 0.91 | 0.1 | 0.02 | 0.03 | 0.01 | 0.018 | 0.011 | 0.013 | 0.009 | 0.004 | |||
| 2 | 1 | 0.37 | 0 | 0.02 | 0.04 | 0.018 | 0.025 | 0.011 | 0.008 | 0.007 | ||||
| 2 | 1 | 1 | 1 | 2.51 | 3.51 | 7 | 7.46 | 3.37 | 0.592 | 16.34 | 11.48 | 5.827 | 2.464 | |
| 2 | 4.45 | 7.08 | 4.64 | 2.73 | 3.26 | 5.592 | 5.531 | 4.789 | 16.41 | 13.79 | ||||
| 2 | 1 | 0 | 1.66 | 0.39 | 0.3 | 1.89 | 0.905 | 1.692 | 1.2 | 1.519 | 1.717 | |||
| 2 | 4.95 | 0.19 | 0.28 | 0.89 | 0.87 | 1.536 | 1.916 | 2.104 | 1.989 | 1.754 | ||||
| 2 | 1 | 1 | 2.03 | 2.08 | 0.47 | 3.3 | 7.76 | 13.02 | 14.28 | 8.618 | 7.224 | 5.802 | ||
| 2 | 3.9 | 2.94 | 3.93 | 3.79 | 7.59 | 12.28 | 5.342 | 8.06 | 7.597 | 10.45 | ||||
| 2 | 1 | 0 | 0.15 | 0.11 | 0.16 | 0.27 | 0.541 | 1.234 | 1.184 | 2.002 | 1.592 | |||
| 2 | 0.26 | 0.29 | 0.25 | 0.79 | 0.11 | 1.059 | 1.448 | 1.503 | 1.626 | 1.583 | ||||
| 2 | 1 | 1 | 1 | 1 | 0.54 | 0 | 0 | 0.03 | 0.01 | 0.013 | 0.004 | 0.001 | 0.008 | 0.002 |
| 2 | 0.4 | 0.03 | 0.02 | 0.01 | 0.02 | 0.005 | 0.002 | 0.005 | 0.002 | 0.004 | ||||
| 2 | 1 | 0.63 | 0 | 0.05 | 0.01 | 0.02 | 0.011 | 0.015 | 0.002 | 0.004 | 0.003 | |||
| 2 | 0 | 0 | 0.01 | 0.02 | 0.02 | 0.007 | 0.007 | 0.005 | 0.003 | 0.002 | ||||
| 2 | 1 | 1 | 1.71 | 0.02 | 0.02 | 0.02 | 0.05 | 0.031 | 0.017 | 0.011 | 0.013 | 0.01 | ||
| 2 | 0.82 | 0.18 | 0.04 | 0.01 | 0.03 | 0.022 | 0.017 | 0.012 | 0.007 | 0.01 | ||||
| 2 | 1 | 0.86 | 0 | 0.04 | 0.03 | 0.02 | 0.031 | 0.022 | 0.018 | 0.017 | 0.007 | |||
| 2 | 0.75 | 0.05 | 0 | 0.04 | 0.02 | 0.023 | 0.022 | 0.019 | 0.008 | 0.008 | ||||
| 2 | 1 | 1 | 1 | 2.07 | 0.9 | 2.67 | 1.93 | 0.59 | 2.327 | 3.921 | 3.449 | 3.781 | 6.719 | |
| 2 | 2.25 | 5.29 | 3.6 | 4.07 | 3.47 | 17.65 | 15.41 | 10.71 | 18.5 | 14.65 | ||||
| 2 | 1 | 0.35 | 0.59 | 2.45 | 0.64 | 0 | 0.102 | 0.451 | 0.442 | 0.695 | 0.537 | |||
| 2 | 2.98 | 0.89 | 0.87 | 0.54 | 0.62 | 0.376 | 0.963 | 0.555 | 0.828 | 0.537 | ||||
| 2 | 1 | 1 | 1.3 | 0.02 | 3.03 | 0.43 | 0.22 | 2.253 | 2.666 | 3.132 | 6.514 | 3.623 | ||
| 2 | 0.47 | 5.27 | 6.16 | 7.39 | 9.57 | 1.011 | 9.588 | 9.407 | 13.65 | 10.79 | ||||
| 2 | 1 | 1.57 | 0 | 0 | 0.07 | 0.14 | 0.082 | 0.515 | 1.029 | 0.462 | 0.741 | |||
| 2 | 0 | 0.02 | 0.24 | 0.63 | 0.06 | 0.394 | 0.517 | 0.453 | 0.333 | 0.614 | ||||
| Input | n | |||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| p | r | q | t | s | 10 | 20 | 30 | 40 | 50 | 100 | 200 | 200 | 400 | 500 |
| 1 | 1 | 1 | 1 | 1 | 2.1 | 0.6 | 3.6 | 3.5 | 2.3 | 2.9 | 6.2 | 5.1 | 15.0 | 20.2 |
| 2 | 3.8 | 2.5 | 2.3 | 0.5 | 1.8 | 6.1 | 2.8 | 5.7 | 10.5 | 23.6 | ||||
| 2 | 1 | 7.2 | 0.7 | 0.5 | 0.6 | 2.8 | 2.8 | 7.6 | 6.1 | 15.1 | 10.2 | |||
| 2 | 2.5 | 0.8 | 0.6 | 1.0 | 4.6 | 2.5 | 6.0 | 7.1 | 18.6 | 18.9 | ||||
| 2 | 1 | 1 | 3.4 | 0.3 | 3.2 | 2.9 | 3.9 | 7.2 | 16.6 | 15.6 | 28.5 | 37.9 | ||
| 2 | 6.1 | 0.5 | 1.8 | 2.7 | 6.2 | 7.6 | 17.7 | 17.6 | 31.1 | 34.6 | ||||
| 2 | 1 | 7.7 | 3.7 | 2.3 | 3.2 | 2.3 | 5.8 | 14.1 | 22.4 | 26.7 | 23.3 | |||
| 2 | 6.0 | 4.3 | 0.9 | 2.3 | 5.6 | 6.9 | 24.7 | 21.1 | 23.6 | 31.6 | ||||
| 2 | 1 | 1 | 1 | 3.9 | 8.7 | 13.8 | 15.7 | 18.3 | 47.2 | 204.6 | 368.1 | 746.3 | 962.6 | |
| 2 | 5.2 | 12.9 | 8.5 | 12.6 | 18.4 | 71.7 | 274.5 | 440.5 | 561.6 | 1113.9 | ||||
| 2 | 1 | 0.1 | 6.4 | 7.5 | 5.1 | 10.8 | 31.4 | 139.0 | 231.3 | 333.2 | 530.7 | |||
| 2 | 7.4 | 2.3 | 7.3 | 9.7 | 13.1 | 43.7 | 143.4 | 239.2 | 404.6 | 565.5 | ||||
| 2 | 1 | 1 | 5.5 | 7.8 | 6.6 | 13.5 | 27.6 | 48.6 | 223.7 | 501.0 | 793.0 | 1057.9 | ||
| 2 | 7.4 | 8.3 | 12.6 | 13.7 | 24.9 | 75.9 | 243.1 | 370.2 | 794.5 | 1008.9 | ||||
| 2 | 1 | 0.1 | 2.6 | 2.1 | 5.1 | 4.2 | 32.7 | 148.2 | 200.3 | 369.2 | 519.3 | |||
| 2 | 1.9 | 2.2 | 4.0 | 7.8 | 7.7 | 32.9 | 125.5 | 239.9 | 400.2 | 534.1 | ||||
| 2 | 1 | 1 | 1 | 1 | 6.5 | 1.0 | 0.7 | 3.3 | 4.5 | 9.2 | 11.3 | 10.7 | 31.7 | 28.3 |
| 2 | 3.4 | 3.1 | 4.6 | 2.8 | 5.3 | 4.5 | 9.2 | 22.9 | 15.6 | 36.2 | ||||
| 2 | 1 | 6.3 | 0.8 | 5.3 | 1.4 | 4.4 | 8.9 | 22.1 | 12.0 | 22.3 | 29.7 | |||
| 2 | 0.2 | 0.4 | 1.9 | 4.0 | 4.6 | 6.4 | 15.9 | 19.8 | 22.3 | 27.7 | ||||
| 2 | 1 | 1 | 7.7 | 2.1 | 2.4 | 3.4 | 4.1 | 13.4 | 17.2 | 32.4 | 50.3 | 55.7 | ||
| 2 | 8.7 | 9.4 | 2.3 | 3.2 | 4.0 | 11.7 | 20.8 | 30.0 | 38.3 | 49.9 | ||||
| 2 | 1 | 7.9 | 1.3 | 4.1 | 3.6 | 4.0 | 12.7 | 25.2 | 30.6 | 44.6 | 46.5 | |||
| 2 | 8.1 | 2.7 | 0.8 | 5.6 | 3.5 | 11.2 | 23.5 | 37.2 | 36.8 | 48.0 | ||||
| 2 | 1 | 1 | 1 | 5.2 | 2.4 | 5.0 | 8.3 | 11.4 | 42.7 | 154.5 | 404.9 | 666.9 | 779.8 | |
| 2 | 5.1 | 7.1 | 7.8 | 15.6 | 12.2 | 46.5 | 142.3 | 438.2 | 743.7 | 983.5 | ||||
| 2 | 1 | 1.6 | 3.7 | 6.6 | 5.6 | 0.4 | 17.1 | 65.3 | 167.5 | 316.1 | 452.3 | |||
| 2 | 3.6 | 2.0 | 4.9 | 4.4 | 4.7 | 27.7 | 106.1 | 188.8 | 376.8 | 383.2 | ||||
| 2 | 1 | 1 | 1.6 | 2.0 | 9.0 | 5.1 | 7.5 | 50.3 | 161.4 | 308.2 | 595.2 | 845.2 | ||
| 2 | 1.8 | 8.9 | 13.7 | 9.9 | 22.7 | 65.4 | 156.9 | 394.6 | 653.8 | 744.8 | ||||
| 2 | 1 | 2.0 | 0.1 | 0.2 | 2.7 | 8.0 | 13.9 | 93.2 | 244.0 | 318.0 | 522.8 | |||
| 2 | 0.1 | 1.9 | 2.5 | 3.5 | 2.4 | 22.8 | 81.7 | 174.3 | 263.6 | 455.4 | ||||
| Source | DF | Seq SS | Contribution | Adj SS | Adj MS | F-Value | p-Value |
|---|---|---|---|---|---|---|---|
| Model | 35 | 17,129.5 | 98.17% | 17,129.5 | 489.41 | 435.05 | 0 |
| Linear | 14 | 12,301.4 | 70.50% | 12,301.4 | 878.67 | 781.07 | 0 |
| p | 1 | 4.5 | 0.03% | 4.5 | 4.54 | 4.03 | 0.046 |
| s | 1 | 3.2 | 0.02% | 3.2 | 3.18 | 2.82 | 0.094 |
| t | 1 | 223.1 | 1.28% | 223.1 | 223.09 | 198.31 | 0 |
| q | 1 | 10.7 | 0.06% | 10.7 | 10.68 | 9.49 | 0.002 |
| r | 1 | 3603.2 | 20.65% | 3603.2 | 3603.24 | 3202.97 | 0 |
| n | 9 | 8456.7 | 48.47% | 8456.7 | 939.63 | 835.25 | 0 |
| 2-Way Interactions | 21 | 4828 | 27.67% | 4828 | 229.91 | 204.37 | 0 |
| 1 | 71 | 0.41% | 71 | 71.03 | 63.14 | 0 | |
| 1 | 214.8 | 1.23% | 214.8 | 214.8 | 190.94 | 0 | |
| 9 | 155.8 | 0.89% | 155.8 | 17.31 | 15.39 | 0 | |
| 1 | 21.7 | 0.12% | 21.7 | 21.67 | 19.26 | 0 | |
| 9 | 4364.7 | 25.01% | 4364.7 | 484.97 | 431.1 | 0 | |
| Error | 284 | 319.5 | 1.83% | 319.5 | 1.12 | ||
| Total | 319 | 17,448.9 | 100.00% |
| Source | DF | Seq SS | Contribution | Adj SS | Adj MS | F-Value | p-Value |
|---|---|---|---|---|---|---|---|
| Model | 29 | 273.925 | 83.35% | 273.925 | 9.446 | 50.06 | 0 |
| Linear | 14 | 203.531 | 61.93% | 203.531 | 14.538 | 77.05 | 0 |
| p | 1 | 1.509 | 0.46% | 1.509 | 1.509 | 8 | 0.005 |
| s | 1 | 3.459 | 1.05% | 3.459 | 3.459 | 18.33 | 0 |
| t | 1 | 42.627 | 12.97% | 42.627 | 42.627 | 225.91 | 0 |
| q | 1 | 0.254 | 0.08% | 0.254 | 0.254 | 1.35 | 0.247 |
| r | 1 | 148.072 | 45.06% | 148.072 | 148.072 | 784.73 | 0 |
| n | 9 | 7.61 | 2.32% | 7.61 | 0.846 | 4.48 | 0 |
| 2-Way Interactions | 15 | 70.395 | 21.42% | 70.395 | 4.693 | 24.87 | 0 |
| 1 | 0.995 | 0.30% | 0.995 | 0.995 | 5.27 | 0.022 | |
| 1 | 1.932 | 0.59% | 1.932 | 1.932 | 10.24 | 0.002 | |
| 1 | 1.896 | 0.58% | 1.896 | 1.896 | 10.05 | 0.002 | |
| 1 | 3.768 | 1.15% | 3.768 | 3.768 | 19.97 | 0 | |
| 1 | 42.091 | 12.81% | 42.091 | 42.091 | 223.07 | 0 | |
| 1 | 1.87 | 0.57% | 1.87 | 1.87 | 9.91 | 0.002 | |
| 9 | 17.843 | 5.43% | 17.843 | 1.983 | 10.51 | 0 | |
| Error | 290 | 54.721 | 16.65% | 54.721 | 0.189 | ||
| Total | 319 | 328.646 | 100.00% |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Al-Shayea, A.M.; Saleh, M.; Alatefi, M.; Ghaleb, M. Scheduling Two Identical Parallel Machines Subjected to Release Times, Delivery Times and Unavailability Constraints. Processes 2020, 8, 1025. https://doi.org/10.3390/pr8091025
Al-Shayea AM, Saleh M, Alatefi M, Ghaleb M. Scheduling Two Identical Parallel Machines Subjected to Release Times, Delivery Times and Unavailability Constraints. Processes. 2020; 8(9):1025. https://doi.org/10.3390/pr8091025
Chicago/Turabian StyleAl-Shayea, Adel M., Mustafa Saleh, Moath Alatefi, and Mageed Ghaleb. 2020. "Scheduling Two Identical Parallel Machines Subjected to Release Times, Delivery Times and Unavailability Constraints" Processes 8, no. 9: 1025. https://doi.org/10.3390/pr8091025
APA StyleAl-Shayea, A. M., Saleh, M., Alatefi, M., & Ghaleb, M. (2020). Scheduling Two Identical Parallel Machines Subjected to Release Times, Delivery Times and Unavailability Constraints. Processes, 8(9), 1025. https://doi.org/10.3390/pr8091025