A Deep Learning Framework to Remove the Off-Focused Voxels from the 3D Photons Starved Depth Images




Abstract
:1. Introduction
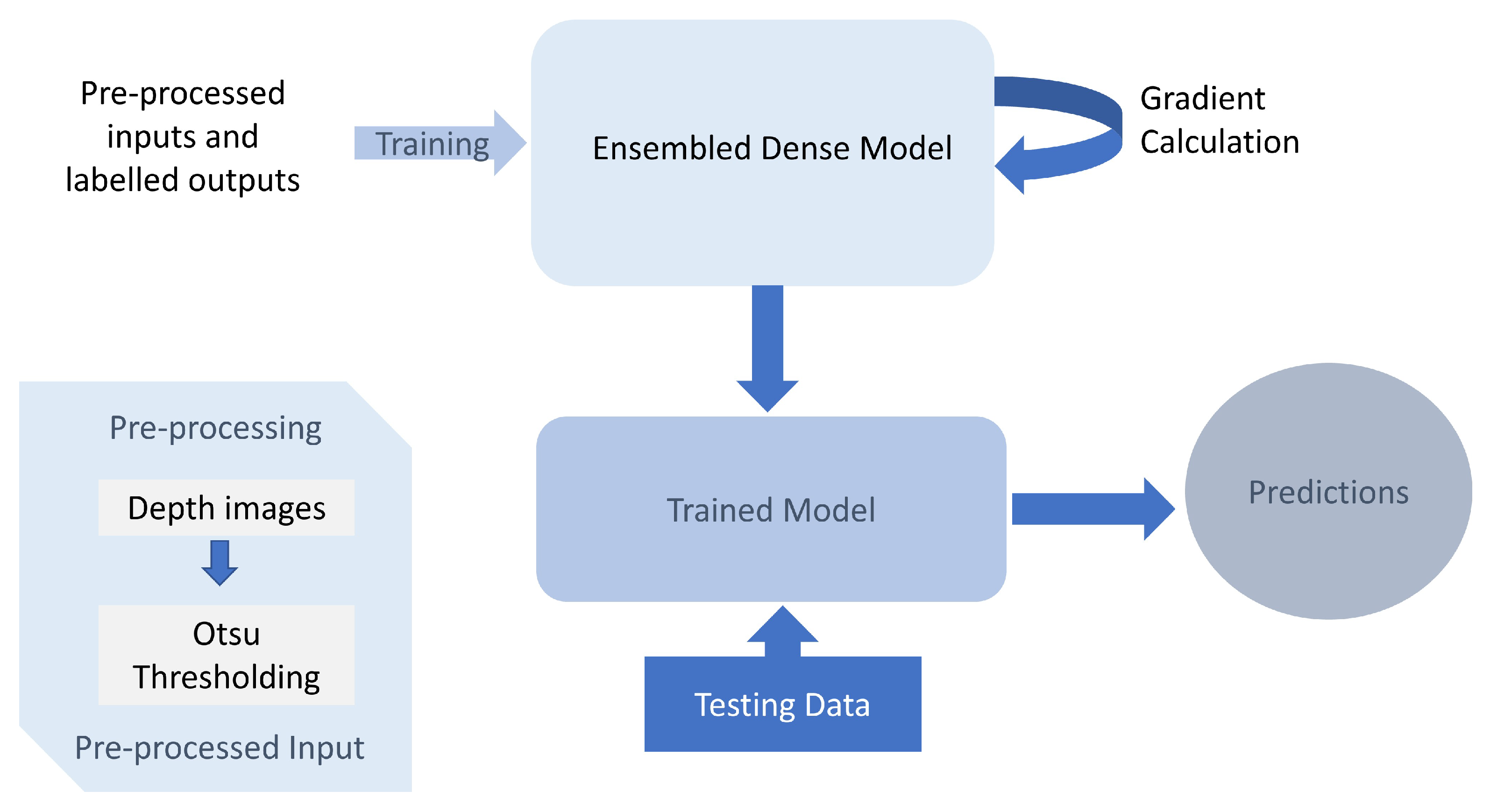
2. Methodology
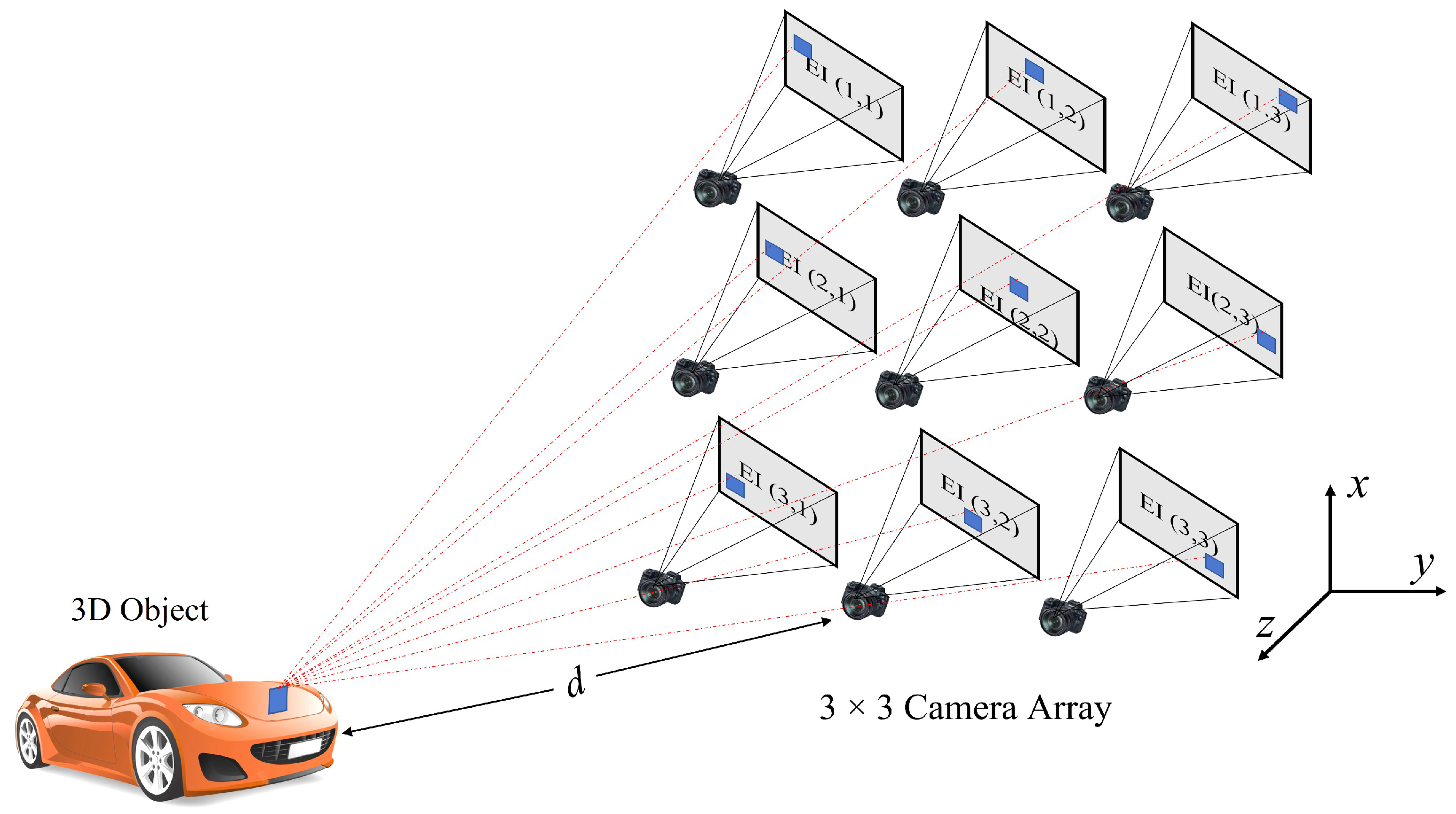
2.1. Photon Counted Integral Imaging
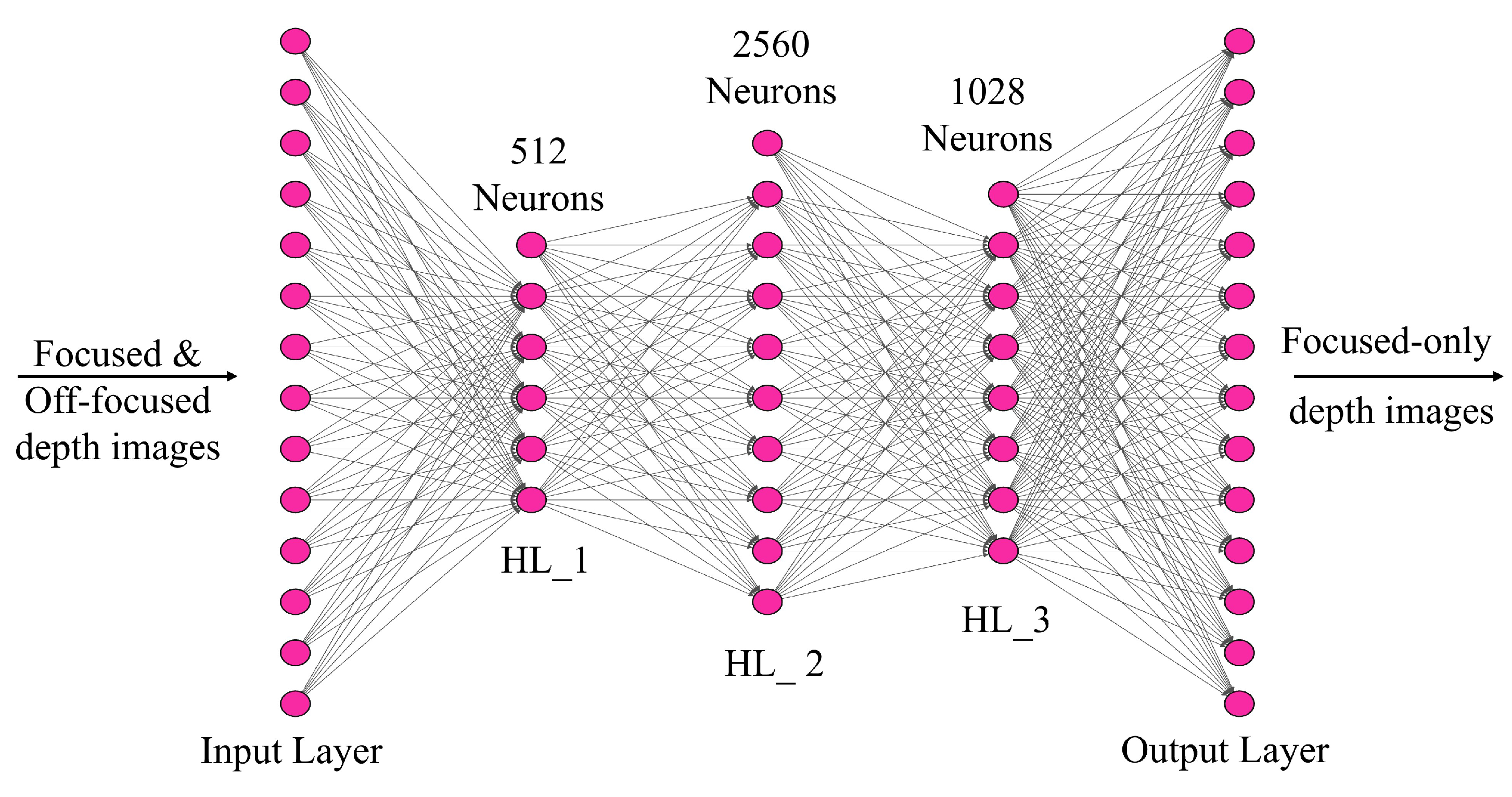
2.2. Deep Neural Network
3. Experimental Results
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Park, J.H.; Hong, K.; Lee, B. Recent progress in three-dimensional information processing based on integral imaging. Appl. Opt. 2009, 48, H77–H94. [Google Scholar] [CrossRef] [PubMed]
- Xiao, X.; Javidi, B.; Martinez-Corral, M.; Stern, A. Advances in three-dimensional integral imaging: Sensing, display, and applications. Appl. Opt. 2013, 52, 546–560. [Google Scholar] [CrossRef] [PubMed]
- Martínez-Corral, M.; Javidi, B. Fundamentals of 3D imaging and displays: A tutorial on integral imaging, light-field, and plenoptic systems. Adv. Opt. Photonics 2018, 10, 512–566. [Google Scholar] [CrossRef]
- Javidi, B.; Carnicer, A.; Arai, J.; Fujii, T.; Hua, H.; Liao, H.; Martínez-Corral, M.; Pla, F.; Stern, A.; Waller, L.; et al. Roadmap on 3D integral imaging: Sensing, processing, and display. Opt. Express 2020, 28, 32266–32293. [Google Scholar] [CrossRef] [PubMed]
- Okano, F.; Arai, J.; Mitani, K.; Okui, M. Real-time integral imaging based on extremely high resolution video system. Proc. IEEE 2006, 94, 490–501. [Google Scholar] [CrossRef]
- Yang, L.; Sang, X.; Yu, X.; Yan, B.; Wang, K.; Yu, C. Viewing-angle and viewing-resolution enhanced integral imaging based on time-multiplexed lens stitching. Opt. Express 2019, 27, 15679–15692. [Google Scholar] [CrossRef]
- Hong, S.H.; Jang, J.S.; Javidi, B. Three-dimensional volumetric object reconstruction using computational integral imaging. Opt. Express 2004, 12, 483–491. [Google Scholar] [CrossRef]
- Muniraj, I.; Kim, B.; Lee, B.G. Encryption and volumetric 3D object reconstruction using multispectral computational integral imaging. Appl. Opt. 2014, 53, G25–G32. [Google Scholar] [CrossRef]
- Goodman, J.W. Statistical Optics; John Wiley & Sons: Hoboken, NJ, USA, 2015. [Google Scholar]
- Morris, P.A.; Aspden, R.S.; Bell, J.E.; Boyd, R.W.; Padgett, M.J. Imaging with a small number of photons. Nat. Commun. 2015, 6, 5913. [Google Scholar] [CrossRef]
- Muniraj, I.; Sheridan, J.T. Optical Encryption and Decryption; SPIE: Bellingham, WA, USA, 2019. [Google Scholar]
- Tavakoli, B.; Javidi, B.; Watson, E. Three dimensional visualization by photon counting computational integral imaging. Opt. Express 2008, 16, 4426–4436. [Google Scholar] [CrossRef]
- Yeom, S.; Javidi, B.; Watson, E. Three-dimensional distortion-tolerant object recognition using photon-counting integral imaging. Opt. Express 2007, 15, 1513–1533. [Google Scholar] [CrossRef] [PubMed]
- Yeom, S.; Javidi, B.; Watson, E. Photon counting passive 3D image sensing for automatic target recognition. Opt. Express 2005, 13, 9310–9330. [Google Scholar] [CrossRef] [PubMed]
- Moon, I.; Muniraj, I.; Javidi, B. 3D visualization at low light levels using multispectral photon counting integral imaging. J. Disp. Technol. 2013, 9, 51–55. [Google Scholar] [CrossRef]
- Yi, F.; Lee, J.; Moon, I. Simultaneous reconstruction of multiple depth images without off-focus points in integral imaging using a graphics processing unit. Appl. Opt. 2014, 53, 2777–2786. [Google Scholar] [CrossRef]
- Muniraj, I.; Guo, C.; Malallah, R.; Maraka, H.V.R.; Ryle, J.P.; Sheridan, J.T. Subpixel based defocused points removal in photon-limited volumetric dataset. Opt. Commun. 2017, 387, 196–201. [Google Scholar] [CrossRef]
- Alzubaidi, L.; Zhang, J.; Humaidi, A.J.; Al-Dujaili, A.; Duan, Y.; Al-Shamma, O.; Santamaría, J.; Fadhel, M.A.; Al-Amidie, M.; Farhan, L. Review of deep learning: Concepts, CNN architectures, challenges, applications, future directions. J. Big Data 2021, 8, 1–74. [Google Scholar] [CrossRef]
- Kwon, K.C.; Kwon, K.H.; Erdenebat, M.U.; Piao, Y.L.; Lim, Y.T.; Kim, M.Y.; Kim, N. Resolution-enhancement for an integral imaging microscopy using deep learning. IEEE Photonics J. 2019, 11, 1–12. [Google Scholar] [CrossRef]
- Yi, F.; Jeong, O.; Moon, I.; Javidi, B. Deep learning integral imaging for three-dimensional visualization, object detection, and segmentation. Opt. Lasers Eng. 2021, 146, 106695. [Google Scholar] [CrossRef]
- Usmani, K.; Krishnan, G.; O’Connor, T.; Javidi, B. Deep learning polarimetric three-dimensional integral imaging object recognition in adverse environmental conditions. Opt. Express 2021, 29, 12215–12228. [Google Scholar] [CrossRef]
- Dodda, V.C.; Kuruguntla, L.; Elumalai, K.; Chinnadurai, S.; Sheridan, J.T.; Muniraj, I. A denoising framework for 3D and 2D imaging techniques based on photon detection statistics. Sci. Rep. 2023, 13, 1365. [Google Scholar] [CrossRef]
- Muniraj, I.; Guo, C.; Lee, B.G.; Sheridan, J.T. Interferometry based multispectral photon-limited 2D and 3D integral image encryption employing the Hartley transform. Opt. Express 2015, 23, 15907–15920. [Google Scholar] [CrossRef] [PubMed]
- Yi, F.; Moon, I.; Lee, J.A.; Javidi, B. Fast 3D computational integral imaging using graphics processing unit. J. Disp. Technol. 2012, 8, 714–722. [Google Scholar] [CrossRef]
- Larochelle, H.; Bengio, Y.; Louradour, J.; Lamblin, P. Exploring strategies for training deep neural networks. J. Mach. Learn. Res. 2009, 10, 1–40. [Google Scholar]
- Nazari, F.; Yan, W. Convolutional versus Dense Neural Networks: Comparing the Two Neural Networks Performance in Predicting Building Operational Energy Use Based on the Building Shape. arXiv 2021, arXiv:2108.12929. [Google Scholar]
- Otsu, N. A threshold selection method from gray-level histograms. IEEE Trans. Syst. Man Cybern. 1979, 9, 62–66. [Google Scholar] [CrossRef]
- Sun, S.; Cao, Z.; Zhu, H.; Zhao, J. A survey of optimization methods from a machine learning perspective. IEEE Trans. Cybern. 2019, 50, 3668–3681. [Google Scholar] [CrossRef]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Saad, O.M.; Chen, Y. Deep denoising autoencoder for seismic random noise attenuation. Geophysics 2020, 85, V367–V376. [Google Scholar] [CrossRef]
- Snoek, J.; Larochelle, H.; Adams, R.P. Practical bayesian optimization of machine learning algorithms. In Proceedings of the Neural Information Processing Systems 25: 26th Annual Conference on Neural Information Processing Systems 2012, Lake Tahoe, NV, USA, 3–6 December 2012. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Hyper-Parameter | Optimised Value from BO Tuner |
|---|---|
| Units of hidden layer | 512, 2560 and 1028 |
| Activation Function (hidden layer, output) | ReLU, Linear |
| Learning rate | 1 |
| Optimizer | Adam |
| No. of epochs | 100 |
| Batch size | 1 |
| Model: “Sequential” | ||
|---|---|---|
| Layer (Type) | Output Shape | Param # |
| dense (Dense) | (None, 512) | 36032000 |
| dense_1 (Dense) | (None, 2560) | 1313280 |
| dense_2 (Dense) | (None, 1028) | 2632708 |
| dense_3 (Dense) | (None, 70,374) | 72414846 |
| Total params: 112,392,834 | ||
| Trainable params: 112,392,834 | ||
| Non- trainable params: 0 | ||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Patel, S.; Dodda, V.C.; Sheridan, J.T.; Muniraj, I. A Deep Learning Framework to Remove the Off-Focused Voxels from the 3D Photons Starved Depth Images. Photonics 2023, 10, 583. https://doi.org/10.3390/photonics10050583
Patel S, Dodda VC, Sheridan JT, Muniraj I. A Deep Learning Framework to Remove the Off-Focused Voxels from the 3D Photons Starved Depth Images. Photonics. 2023; 10(5):583. https://doi.org/10.3390/photonics10050583
Chicago/Turabian StylePatel, Suchit, Vineela Chandra Dodda, John T. Sheridan, and Inbarasan Muniraj. 2023. "A Deep Learning Framework to Remove the Off-Focused Voxels from the 3D Photons Starved Depth Images" Photonics 10, no. 5: 583. https://doi.org/10.3390/photonics10050583
APA StylePatel, S., Dodda, V. C., Sheridan, J. T., & Muniraj, I. (2023). A Deep Learning Framework to Remove the Off-Focused Voxels from the 3D Photons Starved Depth Images. Photonics, 10(5), 583. https://doi.org/10.3390/photonics10050583