




Knowledge Transfer Based on Particle Filters for Multi-Objective Optimization


Abstract
:1. Introduction
2. Background
2.1. Particle Filter
| Algorithm 1 General particle filter. |
|
2.2. Particle Filter Optimization for Global Optimization
- Randomly generate a set/population of candidate solutions from an intermediate distribution over the solution space.
- Update the intermediate distribution using the candidate solutions to obtain a new distribution ; increase k by 1 and reiterate from step 1.
| Algorithm 2 General particle filter optimization framework. |
|
3. Proposed Algorithm
3.1. Algorithm Framework
| Algorithm 3 Particle filter multiobjective optimization. |
|
3.2. The Design of Target Distribution
3.3. The Sampling Procedure
3.4. Particle Move
| Algorithm 4 A Metropolis sampling method based on genetic operators. |
|
4. Comparative Studies
4.1. Test Problems
4.2. Performance Metrics
4.3. Experimental Settings
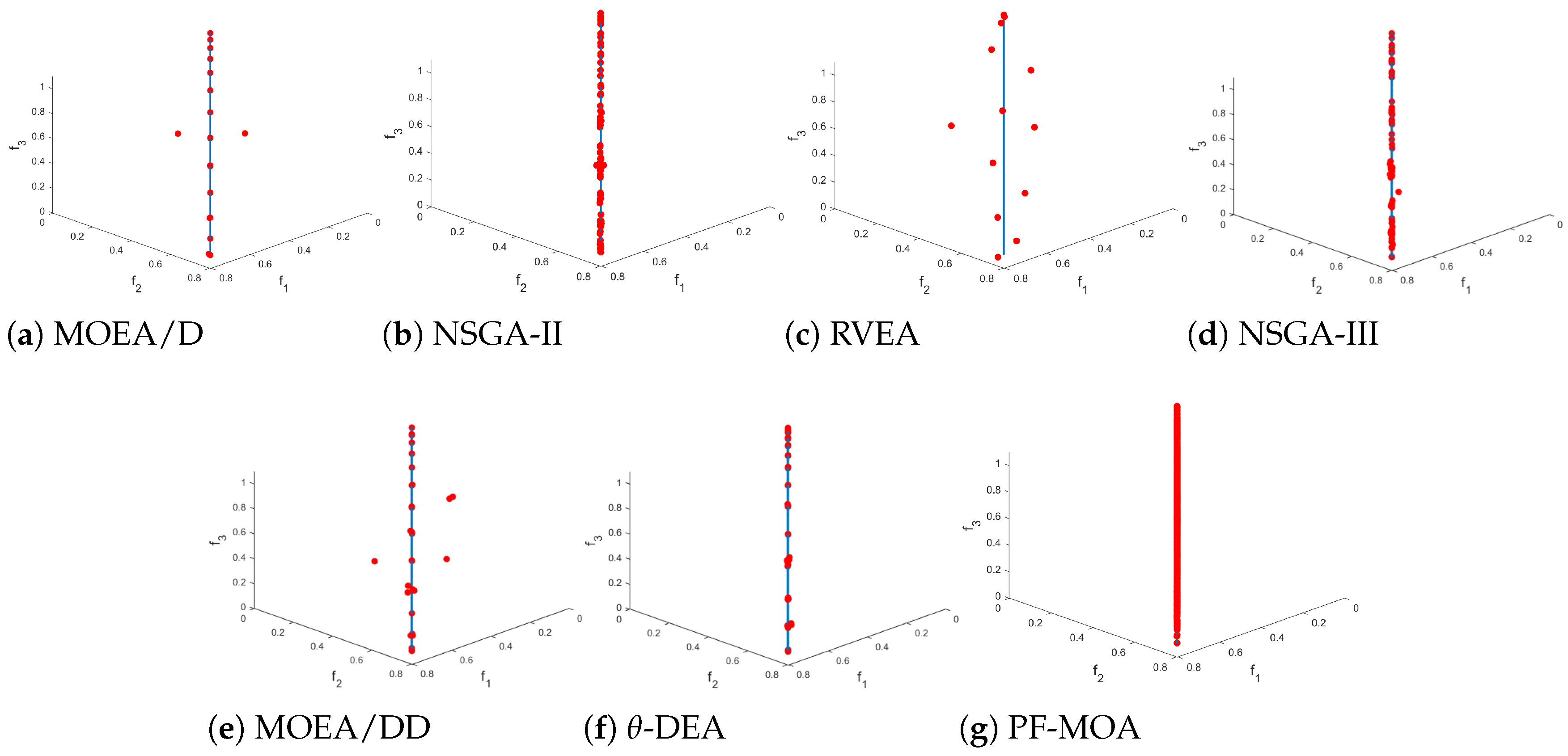
4.4. Experimental Results
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- He, C.; Huang, S.; Cheng, R.; Tan, K.C.; Jin, Y. Evolutionary Multiobjective Optimization Driven by Generative Adversarial Networks (GANs). IEEE Trans. Cybern. 2021, 51, 3129–3142. [Google Scholar] [CrossRef]
- Marler, R.T.; Arora, J.S. Survey of multi-objective optimization methods for engineering. Struct. Multidiscip. Optim. 2004, 26, 369–395. [Google Scholar] [CrossRef]
- Kaliszewski, I. A modified weighted Tchebycheff metric for multiple objective programming. Comput. Oper. Res. 1987, 14, 315–323. [Google Scholar] [CrossRef]
- Tseng, C.; Lu, T. Minimax multiobjective optimization in structural design. Int. J. Numer. Methods Eng. 1990, 30, 1213–1228. [Google Scholar] [CrossRef]
- Miettinen, K. Nonlinear Multiobjective Optimization; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2012; Volume 12. [Google Scholar]
- Ogryczak, W. A goal programming model of the reference point method. Ann. Oper. Res. 1994, 51, 33–44. [Google Scholar] [CrossRef]
- Jin, Y.; Wang, H.; Chugh, T.; Guo, D.; Miettinen, K. Data-driven evolutionary optimization: An overview and case studies. IEEE Trans. Evol. Comput. 2018, 23, 442–458. [Google Scholar] [CrossRef]
- Dasgupta, D.; Michalewicz, Z. Evolutionary Algorithms in Engineering Applications; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2013. [Google Scholar]
- Deb, K.; Pratap, A.; Agarwal, S.; Meyarivan, T. A fast and elitist multiobjective genetic algorithm: NSGA-II. IEEE Trans. Evol. Comput. 2002, 6, 182–197. [Google Scholar] [CrossRef] [Green Version]
- Zhang, Q.; Li, H. MOEA/D: A multiobjective evolutionary algorithm based on decomposition. IEEE Trans. Evol. Comput. 2007, 11, 712–731. [Google Scholar] [CrossRef]
- Cheng, R.; Jin, Y.; Olhofer, M.; Sendhoff, B. A reference vector guided evolutionary algorithm for many-objective optimization. IEEE Trans. Evol. Comput. 2016, 20, 773–791. [Google Scholar] [CrossRef] [Green Version]
- Zitzler, E.; Laumanns, M.; Thiele, L. SPEA2: Improving the strength Pareto evolutionary algorithm. TIK-Report 2001, 103. [Google Scholar] [CrossRef]
- Deb, K.; Jain, H. An evolutionary many-objective optimization algorithm using reference-point-based nondominated sorting approach, part I: Solving problems with box constraints. IEEE Trans. Evol. Comput. 2013, 18, 577–601. [Google Scholar] [CrossRef]
- Yuan, Y.; Xu, H.; Wang, B.; Yao, X. A new dominance relation-based evolutionary algorithm for many-objective optimization. IEEE Trans. Evol. Comput. 2015, 20, 16–37. [Google Scholar] [CrossRef]
- Li, K.; Deb, K.; Zhang, Q.; Kwong, S. An evolutionary many-objective optimization algorithm based on dominance and decomposition. IEEE Trans. Evol. Comput. 2014, 19, 694–716. [Google Scholar] [CrossRef]
- Zhang, T.; Xu, C.; Yang, M.H. Multi-task correlation particle filter for robust object tracking. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4335–4343. [Google Scholar]
- Cappello, F.; Sabatini, R.; Ramasamy, S.; Marino, M. Particle filter based multi-sensor data fusion techniques for RPAS navigation and guidance. In Proceedings of the 2015 IEEE Metrology for Aerospace (MetroAeroSpace), Benevento, Italy, 4–5 June 2015; pp. 395–400. [Google Scholar]
- Orchard, M.E.; Vachtsevanos, G.J. A particle-filtering approach for on-line fault diagnosis and failure prognosis. Trans. Inst. Meas. Control 2009, 31, 221–246. [Google Scholar] [CrossRef]
- Schutte, J.F.; Reinbolt, J.A.; Fregly, B.J.; Haftka, R.T.; George, A.D. Parallel global optimization with the particle swarm algorithm. Int. J. Numer. Methods Eng. 2004, 61, 2296–2315. [Google Scholar] [CrossRef] [Green Version]
- Hou, Y.; Hao, G.; Zhang, Y.; Gu, F.; Xu, W. A multi-objective discrete particle swarm optimization method for particle routing in distributed particle filters. Knowl.-Based Syst. 2022, 240, 108068. [Google Scholar] [CrossRef]
- Ji, C.; Zhang, Y.; Tong, M.; Yang, S. Particle filter with swarm move for optimization. In Proceedings of the International Conference on Parallel Problem Solving from Nature, Dortmund, Germany, 13–17 September 2008; Springer: Berlin/Heidelberg, Germany, 2008; pp. 909–918. [Google Scholar]
- Zhou, E.; Fu, M.C.; Marcus, S.I. A particle filtering framework for randomized optimization algorithms. In Proceedings of the 2008 Winter Simulation Conference, Miami, FL, USA, 7–10 December 2008; pp. 647–654. [Google Scholar]
- Martí, L.; Garcia, J.; Berlanga, A.; Coello, C.; Molina, J.M. On Current Model-Building Methods for Multi-Objective Estimation of Distribution Algorithms: Shortcommings and Directions for Improvement; Department of Informatics, Universidad Carlos III de Madrid: Madrid, Spain, 2010; Tech. Rep. GIAA 2010E001.
- Del Moral, P.; Doucet, A.; Jasra, A. Sequential monte carlo samplers. J. R. Stat. Soc. Ser. B Stat. Methodol. 2006, 68, 411–436. [Google Scholar] [CrossRef] [Green Version]
- Larrañaga, P.; Lozano, J.A. Estimation of Distribution Algorithms: A New Tool for Evolutionary Computation; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2001; Volume 2. [Google Scholar]
- Doerr, B.; Krejca, M.S. Significance-based estimation-of-distribution algorithms. IEEE Trans. Evol. Comput. 2020, 24, 1025–1034. [Google Scholar] [CrossRef] [Green Version]
- Hansen, N.; Müller, S.D.; Koumoutsakos, P. Reducing the time complexity of the derandomized evolution strategy with covariance matrix adaptation (CMA-ES). Evol. Comput. 2003, 11, 1–18. [Google Scholar] [CrossRef]
- Rubinstein, R.Y.; Kroese, D.P. The Cross-Entropy Method: A Unified Approach to Combinatorial Optimization, Monte-Carlo Simulation and Machine Learning; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2013. [Google Scholar]
- Hu, J.; Fu, M.C.; Marcus, S.I. A model reference adaptive search method for global optimization. Oper. Res. 2007, 55, 549–568. [Google Scholar] [CrossRef]
- Hu, J.; Wang, Y.; Zhou, E.; Fu, M.C.; Marcus, S.I. A survey of some model-based methods for global optimization. In Optimization, Control, and Applications of Stochastic Systems; Springer: Berlin/Heidelberg, Germany, 2012; pp. 157–179. [Google Scholar]
- Zhou, E.; Fu, M.C.; Marcus, S.I. Particle filtering framework for a class of randomized optimization algorithms. IEEE Trans. Autom. Control. 2013, 59, 1025–1030. [Google Scholar] [CrossRef] [Green Version]
- Guilmeau, T.; Chouzenoux, E.; Elvira, V. Simulated annealing: A review and a new scheme. In Proceedings of the 2021 IEEE Statistical Signal Processing Workshop (SSP), Rio de Janeiro, Brazil, 11–14 July 2021; pp. 101–105. [Google Scholar]
- Dai, C.; Heng, J.; Jacob, P.E.; Whiteley, N. An invitation to sequential Monte Carlo samplers. J. Am. Stat. Assoc. 2022, 1–38. [Google Scholar] [CrossRef]
- Deb, K.; Thiele, L.; Laumanns, M.; Zitzler, E. Scalable multi-objective optimization test problems. In Proceedings of the 2002 Congress on Evolutionary Computation, CEC’02 (Cat. No. 02TH8600), Honolulu, HI, USA, 12–17 May 2002; Volume 1, pp. 825–830. [Google Scholar]
- Huband, S.; Hingston, P.; Barone, L.; While, L. A review of multiobjective test problems and a scalable test problem toolkit. IEEE Trans. Evol. Comput. 2006, 10, 477–506. [Google Scholar] [CrossRef] [Green Version]
- Bosman, P.A.; Thierens, D. The balance between proximity and diversity in multiobjective evolutionary algorithms. IEEE Trans. Evol. Comput. 2003, 7, 174–188. [Google Scholar] [CrossRef] [Green Version]
- Zitzler, E.; Brockhoff, D.; Thiele, L. The hypervolume indicator revisited: On the design of Pareto-compliant indicators via weighted integration. In Proceedings of the International Conference on Evolutionary Multi-Criterion Optimization, Matsushima, Japan, 5–8 March 2007; pp. 862–876. [Google Scholar]
- Tian, Y.; Cheng, R.; Zhang, X.; Jin, Y. PlatEMO: A MATLAB platform for evolutionary multi-objective optimization [educational forum]. IEEE Comput. Intell. Mag. 2017, 12, 73–87. [Google Scholar] [CrossRef]


{kind=link}
| Problem | D | MOEA/D | NSGA-II | RVEA | NSGA-III | MOEA/DD | -DEA | PF-MOA |
|---|---|---|---|---|---|---|---|---|
| DTLZ1 | 7 | 2.41e-1 (3.56e-1) − | 4.00e-1 (4.17e-1) − | 4.67e-1 (2.83e-1) − | 1.86e-1 (1.73e-1) ≈ | 3.51e-1 (2.36e-1) − | 2.22e-1 (3.58e-1) − | 1.27e-1 (7.06e-2) |
| DTLZ2 | 12 | 5.48e-2 (2.21e-4) − | 6.96e-2 (2.44e-3) − | 5.59e-2 (6.45e-4) − | 5.51e-2 (2.45e-4) − | 5.54e-2 (1.95e-4) − | 5.48e-2 (4.76e-5) − | 4.11e-2 (1.01e-2) |
| DTLZ3 | 12 | 1.18e+1 (6.40e+0) − | 1.02e+1 (6.66e+0) − | 1.63e+1 (5.65e+0) – | 1.04e+1 (2.75e+0) − | 2.22e+1 (1.07e+1) − | 1.06e+1 (1.10e+0) − | 1.79e+0 (3.79e+0) |
| DTLZ4 | 12 | 4.89e-1 (3.50e-1) + | 1.15e-1 (1.44e-1) + | 5.59e-2 (5.89e-4) + | 5.51e-2 (1.20e-4) + | 5.55e-2 (7.39e-4) + | 5.49e-2 (7.99e-5) + | 6.48e-1 (2.32e-1) |
| DTLZ5 | 12 | 3.23e-2 (7.34e-4) − | 6.10e-3 (3.36e-4) − | 8.45e-2 (1.70e-2) − | 1.27e-2 (2.16e-3) − | 3.13e-2 (1.03e-3) − | 3.01e-2 (2.18e-3) − | 3.87e-3 (1.21e-3) |
| DTLZ6 | 12 | 2.09e-1 (3.93e-1) + | 3.58e-2 (1.61e-1) + | 1.46e-1 (1.42e-1) + | 1.89e-2 (2.42e-3) + | 1.00e-1 (1.39e-1) + | 3.81e-2 (1.71e-3) + | 7.63e+0 (3.62e-1) |
| DTLZ7 | 22 | 2.19e-1 (1.99e-1) + | 1.13e-1 (6.90e-2) + | 2.02e-1 (5.32e-2) + | 1.61e-1 (1.39e-1) + | 4.29e-1 (2.44e-1) + | 9.62e-2 (5.39e-3) + | 7.45e+0 (6.91e-1) |
| WFG1 | 12 | 6.84e-1 (1.00e-1) + | 5.72e-1 (8.19e-2) + | 7.62e-1 (8.89e-2) | 1.03e+0 (3.60e-2) ≈ | 1.51e+0 (6.12e-3) − | 1.01e+0 (4.76e-2) ≈ | 1.82e+0 (1.41e-1) |
| WFG2 | 12 | 3.33e-1 (7.77e-2) − | 2.24e-1 (9.68e-3) − | 2.16e-1 (1.22e-2) − | 1.75e-1 (7.12e-3) − | 1.91e-1 (9.10e-3) − | 1.60e-1 (2.81e-3) − | 2.03e-2 (2.65e-2) |
| WFG3 | 12 | 3.55e-1 (1.24e-1) − | 1.29e-1 (2.21e-2) + | 2.65e-1 (2.41e-2) − | 1.65e-1 (1.40e-2) ≈ | 3.79e-1 (1.12e-1) − | 1.43e-1 (1.99e-2) + | 2.18e-1 (1.51e-2) |
| WFG4 | 12 | 2.91e-1 (1.25e-2) − | 2.82e-1 (1.04e-2) − | 2.69e-1 (7.74e-3) − | 2.32e-1 (1.67e-3) − | 2.48e-1 (3.02e-3) − | 2.29e-1 (1.10e-3) − | 1.60e-1 (2.68e-2) |
| WFG5 | 12 | 2.73e-1 (9.26e-3) + | 2.85e-1 (1.22e-2) + | 2.61e-1 (7.34e-3) + | 2.37e-1 (2.13e-3) + | 2.52e-1 (1.05e-3) + | 2.36e-1 (1.38e-3) + | 6.87e-1 (2.43e-2) |
| WFG6 | 12 | 3.44e-1 (2.25e-2) − | 3.29e-1 (1.92e-2) − | 3.37e-1 (2.06e-2) − | 2.78e-1 (2.12e-2) − | 3.04e-1 (2.23e-2) − | 2.67e-1 (1.35e-2) − | 1.71e-1 (3.38e-2) |
| WFG7 | 12 | 4.17e-1 (5.34e-2) − | 2.83e-1 (1.04e-2) ≈ | 2.89e-1 (1.33e-2) − | 2.32e-1 (1.13e-3) ≈ | 2.66e-1 (1.56e-2) ≈ | 2.29e-1 (8.96e-4) ≈ | 2.63e-1 (5.54e-2) |
| WFG8 | 12 | 3.78e-1 (2.51e-2) + | 3.75e-1 (1.02e-2) + | 3.74e-1 (1.39e-2) + | 3.20e-1 (5.91e-3) + | 3.37e-1 (7.67e-3) + | 3.16e-1 (6.32e-3) + | 5.48e-1 (3.59e-2) |
| WFG9 | 12 | 3.70e-1 (6.98e-2) − | 2.84e-1 (2.24e-2) − | 2.78e-1 (3.30e-2) − | 2.38e-1 (3.51e-3) − | 2.61e-1 (1.63e-2) − | 2.35e-1 (4.19e-3) − | 1.21e-1 (2.11e-2) |
| +/−/≈ | 6/10/0 | 7/8/1 | 6/10/0 | 5/7/4 | 5/10/1 | 6/8/2 |
| Problem | D | MOEA/D | NSGA-II | RVEA | NSGA-III | MOEA/DD | -DEA | PF-MOA |
|---|---|---|---|---|---|---|---|---|
| DTLZ1 | 7 | 6.21e-1 (3.49e-1) − | 3.60e-1 (4.02e-1) − | 2.12e-1 (2.86e-1) − | 4.57e-1 (3.40e-1) − | 2.27e-1 (3.15e-1) − | 5.78e-1 (3.33e-1) − | 9.28e-1 (7.50e-2) |
| DTLZ2 | 12 | 5.55e-1 (6.99e-4) − | 5.29e-1 (7.43e-3) − | 5.51e-1 (2.97e-3) − | 5.55e-1 (6.66e-4) − | 5.54e-1 (8.13e-4) − | 5.56e-1 (5.04e-4) − | 6.91e-1 (1.01e-4) |
| DTLZ3 | 12 | 0.00e+0 (0.00e+0) − | 0.00e+0 (0.00e+0) − | 0.00e+0 (0.00e+0) − | 0.00e+0 (0.00e+0) − | 0.00e+0 (0.00e+0) − | 0.00e+0 (0.00e+0) − | 2.00e-2 (1.27e-2) |
| DTLZ4 | 12 | 2.91e-1 (1.12e-1) ≈ | 4.96e-1 (8.42e-2) + | 5.53e-1 (1.93e-3) + | 5.56e-1 (8.24e-4) + | 5.55e-1 (1.45e-3) + | 5.55e-1 (4.87e-4) + | 2.48e-1 (1.32e-1) |
| DTLZ5 | 12 | 1.82e-1 (4.00e-4) − | 1.98e-1 (3.78e-4) − | 1.48e-1 (4.11e-3) − | 1.93e-1 (1.91e-3) − | 1.82e-1 (2.29e-4) − | 1.83e-1 (6.22e-4) − | 4.87e-1 (2.51e-4) |
| DTLZ6 | 12 | 1.77e-1 (3.83e-3) + | 1.99e-1 (1.59e-4) + | 1.35e-1 (2.14e-2) + | 1.90e-1 (1.28e-3) + | 1.54e-1 (4.42e-2) + | 1.81e-1 (1.71e-3) + | 0.00e+0 (0.00e+0) |
| DTLZ7 | 22 | 2.32e-1 (9.16e-3) + | 2.47e-1 (3.41e-3) + | 2.06e-1 (2.69e-2) + | 2.39e-1 (1.33e-2) + | 2.11e-1 (1.70e-2) + | 2.53e-1 (1.69e-3) + | 0.00e+0 (0.00e+0) |
| WFG1 | 12 | 3.72e-1 (2.30e-2) − | 4.91e-1 (4.72e-2) ≈ | 4.58e-1 (2.91e-2) − | 4.60e-1 (1.22e-2) ≈ | 2.82e-1 (5.79e-3) − | 4.61e-1 (1.74e-2) ≈ | 4.78e-1 (1.41e-2) |
| WFG2 | 12 | 8.20e-1 (3.14e-2) − | 9.07e-1 (6.22e-3) − | 8.93e-1 (1.12e-2) − | 9.09e-1 (2.33e-3) − | 8.93e-1 (1.04e-2) − | 9.16e-1 (4.92e-3) − | 9.59e-1 (1.32e-2) |
| WFG3 | 12 | 2.71e-1 (2.63e-2) − | 3.77e-1 (5.82e-3) − | 2.97e-1 (1.68e-2) − | 3.53e-1 (9.30e-3) − | 2.57e-1 (4.44e-2) − | 3.61e-1 (1.62e-2) − | 4.78e-1 (2.11e-2) |
| WFG4 | 12 | 4.91e-1 (1.41e-2) − | 5.01e-1 (6.63e-3) − | 5.17e-1 (2.21e-3) − | 5.26e-1 (2.51e-3) − | 5.19e-1 (3.28e-3) − | 5.32e-1 (1.82e-3) − | 9.51e-1 (5.11e-3) |
| WFG5 | 12 | 4.77e-1 (8.04e-3) ≈ | 4.81e-1 (2.91e-3) + | 4.98e-1 (3.27e-3) + | 5.06e-1 (4.35e-3) + | 4.94e-1 (5.37e-3) + | 5.05e-1 (3.61e-3) + | 4.43e-1 (2.63e-2) |
| WFG6 | 12 | 4.45e-1 (1.90e-2) − | 4.41e-1 (1.06e-2) − | 4.65e-1 (7.82e-3) − | 4.72e-1 (1.58e-2) − | 4.55e-1 (2.01e-2) − | 4.80e-1 (1.21e-2) − | 6.01e-1 (1.63e-2) |
| WFG7 | 12 | 4.41e-1 (2.54e-2) − | 5.10e-1 (4.93e-3) − | 5.18e-1 (7.89e-3) − | 5.31e-1 (2.05e-3) − | 5.11e-1 (1.06e-2) − | 5.35e-1 (1.96e-3) − | 7.63e-1 (1.54e-2) |
| WFG8 | 12 | 4.11e-1 (1.73e-2) − | 4.23e-1 (3.71e-3) − | 4.31e-1 (1.01e-2) − | 4.40e-1 (2.75e-3) – | 4.30e-1 (7.56e-3) − | 4.44e-1 (6.64e-3) − | 7.33e-1 (2.24e-2) |
| WFG9 | 12 | 3.87e-1 (5.17e-2) − | 4.84e-1 (7.56e-3) − | 4.95e-1 (1.15e-2) − | 5.02e-1 (4.90e-3) − | 4.92e-1 (7.97e-3) − | 5.07e-1 (7.91e-3) − | 9.38e-1 (6.11e-3) |
| +/−/≈ | 6/10/0 | 7/8/1 | 2/12/2 | 4/11/1 | 4/12/0 | 4/11/1 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, X.; Jin, Y. Knowledge Transfer Based on Particle Filters for Multi-Objective Optimization. Math. Comput. Appl. 2023, 28, 14. https://doi.org/10.3390/mca28010014
Wang X, Jin Y. Knowledge Transfer Based on Particle Filters for Multi-Objective Optimization. Mathematical and Computational Applications. 2023; 28(1):14. https://doi.org/10.3390/mca28010014
Chicago/Turabian StyleWang, Xilu, and Yaochu Jin. 2023. "Knowledge Transfer Based on Particle Filters for Multi-Objective Optimization" Mathematical and Computational Applications 28, no. 1: 14. https://doi.org/10.3390/mca28010014
APA StyleWang, X., & Jin, Y. (2023). Knowledge Transfer Based on Particle Filters for Multi-Objective Optimization. Mathematical and Computational Applications, 28(1), 14. https://doi.org/10.3390/mca28010014