
Production Flow Analysis in a Semiconductor Fab Using Machine Learning Techniques


Abstract
:1. Introduction
2. Literature Review
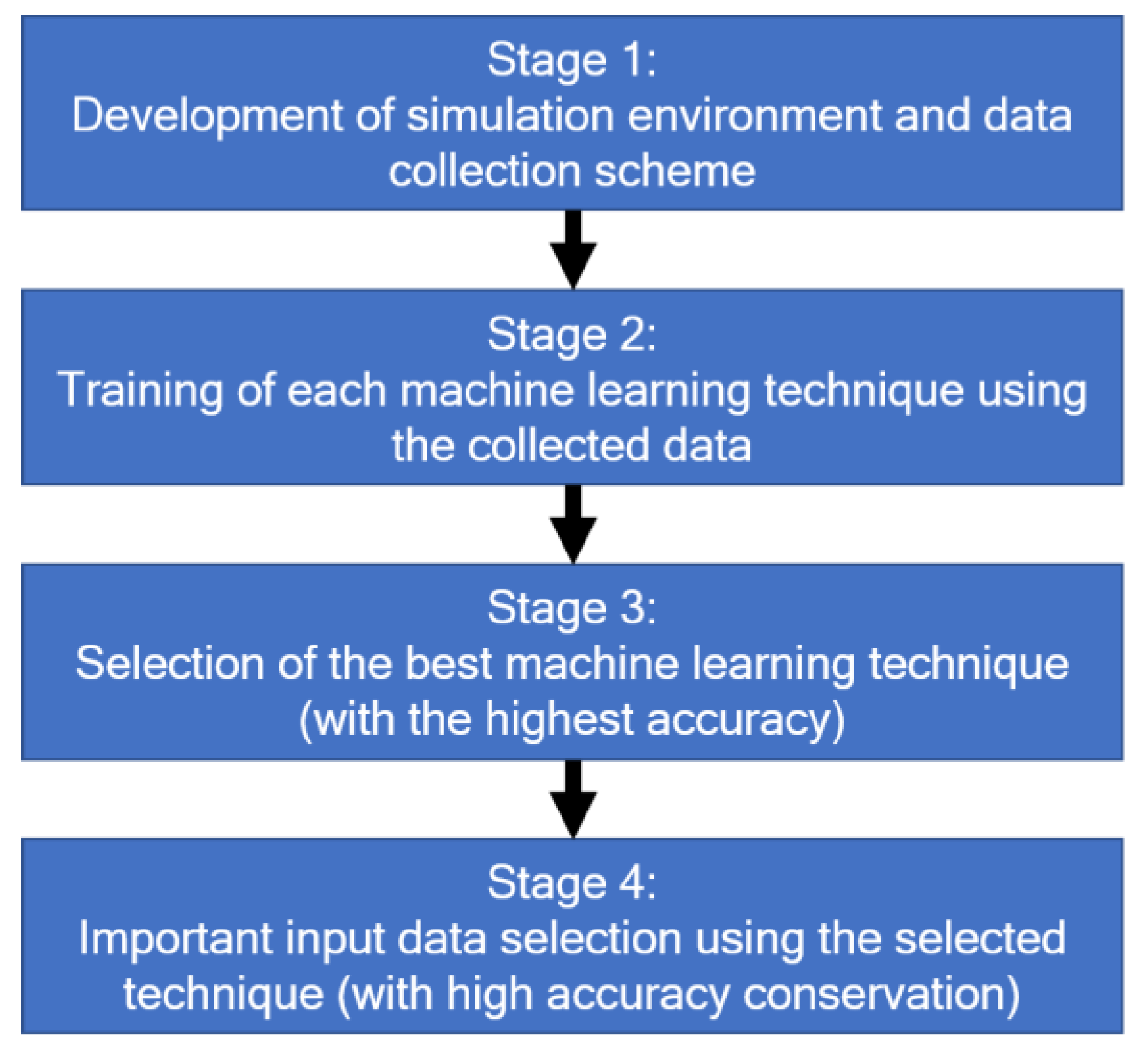
3. Materials and Methods
- The First-In-First-Out rule was used to select which wafer lot entered each machine. In other words, the entrance sequence of the wafer lots into a machine’s queue determined their sequence when entering the machine. For machine A or B, any batch that could be feasibly formed using the earliest arriving products was selected to be processed in the machine. As stated previously [26], when forming a batch for processing step 1, at most, one TW wafer lot can be included. The possible batch configurations for processing step 1 are (Pa,Pa,Pa), (Pa,Pa,Pb), (Pa,Pa,TW), (Pa,Pb,TW), (Pb,Pb,TW), (Pb,Pb,Pa), and (Pb,Pb,Pb). Meanwhile, when performing processing step 5, different product types cannot be mixed into the same batch, though having one TW lot, at most, is acceptable. The possible batch configurations for processing step 5 are (Pa,Pa,Pa), (Pa,Pa,TW), (Pb,Pb,TW), and (Pb,Pb,Pb). Every time machine A or B becomes empty or a wafer lot enters queue of any machine A or B when the machine is idle; any possible batch is formed using the earliest arriving wafer lots at the machine’s queue. If the batch is formed, the batch is released for processing in the machine.
- The machine with a smaller total number of products waiting in the queue and products being processed is selected as the next machine for the lot or batch (when an alternative machine exists). After each wafer lot or batch processing is completed in a machine, the lot or batch is delivered to the next processing step (e.g., after a wafer lot completes its processing step 4 at machine D, before it starts processing step 5 at machine A or B). At this time, it is inserted into the queue of the machine with the rule set above. The rule above is less important than the same machine visit rule for TW, if applicable. Considering that each TW lot is not allowed to be processed in the same machine, if necessary, assigning this TW lot to the next machine with a higher number of allocated wafer lots is acceptable.
- Adaptive boosting (AB)The purpose of AB is to improve the performance of weak classifiers, such as the decision tree. The results of a previous classifier are inserted into the next one in a sequential training scheme. During this process, the mistakes of earlier classifiers are dealt with to improve the final prediction quality.
- Linear classifiers with stochastic gradient descent training (SGD)In SGD, estimation is conducted using linear models with stochastic gradient descent learning. The gradient of the loss is measured using each sample, and the model is updated with a certain decreased strength (learning rate).
- Neural network (multilayer perceptron) (NNMLP)NNMLP is a fully connected feed–forward network. The error propagation method is used for conducting the training.
- Gradient boosting (GB)GB is the improved version of the classification and regression tree (CART). Each new tree is generated in a serial order to correct the prediction error of the prior tree.
- Random forest (RF)RF uses decision trees for the classification task. The tree’s depth is increased by one, and this process is iterated for all nodes in the tree until a certain depth is reached.
- K-nearest neighbors (KNN)KNN predicts each data record in the test set by selecting the k nearest training set vectors. The classification is performed based on the majority of the votes.
- Classification and regression tree (CART)Training of the CART model includes tree generation through recursive binary splitting. Various split points are tested using a cost function, and the lowest cost-split is chosen to deal with the organized values.
- Naive bayes (gaussian) (NB)NB performs the classification based on the conditional probability of each categorical class variable. Such a maximum likelihood method is used for parameter estimation in various problem domains.
- Support vector machine (C-support vector) (SVM)SVM conducts the classification by generating N-dimensional hyperplanes that separate the data. Penalty factor C is considered to control the trade-off between allowing the existence of training errors and setting rigid margins.
- Division of the collected data into training and testing data; the data before the division is shuffled, and the percentage of testing data is set equal to 20%.
- Testing accuracy of each model using k-fold cross-validation; the number of considered splits is ten. The training data are shuffled before the testing.
4. Results
5. Conclusions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Hwang, I.; Jang, Y.J. Q(λ) learning-based dynamic route guidance algorithm for overhead hoist transport systems in semiconductor fabs. Int. J. Prod. Res. 2020, 58, 1199–1221. [Google Scholar] [CrossRef]
- Shahzad, M.A.; Gulzar, W.A. Industrie 4.0 readiness: Green computing in relation with key performance indicator for a manufacturing industry. Mob. Netw. Appl. 2020, 25, 1299–1306. [Google Scholar] [CrossRef]
- Lin, Z.; Matta, A.; Shanthikumar, J.G. Combining simulation experiments and analytical models with area-based accuracy for performance evaluation of manufacturing systems. IISE Trans. 2019, 51, 266–283. [Google Scholar] [CrossRef]
- Waschneck, B.; Reichstaller, A.; Belzner, L.; Altenmüller, T.; Bauernhansl, T.; Knapp, A.; Kyek, A. Deep reinforcement learning for semiconductor production scheduling. In Proceedings of the IEEE/SEMI Conference and Workshop on Advanced Semiconductor Manufacturing, New York, NY, USA, 30 April–3 May 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 301–306. [Google Scholar] [CrossRef]
- Morariu, C.; Morariu, O.; Răileanu, S.; Borangiu, T. Machine learning for predictive scheduling and resource allocation in large scale manufacturing systems. Comput. Ind. 2020, 120, 103244. [Google Scholar] [CrossRef]
- Arinez, J.F.; Chang, Q.; Gao, R.X.; Xu, C.; Zhang, J. Artificial intelligence in advanced manufacturing: Current status and future outlook. ASME J. Manuf. Sci. Eng. 2020, 142, 11804. [Google Scholar] [CrossRef]
- Torres, D.; Pimentel, C.; Duarte, S. Shop floor management system in the context of smart manufacturing: A case study. Int. J. Lean Six Sigma 2020, 11, 837–862. [Google Scholar] [CrossRef]
- Alkan, B.; Bullock, S. Assessing operational complexity of manufacturing systems based on algorithmic complexity of key performance indicator time-series. J. Oper. Res. Soc. 2020, 1–15. [Google Scholar] [CrossRef]
- Gao, J. Performance evaluation of manufacturing collaborative logistics based on BP neural network and rough set. Neural. Comput. Appl. 2020. [Google Scholar] [CrossRef]
- Nath, S.; Sarkar, B. Performance evaluation of advanced manufacturing technologies: A De novo approach. Comput. Ind. Eng. 2017, 110, 364–378. [Google Scholar] [CrossRef]
- Saaty, T.L. The modern science of multicriteria decision making and its practical applications: The AHP/ANP approach. Oper. Res. 2013, 61, 1101–1118. [Google Scholar] [CrossRef]
- Zhong, R.Y. RFID data driven performance evaluation in production systems. Procedia CIRP. 2019, 81, 24–77. [Google Scholar] [CrossRef]
- Tin, T.C.; Chiew, K.L.; Phang, S.C.; Sze, S.N.; Tan, P.S. Incoming work-in-progress prediction in semiconductor fabrication foundry using long short-term memory. Comput. Intell. Neurosci. 2019, 8729367, 1–16. [Google Scholar] [CrossRef] [PubMed]
- Lingitz, L.; Gallina, V.; Ansari, F.; Gyulai, D.; Pfeiffer, A.; Sihn, W.; Monostori, L. Lead time prediction using machine learning algorithms: A case study by a semiconductor manufacturer. Procedia CIRP. 2018, 72, 1051–1056. [Google Scholar] [CrossRef]
- Lee, S.; Kim, H.J.; Kim, S.B. Dynamic dispatching system using a deep denoising autoencoder for semiconductor manufacturing. Appl. Soft Comput. 2020, 86, 105904. [Google Scholar] [CrossRef]
- Lee, S.; Kim, Y.; Kahng, H.; Lee, S.-K.; Chung, S.; Cheong, T.; Shin, K.; Park, J.; Kim, S.B. Intelligent traffic control for autonomous vehicle systems based on machine learning. Expert Syst. Appl. 2020, 144, 113074. [Google Scholar] [CrossRef]
- Hsu, C.-Y.; Chien, J.-C. Ensemble convolutional neural networks with weighted majority for wafer bin map pattern classification. J. Intell. Manuf. 2020. [Google Scholar] [CrossRef]
- Chien, J.-C.; Wu, M.-T.; Lee, J.-D. Inspection and classification of semiconductor wafer surface defects sing CNN deep learning networks. Appl. Sci. 2020, 10, 5340. [Google Scholar] [CrossRef]
- Fan, S.-K.S.; Hsu, C.-Y.; Tsai, D.-M.; He, F.; Cheng, C.-C. Data-driven approach for fault detection and diagnostic in semiconductor manufacturing. IEEE Trans. Autom. Sci. Eng. 2020, 17, 1925–1936. [Google Scholar] [CrossRef]
- Jiang, D.; Lin, W.; Raghavan, N. A novel framework for semiconductor manufacturing final test yield classification using machine learning techniques. IEEE Access. 2020, 8, 197885–197895. [Google Scholar] [CrossRef]
- Lee, D.-C.; Cho, S.-B. An agent-based system for abnormal flow detection in semiconductor production line. In Proceedings of the 17th International Conference on Control, Automation and Systems (ICCAS), Jeju, Korea, 18–21 October 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 2015–2020. [Google Scholar] [CrossRef]
- Jang, S.-J.; Kim, J.-S.; Kim, T.-W.; Lee, H.-J.; Ko, S. A wafer map yield prediction based on machine learning for productivity enhancement. IEEE Trans. Semicond. Manuf. 2019, 32, 400–407. [Google Scholar] [CrossRef]
- Kim, J.-S.; Jang, S.-J.; Kim, T.-W.; Lee, H.-J.; Lee, J.-B. A productivity-oriented wafer map optimization using yield model based on machine learning. IEEE Trans. Semicond. Manuf. 2019, 32, 39–47. [Google Scholar] [CrossRef]
- Lauer, T.; Legner, S. Plan instability prediction by machine learning in master production planning. In Proceedings of the IEEE 15th International Conference on Automation Science and Engineering, Vancouver, BC, Canada, 22–26 August 2019; Curran Associates, Inc.: Red Hook, NY, USA, 2019; pp. 703–708. [Google Scholar] [CrossRef]
- Kang, Z.; Catal, C.; Tekinerdogan, B. Machine learning applications in production lines: A systematic literature review. Comput. Ind. Eng. 2020, 149, 106773. [Google Scholar] [CrossRef]
- Spier, J.; Kempf, K. Simulation of emergent behavior in manufacturing systems. In Proceedings of the SEMI Advanced Semiconductor Manufacturing Conference and Workshop, Cambridge, USA, 13–15 November 1995; IEEE: New York, NY, USA, 1995; pp. 90–94. [Google Scholar] [CrossRef]
- Dabbas, R.M.; Chen, H.-N.; Fowler, J.W.; Shunk, D. A combined dispatching criteria approach to scheduling semiconductor manufacturing systems. Comput. Ind. Eng. 2001, 39, 307–324. [Google Scholar] [CrossRef]
- Dabbas, R.M.; Fowler, J.W.; Rollier, D.A.; Mccarville, D. Multiple response optimization using mixture-designed experiments and desirability functions in semiconductor scheduling. Int. J. Prod. Res. 2003, 41, 939–961. [Google Scholar] [CrossRef]
- Li, Y.; Jiang, Z.; Jia, W. An integrated release and dispatch policy for semiconductor wafer fabrication. Int. J. Prod. Res. 2014, 52, 2275–2292. [Google Scholar] [CrossRef]
- Gu, X.; Guo, W.; Jin, X. Performance evaluation for manufacturing systems under control-limit maintenance policy. J. Manuf. Syst. 2020, 55, 221–232. [Google Scholar] [CrossRef]
- Liu, H.; Chen, C. Spatial air quality index prediction model based on decomposition, adaptive boosting, and three-stage feature selection: A case study in China. J. Clean. Prod. 2020, 265, 121777. [Google Scholar] [CrossRef]
- Ganesh, S.S.; Arulmozhicarman, P.; Tatavarti, R. Forecasting air quality index using an ensemble of artificial neural networks and regression models. J. Intell. Syst. 2017, 28, 893–903. [Google Scholar] [CrossRef]
- Zhang, Y.; Zhang, R.; Ma, Q.; Wang, Y.; Wang, Q.; Huang, Z.; Huang, L. A feature selection and multi-model fusion-based approach of predicting air quality. Isa Trans. 2019, 100, 210–220. [Google Scholar] [CrossRef]
- Liu, H.; Li, Q.; Yu, D.; Gu, Y. Air quality index and air pollutant concentration prediction based on machine learning algorithms. Appl. Sci. 2019, 9, 4069. [Google Scholar] [CrossRef] [Green Version]
- Kück, M.; Freitag, M. Forecasting of customer demands for production planning by local k-nearest neighbor models. Int. J Prod. Econ. 2021, 231, 107837. [Google Scholar] [CrossRef]
- Melgarejo, M.; Parra, C.; Oregón, N. Applying computational intelligence to the classification of pollution events. Int. Lat. Am. Trans. 2015, 13, 2071–2077. [Google Scholar] [CrossRef]
- Shi, G.-Y.; Liu, S. Model selection of c-support vector machines based on multi-threading genetic algorithm. Int. J. Wavelets. Multi. 2013, 11, 1350041. [Google Scholar] [CrossRef]
- Tama, B.A.; Lim, S. A comparative performance evaluation of classification algorithms for clinical decision support systems. Mathematics 2020, 8, 1814. [Google Scholar] [CrossRef]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Processing Steps | Machine A & B | Machine C & D | Machine E | ||||||
|---|---|---|---|---|---|---|---|---|---|
| L | P | U | L | P | U | L | P | U | |
| step 1 | 1200 | 13,500 | 2400 | ||||||
| step 2 | 900 | 1800 | 900 | ||||||
| step 3 | 600 | 3300 | 600 | ||||||
| step 4 | 900 | 3000 | 900 | ||||||
| step 5 | 1200 | 15,300 | 2400 | ||||||
| step 6 | 600 | 600 | 600 | ||||||
| Number of Released Wafer Lots | |||
|---|---|---|---|
| Shift | Pa | Pb | TW |
| shift 1 | 3 | 2 | 1 |
| shift 2 | 4 | 2 | 0 |
| shift 3 | 4 | 2 | 0 |
| shift 4 | 3 | 3 | 0 |
| shift 5 | 4 | 2 | 0 |
| shift 6 | 4 | 2 | 0 |
| shift 7 | 3 | 2 | 1 |
| shift 8 | 4 | 2 | 0 |
| shift 9 | 4 | 2 | 0 |
| shift 10 | 3 | 3 | 0 |
| shift 11 | 4 | 2 | 0 |
| shift 12 | 4 | 2 | 0 |
| shift 13 | 3 | 2 | 1 |
| shift 14 | 4 | 2 | 0 |
| total | 51 | 30 | 3 |
| Data No. | Data Name | Description |
|---|---|---|
| 1 | total_captures_queue_A_per_week | number of wafer lots waiting at machine A’s buffer in one week |
| 2 | total_captures_queue_B_per_week | number of wafer lots waiting at machine B’s buffer in one week |
| 3 | total_captures_queue_C_per_week | number of wafer lots waiting at machine C’s buffer in one week |
| 4 | total_captures_queue_D_per_week | number of wafer lots waiting at machine D’s buffer in one week |
| 5 | total_captures_queue_E_per_week | number of wafer lots waiting at machine E’s buffer in one week |
| 6 | total_captures_queue_AB_per_week | number of wafer lots waiting at machine A’s and machine B’s buffers in one week |
| 7 | total_captures_queue_CD_per_week | number of wafer lots waiting at machine C’s and machine D’s buffers in one week |
| 8 | total_captures_queue_A_1_per_week | number of wafer lots with processing step 1 waiting at machine A’s buffer in one week |
| 9 | total_captures_queue_A_5_per_week | number of wafer lots with processing step 5 waiting at machine A’s buffer in one week |
| 10 | total_captures_queue_B_1_per_week | number of wafer lots with processing step 1 waiting at machine B’s buffer in one week |
| 11 | total_captures_queue_B_5_per_week | number of wafer lots with processing step 5 waiting at machine B’s buffer in one week |
| 12 | total_captures_queue_C_2_per_week | number of wafer lots with processing step 2 waiting at machine C’s buffer in one week |
| 13 | total_captures_queue_C_4_per_week | number of wafer lots with processing step 4 waiting at machine C’s buffer in one week |
| 14 | total_captures_queue_D_2_per_week | number of wafer lots with processing step 2 waiting at machine D’s buffer in one week |
| 15 | total_captures_queue_D_4_per_week | number of wafer lots with processing step 4 waiting at machine D’s buffer in one week |
| 16 | total_captures_queue_E_3_per_week | number of wafer lots with processing step 3 waiting at machine E’s buffer in one week |
| 17 | total_captures_queue_E_6_per_week | number of wafer lots with processing step 6 waiting at machine E’s buffer in one week |
| 18 | machine_A_step1_per_week | number of wafer lots with step 1 processed at machine A in one week |
| 19 | machine_A_step5_per_week | number of wafer lots with step 5 processed at machine A in one week |
| 20 | machine_B_step1_per_week | number of wafer lots with step 1 processed at machine B in one week |
| 21 | machine_B_step5_per_week | number of wafer lots with step 5 processed at machine B in one week |
| 22 | machine_C_step2_per_week | number of wafer lots with step 2 processed at machine C in one week |
| 23 | machine_C_step4_per_week | number of wafer lots with step 4 processed at machine C in one week |
| 24 | machine_D_step2_per_week | number of wafer lots with step 2 processed at machine D in one week |
| 25 | machine_D_step4_per_week | number of wafer lots with step 4 processed at machine D in one week |
| 26 | machine_E_step3_per_week | number of wafer lots with step 3 processed at machine E in one week |
| 27 | machine_E_step6_per_week | number of wafer lots with step 6 processed at machine E in one week |
| 28 | machine_A_available_production_ time_with_idle_per_week | percentage of machine A’s available production time after excluding the preventive and emergency maintenances in one week |
| 29 | machine_B_available_production_ time_with_idle_per_week | percentage of machine B’s available production time after excluding the preventive and emergency maintenances in one week |
| 30 | machine_C_available_production_ time_with_idle_per_week | percentage of machine C’s available production time after excluding the preventive and emergency maintenances in one week |
| 31 | machine_D_available_production_ time_with_idle_per_week | percentage of machine D’s available production time after excluding the preventive and emergency maintenances in one week |
| 32 | machine_E_available_production_ time_with_idle_per_week | percentage of machine E’s available production time after excluding the preventive and emergency maintenances in one week |
| 33 | machine_A_utilization_ all_working_times_per_week | percentage of machine A’s actual production time after excluding the preventive maintenance, emergency maintenance, and idle times in one week |
| 34 | machine_B_utilization_ all_working_times_per_week | percentage of machine B’s actual production time after excluding the preventive maintenance, emergency maintenance, and idle times in one week |
| 35 | machine_C_utilization_ all_working_times_per_week | percentage of machine C’s actual production time after excluding the preventive maintenance, emergency maintenance, and idle times in one week |
| 36 | machine_D_utilization_ all_working_times_per_week | percentage of machine D’s actual production time after excluding the preventive maintenance, emergency maintenance, and idle times in one week |
| 37 | machine_E_utilization_ all_working_times_per_week | percentage of machine E’s actual production time after excluding the preventive maintenance, emergency maintenance, and idle times in one week |
| 38 | machine_A_idle_time_ percentage_per week | percentage of machine A’s total idle time in one week |
| 39 | machine_B_idle_time_ percentage_per week | percentage of machine B’s total idle time in one week |
| 40 | machine_C_idle_time_ percentage_per week | percentage of machine C’s total idle time in one week |
| 41 | machine_D_idle_time_ percentage_per week | percentage of machine D’s total idle time in one week |
| 42 | machine_E_idle_time_ percentage_per week | percentage of machine E’s total idle time in one week |
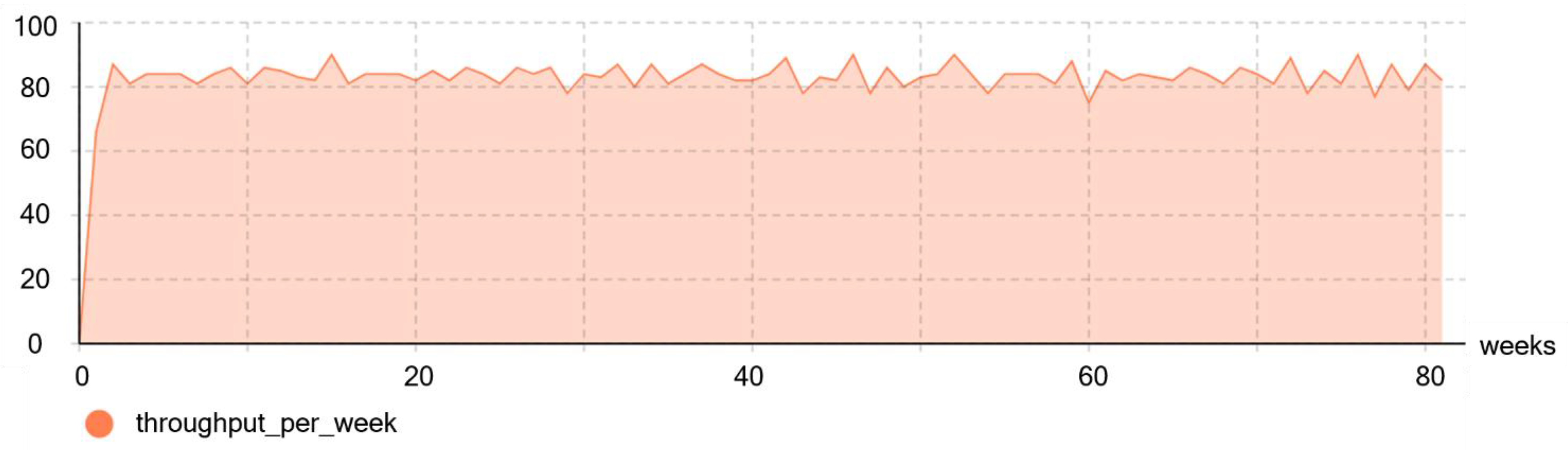
| 43 | throughput_per_week | number of wafer lot finished in one week |
| Machine Learning Technique | Reference |
|---|---|
| adaptive boosting (AB) | [31] |
| linear classifiers with stochastic gradient descent training (SGD) | [32] |
| neural network (multilayer perceptron 1) (NNMLP) | [32] |
| gradient boosting (GB) | [33] |
| random forest (RF) | [34] |
| k-nearest neighbors (KNN) | [35] |
| classification and regression tree (CART) | [33] |
| naive bayes (gaussian 1) (NB) | [36] |
| support vector machine (C-support vector 1) (SVM) | [37] |
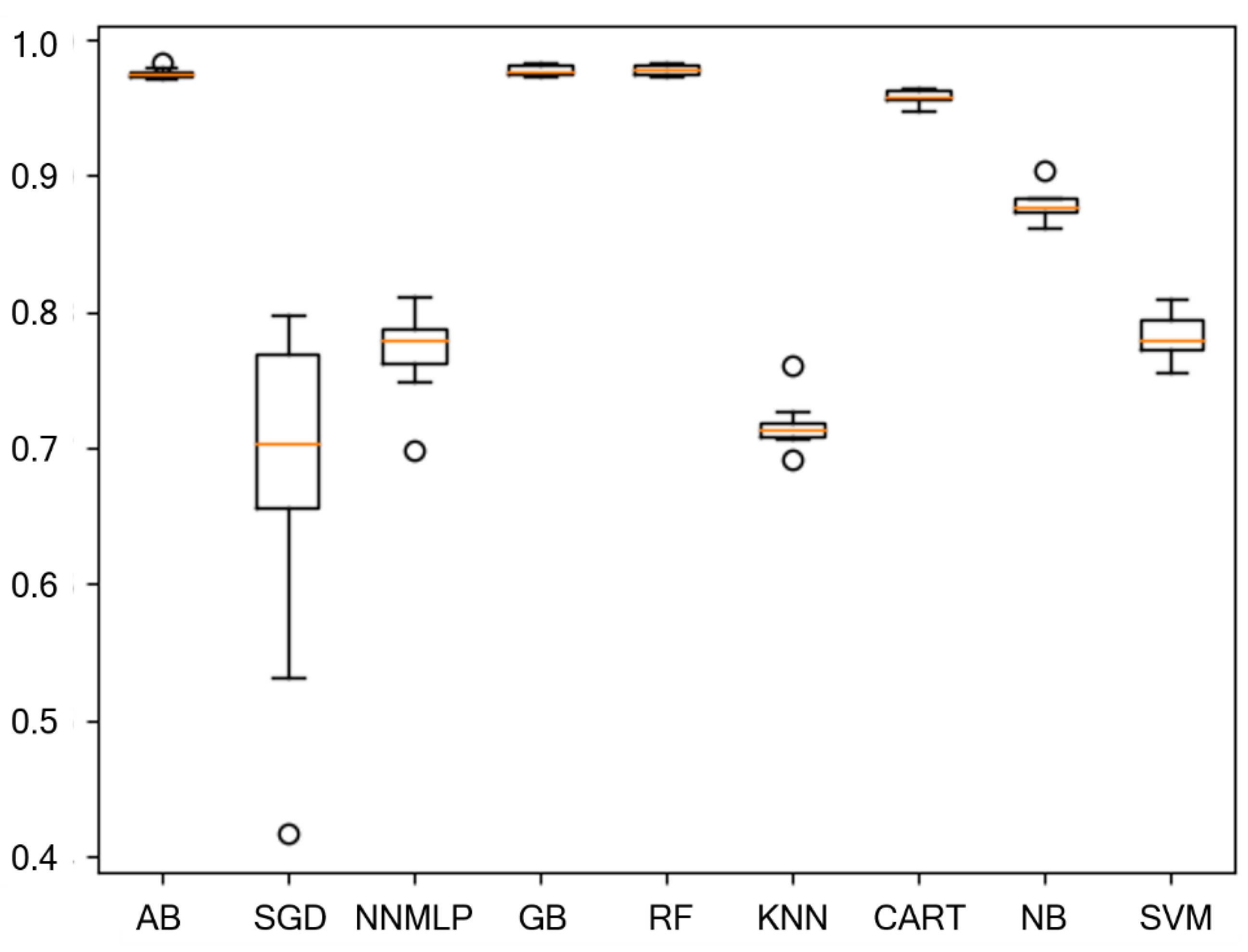
| Machine Learning Technique | Accuracy |
|---|---|
| adaptive boosting (AB) | 97.57% 1 |
| linear classifiers with stochastic gradient descent training (SGD) | 67.96% |
| neural network (multilayer perceptron) (NNMLP) | 77.27% |
| gradient boosting (GB) | 97.78% 1 |
| random forest (RF) | 97.83% 1 |
| k-nearest neighbors (KNN) | 71.70% |
| decision tree (CART) | 95.80% 1 |
| naive bayes (gaussian) (NB) | 87.85% |
| support vector machine (C-support vector) (SVM) | 78.31% |
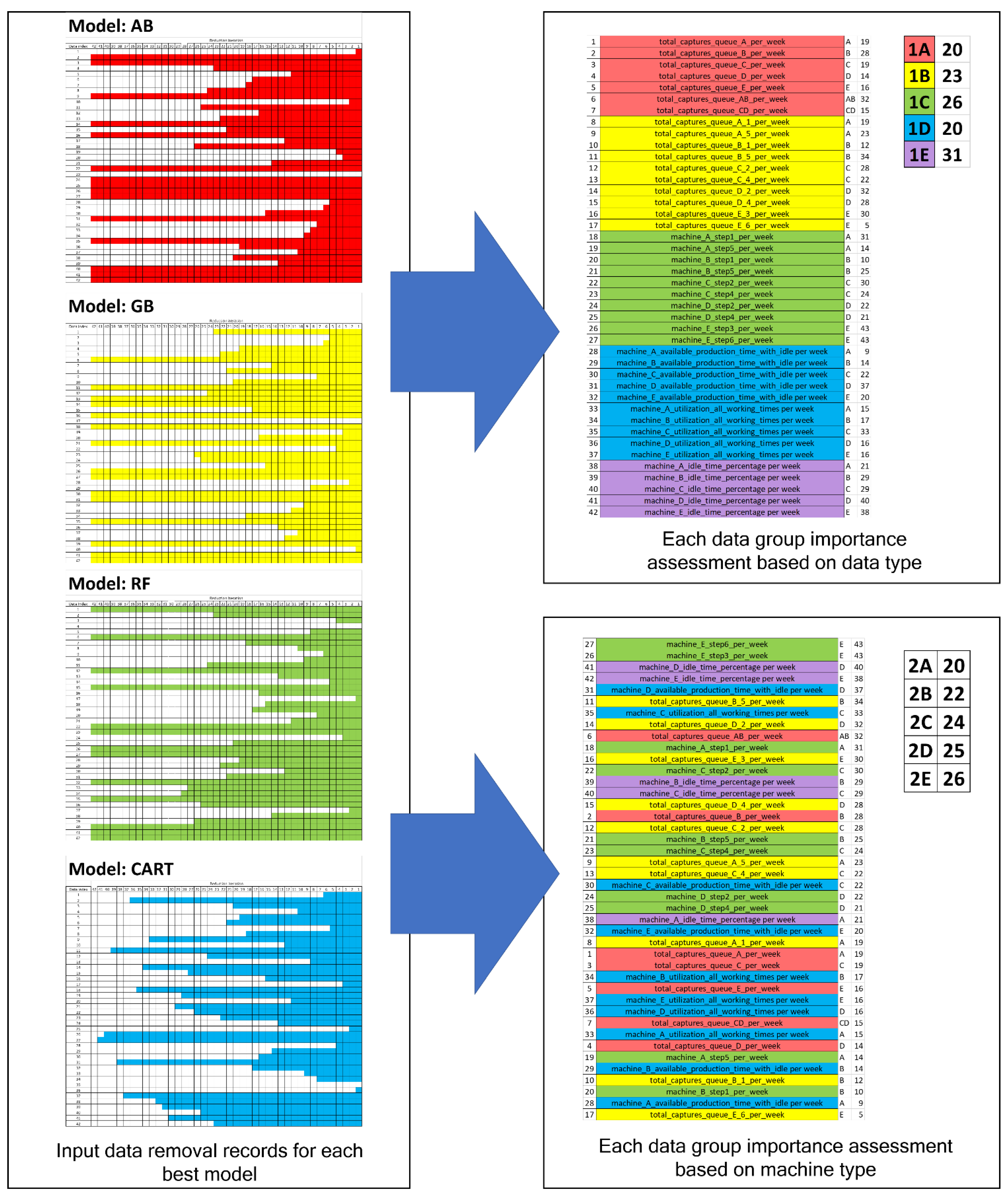
| Best Model | Input Data Combination (with Indices in Table 3) | Accuracy (with Selected Input Parameters) |
|---|---|---|
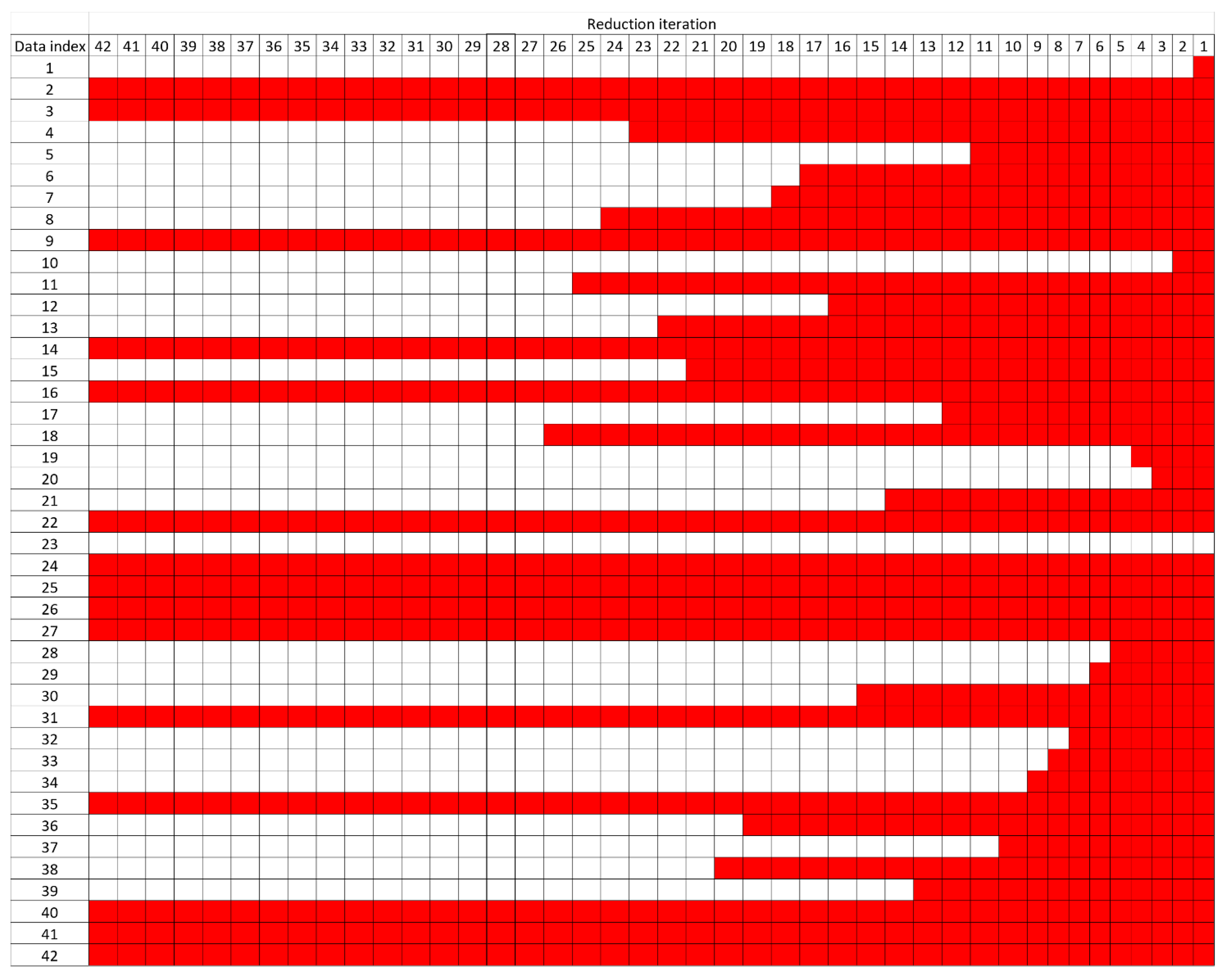
| AB | 2–3, 9, 14, 16, 18, 22, 24–27, 31, 35, 40–42 | 97.88% 1 |
| GB | 6, 11, 13–14, 16, 18, 21, 26–27, 30–31, 35, 39, 41–42 | 97.88% 1 |
| RF | 1, 6, 12, 15, 22–23, 26–27, 32, 35, 41–42 | 97.88% 1 |
| CART | 27 | 97.82% |
| Grouping Rule | Groups and Definitions | Included Input Data |
|---|---|---|
| (1) data type | (group 1A) number of wafer lots waiting at each machine (without processing step consideration) | 1–7 |
| (group 1B) number of wafer lots waiting at each machine (with processing step consideration) | 8–17 | |
| (group 1C) number of processed wafer lots (with processing step consideration) | 18–27 | |
| (group 1D) percentages of available machines’ production times after excluding maintenance times | 28–37 | |
| (group 1E) percentage of machines’ total idle times | 38–42 | |
| (2) machine | (group 2A) machine A-related input data | 1,6,8–9,18–19,28,33,38 |
| (group 2B) machine B-related input data | 2,6,10–11,20–21,29,34,39 | |
| (group 2C) machine C-related input data | 3,7,12–13,22–23,30,35,40 | |
| (group 2D) machine D-related input data | 4,7,14–15,24–25,31,36,41 | |
| (group 2E) machine E-related input data | 5,16–17,26–27,32,37,42 |
| Best Model | Data Class | Evaluation Metrics | Number of Correctly Classified Data | |||
|---|---|---|---|---|---|---|
| Precision | Recall | F1-score | Support | |||
| AB | good | 0.98 | 0.95 | 0.96 | 729 | 691 |
| bad | 0.97 | 0.99 | 0.98 | 1289 | 1275 | |
| GB | good | 0.98 | 0.96 | 0.97 | 729 | 699 |
| bad | 0.98 | 0.99 | 0.98 | 1289 | 1272 | |
| RF | good | 0.98 | 0.96 | 0.97 | 729 | 699 |
| bad | 0.98 | 0.99 | 0.98 | 1289 | 1272 | |
| CART | good | 0.98 | 0.96 | 0.97 | 729 | 699 |
| bad | 0.98 | 0.99 | 0.98 | 1289 | 1272 | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Singgih, I.K. Production Flow Analysis in a Semiconductor Fab Using Machine Learning Techniques. Processes 2021, 9, 407. https://doi.org/10.3390/pr9030407
Singgih IK. Production Flow Analysis in a Semiconductor Fab Using Machine Learning Techniques. Processes. 2021; 9(3):407. https://doi.org/10.3390/pr9030407
Chicago/Turabian StyleSinggih, Ivan Kristianto. 2021. "Production Flow Analysis in a Semiconductor Fab Using Machine Learning Techniques" Processes 9, no. 3: 407. https://doi.org/10.3390/pr9030407
APA StyleSinggih, I. K. (2021). Production Flow Analysis in a Semiconductor Fab Using Machine Learning Techniques. Processes, 9(3), 407. https://doi.org/10.3390/pr9030407