

NIR Spectrometric Approach for Geographical Origin Identification and Taste Related Compounds Content Prediction of Lushan Yunwu Tea

 and
and
Abstract
:1. Introduction
2. Materials and Methods
2.1. Sample Preparation
2.2. Spectra Acquisition
2.3. Chemical Analysis
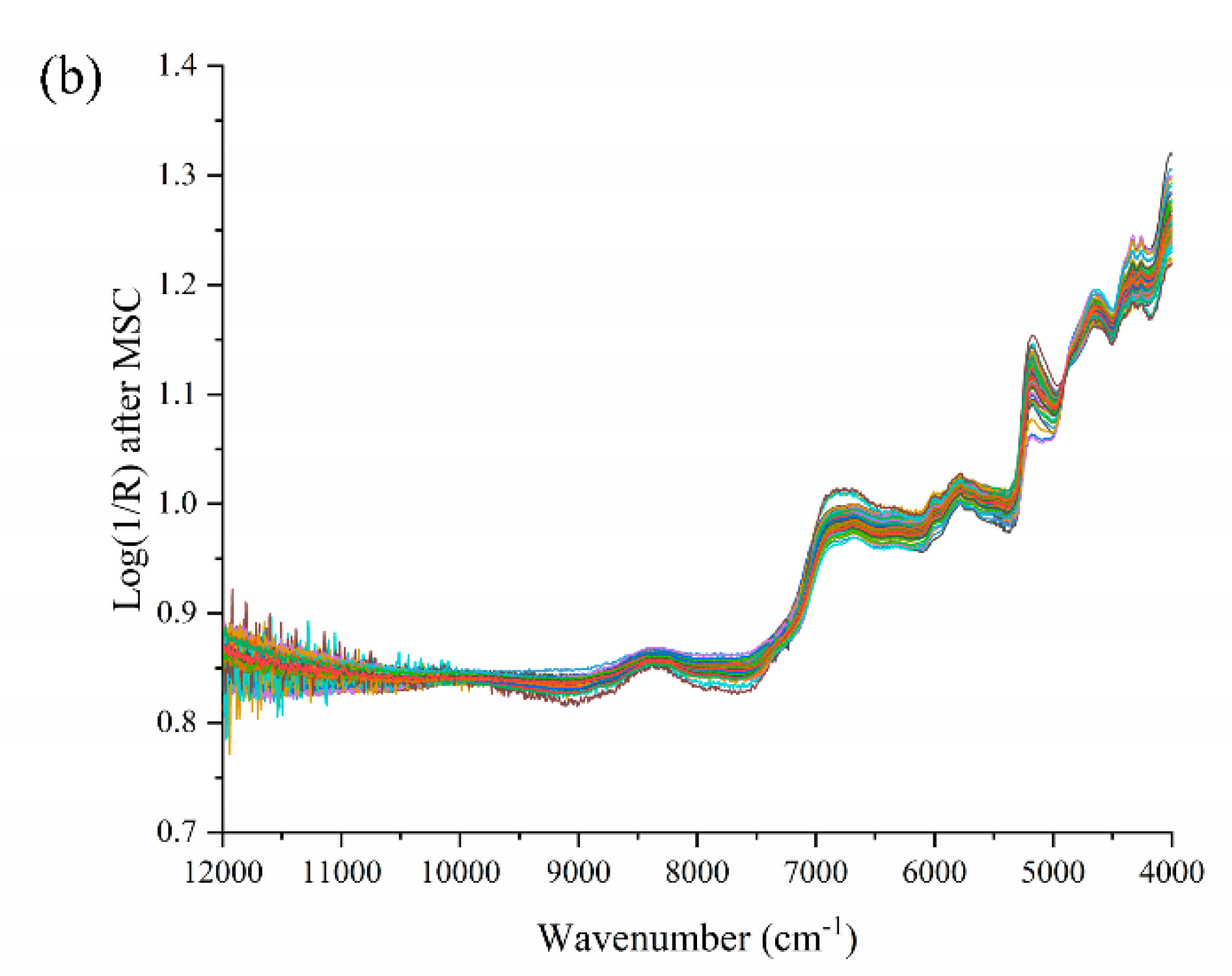
2.4. Spectral Preprocessing
2.5. Multivariate Analysis
2.5.1. Discrimination Analysis (DA)
2.5.2. Partial Least Squares (PLS)
2.5.3. Synergy Interval Partial Least Squares (siPLS)
2.5.4. Backward Interval Partial Least Squares (biPLS)
2.6. Software
3. Results and Discussion
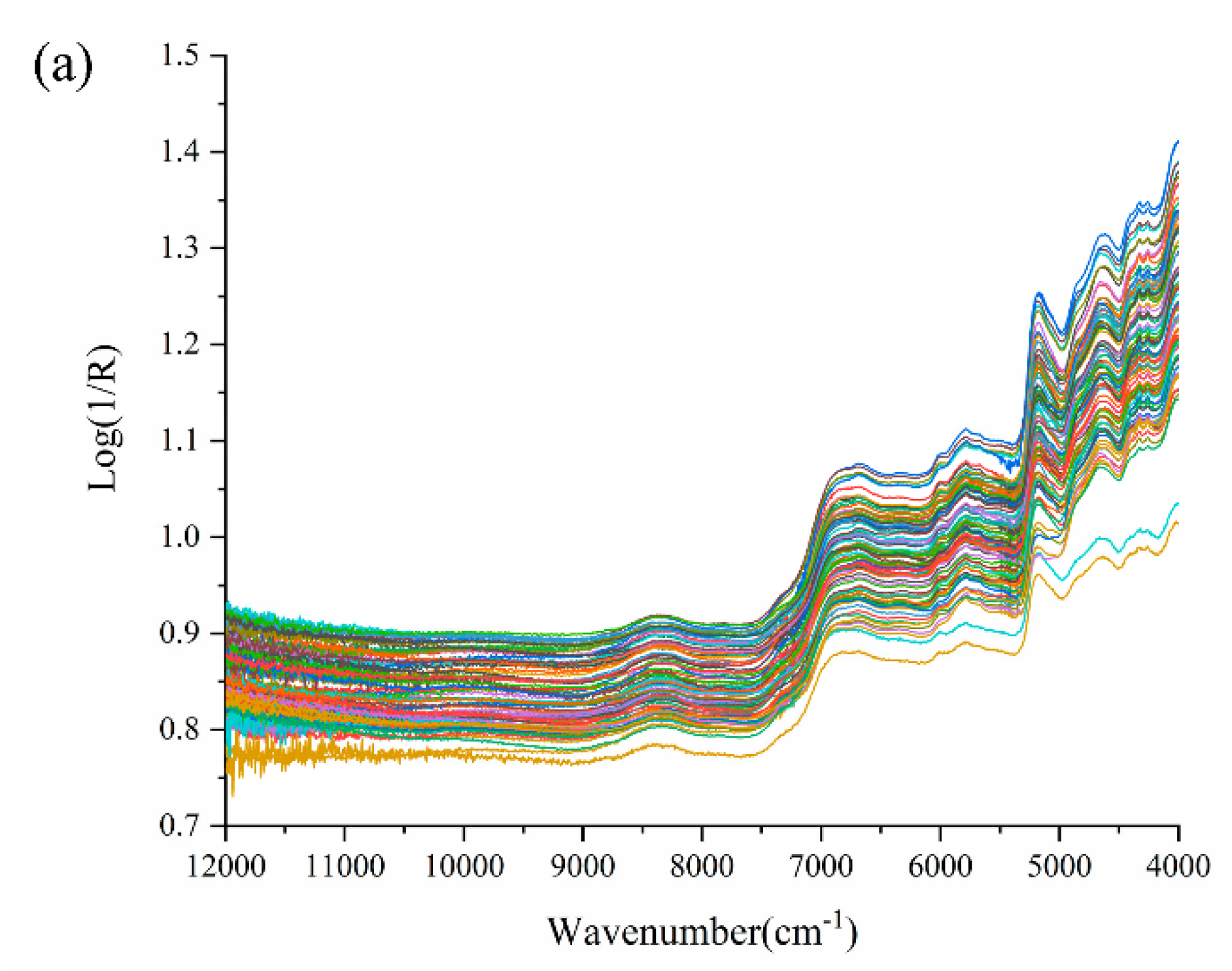
3.1. Spectrum Description
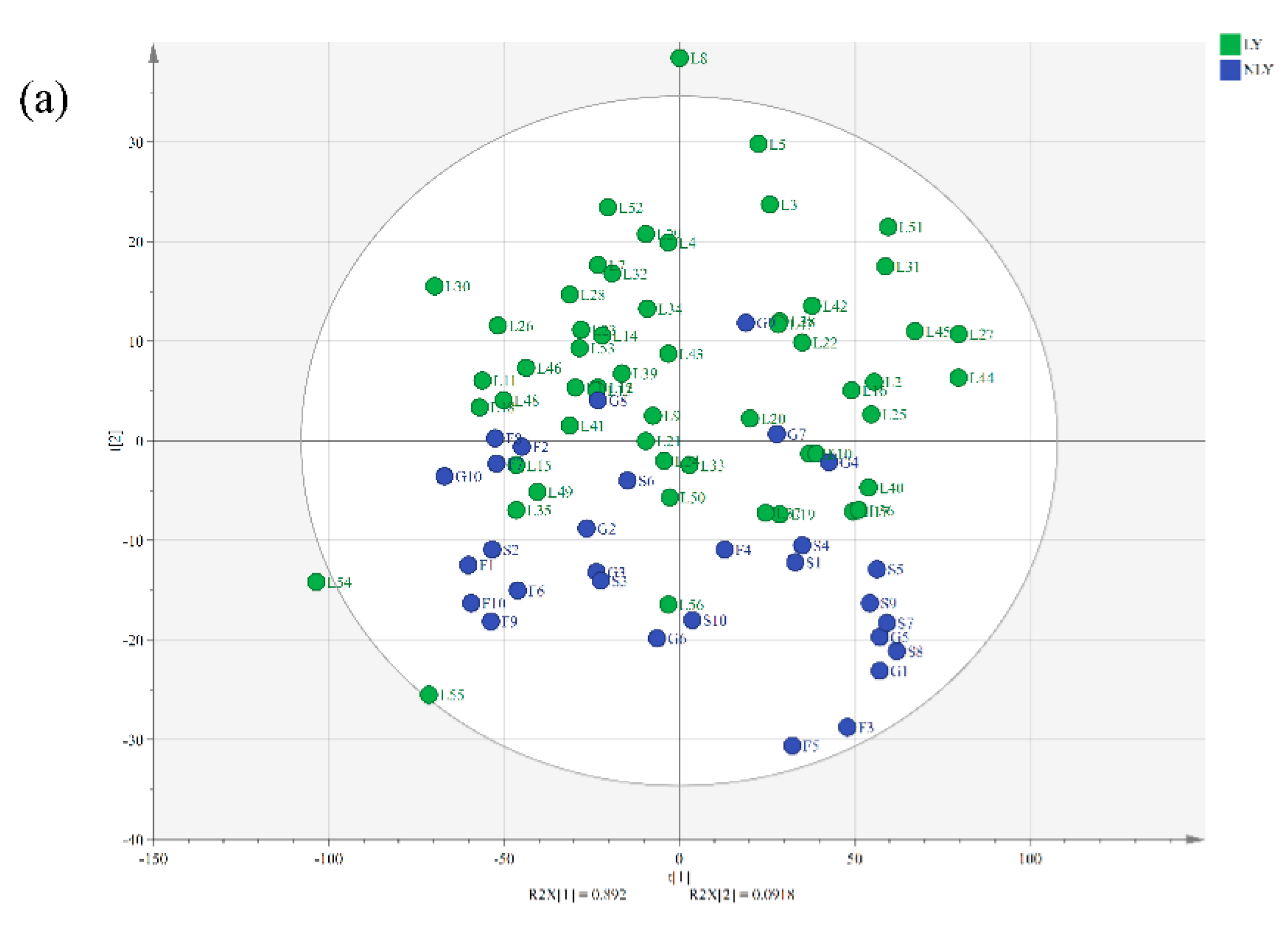
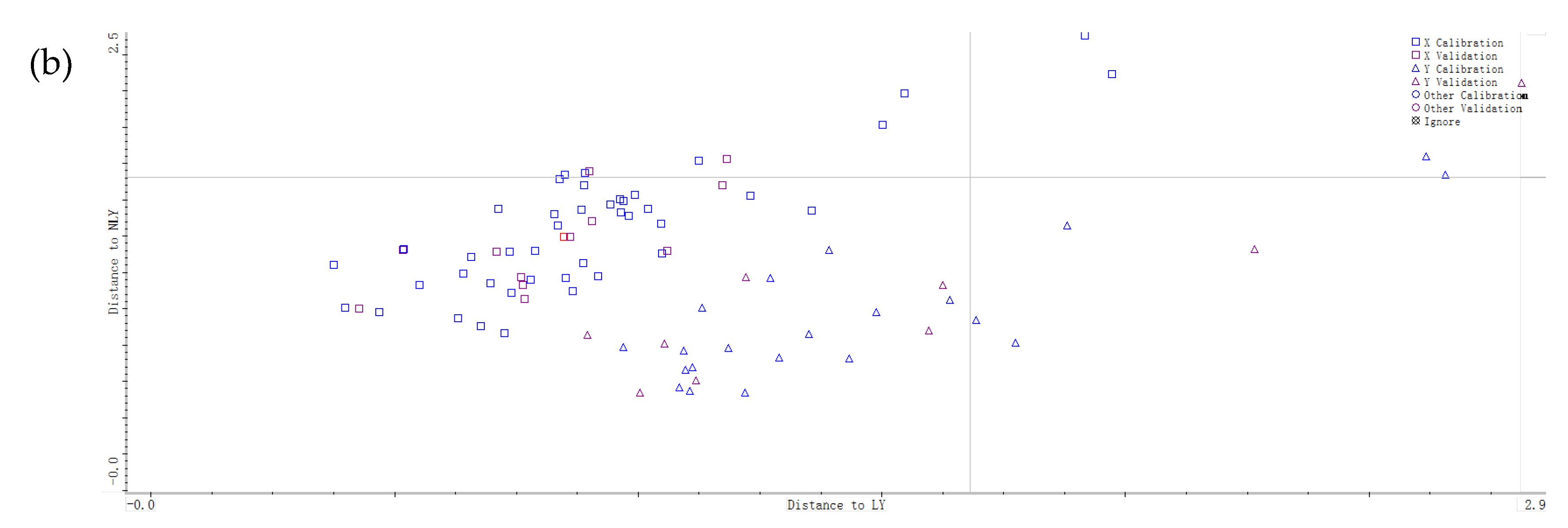
3.2. Authentication of Lushan Yunwu Tea
3.3. PLS Models for TP, FAA, TP/FAA Prediction
3.4. Variables Selection and PLS Models Optimization
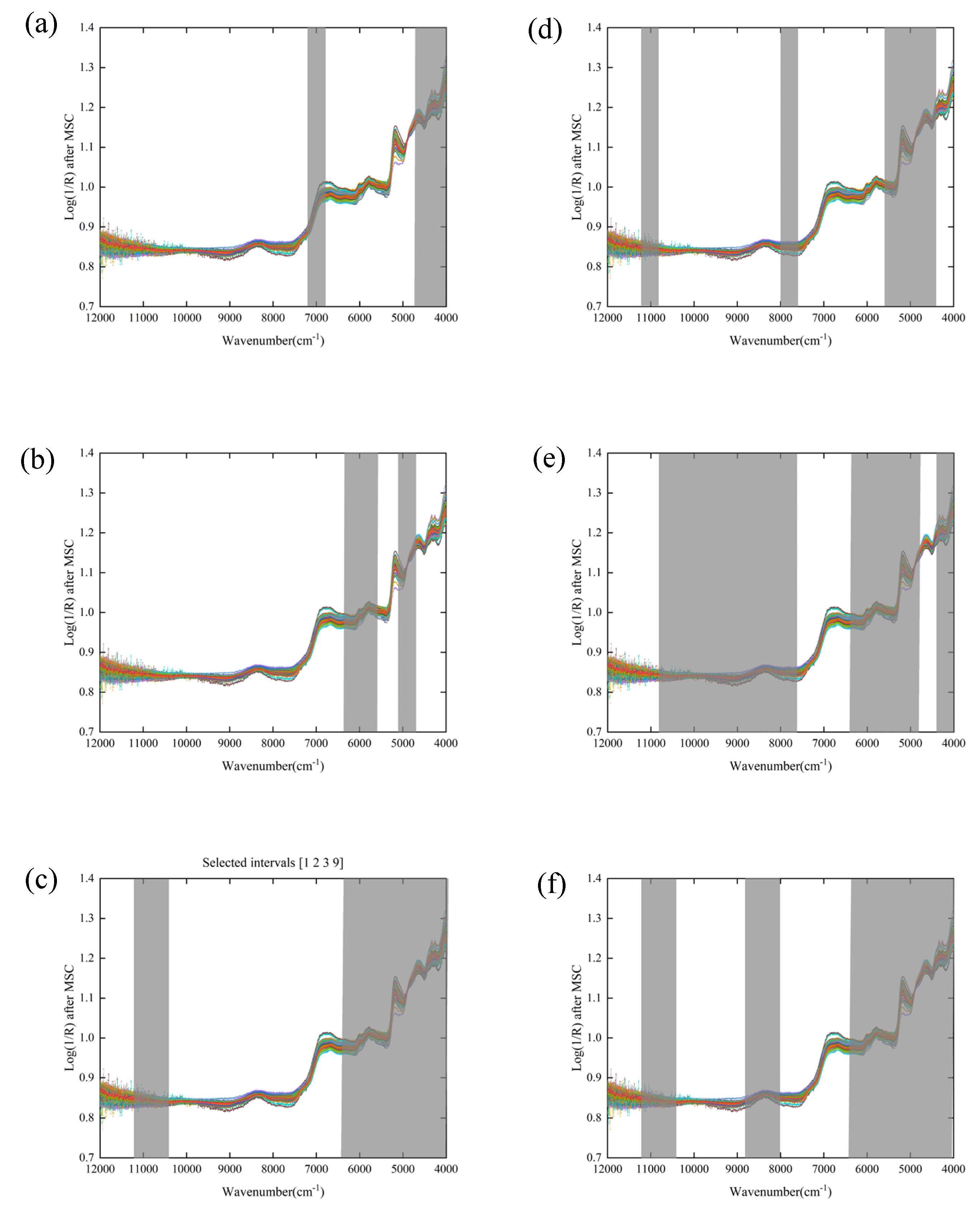
3.4.1. Prediction Models Based on the Manual Selected Wavenumber Range
3.4.2. Prediction Models Based on the siPLS and biPLS Algorithms
4. Conclusions
Supplementary Materials
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Xiao, Y.; Li, M.; Liu, Y.; Xu, S.; Zhong, K.; Wu, Y.; Gao, H. The effect of Eurotium cristatum (MF800948) fermentation on the quality of autumn green tea. Food Chem. 2021, 358, 129848. [Google Scholar] [CrossRef] [PubMed]
- Jiang, H.; Yu, F.; Qin, L.; Zhang, N.; Cao, Q.; Schwab, W.; Li, D.; Song, C. Dynamic change in amino acids, catechins, alkaloids, and gallic acid in six types of tea processed from the same batch of fresh tea (Camellia sinensis L.) leaves. J. Food Compos. Anal. 2019, 77, 28–38. [Google Scholar] [CrossRef]
- Dai, W.; Qi, D.; Yang, T.; Lv, H.; Guo, L.; Zhang, Y.; Zhu, Y.; Peng, Q.; Xie, D.; Tan, J.; et al. Nontargeted Analysis Using Ultraperformance Liquid Chromatography-Quadrupole Time-of-Flight Mass Spectrometry Uncovers the Effects of Harvest Season on the Metabolites and Taste Quality of Tea (Camellia sinensis L.). J Agric. Food Chem. 2015, 63, 9869–9878. [Google Scholar] [CrossRef] [PubMed]
- Peng, T.Q.; Yin, X.L.; Gu, H.W.; Sun, W.; Ding, B.; Hu, X.C.; Ma, L.A.; Wei, S.D.; Liu, Z.; Ye, S.Y. HPLC-DAD fingerprints combined with chemometric techniques for the authentication of plucking seasons of Laoshan green tea. Food Chem. 2021, 347, 128959. [Google Scholar] [CrossRef] [PubMed]
- Han, W.-Y.; Huang, J.-G.; Li, X.; Li, Z.-X.; Ahammed, G.J.; Yan, P.; Stepp, J.R. Altitudinal effects on the quality of green tea in east China: A climate change perspective. Eur. Food Res. Technol. 2016, 243, 323–330. [Google Scholar] [CrossRef]
- Ruan, J.; Haerdter, R.; Gerendas, J. Impact of nitrogen supply on carbon/nitrogen allocation: A case study on amino acids and catechins in green tea [Camellia sinensis (L.) O. Kuntze] plants. Plant Biol. 2010, 12, 724–734. [Google Scholar] [CrossRef]
- Zhao, C.N.; Tang, G.Y.; Cao, S.Y.; Xu, X.Y.; Gan, R.Y.; Liu, Q.; Mao, Q.Q.; Shang, A.; Li, H.B. Phenolic Profiles and Antioxidant Activities of 30 Tea Infusions from Green, Black, Oolong, White, Yellow and Dark Teas. Antioxidants 2019, 8, 215. [Google Scholar] [CrossRef]
- Yu, X.L.; Sun, D.W.; He, Y. Emerging techniques for determining the quality and safety of tea products: A review. Compr. Rev. Food Sci. Food Saf. 2020, 19, 2613–2638. [Google Scholar] [CrossRef]
- Fernando, D.R.; Samita, S.; Peiris, T.U.S. Clustering around latent variables approach to detect panel disagreement in three–way tea sensory evaluation. Int. J. Sci. Res. Publ. (IJSRP) 2020, 10, 779–792. [Google Scholar] [CrossRef]
- Palacios-Morillo, A.; Alcazar, A.; de Pablos, F.; Jurado, J.M. Differentiation of tea varieties using UV-Vis spectra and pattern recognition techniques. Spectrochim. Acta A Mol. Biomol. Spectrosc. 2013, 103, 79–83. [Google Scholar] [CrossRef]
- Diniz, P.H.; Barbosa, M.F.; de Melo Milanez, K.D.; Pistonesi, M.F.; de Araujo, M.C. Using UV-Vis spectroscopy for simultaneous geographical and varietal classification of tea infusions simulating a home-made tea cup. Food Chem. 2016, 192, 374–379. [Google Scholar] [CrossRef]
- Jing, J.; Shi, Y.; Zhang, Q.; Wang, J.; Ruan, J. Prediction of Chinese green tea ranking by metabolite profiling using ultra-performance liquid chromatography-quadrupole time-of-flight mass spectrometry (UPLC-Q-TOF/MS). Food Chem. 2017, 221, 311–316. [Google Scholar] [CrossRef]
- Yun, J.; Cui, C.; Zhang, S.; Zhu, J.; Peng, C.; Cai, H.; Yang, X.; Hou, R. Use of headspace GC/MS combined with chemometric analysis to identify the geographic origins of black tea. Food Chem. 2021, 360, 130033. [Google Scholar] [CrossRef]
- Lin, J.; Dai, Y.; Guo, Y.N.; Xu, H.R.; Wang, X.C. Volatile profile analysis and quality prediction of Longjing tea (Camellia sinensis) by HS-SPME/GC-MS. J. Zhejiang Univ. Sci. B 2012, 13, 972–980. [Google Scholar] [CrossRef]
- Wang, Y.; Li, M.; Li, L.; Ning, J.; Zhang, Z. Green analytical assay for the quality assessment of tea by using pocket-sized NIR spectrometer. Food Chem. 2021, 345, 128816. [Google Scholar] [CrossRef]
- Ren, G.; Ning, J.; Zhang, Z. Multi-variable selection strategy based on near-infrared spectra for the rapid description of dianhong black tea quality. Spectrochim. Acta A Mol. Biomol. Spectrosc. 2021, 245, 118918. [Google Scholar] [CrossRef]
- Ren, G.; Wang, Y.; Ning, J.; Zhang, Z. Using near-infrared hyperspectral imaging with multiple decision tree methods to delineate black tea quality. Spectrochim. Acta A Mol. Biomol. Spectrosc. 2020, 237, 118407. [Google Scholar] [CrossRef]
- Yuan, H.; Chen, X.; Shao, Y.; Cheng, Y.; Yang, Y.; Zhang, M.; Hua, J.; Li, J.; Deng, Y.; Wang, J.; et al. Quality Evaluation of Green and Dark Tea Grade Using Electronic Nose and Multivariate Statistical Analysis. J. Food Sci. 2019, 84, 3411–3417. [Google Scholar] [CrossRef]
- Ouyang, Q.; Yang, Y.; Wu, J.; Liu, Z.; Chen, X.; Dong, C.; Chen, Q.; Zhang, Z.; Guo, Z. Rapid sensing of total theaflavins content in black tea using a portable electronic tongue system coupled to efficient variables selection algorithms. J. Food Compos. Anal. 2019, 75, 43–48. [Google Scholar] [CrossRef]
- Ren, G.; Gan, N.; Song, Y.; Ning, J.; Zhang, Z. Evaluating Congou black tea quality using a lab-made computer vision system coupled with morphological features and chemometrics. Microchem. J. 2021, 160, 105600. [Google Scholar] [CrossRef]
- Xu, L.; Shi, P.T.; Fu, X.S.; Cui, H.F.; Ye, Z.H.; Cai, C.B.; Yu, X.P. Protected Geographical Indication Identification Identification of a Chinese Green Tea (Anji-White) by Near-Infrared Spectroscopy and Chemometric Class Modeling Techniques. J. Spectrosc. 2013, 2013, 1–8. [Google Scholar] [CrossRef]
- Firmani, P.; De Luca, S.; Bucci, R.; Marini, F.; Biancolillo, A. Near infrared (NIR) spectroscopy-based classification for the authentication of Darjeeling black tea. Food Control 2019, 100, 292–299. [Google Scholar] [CrossRef]
- Hazarika, A.K.; Chanda, S.; Sabhapondit, S.; Sanyal, S.; Tamuly, P.; Tasrin, S.; Sing, D.; Tudu, B.; Bandyopadhyay, R. Quality assessment of fresh tea leaves by estimating total polyphenols using near infrared spectroscopy. J. Food Sci. Technol. 2018, 55, 4867–4876. [Google Scholar] [CrossRef] [PubMed]
- Guo, Z.; Barimah, A.O.; Shujat, A.; Zhang, Z.; Ouyang, Q.; Shi, J.; El-Seedi, H.R.; Zou, X.; Chen, Q. Simultaneous quantification of active constituents and antioxidant capability of green tea using NIR spectroscopy coupled with swarm intelligence algorithm. LWT 2020, 129, 109510. [Google Scholar] [CrossRef]
- Chen, Y.; Deng, J.; Wang, Y.; Liu, B.; Ding, J.; Mao, X.; Zhang, J.; Hu, H.; Li, J. Study on discrimination of white tea and albino tea based on near-infrared spectroscopy and chemometrics. J. Sci. Food Agric. 2014, 94, 1026–1033. [Google Scholar] [CrossRef]
- Shawky, E.; Selim, D.A. NIR spectroscopy-multivariate analysis for discrimination and bioactive compounds prediction of different Citrus species peels. Spectrochim. Acta A Mol. Biomol. Spectrosc. 2019, 219, 1–7. [Google Scholar] [CrossRef]
- Shan, R.; Chen, Y.; Meng, L.; Li, H.; Zhao, Z.; Gao, M.; Sun, X. Rapid prediction of atrazine sorption in soil using visible near-infrared spectroscopy. Spectrochim. Acta A Mol. Biomol. Spectrosc. 2020, 224, 117455. [Google Scholar] [CrossRef]
- He, Y.; Li, X.; Deng, X. Discrimination of varieties of tea using near infrared spectroscopy by principal component analysis and BP model. J. Food Eng. 2007, 79, 1238–1242. [Google Scholar] [CrossRef]
- Rinnan, Å.; van den Berg, F.; Balling Engelsen, S.B. Review of the most common pre-processing techniques for near-infrared spectra. TrAC Trends Anal. Chem. 2009, 28, 1201–1222. [Google Scholar] [CrossRef]
- Vidal, M.; Amigo, J.M. Pre-processing of hyperspectral images. Essential steps before image analysis. Chemom. Intell. Lab. Syst. 2012, 117, 138–148. [Google Scholar] [CrossRef]
- Chen, Y.; Xie, M.; Zhang, H.; Wang, Y.; Nie, S.; Li, C. Quantification of total polysaccharides and triterpenoids in Ganoderma lucidum and Ganoderma atrum by near infrared spectroscopy and chemometrics. Food Chem. 2012, 135, 268–275. [Google Scholar] [CrossRef]
- Du, Q.; Zhu, M.; Shi, T.; Luo, X.; Gan, B.; Tang, L.; Chen, Y. Adulteration detection of corn oil, rapeseed oil and sunflower oil in camellia oil by in situ diffuse reflectance near-infrared spectroscopy and chemometrics. Food Control 2021, 121, 107577. [Google Scholar] [CrossRef]
- Guo, Z.; Barimah, A.O.; Yin, L.; Chen, Q.; Shi, J.; El-Seedi, H.R.; Zou, X. Intelligent evaluation of taste constituents and polyphenols-to-amino acids ratio in matcha tea powder using near infrared spectroscopy. Food Chem. 2021, 353, 129372. [Google Scholar] [CrossRef]
- Shi, T.; Zhu, M.; Chen, Y.; Yan, X.; Chen, Q.; Wu, X.; Lin, J.; Xie, M. 1H NMR combined with chemometrics for the rapid detection of adulteration in camellia oils. Food Chem. 2018, 242, 308–315. [Google Scholar] [CrossRef]
- Pereira, C.G.; Leite, A.I.N.; Andrade, J.; Bell, M.J.V.; Anjos, V. Evaluation of butter oil adulteration with soybean oil by FT-MIR and FT-NIR spectroscopies and multivariate analyses. LWT 2019, 107, 1–8. [Google Scholar] [CrossRef]
- Viegas, T.R.; Mata, A.; Duarte, M.M.L.; Lima, K.M.G. Determination of quality attributes in wax jambu fruit using NIRS and PLS. Food Chem. 2016, 190, 1–4. [Google Scholar] [CrossRef]
- Zhu, M.; Long, Y.; Chen, Y.; Huang, Y.; Tang, L.; Gan, B.; Yu, Q.; Xie, J. Fast determination of lipid and protein content in green coffee beans from different origins using NIR spectroscopy and chemometrics. J. Food Compos. Anal. 2021, 102, 104055. [Google Scholar] [CrossRef]
- Liang, H.; Zhang, M.; Gao, C.; Zhao, Y. Non-Destructive Methodology to Determine Modulus of Elasticity in Static Bending of Quercus mongolica Using Near-Infrared Spectroscopy. Sensors 2018, 18, 1963. [Google Scholar] [CrossRef]
- Leardi, R.; Nørgaard, L. Sequential application of backward interval partial least squares and genetic algorithms for the selection of relevant spectral regions. J. Chemom. 2004, 18, 486–497. [Google Scholar] [CrossRef]
- Li, X.; Sun, C.; Luo, L.; He, Y. Determination of tea polyphenols content by infrared spectroscopy coupled with iPLS and random frog techniques. Comput. Electron. Agric. 2015, 112, 28–35. [Google Scholar] [CrossRef]
- Wang, Y.-J.; Li, T.-H.; Li, L.-Q.; Ning, J.-M.; Zhang, Z.-Z. Evaluating taste-related attributes of black tea by micro-NIRS. J. Food Eng. 2021, 290, 110181. [Google Scholar] [CrossRef]
- Ong, P.; Chen, S.; Tsai, C.Y.; Chuang, Y.K. Prediction of tea theanine content using near-infrared spectroscopy and flower pollination algorithm. Spectrochim. Acta A Mol. Biomol. Spectrosc. 2021, 255, 119657. [Google Scholar] [CrossRef] [PubMed]
- Wang, J.; Wang, Y.; Cheng, J.; Wang, J.; Sun, X.; Sun, S.; Zhang, Z. Enhanced cross-category models for predicting the total polyphenols, caffeine and free amino acids contents in Chinese tea using NIR spectroscopy. LWT 2018, 96, 90–97. [Google Scholar] [CrossRef]
- Chen, Q.; Chen, M.; Liu, Y.; Wu, J.; Wang, X.; Ouyang, Q.; Chen, X. Application of FT-NIR spectroscopy for simultaneous estimation of taste quality and taste-related compounds content of black tea. J. Food Sci. Technol. 2018, 55, 4363–4368. [Google Scholar] [CrossRef]
- Ouyang, Q.; Yang, Y.; Wu, J.; Chen, Q.; Guo, Z.; Li, H. Measurement of total free amino acids content in black tea using electronic tongue technology coupled with chemometrics. LWT 2020, 118, 108768. [Google Scholar] [CrossRef]
- Li, C.; Guo, H.; Zong, B.; He, P.; Fan, F.; Gong, S. Rapid and non-destructive discrimination of special-grade flat green tea using Near-infrared spectroscopy. Spectrochim. Acta A Mol. Biomol. Spectrosc. 2019, 206, 254–262. [Google Scholar] [CrossRef]
- Wang, X.; Huang, J.; Fan, W.; Lu, H. Identification of green tea varieties and fast quantification of total polyphenols by near-infrared spectroscopy and ultraviolet-visible spectroscopy with chemometric algorithms. Anal. Methods 2015, 7, 787–792. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Wavenumber Range | Pretreatment Methods | Factors | % of Variability Described | No. of Incorrectly Classified Samples | % of Samples Correctly Classified | |
|---|---|---|---|---|---|---|
| LY (n = 56) | NLY (n = 30) | |||||
| Full wavenumbers (12,000–4000 cm−1) | None | 9 | 99.93 | 0 | 0 | 100 |
| MSC | 9 | 97.01 | 0 | 0 | 100 | |
| SNV | 9 | 96.93 | 0 | 0 | 100 | |
| 1st derivative | 9 | 62.49 | 31 | 0 | 63.95 | |
| 2nd derivative | 9 | 63.44 | 30 | 1 | 63.95 | |
| MSC + 1st + SG filter (7, 3) | 9 | 75.34 | 31 | 1 | 62.79 | |
| SNV + 1st + SG filter (7, 3) | 9 | 75.20 | 31 | 1 | 62.79 | |
| Range 1 (8000–4000 cm−1) | None | 9 | 99.99 | 0 | 4 | 95.35 |
| MSC | 9 | 99.70 | 0 | 1 | 98.84 | |
| SNV | 9 | 99.65 | 0 | 1 | 98.84 | |
| 1st derivative | 9 | 90.31 | 2 | 2 | 95.35 | |
| 2nd derivative | 9 | 91.27 | 24 | 2 | 69.77 | |
| MSC + 1st + SG filter (7, 3) | 9 | 90.23 | 0 | 3 | 96.51 | |
| SNV + 1st + SG filter (7, 3) | 9 | 90.21 | 0 | 3 | 96.51 | |
| Range 2 (9700–8600 + 7400–6800 + 5600–4000 cm−1) | None | 9 | 99.99 | 3 | 2 | 94.19 |
| MSC | 9 | 99.42 | 0 | 0 | 100 | |
| SNV | 9 | 99.41 | 0 | 0 | 100 | |
| 1st derivative | 9 | 86.22 | 3 | 3 | 93.02 | |
| 2nd derivative | 9 | 87.33 | 29 | 1 | 65.12 | |
| MSC + 1st + SG filter (7, 3) | 9 | 86.92 | 2 | 3 | 94.19 | |
| SNV + 1st + SG filter (7, 3) | 9 | 86.89 | 2 | 3 | 94.19 | |
| Wavenumber Range | Pretreatment Methods | TP | FAA | TP/FAA | ||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Factors | Calibration Set | Prediction Set | Factors | Calibration Set | Prediction Set | Factors | Calibration Set | Prediction Set | ||||||||||||||
| RC | RMSEC | RMSECV | RP | RMSEP | RPD | RC | RMSEC | RMSECV | RP | RMSEP | RPD | RC | RMSEC | RMSECV | RP | RMSEP | RPD | |||||
| Full wavenumbers (12,000–4000 cm−1) | None | 8 | 0.9303 | 8.05 | 13.4 | 0.8546 | 14.2 | 1.91 | 6 | 0.7619 | 6.08 | 7.74 | 0.8490 | 6.79 | 1.62 | 8 | 0.9356 | 0.310 | 0.553 | 0.8089 | 0.645 | 1.73 |
| MSC | 7 | 0.9167 | 8.77 | 13.8 | 0.9086 | 11.5 | 2.36 | 2 | 0.4881 | 8.20 | 8.83 | 0.4967 | 9.62 | 1.14 | 7 | 0.9119 | 0.360 | 0.686 | 0.8430 | 0.593 | 1.88 | |
| SNV | 7 | 0.9184 | 8.68 | 13.8 | 0.9073 | 11.6 | 2.34 | 2 | 0.4900 | 8.19 | 8.82 | 0.4989 | 9.61 | 1.14 | 7 | 0.9141 | 0.356 | 0.692 | 0.8352 | 0.603 | 1.85 | |
| 1st derivative | 3 | 0.8940 | 9.83 | 20.6 | 0.7821 | 19.9 | 1.36 | 1 | 0.5134 | 8.06 | 10.0 | 0.5803 | 9.66 | 1.14 | 4 | 0.9612 | 0.242 | 0.86 | 0.7477 | 0.782 | 1.43 | |
| 2nd derivative | 2 | 0.7237 | 15.10 | 21.3 | 0.3379 | 25.6 | 1.06 | 3 | 0.8715 | 4.61 | 9.88 | 0.0681 | 11.1 | 0.99 | 3 | 0.8970 | 0.388 | 0.869 | 0.3258 | 1.04 | 1.07 | |
| MSC + 1st + SG filter (7, 3) | 4 | 0.8990 | 9.61 | 20.6 | 0.8101 | 18.7 | 1.45 | 1 | 0.3511 | 8.79 | 9.70 | 0.4309 | 10.5 | 1.05 | 1 | 0.4057 | 0.802 | 0.896 | 0.7797 | 1.01 | 1.10 | |
| SNV + 1st + SG filter (7, 3) | 4 | 0.8994 | 9.59 | 20.6 | 0.8099 | 19.7 | 1.38 | 1 | 0.3521 | 8.79 | 9.70 | 0.4340 | 10.5 | 1.05 | 1 | 0.4066 | 0.802 | 0.896 | 0.7806 | 1.01 | 1.10 | |
| Range 1 (8000–4000 cm−1) | None | 9 | 0.9085 | 9.17 | 12.3 | 0.8666 | 13.6 | 2.00 | 10 | 0.8687 | 4.65 | 6.78 | 0.8507 | 6.84 | 1.60 | 10 | 0.9195 | 0.345 | 0.514 | 0.8363 | 0.618 | 1.80 |
| MSC | 8 | 0.9054 | 9.31 | 12.0 | 0.9028 | 11.5 | 2.36 | 6 | 0.8559 | 4.86 | 7.08 | 0.8762 | 6.23 | 1.76 | 8 | 0.8980 | 0.386 | 0.55 | 0.8739 | 0.545 | 2.05 | |
| SNV | 7 | 0.9021 | 9.47 | 12.2 | 0.8590 | 13.8 | 1.97 | 8 | 0.8520 | 4.92 | 7.24 | 0.8822 | 6.16 | 1.78 | 8 | 0.8974 | 0.387 | 0.561 | 0.8652 | 0.559 | 1.99 | |
| 1st derivative | 6 | 0.9778 | 4.59 | 13.9 | 0.8958 | 12.6 | 2.15 | 6 | 0.9649 | 2.46 | 7.82 | 0.7796 | 7.85 | 1.40 | 5 | 0.9787 | 0.180 | 0.591 | 0.8312 | 0.656 | 1.70 | |
| 2nd derivative | 5 | 0.9847 | 3.83 | 21.4 | 0.2931 | 25.3 | 1.07 | 2 | 0.6833 | 6.86 | 9.69 | 0.6390 | 9.47 | 1.16 | 6 | 0.9957 | 0.081 | 0.884 | 0.5921 | 0.945 | 1.18 | |
| MSC + 1st + SG filter (7, 3) | 5 | 0.9525 | 6.68 | 13.7 | 0.9264 | 11.2 | 2.42 | 6 | 0.9759 | 2.05 | 7.22 | 0.8480 | 6.96 | 1.58 | 7 | 0.9929 | 0.104 | 0.562 | 0.8676 | 0.610 | 1.83 | |
| SNV + 1st + SG filter (7, 3) | 5 | 0.9527 | 6.67 | 13.8 | 0.9261 | 11.2 | 2.42 | 6 | 0.9759 | 2.05 | 7.22 | 0.8461 | 7.00 | 1.57 | 7 | 0.9931 | 0.103 | 0.561 | 0.8667 | 0.612 | 1.82 | |
| Range 2 (9700–8600 + 7400–6800 + 5600–4000 cm−1) | None | 9 | 0.9199 | 8.60 | 12.5 | 0.8561 | 13.9 | 1.95 | 10 | 0.8793 | 4.47 | 6.62 | 0.8648 | 6.74 | 1.63 | 10 | 0.9371 | 0.306 | 0.505 | 0.9264 | 0.466 | 2.39 |
| MSC | 7 | 0.9046 | 9.35 | 12.4 | 0.8953 | 11.8 | 2.30 | 9 | 0.9260 | 3.54 | 7.28 | 0.8079 | 7.39 | 1.49 | 8 | 0.9238 | 0.336 | 0.566 | 0.8551 | 0.590 | 1.89 | |
| SNV | 5 | 0.8655 | 11.00 | 13.6 | 0.8782 | 12.9 | 2.10 | 9 | 0.8874 | 4.33 | 7.42 | 0.8315 | 6.92 | 1.59 | 8 | 0.9120 | 0.360 | 0.561 | 0.8905 | 0.524 | 2.13 | |
| 1st derivative | 5 | 0.9427 | 7.32 | 16.7 | 0.9111 | 12.7 | 2.14 | 5 | 0.9346 | 3.34 | 9.14 | 0.7021 | 8.39 | 1.31 | 6 | 0.9765 | 0.189 | 0.723 | 0.7915 | 0.709 | 1.57 | |
| 2nd derivative | 2 | 0.6324 | 17.00 | 21.9 | 0.5005 | 24.4 | 1.11 | 2 | 0.5953 | 7.54 | 9.95 | 0.5813 | 9.97 | 1.10 | 6 | 0.9900 | 0.124 | 0.951 | 0.5868 | 0.943 | 1.18 | |
| MSC + 1st + SG filter (7, 3) | 5 | 0.9426 | 7.33 | 16.8 | 0.9118 | 12.2 | 2.23 | 6 | 0.9689 | 2.32 | 8.46 | 0.7297 | 8.11 | 1.35 | 6 | 0.9728 | 0.203 | 0.731 | 0.8218 | 0.657 | 1.70 | |
| SNV + 1st + SG filter (7, 3) | 5 | 0.9425 | 7.33 | 16.8 | 0.9115 | 12.2 | 2.23 | 6 | 0.9724 | 2.19 | 8.52 | 0.7261 | 8.13 | 1.35 | 6 | 0.9713 | 0.209 | 0.737 | 0.8220 | 0.658 | 1.69 | |
| Methods | Tea Polyphenols Content | Free Amino Acids Content | TP/AA | |||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Variables | Factors | Calibration Set | Prediction Set | Variables | Factors | Calibration Set | Prediction Set | Variables | Factors | Calibration Set | Prediction Set | |||||||||||||
| RC | RMSEC | RMSECV | RP | RMSEP | RPD | RC | RMSEC | RMSECV | RP | RMSEP | RPD | RC | RMSEC | RMSECV | RP | RMSEP | RPD | |||||||
| Full | 2075 | 8 | 0.9303 | 8.05 | 13.4 | 0.8546 | 14.2 | 1.91 | 2075 | 6 | 0.7619 | 6.08 | 7.74 | 0.8490 | 6.79 | 1.62 | 2075 | 8 | 0.9356 | 0.31 | 0.553 | 0.8089 | 0.645 | 1.73 |
| siPLS | 312 | 9 | 0.9344 | 7.82 | 12.0 | 0.9407 | 9.04 | 3.00 | 312 | 9 | 0.9103 | 3.89 | 6.3 | 0.9110 | 4.96 | 2.21 | 831 | 9 | 0.9641 | 0.233 | 0.466 | 0.9377 | 0.385 | 2.90 |
| biPLS | 519 | 7 | 0.9125 | 8.79 | 13.5 | 0.9508 | 8.33 | 3.26 | 1454 | 9 | 0.9492 | 2.95 | 7.2 | 0.9199 | 5.31 | 2.07 | 1013 | 9 | 0.9420 | 0.295 | 0.645 | 0.9303 | 0.437 | 2.55 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yan, X.; Xie, Y.; Chen, J.; Yuan, T.; Leng, T.; Chen, Y.; Xie, J.; Yu, Q. NIR Spectrometric Approach for Geographical Origin Identification and Taste Related Compounds Content Prediction of Lushan Yunwu Tea. Foods 2022, 11, 2976. https://doi.org/10.3390/foods11192976
Yan X, Xie Y, Chen J, Yuan T, Leng T, Chen Y, Xie J, Yu Q. NIR Spectrometric Approach for Geographical Origin Identification and Taste Related Compounds Content Prediction of Lushan Yunwu Tea. Foods. 2022; 11(19):2976. https://doi.org/10.3390/foods11192976
Chicago/Turabian StyleYan, Xiaoli, Yujie Xie, Jianhua Chen, Tongji Yuan, Tuo Leng, Yi Chen, Jianhua Xie, and Qiang Yu. 2022. "NIR Spectrometric Approach for Geographical Origin Identification and Taste Related Compounds Content Prediction of Lushan Yunwu Tea" Foods 11, no. 19: 2976. https://doi.org/10.3390/foods11192976
APA StyleYan, X., Xie, Y., Chen, J., Yuan, T., Leng, T., Chen, Y., Xie, J., & Yu, Q. (2022). NIR Spectrometric Approach for Geographical Origin Identification and Taste Related Compounds Content Prediction of Lushan Yunwu Tea. Foods, 11(19), 2976. https://doi.org/10.3390/foods11192976