
Digital Prediction of the Purchase Price of Fresh Tea Leaves of Enshi Yulu Based on Near-Infrared Spectroscopy Combined with Multivariate Analysis

 , ,
, ,
Abstract
:1. Introduction
2. Materials and Methods
2.1. Samples and Classification of Fresh Tea Leaves
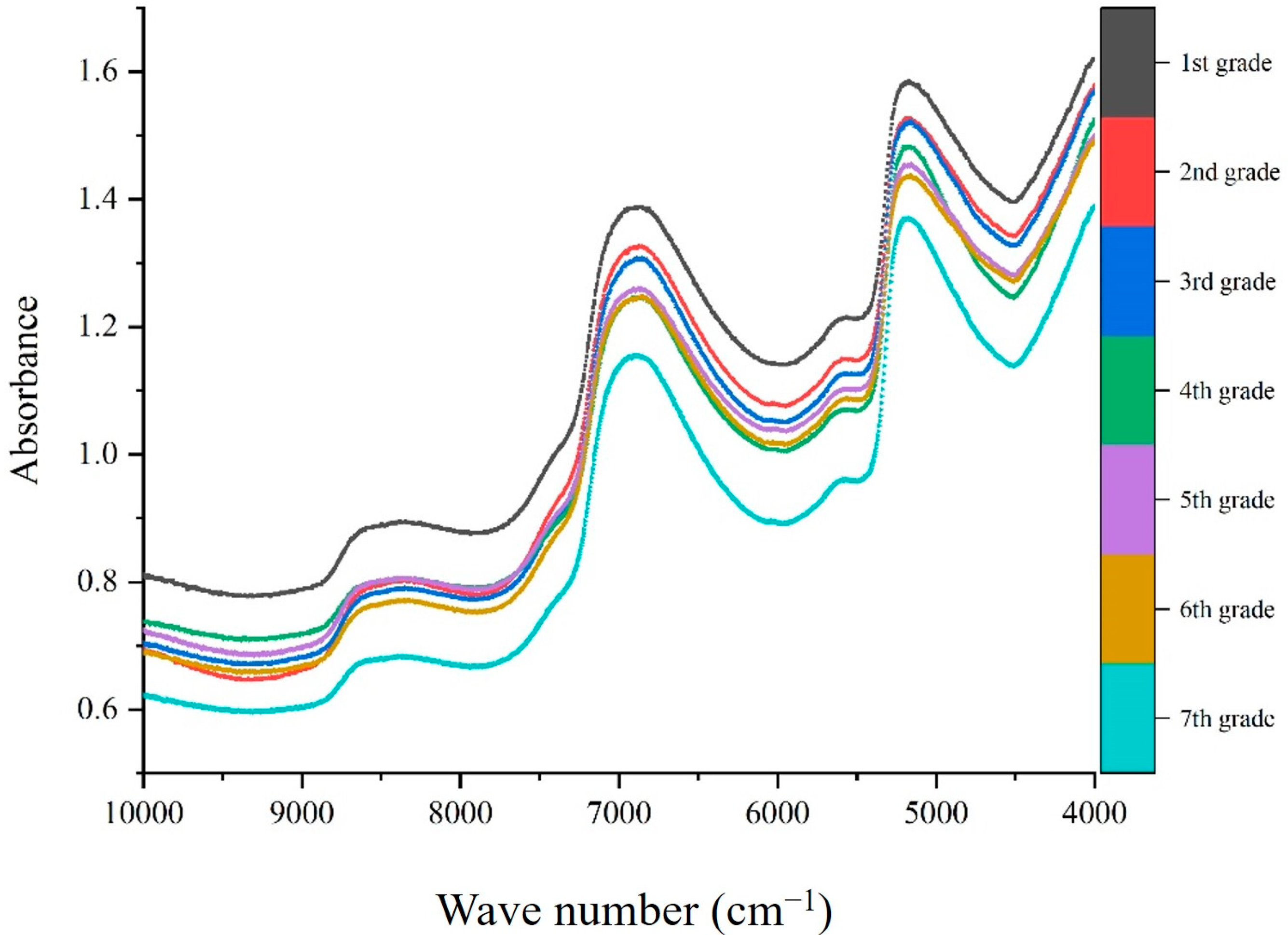
2.2. Spectral Collection
2.3. Spectral Data Analysis
2.4. Modeling Methods
2.4.1. Synergy Interval Partial Least Squares (si-PLS) Method
2.4.2. Genetic Algorithm (GA)
2.4.3. Principal Component Analysis (PCA) and Backpropagation Artificial Neural Network Method (BP-ANN)
3. Results and Discussion
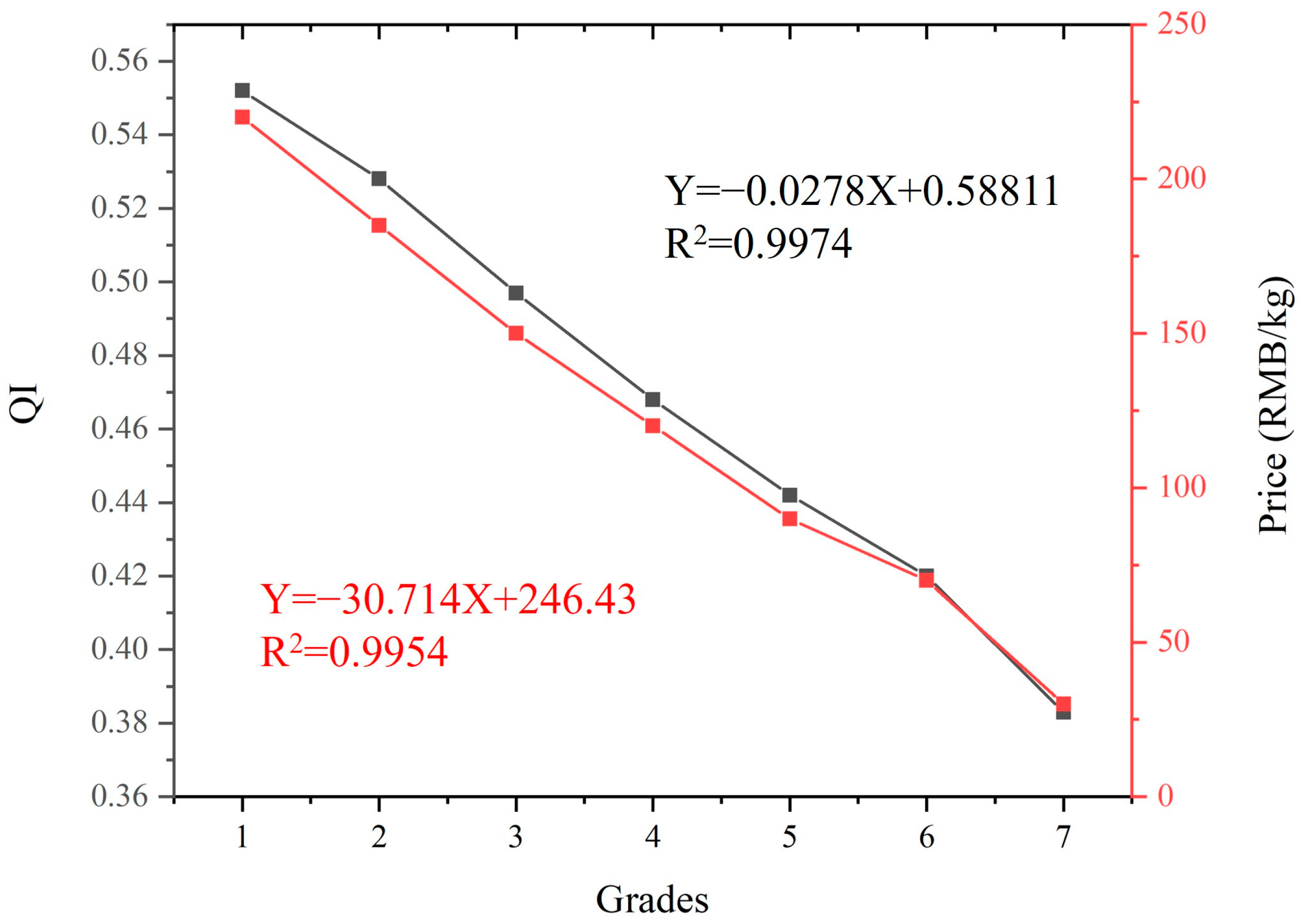
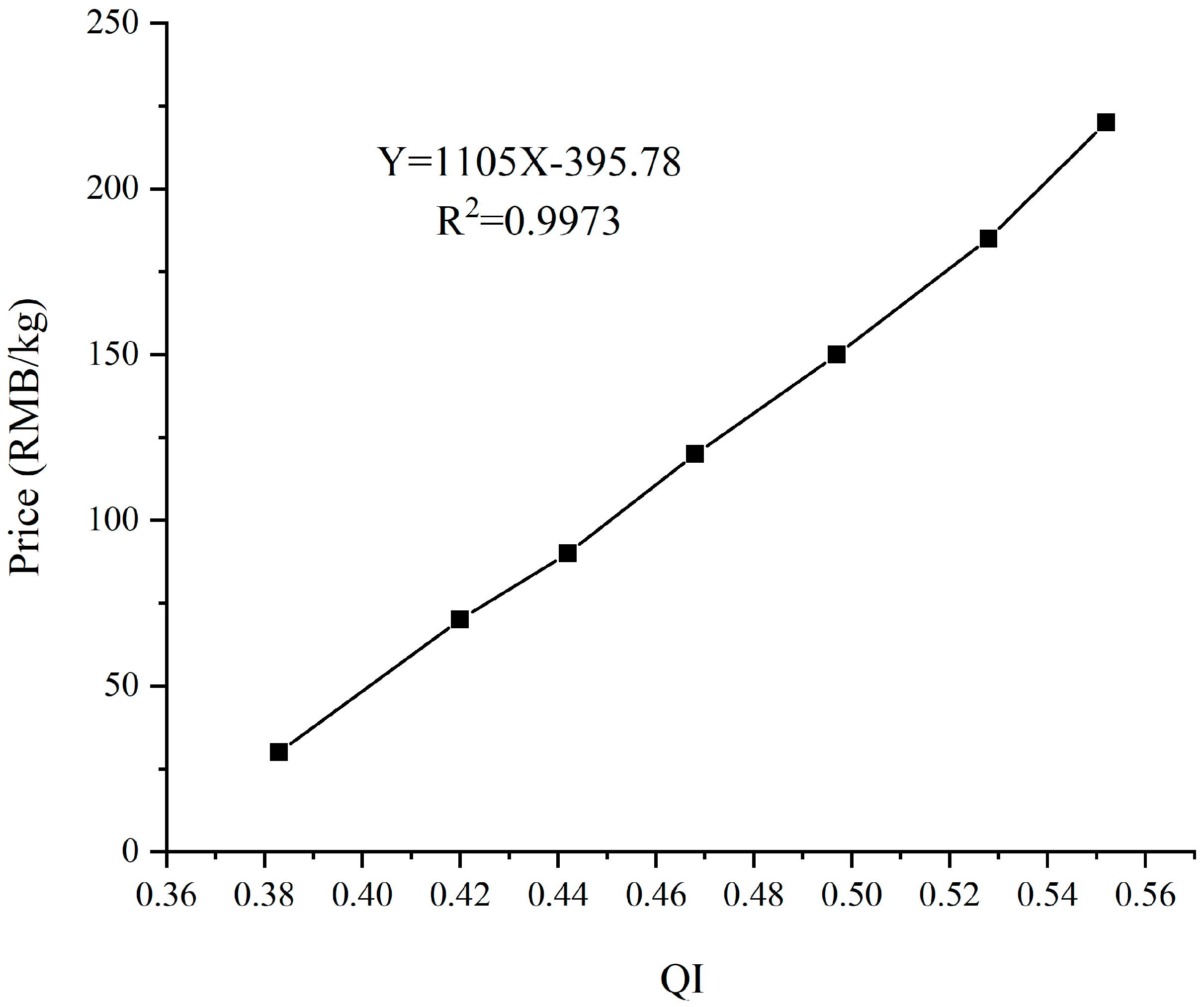
3.1. The Relationships between Quality Grade, Quality Index, and Purchase Price of Fresh Tea Samples
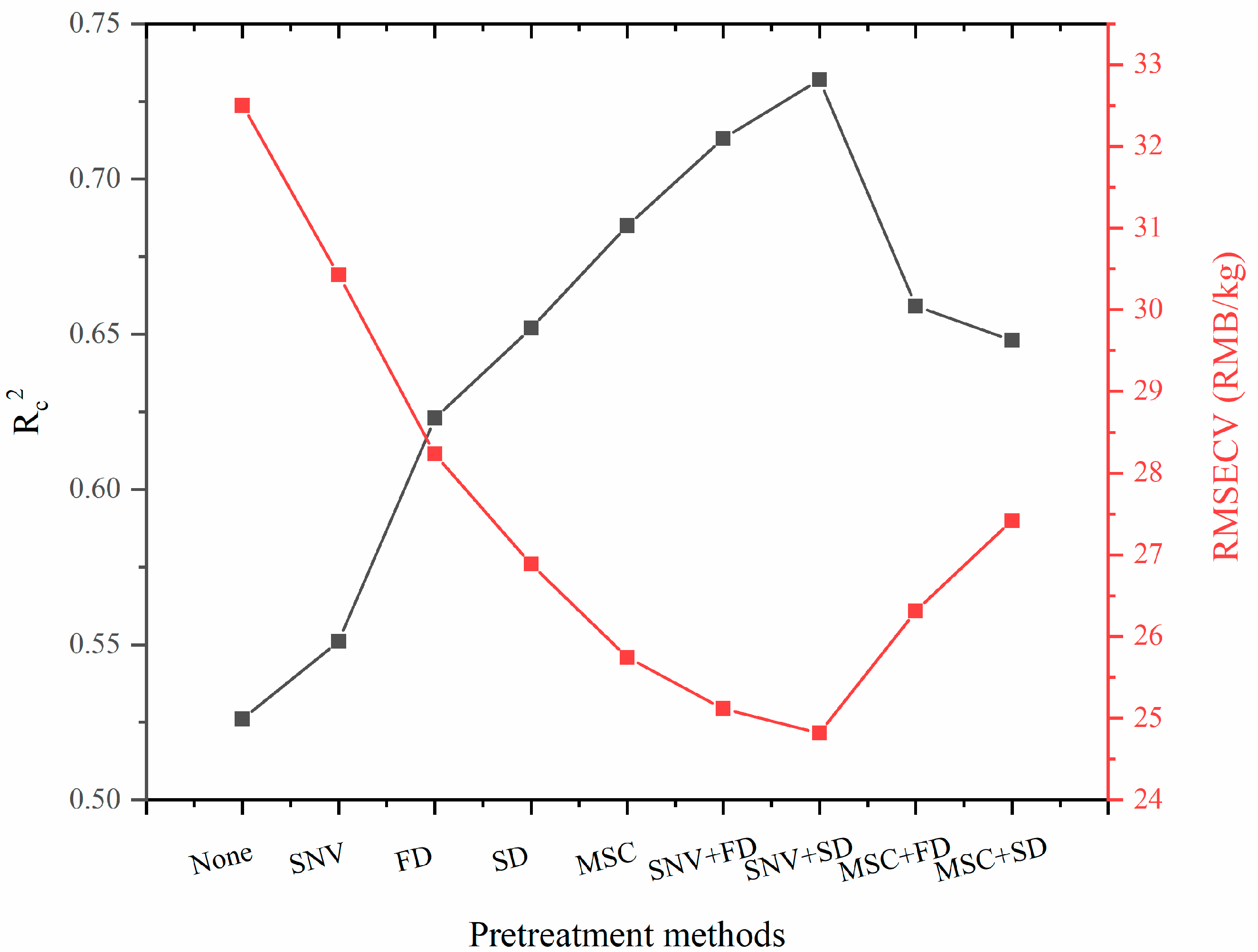
3.2. Comparison of Pre-Processing Methods for Spectral Data
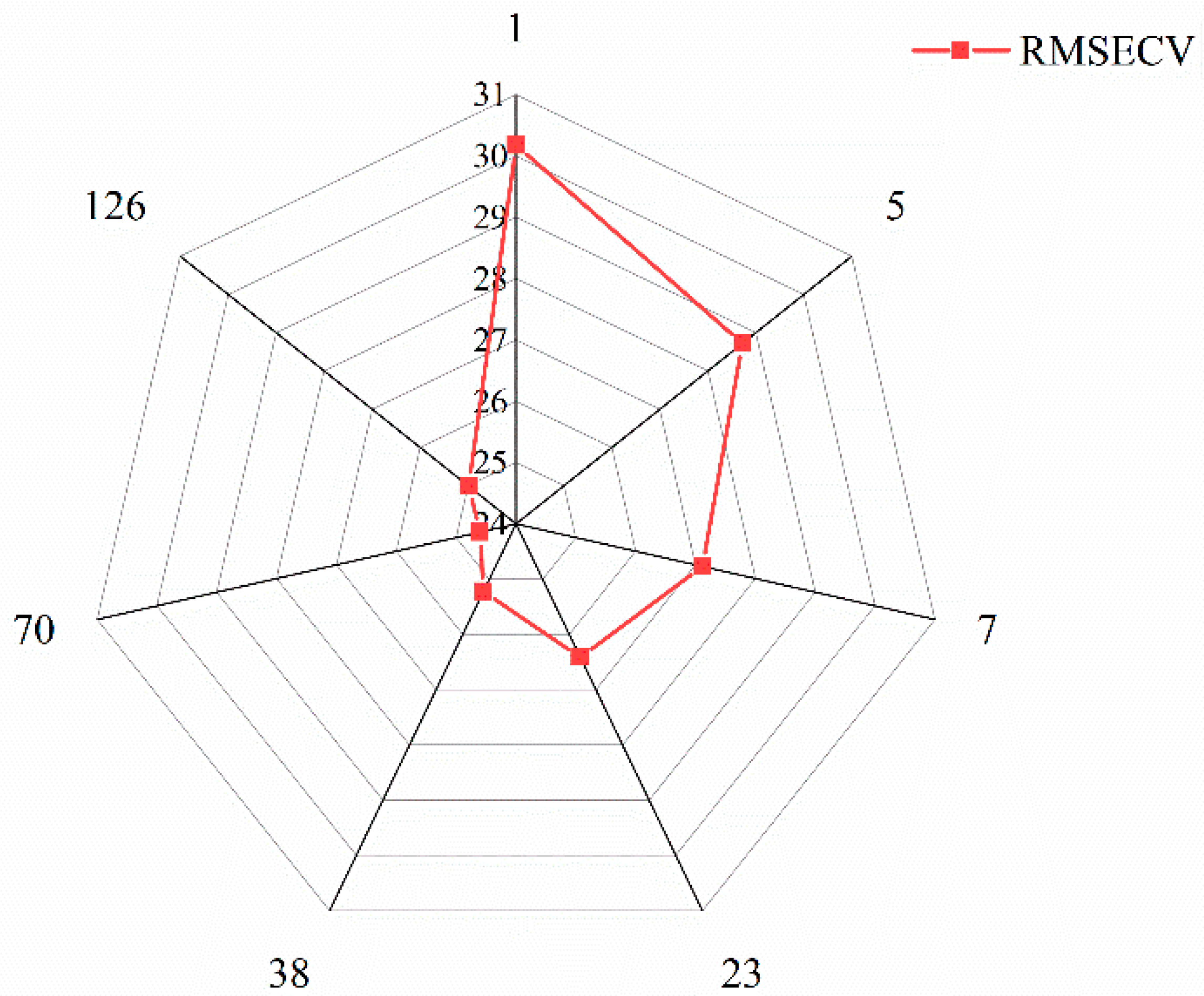
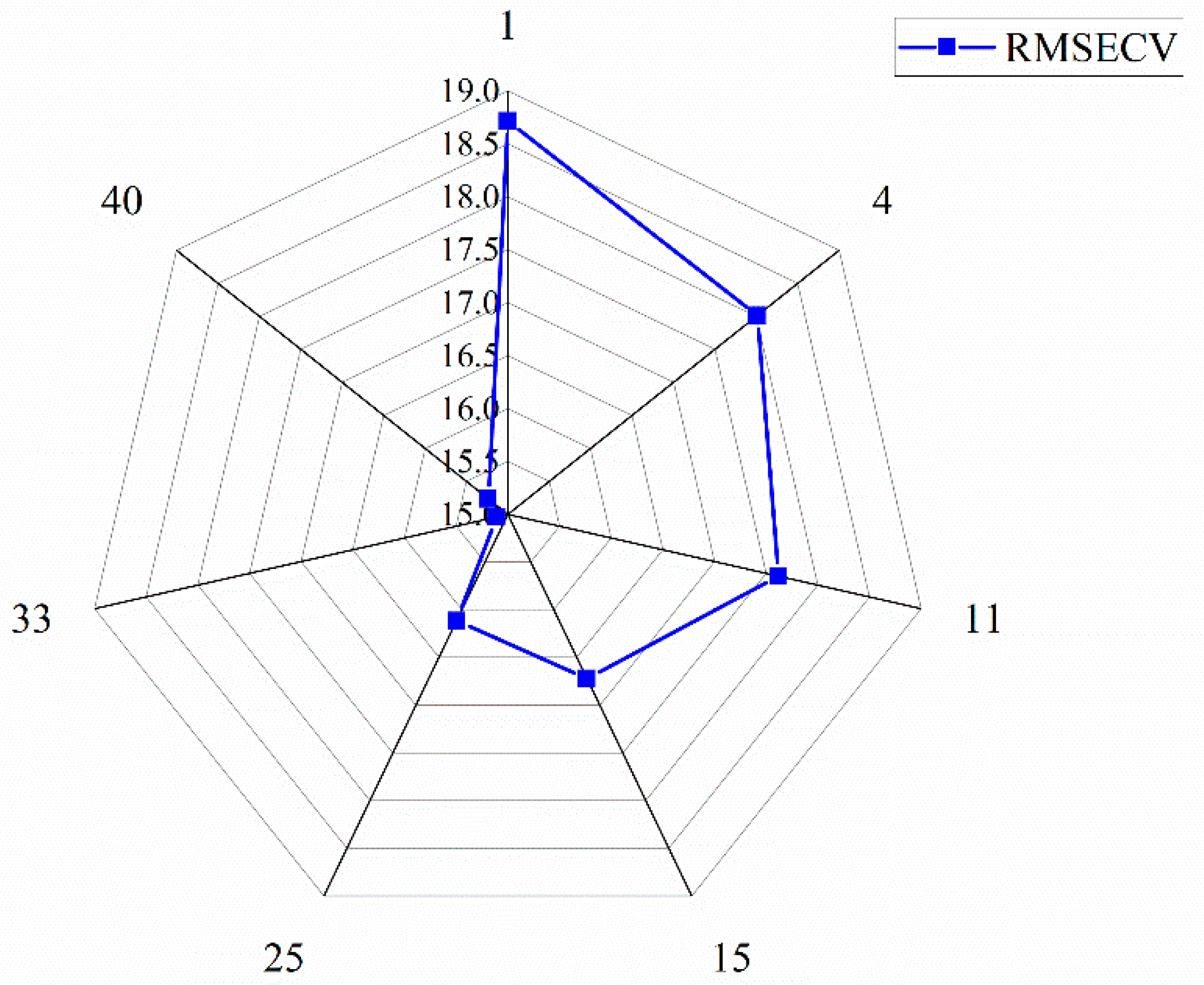
3.3. Results of si-PLS Model
3.4. Results of BP-ANN Model
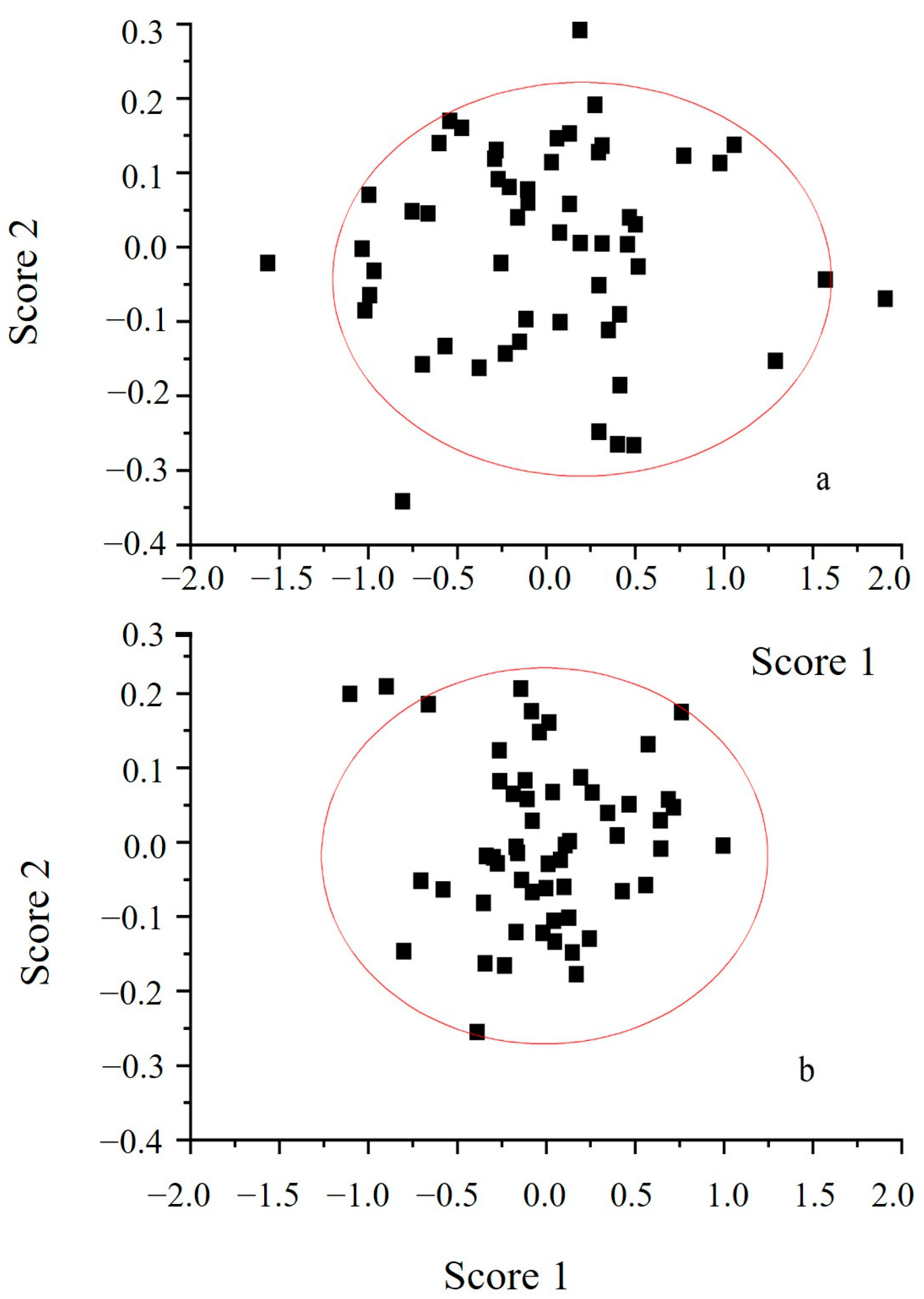
3.4.1. Accurately Screening of Characteristic Spectral Data Points Using GA
3.4.2. Principal Component Analysis (PCA)
3.4.3. BP-ANN Model
4. Conclusions
- (1)
- The QI, seven quality grades, and purchase price of fresh tea samples have shown a linear relationship in pairs, with the R2 being greater than 0.99. The QI of the seven grades fresh tea samples all had statistical significance (p < 0.05).
- (2)
- The best preprocessing method for the original spectra was the combination method of (SNV+SD); four spectral intervals closely related to fresh tea prices were screened out using the si-PLS method, namely 4377.62 cm−1–4751.74 cm−1, 4755.63 cm−1–5129.75 cm−1, 6262.70 cm−1–6633.93 cm−1, and 7386 cm−1–7756.32 cm−1.
- (3)
- The GA was applied to accurately extract 70 feature spectral data points and 33 feature spectral data points from DSD and FSD, respectively. The cumulative contribution rates of the first three PCs were 99.856% and 99.852%, respectively; However, the spatial distance of the samples extracted from FSD was smaller, and the clustering effect was more pronounced.
- (4)
- The BP-ANN model of price was constructed with the 3-5-1 structure, and the best results were obtained using the logistic transfer function (Rp2 = 0.985, RMSEP = 6.732 RMB/kg). The model results established by 33 feature spectral data points were slightly better than those of 70 feature spectral data points.
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- DB 42/T 351-2010; Product of Geographical Indication-Enshi Yulu. China Standards Press: Beijing, China, 2010.
- Xia, T. Tea Processing Science, 3rd ed.; China Agriculture Press: Beijing, China, 2016. [Google Scholar]
- DB 42/T 611-2010; Processing Technical Regulations of Enshi Yulu. China Standards Press: Beijing, China, 2010.
- Zhang, J.; Gong, S.Y.; Tang, D.S.; Zhang, Y.B.; Chen, M.L. Quality evaluation and price discrimination of Jasmine-scented tea. J. Zhejiang Univ. 2015, 41, 577–585. [Google Scholar]
- Dong, C.W.; An, T.; Zhu, H.K.; Wang, J.J.; Hu, B.; Jiang, Y.W.; Yang, Y.Q.; Li, J. Rapid sensing of key quality components in black tea fermentation using electrical characteristics coupled to variables selection algorithms. Sci. Rep. 2020, 10, 1598. [Google Scholar] [CrossRef] [PubMed]
- Yang, Y.Q.; Zhang, M.M.; Hua, J.J.; Deng, Y.L.; Jiang, Y.W.; Li, J.; Wang, J.J.; Yuan, H.B.; Dong, C.W. Quantitation of pyrazines in roasted green tea by infrared-assisted extraction coupled to headspace solid-phase microextraction in combination with GC-QqQ-MS/MS. Food Res. Int. 2020, 134, 109167. [Google Scholar] [CrossRef] [PubMed]
- Ren, G.X.; Wang, S.P.; Ning, J.M.; Xu, R.R.; Wang, Y.X.; Xing, Z.Q.; Wan, X.C.; Zhang, Z.Z. Quantitative analysis and geographical traceability of black tea using Fourier transform near-infrared spectroscopy (FT-NIRS). Food Res. Int. 2013, 53, 822–826. [Google Scholar] [CrossRef]
- Zhang, Z.Z.; Wang, S.P.; Wan, X.C.; Yan, S.H. Evaluation of sensory and composition properties in young tea shoots and their estimation by near infrared spectroscopy and partial least squares techniques. Spectrosc. Eur. 2011, 23, 17–21. [Google Scholar]
- Khan, A.; Munir, M.T.; Yu, W.; Young, B.R. Near-infrared spectroscopy and data analysis for predicting milk powder quality attributes. Int. J. Dairy Technol. 2021, 74, 235–245. [Google Scholar] [CrossRef]
- Silva, L.K.R.; Jesus, J.C.; Onelli, R.R.V.; Conceição, D.G.; Santos, L.S.; Ferrão, S.P.B. Discriminating Coalho cheese by origin through near and middle infrared spectroscopy and analytical measures. Discrimination of Coalho cheese origin. Int. J. Dairy Technol. 2021, 74, 393–403. [Google Scholar] [CrossRef]
- Fagnani, R.; Damião, B.M.C.; Trentin, R.P.S.; Vanot, R.L. Predicting adulteration of grated Parmigiano Reggiano cheese with Ricotta using electrophoresis, multivariate nonlinear regression and computational intelligence methods. Int. J. Dairy Technol. 2022, 75, 239–245. [Google Scholar] [CrossRef]
- Guillemain, A.; Dégardin, K.; Roggo, Y. Performance of NIR handheld spectrometers for the detection of counterfeit tablets. Talanta 2017, 165, 632–640. [Google Scholar] [CrossRef]
- Malegori, C.; Marques, E.J.N.; Freitas, S.T.; Pimentel, M.F.; Pasquini, C.; Casiraghi, E. Comparing the analytical performances of Micro-NIR and FT-NIR spectrometers in the evaluation of acerola fruit quality, using PLS and SVM regression algorithms. Talanta 2017, 165, 112–116. [Google Scholar] [CrossRef]
- Wang, J.H.; Wang, Y.F.; Cheng, J.J.; Wang, J.; Sun, X.D.; Sun, S.; Zhang, Z.Y. Enhanced cross-category models for predicting the total polyphenols, caffeine and free amino acids contents in Chinese tea using NIR spectroscopy. LWT 2018, 96, 90–97. [Google Scholar] [CrossRef]
- Wang, S.P.; Liu, P.P.; Feng, L.; Teng, J.; Ye, F.; Gui, A.H.; Wang, X.P.; Zheng, L.; Gao, S.W.; Zheng, P.C. Rapid determination of tea polyphenols content in Qingzhuan tea based on near infrared spectroscopy in conjunction with three different PLS algorithms. Food Sci. Technol. 2022, 42, e94322. [Google Scholar] [CrossRef]
- Wang, S.P.; Zhang, Z.Z.; Ning, J.M.; Ren, G.X.; Yan, S.H.; Wan, X.C. Back propagation-artificial neural network model for prediction of the quality of tea shoots through selection of relevant near infrared spectral data via synergy interval partial least squares. Anal. Lett. 2013, 46, 184–195. [Google Scholar] [CrossRef]
- Wu, X.H.; He, F.; Wu, B.; Zeng, S.P.; He, C.Y. Accurate classification of Chunmee tea grade using NIR spectroscopy and fuzzy maximum uncertainty linear discriminant analysis. Foods 2023, 12, 541. [Google Scholar] [CrossRef] [PubMed]
- Lv, W.Z. Modern Near Infrared Spectroscopy Analysis Technology, 1st ed.; China Petrochemical Press: Beijing, China, 2006. [Google Scholar]
- Ren, D.; Qu, F.F.; Lv, K.; Zhang, Z.; Xu, H.L.; Wang, X.Y. A gradient descent boosting spectrum modeling method based on back interval partial least squares. Neurocomputing 2016, 171, 1038–1046. [Google Scholar] [CrossRef]
- Jiang, S.; Tian, H.; Wang, Y.W.; Jin, L.; Rong, J.; Kang, S.Q.; Cao, L.A.; Gao, D.B.; Li, H.S.; Liu, J.T.; et al. Optimization of source pencils loading plan with genetic algorithm for gamma irradiation facility. Radiat. Phys. Chem. 2023, 207, 110839. [Google Scholar] [CrossRef]
- Ghaziri, A.E.; Qannari, E.M. A continuum standardization of the variables. Application to principal components analysis and PLS-regression. Chemom. Intell. Lab. Syst. 2015, 148, 95–105. [Google Scholar] [CrossRef]
- Liu, Y.D.; Sun, X.D.; Ouyang, A.G. Nondestructive measurement of soluble solid content of navel orange fruit by visible-NIR spectrometric technique with PLSR and PCA-BPNN. LWT-Food Sci. Technol. 2010, 43, 602–607. [Google Scholar] [CrossRef]
- Wang, S.P.; Wan, X.C.; Lin, M.X.; Zhang, Z.Z. Estimating the quality of tea leaf materials based on contents of moisture, total Nitrogen and crude fiber by NIR-PLS techniques. J. Tea Sci. 2011, 31, 66–71. [Google Scholar]
- Gai, J.Y. Experimental Statistical Methods, 3rd ed.; China Agriculture Press: Beijing, China, 2001. [Google Scholar]
- Wan, X.C. Tea Biochemistry, 3rd ed.; China Agriculture Press: Beijing, China, 2003. [Google Scholar]
- Li, Y.J.; Altaner, C.M. Effects of variable selection and processing of NIR and ATR-IR spectra on the prediction of extractive content in Eucalyptus bosistoana heartwood. Spectrochim. Acta Part A Mol. Biomol. Spectrosc. 2019, 213, 111–117. [Google Scholar] [CrossRef]
- Yan, Y.L.; Chen, B.; Zhu, D.Z. Near Infrared Spectroscopy-Principles, Technologies and Applications, 1st ed.; China Light Industry Press: Beijing, China, 2013. [Google Scholar]
- Rahi, S.; Mobli, H.; Jamshidi, B.; Azizi, A.; Sharifi, M. Achieving a robust Vis/NIR model for microbial contamination detection of Persian leek by spectral analysis based on genetic, iPLS algorithms and VIP scores. Postharvest Biol. Technol. 2021, 175, 111413. [Google Scholar] [CrossRef]
- Wang, S.P.; Gong, Z.M. Introduction to Near-Infrared Spectroscopy Technology and Its Application in the Evaluation of Fresh Tea Leaves, 1st ed.; China Agricultural Science and Technology Press: Beijing, China, 2019. [Google Scholar]
- Chen, S.Y. Applied Multivariate Statistical Analysis, 2nd ed.; Peking University Press: Beijing, China, 2014. [Google Scholar]
- Liu, K.Z.; Shi, W.W.; Huang, C.J.; Zeng, D.D. Cost effective Tanh activation function circuits based on fast piecewise linear logic. Microelectron. J. 2023, 138, 105821. [Google Scholar] [CrossRef]
- Sabbaghi, H.; Tabatabaei, S.H. Data-driven logistic function for weighting of geophysical evidence layers in mineral prospectivity mapping. J. Appl. Geophys. 2023, 212, 104986. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Tenderness | Grade 1 | Grade 2 | Grade 3 | Grade 4 | Grade 5 | Grade 6 | Grade 7 |
|---|---|---|---|---|---|---|---|
| Bud | 100 | 0 | 0 | 0 | 0 | 0 | 0 |
| One bud and first leaf | 0 | 100 | 85 | 75 | 25 | 0 | 0 |
| One bud and two leaves | 0 | 0 | 15 | 25 | 75 | 75 | 25 |
| One bud and three leaves | 0 | 0 | 0 | 0 | 0 | 25 | 75 |
| Grades | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
|---|---|---|---|---|---|---|---|
| 1 | - | 3.25 | 4.23 | 6.33 | 9.12 | 9.31 | 11.76 |
| 2 | 3.25 | - | 3.98 | 5.85 | 8.82 | 8.87 | 11.65 |
| 3 | 4.23 | 3.98 | - | 5.20 | 8.16 | 8.05 | 10.63 |
| 4 | 6.33 | 5.85 | 5.20 | - | 7.52 | 7.48 | 9.35 |
| 5 | 9.12 | 8.82 | 8.16 | 7.52 | - | 6.68 | 8.26 |
| 6 | 9.31 | 8.87 | 8.05 | 7.48 | 6.68 | - | 5.21 |
| 7 | 11.76 | 11.65 | 10.63 | 9.35 | 8.26 | 5.21 | - |
| Number of Intervals | PLS Factors | Selected Intervals | RMSECV (RMB/kg) |
|---|---|---|---|
| 10 | 9 | [1 4] | 27.656 |
| 11 | 10 | [1 3 7 12] | 27.143 |
| 12 | 10 | [5 8 10 12] | 25.632 |
| 13 | 8 | [6 7 10 11] | 22.512 |
| 14 | 9 | [1 8 10 12] | 19.647 |
| 15 | 9 | [1 4 7 10] | 17.251 |
| 16 | 8 | [2 3 7 10] | 15.340 |
| 17 | 9 | [1 7 12 14] | 15.785 |
| 18 | 9 | [2 9 10 14] | 16.431 |
| 19 | 9 | [4 6 8 12] | 16.876 |
| 20 | 7 | [3 7 11 13] | 17.122 |
| 21 | 10 | [3 5 7 14] | 17.524 |
| 22 | 9 | [10 12 15 18] | 17.936 |
| 23 | 9 | [1 4 7 8] | 18.451 |
| 24 | 9 | [1 4 8 11] | 18.624 |
| 25 | 9 | [4 8 11 19] | 18.875 |
| Spectral Information | Feature Spectral Data Points (cm−1) |
|---|---|
| DSD (70) | 4269.63, 4393.05, 4477.90, 4524.18, 4720.89, 4801.88, 4805.74, 4859.74, 4863.59, 4894.45, 4956.16, 4994.73, 5095.01, 5376.57, 5399.71, 5411.28, 5430.56, 5434.42, 5442.13, 5457.56, 5472.99, 5507.70, 5515.42, 5650.41, 5661.98, 5665.84, 5669.69, 5673.55, 5719.83, 5766.12, 5773.83, 5881.82, 6032.24, 6086.24, 6194.24, 6201.95, 6545.22, 6857.63, 6984.91, 7108.33, 7131.47, 7208.61, 7231.75, 7289.60, 7308.89, 7328.17, 7339.74, 7343.60, 7347.46, 7374.46, 7382.17, 7432.31, 7532.59, 7567.30, 7636.73, 7667.58, 7729.29, 7760.15, 7837.29, 7891.29, 7899.00, 8022.42, 8296.26, 8697.39, 8701.24, 8708.96, 8751.38, 9044.51, 9414.77, 9569.05. |
| FSD (33) | 4474.04, 477.90, 4481.76, 4574.32, 4605.18, 4612.89, 4778.74, 4782.60, 4786.45, 4805.74, 4809.60, 4821.17, 4879.02, 4882.88, 4936.88, 4940.73, 4987.02, 5079.58, 5083.44, 5087.30, 5106.58, 5110.44, 5114.29, 6286.80, 6313.80, 6506.65, 6541.36, 6545.22, 6603.07, 6317.66, 6321.51, 6549.07, 7706.15. |
| PCs | PC1 | PC (1–2) | PC (1–3) | PC (1–4) | PC (1–5) | PC (1–6) |
|---|---|---|---|---|---|---|
| Cumulative contribution rate of DSD 70 data points/% | 94.828 | 98.558 | 99.856 | 99.934 | 99.968 | 99.981 |
| Cumulative contribution rate of FSD 33 data points/% | 93.101 | 99.338 | 99.852 | 99.957 | 99.986 | 99.992 |
| Transfer Functions | Calibration Set | Prediction Set | ||
|---|---|---|---|---|
| Rc2 | RMSECV (RMB/kg) | Rp2 | RMSEP (RMB/kg) | |
| linear [−1, 1] | 0.845 | 11.164 | 0.812 | 14.014 |
| tanh | 0.883 | 10.135 | 0.857 | 10.875 |
| logistic | 0.912 | 8.436 | 0.873 | 10.364 |
| Transfer Functions | Calibration Set | Prediction Set | ||
|---|---|---|---|---|
| Rc2 | RMSECV (RMB/kg) | Rp2 | RMSEP (RMB/kg) | |
| linear [−1, 1] | 0.877 | 10.863 | 0.852 | 10.463 |
| tanh | 0.925 | 7.912 | 0.905 | 7.923 |
| logistic | 0.989 | 5.825 | 0.985 | 6.732 |
| No. | True Values | Predicted Values | No. | True Values | Predicted Values |
|---|---|---|---|---|---|
| 1 | 32.5 | 25.65 | 8 | 125 | 132.2 |
| 2 | 34 | 40.1 | 9 | 146 | 154.2 |
| 3 | 65 | 60.5 | 10 | 150 | 142.65 |
| 4 | 73 | 79.25 | 11 | 180 | 186.3 |
| 5 | 85 | 80.25 | 12 | 186 | 180.6 |
| 6 | 93 | 87.62 | 13 | 210 | 200.4 |
| 7 | 118 | 110.4 | 14 | 213 | 219.0 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, S.; Feng, L.; Liu, P.; Gui, A.; Teng, J.; Ye, F.; Wang, X.; Xue, J.; Gao, S.; Zheng, P. Digital Prediction of the Purchase Price of Fresh Tea Leaves of Enshi Yulu Based on Near-Infrared Spectroscopy Combined with Multivariate Analysis. Foods 2023, 12, 3592. https://doi.org/10.3390/foods12193592
Wang S, Feng L, Liu P, Gui A, Teng J, Ye F, Wang X, Xue J, Gao S, Zheng P. Digital Prediction of the Purchase Price of Fresh Tea Leaves of Enshi Yulu Based on Near-Infrared Spectroscopy Combined with Multivariate Analysis. Foods. 2023; 12(19):3592. https://doi.org/10.3390/foods12193592
Chicago/Turabian StyleWang, Shengpeng, Lin Feng, Panpan Liu, Anhui Gui, Jing Teng, Fei Ye, Xueping Wang, Jinjin Xue, Shiwei Gao, and Pengcheng Zheng. 2023. "Digital Prediction of the Purchase Price of Fresh Tea Leaves of Enshi Yulu Based on Near-Infrared Spectroscopy Combined with Multivariate Analysis" Foods 12, no. 19: 3592. https://doi.org/10.3390/foods12193592
APA StyleWang, S., Feng, L., Liu, P., Gui, A., Teng, J., Ye, F., Wang, X., Xue, J., Gao, S., & Zheng, P. (2023). Digital Prediction of the Purchase Price of Fresh Tea Leaves of Enshi Yulu Based on Near-Infrared Spectroscopy Combined with Multivariate Analysis. Foods, 12(19), 3592. https://doi.org/10.3390/foods12193592