1. Introduction
The problem of assigning resources to respond to a stochastic demand is a ubiquitous topic in operational research. The trade-off between service quality and operational efficiency is a crucial aspect of the Emergency Medical Services (EMS), where the lives of patients depend on the timeliness of care. Thus, the development of Key Performance Indicators (KPIs) to objectively quantify the performance across the operational, clinical and financial departments is a current demand of an industry that is becoming increasingly data-driven. KPIs are the basic tools for planners, and the nature of each KPI selects a particular feature of the system and determines its data gathering strategy.
Among the most intuitive and used operational KPIs in EMS are the successive times involved in the service cycle: call reception, patient triage, dispatch, ambulance turnout, travel from the base to the emergency site, paramedic care, eventual transfer of the patient to a hospital and return of the ambulance to its base. Response time (the interval between the reception of an emergency call and the arrival of a paramedic at the scene of the event) is a common operational metric of EMS, and it is considered a good indication of the quality offered by the service [
1]. One reason for its popularity as a KPI resides in the fact that it is directly quantifiable and easily understood by the public and policy makers. Additionally, the EMS industry has the goal of providing care within eight minutes for cardiac arrest [
2] and major trauma [
3]. However, there is evidence that exceeding that response time criterion does not affect patient survival after a traumatic impact injury [
4,
5]. Moreover, solutions that only focus on shortening the response time are cost prohibitive and put the safety of patients, attendant crew and the public at risk [
6]. A rational approach to the ambulance business process should simultaneously consider multiple metrics and operational trade-off between administrator-oriented and patient-centered KPIs [
7].
One of the most important aspects of emergency medical management is avoiding the oversaturation of the system. Therefore, in this work, we consider the First-Passage Time (FPT) [
8] to the critical condition, under which there will be not available servers to respond to the next incoming call. Criticality prediction is of special interest for the quality of the medical service (response time off-target) as well as for the financial management of the service, given that, as we will see, the critical condition strongly depends on the number
L of ambulances simultaneously in service and because queueing a call may involve transferring it to another EMS. Any system operating under fixed conditions with a given number of servers and a First-Come First-Served (FCFS) discipline is a discrete one-dimensional stochastic process over the occupation states of servers. Therefore, the first-passage time to the state of oversaturation, in which there are no available servers, is finite. The question is how long is that time. Thus, the mean first-passage time (MFPT) becomes a relevant key performance indicator for the operational condition in EMS.
In urban emergency services logistics, there are two distinct fields: capacity planning and location analysis. Both fields are interrelated in the districting problem or how the region should be partitioned into areas of primary responsibility (districts) [
9,
10]. Here, MFPT can be applied to an operational subarea or district, preferably intended to be independently served by a subset of ambulances (intradistrict dispatches). In this case, MFPT gives us the average time to request an ambulance from another operational zone to answer the next emergency call when the primary equipment is busy (interdistrict dispatches). MFPT can also be a useful KPI in the decision-making process of emergency departments [
11,
12], where MFPT provides the average time to a shortage of intensive therapy beds when the FCFS discipline is used after the patient’s triage.
Queueing theory has been widely applied in health care in the last 70 years [
13]. Since Larson’s seminal article [
9], quite a few queueing models have been developed to incorporate the intrinsic probabilistic nature of urban EMS derived from the Poisson nature of the call arrival process and the variability in service times. Multiple queueing systems have been developed that respond with different emphasis on the KPIs selected in each case. In this contribution, we use a birth–death process to properly analyse the dependence of MFPT on the number of servers and the rest of the system’s operational parameters. The birth–death process is basic to queueing models involving exponential inter-arrival and service time distributions. In the Kendall–Lee notation, we have
[
8]. Thus, our analytical model is based only on two average times:
, the mean inter-arrival time, and
, the mean service time of a single server, that is, the time it takes for an ambulance to complete a trip from the instant a call is assigned until the release of this server. Several analytical results are well known in operational research under that assumption [
8].
However, experimental evidence from an emergency service indicates that service time distributions are well fitted by lognormal distributions [
12,
14,
15,
16]. Hence, our objective is also to numerically evaluate the deviation between analytical and simulated results for MFPT. Thus, we present an
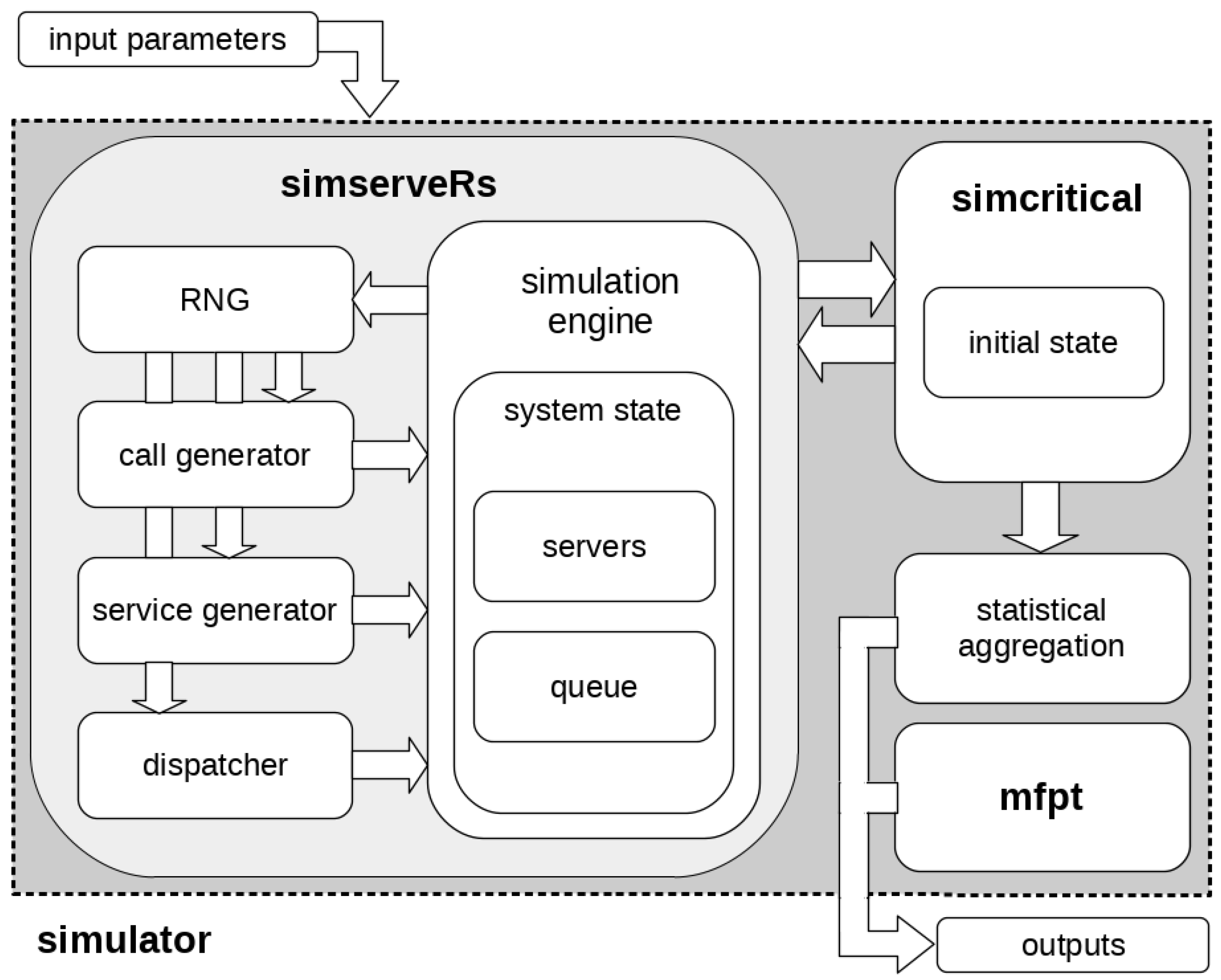
R-simulator for a system of
L servers in parallel with general distributions for inter-arrival and service times and FCFS discipline:
[
8]. This tool allows the user to calculate the key performance indicators of direct interest in the industry beyond the known analytical results, which are limited to exponential distributions. Particularly, we show our work on Mean First-Passage Time (MFPT) to system critical condition.
In this way, the motivation of our work is two-fold. On the one hand, we provide an explicit analytical expression for the MFPT to the critical condition, and, on the other hand, under more realistic conditions, we analyse the validity of our assumptions through exhaustive simulations. In
Section 2, we provide our analytical expression for MFPT and explore the generic nature of the method, postponing detailed mathematical derivations to the appendices. Additionally, in that section, we describe the simulation framework for experimentation.
Section 3 deals with the numerical results, and last, in
Section 4, we discuss the importance of our contribution.
3. Results
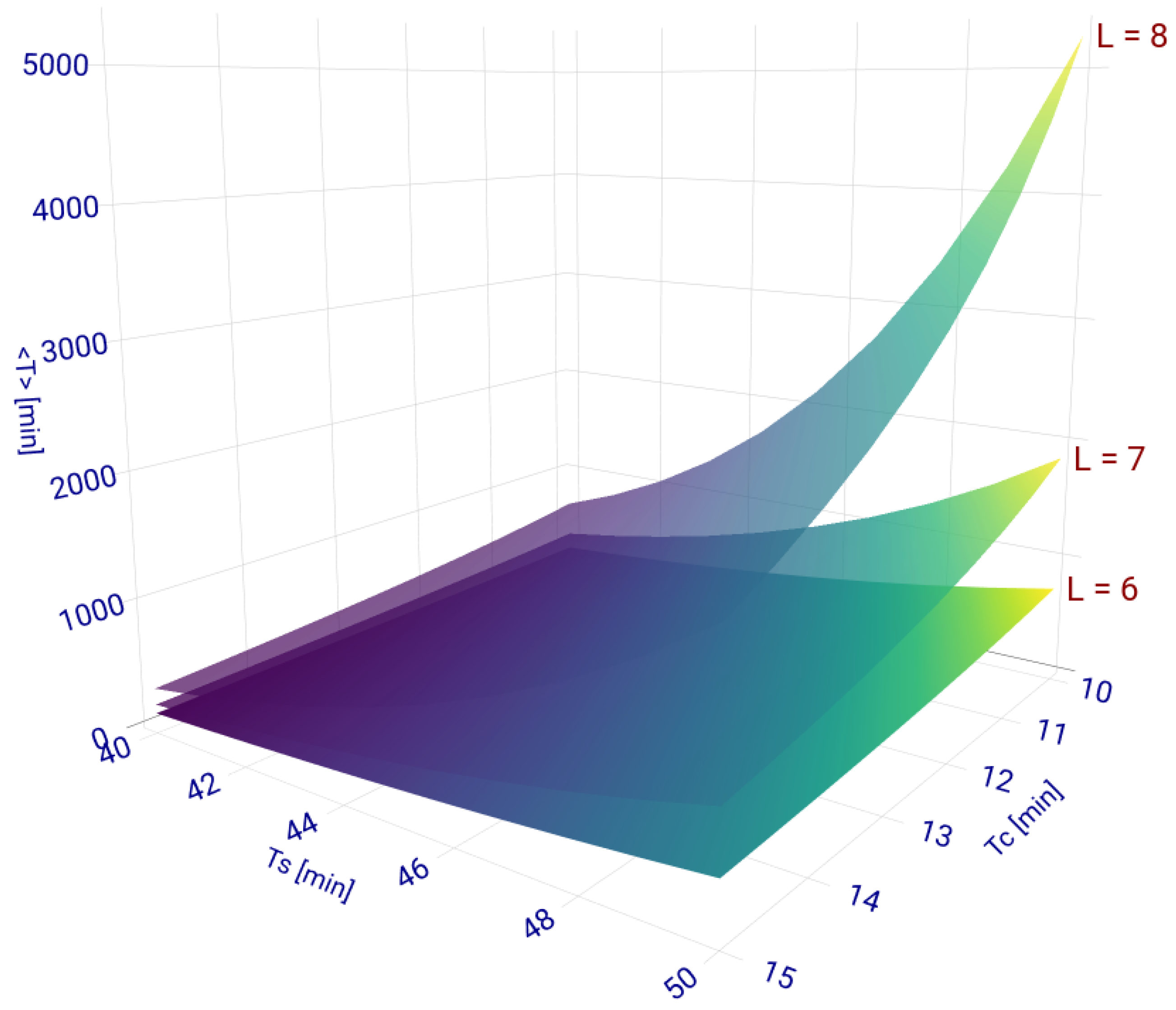
In
Figure 2, we show the non-linear behaviour of
as a function of
and
and its strong dependence on
L, as they are derived from Equations (
2)–(
4).
The non-linear nature of
is given by the powers of
in Equation (
2) and implies a sensitive dependence of the time to the critical condition on its variables. Thus, on the scale of the figure, variations in the order of one minute in
or
may represent variations of tens to thousands of minutes in
. The value of
L determines the number of terms in Equations (
2) and (
3). Therefore, adding or removing a server, with the same values of
and
, can make a substantial change in the value of the average MFPT, as can be seen in
Figure 2. The sensitivity of our problem on its parameters is very difficult to grasp intuitively and to predict from past experiences in practice.
The main reason for using the birth and death queueing model (
) is the fact that we can derive the closed-form result given in
Section 2. However, the analytical prediction of any performance measure needs to be contrasted with numerical outputs from more realistic scenarios. As an illustration, we take values of inter-arrival and service times measured by the EMS
Sistema de Urgencias del Rosafe (URG) [
25] in Córdoba, Argentina. URG is one of several private EMS operators in a city of about 1.39 million inhabitants. In 2016, URG operated a fleet of nine ambulances that were usually stationed in predefined parking spots scattered throughout the metropolitan zone. The operating scenario distinguishes several daily time bands within which the mean values
and
are relatively constant, although these, in turn, show seasonal changes throughout the year.
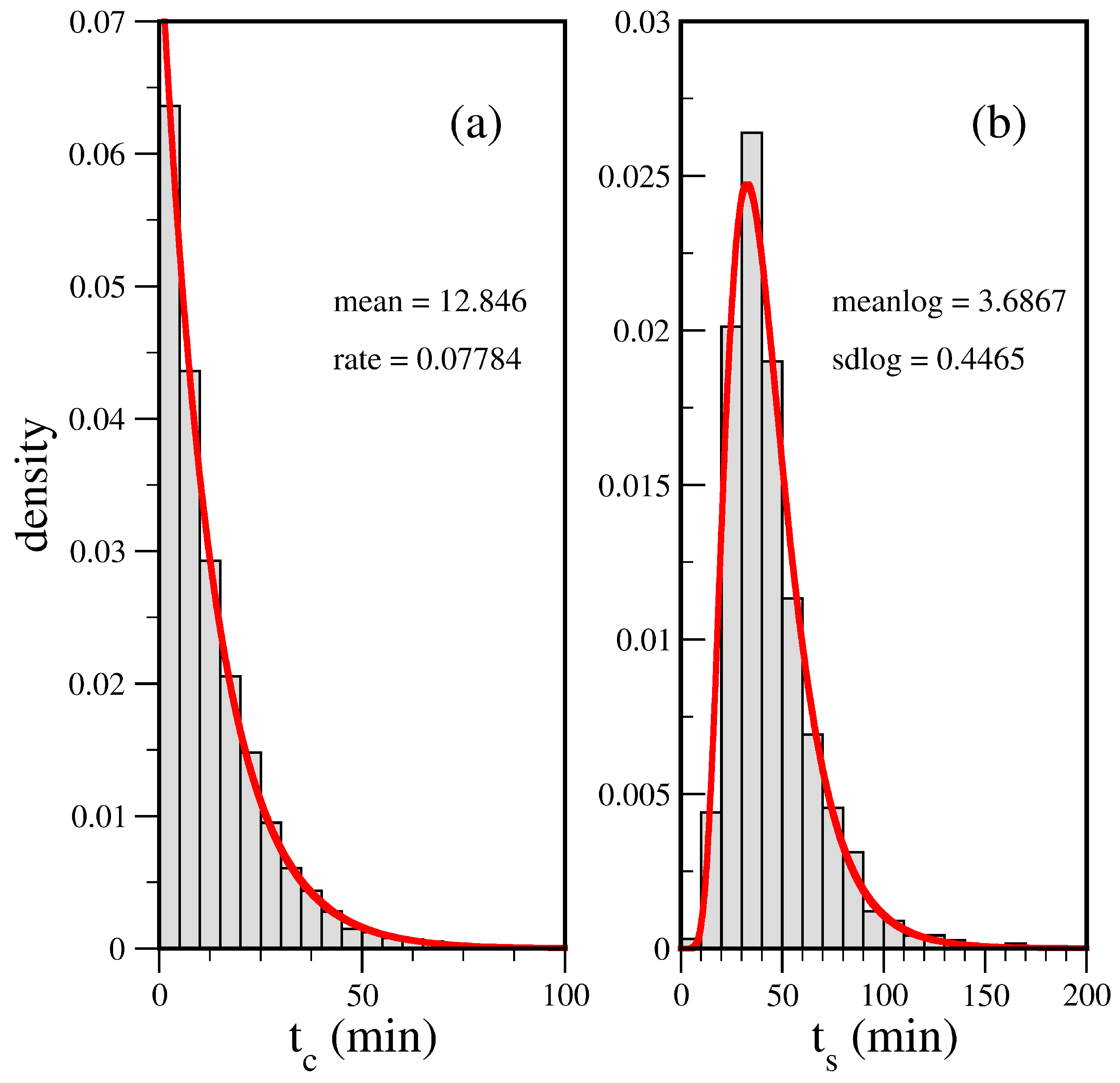
In
Figure 3, we show histograms of real data corresponding to 2568 calls received by URG between May 1 and October 31, 2016, late evening (20:00 to 23:00 h). In this time period, we found good stationary statistics in the data, and no critical condition was reported in which there were no ambulances available to serve a call. The service time value measures the time elapsed from dispatch until the ambulance is released. Very low service times correspond to situations that were quickly resolved at scenes close to the ambulance base, whereas the distribution tail involves complex cases with the transfer of the patient to a hospital.
From the figure, we can see that the inter-arrival times fit perfectly with an exponential distribution ( min, goodness-of-fit tests: Kolmogorov–Smirnov p-value , Cramer–von Mises p-value ), but the best fit for service times is with a lognormal distribution ( min, goodness-of-fit tests: Kolmogorov–Smirnov p-value , Cramer–von Mises p-value ). Thus, in this case, it is apparent that the main limitation of our analytical model is the assumption that the distribution of service times is exponential.
The input traffic to a call centre is a nonstationary Poisson process [
7,
14,
26]. However, the arrival rate function
is roughly constant over periods of a few hours [
11,
14,
16,
27]. Lognormal distributions for service times have already been reported in the literature [
12,
14,
15,
16]. The fact that the distribution of the sum of a few independent, but not necessarily identical, lognormal random variables could be approximated by a lognormal distribution [
28] may explain the experimental findings when we only use two fitting parameters.
In
Table 1, we show a comparison between analytical results given by Equation (
2) and simulated MFPT from each initial state of a system with seven servers to the critical condition. The simulations were performed using the fitted distributions in
Figure 3 and also using an exponential distribution for service times with a mean value equal to that of the fitted distribution in the right panel.
The analytical predictions agree perfectly with the simulations for the exponentially distributed service times in all cases. For the lognormal distribution of service times, the deviations between the prediction and simulation are about in the worst situations. However, these cases are of little practical interest. Given a fixed number of servers, low values of imply very low MFPT values that are incompatible with EMS response times, while situations with very high values of MFPT are often related with idle infrastructure, which are also avoided in practice.
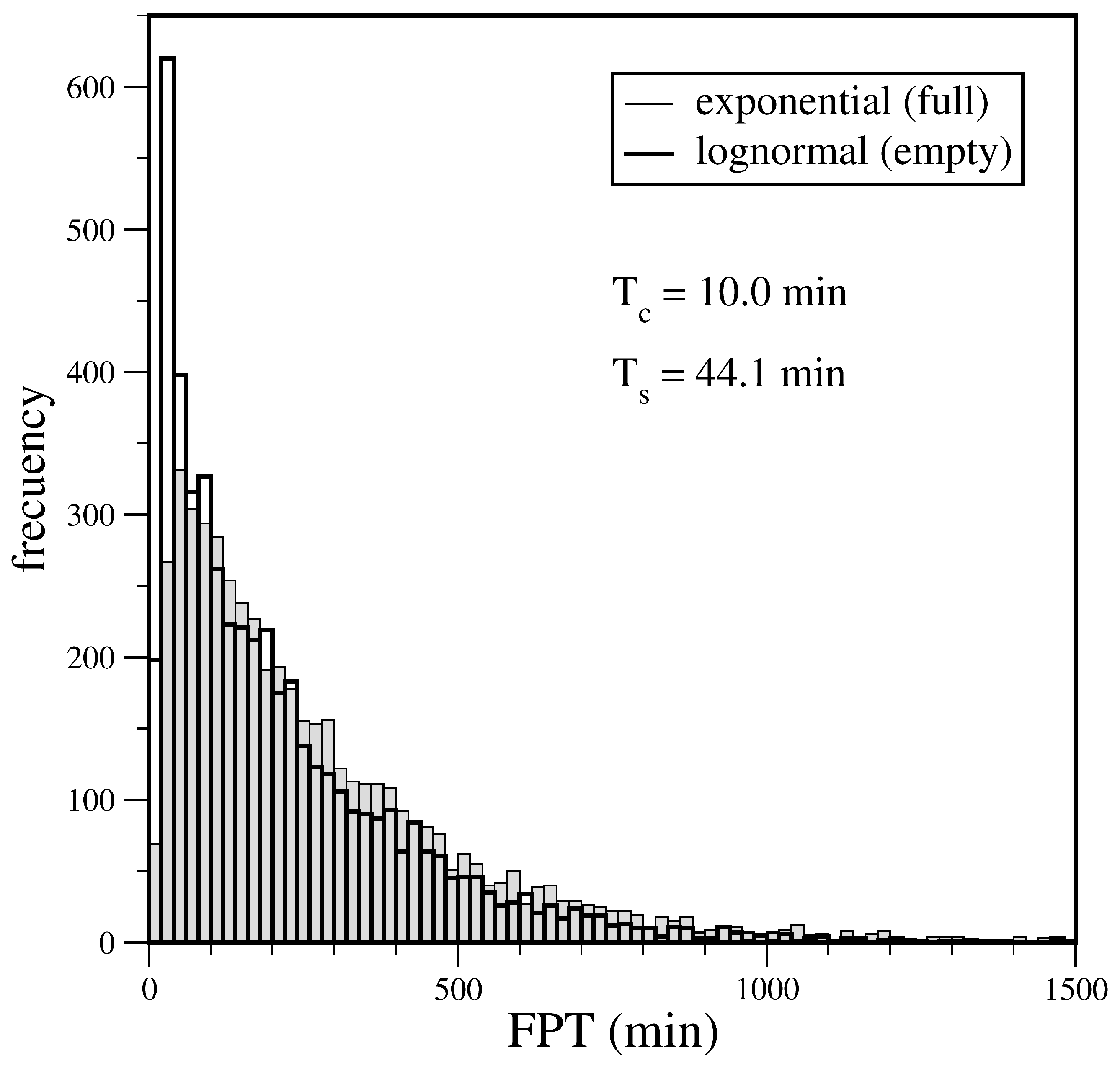
In order to study the differences in the values of FPT under different service time distributions, in
Figure 4, we superimpose two histograms of simulated values for a system with seven servers. Both cases correspond to an initial condition with four occupied servers and the same exponential inter-arrival time distribution, but we use two different service time distributions with the same mean value. The FPT distribution with exponential service times is broader than the lognormal counterpart. Therefore, the MFPT under these conditions is shorter for the lognormal service time distribution (also see entry for initial state equal to 4 in
Table 1).
Now, we investigate what happens with the residence probabilities in the long time limit. The analytical result given by the Erlang formula has been proven for systems without queue or
blocking systems [
19,
20]. That is, if every server is busy when a call arrives, the call is lost; however, it is instructive to analyse the situation of a system with queue. The probability of residence in the queue,
, is equivalent to the probability absorbed in the site
of the Markov chain. From Equation (A11), we can see that the probabilities in Equation (4) are the renormalized residence probabilities of a system with a queue in the interval [0,
L]. To find out if this is also the case for lognormal service time distributions, we run our simulator
min in order to visit each state several times. In the first column of
Table 2, we show the analytic result of Equations (
A11)–(
A13) and compare this prediction with the simulated values using four different service time distributions: an exponential and three different lognormal service time distributions—all of these with the same value
min (
min in all cases). The value
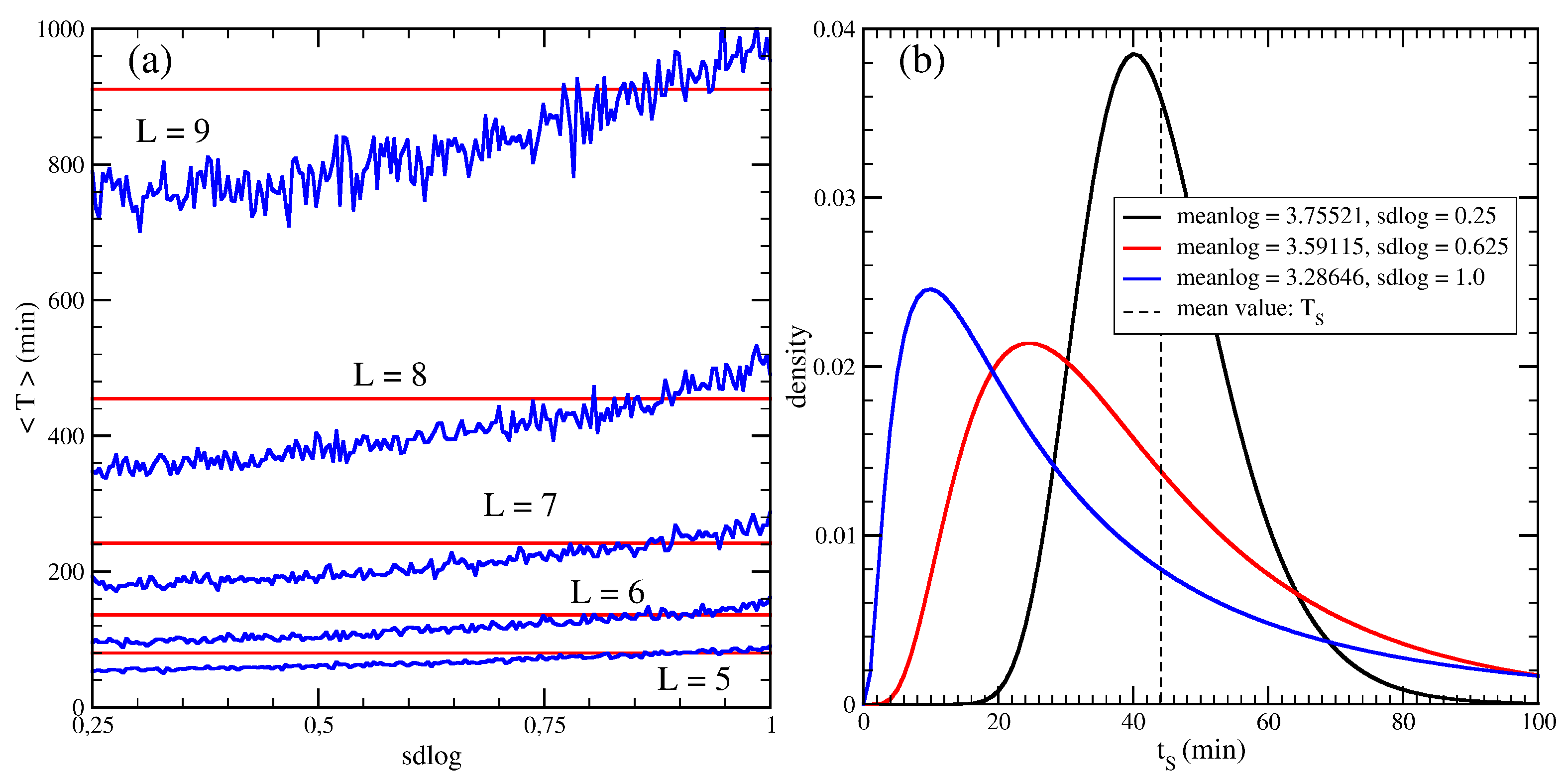
sdlog = 0.25 corresponds to the almost symmetric case of the lognormal distribution, and
sdlog = 1 corresponds to the more asymmetric situation (see Figure 6b). The exponential distribution is the case completely asymmetric, where the distribution does not have a maximum value. For comparison, we also introduce the middle value
sdlog.
The difference among analytical and simulated values are less than
in all states with the exception of the queue. The analysed case with queue is a worse situation than the finite chain with both reflecting ends, used in the derivation of Equation (
4), because of the probability of residence in the queue may be greater than the saturated state. Therefore, we find it is valid to use the analytic result of Equation (
4) for taking the average in Equation (
3) and also in the simulation of MFPT with lognormal service time distributions in a system with queue.
In
Figure 5, we show the plots of MFPT averaged over the initial conditions,
, as a function of the mean inter-arrival time
using the probabilities given by Equation (
4). We have sketched a characteristic situation for the service time, and we considered several numbers of servers
. The curves clearly show the non-linear behaviour of
and allow us to evaluate the quality of the fit for the simulated situations achieved with our analytical expression.
Again, in the left panel, we find excellent agreement among the analytical predictions and the simulations for exponentially distributed service times. In contrast, in the right panel, for lognormal distributed service times, we see that the analytical curves always run over the corresponding simulation. This fact has just been seen in
Figure 4, where the FPT distribution has a longer tail in the case of service times distributed exponentially with respect to lognormal service times. Thus, the mean value of the FPT distribution (MFPT) is higher for exponential service times. Therefore, the analytic model underestimates the number of necessary servers under a given stress condition. Drawing a horizontal line in
Figure 5b, when we move in the direction of increasing demand (that is, lowering
), we first cross the blue (simulated) curves in all the considered cases. This is an important fact to keep in mind if we want to use the analytical model to find the best number of servers in a particular operational scenario. However, the discrepancies observed between the simulations and the closed form expression for the average MFPT are not significant enough to cause a considerable effect in the estimation of the optimal number of servers, given the separation among the curves for different values of
L. Thus, for example, from
Figure 5b, we can see that to obtain an average MFPT of 6 hs, given
min, six servers are needed, whereas for
, eight servers are needed under the same service conditions.
We also analyse the effect of asymmetry in the service time distribution on average MFPT. For this purpose, we simulate the average MFPT for a whole family of service time distribution with fixed
but changing the parameter
sdlog in the interval
, where the minimum value corresponds to the almost symmetric case and the maximum corresponds to the more asymmetric situation. The average MFPT as a function of the
sdlog parameter is shown in
Figure 6.
In all cases, the analytical prediction gives an acceptable approximation for the simulated data.
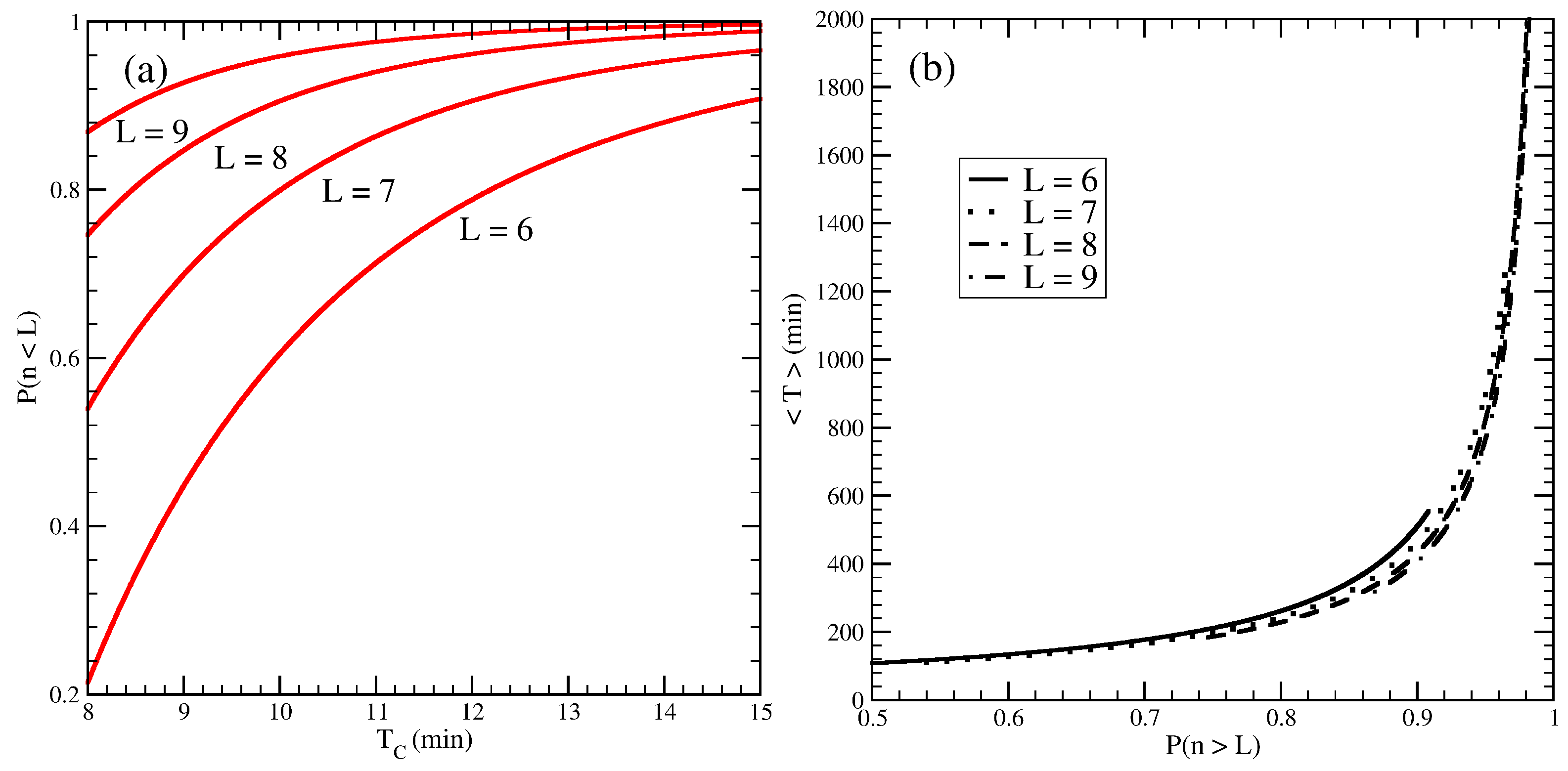
Finally, in the left panel of
Figure 7, we plot the probability that one or more servers are available at the instant of a emergency call,
[
27], as a function of the time between calls for a fixed mean service time. We are using Equation (
4) for the calculation of this probability. In the right panel, we plot the average MFPT as a function of this availability probability for the same values of
given in the left panel. We can observe a very strong sensitivity of the average MFPT to the availability probability for high values of system availability. Thus, only controlling the availability of the system is not enough to assure a long enough time to the critical condition. A dispatcher observing a high availability probability value might conclude that the system is running unreasonably idle; however, the time to critical condition may be shorter than the expectation. More interesting, however, is that the function
vs.
is practically independent of the number of servers.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}