

Modeling and Optimization of Triticale Wort Production Using an Artificial Neural Network and a Genetic Algorithm


Abstract
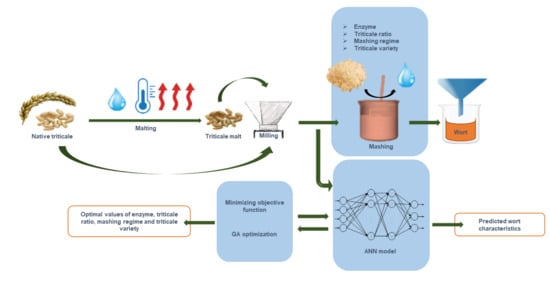
:
1. Introduction
2. Materials and Methods
2.1. Materials
2.2. Methods
2.2.1. Mashing Process
2.2.2. Mashing Process Modelling
2.2.3. Mashing Process Model Optimization
3. Results and Discussion
3.1. Influence of Triticale Characteristics on Wort Quality
3.2. Dataset Analysis
3.3. ANN Training Results
3.4. ANN Test Results
3.5. Optimization Results Applying GA
3.6. Experimental Verification
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Dabija, A.; Ciocan, M.E.; Chetrariu, A.; Codină, G.G. Maize and sorghum as raw materials for brewing, a review. Appl. Sci. 2021, 11, 3139. [Google Scholar] [CrossRef]
- Materna, K.; Bernhäuserová, V.; Hasman, J.; Hána, D. How microbreweries flooded Europe: Mapping a new phenomenon in the beer industry. J. Maps 2022, 18, 18–25. [Google Scholar] [CrossRef]
- Anderson, H.E.; Santos, I.C.; Hildenbrand, Z.L.; Schug, K.A. A review of the analytical methods used for beer ingredient and finished product analysis and quality control. Anal. Chim. Acta 2019, 1085, 1–20. [Google Scholar] [CrossRef] [PubMed]
- Yorke, J.; Cook, D.; Ford, R. Brewing with unmalted cereal adjuncts: Sensory and analytical impacts on beer quality. Beverages 2021, 7, 4. [Google Scholar] [CrossRef]
- Ozatay, S. Recent Applications of Enzymes in Food Industry. J. Curr. Res. Eng. Sci. Technol. 2020, 6, 17–30. [Google Scholar] [CrossRef]
- Steiner, E.; Auer, A.; Becker, T.; Gastl, M. Comparison of beer quality attributes between beers brewed with 100% barley malt and 100% barley raw material. J. Sci. Food Agric. 2012, 92, 803–813. [Google Scholar] [CrossRef] [PubMed]
- Gomaa, A.M. Application of Enzymes in Brewing. J. Nutr. Food Sci. Forecast. 2018, 1, 17–30. [Google Scholar]
- Cadenas, R.; Caballero, I.; Nimubona, D.; Blanco, C.A. Brewing with starchy adjuncts: Its influence on the sensory and nutritional properties of beer. Foods 2021, 10, 1726. [Google Scholar] [CrossRef]
- Rosa, R.S.; Lannes, S.C.d.S. Impact of the use of unmalted adjuncts on the rheological properties of beer wort. Food Sci. Technol. 2022, 42, 1–8. [Google Scholar] [CrossRef]
- Kok, Y.J.; Ye, L.; Muller, J.; Ow, D.S.W.; Bi, X. Brewing with malted barley or raw barley: What makes the difference in the processes? Appl. Microbiol. Biotechnol. 2019, 103, 1059–1067. [Google Scholar] [CrossRef]
- Ambriz-Vidal, T.N.; Mariezcurrena-Berasain, M.D.; Heredia-Olea, E.; Pinzon Martinez, D.L.; Gutierrez-Ibañez, A.T. Potential of Triticale (X Triticosecale Wittmack) Malts for Beer Wort Production. J. Am. Soc. Brew. Chem. 2019, 77, 282–286. [Google Scholar] [CrossRef]
- Cioch-Skoneczny, M.; Zdaniewicz, M.; Pater, A.; Skoneczny, S. Impact of triticale malt application on physiochemical composition and profile of volatile compounds in beer. Eur. Food Res. Technol. 2019, 245, 1431–1437. [Google Scholar] [CrossRef]
- Hu, S.; Dong, J.; Fan, W.; Yu, J.; Yin, H.; Huang, S.; Liu, J.; Huang, S.; Zhang, X. The influence of proteolytic and cytolytic enzymes on starch degradation during mashing. J. Inst. Brew. 2014, 120, 379–384. [Google Scholar] [CrossRef]
- Lalor, E.; Goode, D. Brewing with Enzymes. In Enzymes in Food Technology, 2nd ed.; Whitehurst, R.J., van Oor, M., Eds.; Blackwell Publishing Ltd.: Clive, IA, USA, 2009; pp. 163–193. [Google Scholar]
- Demeester, A.; Laureys, D.; Baillière, J.; Huys, J.; Vermeir, P.; De Leyn, I.; Vanderputten, D.; De Clippeleer, J. Comparison of Congress Mash with Final 65 °C Mash for Wort Production with Unmalted Barley, Tritordeum, and Quinoa, with or without Pregelatinization and/or Enzyme Addition. J. Am. Soc. Brew. Chem. 2023, 81, 66–75. [Google Scholar] [CrossRef]
- Min, W.; Jiang, S.; Liu, L.; Rui, Y.; Jain, R. A Survey on Food Computing. ACM Comput. Surv. 2019, 52, 92. [Google Scholar] [CrossRef]
- Gonzalez Viejo, C.; Fuentes, S.; Torrico, D.D.; Godbole, A.; Dunshea, F.R. Chemical characterization of aromas in beer and their effect on consumers liking. Food Chem. 2019, 293, 479–485. [Google Scholar] [CrossRef]
- Takahashi, M.B.; Coelho de Oliveira, H.; Fernández Núñez, E.G.; Rocha, J.C. Brewing process optimization by artificial neural network and evolutionary algorithm approach. J. Food Process Eng. 2019, 42, e13103. [Google Scholar] [CrossRef]
- Mane, S.U.; Rao, M.R.N. Many-Objective Optimization: Problems and Evolutionary Algorithms-A Short Review. Int. J. Appl. Eng. Res. 2017, 12, 9774–9793. [Google Scholar]
- Imandi, S.B.; Karanam, S.K.; Nagumantri, R.; Srivastava, R.K.; Sarangi, P.K. Neural networks and genetic algorithm as robust optimization tools for modeling the microbial production of poly-β-hydroxybutyrate (PHB) from Brewers’ spent grain. Biotechnol. Appl. Biochem. 2023, 70, 962–978. [Google Scholar] [CrossRef]
- Becker, T.; Enders, T.; Delgado, A. Dynamic neural networks as a tool for the online optimization of industrial fermentation. Bioprocess Biosyst. Eng. 2002, 24, 347–354. [Google Scholar]
- Dębska, B.; Guzowska-Świder, B. Application of artificial neural network in food classification. Anal. Chim. Acta 2011, 705, 283–291. [Google Scholar] [CrossRef] [PubMed]
- Zhang, Y.; Jia, S.; Zhang, W. Predicting acetic acid content in the final beer using neural networks and support vector machine. J. Inst. Brew. 2012, 118, 361–367. [Google Scholar] [CrossRef]
- Hassen, E.B.; Asmare, A.M. Predictive performance modeling of Habesha brewery wastewater treatment plant using artificial neural networks. Chem. Int. 2019, 5, 87–96. [Google Scholar]
- Methodensammlung der Mitteleuropäischen Analysenkommission. Raw Materials: Barley, Adjuncts, Malt, Hops and Hop Products; MEBAK: Freising, Germany, 2011. [Google Scholar]
- Glatthar, J.; Heinisch, J.; Senn, T. A study on the suitability of unmalted triticale as a brewing adjunct. J. Am. Soc. Brew. Chem. 2002, 60, 181–187. [Google Scholar] [CrossRef]
- Black, K.; Tziboula-Clarke, A.; White, P.J.; Iannetta, P.P.M.; Walker, G. Optimised processing of faba bean (Vicia faba L.) kernels as a brewing adjunct. J. Inst. Brew. 2021, 127, 13–20. [Google Scholar] [CrossRef]
- Puligundla, P.; Smogrovicova, D.; Mok, C.; Obulam, V.S.R. Recent developments in high gravity beer-brewing. Innov. Food Sci. Emerg. Technol. 2020, 64, 102399. [Google Scholar] [CrossRef]
- Goode, D.L.; Arendt, E.K. Developments in the supply of adjunct materials for brewing. In Brewing; Bamforth, C.W., Ed.; Blackwell Publishing Ltd.: Cambridge, UK, 2006; pp. 30–67. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Independent variables | Triticale variety | ‘NS Paun’ and ‘Odisej’ both in unmalted and malted forms |
| Triticale ratio in the grist (%) | 10, 30, 50, and 70 | |
| Enzyme quantity (µL) | 50, 10, and 5 | |
| Mashing regime | Congress mashing [25]: Initial temperature of 50 °C was maintained for 40 min. The temperature was then increased to 63 °C and held for 45 min. After the addition of a further 100 mL of distilled water, temperature was raised to 70 °C and held for 30 min. Final temperature of 76 °C was maintained for an additional 10 min. | |
| Modified mashing [26]: Initial temperature of 45 °C was maintained for 30 min before it was increased up to 70 °C at 1 °C/min. After the addition of a further 100 mL of distilled water, the temperature was maintained at 70 °C for a further 60 min. | ||
| Dependent variables | Quality parameters | Wort extract content, wort viscosity, and FAN content |
| Outputs | |||||
|---|---|---|---|---|---|
| Variety | Enzyme Addition | Wort Extract Content (% w/w) | Wort Viscosity (mPa·s) | Wort FAN Content (mg/L) | |
| Unmalted | NS Paun | Without enzyme | 8.28–8.49 | 1.626–1.765 | 64.1–129.42 |
| 50 µL (100%) | 8.13–8.38 | 1.384–1.498 | 77.23–148.16 | ||
| 10 µL (20%) | 8.22–8.39 | 1.403–1.587 | 70.81–141.89 | ||
| 5 µL (10%) | 8.22–8.46 | 1.576–1.613 | 67.23–136.37 | ||
| Odisej | Without enzyme | 8.27–8.47 | 1.639–2.220 | 56.0–120.78 | |
| 50 µL (100%) | 8.22–8.33 | 1.386–1.495 | 74.62–139.99 | ||
| 10 µL (20%) | 8.22–8.43 | 1.401–1.588 | 67.33–130.03 | ||
| 5 µL (10%) | 8.22–8.45 | 1.538–1.629 | 64.24–124.55 | ||
| Malted | NS Paun | Without enzyme | 8.75–8.89 | 1.500–1.755 | 130.95–156.12 |
| 50 µL (100%) | 8.45–8.80 | 1.432–1.582 | 157.43–191.37 | ||
| 10 µL (20%) | 8.49–8.81 | 1.461–1.583 | 142.19–189.04 | ||
| 5 µL (10%) | 8.54–8.83 | 1.468–1.590 | 146.98–187.97 | ||
| Odisej | Without enzyme | 8.69–8.78 | 1.564–1.833 | 125.80–142.91 | |
| 50 µL (100%) | 8.39–8.71 | 1.440–1.570 | 143.37–186.35 | ||
| 10 µL (20%) | 8.42–8.74 | 1.498–1.685 | 140.50–184.46 | ||
| 5 µL (10%) | 8.46–8.77 | 1.500–1.783 | 139.76–183.59 | ||
| Outputs | |||||
|---|---|---|---|---|---|
| Variety | Enzyme Addition | Wort Extract Content (% w/w) | Wort Viscosity (mPa·s) | Wort FAN Content (mg/L) | |
| Unmalted | NS Paun | Without enzyme | 8.21–8.41 | 1.596–1.650 | 71.28–134.67 |
| 50 µL (100%) | 8.12–8.36 | 1.320–1.432 | 79.49–151.82 | ||
| 10 µL (20%) | 8.12–8.37 | 1.408–1.491 | 72.29–147.16 | ||
| 5 µL (10%) | 8.28–8.38 | 1.419–1.527 | 69.70–140.07 | ||
| Odisej | Without enzyme | 8.23–8.44 | 1.607–2.060 | 63.76–132.69 | |
| 50 µL (100%) | 8.20–8.32 | 1.339–1.446 | 76.4–144.33 | ||
| 10 µL (20%) | 8.21–8.40 | 1.415–1.522 | 68.94–138.31 | ||
| 5 µL (10%) | 8.20–8.42 | 1.529–1.618 | 67.04–135.13 | ||
| Malted | NS Paun | Without enzyme | 8.69–8.79 | 1.518–1.713 | 141.27–159.19 |
| 50 µL (100%) | 8.42–8.74 | 1.414–1.502 | 162.38–198.62 | ||
| 10 µL (20%) | 8.48–8.75 | 1.433–1.529 | 154.18–192.72 | ||
| 5 µL (10%) | 8.52–8.77 | 1.430–1.562 | 150.30–188.19 | ||
| Odisej | Without enzyme | 8.65–8.74 | 1.541–1.790 | 138.30–149.20 | |
| 50 µL (100%) | 8.38–8.67 | 1.422–1.563 | 155.13–192.13 | ||
| 10 µL (20%) | 8.40–8.70 | 1.460–1.680 | 150.09–188.90 | ||
| 5 µL (10%) | 8.41–8.71 | 1.480–1.720 | 148.50–184.42 | ||
| Name of Parameter | Min. | Max. | Mean | Std. Dev. | |
|---|---|---|---|---|---|
| Inputs | Triticale ratio (%) | 10 | 70 | 40 | 22.39 |
| Enzyme ratio (%) | 0 | 100 | 32.5 | 39.66 | |
| Mashing regime index | 1 | 2 | 1.5 | 0.5 | |
| Triticale variety index | 1 | 4 | 2.5 | 1.12 | |
| Outputs | Wort extract content (% w/w) | 8.12 | 8.89 | 8.47 | 0.2 |
| Wort viscosity (mPa·s) | 1.320 | 2.220 | 1.56 | 0.13 | |
| FAN content (mg/L) | 56.0 | 198.62 | 130.48 | 39.32 |
| Min. abs. Error | Max. abs. Error | Mean abs. Error | Mean Square Error | Root Mean Square Error | Mean abs. Percent. Error | |
|---|---|---|---|---|---|---|
| Wort extract | 0.001 | 0.007 | 0.004 | 0.00002 | 0.005 | 0.05 |
| Wort viscosity | 0 | 0.005 | 0.002 | 0.00001 | 0.002 | 0.13 |
| FAN in wort | 0.01 | 0.03 | 0.016 | 0.0003 | 0.018 | 0.015 |
| Inputs | Result |
|---|---|
| Triticale ratio (%) | 23 |
| Enzyme ratio (%) | 9 |
| Mashing regime index | Congress–1 |
| Triticale variety index | Malted NS Paun–3 |
| Wort Extract Content (% w/w) | Wort Viscosity (mPa·s) | FAN Content (mg/L) | |
|---|---|---|---|
| GA optimization results | 8.65 | 1.52 | 148.32 |
| Real mashing process | 8.63 ± 0.01 | 1.51 ± 0.02 | 148.88 ± 0.02 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Pribić, M.; Kamenko, I.; Despotović, S.; Mirosavljević, M.; Pejin, J. Modeling and Optimization of Triticale Wort Production Using an Artificial Neural Network and a Genetic Algorithm. Foods 2024, 13, 343. https://doi.org/10.3390/foods13020343
Pribić M, Kamenko I, Despotović S, Mirosavljević M, Pejin J. Modeling and Optimization of Triticale Wort Production Using an Artificial Neural Network and a Genetic Algorithm. Foods. 2024; 13(2):343. https://doi.org/10.3390/foods13020343
Chicago/Turabian StylePribić, Milana, Ilija Kamenko, Saša Despotović, Milan Mirosavljević, and Jelena Pejin. 2024. "Modeling and Optimization of Triticale Wort Production Using an Artificial Neural Network and a Genetic Algorithm" Foods 13, no. 2: 343. https://doi.org/10.3390/foods13020343
APA StylePribić, M., Kamenko, I., Despotović, S., Mirosavljević, M., & Pejin, J. (2024). Modeling and Optimization of Triticale Wort Production Using an Artificial Neural Network and a Genetic Algorithm. Foods, 13(2), 343. https://doi.org/10.3390/foods13020343